機器學習基于不平衡數據預測急性新發缺血性卒中患者院內死亡模型研究
2021-09-03 02:48:56陳思玎谷鴻秋黃馨瑩劉歡姜勇王擁軍
中國卒中雜志 2021年8期
陳思玎,谷鴻秋,黃馨瑩,劉歡,姜勇,2,王擁軍,3,4
卒中是全球死亡率最高的疾病之一,根據全球疾病負擔研究最新估計,2017年我國卒中死亡率為106/10萬,居我國疾病死因首位[1-2]。利用預測模型預測卒中患者結局,對患者進行精準風險分層與管理有利于優化醫療資源配置、降低卒中死亡率。
在結局為二分類問題的醫學數據集中,通常會存在正樣本(如患者死亡)和負樣本(如患者存活)比例不平衡的情況,即少數類樣本數量顯著少于多數類樣本的情況[3]。傳統分類算法會向多數類傾斜,導致少數類樣本檢出率不高[4]。如果不處理不平衡數據,預測的結果會存在偏向性問題,在應用于現實臨床場景時,無法達到準確預測正樣本的目的。本研究利用多中心登記的中國卒中聯盟(China Stoke Center Alliance,CSCA)數據庫,采用欠采樣技術、特征選擇和平衡權重的方法,探索基于不平衡數據預測新發缺血性卒中患者院內死亡的模型,同時比較機器學習模型和傳統logistic模型的預測性能,以期為建立更加完善的缺血性卒中院內死亡預測模型提供借鑒。
1 對象與方法
1.1 研究對象 本研究的研究對象來源于CSCA數據庫。CSCA是一個全國性、以醫院為基礎、多中心、多方面干預和基于證據的績效衡量的監測/反饋系統,是由中國卒中學會發起,國家衛生健康委員會神經系統疾病醫療質量控制中心指導的中國卒中醫療質量規范和改進項目[5]。本研究納入CSCA數據庫2015年8月1日-2019年7月31日急性新發缺血性卒中患者資料。入組標準:①發病年齡≥18歲;②臨床確診為缺血性卒中或TIA;③發病7 d內就診并住院治療的患者。排除標準:①既往有缺血性卒中史或TIA病史;②院內死亡/存活結局缺失。
1.2 預測因子與結局 CSCA數據庫資料的總變量有545個,本研究的結局變量是急性新發缺血性卒中患者院內死亡。結合臨床經驗及急性缺血性卒中早期管理指南、文獻報道的相關評分預測模型和CSCA數據特點確定備選預測因子,包括人口學特征(性別、年齡、民族等)、入院情況(BMI、入院吞咽功能評價等)、卒中單元、卒中嚴重程度(入院NIHSS評分)、既往史(吸煙、飲酒、高血壓等)、地區、家庭人均月收入、院內并發癥(合并心房顫動、心肌梗死等)、院內藥物治療(抗栓藥物、降脂藥物等)和入院首次臨床檢測指標(TC、TG、LDL-C、HDL-C、收縮壓、舒張壓等)等共54個變量(表1)[6-7]。
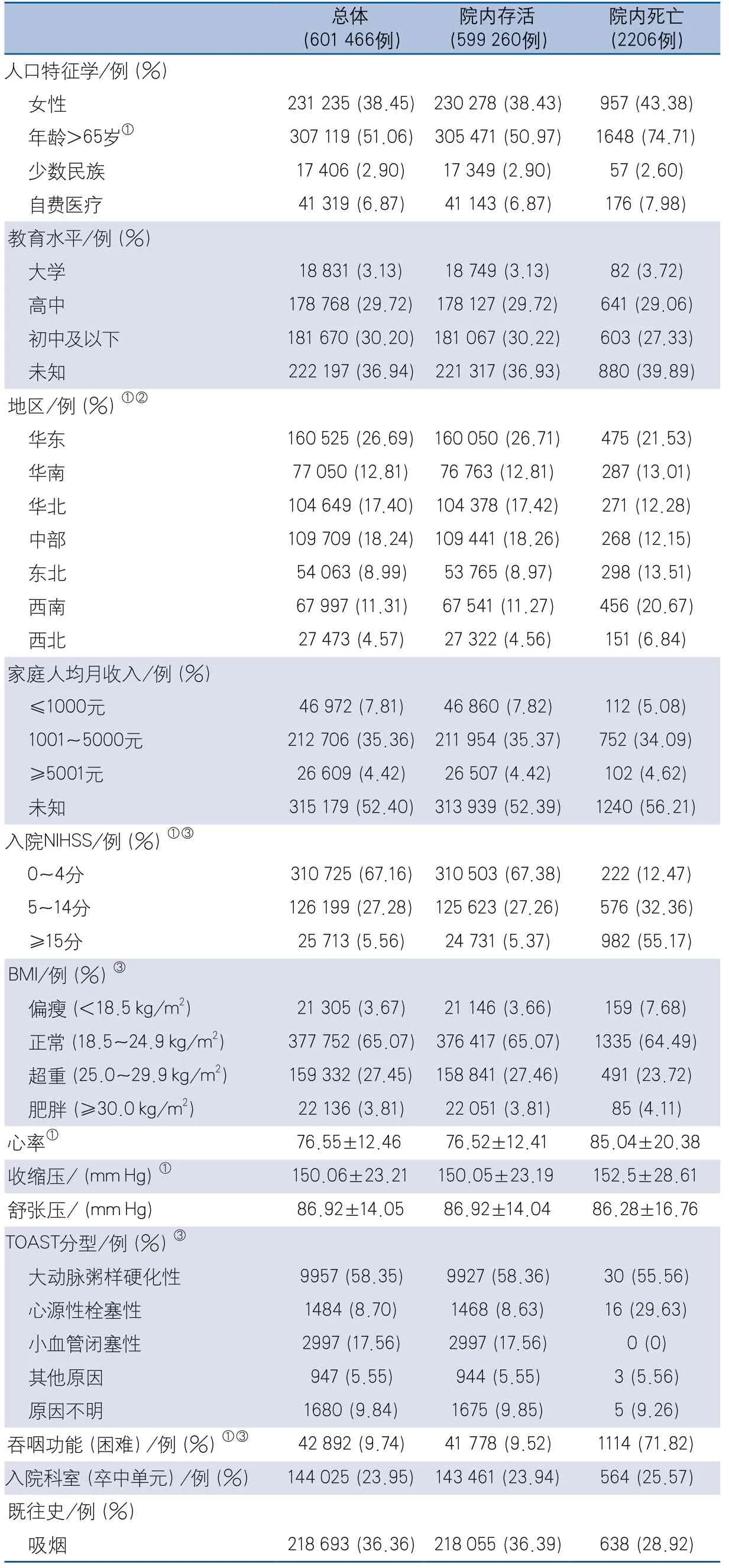
表1 入組患者基本特征
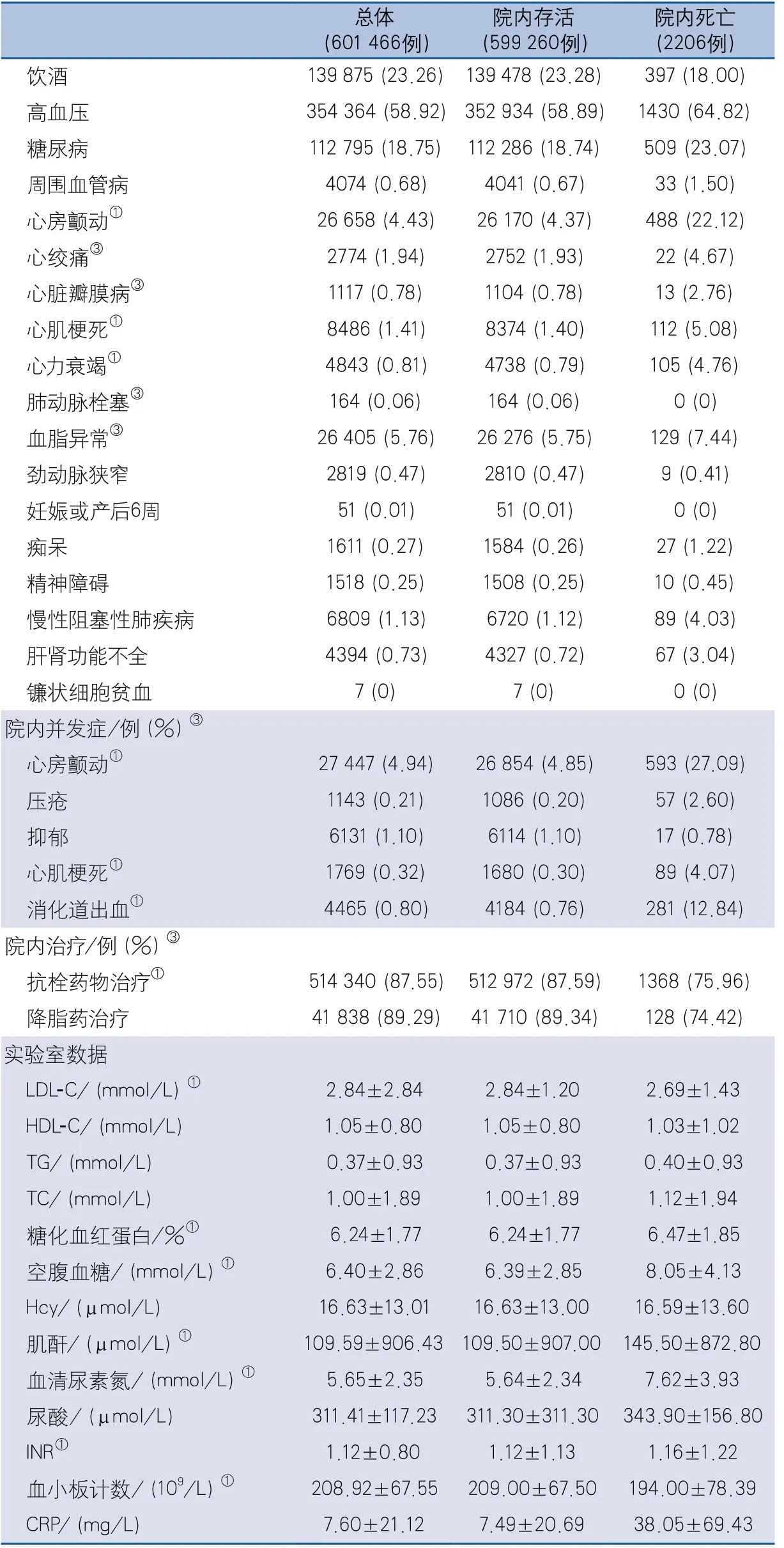
表1(續)
1.3 數據預處理 刪除不合邏輯的異常值,刪除缺失值>30%的變量,連續變量利用interpolate函數進行線性插值法填補,分類變量利用mode函數進行眾數填補。對地區等多分類變量且無等級含義的變量進行獨熱(One-Hot)編碼。由于實驗室數據存在連續變量數值波動范圍較大的問題,本研究利用離差標準化的方法對其進行線性變換,使數據按比例縮放并保持在[0,1]之間。
1.4 數據不平衡處理 數據結構:本研究中正樣本為院內患者死亡,負樣本為院內患者存活,考慮到正負樣本極不平衡,針對處理后的數據集,利用imblearn庫中的隨機欠采樣方法進行不平衡處理,對訓練集的結局變量也進行隨機欠采樣處理。隨機欠采樣原理是從多數類樣本中隨機選取一些樣本剔除掉。設置采樣策略為0.3,即欠采樣后正樣本為負樣本的30%。
算法結構:對每個機器學習模型進行訓練時均設置平衡權重的參數,助推(boosting)模型(XGBoost和Catboost)設置scale_pos_weight參數為負樣本數/正樣本數。隨機森林(random forest)、支持向量機(support vector machine,SVM)和logistic模型設置class_weight為balanced。
1.5 模型構建方法
1.5.1 特征選擇 特征選擇是在建立模型之前減少輸入預測因子數量的過程。考慮到本研究樣本量過大,會存在有統計學意義但可能沒有臨床意義的指標。因此本研究通過機器學習的特征選擇預先挑選出一個最相關的特征子集,這些特征(即預測因子)則是為后續建模做出最大貢獻的預測因子集合。此外,簡化輸入預測因子的數量可以提高計算效率,提高模型的可解釋性。特征選擇過程包括兩個步驟:特征重要性排序和子集特征選擇。
XGBoost是集成學習boosting方法的一種,兼具線性規模求解器和樹學習算法,可以在建造樹的同時自動選擇特征,是一種正則化模型。為了更合理地識別輸入特征的相對重要性,以及防止過擬合并提高模型的泛化能力,本研究利用train_test_split函數以7:3比例的留出法進行5次隨機分組。利用XGBoost模型和SelectFromModel分類器,再對5次隨機分組樣本分別進行特征篩選,對feature_importances_函數特征以重要性排序輸出的前20位預測因子求并集。然后對并集中的所有特征以AUC為標準進行內部循環,設置步長為1,最后篩選出最優特征子集作為后續建模的預測因子。SelectFromModel是一個通用轉換器,如果相應的coef或feature_importances值低于提供的閾值參數,則認為這些特性不重要并將其刪除。
1.5.2 機器學習模型 本研究涉及的機器學習模型有XGBoost、Catboost、隨機森林(random forest)和SVM四種。
①XGBoost模型:XGBoost是美國華盛頓大學于2016年開發的Boosting庫,兼具線性規模求解器和樹學習算法[8]。XGBoost是對損失函數做了二階的泰勒展開,并在目標函數之外加入了正則項,整體求最優解,用于權衡目標函數的下降和模型的復雜程度,避免過擬合,提高模型的求解效率。
②CatBoost模型:CatBoost是一種新的集成學習算法,具有獨特的對稱數結構,通過計算葉子節點的值來構造決策樹,在此過程中,CatBoost對特征進行了量化的度量[9]。
③隨機森林模型:隨機森林是將決策樹作為元分類器的一種集成學習方法,對變量共線性不作要求,其原理是通過自舉(bootstrap)抽樣方法從原始訓練樣本集N中有放回地隨機抽取k個樣本生成相互之間有差異的新的訓練子集,再根據k個訓練子集建立k個決策樹,分類結果由k個決策樹投票決定[10]。
④支持向量機模型:SVM由Cortes與Vapnik[11]提出,Boser等[12]通過加入核技巧將線性支持向量機擴展到非線性支持向量機,SVM的基本模型是一種最大化樣本和類邊界之間距離的線性二分類模型,可以實現結構風險的最小化。此外,SVM模型是基于小樣本數據建立的,能夠有效地避免高維數據分析中的維度災難問題。該模型廣泛適用的分類函數有感知器、多項式和徑向基函數等。
1.6 統計學指標和分析方法 比較不同模型對院內死亡的預測性能時,主要從區分度和校準度兩個方面進行比較和評價。在本研究中,區分度指標采用ROC中的AUC,AUC值越高,表明模型的區分度越高。校準度指標采用Brier得分(評分范圍為0~1),Brier得分越趨近0,模型的校準度越好[13]。以P<0.05為差異有統計學意義。
(3)呼吸道護理:護理人員應密切關注患兒呼吸,因患兒氣管細弱,在幫助患兒吸痰時,應使用直徑較小,材質柔軟的吸管,動作應放輕柔,不可過重,同時,應注意調整負壓,保持用時在15s之內,以免損害粘膜,防止出現呼吸暫停的現象。
本研究涉及的其他指標有準確度、靈敏度、特異度以及G均值(G-mean)。G-mean是靈敏度和特異度的乘積的平方根,使用該指標是為了衡量模型對不平衡數據的整體分類性能,G-mean值越大,說明模型整體預測性能越好。
2 結果
2.1 一般資料 研究共納入急性新發缺血性卒中患者602 259例,剔除院內死亡/存活結局缺失病例793例,最終納入分析601 466例,其中院內死亡患者2206例(0.37%);患者平均年齡為65.43±12.37歲;女性231 235例(38.45%),患者基本特征資料詳見表1。
2.2 預測模型變量篩選結果 選定進入預測模型的最優特征集:經過數據預處理后,剔除9個缺失值>30%的變量,將剩余的45個基線變量作為預測因子進行特征選擇,經過5次重復和內部循環,設置循環步長為1,進入預測因子特征數為20時AUC在訓練集上的表現最佳。這20個預測因子分別為:年齡、地區、入院NIHSS、心率、收縮壓、吞咽功能(困難)、心肌梗死史、心力衰竭史、心房顫動史、院內心房顫動、院內并發心肌梗死、院內消化道出血、抗栓藥物治療及LDL-C、糖化血紅蛋白、血糖、肌酐、血清尿素氮、血小板計數、INR水平。最終上述20個特征組成的最優特征子集進入預測模型。機器學習模型中前3位強預測因子為入院NIHSS、吞咽功能(困難)、空腹血糖,其他特征對結局變量的具體影響見圖1。
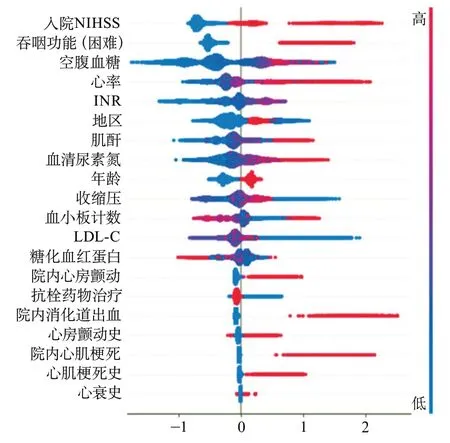
圖1 構建機器學習模型20個預測因子Shapley加法解釋圖
2.3 多因素logistic回歸模型 采用逐步回歸法從20個最優特征中篩選18個預測因子進入logistic回歸預測模型,分別是年齡、地區、入院NIHSS、心率、收縮壓、吞咽功能(困難)、心肌梗死史、心力衰竭史、心房顫動史、院內心房顫動、院內心肌梗死、院內消化道出血、抗栓藥物治療及LDL-C、糖化血紅蛋白、血糖、血清尿素氮、血小板計數水平(表2)。
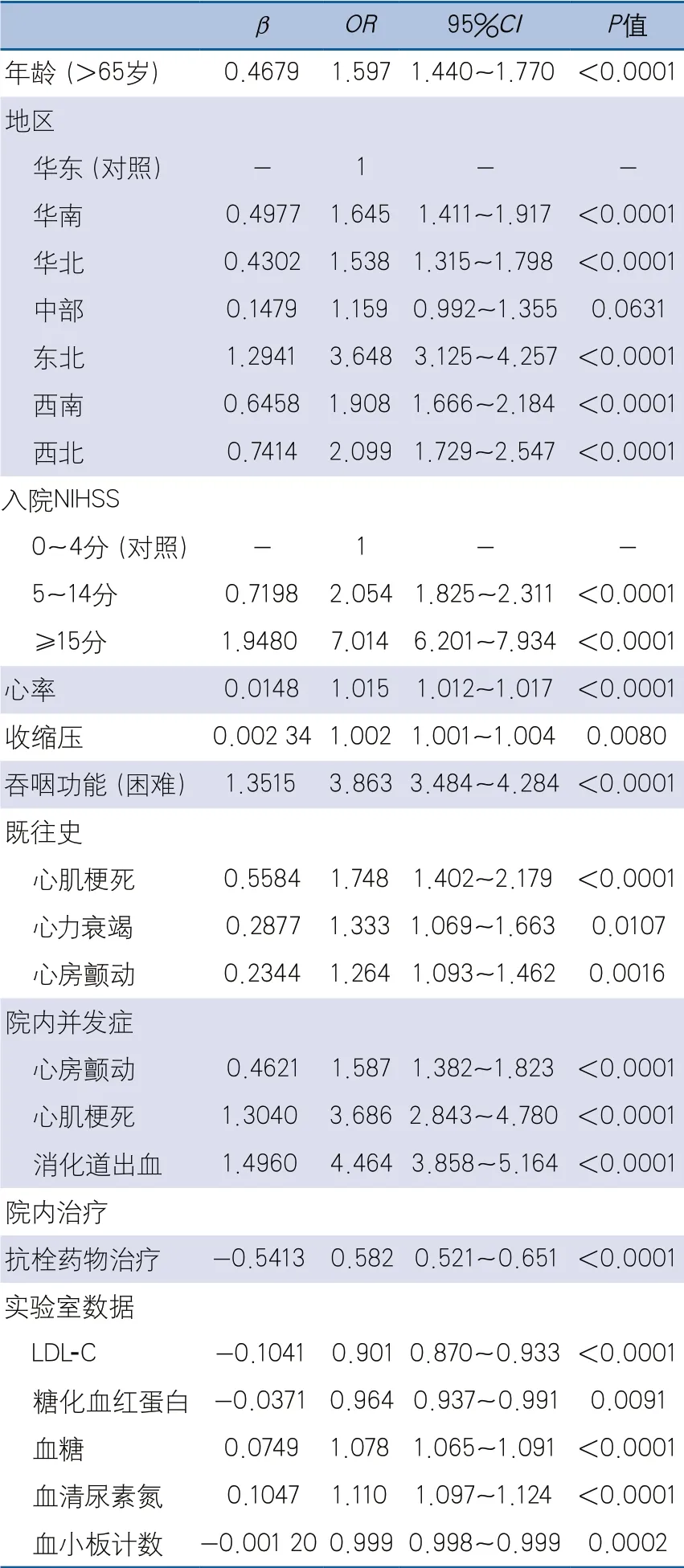
表2 多因素logistic回歸模型篩選出的院內死亡預測因子
2.4 預測性能效果比較 進行數據不平衡處理前,最優特征子集在測試集logistic模型中AUC為0.902±0.007,靈敏度為0.008±0.003,G-mean為0.249±0.366。經過數據不平衡處理后AUC為0.913±0.000,靈敏度為0.824±0.002,G-mean為0.846±0.001。
平衡數據后,測試集中機器學習XGBoost模型AUC為0.921±0.000,CatBoost模型AUC為0.919±0.001,隨機森林模型AUC為0.925±0.000,SVM模型AUC為0.900±0.001。其中XGBoost模型(P=0.0002)、CatBoost模型(P=0.0094)和隨機森林模型(P<0.0001)表現的預測性能優于logistic模型,logistic模型表現優于SVM模型(P=0.0029),隨機森林模型AUC最好。logistic模型、XGBoost模型、CatBoost模型、隨機森林模型、SVM模型的Brier分數分別為0.115±0.001、0.096±0.001、0.093±0.001、0.084±0.000和0.045±0.001,SVM模型校準度最好,機器學習模型的校準度均優于logistic模型,差異有統計學意義(均P<0.0100),詳細數據見表3。

表3 機器模型和logistic模型對院內死亡預測性能的比較
3 討論
在本研究中,新發卒中患者(包括缺血性卒中和TIA)共601 466例,院內死亡2206例(0.37%)。其中院內死亡患者數量遠少于存活患者,即正負樣本極不平衡。如果不對不平衡數據進行處理,會導致分類器訓練后的模型偏向于多數類,存在預測的偏向性問題。考慮到本研究基于現實臨床場景,需要更準確地預測院內死亡患者,選擇隨機欠采樣的方式平衡數據結構,雖然欠采樣可以提升模型的泛化能力,但有一定的過擬合的風險,故而在進行特征選擇的時候使用了強正則化模型(XGBoost模型)進行平衡,最后對算法結構進行平衡權重的調整。由于本研究樣本量過大,傳統顯著性檢驗對樣本量較為敏感,會出現有統計學意義但實際可能沒有臨床意義的情況[14]。本研究通過探索機器學習的方法進行特征選擇,獲得的最優特征子集再進入不同模型進行訓練和測試。為了增加機器學習的可解釋性,本研究顯示了最優特征子集的20個預測因子在SHAP圖上的表現。在logistic模型的逐步回歸結果中顯示最優特征集中有18個最后進入模型,說明本研究對于最優特征子集選擇的合理性。另外,在測試集上每個模型的區分度指標AUC和校準度指標Brier分數均較好,說明本研究特征選擇和模型訓練的可行性。
在結果中可見,對數據進行平衡處理前logistic模型返回的結果靈敏度較低(0.008±0.003),特異度較高(0.999±0.000),G-mean(0.249±0.366)較低,出現這種狀況是因為對極不平衡數據直接進行分析時,訓練后的模型偏向多數類(即存活患者結局)。盡管logistic模型所得區分度指標AUC(0.902±0.007)和校準度指標brier分數均較好(0.022±0.041),但因其過低的真陽性率,在實際臨床應用中不具備良好的鑒別死亡患者結局的能力,因而不具有可信度。通過平衡數據處理后,logistic模型所得區分度指標AUC(0.913±0.000)和校準度指標brier分數依舊較好(0.115±0.001),靈敏度和同時衡量靈敏度、特異度指標的G-mean獲得了較大的提高(分別為0.824±0.002和0.846±0.001),此時訓練后的logistic模型具有良好的鑒別正負樣本的能力。
在本研究中,數據平衡后每個模型的預測性能都較好。在機器學習模型中,從區分度指標AUC值來看,隨機森林模型的效果最好且準確率最高,其次是XGBoost模型、CatBoost模型和SVM模型。隨機森林模型、XGBoost模型和CatBoost模型AUC略高于logistic模型,而SVM模型AUC略低于logistic模型,且差異均有統計學意義。
本研究中每個模型的校準度brier分數均較好,但總體看機器學習模型的brier分數低于傳統logistic模型,說明機器學習模型的校準度更好。在所有機器模型中,隨機森林模型表現最好,這可能與隨機森林算法隨機構建樹節點以避免過擬合,比單獨的樹模型泛化能力有提升,并且對變量共線性不作要求等優點有關。
盡管本研究通過平衡數據和歸一化處理優化了SVM模型表現,但SVM模型的性能最終仍略低于其他模型。SVM模型與其他模型相比更適合于樣本規模小、多特征的多維數據。在本研究的樣本量遠大于特征量的情況下,SVM模型并沒有表現出明顯優勢,在訓練過程中還消耗了大量的機器內存和計算時間。同時,與其他模型相比,SVM模型很難找到合適的核函數,并且SVM模型只考慮邊界附近的點(支持向量),可能不會包含全部重要的預測因子。而logistic算法則考慮所有點(遠離的點對邊界線的確定也起作用),這可能導致SVM模型忽略掉被logistic模型考慮進去的個別預測因子,從而導致SVM模型的AUC表現略低。
本研究局限性在于僅采用隨機欠采樣的方式以平衡數據,浪費了部分負樣本數據,未來可嘗試結合多種表現良好的過采樣技術,如常見的SMOTE、SMOTE-Borderline、ADASYN及基于GAN的方法等[15-16]。此外,可結合更優的選擇算法來提高精準預測的能力。未來將進一步探究不同模型對缺血性卒中的適應條件,在預測因子、模型開發及預測性能方面進行全面研究,以期為建立更加完善的缺血性卒中死亡預測模型提供更全面的借鑒。
【點睛】本文基于CSCA大樣本數據庫中急性新發缺血性卒中患者的數據,應用欠采樣技術和平衡權重方法處理患者院內死亡結局的不平衡數據,在此基礎上比較XGBoost、CatBoost、隨機森林和SVM四種機器學習模型和logistic模型預測患者院內死亡結局的性能,結果顯示機器模型的預測性能整體優于logistic模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
