條形基礎下砂-黏土雙層地基極限承載力預測模型的不確定性分析
2021-10-22 02:16:14張毅博
重慶大學學報 2021年9期
關 宇, 張毅博
(中國人民大學 a.審計處;b.國際交流處,北京 100872)
地基承載力是土力學中的一個經典問題。均勻土層上條形淺基礎在豎向荷載作用下的極限承載力一般采用太沙基承載力公式來確定。在實際工程中,成層土是常見的現象,由各種自然因素或人為因素造成[1]。在地基處理中,一般采用砂土來替換上層的軟粘土層以提高地基承載力。這就形成了上砂下黏的雙層地基,這種雙層地基的破壞模式比均勻土層更為復雜,其破壞面可能僅在砂土層范圍內,也可能延伸到下臥黏土層。目前對于這種砂-黏土雙層地基的極限承載力問題已有較多的研究,其研究方法主要有極限平衡法[2-4]、極限分析法[5-8]、實驗方法[3,9-14]和數值分析法[1,15-17]等。其中,在極限平衡法的基礎上,逐漸演化和發展出了不考慮剪切強度,將土層重度超載化的應力擴散法[4]和假設土層完全剪切且被動失效的沖剪破壞法[2-3]。這2種方法都是基于理想假設條件下的半理論半經驗方法,參數簡單、易于理解,對于解決地基極限承載力的工程問題發揮了重要的作用。但是基于理想假定條件下產生的系統誤差往往會使理論結果與工程實際產生較大的偏差。
巖土工程的可靠性理論是在統計學方法和概率論方法的基礎上不斷發展和完善的,由于解決巖土工程問題的數學模型、數值分析程序等都是基于一定理想化條件的,理論基礎往往不能夠完全反映工程實際,計算結果也不夠準確,因此不確定性成為最大的特點。這種基于理想條件下的不確定性被認為是認知不確定性[18]。在對巖土工程實際問題的可靠性設計過程中,如何分析理想模型的認知不確定性成為重中之重[19]。對于條形基礎下,砂-黏土雙層地基極限承載力的預測問題,Tang等[20]收集了一個包括離心機試驗得到的承載力數據庫,并結合有限元方法對這2種工程中最常用的半經驗方法進行了不確定性分析和經驗性修正。研究結果沒有提出新的計算方法,仍然是在此2種方法假設的破壞模式基礎上得到。
文中針對豎向荷載時條形基礎下的砂-黏土雙層地基極限承載力問題,提出一種不依賴于破壞模式假設的計算方法,并對該設計方法進行不確定性分析。采用極限分析上限法對承載力進行數值計算,得到不同工況下的設計圖表,并對參數進行敏感性分析。基于計算結果提出了預測極限承載力的簡化公式。收集了基于不同方法研究中得到的砂-黏土雙層地基極限承載力預測值,建立數據庫,基于此數據庫對文中的數值結果和得到的簡化公式進行統計學不確定性分析。
1 數值模型及驗證
1.1 數值模型
圖1是數值模型示意圖。在砂-黏土雙層地基上放置了一個剛性條形基礎。B是基礎寬度。砂土沒有黏聚力,φ是摩擦角,D是厚度,γ是重度。黏土沒有摩擦力,c是黏聚力。砂土層假設排水、黏土層假設不排水。基礎與砂土層的交界面認為完全粗糙,這一摩擦角與砂土摩擦角相等。
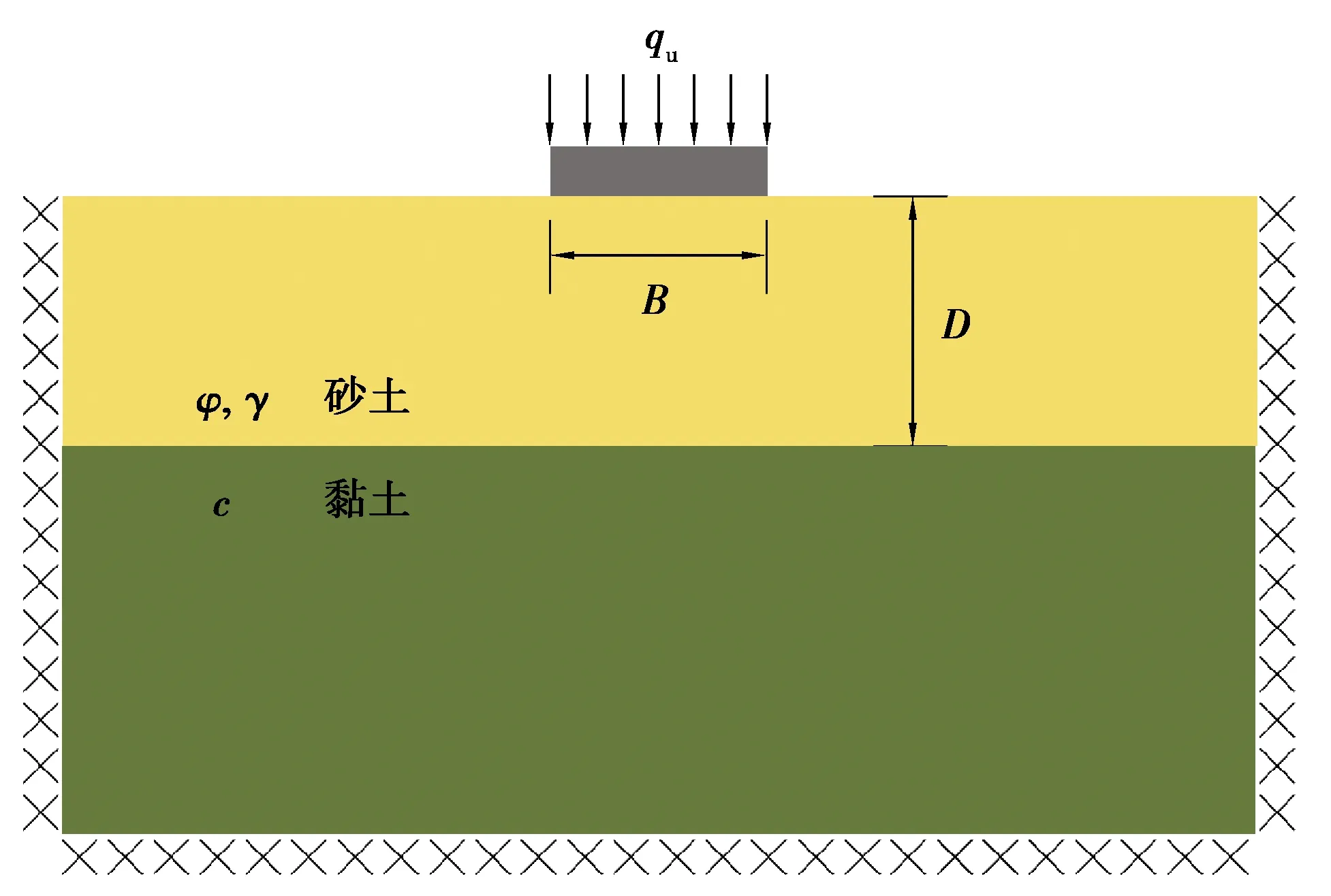
圖1 數值模型
文中使用計算軟件LimitState:GEO[3]基于不連續布局優化(discontinuity layout optimization,DLO)算法來計算地基承載力。DLO是一種計算程序,基礎是塑性理論,原理是極限分析上限法,在已有研究中被廣泛應用于各種承載力計算[21-25]。根據不同的工況在建模時協調均勻地布置了網格密度,節點數量為3 000~5 000,在塑性區集中的局部區域進行了網格加密,這樣做可以提高計算精度并保證計算結果協調一致。
1.2 數據庫建立及模型驗證
為了分析DLO方法計算得到的極限承載力準確性,作為進行不確定性分析的基礎,收集了現有文獻中砂-黏土雙層地基的極限承載力數據,形成一個共包含81個數據[1,2,7,12,17,26-29]的數據庫。為了便于分析驗證,對數據庫中的參數作無量綱處理,包括tanφ、c/γB、D/B以及qu,m/γB。基于此數據庫,對每一個工況分別使用DLO方法對承載力進行計算,同樣對其進行無量綱化,為qu,DLO/γB,與現有文獻中的承載力進行比較,如圖2所示。由圖可見,這些對比數據的平均趨勢非常接近1∶1線,幾乎所有數據的誤差都在20%之內。對比數據的決定系數R2(0.92)同樣可以說明其準確性。上述特征表明,采用DLO計算的承載力與現有文獻中的承載力近似度很高,證明了DLO方法在預測砂-黏土雙層地基的極限承載力時比較精確。
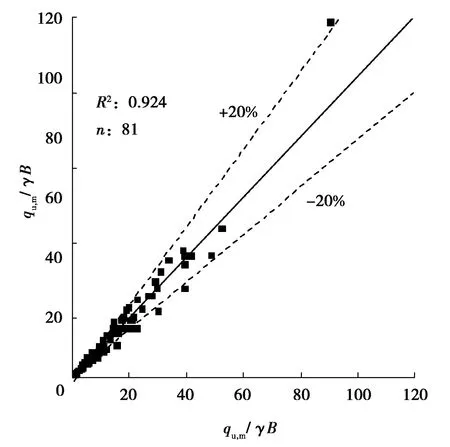
圖2 DLO計算結果(qu,DLO/γB)與文獻結果(qu,m/γB)比較
在巖土工程領域,計算模型不確定性的評估通常以模型因子[19-20,30]為媒介,模型因子往往是通過實際測量值與該模型預測值的比來表征的。因此,為了表征DLO計算結果的不確定性,定義其模型因子λ為
λ=qu,m/qu,DLO
(1)
通過2個環節[20]對模型因子λ進行不確定性分析:1)對模型因子關于輸入參數的依賴性進行分析;2)建立一個有意義的統計模型用來表征模型因子。基于Spearman相關系數[31]對模型因子λ分別關于輸入變量(tanφ、c/γB和D/B)的依賴性進行分析。其中,Spearman相關系數是一種在統計學中常用的非參數指標,作用是對變量之間的依賴性進行量度,表示為τ,其值為+1時表示2個變量完全單調正相關,其值為-1時表示負相關。分別對不同模型因子的Spearman相關系數進行計算分析,如表1所示。其中,λ的關于所有輸入變量的p值均大于0.05,從統計學考慮λ可以被看作一個隨機變量。
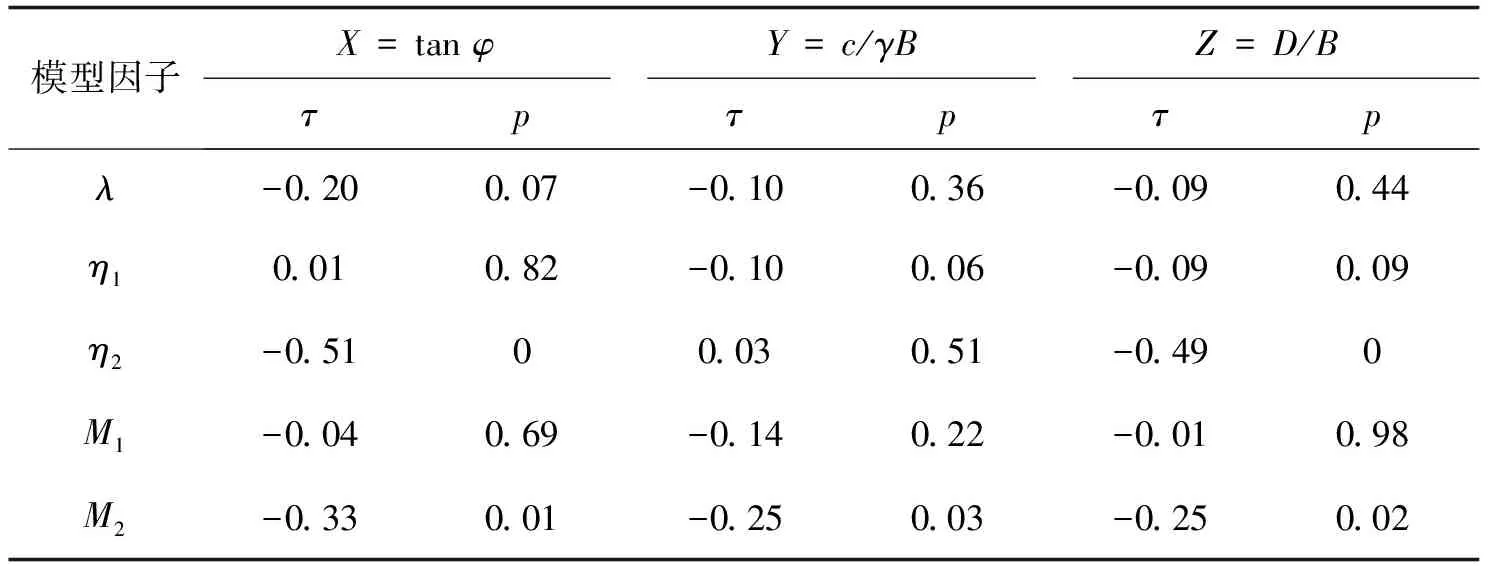
表1 文中得到的Spearman相關系數
建立統計學模型用以表征λ。通過計算,λ的均值為1.01、標準差為0.15和變異系數為0.14。均值約等于1說明DLO方法的預測合理性,標準差、變異系數比較小,說明DLO方法的預測精確性。圖3是λ的概率密度函數(PDF)和累計分布函數(CDF),說明λ的分布在統計學上可以被看作符合對數正態。K-S檢驗[31]的p值遠大于0.05同樣可以說明這一點。
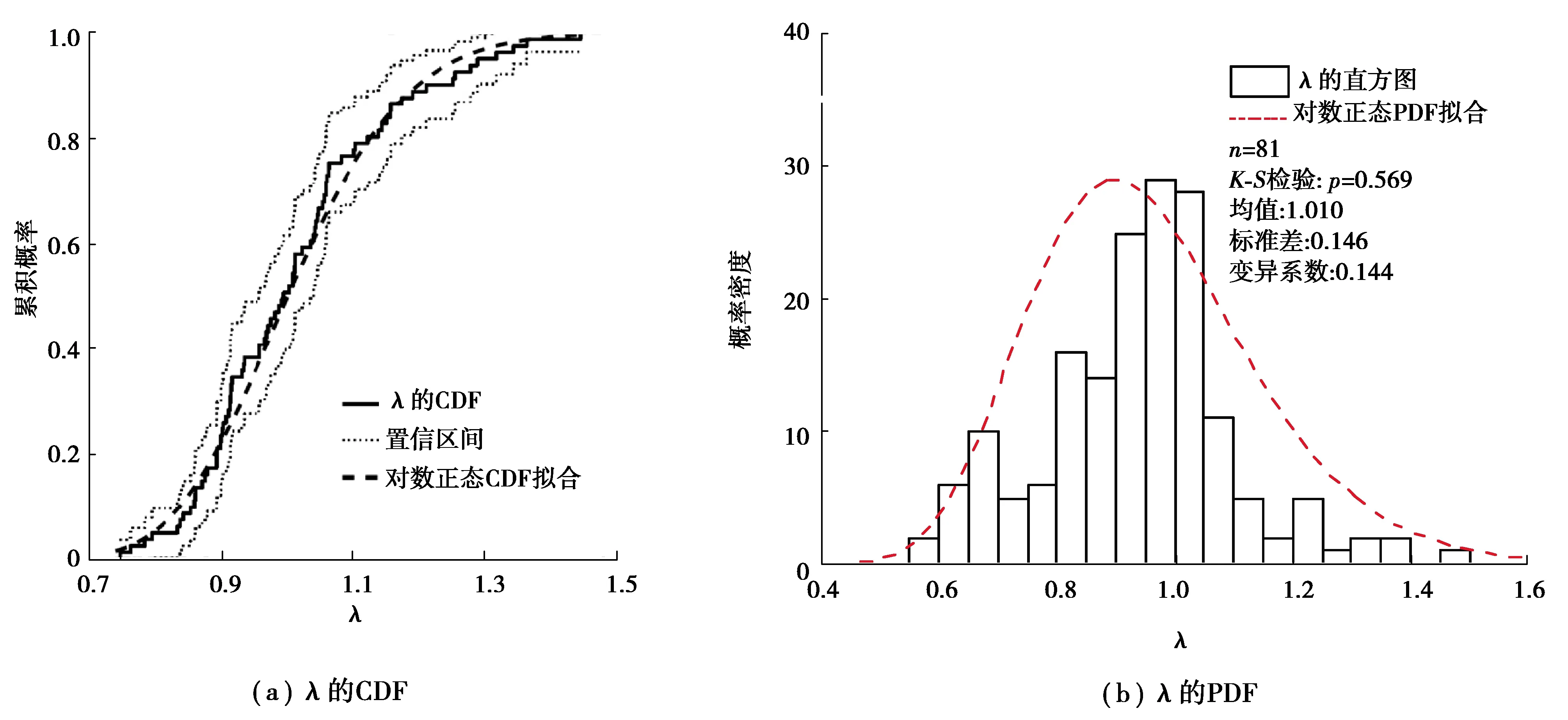
圖3 λ的CDF和PDF
λ與各個參數分別獨立,在統計學上被認為是一個隨機變量,并且符合對數正態分布。結果表明,在統計學意義上DLO計算地基極限承載力時只有隨機誤差而不具有系統誤差,其計算結果可以作為可靠度設計的依據。
2 承載力設計圖表
采用DLO方法計算條形基礎下砂-黏土雙層地基極限承載力,參數取值如表2所示,在承載力變化的臨界值附近加大計算工況的分布密度。在經典承載力理論的基礎上,提出了承載力折減系數R:
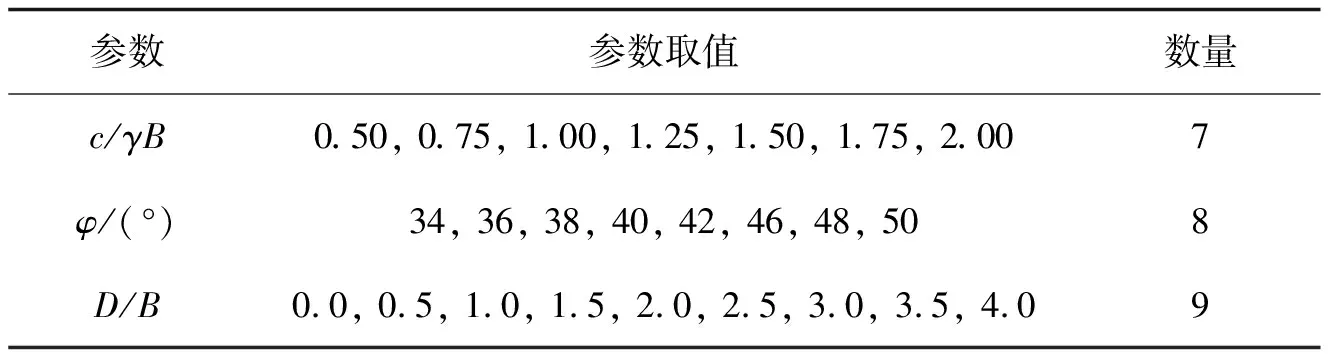
表2 承載力參數取值
(2)
式中,qu,s為條形基礎下純砂土的地基極限承載力。根據太沙基承載力理論,qu,s計算公式為
(3)
圖4為條形基礎下,砂-黏土雙層地基承載力折減系數R使用DLO的計算結果。與預想結果一致,R值與D/B呈正相關趨勢,這是因為更厚的上層砂土對承載力起到更大的作用。當φ<42°時,不論c/γB取何值,當D/B增加到一定程度,R值最終都會逐漸趨于1,此時的砂-黏土雙層地基承載力完全是由純砂土進行承載的,下部黏土層對承載力的貢獻為0,總體的破壞模式為Prandtl形式,并且破壞范圍只在砂土層中。當φ≥46°時,R值在當前厚度范圍內始終小于1,即砂-黏土雙層地基承載力始終小于純砂土承載力,此時的破壞面始終很大,黏土層仍然對承載力有所貢獻。對于φ<42°的工況,存在一種由黏土層貢獻承載力向黏土層不參與承載力的臨界狀態,此時的厚度稱之為臨界厚度(D/B)cri。可見,(D/B)cri與φ呈正相關關系,與c/γB呈現負相關。

圖4 地基承載力折減系數R設計圖表
3 簡化公式及不確定性分析
3.1 簡化公式
預測模型采用多元回歸(PR)的方法進行構建[20,32]。由圖4可知,R值關于D/B的函數形如一個凹函數,其開口向上,這種形式與冪函數一致。定義這一函數的縱軸截距為R0,此時砂土層厚度為0,代表該工況下純黏土承載力和純砂土承載力的比值。基于以上計算數據,可以得到R值的多元回歸模型為
R=(α1X0.2Y+α2X0.3+α3X+α4Y+α5)Z(-Xα6Yα7+α8)+R0,
(4)
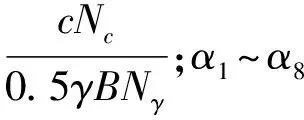

表3 簡化公式參數
3.2 不確定性分析
3.2.1η的不確定性分析
簡化公式(4)得到承載力進行無量綱化為qu,c/γB,將其與DLO計算的承載力qu,DLO/γB進行對比,如圖5所示。可以看到,對比數據的趨勢與1∶1線非常接近,幾乎所有點的誤差都小于20%,決定系數R2為0.99。圖5表明簡化公式(4)可以較為精確地對DLO承載力的計算進行擬合。
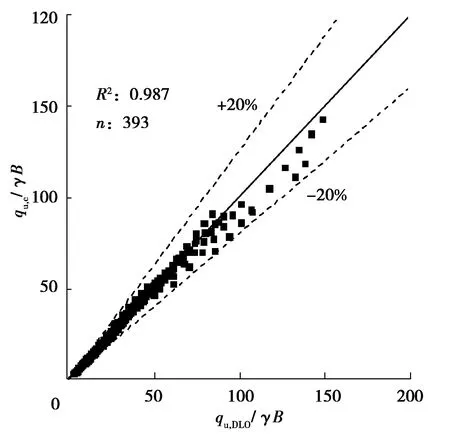
圖5 簡化公式計算結果(qu,c/γB)與DLO計算結果(qu,DLO/γB)比較
式(4)對于DLO計算結果的擬合存在不確定性,定義模型因子η為
η=qu, DLO/qu,c。
(5)
得出η的統計模型的先決條件是評估其對輸入變量的依賴性。基于上述數據,分析所有的Spearman相關系數如表2所示。可見,3個輸入變量均具有大于0.05的p值,η可以被看作一個隨機變量。η的均值、標準差和變異系數分別為1.00、0.05和0.05。圖6是η的累計分布函數(CDF)和概率密度函數(PDF),通過K-S檢驗(p值為0.05)認為η符合對數正態分布。
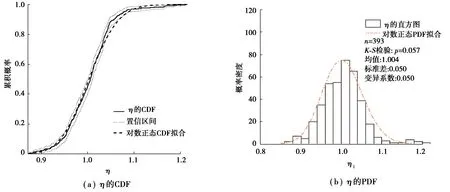
圖6 η的CDF和η的PDF
3.2.2 M的不確定性分析
將qu,c/γB與文獻中的承載力qu,m/γB進行對比,如圖7所示。可以看到,簡化公式(4)預測結果接近現有文獻的結果,平均趨勢類似于1∶1線,決定系數R2為0.96。
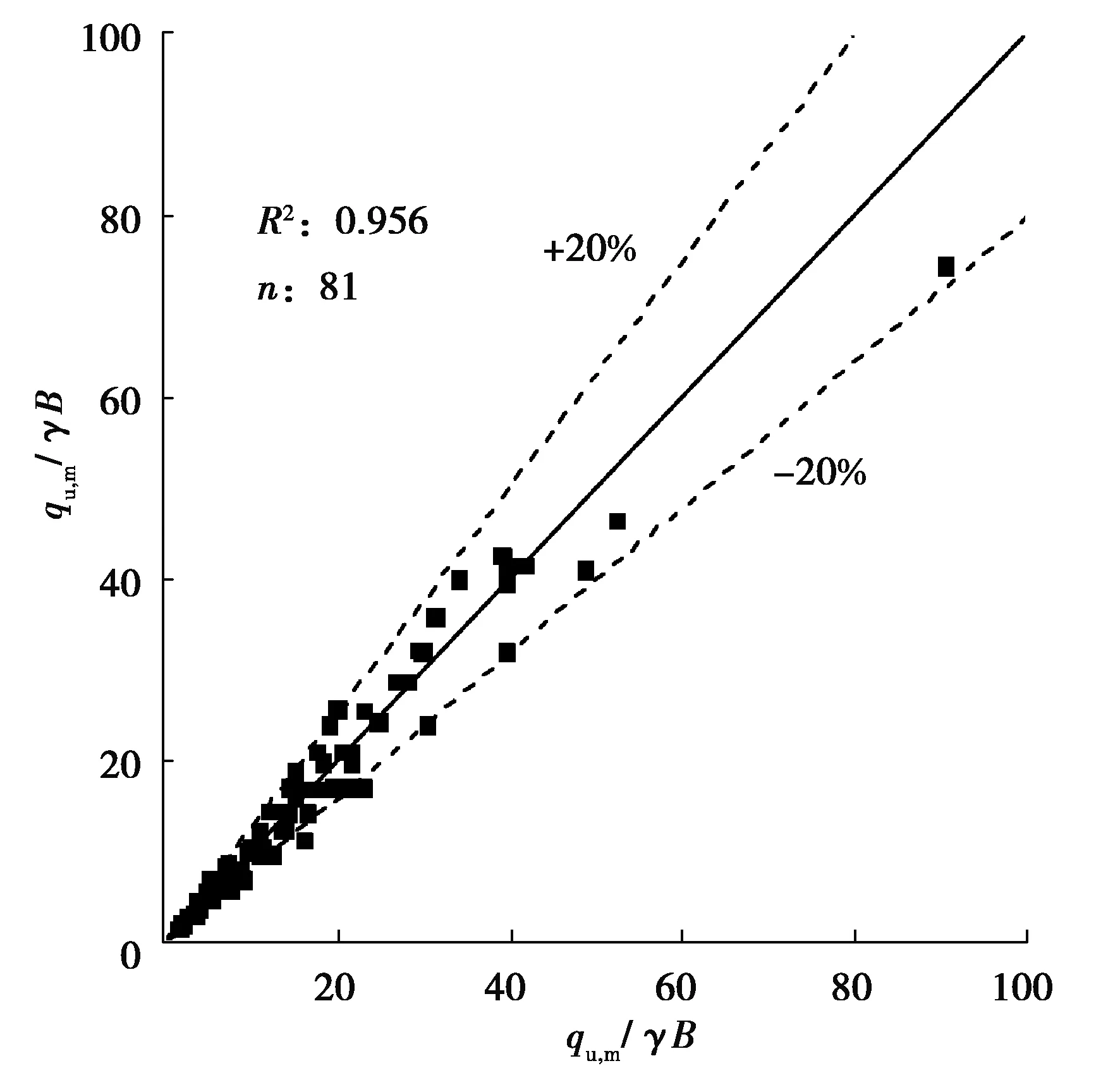
圖7 簡化公式計算結果(qu,c/γB)與文獻中計算結果(qu,m/γB)比較
定義模型因子M為
M=qu,m/qu,c。
(6)
通過文獻中的81個數據,計算M與3個輸入變量的Spearman相關系數如表2所示。3個輸入變量的相關系數p值均比0.05大,說明M不具有系統誤差,可以被看作隨機變量。M的均值、標準差和變異系數既可以直接計算得到,也可以表示為2個隨機變量(λ和η)的積:
M=λη。
(7)
因為λ和η均符合對數正態分布并且相互獨立,所以M同樣符合對數正態分布[33],其均值和變異系數分別計算如下:
μM=μλμη,
(8)
(9)
式中,μM、μλ和μλ分別是M、λ和η的均值;δM、δλ和δη分別是M、λ和η的變異系數。
根據式(8)和式(9)可得,M的均值、標準差和變異系數分別為1.01、0.15和0.15。作為比較,由81個數據計算得到的M均值、標準差和變異系數分別為1.00、0.14和0.14,區別很小。
M、λ和η3個模型因子的均值都非常接近1;M和λ的變異系數較大且非常接近,但是η的變異系數要明顯更小。根據式(9),這一現象揭示了λ是M隨機誤差的主要來源,即簡化公式關于DLO結果的預測模型具有很高的精度,而DLO方法關于文獻承載力的預測較為粗略。圖8是M的累計分布函數(CDF)和概率密度函數(PDF),K-S檢驗p值為0.47,可知M可以被看作符合對數正態分布,這一結論與式(9)一致。
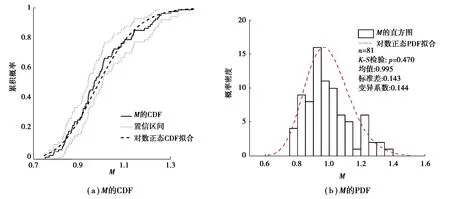
圖8 M的CDF和PDF
4 結 論
使用極限分析上限法對條形基礎下,砂-黏土雙層地基極限承載力進行計算,繪制了設計圖表用以表示承載力折減系數R。提出了簡化公式用以預測極限承載力。收集了文獻中的承載力計算結果,對DLO的計算和簡化公式的計算不確定性進行分析,得到如下結論:
1)條形基礎下,砂-黏土雙層地基極限承載力的影響因素大體包括土體強度和幾何尺度。承載力折減系數R與D/B呈正相關關系,這種情況下的破壞面超出了上層砂土的范圍;當R等于1時,破壞面則不會延伸到軟土層。根據這一轉換定義了臨界厚度(D/B)cri,這一臨界厚度關于φ呈正相關,關于c/γB則相反。
2)條形基礎下,砂-黏土雙層地基極限承載力的DLO預測結果具備統計學意義上的可靠性。DLO關于文獻承載力結果的預測模型因子λ可以被看作隨機變量并且符合對數正態分布,其均值為1.01、標準差為0.14、變異系數為0.14。
3)提出的簡化公式對承載力的預測具有計算精確、沒有系統誤差的特點。簡化公式關于DLO計算結果和現有文獻承載力結果的模型因子η、M可以看作隨機變量并且符合對數正態分布,其中η的均值為1.00、標準差為0.05、和變異系數為0.05,M的均值為1.00、標準差為0.14、變異系數為0.14。M的隨機誤差主要來源于DLO對現有文獻計算結果的預測。這一簡化公式可以作為條形基礎下,砂-黏土雙層地基極限承載力可靠度設計的參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
結構工程師(2022年2期)2022-07-15 02:22:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
廣西科技大學學報(2016年1期)2016-06-22 13:10:41
鐵道科學與工程學報(2015年5期)2015-12-24 12:11:58
核科學與工程(2015年4期)2015-09-26 11:59:03
太陽能(2015年6期)2015-02-28 17:09:30
中國艦船研究(2014年6期)2014-05-14 06:45:22
