一種結合域自適應的圖像語義分割算法
2021-10-20 10:59:30高宏力
機械設計與制造 2021年10期
毛 威,高宏力
(西南交通大學機械工程學院,四川 成都610031)
1 引言
語義分割是視覺研究的核心問題,相關實際應用如自動駕駛[1]、故障診斷[2-3]、車輛檢測[4]對其需求不斷增長。語義分割的目標是為圖像的每個像素分配語義標簽。現有基于深度神經網絡的圖像語義分割方法的訓練需要大量標記數據,這些數據的收集和標記成本高昂,這很大程度上限制了此類方法的實際應用。為解決此問題,這里使用成本較低的計算機生成并標記的逼真的合成數據訓練深度網絡。但真實圖像與合成圖像在分布域上存在的差異會降低模型性能,因此這里使用一種對抗學習方法來實現域自適應,以解決上述問題。
又由于語義分割輸出空間包含空間信息和局部信息(如空間布局和局部環境)。且即使在不同域的輸入圖像外觀迥異的情況下,語義分割輸出仍可能存在許多相似性。因此,這里采用在輸出空間上進行像素級域自適應的方法。在此基礎上,這里于不同級別的輸出空間構建多級域自適應網絡以提升模型性能。
具體來說,這里采用的域自適應方法是基于卷積神經網絡的端到端算法。在輸入空間上,通過對抗學習實現源域與目標域所預測的標簽分布的近似。基于對抗生成網絡[5],這里使用的模型由兩部分組成,一部分是語義分割模型用以預測分割結果,另一部分是判別器網絡用以判斷其輸入是源自目標域還是源域的語義分割輸出。對抗學習的目標是利用損失函數,使語義分割模型能夠欺騙判別器,進而使源圖像與目標圖像在輸出空間生成相似分布。
2 算法綜述
2.1 模型概述
概括地說,這里所使用的模型主要由兩部分組成,分別是用于語義分割的網絡G與判別器Di。其中當使用多級對抗學習時,i表示判別器所在的級別。將合成圖像集視為來自源域,用{}Is表示,相對的真實圖像集來自目標域,表示為{It}。兩個圖像集都∈RH×W×3,且只有源域圖像已被標記。
具體的方法是首先通過使用源域圖像訓練G以優化該網絡。再將目標圖像集輸入優化后的G,預測It的語義分割輸出Pt。然后根據對抗生成網絡的原理,將兩種預測輸出作為判別器的輸入,目的是判別輸入是否出自源域或目標域。由于任務的目標是使源圖像與目標圖像的語義分割預測相互近似,通過對目標域的預測計算對抗學習損失,經由Di向G的網絡梯度傳播,促進G在目標域生成與源域預測更相似的分割分布。
2.2 輸出空間自適應
盡管分割輸出位于低維空間,但其仍包含如場景布局等在內的豐富信息。即使源域與目標域的圖像不同,它們的分割輸出仍可能具有程度很高的空間和局部相似性。因此,在輸出空間上進行域自適應是更合適的選擇。這里利用這一特點,結合對抗學習方法來改進圖像的域自適應方法。
根據所提出的模型,這里使用構成模型的兩個網絡的損失函數構建域自適應方法的目標函數:

式中:Lseg-源域圖像輸入語義分割網絡的損失,使用交叉熵損失函數;Ladv-使目標域圖像的預測分割輸出近似于源域的輸出分布產生的對抗損失;λadv-平衡兩種損失的權值。
2.3 單級對抗學習
結合WassersteinGAN(W-GAN)[6]來定義判別器目標函數與對抗損失函數。WGAN與原始GAN算法的不同之處包括基于Wasserstein距離確定損失函數,且不使用log對數函數等。WGAN相較于原始GAN的優點體現于確保了GAN訓練的穩定性,降低對抗學習訓練的難度。
給定語義分割輸出為P=G(I)∈RH×W×C,其中C表示類別數目。將P輸入判別器D,通過訓練判別器的參數最大化源域與目標域圖像分割輸出的絕對差異。其損失函數可表示為:
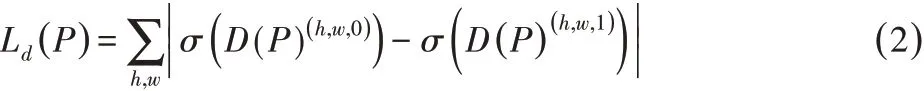
對于分割網絡的訓練,這里使用源域圖像的交叉熵損失定義分割損失:
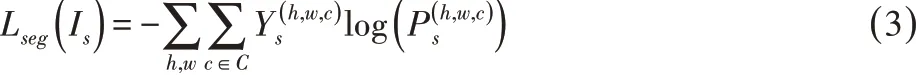
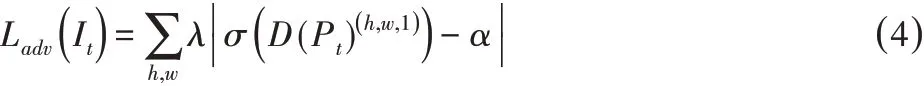
利用該損失函數訓練分割網絡,并通過促進Pt分布與Ps近似,最大化判別器將目標域的預測結果誤判為源域結果的概率。
2.4 多級對抗學習
與預測結果不同,由于距離輸出較遠,在輸出空間應用單級對抗學習時,低階特征所產生的改變不能達到要求。根據為語義分割算法添加附加損失函數的方法[8],這里于單級對抗學習模型基礎上,在低階特征空間增加另外的對抗模塊構成多級對抗學習模型,以提高自適應方法。這樣便可將分割網絡的訓練目標函數擴展為:
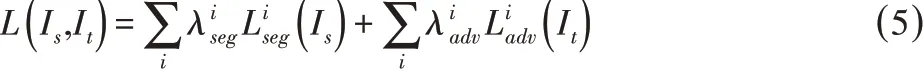
式中:i-對抗模型所在級別。注意到在輸入各判別器進行對抗學習之前,分割輸出是在各特征空間中產生的。因此與的形式仍和單級對抗學習中的相同。然后根據訓練對抗學習所常用的min-max準則,對式(5)進行優化:

訓練優化的最終目標是最小化源域圖像在G的分割損失,同時使目標域預測被判斷為源域預測的概率最大。
2.5 網絡結構與訓練
為保證G的分割結果符合需求,采用以在ImageNet上預訓練的ResNet-101[9]為基礎的DeepLab-v2[10]的殘差網絡變體作為語義分割G的基本模型。參照近期語義分割工作的方法[10][11],這里將最后兩個卷積層的步幅改為1,并移除了最后的全連接層。為了擴大感受野,在conv4與conv5層使用孔卷積方法[10],且步幅分別為2和4。在網絡最后,分類器使用孔空間金字塔池化(ASPP)[10]方法,并添加一個上采樣層使生成的softmax輸出的尺寸與輸入圖像相同。
判別器的結構與[12]相似,但為保存空間信息,只使用全卷積層。具體的,網絡由五個卷積層構成,使用步幅為2的4×4卷積核,每層的通道數分別為{64,128,256,512,1}。這里不使用批歸一化層,而以小批訓練,且在除最后層外的每一卷積層后都連接一個leaky ReLU層,并在最后的卷積層添加一個上采樣層以將輸出縮放至與輸入相同的尺寸。
根據上述分割網絡與判別器即可構建單級自適應模型。更進一步,這里從conv4層提取特征圖,并以ASPP模塊作為附加分類器,之后再連接用于對抗學習的判別器,這樣就生成了單級的自適應模塊。如此在不同卷積層應用該方法就能構建出多級自適應模型,而出于對效率與精度的權衡,這里只使用兩級自適應模型。網絡結構與域自適應模塊結構分別如圖1、圖2所示。
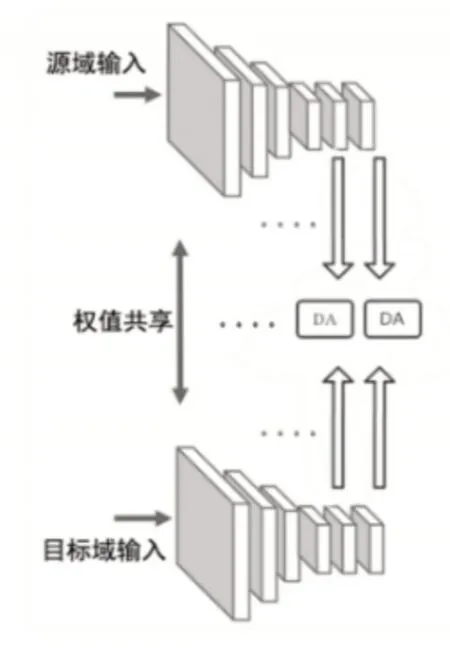
圖1 網絡結構,其中DA表示域自適應模塊Fig.1 Network Architecture,Domain Adaptation Module(DA)
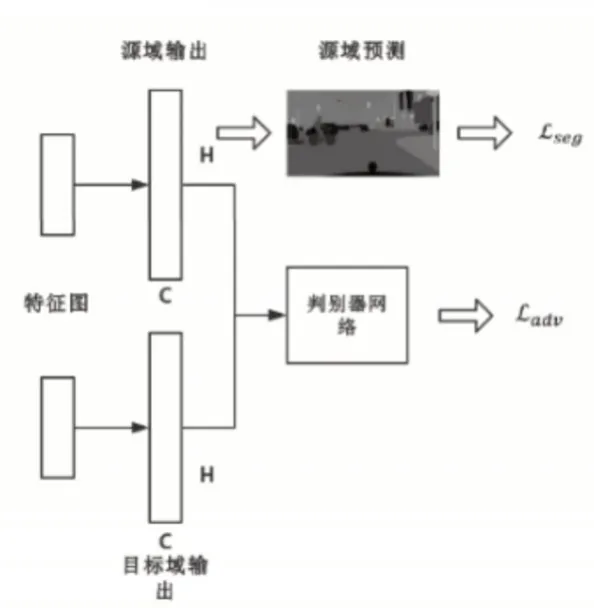
圖2 (DA)域自適應模塊,包含判別器網絡Fig.2(DA)Domain Adaptation Module
這里通過聯合訓練分割網絡與判別器的方法來有效訓練提出的模型。在每一訓練批次中,源域圖像Is首先被輸入進分割網絡以優化式(3)中的Lseg,并生成輸出Ps。緊接著,分割網絡對目標域圖像It的輸出Pt將與Ps共同被用于判別器,進而實現對式(2)中Ld的優化。最后再計算式(4)中的Ladv,以促進Pt與Ps分布的近似。對于多級模型的訓練,只需在每個自適應模塊中重復相同的步驟。為訓練分割網絡,這里采用隨機梯度下降優化(SGD)算法,其中權值衰減、動量等參數被設置為10-4和0.9,且初始學習率設為2.5×10-4并以指數為0.9進行多項式衰減。又由于WGAN訓練方法的特性,這里不選擇基于動量的優化方法,而使用隨機梯度下降優化算法訓練判別器,并設學習率為10-4。這里在GPU計算機上,使用PyTorch庫實現所用網絡。
3 實驗驗證
GTA5數據集是計算機合成圖像數據集,圖像總數為24966,且圖像分辨率為1912×1052,包含19個類別。在訓練過程中,這里先使用整個GTA5數據集訓練模型,再將CityScapes的訓練數據集的2975個圖像數據應用于該模型。當測試模型時,使用CityScapes的含有500個圖像的驗證集評估模型性能。所有的實驗都使用IoU測度評估結果。如圖3所示為實驗實例結果。

圖3 實驗實例結果Fig.3 Experiment Result
表1 的內容是這里所使用方法的結果與其他域自適應方法的比較。對于使用基于VGG-16結構的方法,這里采用與之相同的基本網絡結構訓練所提出的單級自適應模型,以準確評估比較不同方法。從表1可看出,這里所用方法取得了相對不錯的結果。并且與這里方法不同,其他方法皆擁有特征自適應模塊,而結果則表明在輸出空間實現自適應的方法是更合適的選擇。
利用高性能的模型作為基準與用自適應方法改進過的模型進行比較也是理解自適應方法重要性的手段。因此,這里在基于ResNet-101的網絡的基礎上訓練自適應模型。表1中表現了基準模型只使用源域圖像訓練且不結合自適應方法與不同自適應模型的結果比較。另外,監督模型與自適應模型間的差異的縮小程度也是評價自適應方法的重要因素。因此,這里使用CityScapes數據集的標記真值訓練得到監督模型,作為參照結果。通過表2的比較結果可發現,基于VGG-16網絡的模型與參照結果的差異更大,因此基于ResNet網絡的方法更為適用。
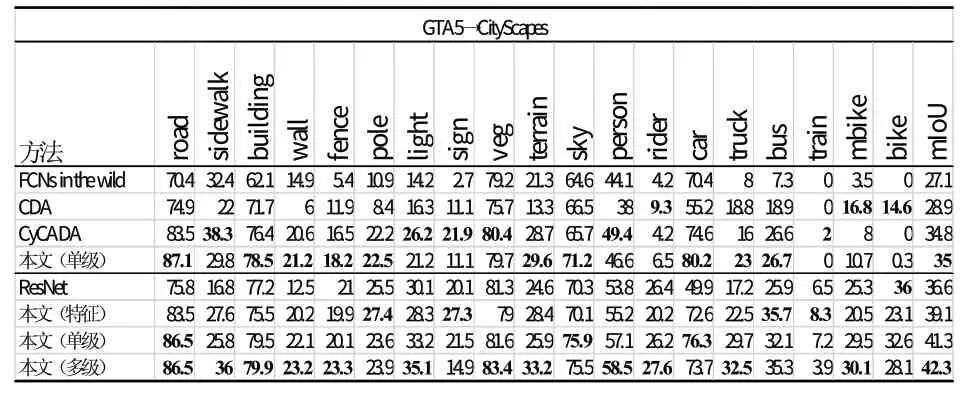
表1 基于VGG-16的方法及基于ResNet-101的方法實驗結果Tab.1 Experiment Result Based on VGG-16 and ResNet-101
在訓練優化分割網絡G時,確保分割損失與對抗損失的權值的相對平衡非常重要。基于單級自適應模型,這里通過比較改變λadv所取得的不同結果尋找合適的λadv值。實驗結果表明較大的λadv值可能致使網絡傳播錯誤的梯度,所以這里選取0.001作為λadv值。同樣在單級自適應模型的基礎上,這里比較了基于特征的域自適應與在輸出空間上的域自適應方法的結果,其中基于特征的方法使用判別器判別不同域的圖像的特征。可以看到在輸出空間的自適應方法的優點體現在兩點:一是其實驗結果更好;二是在特征空間的自適應對λadv參數的改變更為敏感,這增加了訓練的難度。對于多級對抗學習的訓練,位于高階輸出空間的模塊的參數設置與單級對抗學習的參數相同(即0.001)。而由于低階輸出用于分割預測的信息較少,故這里賦予其分割與對抗損失較小的權值(即
總結來說,由表3的實驗結果可看到,相較于基于特征的自適應方法,在輸出空間上的自適應方法結果更好,并對參數改變更不敏感,從而降低了訓練的難度,所以這里選用在輸出空間的自適應方法。通過表1的實驗結果可看到這里所用域自適應方法取得了與其他一些方法相比較較為良好的結果準確度。表2通過對不同自適應模型與監督模型的精度差的比較可以看到這里所使用的基于ResNet的多級自適應方法對精度提高的作用更為顯著。
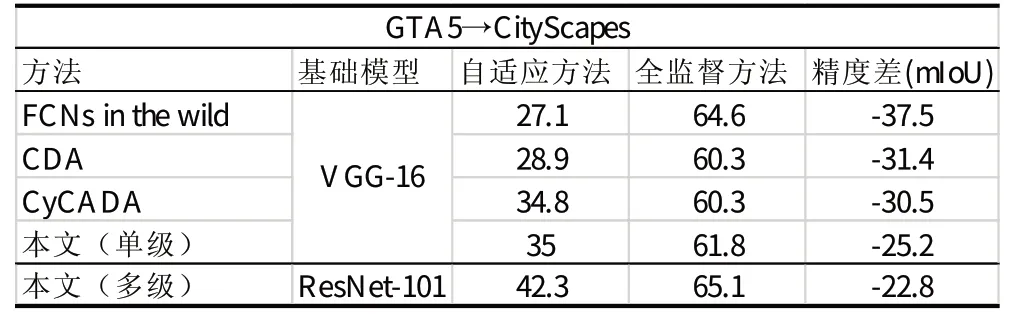
表2 自適應模型與監督模型的精度差Tab.2 mIoU of Adaptation Model and Supervised Model
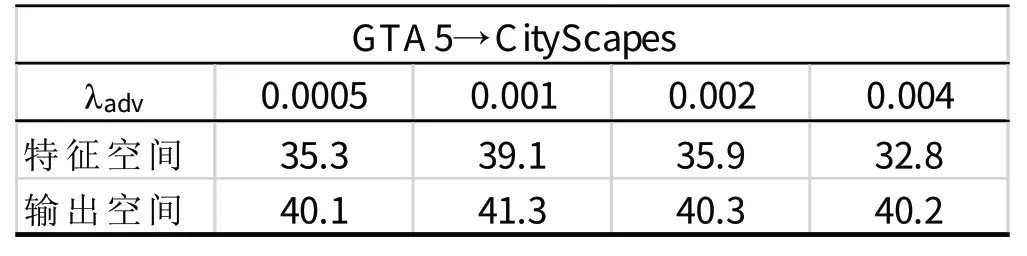
表3 不同空間的域自適應方法對λadv參數改變的敏感度Tab.3 Sensitivity for Domain Adaptation Method to λadv in Different Space
4 結束語
這里采用域自適應方法將通過合成圖像訓練的模型應用于真實圖像的語義分割,以解決大量有標記真實圖像獲取成本高昂的問題,其中域自適應方法通過在輸出空間上的對抗學習實現。根據WGAN對對抗學習損失函數進行了改進。另外,還通過構建多級對抗學習網絡來利用不同級別特征信息以提升模型性能。實驗結果表明這里所提出方法相較于其他方法取得較好的結果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
