基于圖像LBP特征與Adaboost分類器的垃圾分揀識別方法*
2021-11-15 02:41:52陳昱辰曾令超張秀妹鐘廣澤
南方農機 2021年21期
陳昱辰 , 曾令超 , 張秀妹 , 鐘廣澤
(廣東白云學院,廣東 廣州 510450)
0 引言
隨著人們生活水平的提高,對于生活垃圾的有效處理和相關高價值廢品的回收再利用,已日益成為社會關注的焦點。目前,生活垃圾多由環衛工人手動分揀,工作強度大、效率低而且嚴重危害環衛工人身體健康[1]。雖然有用于分類的垃圾回收裝置,但是要求丟棄者進行預分類且相關人員需具有很高的環保分類知識,垃圾分類在社會上推廣受到一定的限制。
在垃圾識別和圖像分類方面,學者們進行了大量的研究。吳健等[2]利用顏色和紋理特征,初步完成了垃圾分類,但由于不同數據集的圖像背景、尺寸、質量不盡相同,傳統算法需要根據相應數據人工提取不同的特征,算法的魯棒性較差,并且處理方式復雜,所需時間較長,無法達到實時分類的效果。在非公開數據集方面,Mittal等[3]利用2 561張的垃圾圖片數據集GINI,使用GarbNet模型,得到了87.69%的準確率。不過由于相同類別垃圾的特征表征差異性較大,不僅增加了樣本的收集量,還無法確保準確率。莫卓亞等[4]通過圖片的采集、模型的訓練,初步實現了垃圾分類的識別。然而由于模型對預測圖片明暗色彩過度依賴,導致不同場景的圖片有些識別效果好,有些識別效果差。
針對目前垃圾識別和圖像分類精準度、效率上存在的不足,課題組設計了基于LBP特征的級聯分類器對果皮和有害垃圾進行識別,這種基于LBP特征的級聯分類器具有識別精度、效率較高的特點[5],并采用紋理描述算法對果皮和有害垃圾特征進行提取的方法[6],最終實現對果皮和有害垃圾快速取樣識別。
1 基于LBP特征的級聯分類器模型分析
1.1 基于LBP圖像的編碼
LBP編碼算法是常見的紋理描述符算法[7],它根據圖像的n×n鄰域中,中心位置的像素值為閾值,將圖像的像素值轉換成一個二進制數字。例如,在3×3的鄰域中,編碼后的像素值是根據閾值(對應的原像素值)以及其相鄰的8個像素值決定的。編碼前需要將3×3區域的rgb像素值轉化為灰度值,并將其與相鄰點灰度值進行比較,如果大于閾值為0,否則為1,最終得到由0和1組成的集合,最后沿圓周順時針追蹤像素,得到一個8位數的二進制值,作為該點的像素值。
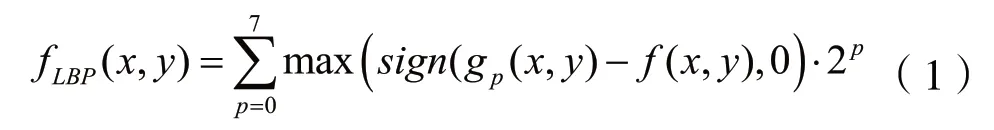
其中,fLBP(x,y)為編碼后圖像的f(x,y)的灰度值,滿足0≤fLBP(x,y)≤255;f(x,y)為編碼前圖像的(x,y)的灰度值。gp(x,y)與f(x,y)對應關系如表1所示。

表1 gp(x,y)與f(x,y)對應關系
1.2 Adaboost強分類器訓練
輸入的樣本數為m,定義果皮樣本的輸出為1,有害垃圾等其他樣本輸出為-1,輸出結果集合為{-1,1}。訓練弱分類器前,初始化各樣本集得到權重系數集合為:
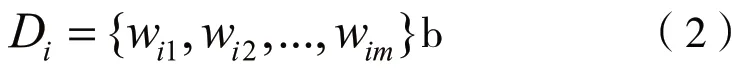
其中,wij為第i級弱分類器的第j個樣本的權重系數,wij滿足
利用決策樹算法,將帶權重的圖像提取的LBP灰度特征與分類器的特征進行逐個比較,得到弱分類器hi(x)。由于LBP紋理特征計算涉及指數運算,本研究采用的誤差計算方法是指數誤差計算,得到第i級分類器的誤差率ei滿足:
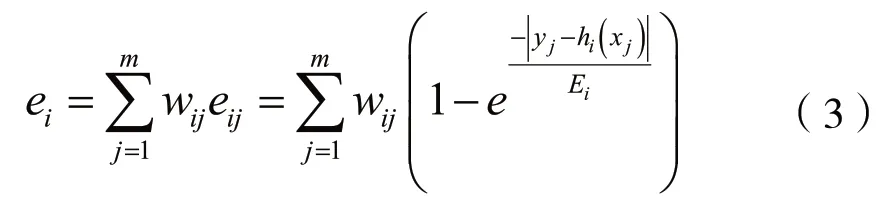
其中,yj為第j個樣本的實際分類值(1或-1)。hi(xi)為第i級弱分類器對第j張圖片計算得到的預測值,Ei為第i級弱分類器的最大誤差,滿足:
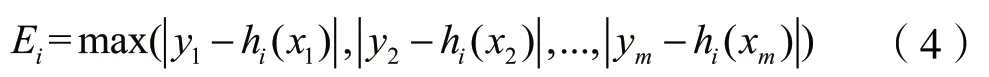
計算第i級弱分類器的學習率權重系數αi,誤差越大,學習的權重越大:

根據學習率權重系數αi更新下一級弱分類器各樣本的權重系數wij,滿足:
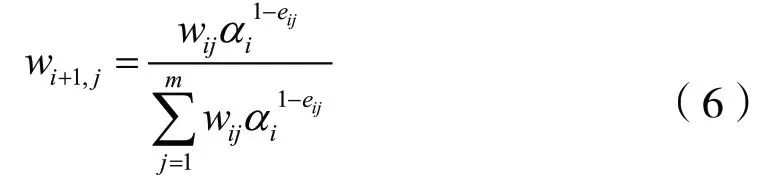
對前i級的分類器進行加權平均,得到弱分類器組成的強分類器識別模型[8-10]Hi(x):

Adaboost的強分類器訓練模型如圖1所示。
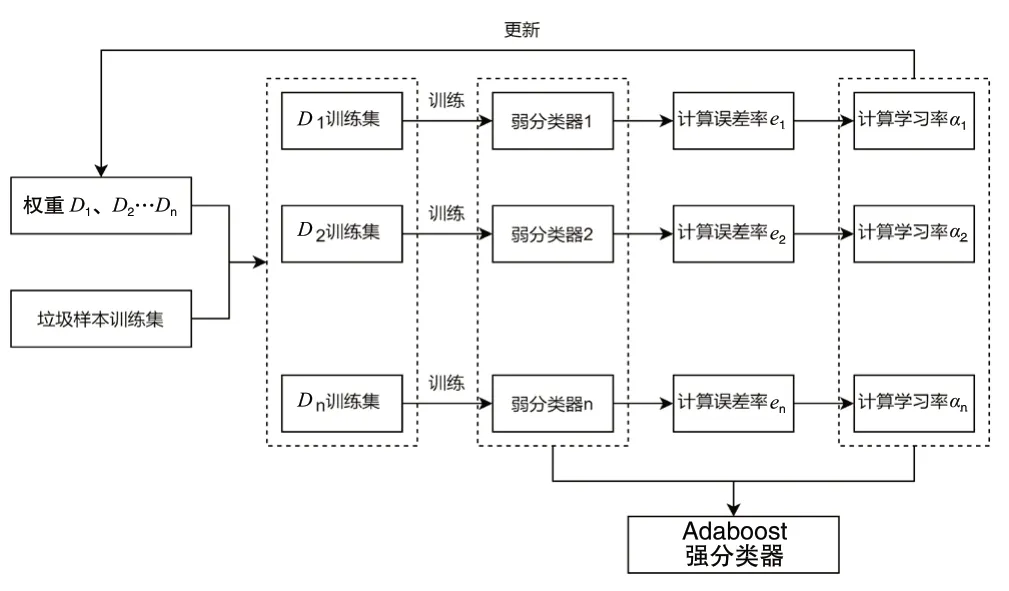
圖1 Adaboost的強分類器訓練模型
1.3 果皮和有害垃圾識別模型訓練
針對果皮和有害垃圾的小樣本數據集進行分類器訓練,先對這兩類垃圾進行分類標定,果皮樣本作為正樣本,有害垃圾等其他樣本作為負樣本,并對正樣本進行圖像尺寸變換為100×100。然后,初始化分類器參數,負樣本進行隨機裁切后,對所有樣本進行LBP特征值計算,迭代訓練i級弱分類器,一旦超過用戶設定的最大級數nS或者前i級組成的強分類器識別模型小于用戶設定的最小報警率FA,訓練完成。
算法流程圖如圖2所示。
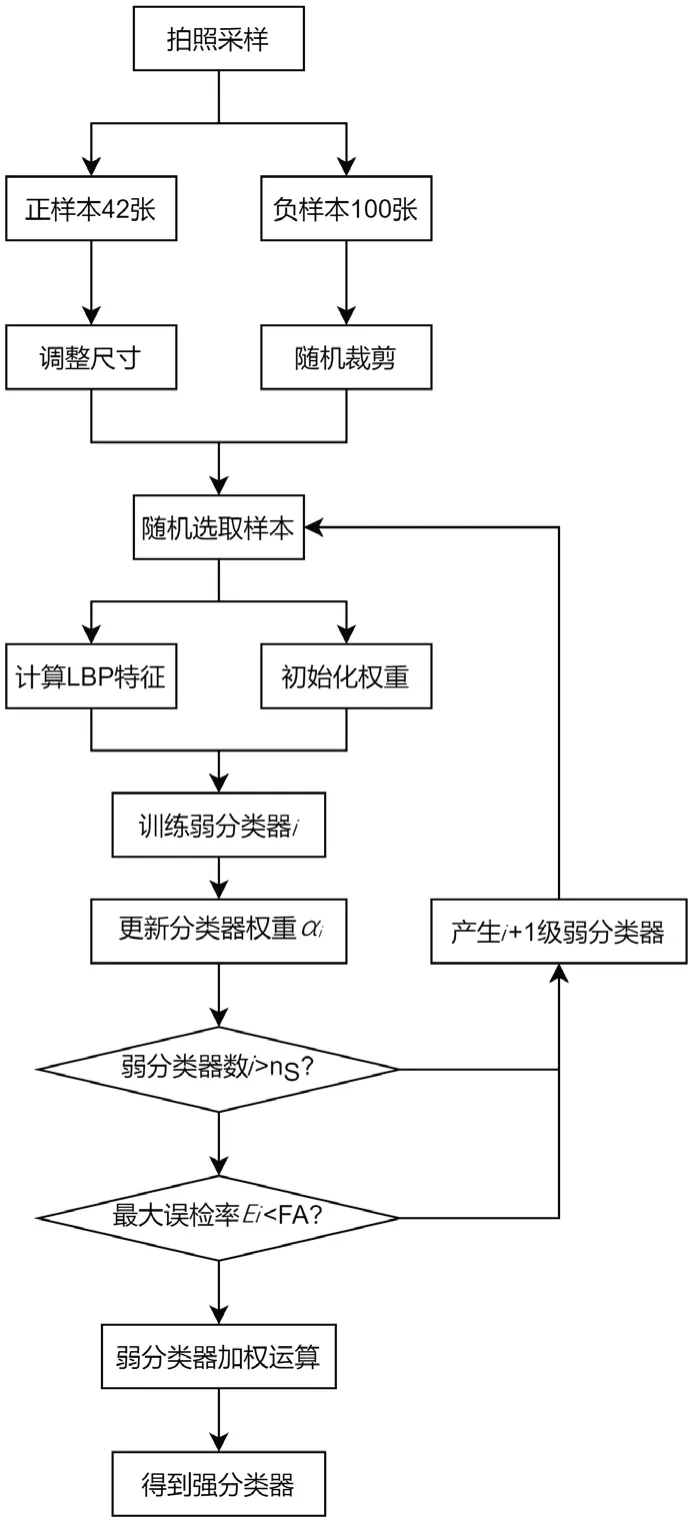
圖2 算法流程圖
主要算法流程如下:
1)輸入果皮和有害垃圾樣本。隨機從果皮和有害垃圾圖像庫中抽取42張圖片,作為訓練正樣本集進行輸入。
2)預處理。對輸入果皮和有害垃圾訓練圖像進行尺度和灰度轉換至預訓練模型,規定輸入尺度大小。
3)建立果皮和有害垃圾識別模型。對LBP特征提取后的圖片樣本帶權重的輸入到Adaboost模型訓練,通過梯度下降法調整弱分類器的模型權重,并計算學習率權重,產生該級弱分類器的權重系數以及下一級訓練輸入至弱分類器模型的權重,直至滿足終止條件——級數超過設定值、總誤差率小于設定值。
4)模型測試。從果皮和有害垃圾圖像庫中抽取不同類型的果皮和有害垃圾圖片,作為測試原本集進行模型測試,以驗證模型的精確度。
2 結果與分析
對果皮和電池、廢燈管、殺蟲劑等有害垃圾進行了識別研究,以123張圖片作為訓練集,其余的作為測試集。
2.1 網絡模型訓練基本參數配置
模型訓練和測試硬件環境:Intel(R) Core(TM)i5-7300HQ CPU @ 2.5GHZ * 4處理器,16 G內存,NVIDIA GeForce GTX 1050Ti 顯卡加速圖像處理。軟件環境:操作系統為Windows 10 Pro,開發軟件為CLion 2019。具體訓練參數設置如表2所示。

表2 所有的級聯分類器LBP模型訓練參數設置
2.2 網絡模型訓練結果
訓練樣本大小為123,通過訓練層數得出由18級弱分類器加權得到的強分類器預測精確度最接近90%。網絡訓練參數曲線圖以及果皮和有害垃圾識別效果圖如圖3、圖4所示。
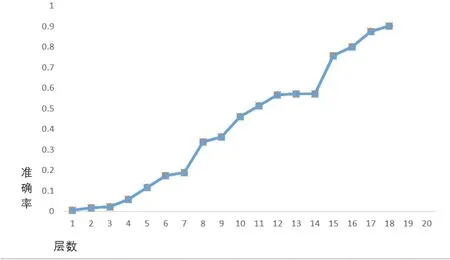
圖3 網絡訓練參數曲線圖

圖4 果皮和有害垃圾識別效果圖
2.3 模型測試結果
果皮和有害垃圾數據測試集共用了314張圖片,包括香蕉皮80幅、電池97幅、廢燈管30幅,殺蟲劑107幅,分別測試網絡模型,得出識別結果如表3所示。

表3 垃圾圖像識別結果
3 結論
1)提出了一種基于級聯分類器的LBP特征模型識別果皮和有害垃圾的方法,可提取果皮和有害垃圾的特征,避免了手工特征的設計和提取。
2)基于級聯分類器的LBP特征模型具有較高的識別精準度,能夠達到快速識別的目的。
3)操作簡單,具有較強的健壯性,能夠維持某些性能的特征。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
