基于H-op組合算法的財務數據特征預測系統設計
2021-09-06 08:55:28吳笛
喀什大學學報 2021年3期
吳 笛
(新疆財經大學 統計與數據科學學院,烏魯木齊 830012)
我國市場存在著嚴重的信息不對稱問題,投資者能夠獲取的財務信息大多來自企業的公告,但是由于利益問題,上市公司的實際財務情況往往與預測值相差巨大,這非常有損于投資者的利益[1-2].因此與財務數據特征相關的預測就成為當前研究的熱點,其中預測的核心指標就是圍繞著企業核心利潤展開的[3].當前一部分財務狀況較差的企業,并不是很愿意披露自身的盈利狀況及預測情況,并且這類企業的財務披露問題也與其所在行業存在一定關聯[4].在互聯網時代,大量學者已經開始對企業相關的財務數據進行處理,并應用科學的方法找到數據間存在的關聯,同時采用模型選擇最優算法[5].隨著計算機算法的不斷發展,越來越多的高級算法開始應用于各大行業,尤其是一些非常適合某種行業的機器學習算法[6].本研究將混合最優選擇算法(Hybrid optimization,H-op)應用到研究樣本數據中,以便對企業財務數據進行有效的預測,旨在找出當前行業研究適用的最優算法,為用戶或企業提供財務盈利預測結果.
1 基于H-op 組合算法的財務數據特征預測系統設計
1.1 預測系統模塊及混合最優選擇H-op 算法設計
本次系統設計的目的主要是為了提升用戶對企業財務特征預測的判斷能力,預測系統主要包括企業活力、風險評估、固定資產以及利潤四大模塊,財務數據特征預測系統的功能模塊如圖1 所示.
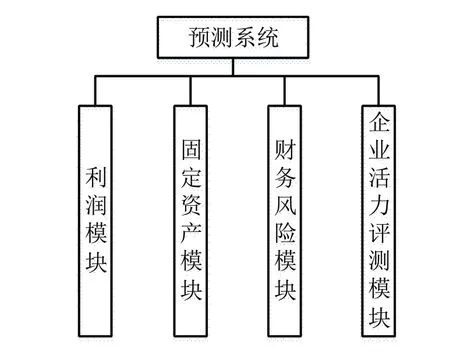
圖1 財務數據特征預測系統的功能模塊
預測系統中的四大模塊在不同程度上反映出了企業的財務狀況,不僅有與財務狀況密切相關的模塊,也有與活力、風險等潛在因素相關的模塊.這些模塊的應用,能夠為用戶提供企業當前的財務狀況及未來可能發生的情況[7].采用圖例及文字表情將預測信息傳遞給用戶,同時系統會自動進行預測結果的存檔,以便于以后的搜索[8].本研究主要針對數據處理與算法最優選擇方面的問題,采用對不同學習算法進行對比的方式,優選出適用于不同行業的學習算法,以對不同行業自動進行算法篩選,從而提升運算效率.
本文主要研究的算法為混合最優選擇算法,同時對7 種機器學習算法進行對比研究.該算法主要對行業特征進行構建后,對不同的行業運用了不同的機器學習算法與歸一化處理方法,Hop 主要是對不同行業的樣本數據進行了訓練,并依據行業預測評價標準進行預測對比,選取出最優模型應用到行業預測工作中[9].本研究的樣本數據是由網易財經所提供,均為我國上市公司歷年來的季度財務報表,運用爬蟲方式將數據保存至表格中備用,包括了現金流量表、利潤表、資產負債表.整理相關樣本數據,由于不同表格的數據存在著相對獨立性,對機器學習的訓練造成一定影響,所以本研究將現金流量表、利潤表、資產負債表進行了合并,并采用上市公司股票代碼作為標識,再轉置得出表格,這樣便能得到合并后的表.該表縱軸表示按照時間序列分布的數據值,橫軸表示數據特征,如圖2 所示.
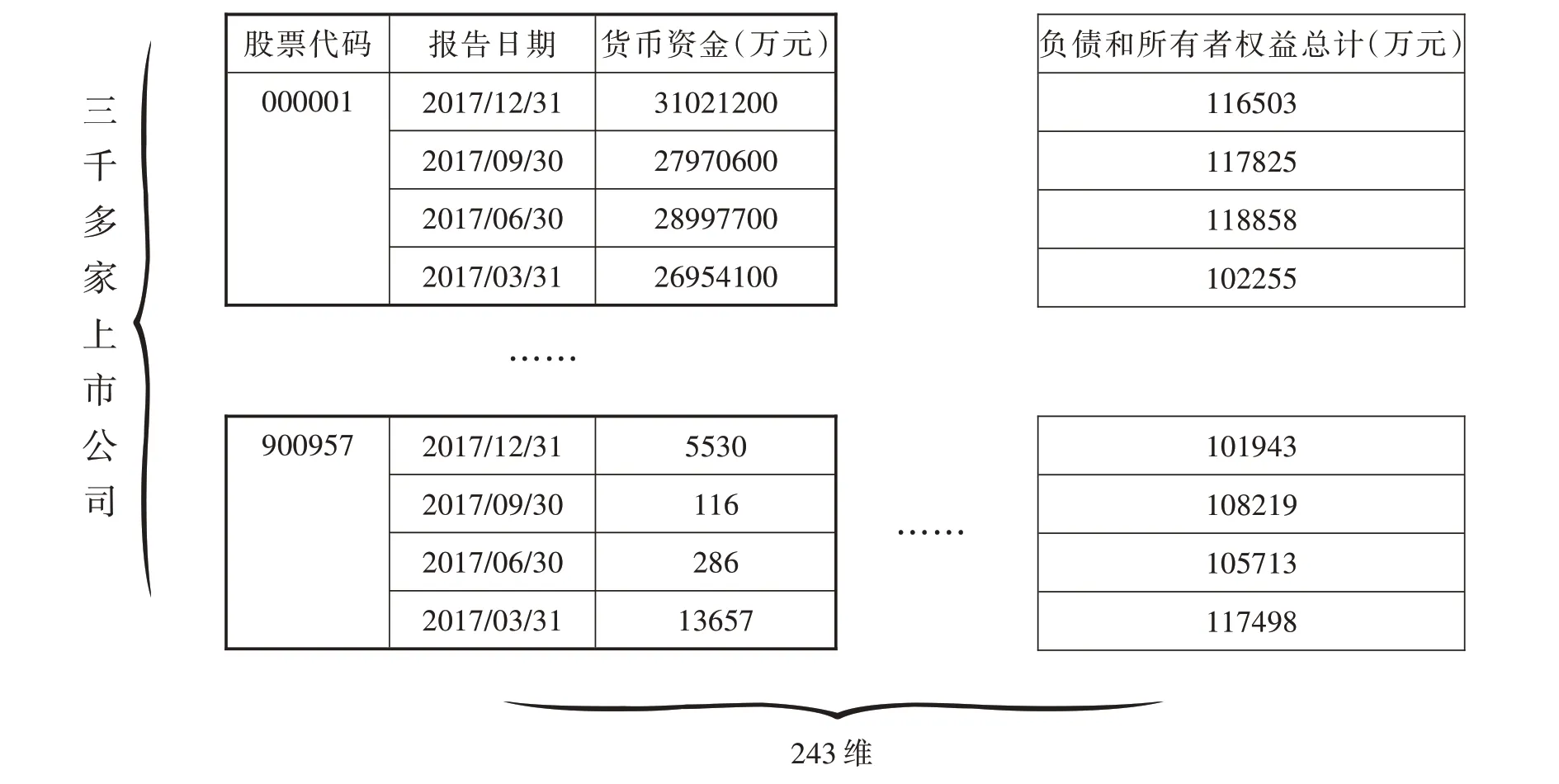
圖2 數據資料整合
由圖2 可以看出,合并后的數據特征綜合了現金流量表、利潤表、資產負債表的數據特征,包含了243 個數據特征,上市公司數量超過了三千家,并且均包括了十年以上的季度報表數據.通過對數據特征進行觀察后,可以看到隨著各年度季度的增加,數據值也隨之增加,為了使本研究不會受到數據值逐年增加的影響,對數據進行一次遞減,并按照季度劃分的方式將表格數據進行相對獨立的整理.
由于不同行業之間存在著不同的影響因素,財務數據特征的預測是否合理,還是要對具體的行業進行區分,這樣也能夠有效提升模型的訓練效率.這就需要對數據集提前進行行業劃分,對獨立的行業樣本數據進行獨立表格整理[10].本研究根據當前上市企業行業劃分標準,對我國三千多家上市企業進行了行業劃分,劃分出61 種行業,并單獨對各個行業進行獨立表格整理,行業分類如表1 所示.

表1 行業分類(部分)
由于本研究的樣本數據較為特殊,報表合并后存在大量的數據特征,因此要提前篩選出適用的數據特征,并統計數據特征的個數.由于部分數據特征存在缺失情況,故將該類部分數據進行剔除,以避免對預測結果的干擾[11].保留85%以上的數據特征,并選取剩余部分數據的特征.還要對某些行業的數據存在的特殊情況進行分析,有時某一個數據的特征,在絕大多數行業中數值極低,然而在個別行業中數值卻極高,甚至高于90%.本研究列舉了個別特征進行觀察,如數據“手續費及傭金收入”的特征,在大部分行業中均低于10%;然而在券商信托與銀行行業中,數值卻非常高,銀行行業竟達到了99%.如圖3 所示.
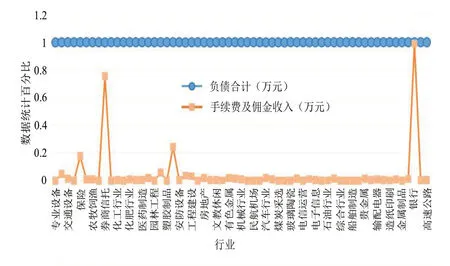
圖3 比較不同行業的“負債合計”“手續費及傭金收入”特征數值
由圖3 可看出,全部行業中“負債合計”均保持在100%左右,然而“手續費及傭金收入”,卻只有銀行行業與券商信托行業最特殊.同樣也有許多相似的情況,例如“保險合同準備金”與“所得稅費用”的數值統計情況,如圖4 所示.由圖4 可知,全部行業中“負債合計”均保持在95%左右,但“保險合同準備金”在大部分行業中保持在0上下,只有保險行業數值最為特殊,在75%上下.此外,有許多數據特征具有顯著的行業差異性.
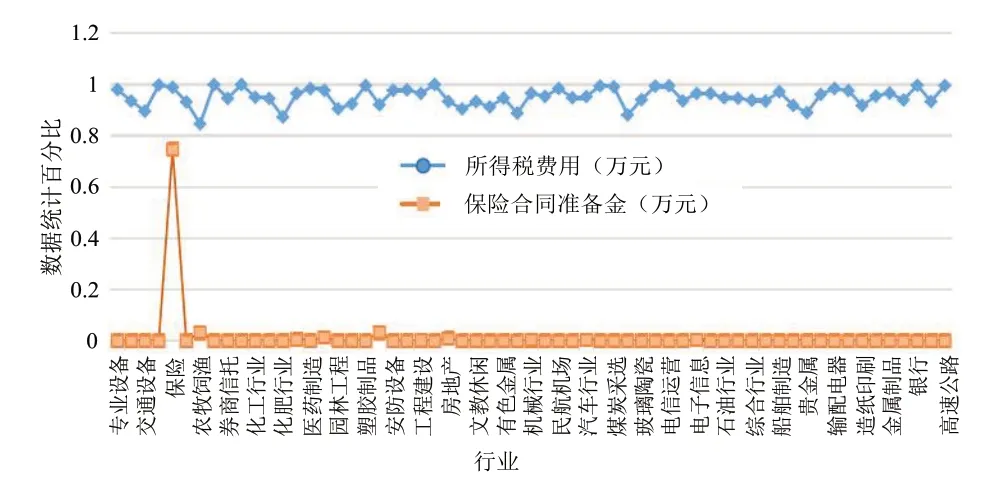
圖4 比較不同行業的“所得稅費用”“保險合同準備金”特征數值
為了確保預測結果的準確性,本研究應用了python 軟件對數據特征與利潤進行了相關性分析.畫出每個行業的獨有的特征圖,并進行對比觀察,篩選出二者中呈現正相關的數據特征,進行數據記錄.通常會因為數據量過于巨大,導致分析時間與成本較高,并且難度也非常高.本研究對相同行業中的公司進行隨機抽樣,共進行3輪,每輪抽取2 個公司,總計對6 個不同的公司進行數據特征的相關性分析.將數據相關性較高的特征選作行業預測特征,剔除相關性較差的數據,并將分析結果進行整合.例如“保險合同準備金”特征在保險行業中的呈現出較高的正相關性,所以該特征相對于保險行業為有效特征,而該特征在安防設備行業卻顯示非常雜亂,因此在安防設備行業中應剔除“保險合同準備金”特征.因此,相同的數據特征會在不同行業中具有不同的相關性.
從分析整理完成的數據,可以看到數據特征不同也會引起數據量級的不同,造成在預測時結果會偏向于數據差值較大的特征,因此要對樣本數據運用歸一化處理方法,以使不同數據特征間具有可比性[12].例如某些大型企業經營狀態良好,盈利遠高于中小型企業,因此其本身盈利值數據特征相對大很多.為了能夠消除這種差距給預測結果帶來的影響,本次研究將對樣本數據進行歸一化處理,以便數據之間具有可比性,提升了后期訓練優化的準確度,最終可得到相對準確的預測值.歸一化主要包括了極差、標準、正則三種方法,分別如下式所示:
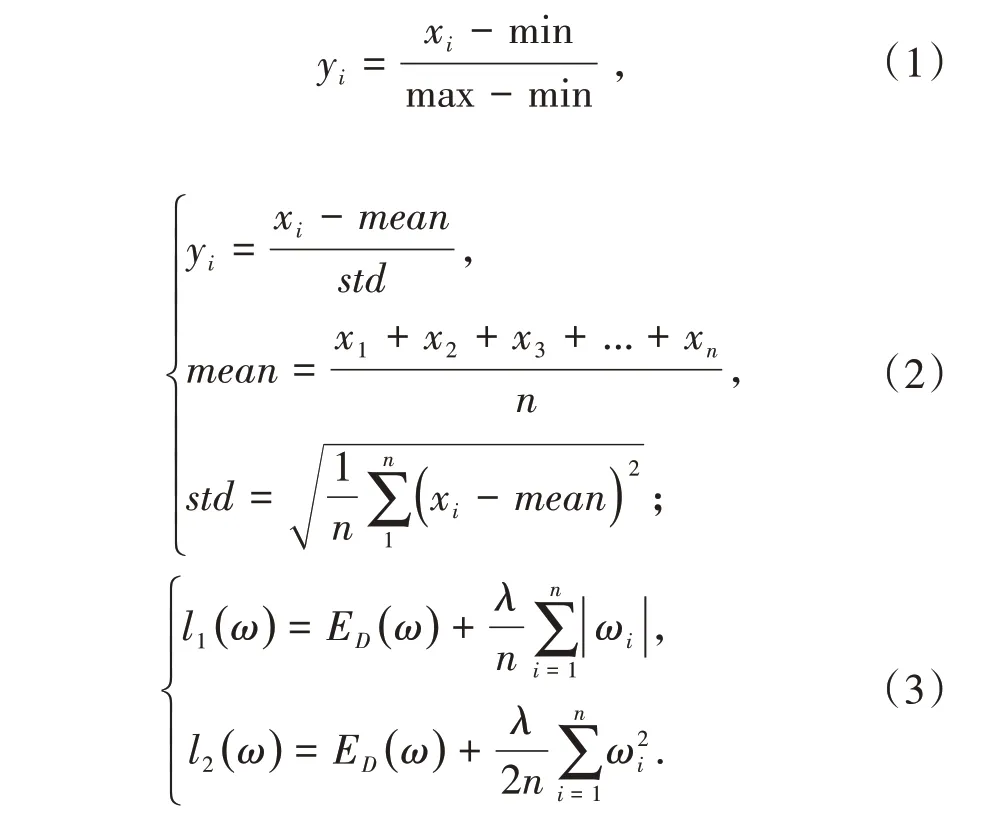
式(1)-(3)中,max為最大值,min為最小值,xi為當前數據,std為標準差,mean為平均值,l1,l2均表示正則化.歸一化處理是將數據轉化成[0,1 ]之間的數值,且不同歸一化處理方法得出的結果不同,所以歸一化處理也會影響到算法的優化,選取合適的歸一化處理方法能夠很好提升算法效率.
機器學習算法通常有較多參數,本研究對各種學習算法設定了固定參數,例如在LSTM 中設定迭代次數為80,學習率為0.0001,神經元個數為100.決策樹參數選取為默認,隨機森林決策樹個數選取為80~100,支持向量機迭代次數為1000~10000,并且LSTM主要由pytorch框架來進行優化.
1.2 設計評估標準
通常對算法的評判標準為算法的準確度,本研究的重點為回歸問題中的數值誤差.對于系統中財務樣本數據的評判,要對行業規范具有一定的了解.盈利預測可靠性的計量指標為平均預測誤差率與預測誤差率.由于本研究主要是對企業財務特征進行預測,因此只對誤差進行判別,不考慮具體誤差的樂觀度.在進行預測過程中,為了確保預測結果不為負,需要對公式進行調整,對公式取絕對值,預測誤差率的計算如下式:
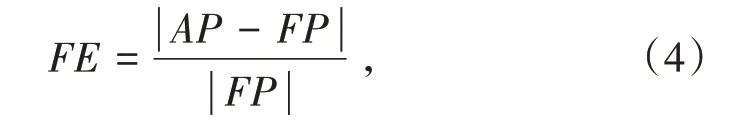
式(4)中,FP表示預測值,AP表示實際值.而平均預測誤差率如式
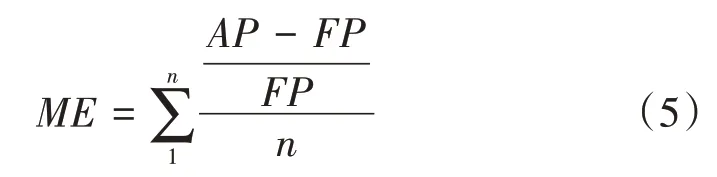
所示.
將我國上市公司財務特征預測可靠性標準設定為三類:一是FE≤10%,可靠性較高;二是10%<FE≤20%,可靠性一般;三是FE>20%,可靠性很差.上述標準為評判標準,為確保算法的有窮性,若預測結果收斂于迭代范圍內,則將結果輸出;若預測結果不能在迭代范圍內收斂,則對比最大迭代次數.選取上文中所述適合的歸一化處理方法能夠較好地提升運算準確度.因此,本研究將按照以上評判標準,以銀行行業、軟件服務業為例,對比三種歸一化處理方式的結果,能夠較好地看出不同歸一化方式對結果準確率的影響.
2 系統算法混合最優選擇H-op測試分析
2.1 不同機器學習預測算法在不同行業中的應用對比
本研究首先以銀行金融業為例,應用歸一化方法對測試數據進行了處理,并將實際結果與機器學習預測結果進行對比,如圖5 所示.
由圖5 可以發現各種算法對銀行業存在不同程度的影響,為了方便觀察對比結果,這里將以準確率的形式進行各種算法的對比,結果如圖6 所示.
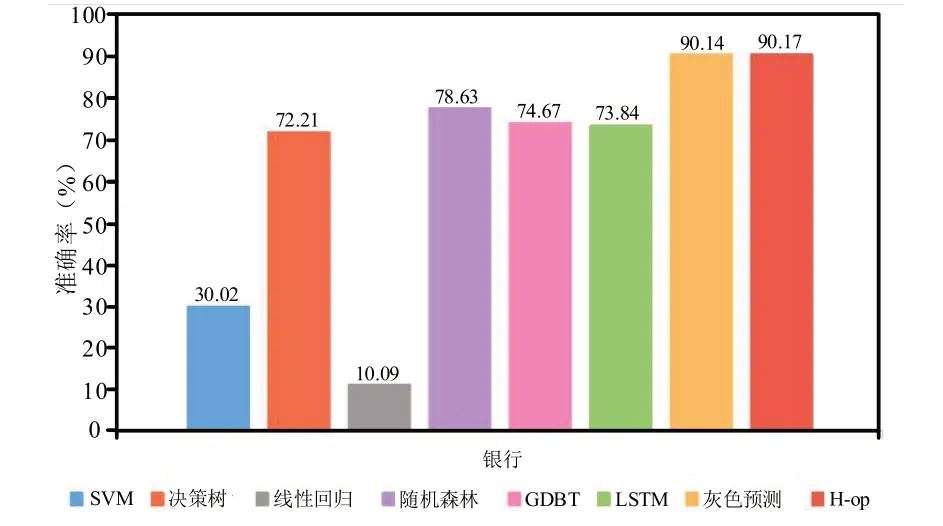
圖6 銀行行業結果準確率對比
由圖6 可以看出,H-op 在學習與歸一化方法組合后,選取了銀行行業中準確率最高的灰色預測算法.為了能夠更為全面的展示結果,本研究還針對軟件服務業,對該行業的相關數據進行了不同機器學習方法的預測,并與實際結果進行對比,結果如圖7 所示.
由圖7 可知,在各種算法中預測值與真實值幾乎完全重合,并且不同學習方法對軟件服務業也具有不同預測效果.本研究以準確率為標準,比較各種學習算法之間的準確率,結果如圖8 所示.
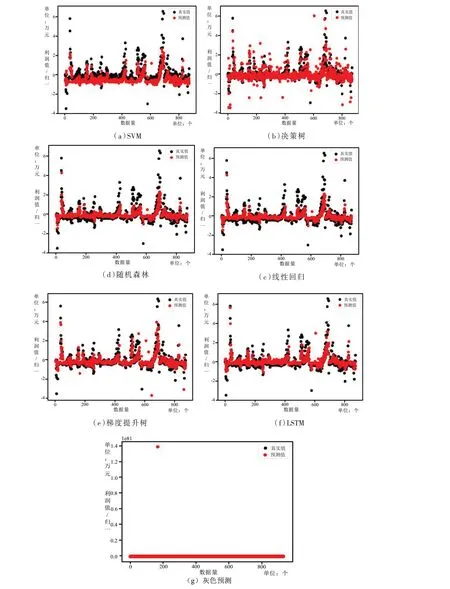
圖7 軟件服務業誤差圖
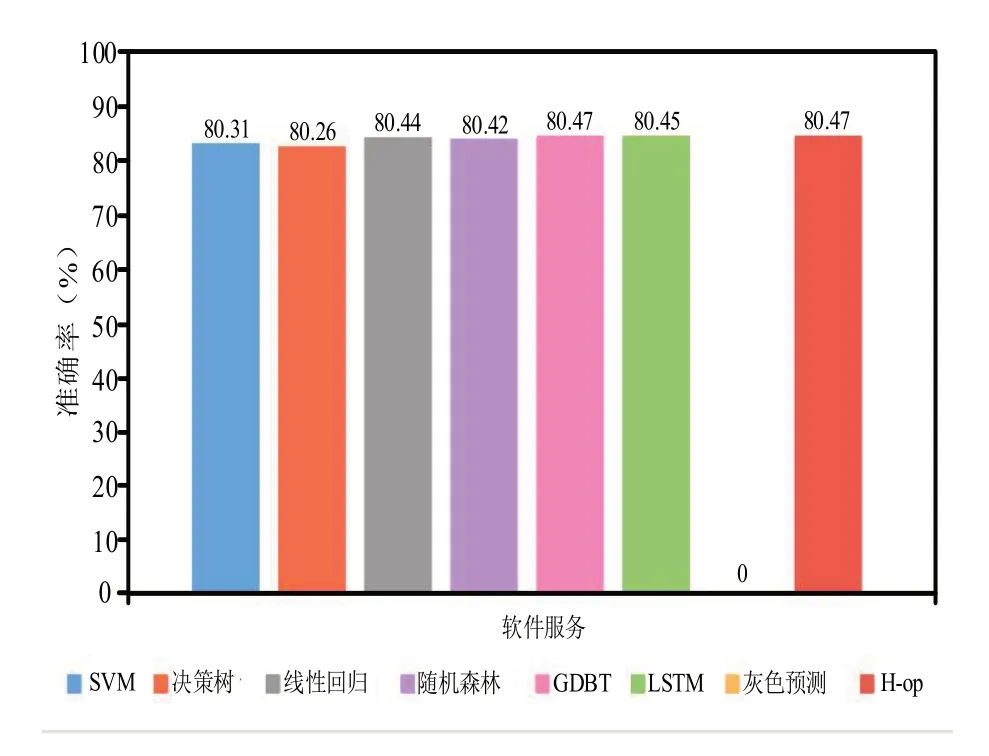
圖8 軟件服務業結果準確率對比
由以上分析對比可以得出,銀行行業中采用灰色預測算法更為合適,而軟件服務業則除了灰色預測算法外,其他算法均表現較好,因此,應該針對各自行業的適用學習算法進行進一步優化,以提升相關行業的預測準確率.
2.2 財務數據特征預測系統算法性能測試
根據相同的對比方法,本研究整理60 多類行業的算法選擇表,作為系統算法選擇的依據.如表2所示.

表2 系統算法選擇表(部分)
在設計的系統中導入表2內容,由表格內容來決定行業預測算法的選擇.在進行系統預測時,首先要輸入行業代碼,系統會根據行業代碼進行行業判定,從而選擇合適的學習算法進行預測,并將預測結果進行記錄,把預測結果顯示在初始財務整合表內,以備今后數據的查詢.這樣節省了學習算法的學習耗時,增強系統的運算效率.其次,要對本研究所提出的H-op 組合算法進行測試,測試內容包括了算法的搜索時間和搜索結果的驗證.在系統中輸入行業代碼時,系統會直接進行行業判定,并依據行業的不同選擇計算效率最高的算法進行預測,并將預測結果返回,預測結果如表3所示.

表3 算法預測結果
由表3 可知,在系統中輸入不同行業代碼時,系統響應速度快,且輸出結果均正確,反映出算法性能優越,同時具有非常高的穩定性.所以文中提出的算法測試結果優良,整體測試效果符合設計預期.
3 結論
本研究針對企業財務數據的預測問題,對基于H-op 組合算法的財務數據特征預測系統進行了設計研究.結果顯示,在銀行行業中采用灰色預測算法更為合適,而軟件服務業則在各種算法中預測值與真實值幾乎完全重合,并且不同學習方法對軟件服務業也具有不同預測效果,除了灰色預測算法外,其他算法均表現較好;設計算法節省了學習算法的學習耗時,增強系統的運算效率;整理60 多類行業的算法選擇表,作為系統算法選擇的依據;在系統中輸入不同行業代碼時,系統響應速度快,且輸出結果均正確,反映出算法性能優越和非常高的穩定性.因此本文提出的算法測試結果優良,整體測試效果符合設計預期.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
科技傳播(2019年22期)2020-01-14 03:06:54
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
