基于數據分析角度論述游客目的地印象
2021-12-24 10:48:51蔡金勇羅浩杰李澤星沈洋
電子樂園·上旬刊 2021年3期
關鍵詞:數據分析
蔡金勇 羅浩杰 李澤星 沈洋


摘要:本文旨在利用數據分析對游客對景區與酒店的評價進行數據挖掘,由于游客滿意度與目的地美譽度緊密相關,游客滿意度越高,目的地美譽度就越大。找出其中穩定客源、取得競爭優勢、吸引游客到訪消費等的主要原因。這對于旅游企業科學監管、資源優化配置以及市場持續開拓具有長遠而積極的作用。
關鍵詞:數據分析;jieba分詞; 停用詞; 均方誤差; 編輯距離
一、問題重述
提升景區及酒店等旅游目的地美譽度是各地文旅主管部門和旅游相關企業非常重視和 關注的工作,涉及到如何穩定客源、取得競爭優勢、吸引游客到訪消費等重要事項。游客滿意度與目的地美譽度緊密相關,游客滿意度越高,目的地美譽度就越大。
二、景區及酒店印象分析
(一)使用方法
我們將會用到jieba分詞的方法,有三種分詞模式
(1) 精確模式:試圖將句子最精確地切開,適合文本分析;
(2) 全模式:把句子中所有的可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義問題;
(3) 搜索引擎模式:在精確模式的基礎上,對長詞再次切分,提高召回率,適合用于搜索引擎分詞。
(二)問題解決
1.目的地TOP20熱門詞
本節使用jieba模塊中的精準模式對網評文本進行分詞,再使用中文常用停用詞(中文停用詞表“cn_stopwords.txt”,哈工大停用詞表“hit_stopwords.txt”,百度停用詞表“baidu_stopword.txt”,四川大學機器智能實驗室停用詞庫“scu_stopwords.txt”)表對文本進行過濾,遍歷所有詞語,每出現一次加一,再將對應鍵值轉換為列表,根據詞語出現的次數進行從到大到小進行排列,將排名前二十的熱詞及熱度輸出。
2. 每家酒店和景區的印象詞云表
我們將景區評論及酒店評論使用JupyterNotebook將其轉換為矩陣,新建一個空列表list1,創建一個循環,將矩陣中第一列一樣的評論依此增加如list1中,每次添加完一次之后對list1進行分詞及過濾之后將前20個數據保存入對應名稱的后綴為.csv的文件中。
總結:由于數據處理對象為景區評論和酒店評論,我們選用停用詞表時可以選用針對性較強的,可以過濾更多無關詞語。分詞方法有很多,可以針對不同情況使用。待分詞的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建議直接輸入 GBK 字符串,可能無法預料地錯誤解碼成 UTF-8
三、景區及酒店的綜合評價
1. 數學模型及相應算法
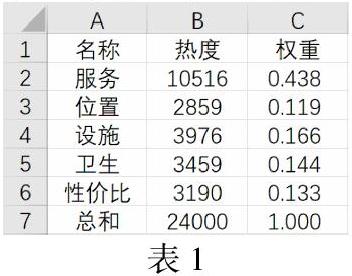
我們對問題一中的熱度數據對景區及酒店的服務、位置、設施、衛生、性價比進行分析,在列表中衛生熱度只有1931,而與其近似的干凈則占熱度3459,所以我們決定用干凈的熱度來表示衛生的熱度。以及列表中性價比的熱度為2237,與其近似的便宜熱度為3190,及免費2360,考慮到有可能會有一句網評中都包含了這幾個詞語,所以我們決定用熱度較高的便宜來表示性價比的熱度。然后對這五個求權重得到下表:
提取出這五個的權重生成5×1的矩陣mat3,mat3則為評分權重矩陣。再將酒店評分提取出來生成5×50的矩陣mat1,將景區評分提取出來生成5×50的矩陣mat2。
用x1=np.dot(mat1,mat3)求得對酒店評分的預測矩陣,x2= np.dot(mat2,mat3)求得對景區的預測矩陣,在excel表中提取出酒店評分真實值y1及景區評分真實值y2。然后使用預測矩陣x減去真實矩陣y,分別得到差值矩陣d1,d2。
然后使用預測矩陣x減去真實矩陣y,分別得到差值矩陣d1,d2。
最后使用均方誤差進行模型判斷:
MSE:
計算酒店評分的均方誤差:np.dot(np.transpose(d1),d1)/50
計算景區評分的均方誤差:np.dot(np.transpose(d2),d2)/50
計算酒店加景區評分的均方誤差:
(np.dot(np.transpose(d2),d2)+np.dot(np.transpose(d1),d1))/100
得到MSE(酒店)≈0.0098
MSE(景區)≈ 0.0121
MSE(酒店+景區)≈ 0.0109
當MSE越小,我們建立的模型越好。
四、網評文本的有效性分析
出于各種原因,網絡評論常常出現內容不相關、簡單復制修改和無有效內容等現象,為了解決這個問題,我們使用了計算編輯距離的方法。
1.算法
編輯距離,又稱Levenshtein距離(也叫做Edit Distance),是指兩個字串之間,由一個轉成另一個所需的最少編輯操作次數,如果它們的距離越大,說明它們越是不同。許可的編輯操作包括將一個字符替換成另一個字符,插入一個字符,刪除一個字符。
代碼實現:
Levenshtein.distance(’abc’,’cba’)
Levenshtein.distance(’kitten’,’sitting’)
2.問題解決
通過計算編輯距離,我們剔除距離小于0.5的數據,使得數據更加簡潔,提高數據有效性。
在執行過程中,為了減少計算,我們首先對數據進行了清洗,主要用到了去停用詞,結巴精準分詞等方法,然后計算編輯距離。但是通過對比較結果進行分析,我們發現距離普遍較小,即相關性普遍較大,無法進行有效剔除。因此我們放棄了此方法,選擇分析文本。
我們將每個文本與后面的文本進行比較,得到對應的相關性(代碼用的是1-aa,因此,值越靠近1相關性越強):
我們將這些篩選出的相關度高的數據進行剔除,就整理出來了一個更有效的數據。
猜你喜歡
職工法律天地·下半月(2016年10期)2016-11-30 11:52:57
商情(2016年40期)2016-11-28 11:28:07
商(2016年32期)2016-11-24 17:39:41
科技資訊(2016年18期)2016-11-15 18:05:53
考試周刊(2016年84期)2016-11-11 23:57:34
科技視界(2016年18期)2016-11-03 22:51:40
體育時空(2016年8期)2016-10-25 18:02:39
現代經濟信息(2016年19期)2016-10-20 17:46:29
中國科技博覽(2016年18期)2016-10-19 10:30:11
中國市場(2016年36期)2016-10-19 04:31:23
