融合類別語義特征的卷積神經網絡建筑物提取
2021-12-17 08:52:50張濤丁樂樂史芙蓉
遙感信息 2021年5期
張濤,丁樂樂,史芙蓉
(1.天津市勘察設計院集團有限公司,天津 300191;2.武漢大學 測繪遙感信息工程國家重點實驗室,武漢 430079)
0 引言
建筑是城市最主要的基礎地理要素之一,準確的建筑信息對城市動態監測、城市密度估計與城市環境評價等方面具有重要意義[1-2]。當前,從高分辨率影像上提取建筑信息吸引了眾多學者的關注,成為測繪遙感領域的熱點研究問題[3]。
建筑提取方法主要可以分為兩大類:基于人工設計特征的方法和基于卷積神經網絡的深度學習方法。傳統人工設計特征方法主要根據專家先驗知識,綜合考慮建筑的光譜、紋理、形狀和空間關系等方面信息[4],構建建筑知識規則,實現建筑的提取。該方法主要依賴人工設計特征的精巧程度。實際上,由于建筑自身和周圍環境的復雜性,人工設計特征在描述建筑屬性時,依然存在巨大挑戰。
近些年來,以卷積神經網絡模型(convolutional neural network,CNN)為代表的深度學習方法在圖像處理領域取得了巨大的成功[5-6]。深度學習擁有強大的特征學習和表達能力,能夠從標記數據中自動學習中高層的抽象特征[7]。建筑提取可以看成是一個二類的語義分割任務,即在影像上對建筑與非建筑區域進行像素級的區分。目前,典型的語義分割模型有全卷積神經網絡(fully convolutional network,FCN)[8]、SegNet[9]、U-Net[10]、Deeplab系列[11]等。其中,SegNet網絡模型引領了目前在語義分割任務中廣泛采用的編碼-解碼結構,成為很多算法改進的基本模型[12]。該模型結構簡單清晰,通過編碼層提取影像特征,再經過解碼還原圖像的尺寸和細節信息。此外,SegNet在解碼過程中使用了池化位置信息,訓練參數體量較小,訓練速度較快。一些研究已經將SegNet等CNN模型應用于建筑提取任務。例如:陳凱強等[13]基于編解碼結構的CNN,學習多級并具有區分度的特征,實現航空影像中建筑物的提取;Boonpook等[14]采用標準的SegNet模型,從無人機影像上提取了沿河邊的居民區建筑。
雖然深度學習模型不依賴于人工設計特征,但是良好的特征,尤其是具有高層語義信息的特征依然能夠有助于問題的解決。當前建筑提取的深度學習方法多采用標準的三通道彩色影像(RGB)輸入,在數據層對建筑語義信息利用不足。因此,有必要從影像中提取合適的建筑語義特征,作為初始RGB影像的補充通道,進一步增強建筑信息表征,提升建筑提取精度。形態學建筑指數(morphological building index,MBI)是一種有效的建筑表征指數[15],已經成功應用于變化檢測和災害評估等領域[16]。它通過一系列數學形態學基本運算(如重構、頂帽變換)來描述建筑的基本信息(如尺寸、方向、對比度等)。MBI指數是一種具有高層語義信息的特征,它能夠較好地突出建筑形態特點,直接表征建筑覆蓋信息,能夠增強建筑與背景的可分性,有助于深度學習模型的訓練和預測。
綜上,本文提出一種融合類別語義特征的卷積神經網絡建筑物提取方法。首先,采用SegNet作為基本網絡模型,同時提取形態學建筑指數MBI作為建筑語義特征,在數據層進一步增強建筑特征,提升類別可分性;然后,聯合原始光譜信息一起輸入到卷積神經網絡中進行模型訓練和預測。融合標準RGB影像和建筑語義特征的語義分割模型有望進一步提升建筑提取效果。
1 建筑提取方法
圖1展示了本文的方法框架。首先,對原始影像提取高層次的建筑語義特征,在初始數據層增強建筑類別的特征表達能力;然后,將建筑語義特征作為補充通道,疊加原始RGB波段共同輸入到SegNet網絡中進行模型訓練并進行建筑信息的提取。
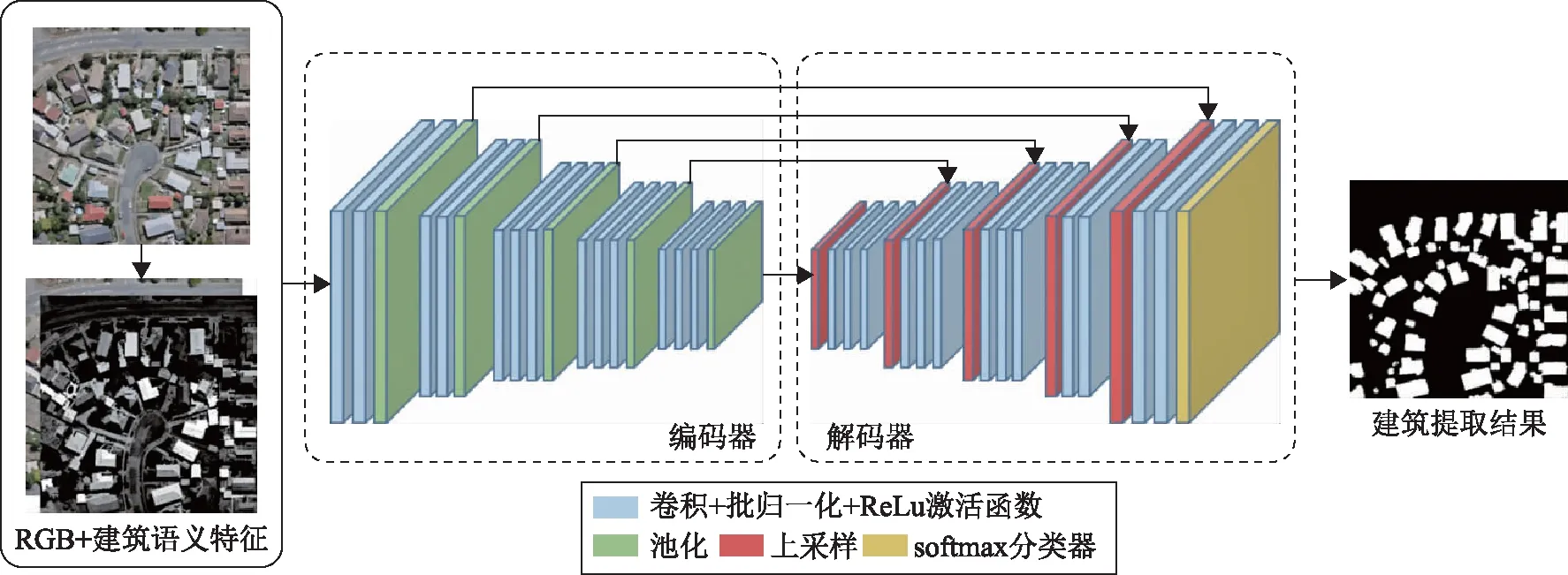
圖1 本文方法框架與卷積神經網絡結構圖
1.1 建筑語義特征
卷積神經網絡的輸入通常是標準的RGB影像,本文希望在數據層進一步增強建筑類別的表征能力,預先提取高層次的建筑語義特征作為原始RGB影像的補充通道。具體地,本文采用形態學建筑指數MBI來增強建筑語義信息。MBI是一種有效的建筑特征提取指數,能夠較好地突出高分辨率影像上的建筑信息。它的思想旨在建立建筑的內在屬性(如亮度、對比度、方向和尺寸等)與基本的形態學操作(如白頂帽變換、形態學差分)之間的關聯。MBI的構建主要包含以下幾個步驟。
1)亮度影像計算。計算輸入的多波段的亮度影像作為后續處理的基影像。由于建筑的材質在可見光波段范圍內一般表現為較高的反射率,因此亮度影像定義為每個像素在可見光波段的最大值。
2)白頂帽變換。對亮度影像做重構開運算,重構開運算能夠更好地保持邊緣信息。然后,從亮度影像中減去其開運算后的圖像,該操作稱為形態學白頂帽變換。白頂帽變換的效果是凸顯影像中的亮結構目標。
3)形態學建筑指數。采用多尺度和多方向的線性結構元素對亮度影像進行白頂帽變換,并生成差分形態學特征(DMP-WTH)表征不同尺度和方向上的建筑分布。考慮到建筑相對于狹長的道路顯得更加各向同性,因此對差分形態學譜進行均值聚合凸顯建筑的存在,得到形態學建筑指數MBI。
圖2展示了幾個典型的RGB影像及其對應的建筑語義特征。可以看到建筑語義特征圖上,建筑類別表現為高亮區域,尤其是具有較高對比度的建筑,而背景信息(如樹木、草地、裸地和道路等)響應較弱。建筑語義指數進一步增強了建筑特征,同時也抑制了背景區域,這為后續的建筑識別提供了輔助信息。

圖2 局部影像及其建筑語義特征示意圖
1.2 卷積神經網絡模型
建筑的像素級提取在計算機視覺領域可以看成是一個語義分割任務。FCN使用卷積層替換原CNN中的全連接層,可以接受任意尺寸的輸入圖像,并通過圖像上采樣的方式,保證了輸出影像和輸入影像大小一致,從而實現了基于端到端(end-to-end)的CNN圖像語義分割任務。
此后,基于FCN的語義分割方法蓬勃發展,SegNet網絡模型是其中一個經典的變體,成為很多改進算法的基礎模型。SegNet模型結構簡單清晰,是一種基于編碼-解碼的全卷積神經網絡。它通過先編碼提取影像特征,再解碼還原圖像的位置和細節信息,從而完成圖像的分割任務。如圖1所示,該網絡的前五層為編碼層,通過卷積和池化完成圖像的下采樣操作。網絡的后五層為解碼層,通過反池化和卷積操作完成圖像的上采樣操作。SegNet的特色在于其編碼器結構與解碼器結構一一對應,在池化過程中,記錄相應的最大池化索引值位置,然后在解碼時通過對應的池化索引實現非線性上采樣。因此,SegNet在上采樣階段無需學習新參數,減少了訓練參數的體量,節省了內存空間,提升了模型訓練的效率。基于這些特點,SegNet模型非常適合作為本文研究的基礎網絡。
1.3 精度評價
針對二分類語義分割問題,本文采用準確率P(precision)、召回率R(recall)和F分數(F-score)這三個常用的指標來衡量建筑提取的精度[17]。其中,準確率表示建筑提取的正確性,反映建筑提取的錯分誤差;召回率表示建筑提取的完備性,反映建筑提取的漏檢誤差。通常情況下,準確率和召回率這兩種指標是此消彼長的,而F分數是同時考慮建筑提取正確性與完備性的綜合指標。
2 實驗與分析
2.1 實驗數據與實驗設置
本文采用的實驗數據是武漢大學季順平團隊生產的建筑數據集(WHU building)[18],該數據集是國際上用于建筑提取的一套標準數據集(http://study.rsgis.whu.edu.cn/pages/download/)。WHU building數據集為航空影像,空間分辨率為0.3 m,包含RGB三個可見光波段,覆蓋范圍超過400 km2,共含有18萬棟不同大小、不同色彩和不同功能的建筑(圖3)。為了便于深度學習方法的處理,WHU building數據集被裁剪成了512像素×512像素的瓦片,其中包含4 736個訓練樣本塊、1 036個驗證樣本塊和2 416個測試樣本塊,分別對應圖3中的藍色、黃色和紅色邊框區域。
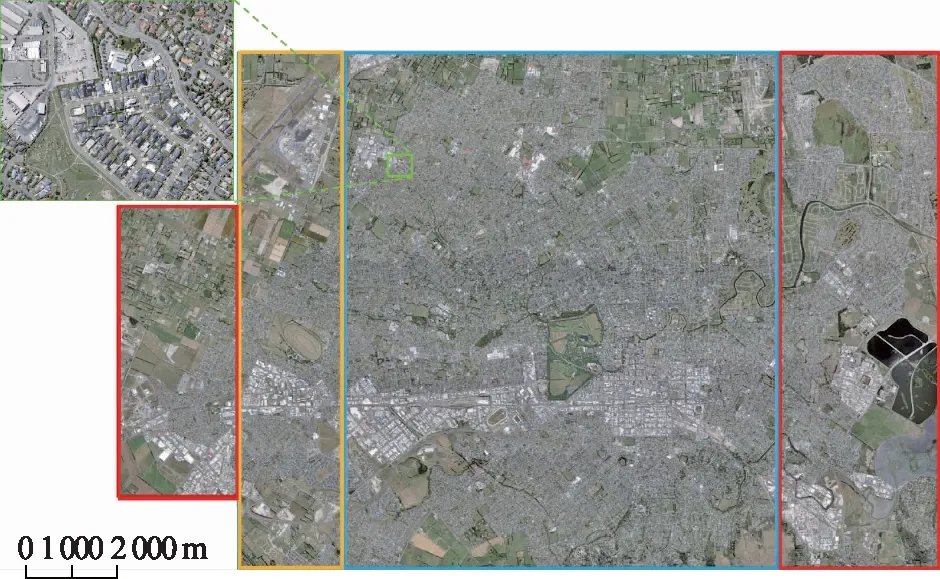
圖3 本文實驗數據集
本文采用動量梯度隨機下降法(stochastic gradient descent with momentum,SGDM)進行卷積神經網絡模型的訓練,并對主要的訓練參數進行了調試優化,將動量參數(momentum)設為0.9,batch size大小設為2,學習率設為0.001,訓練輪數(epoch)設為80。訓練過程中,每一輪迭代完成后做一次精度驗證。圖4展示了兩種方法的網絡中間訓練過程,訓練精度與驗證精度都趨于平穩,這表明本文的訓練參數選擇是合理的。形態學建筑指數在計算過程中,考慮建筑的實際尺寸,將線性結構元素尺寸的最小、最大值分別設為5 m和60 m,方向包含0°、45°、90°和135° 四個方向。

圖4 卷積神經網絡訓練過程
2.2 建筑提取結果與分析
1)建筑提取整體精度。表1展示了建筑提取的總體精度。具體來說,對于標準RGB影像輸入的SegNet網絡模型,建筑提取結果的準確率、召回率和F分數分別為83.02%、94.13%和87.57%。加入建筑語義特征一起訓練模型后,準確率、召回率和F分數分別為85.06%、93.16%和88.41%。可以看到,提取結果的召回率比正確率要高,這說明在該數據集中,建筑提取結果的誤差主要是錯分誤差,而遺漏誤差相對較小。此外,建筑語義特征的加入對準確率有較高提升,而召回率有所下降。一般而言,正確率和召回率兩個指標是此消彼長的,提升其中一個精度往往有損于另一個指標。但是對于綜合指標F分數,本文融合建筑語義特征的方法還是從整體上提升了建筑提取的精度。

表1 建筑提取總體精度
2)精度變化分布。本文進一步對所有的測試樣本統計了在引入建筑語義特征后的精度變化分布。表2展示了本文方法在各個精度提升區間的影像塊比例。

表2 本文方法相對傳統方法的精度變化分布 %
整體上,正確率P和F分數呈右側分布,召回率R呈左側分布,這與之前的總體精度評價是一致的。具體地,對于正確率,本文方法在49.9%的測試圖像中將精度提升了0.02以上。對于召回率,本文方法在40.2%的測試圖像中精度下降了0.01以內,但有16.4%的測試圖片,召回率提升了0.01以內。最后,本文方法在32.0%的測試圖像中將F分數提升了0.01以內,其次也有25.0%的測試圖像的F分數提升了0.01至0.02。綜上,由于測試圖像中地物覆蓋的多變與差異,本文方法的效果也不盡相同。整體上,本文方法更加有利于正確率P和綜合指標F分數的提升。
3)分類可靠性比較。卷積神經網絡不僅能預測類別標簽,同時也能輸出每個像素屬于每個類別的概率信息。對于二類分割任務,分類概率可以直接衡量分類可靠性。分類概率值越大,則該像素的分類可靠性越高。本小節比較本文方法與傳統方法的分割結果中高可靠性分類結果的比例。對于某一個測試樣本塊,本文設置分類概率大于0.9為高可靠性分類結果。
圖5展示了所有測試圖像塊的高可靠性像素所占比例的箱形分布圖。整體上,本文方法提升了分類結果中高可靠性像素的比例。具體地,高可靠性像素比例分布的中值由94.8%(標準RGB輸入)提升到95.7%(本文方法)。

圖5 所有測試圖像塊的高可靠性像素比例分布
4)目視結果對比與誤差源分析。圖6展示了幾個典型的建筑提取結果及其精度圖,這些區域的建筑具有不同的光譜、形狀和密度分布。從圖6(a)和圖6(b)可以看到,建筑語義特征較好地凸顯了建筑特征并同時抑制了背景信息,這有助于更準確的建筑提取。圖6(c)中,標準RGB影像輸入的SegNet網絡在一些裸地廣場、高大樹木的區域會產生一些虛警,而建筑語義指數在這些區域都是弱響應,并且響應的空間形態與建筑也有較大區別。這表明,在這些區域,建筑語義特征能夠提供與原始光譜互補的信息。圖6(d)中,融入建筑語義特征的SegNet網絡消除了這些虛警,提升了建筑提取的整體精度。

注:TP為正確提取的建筑;FP為錯誤提取的建筑;FN為遺漏的建筑。
本小節繼續分析了本文算法在一些復雜場景下的表現,探究建筑提取中的主要誤差來源。在圖7(a)和圖7(b)中,建筑提取結果主要表現為錯分誤差,成片的施工裸地以及建筑周圍鄰接的道路與建筑的光譜特征非常類似,容易與建筑混淆,成為建筑提取的主要誤差源。圖7(c)中,建筑提取誤差主要表現為漏檢誤差。建筑由于其高度不同,在屋頂上產生了陰影,這些陰影區域容易被誤認為是背景,影響建筑提取的完整性。綜上,本文算法的建筑提取結果在一些復雜場景下也存在一定的錯分和漏檢誤差,但整體上的表現是合理的,對于影像中常見的主要道路、裸地、植被等區域,本文算法都能將其與建筑較好地區分開來。

注:TP為正確提取的建筑;FP為錯誤提取的建筑;FN為遺漏的建筑。
3 結束語
建筑信息提取是測繪和計算機視覺領域的研究熱點和難點,對城市規劃與管理具有重要作用。傳統的卷積神經網路建筑提取方法對建筑的語義信息利用不足,本文提出了一種融合類別語義特征的卷積神經網絡建筑物提取方法。該方法首先提取影像的高層次建筑語義特征,預先突出建筑覆蓋信息,并作為原始影像的補充通道一起輸入到卷積神經網絡模型中訓練進行建筑提取。實驗表明,相對于原始的RGB影像輸入,建筑語義特征的加入能夠在數據層增強建筑特征表達能力,整體上提升建筑提取的精度。后續工作中,可以考慮融合其他有效的類別語義特征(如植被指數),進一步區分建筑與背景區域,從而有助于更準確的建筑提取。
猜你喜歡
北方建筑(2021年6期)2021-12-31 03:03:54
文苑(2020年10期)2020-11-07 03:15:36
現代裝飾(2020年6期)2020-06-22 08:43:12
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
少兒科學周刊·兒童版(2015年6期)2015-11-24 03:49:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
