異常信息的智能分類算法研究
2021-11-01 13:37:32馬宗方馬祥雙
計算機測量與控制 2021年10期
馬宗方,馬祥雙,宋 琳,羅 嬋
(西安建筑科技大學(xué) 信息與控制工程學(xué)院, 西安 710055)
0 引言
智能信息處理是信號與信息技術(shù)領(lǐng)域一個前沿的富有挑戰(zhàn)性的研究方向,它以人工智能理論為基礎(chǔ),側(cè)重于信息處理的智能化,包括計算機智能化(文字、圖象、語音等信息智能處理)、通信智能化以及控制信息智能化[1-3]。然而在實際應(yīng)用中,各種復(fù)雜因素可能會導(dǎo)致采集到的數(shù)據(jù)信息是不完整的。例如,在氣象數(shù)據(jù)的采集過程中,由于傳感器故障或者在數(shù)據(jù)傳輸過程中信號受到噪聲干擾,就會造成某一段時間內(nèi)的數(shù)據(jù)缺失;在填寫調(diào)查問卷時,調(diào)查者不愿意回答那些涉及到個人隱私的問題,這樣就導(dǎo)致無法獲取這部分信息。由于大多數(shù)傳統(tǒng)的分類器不能直接處理含有缺失值的數(shù)據(jù)集,因此有大批學(xué)者研究并提出了適用于不完整數(shù)據(jù)的分類算法[4-5]。其中,最簡單的就是刪除含有缺失值的樣本或者刪除缺失值所在的屬性項,然后再用傳統(tǒng)的分類器分類[5]。但是刪除法僅適用于缺失率不到5%的數(shù)據(jù)集,并且刪除屬性項可能會改變數(shù)據(jù)分布,進而會影響算法分類性能。最為常見并且有效的處理不完整數(shù)據(jù)分類問題的方法是插補法,就是通過合理的估值來填補缺失數(shù)據(jù),這樣就能用基礎(chǔ)分類器對帶有估計值的完整數(shù)據(jù)分類[5]。
1987年,Little和Rubin[7-8]針對數(shù)據(jù)缺失機制提出了3種不同類型的缺失情況:完全隨機缺失(MCAR,missing complete at random)、隨機缺失(MAR,missing at random)和非隨機缺失(MNAR,missing not at random)。目前對缺失數(shù)據(jù)的研究主要集中在MAR和MCAR上。在眾多的缺失值插補方法中,主要分為單值插補和多值插補。常用的單值插補方法是均值插補(MI,mean imputation)[9],其主要思想是根據(jù)已觀測屬性值的平均值代替缺失值,但是均值插補沒有考慮到樣本不同屬性之間的聯(lián)系并且可能會改變數(shù)據(jù)的分布。K近鄰插補(K-nearest neighbors imputation, KNNI)[10],主要根據(jù)數(shù)據(jù)中缺失樣本的完整變量找出與其距離最近的K個樣本,然后利用距離函數(shù)分別計算這K個樣本與該樣本的距離加權(quán)這K個樣本對應(yīng)不完整樣本的缺失項得出估計值。FCM 插補(FCMI,fuzzy c-means imputation,)[11]是首先對數(shù)據(jù)集用FCM聚類,然后用聚類后的類中心和隸屬度來估計不完整樣本的缺失值。多值插補方法,也就是為缺失值提供多個版本的估計值來表征估計值的不精確性。最早提出的多重插補方法[12]是對缺失數(shù)據(jù)集插補m次(m>1),每次插補后得到一個完整的數(shù)據(jù)集,最終可以得到m個完整的數(shù)據(jù)集,接著對這m個完整數(shù)據(jù)集進行分析,綜合這m次插補結(jié)果,做出統(tǒng)計推斷。一種基于隨機森林的多值插補方法[13]是通過構(gòu)造大量的回歸樹與隨機樹來給缺失值提供多個版本的估計值。
傳統(tǒng)的基于插補的不完整數(shù)據(jù)分類方法會將待測樣本分配給確切的類別。然而由于數(shù)據(jù)的缺失,樣本的類別可能變得很模糊,而這些方法并沒有考慮到這種數(shù)據(jù)缺失對分類的影響。在這種情況下如果強硬的劃分樣本給某一單類,這會增加錯誤分類的風(fēng)險。在這種情況下,如何去表征數(shù)據(jù)缺失引起的不確定性是亟待解決的問題。
證據(jù)推理[14-19],是由Dempster在1967年最先提出的,后來由Shafer推廣并形成的理論,所以也稱為Dempster-Shafer理論。因為證據(jù)理論具有處理不精確和不確定信息的優(yōu)勢,因此廣泛應(yīng)用于數(shù)據(jù)分類、專家系統(tǒng)和信息融合等領(lǐng)域。文獻[20]提出了一種基于證據(jù)推理的不完整數(shù)據(jù)分類方法(PCC,Pototype-based credal classification)。PCC首先用不同類別的中心分別估計缺失值來表征估計值的不精確性,然后對帶有不同版本估計值的不完整樣本的分類結(jié)果折扣融合,最后將那些難以確切劃分類別的樣本分配到合適的復(fù)合類來表征由于缺失值引起的類別的不確定性。
本文提出了一種不完整數(shù)據(jù)智能分類方法,該方法依據(jù)不完整樣本近鄰中的類別信息自適應(yīng)的估計缺失值,也即采取單值插補與多值插補相結(jié)合的混合插補策略,并且在證據(jù)推理框架下,提出一種新的信任分類方法來合理的表征不完整樣本類別的不確定性,并有效地避免錯誤分類的風(fēng)險。
1 背景知識
1.1 K近鄰插補
K近鄰插補是用不完整數(shù)據(jù)的已知屬性在完整數(shù)據(jù)中找到K個近鄰,然后用它們估計不完整數(shù)據(jù)對應(yīng)的缺失值。假設(shè)測試樣本集X={x1,x2,...,xn}利用訓(xùn)練樣本集Y={y1,y2,...,yn}在類別識別框架Ω={w1,w2...,wc}下進行分類,其中xi是測試樣本集中的第i個樣本。目標xi已知T個屬性值。首先,利用xi已知屬性計算它與訓(xùn)練集Y中的每一個樣本yi(1,2,...,n)之間的歐氏距離,距離公式如下:
(1)

(2)
由此,我們可以得到,距離xi越近的近鄰所占的權(quán)重越大。最后對xi缺失值對應(yīng)的K近鄰的已知屬性值加權(quán)求和,得到的結(jié)果即為xi的估計值。
1.2 信任函數(shù)的理論基礎(chǔ)
信任函數(shù)是由Shafer在其獨創(chuàng)的數(shù)學(xué)證據(jù)理論中引入的,該理論也被稱為證據(jù)理論 (evidence theory),簡稱DST。該理論已經(jīng)在信息融合、模式識別以及決策分析等領(lǐng)域得到了廣泛應(yīng)用。
假設(shè)Ω是一個識別框架,或稱為假設(shè)空間。在證據(jù)推理中,識別框架從Ω={ω1,ω2,...ωc}擴展到冪集2Ω,其包含了Ω所有的子集。一個證據(jù)的基本信任分配(BBA, basic belief assignment),指從冪集2Ω到[0,1]上的一個映射函數(shù)m(.):2Ω→[0,1](又稱為基本信任函數(shù)或者mass函數(shù)),并滿足以下條件:
(3)
如果m(A)>0,則稱A為焦元。如果m(A)=max(m(·)),則稱A為主焦元。
設(shè)在識別框架上有兩個獨立證據(jù)B和C,它們的mass函數(shù)分別為m1,m2的Dempster合成規(guī)則為:
(4)
其中:K為歸一化常數(shù)即矛盾因子:
(5)
由于滿足交換律和結(jié)合律,即可推廣到n個互相獨立的證據(jù),Dempster合成結(jié)果為:
(m1⊕m2⊕...⊕mn)(A)=
(6)
其中:
(7)
盡管證據(jù)理論在解決不確定性的問題方面具有一定優(yōu)勢,但是在實際應(yīng)用中,Dempster組合規(guī)則不適用于高沖突證據(jù),在這種情況下常常會得出與常識相悖的結(jié)論。為此,許多學(xué)者提出了改進的組合規(guī)則。大致分為兩種:1)改進組合規(guī)則;2)融合前對證據(jù)進行修改。在改進規(guī)則中,一般認為不合理融合結(jié)果主要由于DS規(guī)則對高沖突信息的分配不當(dāng)造成的,針對此一些學(xué)者提出了改變沖突信息分配方式來改進規(guī)則。在證據(jù)修改方法中,一般認為高沖突證據(jù)在融合過程中每個證據(jù)的權(quán)重是不一樣的,要先對證據(jù)加權(quán)處理,然后再融合。
2 不完整數(shù)據(jù)智能分類算法
針對不完整數(shù)據(jù)分類問題,本文提出了一種不完整數(shù)據(jù)智能分類方法。它主要包含3個步驟:1)自適應(yīng)插補;2)折扣分類結(jié)果;3)全局融合。
2.1 自適應(yīng)插補
假定訓(xùn)練集為Y={y1,...,ym},共包含了c個類別,并且訓(xùn)練樣本都是完整的;測試集X={x1,...,xn},并且測試樣本都存在缺失值。用缺失樣本xi(i=1,...,n)的T個已知屬性在訓(xùn)練集中尋找K近鄰。首先計算xi與每一個測試樣本yj(j=1,...,m)之間的歐式距離,如下所示:
(8)
其中:xia和yja和分別表示測試樣本xi和訓(xùn)練樣本yi的第a個屬性。計算得出m個距離值,對這m個距離從小到大排序,其中最小的K個距離對應(yīng)的K個樣本{y1,...,yk,...,yK}即為xi的K近鄰。這K個近鄰可能來自于p(1≤p≤c)個類別{ω1,...,ωg,...,ωp}。當(dāng)p=1時,也即近鄰都來自于同一個類,在這種情況下樣本xi就有很大的可能屬于這個類,那么就用這些近鄰插補xi得到一個精確的估計值。當(dāng)p>1時,也即近鄰都來自于多個類,說明樣本的數(shù)據(jù)缺失導(dǎo)致它的類別變得很模糊,為了降低這種數(shù)據(jù)缺失帶來的不確定性的影響,在這種情況下我們采取多值估計策略,用這不同類別的近鄰分別估計xi的缺失值。
此外,由于每個近鄰與不完整樣本間的距離不同,因此對估計缺失值的貢獻也就不同,也即距離不完整樣本越近的近鄰在估計缺失值時的比重應(yīng)該越大。對于不完整樣本xi來說,我們用它的K近鄰中屬于類的近鄰來估計缺失值,那么用這些近鄰估計缺失值ωg(g=1,...,p)時的權(quán)重計算如下所示:
(9)

(10)

對樣本xi估計的p個版本用用標準分類器分類。然而,不同版本估計值的準確性是不同的,這會導(dǎo)致其分類結(jié)果的可靠性不同。
2.2 折扣分類結(jié)果

(11)
如果p=1,也即樣本xi的K近鄰均來自同一個類別,那么帶有唯一估計值的不完整樣本就會得到特定的分類結(jié)果,在這種情況下,樣本xi分配給結(jié)果中支持所屬類別概率最大的那一類。
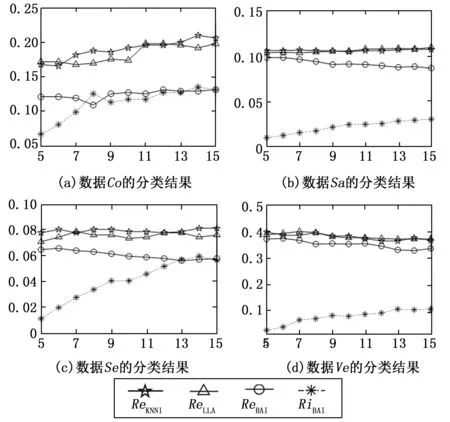
如果1 (12) 其中: (13) (14) (15) 基于可靠性的折扣規(guī)則通過修改證據(jù)能夠有效地降低證據(jù)間的沖突,在這種情況下就可以用DS直接融合這些折扣后的證據(jù)。然而,由于數(shù)據(jù)缺失會帶來不完整樣本類別的不精確性,為了表征這種不精確性并且降低錯誤分類的風(fēng)險,本文提出一種新的全局融合策略。 這p個分類結(jié)果可能將樣本目標分給不同的類別。由于折扣后的分類結(jié)果只有單類和由整個辨識框架表示的完全未知類,也即每個表示分類結(jié)果的BBA中只有單焦元和完全未知焦元。為此我們要確定樣本目標xi最有可能屬于的復(fù)合類。假設(shè)這p個分類結(jié)果支持樣本xi屬于q個不同的類{ω1,...,ωr,...,ωq},那么根據(jù)這些分類結(jié)果所屬類別將它們劃分成q個不同的群組。對于樣本目標xi來說,假定有s個分類結(jié)果支持它屬于ωr,然后定義如下函數(shù)來計算支持樣本xi分別屬于這q個類最大的m(.)值。 mi(ωr)=max{mi1(ωr),...,mis(ωr)},r=1,...,q (16) 然后通過下式計算得到擁有最大信任值支持樣本xi屬于的那個類ωmax。 (17) 接著通過下式找到樣本xi最有可能屬于的復(fù)合類中的單類。 Λi={ωmax∪ωr|mi(ωmax)-mi(ωr)≤α} (18) 最后,在DS融合的基礎(chǔ)上,定義如下規(guī)則融合這多個版本的分類結(jié)果,如下所示: mi(A)= (19) 其中: (20) 其中:α為控制不精確率的參數(shù),α越大,就會計算越多的復(fù)合類,從而會增加分類結(jié)果中的不精確性,但同時也會有效降低錯誤分類的風(fēng)險。在實際應(yīng)用中,α可以根據(jù)可接受的不精確率來選擇,本文默認為α=0.3。在實際應(yīng)用中,對于分配到復(fù)合類中的樣本,可以根據(jù)其他的信息來進一步的準確劃分它們的類別。 為了清楚直觀地表示算法的基本原理,我們繪制了算法的流程,如圖1所示。 圖1 本文方法算法流程圖 本文從UCI數(shù)據(jù)庫(http://archive.ics.uci.edu/ml)選取了7個標準數(shù)據(jù)集進行測試。Ecoli(Ec)是關(guān)于蛋白質(zhì)定位的數(shù)據(jù)集,Yeast (Ye)為預(yù)測蛋白質(zhì)細胞定位位置數(shù)據(jù)集,Vehicle (Ve)是關(guān)于車輛輪廓特征的數(shù)據(jù)集,Wifi (Wi)是無線數(shù)據(jù)定位數(shù)據(jù)集,Satimage (Sa)數(shù)據(jù)集是關(guān)于衛(wèi)星圖像的像素值,Segment (Se)是一個圖像分割數(shù)據(jù)集,Connectionist (Co)是一個關(guān)于英式元音識別數(shù)據(jù)集。這些數(shù)據(jù)的類別在3~11類之間,屬性個數(shù)在7~36之間,樣本數(shù)在255~6 435之間,因此這些數(shù)據(jù)是UCI數(shù)據(jù)庫中比較有代表性的數(shù)據(jù),這樣也能夠更加全面并充分地驗證不同算法在處理不同類型數(shù)據(jù)集性能。這些數(shù)據(jù)的基本信息,包括數(shù)據(jù)集的名稱和簡寫、類別數(shù)、屬性數(shù)以及樣本數(shù),如表1所示。 表1 數(shù)據(jù)集基本信息 本文方法用以上的真實數(shù)據(jù)集分別與KNNI[10]、FCMI[11]、LLA[18]、PCC[19]算法進行對比分析。同時采用了K-NN、EK-NN和決策樹DT三種標準分類器進行實驗。在本文方法算法中設(shè)置不精確率的閾值α=0.3,近鄰數(shù)K=11。 實驗中,我們隨機選取每個數(shù)據(jù)集的一半數(shù)據(jù)作為訓(xùn)練集,另一半數(shù)據(jù)作為測試集,然后對測試集進行隨機缺失處理(MCAR)。每個測試樣本有γ個缺失屬性值,隨機分布在樣本的各個屬性上。實驗以分類器在測試集上的最終分類誤分率Re和不精確率Ri作為評價標準,Re=Ne/N,Ri=Ni/N,其中N表示樣本數(shù)量,Ne表示錯誤分類的樣本數(shù)量,Ni表示分配到復(fù)合類的樣本數(shù)量。Re是用于評估分類結(jié)果中錯誤分類樣本所占比重,Re值越小說明誤分的樣本越少,算法性能越好。Ri是用于評估分類結(jié)果中劃分到復(fù)合類的樣本所占比重,該值越大,說明劃分到復(fù)合類中樣本越多,這樣并不利于決策,因此根據(jù)具體實際應(yīng)用的要求,該值應(yīng)在一個可接受范圍內(nèi)。 不同方法用K-NN分類器分類后的結(jié)果如表2所示。由于傳統(tǒng)的概率框架下的方法KNNI、FCMI和LLA得到的是確切的類別輸出,因此只有錯誤率,而PCC和本文方法在證據(jù)框架下能得到不精確輸出表征不確定性,因此存在有不精確率。從實驗結(jié)果可以看出,本文方法得到了比KNNI、 FCMI、 LLA和PCC更低的誤分率。當(dāng)每個測試樣本中缺失值的個數(shù) (γ) 增加時,所有分類器的錯誤率也會增加,這是由于數(shù)據(jù)缺失會影響分類的性能,缺失的數(shù)據(jù)越多,分類性能也就越差。在本文方法中,一部分難以劃分類別的樣本被分配到復(fù)合類中,這能夠表征缺失值引起的類別的不確定性,同時這種謹慎的決策方式能夠有效降低錯誤分類的風(fēng)險。 表2 不同算法用K-NN的分類結(jié)果 由于本文方法以及對比方法都是基于插補的不完整數(shù)據(jù)分類方法,也即先補全缺失數(shù)據(jù),再用能夠分類完整樣本的基礎(chǔ)分類器分類。為了研究使用不同分類器情況下不同方法的性能,這里分別使用EK-NN和DT作為基礎(chǔ)分類器分類不同數(shù)據(jù)集,實驗結(jié)果如表3和表4所示。從實驗結(jié)果可以看出,使用EK-NN分類器相較于使用其他兩種分類器的分類結(jié)果更優(yōu),當(dāng)然這主要由分類器本身的分類性能決定的。當(dāng)然,雖然使用不同分類器得到的分類結(jié)果不同,但是本文方法在使用不同分類器情況下的整體分類性能要優(yōu)于其他方法。根據(jù)實驗結(jié)果,在實際應(yīng)用中,本文方法在執(zhí)行過程中推薦使用EK-NN或者K-NN分類器。 表3 不同算法用EK-NN的分類結(jié)果 表4 不同算法用DT的分類結(jié)果 本文算法主要有兩個參數(shù):K和α。其中K用于表示用于估計缺失值的近鄰個數(shù);α用于判別本文算法中待測不完整樣本是否會被劃分到復(fù)合類的閾值,因此它也能夠用于調(diào)節(jié)本文算法中錯誤率和不精確率。本小節(jié)主要是通過實驗研究這兩個參數(shù)對本文算法以及其他方法的影響。 3.3.1K值的影響 由于這些對比方法中只有KNNI、LLA以及本文方法存在該參數(shù),因此這里選擇部分有代表性的數(shù)據(jù)集來測試K值對這些算法性能的影響。如圖2所示,X軸表示分類器K的個數(shù)從5~15,Y軸表示KNNI、LLA和本文方法算法不同分類器錯誤率和不精確率。從圖中可以看到,與其他方法相比,本文方法的錯誤率更低,并且不精確率也在可接受的范圍內(nèi)。可以看到,隨著K值的改變,不同方法的分類結(jié)果有所變化。本文方法受K值的影響比較小,這也證實了本文方法對于K值的選擇具有一定的魯棒性。 圖2 選擇不同的K值時不同方法的分類結(jié)果 3.3.2 閾值α的影響 由于閾值α只存在于本文方法中,因此這里選擇兩個代表性的數(shù)據(jù)來研究閾值α對本文方法的影響,圖3顯示的是閾值α取不同值時本文方法的分類正確率和不精確率,其中X軸表示α的不同取值,Y軸表示本文方法的錯誤率和不精確率。從圖中可以看到隨著α值的增大,錯誤率在降低的同時不精確率在逐漸升高。α的值過小會導(dǎo)致很多樣本被錯誤分類。當(dāng)然,α的值并不是越大越好,因為這樣會使大量樣本分配到復(fù)合類,這并不利于決策分析。在實際應(yīng)用中,α可以根據(jù)可接受的不精確率取值。 圖3 選擇不同閾值α?xí)r本文方法的分類結(jié)果 本文提出了一種不完整數(shù)據(jù)智能分類算法,該方法通過自適應(yīng)插補來提高估計精度,同時在證據(jù)推理框架下將難以劃分類別的不完整樣本分配到相應(yīng)的復(fù)合類,這樣能夠有效地表征缺失值帶來的不確定性,同時降低錯誤分類的風(fēng)險。雖然實驗結(jié)果證實了本文方法分類不完整數(shù)據(jù)的有效性,但是本文方法的插補是基于K近鄰的,這需要大量的計算,在未來的工作中會考慮研究一種快速的K近鄰插補技術(shù),在保證估計精度的同時降低算法計算K近鄰所產(chǎn)生的計算量。
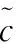
2.3 全局融合


3 實驗及結(jié)果分析
3.1 數(shù)據(jù)集
3.2 對比實驗



3.3 算法參數(shù)對分類性能的影響

4 結(jié)束語
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
