基于改進支持向量機的水聲目標-雜波不平衡分類研究
2021-09-22 03:14:24李然威馮金鹿何榮欽
應用聲學 2021年5期
關鍵詞:分類
關 鑫 李然威 胡 鵬 馮金鹿 何榮欽
(中國船舶第七一五研究所 杭州 310023)
0 引言
通常主動聲吶較被動聲吶具備探測距離優勢,但是,在工作過程中經常伴隨著大量的雜波虛警,并且隨著水下目標隱身降噪技術的發展,探測難度不斷加大[1],尤其是在淺海海域,分布著礁石、海底山脊、山峰和沉船等強散射體,主動發射信號接觸這些散射體,會產生和目標強度相近的回波,在探測畫面上出現大量類目標雜波亮點。大量雜波的存在對主動聲吶探測性能主要有兩方面的影響,第一,難以通過調整信噪比門限,在不損失檢測概率的同時降低虛警概率;第二,在自動跟蹤端生成大量虛假航跡,影響航跡關聯,加劇跟蹤系統的計算負擔,甚至導致跟蹤系統癱瘓。因此,雜波抑制是主動聲吶信號處理中的重要研究問題,通過對目標和雜波的分類判別,可以有效解決這個問題[2]。
隨著大數據時代的到來,從海量數據中挖掘有效信息的需求推動了機器學習的發展,Berg等[2]為了解決自主水下潛航器群(Autonomous underwater vehicles,AUVs)受制于有限的通信能力而不能共享大量主動聲吶探測數據的問題,研究了k 近鄰(k near neighbor,k-NN)、ID3、樸素貝葉斯(Naive Bayes)和神經網絡(Neural network)等機器學習算法,通過對目標和雜波的分類來縮減探測數據。Stender 等[3?4]指出在跟蹤階段,由海底地形特征物(海山、山脊等)產生的雜波和人造特征物(無人潛航器(Underwater unmanned vehicle,UUV)、潛艇等)產生的回波運動特性不同,建立了包含運動航跡和信噪比特征的數據集,訓練機器學習模型,能夠準確地從背景中發現人造特征物。可見,機器學習能夠利用數據發現一些潛在的變化規律用來預測未知數據,為水聲目標和雜波的分類提供了一種新的解決思路。
然而,以上研究[1?4]并未考慮水聲數據集的類不平衡特性,即主動聲吶使用中海底/海面的不平整性、航船輻射噪聲等對水聲數據采集帶來大量的雜波干擾,一個水下目標回波通常伴隨著數百個雜波。因而,相應的機器學習分類問題為不平衡分類問題,即在一個分類問題中某些類的樣本數量遠多于其他類別的樣本數量[5]。一般的機器學習分類算法不適合處理類不平衡數據[6?7],因為機器學習算法在訓練的過程中基于整體分類誤差最小構建分類模型,導致多數類樣本的分類準確率存在高于少數類樣本的趨勢[8],整體分類準確率主要受前者影響而變高,但是少數類樣本的分類準確率不能滿足實際需求。
支持向量機(Support vector machine,SVM)是一種經典的機器學習算法,具有堅實的統計學習理論基礎[8?12],為了探究其在不平衡數據中的分類性能,Lin等[10]建立了支持向量機和貝葉斯決策理論之間的關系,在貝葉斯決策理論中,貝葉斯最優決策是最優分類決策[11],他們從理論上證明了對于錯分代價相同的類平衡樣本,SVM可在樣本數量趨于無窮時逼近貝葉斯最優決策,但是對于不平衡數據,SVM無法逼近貝葉斯最優決策,即分類性能差。
代價敏感支持向量機(Cost sensitive support vector machine,CS-SVM)由SVM結合代價敏感技術發展而來,主要用來解決不平衡分類問題[11?12]。不平衡分類問題與代價敏感學習密切相關,在代價敏感學習中每個類的錯分代價不同,不平衡分類問題中,少數類往往具有更高的錯分代價[7,13],對于錯分代價不同的類不平衡樣本,CS-SVM 理論上在樣本數量趨于無窮大時同樣可以逼近貝葉斯最優決策[10]。然而實際中的樣本數量往往有限,導致CS-SVM的分類性能總是次優的。
針對CS-SVM 在有限不平衡樣本中難以逼近貝葉斯最優決策的問題,本文提出了一種基于能量統計法的En-SVM算法。利用能量距離量化少數類樣本在不完全采樣過程中的信息損失,使得少數類樣本在再生核希爾伯特空間(Reproducing kernel Hilbert space,RKHS)中可以為機器學習算法提供更多的分類信息,提高少數類樣本的分類精度。實驗結果表明,該算法能夠有效地處理不平衡水聲數據,同時獲得高檢測概率及較低的虛警概率,并且隨著不平衡比率的增加,仍能保持良好的性能。
1 CS-SVM的貝葉斯最優決策
1.1 貝葉斯最優決策
水聲目標-雜波分類是典型的二分類問題,不失一般性,做如下約定,(X,Y)代表原始數據空間,X ∈Rd,Y ∈{?1,+1},(Xs,Ys)為樣本空間,Xs ∈Rd,Ys ∈{?1,+1},d表示數據維數,“Ys=?1”代表負樣本,“Ys= +1”代表正樣本,正樣本為少數類樣本,具有更高的錯分代價,對應水聲目標。則來自(X,Y)的某一數據分為正類的貝葉斯后驗概率為p(x)=Pr(Y=+1|X=x),如式(1)所示:
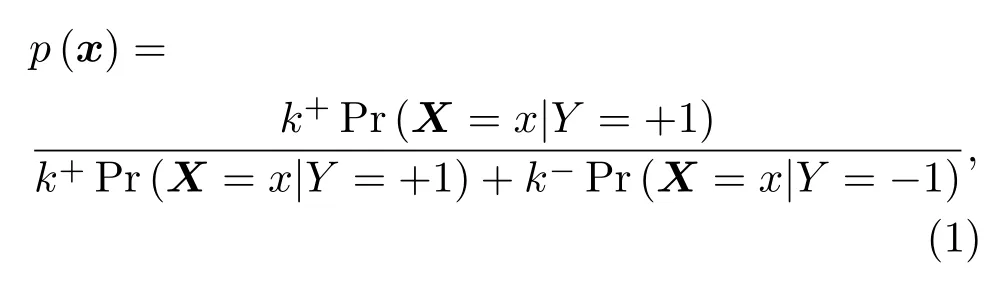
其中,k+和k?分別為原始數據中正負樣本的分布概率,Pr(X=x|Y= +1)為正樣本條件概率,Pr(X=x|Y=?1)為負樣本條件概率,對于樣本空間也有類似的表述。在分類過程中,正類(正樣本)和負類(負樣本)具有不同的錯分代價,可用代價矩陣表示,如表1所示。

表1 代價矩陣Table 1 Cost matrix
表1 中C?為假負例(False negative instance,FN)的錯分代價,C+為假正例(False positive instance,FP)的錯分代價。機器學習數據集的建立是對原始數據空間的不完全隨機采樣過程,正樣本和負樣本的采樣數量并非總是相同的,且正樣本和負樣本的重要性是不同的,比如具有不同錯分代價的不平衡樣本。Lin等[10]通過貝葉斯決策理論證明了在有偏采樣和錯分代價不同的條件下,機器學習算法在原始數據空間和樣本空間中的貝葉斯最優決策存在差異。最高的分類準確率在統計意義上對應最小貝葉斯風險:
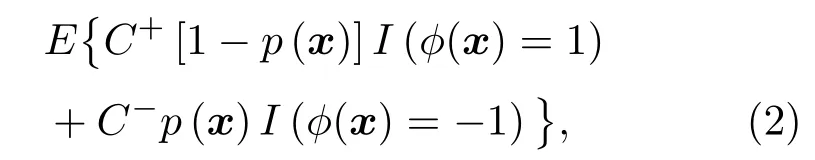
其中,I(·)為指示函數,條件為真,I(·)=1,否則為0。使得式(2)最小的?B(x)即為貝葉斯最優準則:
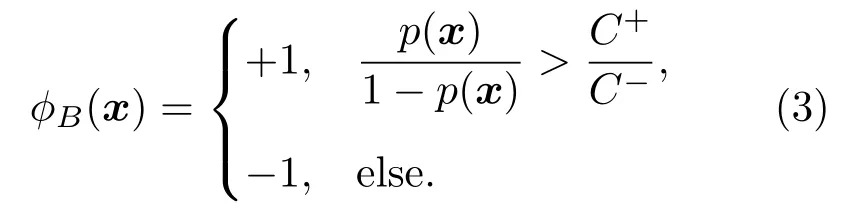
在原始數據空間中正類與負類滿足獨立同分布(Independent and identically distributed,IID)條件,此時錯分代價趨于相等,可得貝葉斯最優決策:
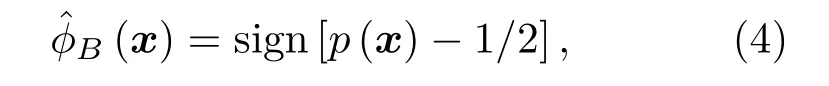
式(4)中,sign(·)為符號函數,然而對具有不同錯分代價的不平衡樣本(Xs,Ys),貝葉斯最優準則為
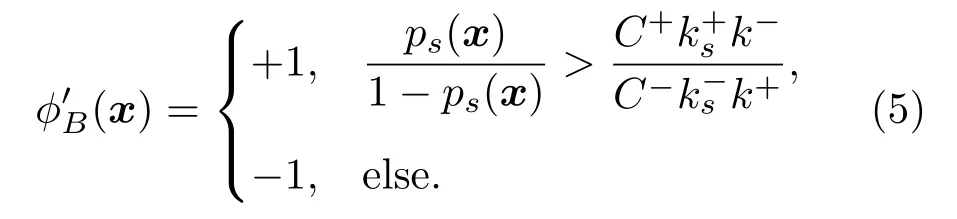
貝葉斯最優決策變為

由式(4)和式(6)可知,在原始數據空間中,后驗概率p(x)只需和1/2 比較,而在有偏采樣和錯分代價不同的樣本空間中,后驗概率ps(·)和1/2 比較會產生不準確的結果。因此,對于具有不同錯分代價的不平衡樣本,為了獲得良好的分類效果,需要考慮貝葉斯最優決策。
1.2 代價敏感支持向量機
對于不平衡樣本,負類樣本主導整體分類準確率,超平面會向正類樣本偏移,導致具有更高錯分代價的正類樣本分類準確率下降,而整體準確率很高。CS-SVM通過給少數類樣本和多數類樣本賦予不同的錯分代價來處理不平衡樣本,它的求解等價于在再生核希爾伯特空間(RKHS)Hk中求解關于目標函數的正則問題,決策函數可寫為
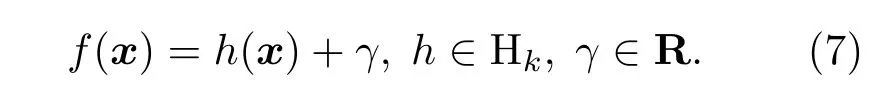
Zhang 證明了Hinge 損失在SVM 的求解中具有貝葉斯一致性(Bayesian consistency),因此,Hinge 損失常作為SVM 的目標函數[14]。在SVM的基礎上,CS-SVM 引入了調節因子L(·),如式(8)所示:
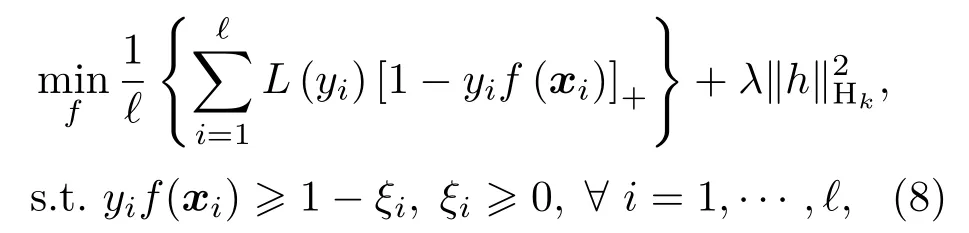
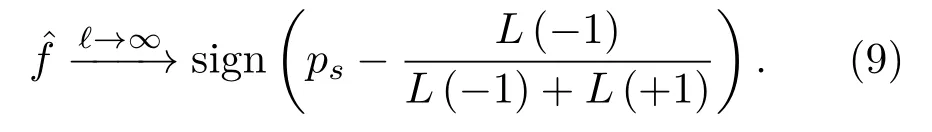
需要注意的是,SVM 的標準輸出為置信度?f(x),經過Sigmoid 函數映射得到后驗概率ps[15]。式(9)說明了對于具有不同錯分代價的不平衡樣本,CS-SVM 是貝葉斯最優的。但是,實際樣本總是有限的,在獨立同分布的采樣過程中,k+和k?接近,而對于有限不平衡樣本,將k+s和k?s視為先驗概率是不合適的,因為在采樣過程中正類樣本存在信息損失,比如主動聲吶探測過程中,受混響、多徑效應等因素影響,目標回波往往會發生畸變并伴有能量損失,導致目標探測數據稀少。因此,正負樣本的信息不對稱使得式(9)有如下的修正:

其中,Hshannon代表正類樣本采樣過程中丟失的信息,用香農熵來表示,fH(·)為其度量準則。基于這一思想,本文提出了改進的CS-SVM。
2 基于能量統計方法的En-SVM
2.1 信息損失度量
根據拉格朗日對偶性,式(8)的對偶問題如下:

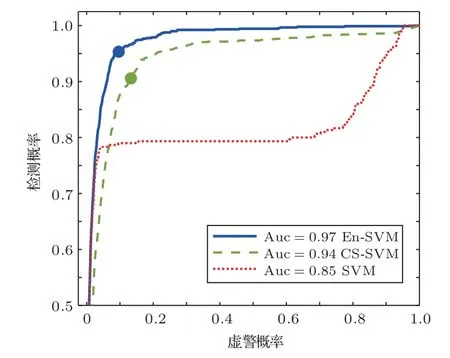
式(11)中,K(·)為核函數,可將非線性數據映射為希爾伯特空間中的線性數據,因此,在RKHS 中認為正負樣本線性可分,滿足0<αi 從圖1(b)可知,正類支持向量的后驗概率較小,具有較大的自信息(虛線同心圓表示),含有更多的分類信息,自信息的期望即為香農熵,用來度量樣本整體的信息,可以發現多數類樣本整體包含的信息大于少數類樣本,導致CS-SVM 仍有錯分的正類樣本。En-SVM 利用fH(Hshannon),可使分類結果對正類樣本更加有利,如圖1(c)所示,“0”號錯分樣本獲得了一定的置信度。能量統計方法通過計算特征函數間的加權平方距離來表征不同分布之間的差異[16],少數類樣本經原始數據空間不完全采樣得到,存在信息損失Hshannon,本質上是其概率分布發生了變化,因此,可以用分布差異來度量信息損失,得到fH(Hshannon)近似解。能量距離表示如下: 圖1 RKHS 中的不平衡分類Fig.1 Imbalance classification in RKHS 式(12)中,p和p′分別表示有限樣本和原始數據的概率分布,φ(·)為其對應的特征函數,對于不同的概率分布,特征函數總是存在且收斂的,‖·‖表示歐幾里得范數,Γ(·)為伽馬函數,d表示特征向量x的維數。能量距離可以等效地表示為 式(13)中,Ex~p表示服從概率密度p的期望,類別數只有兩類時,k=[k+,k?]T,c為與k無關的常量,A為2×2 階對稱矩陣。對于少數類樣本,DE(p,p′)可表示為一個相當于常量的k+的函數: 其中,μ為貝葉斯風險DE(p(x|y= 1),p(x|y=?1)),Ay,ˉy和σy可近似給出: 結合式(14)~(19)可得到信息損失度量: En-SVM 算法的核心在于利用少數類樣本不完全采樣過程的信息損失來補償分類模型在訓練過程中所需的分類信息,使得分類結果對少數類樣本更加有利。記fH=fH(Hshannon),由此,可得En-SVM如下: RKHS理論保證了式(7)有如下的形式:為了減少待優化參數的數量,需要利用拉格朗日對偶性得到原始問題式(21)的對偶問題[13]: 式(23)中,α為對偶解,則原始問題的解為 選取一個滿足0<αi <(fHI(yi=1)+I(yi=?1))L(yi)的樣本,則根據KKT 條件(Karush-Kuhn-Tucker condition)可得 為驗證本文算法,使用某海域的水下目標歷史探測數據來構建目標-雜波數據集,由于數據集的樣本量較小,為了能夠得到有效的機器學習模型,采用“交叉驗證(Cross validation)”方法來處理數據。 對于類別不平衡數據,ROC曲線(Receiver operating characteristic curve)不易受到數據分布影響,是一種評價機器學習模型性能的常用方法[13]。ROC 曲線以真正率(True positive rate)為橫坐標,以假正率(False positive rate)為縱坐標,反映了檢測概率和虛警概率之間的制約關系。ROC 曲線下的面積被稱為Auc(Area of under curve)值,值越大表明分類效果越好。 不平衡樣本中,多數類樣本與少數類樣本的數量之比稱為不平衡率(Imbalanced rate,IR),本文所采用數據集(Xs,Ys)的IR≈245.3,數據維數為11(對應11 類特征),即Xs ∈R11,Ys ∈{?1,+1},“?1”代表雜波,“+1”代表目標,為少數類樣本。在該數據集上做10 次3 折交叉驗證[13],即每一次交叉驗證前分別將雜波和目標樣本隨機等分為3 份(每一份稱為一折),即Data1、Data2 和Data3,如表2所示,并形成3 組訓練集和測試集:(1)訓練集Data1 + Data2,測試集Data3;(2)訓練集Data1 +Data3,測試集Data2;(3)訓練集Data2 + Data3,測試集Data1。 表2 水聲目標-雜波樣本Table 2 Underwater acoustic target-clutter sample 分別在(1)、(2)和(3)上訓練并測試,重復進行10次,以減小實驗過程中的隨機性。 為便于比較,標準SVM、CS-SVM 和本文算法En-SVM 均采用徑向基核函數,核自由參數δ取1,采用序列最小最優化(Sequential minimal optimization,SMO)算法,由于涉及樣本間距離的計算,為防止受到具有過高特征值或過低特征值樣本的影響,輸入數據均做標準化處理。CS-SVM 和En-SVM 中的假負例FN 與假正例FP 的代價之比C?/C+取和IR 相同的值,算法在表2所示的數據集上做10次3折交叉驗證。 (1)算法性能比較 為了有效比較標準SVM、CS-SVM 和En-SVM在貝葉斯最優準則(式(5))下的性能,始終以0.5 作為概率決策門限,即算法輸出的后驗概率大于0.5時,該樣本(x,y)被判斷為目標,否則為雜波。為了保證實驗結果的可靠性,按照10 次3 折交叉驗證的方式進行,統計每次每折的分類后驗概率預測值繪制ROC 曲線并通過梯度法計算Auc 值,有效地消除了ROC 曲線中的“鋸齒”,使得固定門限下的數值更加準確。 依照圖例順序,圖2中所示曲線分別表示SVM、CS-SVM 和En-SVM 算法的ROC 性能,其中,每條曲線上會標記一個與曲線同色的實心點,該點表示決策門限值為0.5 時,算法能夠達到的檢測概率和虛警概率。為了使得算法輸出結果具有一定的統計意義和可信度,本文將機器學習算法的輸出通過Sigmoid 函數統一映射為正樣本(目標)的后驗概率值,即未知樣本數據是目標的可能性,后驗概率值越大,是目標的可能性越大。對于一條ROC性能曲線,當取不同的后驗概率值作為決策門限時,該門限將對應一組不同的檢測概率和虛警概率,為了防止人為的先驗知識對結果產生干擾,同時,為了使得不同算法具有相同的衡量標準,本文選取了概率值為0.5 處作為決策門限,大于0.5,則該未知樣本數據就是目標,否則是雜波,實現了從統計意義上的可能性向確定性決策的轉變。Auc值說明了ROC性能曲線接近左上角的程度,而實心點處對應的檢測概率和虛警概率則進一步說明了算法在統計意義上的優劣。 圖2 算法性能比較Fig.2 Algorithm performance comparison 可以看到圖2 中SVM的ROC性能曲線上沒有出現實心點,原因在于其實心點對應的檢測概率小于50%,一般更加關注檢測概率大于90%時對應的虛警概率,為了便于觀察不同算法性能曲線的差異,圖2中僅繪制出了檢測概率大于50%的部分。SVM算法的Auc 值低于CS-SVM 和En-SVM,且檢測概率低于50%,分類性能差。相較于CS-SVM算法,本文算法En-SVM 的Auc 值高出0.03,并且固定決策門限下的性能更靠近左上角,虛警概率降低了3.4個百分點,檢測概率提高了5 個百分點,分別達到了9.9%和95.6%,分類性能優于CS-SVM,即En-SVM算法在獲得高檢測概率時,可以排除約90.1%的雜波。實驗結果表明,對于不平衡數據的分類問題,本文算法En-SVM 因為考慮了少數類樣本不完全采樣過程中的信息損失,而具有更好的分類性能,更加接近貝葉斯最優決策(式(9))。 (2)數據集不平衡率對算法的影響 本文算法En-SVM 的核心思想在于度量原始數據空間(X,Y)和樣本空間(Xs,Ys)正類樣本分布的能量距離來量化正類樣本不完全采樣過程中的信息損失,來補償CS-SVM 在RKHS 中正類樣本的香農熵,使得正類樣本能在分類過程中為算法提供更強的分類信息,從而使En-SVM 能夠在有限樣本中逼近貝葉斯最優決策,獲得更好的分類性能。為了進一步驗證算法效果,將數據集(表2所示)中的目標數量(+1 表示)依次從105 隨機下采樣為90、60、30,對應的不平衡率IR 從245.3 變為286.2、429.3 和858.6,統計10 次3 折交叉的Auc 值,以“均值±標準差”的形式給出,并得到對應的ROC曲線。 由表3 可以看出,隨著IR 的增大,標準SVM的性能明顯下降,CS-SVM 性能也有所下降,而En-SVM的性能保持穩定,Auc值高于其他兩者。 表3 不平衡率對Auc 值的影響Table 3 Effect of unbalance rate on Auc value 圖3~5 分別為SVM、CS-SVM 和En-SVM 在不同IR 數據下得到的ROC 曲線,可以看出,隨著數據IR 的增大,En-SVM 能夠保持良好的性能,且0.5 決策門限下的性能波動程度比SVM 和CSSVM 小。實驗結果表明,En-SVM 能夠充分利用少數類樣本不完全采樣過程中的信息損失,提升算法性能,并具有一定的穩定性。 圖3 標準SVM 的ROC 曲線Fig.3 ROC of Standard SVM 圖4 CS-SVM 的ROC 曲線Fig.4 ROC of CS-SVM 圖5 En-SVM 的ROC 曲線Fig.5 ROC of En-SVM 本文針對少數類樣本在不完全采樣過程中存在信息損失,結合能量統計法提出了En-SVM算法,在處理水聲目標-雜波不平衡數據中有著良好的分類效果。實際海試數據的處理結果表明,En-SVM算法能夠在有限樣本中更加逼近貝葉斯最優決策,并且對樣本的不平衡率變化不敏感,驗證了算法的有效性和穩定性。本文采用的水聲數據集建立在高于最小可檢測閾6 dB 的數據上,未來將進一步研究該算法在更低可檢測信噪比數據集上的不平衡分類效果。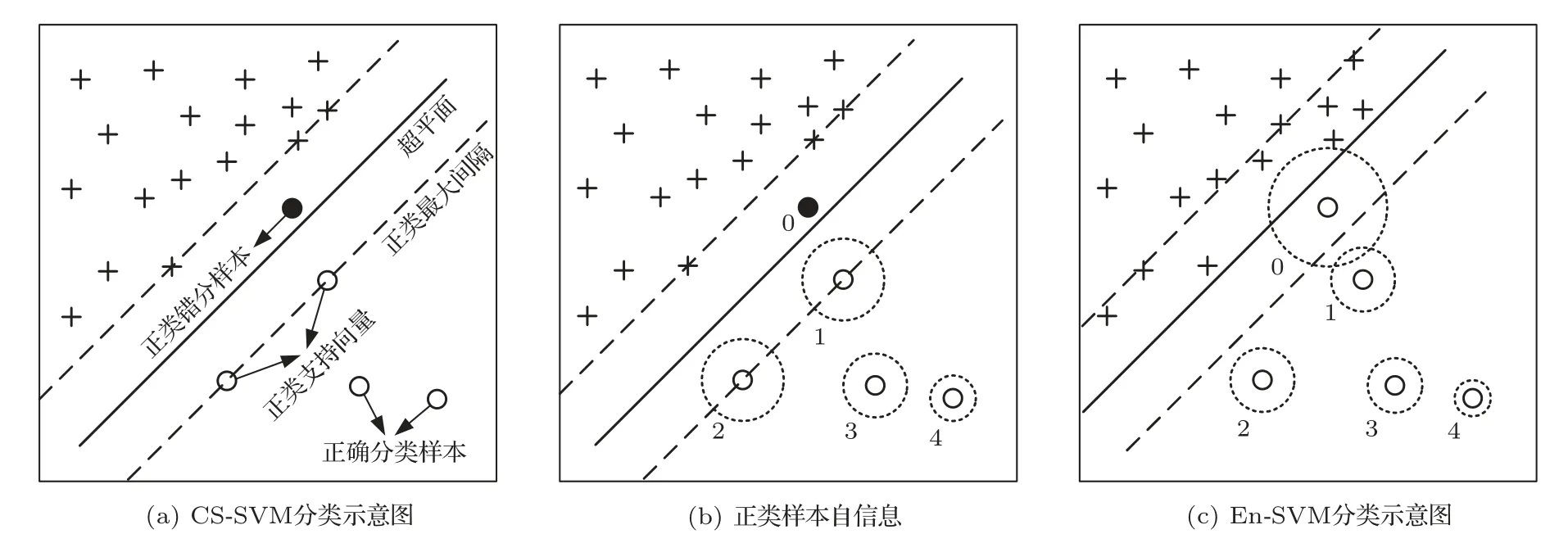

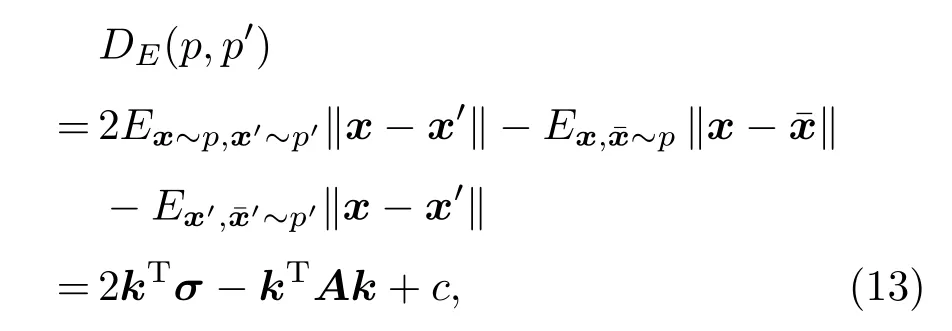

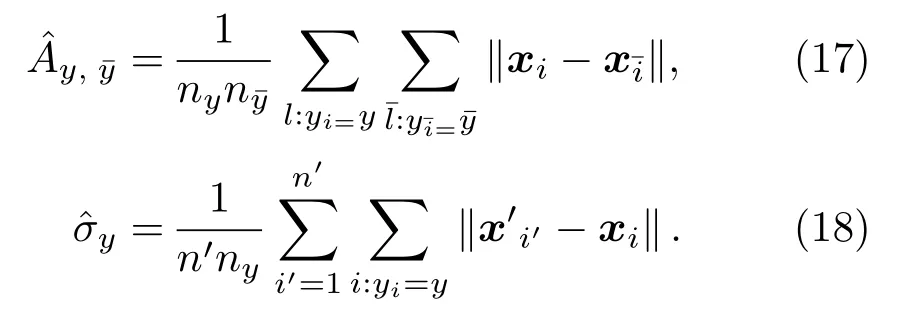


2.2 En-SVM算法求解




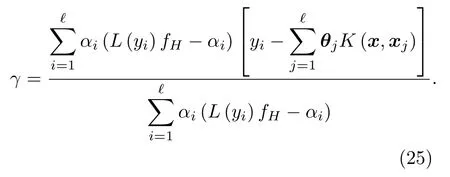
3 海試數據處理結果及分析
3.1 評價指標
3.2 水聲目標-雜波數據集

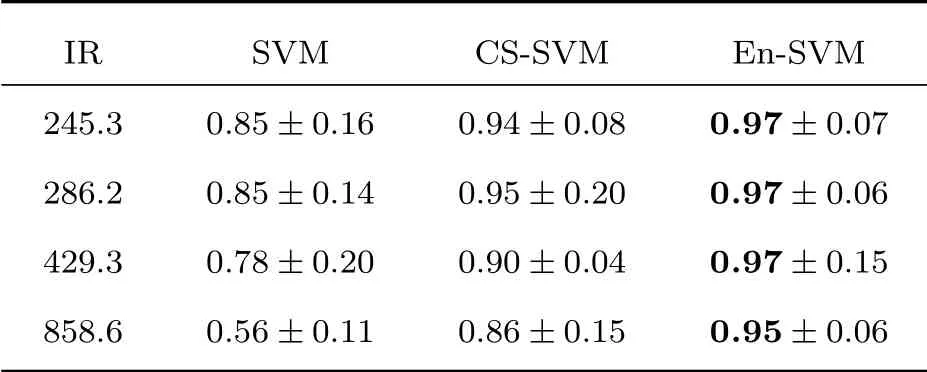
3.3 實驗結果及分析



4 結論
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
