
使用HRV 多特征參數和機器學習的心衰診斷方法研究
2021-10-26 12:27:24趙興群
電子器件 2021年4期
張 敏,趙興群
(東南大學生物科學與醫學工程學院,江蘇 南京 210096)
充血性心力衰竭(congestive heart failure,CHF)是一種常見的慢性心血管綜合征,也稱為心力衰竭,當心臟無法向人體中泵送足夠的血液時,就會發生心衰[1]。CHF 的主要特征是心室收縮或舒張功能障礙,常見癥狀包括疲勞、呼吸困難、運動耐力低下和體液潴留等,進一步可導致內臟和肺部充血[2]。心衰是各種心臟疾病的嚴重表現或晚期階段,死亡率和再住院率居高不下,中國心力衰竭注冊登記研究(China-HF)顯示,各年齡段心衰病死率均高于同期其他心血管病,七十歲以上人群患病率大于等于10%[3]。因此,研究心衰疾病的預防及診斷技術具有重要的價值和意義。目前,診斷心衰疾病主要根據癥狀和體征等綜合分析判斷,需要耗費大量的醫療資源及人工成本。對于不斷增加的患者,需要研究一種便捷、快速且有效的檢測系統來進行心衰診斷。
心電圖(electrocardiogram,ECG)能夠記錄心臟電活動的變化情況,反映相關生理和病理信息,且具有無創、簡便、經濟等優點,已成為各種心血管疾病診斷中的必備基本診斷技術。與依靠醫生經驗直接通過心電圖進行診斷相比,信號處理技術和生物醫學分析方法的應用可以進一步提高診斷的可靠性。在過去的研究中,已經使用多種方法來通過ECG 信號檢測CHF。Chen 等[4]使用稀疏自動編碼器提取相鄰兩個R 波之間的間隔(RR 間期)的無監督特征,然后應用具有不同隱藏節點組合的全連接神經網絡來檢測心衰信號。Wang 等[5]設計了一個基于RR 間隔的長短期記憶(long short-term memory,LSTM)網絡來檢測CHF,準確度最高達到85.13%。Acharya 等[6]訓練了一個11 層卷積神經網絡模型,并直接對原始ECG 信號進行識別分類,最高準確度可達98.97%。這些研究均使用了神經網絡和深度學習的方法,雖然分類準確度較高,但這些結果很難被臨床醫生解釋,分解得到的特征參數也并無具體含義,同時,由于對整個模型的運作機制無法理解和解釋,在進一步設計明確并有針對性模型的優化方案時也存在困難。
因此,通過ECG 信號得到有實際意義的特征,再進行分類識別,這樣的方法可解釋性和可應用性會更高。對于CHF 診斷,許多研究通過ECG 信號QRS 波群[7]、從QRS 波起始至T 波終止的時間間隔(QT 間隔)[8]和RR 間期差異[9]等重要特征進行檢測。其中,RR 間期差異的變化情況又被稱為心率變異性(heart rate variability,HRV),HRV 分析是一種用于評估心血管自主神經系統功能的非侵入性方法[10],已應用在臨床心臟疾病和非心臟疾病研究的各個領域,包括心肌梗塞[11]、糖尿病[12]和心源性猝死[13]等。近些年來,越來越多的研究證明了HRV 與CHF 的相關性。CHF 患者通常具有較高的交感神經活動和較低的副交感神經活動[14]。Kamen 等[15]對健康受試者進行交感神經和副交感神經的控制并進行HRV 分析,結果表明交感神經活動的增強和副交感神經活動的降低會導致平均RR 間隔、RR 間期標準差、低頻含量(LF)的降低和Poincare 圖的寬度(SD1)的增加。Malliani 等[16]研究表明LF-HF 平衡會隨著交感神經活動的增加而發生變化,且副交感神經活動的增加是導致高頻(HF)含量增加的主要因素。Liu 等[17]計算了健康者和CHF 受試者HRV 信號的近似熵(ApEn),結果表明CHF 組的ApEn 值降低。上述研究表明,心衰病人和健康人的HRV 在多個特征參數上都具有明顯差異性,可以通過HRV 分析提取特征參數來檢測CHF。
本研究綜合選取基于HRV 分析計算得到的多個特征參數,并使用機器學習的分類方法進行CHF的檢測。首先,對ECG 信號進行HRV 分析,從時域、頻域、非線性分析中各選取多個相關指標,并將其共同做為樣本的特征參數。然后,使用機器學習方法中的決策樹、支持向量機、貝葉斯、最近鄰算法、隨機森林等設計分類器,進行心衰信號的識別分類。最后,提出一種基于個人的分類評估方法,在數據劃分時避免一個人的數據同時出現在訓練集和測試集中,給出分類結果的客觀評價指標。
1 實驗數據與預處理
1.1 實驗數據
本研究使用來自復雜生理信號研究資源庫PhysioNet[18]中的充盈性心衰數據庫BIDMC Congestive Heart Failure Database[19]及正常竇性心律數據庫Mit-bih Normal Sinus Rhythm Database 1.0.0。其中心衰數據庫包括15 例CHF 患者,信號采樣頻率為250 Hz;正常竇性心律數據庫包括18 例健康人,信號采樣頻率為128 Hz。兩個數據庫中樣本采樣時間都在18 h~24 h 之間,為長時采樣。
為了符合更多的實際應用場景,考慮短時采樣的情況,并達到擴充實驗樣本數的目的,本研究采用信號分段的方式,將長時采樣數據分割成以10 min 為間隔的信號段,結果可得到5 220 組有效心電信號。
1.2 預處理
由于HRV 反映的是心電信號中逐次心跳周期的變化情況,進行HRV 分析需首先從心電信號中計算得到心電信號周期,即RR 間期序列。因此要進行R 波檢測,得到R 波峰值,本文采用基于濾波和自適應閾值的檢測方法,經過濾波、差分、幅值逐點平方、移動窗口積分、自適應閾值及決策融合等步驟,檢測到各個位置的R 波,結果如圖1 所示,上圖為ECG 信號R 峰檢測結果,用符號“+”標注,下圖為對應的RR 間期序列。
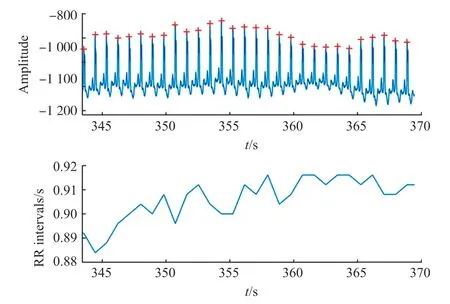
圖1 R 波檢測結果
1.3 HRV 特征參數計算
在CHF 檢測和分析中可使用多種HRV 分析方法,其中最經典和全面的分析方法分為三個部分,時域、頻域和非線性分析。
1.3.1 時域分析
時域分析法是心率變異性分析中最簡單的方法,能夠直觀地反映信號的特點,同時具備醫學上的生理意義。相關的指標直接從RR 間期序列中統計或計算得到,本研究選取RR 間期均值Mean、中位數Median、正常RR 間期標準差SDNN、每5 分鐘RR間期平均值的標準差SDANN、相鄰兩個RR 間期差值的均方根rMSSD、相鄰RR 間期相差大于50 ms的個數占總心跳次數的百分比PNN50、平均心率MeanHR、心率標準差SDHR 等8 個特征參數,對于數據長度為N的RR 序列{RRi:1≤i≤N},相關計算方法如下:

1.3.2 頻域分析
頻譜分析技術的原理是將隨機變化的間期或瞬時心率信號分解成各種不同能量的頻率成分,能反映更復雜的心率變化規律,也稱為功率譜密度(Power Spectrum Density,PSD)分析。HRV 頻域分析會首先計算RR 序列的功率譜密度,將頻域分成多個頻段,然后統計與每個頻段匹配的RR 間期數量。通常將頻段分為三部分:0.15 Hz~0.40 Hz 的高頻(HF)、0.04 Hz~0.15 Hz 的低頻(LF)和0.003 3 Hz~0.040 Hz 的極低頻(VLF)。因此,選取以下4 個頻域相關指標:VLF、LF、HF 和LF/HF。
HRV 時間序列功率譜密度的計算可使用自回歸模型法求解[20],對于時間序列x(n)的p階的自回歸模型可表示為公式(8)。
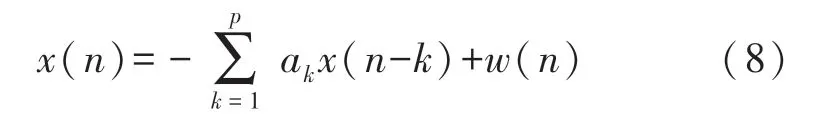
式中:w(n)方差為σ2的白噪聲。功率譜密度的表達式為:
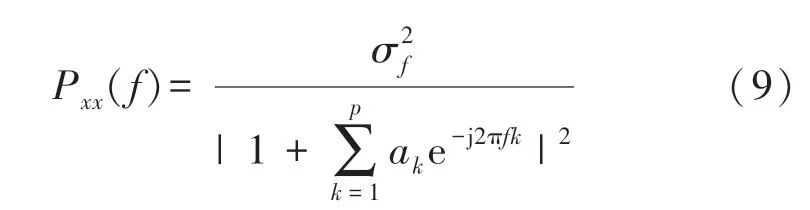
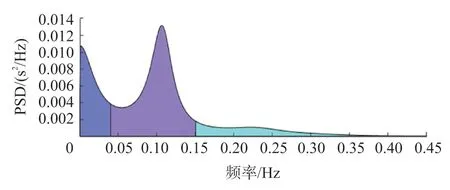
圖2 RR 序列功率譜密度
1.3.3 非線性分析法
非線性理論的發展為心率變異性分析提供了更多的方法和手段,按照一定采樣周期去測量得到的時間序列數據,幾乎所有的非線性分析方法均被用于心率變異性信號的特征分析,本研究選取的方法包括Poincare 散點圖(Poincare plot)、去趨勢波動分析(Detrended Fluctuation Analysis,DFA)、遞歸圖分析(Recurrence Plot Analysis,RPA),以及近似熵(Approximate Entropy,ApEn) 和樣本熵(Sample Entropy,SampEn)等。
Poincare 散點圖表示的是連續RR 間期的相關程度。以相鄰兩個心搏的前一個RR 間期為橫坐標,后一個心搏的RR 間期為縱坐標繪制一點,如此連續繪制,即形成散點圖,如圖3 所示。圖中這些散點的分布可近似為橢圓,其中,SD1 和SD2 分別為橢圓的半短軸和半長軸。
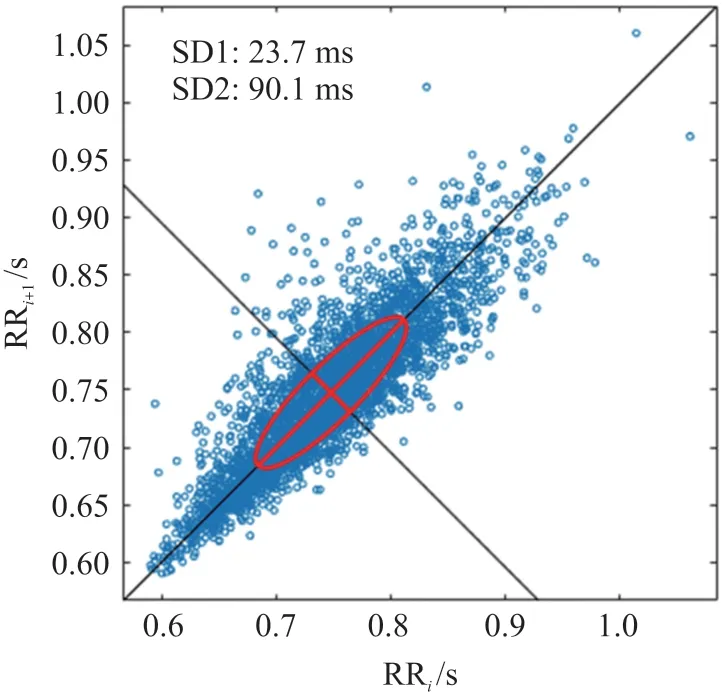
圖3 RR 序列Poincare 散點圖
去趨勢波動分析度量了信號內部的相關程度。計算方法如下:
首先對RR 間期序列進行積分:
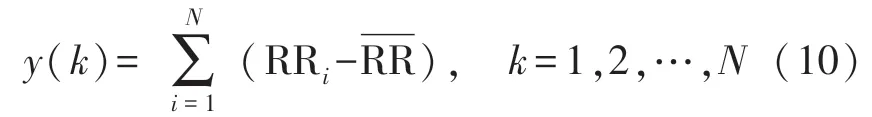
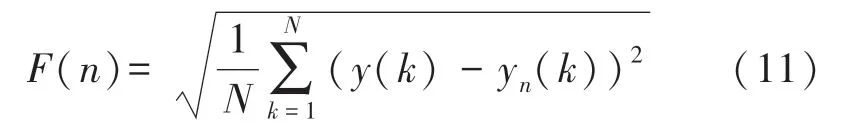
取n=4,5,…,16,得到一組數據(logn,log(F(n))),采用最小二乘法對這組數據進行擬合,其斜率即DFA 分析的一個參數αl。相應的,取n=16,17,…,64 時,得到DFA 分析的另一個參數α2。擬合結果如圖4 所示。
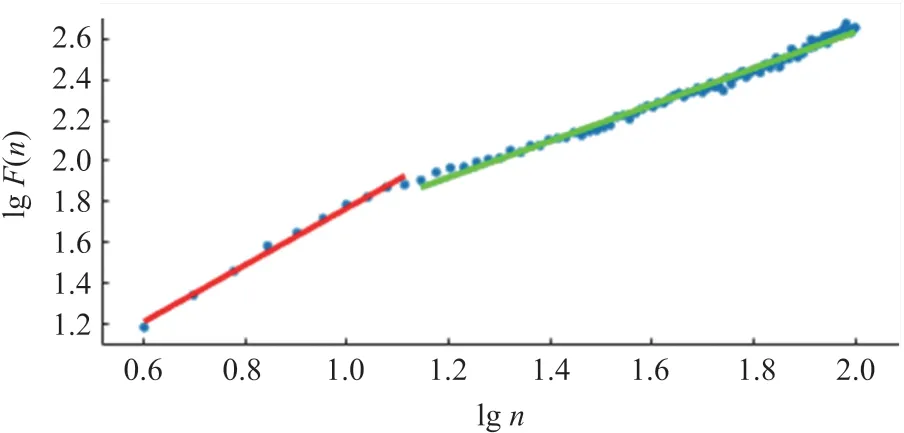
圖4 RR 序列DFA 分析結果
近似熵是測量信號復雜度或不規則度的指標,取值越大,復雜度或不規則度越大。計算近似熵,首先需要計算向量

最后得到近似熵:
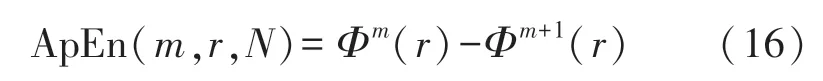
樣本熵的計算與近似熵類似,首先需要計算向量ui,并定義距離d,然后根據以下公式計算樣本熵:
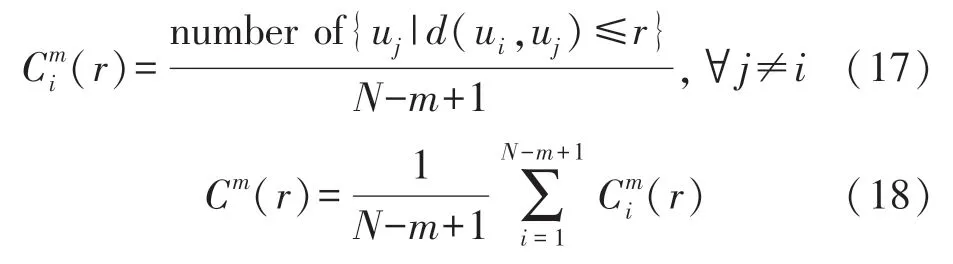
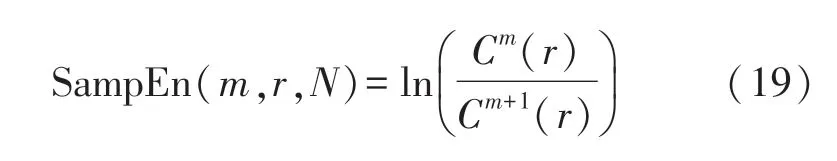
2 分類及結果分析
2.1 分類
隨著對分類問題研究的深入,越來越多泛化性高、穩健性強的算法涌現而出。其中,機器學習算法能夠從數據中自動分析獲得規律,并利用規律對未知數據進行預測,具有精確、自動化、分類用時短等優勢。本文選擇了五種不同的機器學習分類器,一是利用概率統計知識進行分類的樸素貝葉斯算法(Naive Bayes,NB),二是以實例為基礎的歸納學習算法決策樹(Decision Trees,DT),三是具有聚類思想的K 近鄰算法(K-Nearest Neighbor,KNN),四是具有集成學習思想的分類器隨機森林(Random Forest,RF),五是具有最大邊距決策思想的支持向量機算法(Support Vector Machines,SVM)。
2.2 結果及分析
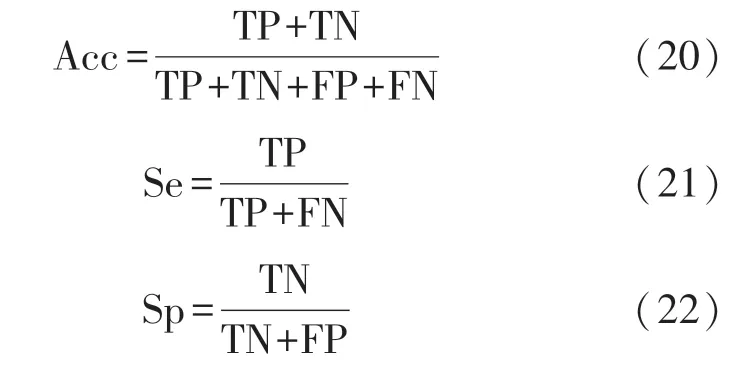
本研究對5 220 個樣本數據分別進行了時域、頻域、非線性分析,選取8 個時域指標、4 個頻域指標和7 個非線性指標作為特征參數,使用樸素貝葉斯算法、決策樹、K 近鄰、隨機森林、SVM 等機器學習方法的分類結果進行比較。分類結果主要通過三個指標進行評估:準確率(Acc),靈敏度(Se)和特異性(Sp)。通過式(20)~式(22)計算得到,其中TP表示正確診斷出的CHF 的數量,TN 表示正確診斷出的正常信號(以Normal 表示)數量,FP 表示被誤分類為CHF 的Normal 數,FN 表示被誤分類為Normal 的CHF 數。
為了能夠與之前的分類算法進行比較,在數據劃分時,訓練集與測試集首先按照3∶1 的比例從所有數據中隨機選取,并將所得結果與以前的研究進行比較,最終比較結果如表1 所示。
由表1 可看出,將HRV 分析的多個參數作為特征時,使用機器學習的各分類方法識別心衰信號都可取得較高的準確率,其中,SVM 方法分類準確率最高,可達到98.81%,特異性和靈敏度分別達到98.76%和98.87%,與之前的研究結果相比,超越了基于其他特征的分類方法,如基于Hankel 矩陣的特征值分解方法[21]和基于經驗模態分解的分類方法[22],證明了本研究方法的可行性。

表1 分類結果比較
此外,本研究還進行了基于個人進行數據劃分,使同一個人的相關樣本數據只出現在測試集或只出現在訓練集中,在這種方式下,訓練集和測試集中不會同時出現同一個人的數據,更符合實際應用場景,評估結果更客觀可信。結果表明,應用SVM 分類方法準確度仍可達到98.32%,靈敏度和特異性分別為98.62%和98.03%,進一步驗證了本方法在實際應用中的有效性。
3 結束語
本文研究了基于ECG 信號進行心衰診斷的方法,首先進行R 波檢測得到RR 間期序列,再通過HRV 分析計算得到時域、頻域、非線性的多個參數,并使用機器學習的多種分類方法進行心衰信號的分類識別,均取得較高的準確率,其中,SVM 方法超越了已有的心衰檢測算法,在分類精度、特異性和靈敏度方面均有所提高,證明了在心衰診斷方面的可行性。未來將進一步充實臨床數據,繼續探討本方法在臨床方面的應用效果。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
鴨綠江(2021年35期)2021-04-19 12:24:18
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年11期)2018-08-04 03:25:42
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
山東工業技術(2016年15期)2016-12-01 05:31:22
