基于改進詞性信息和ACBiLSTM的短文本分類
2021-12-14 01:28:34朱向其張忠林李林川馬海云
計算機應用與軟件 2021年12期
朱向其 張忠林* 李林川 馬海云
1(蘭州交通大學電子與信息工程學院 甘肅 蘭州 730070)2(天水師范學院電子信息與電氣工程學院 甘肅 天水 741001)
0 引 言
當今信息傳播主要還是依賴文本的形式,而短文本能夠傳達即時的信息,例如新聞標題、微博推送等。如何高效正確地分類中文短文本,一直受到廣泛的研究。
中文短文本分類最重要的問題是如何表示短文本,傳統的文本表示方法主要是基于詞袋模型[1],但該方法未考慮詞序和詞語之間的語義信息,導致分類效果不理想。針對這個問題,有學者從外部引入語料庫對文本進行特征擴展,進一步對人工標注好的短文本數據進行特征處理,豐富語義關系[2-3],但是該方法要求高質量的語料庫。另外Phan等[4]通過pLSA和LDA等[5-7]模型挖掘文本的語義信息,利用支持向量機(SVM)同時在主題特征空間上構建短文本的空間向量進行分類,獲得了較好的效果。雖然這些傳統的分類方法可以在一定程度上提高文本分類的效果,但針對中文短文本分類固有的特征稀疏、語義不足和維度過高等問題效果不佳。
深度學習已廣泛應用于自然語言處理領域。神經網絡語言模型(NNLM)是由Bengio等[8]在2003年率先提出,Mikolov等[9]對此模型做出改進,并提出基于神經網絡的Word2Vec模型。利用其生成的詞向量引入了語義特征,解決文本特征表達問題,但是該模型會存在多義詞的問題,不能區分多義詞的不同語義。艾倫研究所在NAACL 2018年發布的ELMo模型提供了一種簡潔的解決方案,根據當前上下文對詞向量進行動態調整解決這個問題,處理了句法和語義信息。同年谷歌提出BERT模型,使用了新型的特征抽取器(雙向Transformer)來增強特征提取和融合能力。
Kim[10]首次將卷積神經網絡(CNN)應用于句子模型的構建中,實現CNN應用到文本分類。CNN可以捕捉空間的局部特征,圖神經網絡(GCN)能夠捕捉全局詞的協同信息,由于都忽視時間相關性,會導致部分重要信息丟失。而循環神經網絡(RNN)可以讀取和操作任意長度的文本序列,并獲取長期依賴性。其變體長短時記憶神經網絡(LSTM)[11]和圖結構循環網絡(G-LSTM)可以記憶和訪問歷史信息,但是不會考慮未來下文的語法和語義。由此,雙向長短時記憶網絡[12](BiLSTM)被設計出來以獲取上下文信息。
近幾年,注意力機制被引入用來對向量賦予注意力權重突出關鍵信息。使用注意力機制可以更好地表達特征,使訓練出來的模型具有更高的精度,直觀地看出不同詞語的重要程度。
綜上所述,傳統的文本表示存在特征稀疏、語義不足、維度過高等問題,忽視了詞性的影響力。因此,本文提出一種基于改進詞性信息和ACBiLSTM的中文短文本分類模型。采用基于Transformer架構的BERT中文預訓練模型,即BERT-Base,Chinese模型動態訓練詞向量,同時結合改進的TF-IDF模型將得到的詞向量作為輸入層的輸入信息。由于本文的數據集都是中文短文本,為了突出與主題有關的信息,本文運用注意力機制結合CNN和BiLSTM,賦予關鍵詞語不同特征權重,減少文本中主要信息的遺失,優化最終的特征表達,使分類的準確度得到提升。
1 相關知識
1.1 BERT模型
BERT模型是谷歌公司2018年發布的一種語言表示模型,其基于Transformer架構,通過訓練Masked Language Model和預測下一句任務得到的模型。
1.2 卷積神經網絡
CNN是一種前饋型的神經網絡,它具有兩個非常顯著的特點,一是對局部感知較為明顯,二是權值共享。由于本文的短文本數據集簡短精悍,構造比較緊湊,在一定程度上可以釋義,使得CNN在提取文本的特征上能夠獲得較好的結果。CNN主要是由輸入層、卷積層和池化層組成,CNN結構如圖1所示。其中,將短文本的字詞映射到相應的詞向量空間作為輸入層,輸入的詞向量通過含有若干濾波器的卷積層,通過其卷積操作獲得不同位置的特征,然后這些不同位置的特征經過池化層,提取出最具有代表性的特征,最后輸入全連接層,求得不同類別的概率。
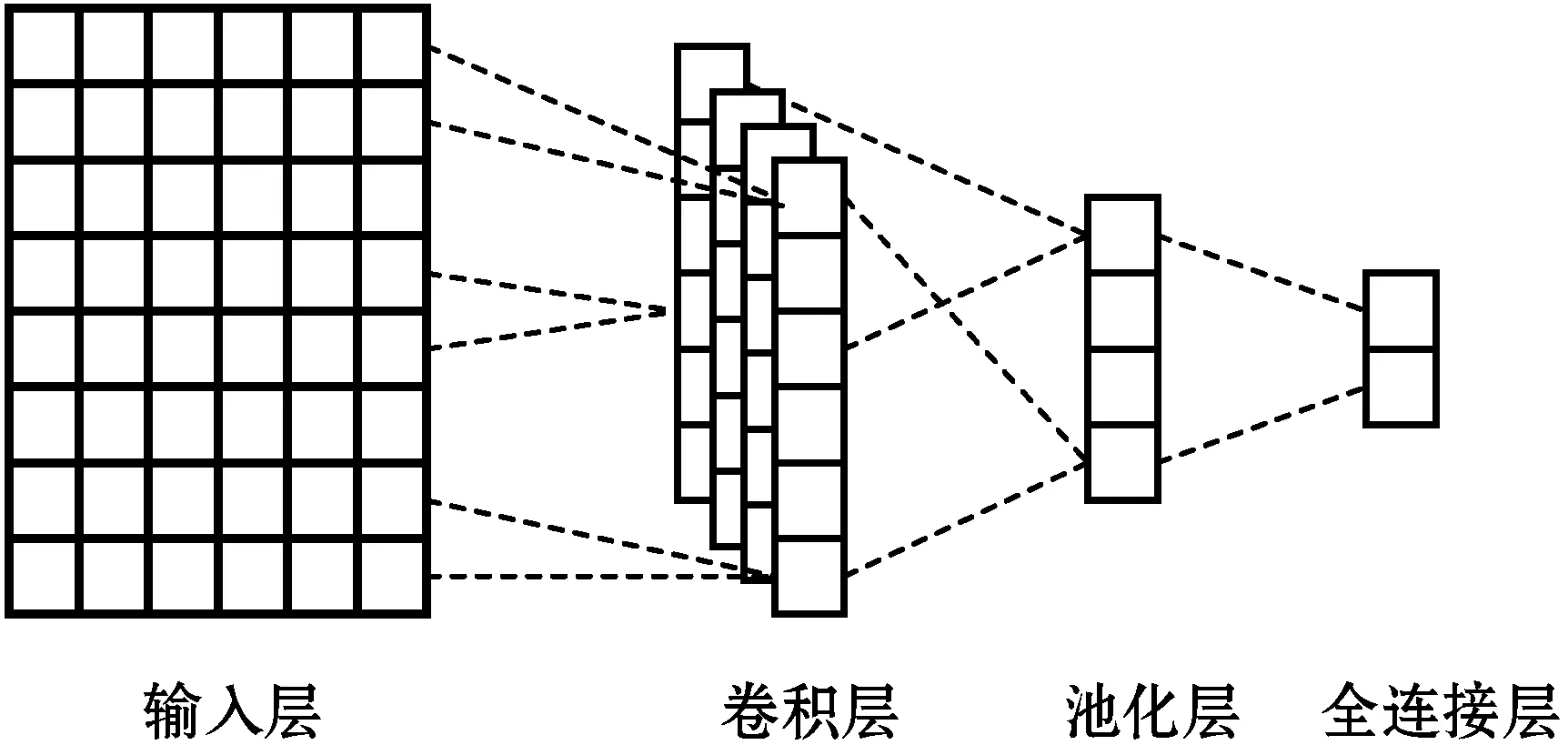
圖1 卷積神經網絡結構圖
1.3 循環神經網絡
循環神經網絡目前也廣泛應用,相比較CNN只能提取局部特征且不考慮時間的相關性,它對可變長度的輸入序列進行操作,同時捕捉單詞和上下文之間的語義聯系,獲得更廣泛的特征信息。但在實際的處理過程中,常常遇到梯度消失和梯度爆炸的現象,而長短時記憶神經網絡避免了這個結果,也能夠更方便地訪問和存儲信息。Cheng等[13]運用LSTM,對上下文的信息也進行了更好的分類。
1.4 注意力機制
注意力機制的主要作用是讓神經網絡把“注意力”放在一部分輸入上,即區分輸入的不同部分對輸出的影響。注意力機制主要涉及到Query、Key和Value三個概念,將目標字和上下文各個字的語義向量表示作為輸入,首先通過線性變換獲得目標字的Query向量表示、上下文各個字的Key向量表示及目標字與上下文各個字的原始Value表示,然后計算Query向量與各個Key向量的相似度作為權重,加權融合目標字的Value向量和各個上下文字的Value向量,作為Attention的輸出,即目標字的增強語義向量表示。其模型結構如圖2所示。
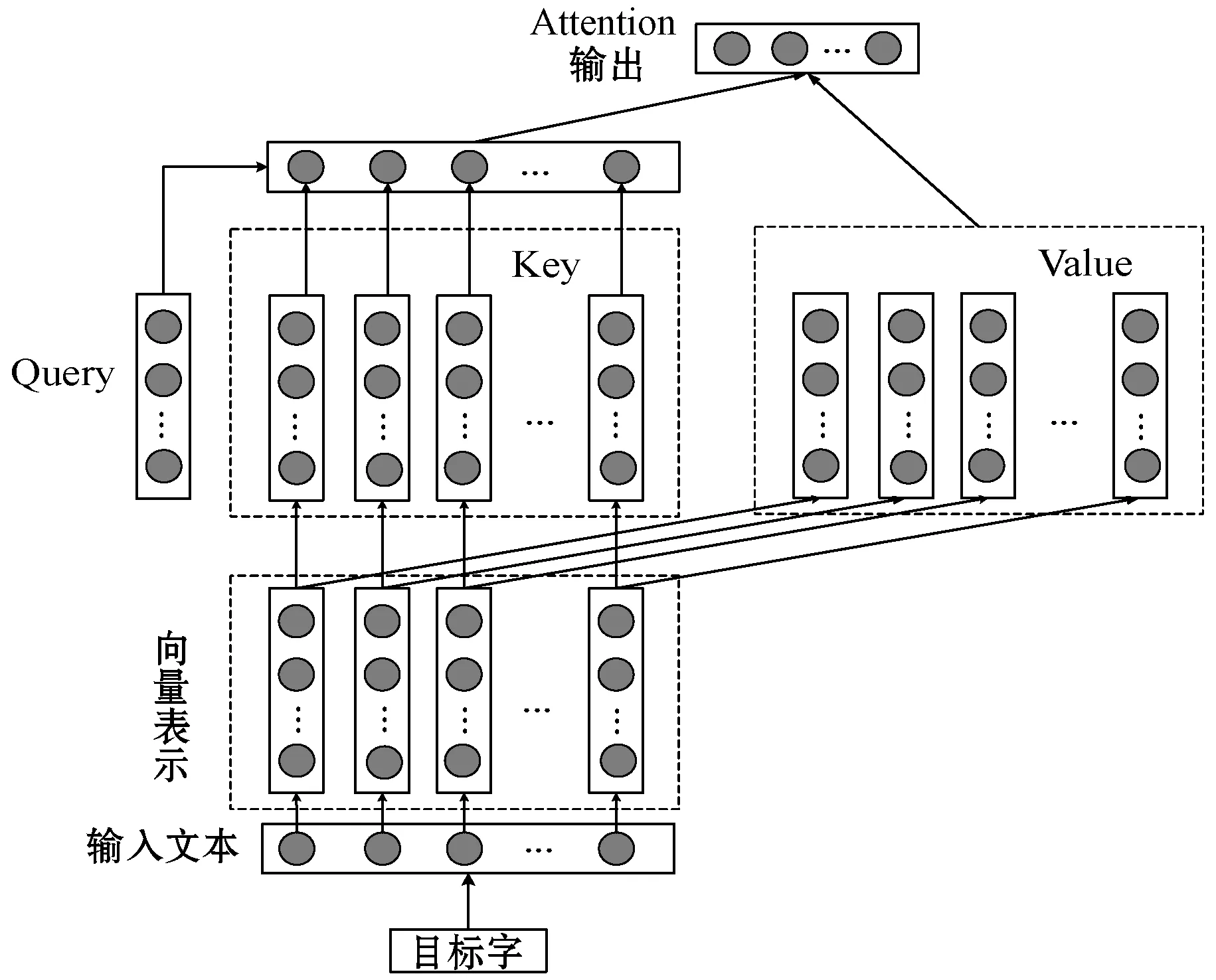
圖2 注意力機制模型結構
2 模型構建
本文構建的基于改進詞性信息和ACBiLSTM的中文短文本分類模型的結構如圖3所示,主要由詞向量輸入層、CNN卷積層、BiLSTM層、注意力層和Softmax分類層五個基本部分組成。這個模型通過對BERT模型預訓練得到的詞向量引入詞性因子進行改進,然后基于注意力機制結合CNN和BiLSTM來提取局部卷積特征和捕捉序列特征上的依賴關系來獲得中文短文本的最終特征向量。
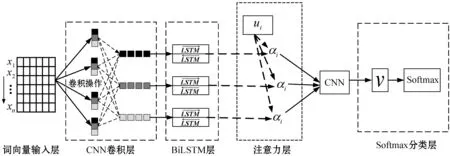
圖3 模型結構圖
2.1 詞向量輸入層
2.1.1文本預處理
未處理的中文短文本數據帶有部分的干擾項,比如一些標點符號和字符等,詞語的詞性信息也沒有標注出來,因此要在進行分類工作之前對數據集進行數據清洗。
本文使用Python中Jieba分詞模塊自帶的精確模式對數據集進行分詞,同時能夠將每個詞語對應的詞性標注出來,然后根據處理好的停用詞表(融合了哈爾濱工業大學停用詞表、四川大學機器智能實驗室停用詞表、百度停用詞表)對分詞之后的中文短文本數據進行去除停用詞操作,將無用的詞及一些特殊符號去除。
2.1.2BERT模型預訓練
本文使用的BERT模型由多層的雙向Transformer編碼器連接而成,其結構圖如圖4所示。其中:E表示詞向量嵌入Word Embedding;Trm表示Transformer Encoder,它是BERT模型的核心部分,可以理解為將輸入文本中各個字詞的語義向量轉化為相同長度的增強語義向量的一個黑盒;T表示輸出的單詞序列。
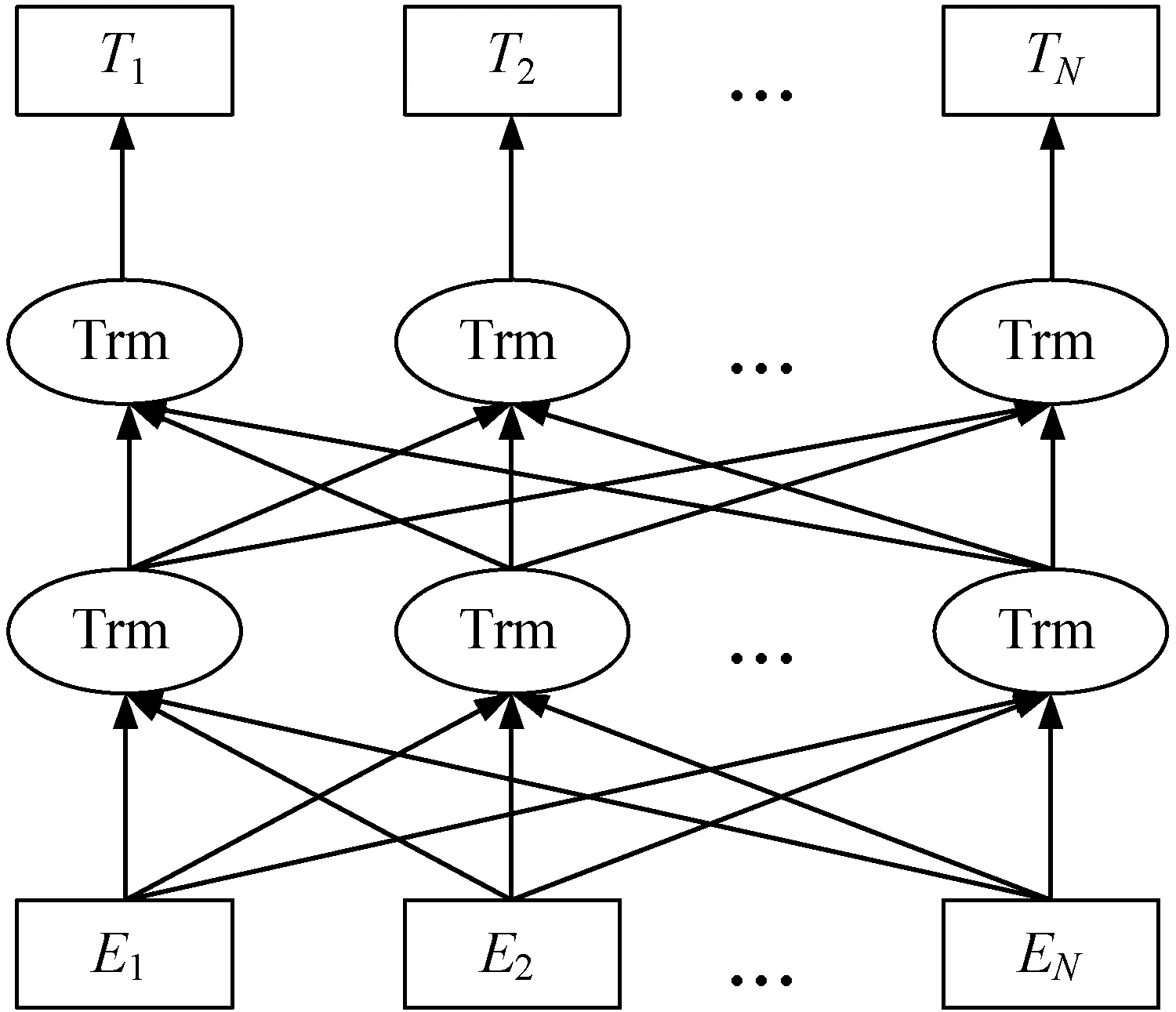
圖4 BERT模型結構圖
BERT模型的輸入包括三個部分。(1) 字向量。通過查詢字向量表將文本中的每個字轉化為一維向量。(2) 文本向量。該向量的取值在模型訓練過程中自動學習,用于刻畫文本的語義信息,并與字和詞語的語義信息融合。(3) 位置向量。由于出現在文本不同位置的字/詞所攜帶的語義信息存在差異(比如:“我愛你”和“你愛我”),BERT模型對不同位置的字/詞分別附加一個不同的向量以作區分。這三個部分的和作為BERT模型的輸入,輸出則是輸入字和詞語對應的融合語義信息后的向量表示。
2.1.3改進詞性信息
通過BERT模型預訓練得到詞向量存在著兩個問題,一是每個詞語對整個文本的重要程度沒有體現出來;二是在實現訓練的過程中,每個詞語作為被替換詞進行雙向編碼來動態調整的時候都受到上下文詞語的影響,因此每個詞語的屬性對訓練的影響也很重要。針對這兩個問題,本文分別提出了改進方法。
首先,構建一個基于TF-IDF的加權BERT模型結構,對詞向量進行權重計算,使得詞向量體現出當前詞語在整個文本中的重要程度,更好地體現詞語之間的語義信息。TF-IDF作為一種加權技術,經常被用來評價某一字詞對某一文件的重要性。詞頻TF和逆文檔頻率IDF組成了TF-IDF方法,其計算式為:
TF-IDF=TF×IDF
(1)
式中:TF表示某一確定詞語在所屬文件中出現的頻率;IDF衡量了一個詞語的常見程度。
其次,不同詞性的詞語具有不同的表征能力,黃賢英等[14]提出中文短文本主要依靠四種詞性來進行表達,即動詞、名詞、副詞和形容詞。在一個文本當中,動詞、名詞能夠主要反映出文本內容,對文本分類具有大的影響;形容詞和副詞的表達效果略差一籌,對文本分類的影響也稍低一些;其他詞性的詞語影響程度更小。而經典的TF-IDF計算方法并沒有體現詞語詞性的影響,文獻[15]考慮到了詞性的影響,但是對詞性的影響分配不夠合理。因此,本文決定根據詞語的不同詞性提供不同的詞性因子,并且對上述文獻的辦法進行改進,為詞性因子根據影響程度合理賦值,再與傳統的TF-IDF模型結合計算詞向量的權重。
改進之后的TF-IDF模型本文稱為ITF-IDF模型,其計算式為:
ITF-IDFt=TF-IDFt×θ

(2)
式中:t為當前分詞;θ為根據當前分詞的詞性提供的詞性因子;令α+β+γ=1,且γ<β<α∈[0,1]。
綜上所述,本文對BERT模型引入詞性因子進行改進,在訓練詞向量的基礎上結合詞性權重,得到改進詞性信息的詞向量作為輸入層的輸入。詞性信息加權的詞向量表達如下:
Wt=wt×ITF-IDFt
(3)
式中:wt代表BERT模型訓練的分詞t的詞向量;ITF-IDFt代表分詞t對應的詞性權重;Wt代表分詞t對應的改進加權詞向量,并將其作為詞向量輸入層的輸入進行分類。
2.2 基于注意力機制的ACBiLSTM模型
2.2.1結合CNN模型提取特征
對于輸入層的輸入信息,下一步還需要使用CNN模型對這些信息進行特征提取,本文使用一維卷積,假設xi∈Rd是句子中的第i個詞語的d維向量,句子x1:n=(x1,x2,…,xn)經過卷積層通過長度為k的濾波器進行卷積操作生成特征映射cj∈Rn-k+1,n表示句子長度。而對于句子中的每一個位置j,從詞語xi到xi+k-1會生成k個連續詞向量的特征cj,計算式表示為:
cj=f(W×xi:(i+k-1)+b)
(4)
式中:b∈R是一個偏置項;f(·)是一個非線性的激活函數。本文使用SeLU函數[20]作為激活函數,能夠預防梯度爆炸和梯度消失的現象,其公式如下:
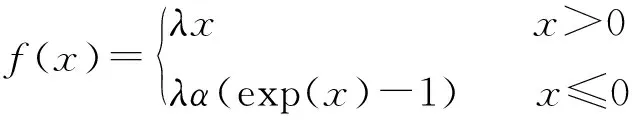
(5)
上述的每個特征映射進行列向量之間的連接得到整個句子的特征表達C為:
C=[c1,c2,…,cj]
(6)
有n個長度一樣的濾波器,會產生n個特征映射F,再將其重新排列為特征表達為:
F=[C1⊕C2⊕…⊕Cn]
(7)
式中:⊕表示列向量之間的連接;Ci是第i個濾波器生成的特征映射;F∈Rn-k+1中的每行Fj是在位置j使用n個濾波器的特征表達。
一般情況下,在卷積之后要進入池化層來選擇最重要的特征,然而CNN模型提取的只是局部的特征,忽視了時序的相關性。本文決定在卷積之后不進入池化層,而是使用BiLSTM生成中間詞表示,然后結合注意力機制獲得句子在CNN中的最終表示。
2.2.2利用BiLSTM模型生成中間向量
LSTM可以學習長期依賴關系、記憶和訪問歷史信息。LSTM模型結構包括輸入門it、遺忘門ft和輸出門ot,對于一個給定的序列在各個門和狀態中更新方式如下所示:
it=σi(Wxixt+Whiht-1+bi)
(8)
ft=σf(Wxfxt+Whfht-1+bf)
(9)
ct=ft·ct-1+it·tanh(Wxcxt+Whcht-1+bc)
(10)
ot=σo(Wxoxt+Whoht-1+o)
(11)
ht=ot·tanh(ct)
(12)
式中:xt是當前時間t的輸入;σ()表示[0,1]內的Sigmod函數;tanh代表[-1,1]之間的雙曲正切函數;符號·表示乘法運算;ht是時間t的輸出向量。
單向的LSTM只能讀取歷史信息,沒有利用未來下文的語法語義信息,因此本文使用BiLSTM。對上述序列分別進行正向和反向的處理,既能獲得歷史信息,又能讀取未來的信息。經過BiLSTM處理之后,在時間t的輸出ht更新為:
(13)

圖5 BiLSTM計算過程
2.2.3利用注意力機制計算最終向量
CNN提取的是局部特征,但忽視了時序的相關性;BiLSTM雖然可以處理歷史和未來的時序信息,卻會丟失某個位置在某個時間的局部信息。而注意力機制又可以對輸入序列的不同局部賦予不同的權重,突出其影響程度。因此,本文運用注意力機制,將CNN和BiLSTM結合,期望可以同時獲得局部和時序信息。
利用注意力機制,最終特征表達的具體計算式為:
ui=cos(ht,wi)
(14)
(15)
(16)
式中:ht表示通過BiLSTM模型計算的中間向量表示;wi表示通過改進的CNN模型得到的局部特征,通過它們的余弦相似度ui來計算vi對應的權重值αi,其值越高,說明局部卷積和中間向量越相似,分配的注意力就越多;v表示最終的特征表達。最終向量計算過程如圖6所示,其中:x表示輸入向量,h表示經過CNN卷積和BiLSTM處理過的中間向量,α表示注意力權重,v表示最終句子向量。
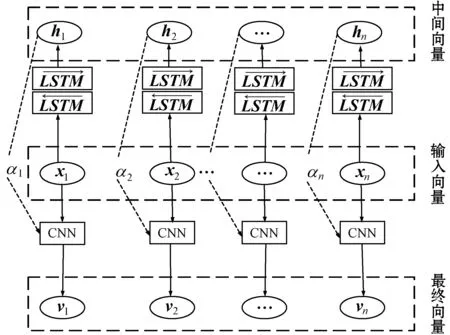
圖6 最終向量計算過程圖
2.3 Softmax分類層
將最終的句子向量表示輸入到Softmax層進行分類,首先計算屬于某個類別i的概率pi:
(17)
然后判斷輸入句子的類別,選擇概率最大的作為分類類別c:
c=arg max(pi)
(18)
本文模型為了避免出現過度擬合的現象,還采用了Dropout技術和L2正則化。
3 實 驗
3.1 實驗環境和數據
本文實驗是在Windows 7 64位操作系統下進行的,PC的處理器是Intel(R)Core(TM)i7- 3520M 2.90 GHz,內存大小為8 GB,實驗使用的編程語言是Python 3.6,開發的工具為PyCharm,深度學習框架為TensorFlow 1.12.0。
實驗的新聞標題數據集來源有三個:(1) 復旦大學搜集公開的文本分類數據,下稱FudanNews。原始的文本數據一共有20個類別,但是某些類別所包含的文檔數目過少,因此選取文檔數目大于1 000的5個類別共6 500條數據。(2) 搜狗實驗室提供的Sougou新聞語料庫,下稱SougouNews。選取完整數據中的9個類別共27 000條數據。(3) 清華NLP小組提供的新浪新聞文本分類數據集的子集,下稱THUCNews。選取其中10個類別共65 000條新聞數據。將這些數據中的新聞標題提取出來,作為本文實驗的數據集,并且按照8 ∶1 ∶1的比例分配訓練集、驗證集和測試集。
3.2 參數設置
本文提出的模型的參數中包含了CNN和BiLSTM模型的參數,主要的參數設置如表1所示。
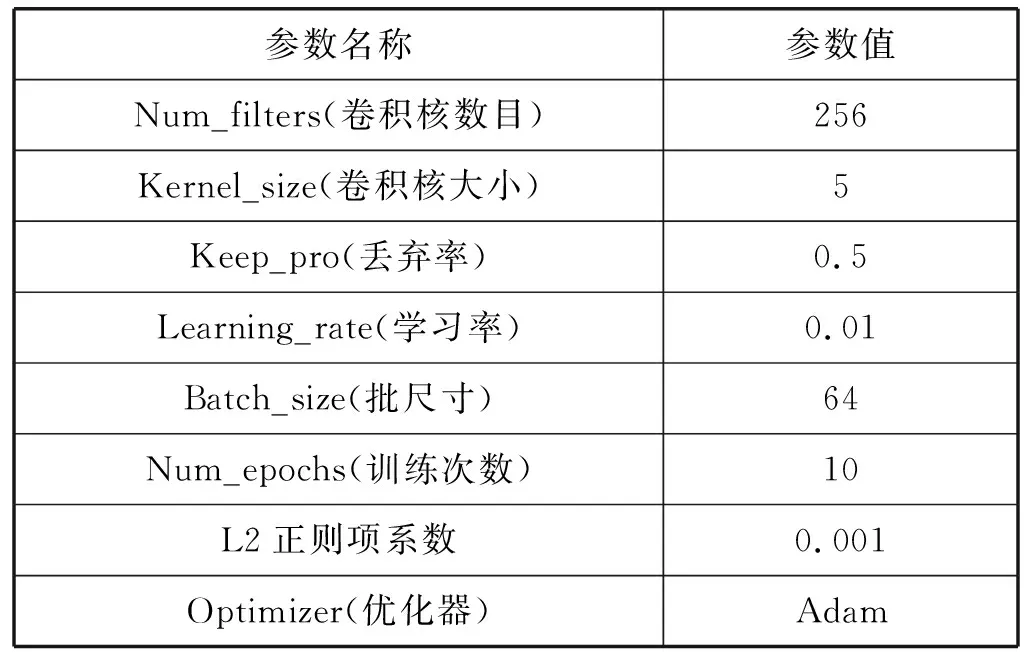
表1 參數設置表
3.3 分類性能評價指標
本文采用常用的準確率Acc和F1值作為評價指標來評價本文提出模型的分類結果。根據實驗結果建立的分類評價指標含義如表2所示。
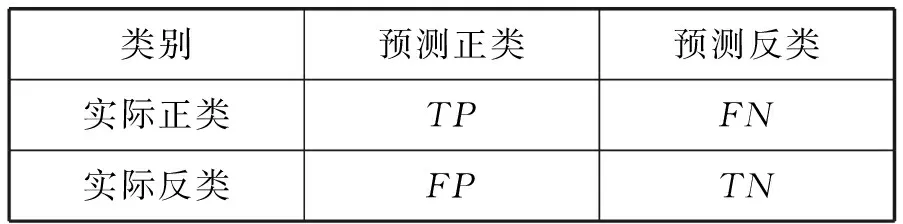
表2 分類評價指標含義
準確率Acc的計算式如下:
(19)
式(19)的分子表示分類正確的文檔數目,分母表示總的文檔數目。F1值的計算式如下:
(20)
式中:P和R分別代表精確率和召回率。P和R的計算式為:
(21)
(22)
3.4 最佳詞性因子的確定
為了驗證本文引入的詞性因子對分類效果的影響,確定最佳的詞性因子,在其他參數相同的條件下,以在FudanNews數據集上進行實驗為例,選取準確率最高時的數值作為最佳詞性因子。如前文所述,動詞和名詞能夠主要反映出文本內容,由此可見動詞(短語)和名詞(短語)的影響超過50%,按照α+β+γ=1且γ<β<α的原則,α從0.5開始取值,按照0.1的步長依次改變γ<β<α∈[0,1]的值。實驗結果如表3所示。
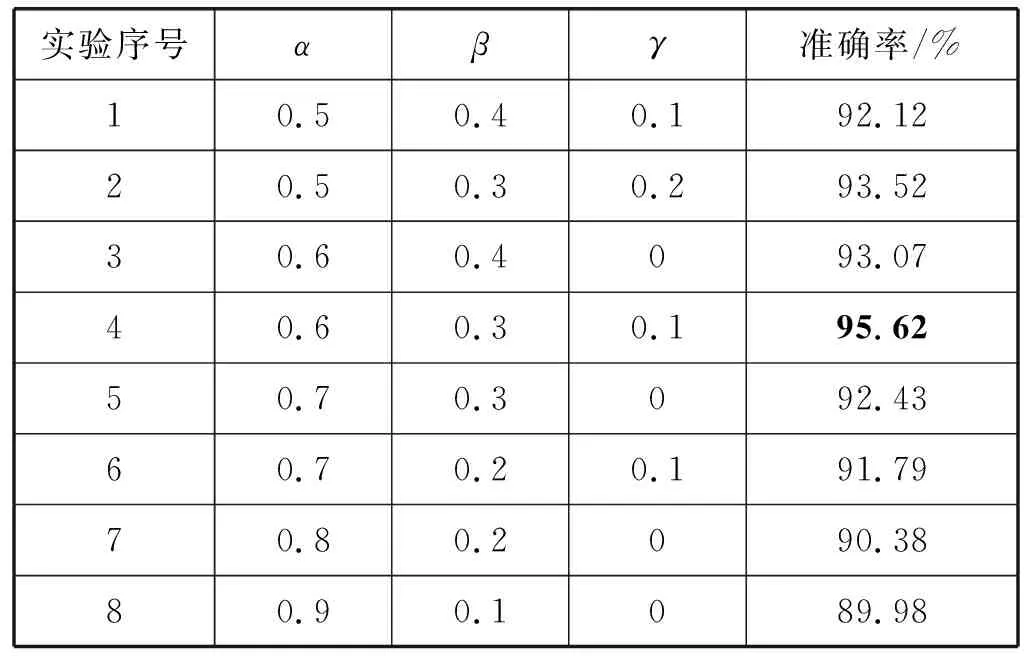
表3 準確率和詞性因子關系表
可以看出,不同的詞性的確對短文本分類存在重要的影響,恰當的詞性因子賦值能夠提高分類的效果,不恰當的賦值反而會降低分類效果,驗證了引入詞性因子的有效性。當α、β、γ分別取0.6、0.3、0.1時分類效果最好,準確率達到最高,即為最佳詞性因子。
3.5 結果分析
通過在相同數據集上和其他模型進行對比實驗,驗證本文模型的有效性。對比的模型主要類別有傳統模型、CNN模型、LSTM模型、CNN+LSTM混合模型和基于注意力機制的LSTM模型等。表4-表6分別是本文模型和其他模型在FudanNews、SougouNews和THUCNews數據集上的實驗結果。
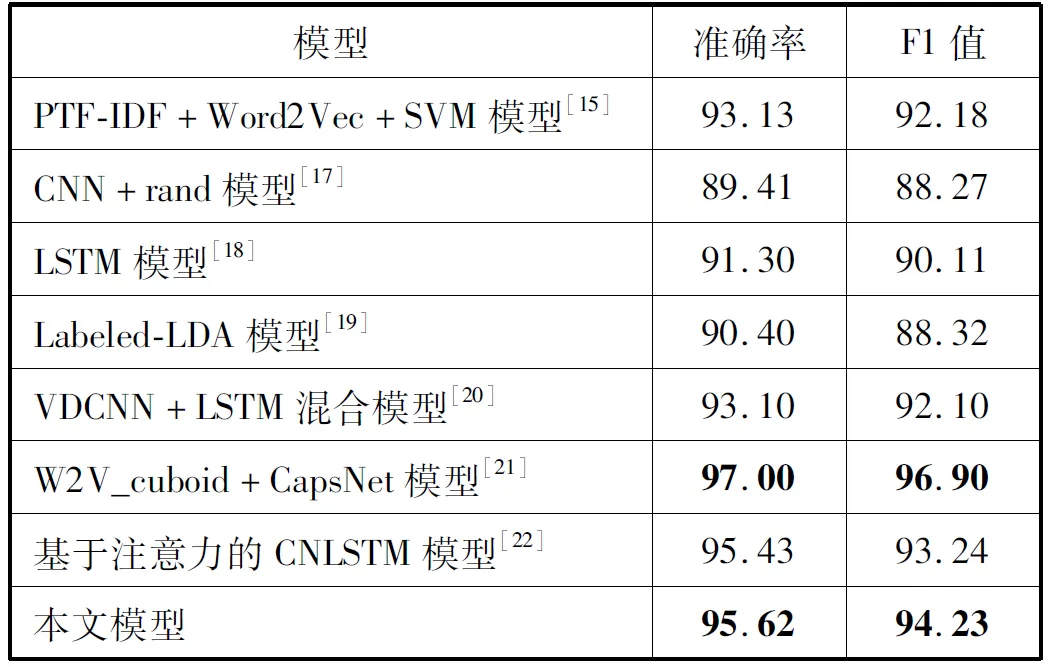
表4 不同模型在FudanNews上的實驗結果(%)
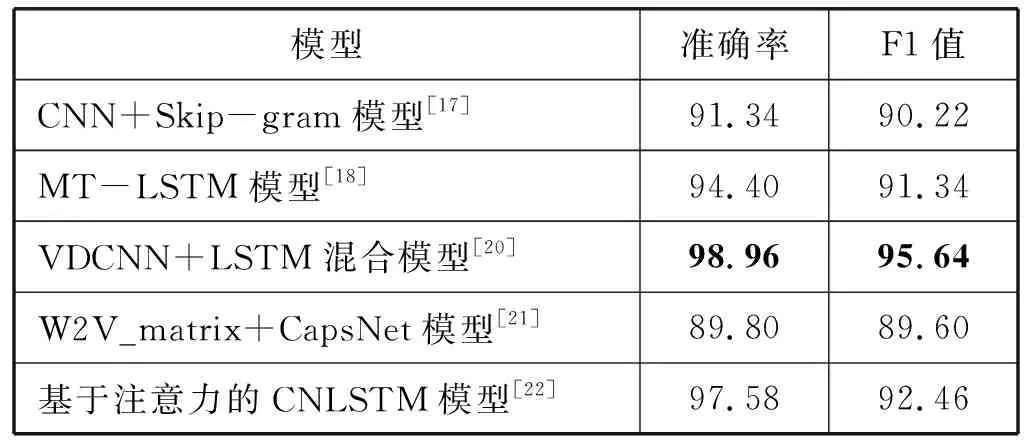
表5 不同模型在SougouNews上的實驗結果(%)
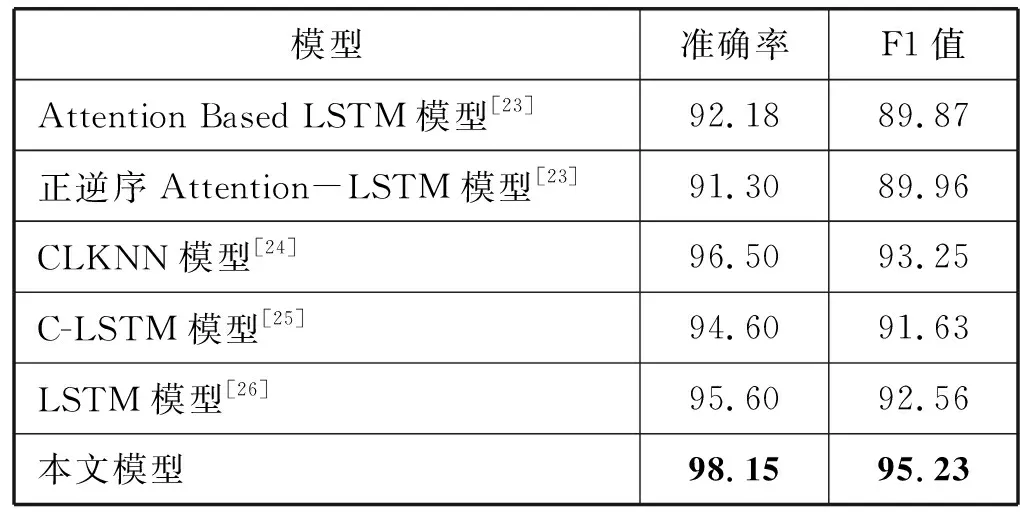
續表5
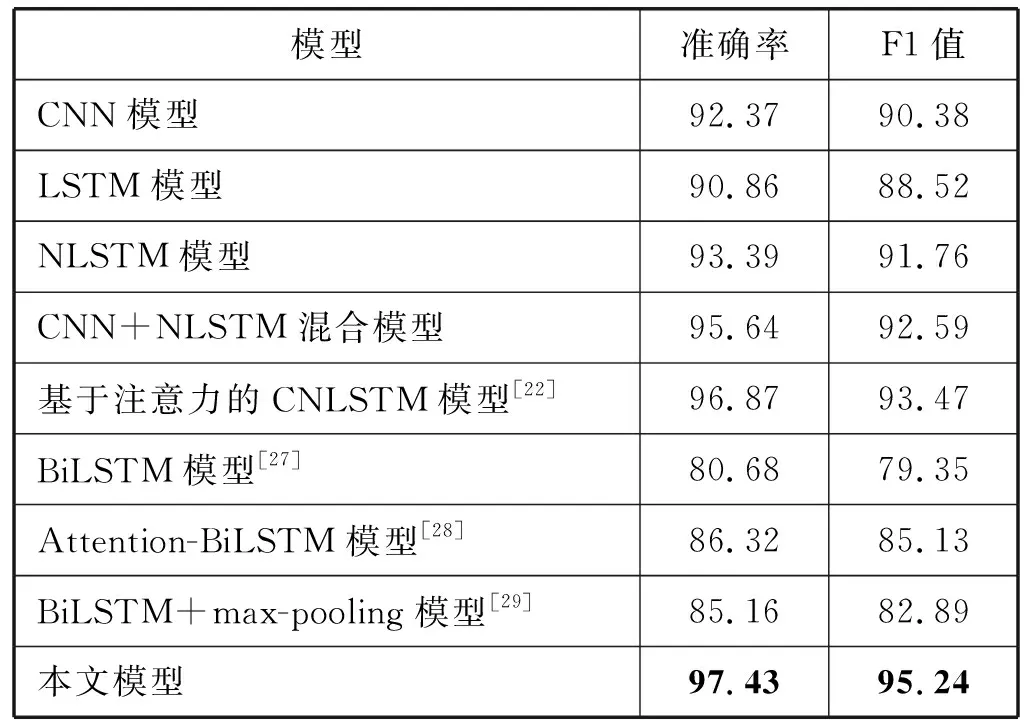
表6 不同模型在THUCNews上的實驗結果(%)
從表4可以看出,本文提出的模型在FudanNews數據集上的分類效果要優于大多數的模型,準確率和F1值分別能夠達到95.62%和94.23%,只比文獻[21]使用膠囊神經網絡的效果略差,較CNN模型提升了6.21百分點和5.96百分點。
從表5可以看出,在SougouNews數據集上,本文模型的準確率和F1值分別能夠達到98.15%和95.23%,只比文獻[20]中使用的VDCNN+LSTM混合模型的準確率和F1值低0.81百分點和0.41百分點,優于其他模型。
從表6可以看出,本文提出的分類模型相比其他的模型在THUCNews數據集上表現最好,準確率和F1值分別達到97.43%和95.24%,明顯優于其他模型。
對比表4和表5發現,文獻[21]使用膠囊神經網絡模型在FudanNews上的準確率高達97.00%,在SougouNews上卻是最低的89.80%;文獻[20]中的VDCNN+LSTM混合模型在SougouNews上的準確率最高,達到98.96%,在FudanNews上的準確率只有93.10%;說明這兩個模型在不同數據集上的實驗結果波動都比較大,而本文模型在這兩個數據集上的實驗結果分別為95.62%和98.15%,實驗結果比較均衡,說明本文模型的分類效果更加穩定,普適性和泛化性更好。
綜上所述,本文模型能夠有效地提升中文短文本分類效果,主要表現在三個方面:(1) 較傳統的SVM等分類模型,可以更好地提取文本特征;(2) 較CNN、LSTM等單個神經網絡模型,本文將CNN和BiLSTM相結合,同時引入注意力機制,不僅可以提取局部特征,獲取歷史和未來的時序信息,還能夠防止主要信息的丟失,突出局部特征的關鍵信息;(3) 較使用注意力機制的神經網絡模型,本文使用BERT模型動態預訓練詞向量,并引入改進的詞性因子,可以更好地學習詞向量的語義和句法信息,有效地優化詞向量。
4 結 語
本文針對傳統的文本表示方法存在的特征稀疏、語義不足等問題,提出一種基于改進詞性信息和ACBiLSTM的混合神經網絡模型。改進BERT模型預訓練的詞向量,利用CNN卷積層初步提取特征,輸入到BiLSTM網絡中進一步獲得上下文時序信息,結合注意力機制獲得文本最終特征表示。在三個公共數據集上進行實驗驗證,結果表明本文模型取得了良好的效果,不僅考慮詞性信息的影響,還可以捕捉短文本的局部特征和上下文的時序信息,防止主要信息丟失,突出關鍵信息,有效地提高短文本分類精度,具有一定應用價值。
本文提出的算法在使用BERT模型和BiLSTM模型的過程中,由于都是進行雙向操作,會消耗較多的時間,因此未來研究將對這一問題進行改進,在不影響分類精度的前提下,嘗試優化時間復雜度。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
