基于語義網技術的海量數字檔案智能挖掘方法
2021-10-22 01:11:40謝暉
北京印刷學院學報 2021年9期
謝 暉
(菏澤醫學專科學校,菏澤 274000)
在文化的傳承和社會發展中,檔案記錄與保存有著重要意義。隨著時代的變遷,檔案記錄與保存也在不斷變化與發展,逐漸形成了現今這種分類體系明確的不同等級檔案館[1-3]。檔案不僅包括個人的學籍資料和人事資料等,還包含企業公司信息文件。檔案文件種類繁多,紙質檔案的保存形式已經不能滿足現今檔案記錄產生的速度,因此,各級檔案館均已開展數字化工作,建立了相應的電子檔案庫以及檔案網站供公眾使用,但是能做到全文檢索的少之又少[4-5]。對于這種情況,國內外研究學者研究數字檔案智能挖掘方法,利用高新技術在海量數字檔案中挖掘出有價值的檔案,如遺傳算法和支持向量機的應用,但是這兩種技術的應用局限于簡單的電子化,在理解關鍵詞中只能理解詞語的概念,難以發現詞語之間的潛在邏輯,導致挖掘的數據之間關聯性不強[6-8]。因此,可以應用語義網技術,設計基于語義網技術的海量數字檔案智能挖掘方法。語義網是一種智能網絡,利用該技術更深層地理解關鍵詞之間的邏輯關系,可以使挖掘的數據關聯性更強,使交流變得更有效率和價值。
一、基于語義網技術的海量數字檔案智能挖掘方法
(一)聚合數字檔案資源
數字檔案資源種類繁多,各類資源之間存在較強的語義關系。通過語義網技術挖掘出各種不同類別檔案的內在聯系,并將存在關系的檔案通過語義網技術連接在一起,實現資源聚合[9]。數字檔案涉及的種類比較多,以學科電子檔案為例,檔案資源有科研團隊、條件設施和規章制度等。這些資源之間具體聯系,如圖1所示。

圖1 學科電子檔案各類資源關系
從圖1中可以看出,電子檔案各類資源之間存在較強的關聯,這些關聯關系的存在,使得電子檔案資源的語義關聯和聚合成為可能。在對數字檔案資源的語義關系和聚合與服務的支撐技術分析的基礎上,利用關聯數據框架實現數字檔案資源的聚合,如圖2所示。
圖2中顯示的框架能夠引導數字檔案數據的創建與發布,在聚合框架中,借助檔案語義描述的本體或詞表,實現資源的語義關聯,再利用檔案資源關聯數據創建、聚合數字檔案資源[10]。采用圖2顯示的聚合框架流程,按照從底層到頂層的順序,基于關聯數據逐層實現數據資源的聚合,從而完成整個數字檔案資源的聚合。在聚合完成后,基于語義網技術構建檔案知識庫。

圖2 數字檔案資源聚合框架
(二)構建檔案知識庫
構建檔案知識庫的主要目標是借助本體技術將數據庫內知識概念化,通過語義網挖掘出檔案記錄中各個項目的內在聯系,如事件和任務。在已知各類檔案記錄內在聯系的基礎上,即可根據關聯程度形成具有知識關聯網絡的知識庫。通過檔案知識庫,能夠更好地幫助用戶獲取和利用檔案知識,也能享受到資源共享的知識庫服務[11]。
構建的檔案知識庫采用分層架構體系結構,主要分為資源層、知識組織層和應用層,分層的主要依據是檔案知識庫中數據的流向和數據的處理。檔案館館藏資源原始數據再經過知識抽取本體組織得到互聯的知識網,再利用語義網技術將用戶檢索需求與知識庫內容相匹配,通過可視化技術將數據呈現給用戶[12]。
館藏資源層中包含很多含有語義解釋的檔案數據和資源,這些檔案數據和資源有不同的種類,是通過拍照或掃描等方式處理后獲得的,通過數字化技術轉化為數字資源存儲在數據庫中。數據中包含檔案源文件數據庫以及音視頻數據庫[13]。依據知識庫的分層體系結構,可知館藏資源層是整個體系結構中的數據來源,通過結構中的知識組織層處理檔案數據,如語義分析、關系抽取等,處理完成后將資源傳遞給功能應用層。應用層中包含檔案資源的屬性特征,主要表現為網狀知識結構,檔案資源本體在對檔案數字資源進行映射后,形成符合知識本體框架結構的實例庫。根據用戶的實際需求和數字檔案管理的實際需求,在應用層中開發出相應的功能塊和應用接口,實現對檔案數字資源的調用與管理[14]。
在檔案資源數據檢索中,主要利用知識本體和推理規則實現。其中,知識本體明確了檔案記錄的種類、屬性和內在關系,通過計算檢索詞與知識概念間的相似度,即可實現數據檢索,將符合檢索條件的內容呈現給用戶。但是這時返回給用戶的結果中可能存在部分無用數據,因此通過挖掘后將關聯性較強的數據再傳遞給用戶。
(三)挖掘數字檔案
根據現有檔案知識庫,使用決策樹算法實現數字檔案挖掘,依據離散屬性—值對,將檔案知識庫中的數據分割成若干個小型樣本數據集。將決策樹結點改造成能夠滿足樣本數據集需求的結構,將改造完成后的決策樹結點分為貝葉斯結點和普通葉結點[15]。
在挖掘數字檔案資源過程中,根據檔案資源數據生成葉結點,為避免出現匹配過度的情況,設置一個閾值,計算劃分前的結點差異值的度量,將計算結果與閾值相比較,若大于閾值,則進行進一步挖掘;反之,計算結果小于閾值,則生成葉結點。重復上述過程,如果有i個實例數據要規劃到當前結點,并且其中有i1個實例屬于分類k,它們最可能的分類是G,則可以得到G與i1的關系:

此時生成初始決策樹,將獲得的實例集合G作為輸入,分別計算結點的差異度,并與閾值相比,選擇集合中分布期望做小的屬性—值對B,返回一個與其對應的樣本數據集合并輸出,該集合即為挖掘的數據集合。
在上述過程中,算法會不斷將新的檔案實例與決策樹中劃分的屬性相匹配,判斷該實例是否正確劃分,若已經被準確劃分,則進行下一例,重復上述過程。直到所有實例均已劃分完成,實現數字檔案挖掘。若實例劃分錯誤,則結合該實例對該節點的貝葉斯參數進行更新修正,如此不斷地更新修正,直到實例劃分正確,完成挖掘。至此,設計的基于語義網技術的海量數字檔案智能挖掘方法完成。
二、海量數字檔案智能挖掘方法實驗研究
(一)實驗準備
在海量數字檔案智能挖掘方法實驗研究中,選取某省檔案館館藏某勞動廳全宗作為研究對象,主要包含各個不同時期的檔案資料,共計400多個卷宗。檔案館對這些檔案的分類方式以年度—問題方式為主,主要包括綜合性檔案、勞動保護、勞動工資等內容。
基于原有的檔案,構建出檔案本體,因本體范圍較大、類目層級過多無法構建全部檔案,考慮實驗的實際需求,從多個類別選擇部分檔案構建本體。主要從主題、責任者、時期、地域、日期和檔案資源格式這六個方面構建,將構建完成的數字檔案作為實驗對象。使用不同的數字檔案智能挖掘方法挖掘檔案中的數據的關聯性。計算檔案數據之間的支持度和置信度,并利用第三方軟件輸出某關鍵數據的并發性。通過以上結果分析不同的數字檔案智能挖掘方法的實際性能。支持度和置信度計算公式如下:
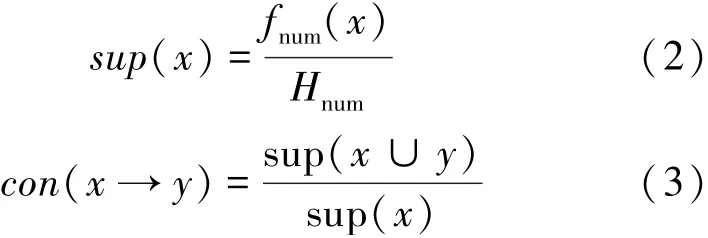
公式中sup(x)表示數據x的支持度,con(x→y)表示數據x與y的置信度,fnum表示數據x在挖掘出的檔案數據中出現的次數,Hnum表示挖掘出的數據總量。通過上述公式計算出不同挖掘方法數據的支持度和置信度,結合數據的并發性分析挖掘方法關聯水平的高低。
(二)支持度與置信度實驗結果與分析
隨機選取檔案中關鍵詞,使用不同的挖掘方法挖掘出相關數據,計算該關鍵詞的支持度與置信度,結果如表1所示。
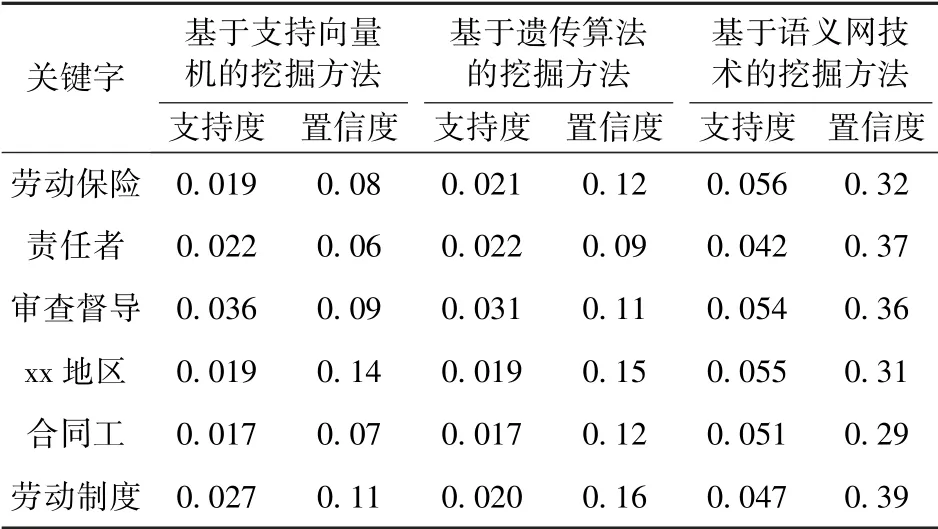
表1 支持度與置信度計算結果
觀察表1中數據,支持度表示挖掘方法中挖掘數據在整體數據集中的比率,置信度表示挖掘的數據與選擇的關鍵詞之間的關聯程度。從表1數據可以看出,在不同的關鍵詞中支持度和置信度較高的都是基于語義網技術的挖掘方法,兩個指標均高于另外兩種方法,這是因為語義網技術的應用解決了以往使用的挖掘方法中的問題,在數據之間建立較強的聯系,挖掘出的數據關聯性極強。
(三)并發性實驗結果及分析
在上述實驗的基礎上,隨機選擇某一關鍵詞,利用第三方軟件將不同挖掘方法的該關鍵詞的關聯關系展示出來。
圖3中顯示的點表示與關鍵詞相關的數據,線段的長短表示并發性。從圖3中的結果可以看出,基于語義網技術的數據挖掘方法關聯的數據點更多,并發性更強。結合支持度與置信度數據可知,設計的基于語義網技術的海量數字檔案智能挖掘方法關聯性更強,挖掘出的數據更能滿足實際應用的需求。

圖3 不同挖掘方法的數據并發性實驗結果
三、結語
隨著互聯網絡的飛速發展,檔案數字化逐漸完善,海量數字檔案的智能挖掘成為當前研究的重點。在本文研究中,利用語義網技術發現數據中潛在的邏輯關系,構建檔案知識庫,在檔案數據間建立更加牢固的關聯,保證挖掘結果的可靠性和適用性。但是研究中依然存在不足之處,如語義研究中很大一部分是基于本體,受到的限制比較多,在后續的研究中仍然需要投入更多的精力研究這一問題。
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
當代陜西(2021年17期)2021-11-06 03:21:36
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
開放教育研究(2020年2期)2020-03-31 01:54:14
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
資源再生(2017年3期)2017-06-01 12:20:59
讀者(2017年5期)2017-02-15 18:04:18
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
