基于BERT模型的中醫文本分類研究
2021-11-08 13:26:59王培王亞文盧苗苗
電腦知識與技術 2021年27期
關鍵詞:深度學習
王培 王亞文 盧苗苗

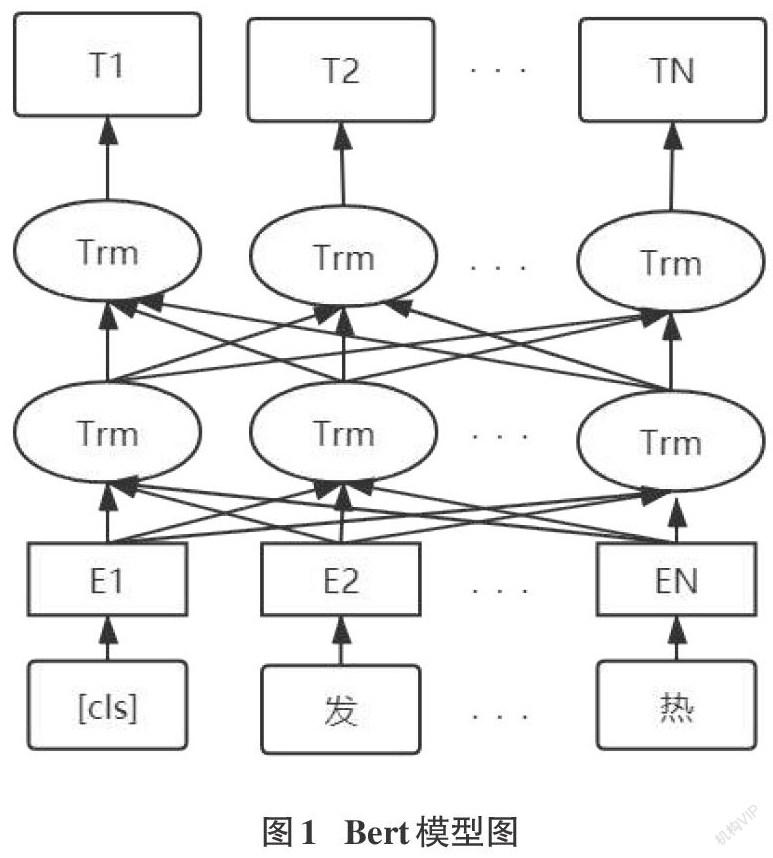
摘要:文本分類是自然語言領域一個重要的研究方向和技術核心,一直受到研究者的熱切關注。在醫學領域,中醫源遠流長,在人類歷史發展中發揮著不可磨滅的作用。中醫語言包含了大量中醫領域術語,且多為表述嚴謹和富含辯證思維的古文,上下文詞語關聯性較強,且大多是結構化、半結構化或非結構化數據的形式,這些特點給中醫病案的智能分析分類造成了很大地困難。該文基于注意力機制的深度學習模型Bert模型實現中醫深層全局語義的特征表示,并進行中醫臨床文本的分類研究。最后通過對中醫臨床文本分類實驗的驗證,該模型達到了非常可觀的分類效果。
關鍵詞:文本分類;深度學習;中醫文本;注意力機制
中圖分類號:TP311? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2021)27-0013-02
Abstract: Text classification is an important research direction and technical core in the field of natural language, and it has always received eager attention from researchers. In the field of medicine, Chinese medicine has a long history and has played an indelible role in the development of human history. The language of Chinese medicine contains a large number of terms in the field of Chinese medicine, and most of them are ancient texts with rigorous expressions and rich dialectical thinking. The contextual words are strongly related, and most of them are in the form of structured, semi-structured or unstructured data. These characteristics give Chinese medicine The intelligent analysis and classification of medical records caused great difficulties. In this paper, the Bert model, a deep learning model based on the attention mechanism, realizes the feature representation of the deep global semantics of TCM, and conducts the classification research of TCM clinical text. Finally, through the verification of the TCM clinical text classification experiment, the model achieved a very considerable classification effect.
Key words: text categorization; deep learning; TCM text; attention mechanism
1 引言
文本分類是按照一定的分類規則對文本進行自動劃分類別的過程,在很多領域它都有著非常廣泛的應用場景[1]。文本分類分為基于傳統機器學習的文本分類和基于深度學習的文本分類。文本分類的核心是文本的處理分類,它有著非常廣的應用前景。
在中醫領域對于文本分類技術的使用和探索從未停止,常被用于中醫藥文本分類、中醫方劑相似度計算等多項任務之中。中醫是以古時候的“天人合一”為指導思想,以陰陽五行理論為工具,研究人體生命變化規律的一門學問[2]。中醫臨床文本承載了名老中醫的臨床經驗,也是為病人臨床決策的重要依據。中醫臨床文本的正確分類對于中醫的蓬勃發展有著重要的意義。本文使用Bert模型對中醫臨床文本進行文本分類研究,該模型的向量表示會隨著上下文的不同而變動,解決了傳統詞向量無法處理的一詞多義的問題。通過Bert預訓練模型可以生成融合中醫深層全局語義的特征表示,并且進行中醫臨床文本的分類工作,最后輸出分類的結果。
2相關研究
文本分類屬于人工智能技術領域,是自然處理領域一個重要的應用,也是文本處理中一個很重要的模塊。文本分類算法的研究就從未停止,在中醫領域的研究者也進行了深入的研究。
顧錚等人[3]將文本分類相關技術運用到中醫方劑相似度的計算上,為中醫藥研究開辟了新的發展道路。王華珍等人[4]使用傳統分類算法針對數據庫中疾病和癥狀的相關知識進行文本挖掘研究,并在此基礎上構建智能診療模型用于智能證型的分類,該模型為中醫輔助診療決策提供了支持。付釗等人[5]研究了基于語義分塊的中醫病情分類問題,實現基于TF-IDF特征的隨機森林病情分類模型和SVM病情分類模型。陳廣等人[6]研究基于關鍵語義信息的中醫腎病病情文本分類問題,使用N-Grams片段的信息熵和關鍵詞提取算法以及文本關鍵語義信息提取方法應用到中醫腎病病情文本分類上。
3 研究方法
語言模型的研究經歷了one-hot、Word2vec、ELMO、GPT再到Bert模型。Word2vec模型訓練出來的詞向量屬于靜態的詞向量,無法表示一詞多義。GPT屬于單向語言模型,無法獲取一個字或者詞的上下文。ELMO為一詞多義提供了一個很好的解決方案,會考慮更多的文本信息,基于給定的上下文動態的生成每個詞的嵌入。Bert模型是綜合ELMO和GPT兩者的優勢,是一個多層雙向Transformer編碼器語言模型,Transformer可以并行訓練所有的字,不僅計算效率很快,而且通過位置嵌入,模型的語言順序的理解能力也比較好。BERT模型具有很多特點:真正的雙向、解決一詞多義、并行運算、泛化能力強等。Bert是一個兩階段模型:第一階段雙向語言模型預訓練,預訓練過程中,可以學習到每個詞對應的上下文信息。第二階段針對具體的任務進行fine-tine模型,使其學到新特征,因此可以在具體任務上打造一個比較好的效果。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
