基于統計學習方法的模型構建與數據分析
2021-09-06 08:55:30姚瑞,唐泉
喀什大學學報
2021年3期
姚 瑞,唐 泉
(新疆師范大學 數學科學學院,烏魯木齊 830017)
統計學習,也稱為統計機器學習,在計算機及其應用領域中具有重要意義.統計學習[1]的主要方法是基于數據建立統計模型來預測和分析數據,由監督學習、非監督學習、半監督學習和強化學習組成,包括k近鄰法、樸素貝葉斯方法、支持向量機等方法.半監督學習是一種同時兼顧標簽樣本和無標簽樣本的學習方法,利用標記樣本的優點來精確描述單個樣本,同時使用大量無標記數據來進一步提高分類器的性能[2].半監督支持向量機(S3VM)最初應用于文本分類[3],主要有梯度下降法(Gradient descent)[4]、確定性退火方法(Deterministic annealing)[5]和半正定規劃方法(Semi-definite programming)[6]等研究方法.模糊支持向量機在傳統支持向量機基礎上提出,分類精度和回歸精度更高,查翔等[7]提出了一種基于多區域劃分的模糊支持向量機方法;譚萍等[8]結合模糊C-均值與FSVM 提出了一種多級的模糊支持向量機對說話人進行語音識別;Muscat R 等[9]提出了分層模糊支持向量機模型.本文討論支持向量機模型,對支持向量機模型的基本思想、發展完善及應用情況進行概述,并深入探討一種通過識別誤分類點來構造半監督的模糊支持向量機模型及算法實現.
1 模糊支持向量機
1.1 線性可分的模糊支持向量機
對于模糊訓練集

模糊約束規劃為:
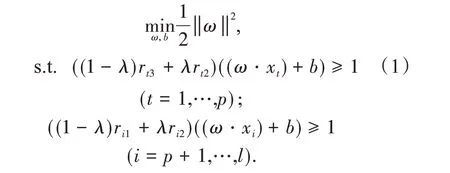
其中,λ(0 ≤λ≤1)為置信區間.
其對偶問題為:
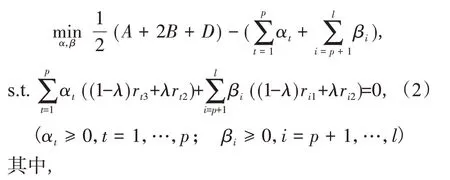

Step4:計算ω*和b*,如式(4);
Step5:構造最優分類超平面(ω*·x)+b*=0,得到最優分類函數式(5).
2.2 非線性可分的模糊支持向量機
對于模糊非線性問題,引入變換
登錄APP查看全文
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
人大建設(2020年4期)2020-09-21 03:39:12
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
浙江人大(2014年4期)2014-03-20 16:20:16
