基于BERT的多特征融合的醫療命名實體識別
2021-12-30 01:15:12李正民云紅艷王翊臻
青島大學學報(自然科學版) 2021年4期
李正民 云紅艷 王翊臻


摘要:
針對傳統字向量難以表達上下文語義以及抽取的特征較為單一等問題,提出基于BERT的多特征融合模型BERT-BiLSTM-IDCNN-Attention-CRF,通過BERT建模字向量的上下文語義關系,并融合雙向長短期記憶網絡(BiLSTM)和迭代膨脹卷積 (IDCNN),分別抽取的上下文特征和局部特征,使兩種特征進行互補以提升實體抽取效果。本模型在全國知識圖譜與語義計算大會CCKS2020中文電子病歷數據集上進行測試,與BiLSTM-CRF等基準模型進行比較,F1值提升127%。實驗結果表明,本模型能較好地識別電子病歷中的醫療實體。
關鍵詞:
命名實體識別,多特征融合,BERT,BiLSTM,IDCNN
中圖分類號:TP391
文獻標志碼:A
收稿日期:2021-05-19
基金項目:
國家重點研發計劃 (批準號:2016YFB1001103)資助。
通信作者:云紅艷,女,博士,教授,主要研究方向為語義Web與本體工程、智能信息系統、大數據集成。E-mail:yunhy2001@163.com
電子病歷用于患者臨床治療過程中,以電子化方式記錄患者就診時的病情變化及診療過程,是臨床科學診斷治療的基礎材料[1]。電子病歷包含了豐富的醫療實體,通過使用醫療命名實體識別技術(Medical Named Entity Recognition,MNER)從電子病歷中挖掘出各類醫療實體,可用于建立醫療知識圖譜,增強數據的可用性、可理解性與可見性[2]。命名實體識別技術從早期的基于規則和詞典的方法逐漸向機器學習和深度學習過渡,近年來由于神經網絡具有強大的特征提取能力,因此成為命名實體識別中的主流方法。Liu等[3]通過實驗對比了深度學習算法BiLSTM-CRF與機器學習算法CRF識別實體的性能,證明了深度學習算法更為有效。Yang等[4]基于BiLSTM-CRF訓練實體識別模型,從入院記錄和出院小結中有效的抽取醫學實體。Chiu[5]使用BiLSTM和CNN混合結構獲取詞級和字符級特征,進一步提升了模型識別性能。Strubell等[6]將空洞卷積IDCNN應用于命名實體識別中,大大縮減了模型的訓練時間。近年來,注意力機制在自然語言處理領域得到了廣泛的應用。Yin[7]等利用CNN提取漢字字符間特征信息,利用自注意力機制捕獲字符之間的依賴關系特征來識別醫學電子病歷中相關實體。以上傳統方法未能充分利用不同粒度特征在實體識別方面的優勢,且電子病歷命名實體識別面臨訓練語料不足、標注質量不高以及傳統靜態字向量在表征字的語義方面的不足等限制了模型的學習能力。針對以上問題,本文使用微調的BERT提取動態字向量并拼接詞性等特征嵌入共同作為嵌入層的輸出;在特征提取層分別使用BiLSTM和IDCNN提取上下文依賴特征與局部特征;最后將抽取的兩類特征動態融合后經CRF解碼層獲取全局最優標簽序列。該模型融合了兩類不同粒度特征,有效提升了模型識別準確率。
1 數據
1.1 數據來源
采用的數據集是CCKS2020中文電子病歷數據集,數據集共標注了“疾病和診斷” “解剖部位” “實驗室檢驗” “影像檢查” “手術” “藥物”等六種實體類型,共包括1 050條標記數據。
1.2 數據預處理
數據集由專業人士手工標注完成,并且其中存在大量標注不統一、漏標以及標注錯誤等問題。因此,本文對數據集的標注做了預處理,并對上述標注采用手工的方式進行糾正。另外,統一數據集中字母大小寫與中英文標點符號等;在保證語義相對完整的前提下,對句子進行切分,設定每個句子長度最長為202,最短為20。數據預處理后,訓練集與測試集中實體類型與實體數量見表1。
1.3 實體標注
命名實體識別可看作是序列標注問題,需要將原始標注語料處理成序列標注形式。本文使用BIOES標注方案將數據集給出的標簽映射到每一個字符上,進行字符級別的標記[8]。其中B,I,E分別表示實體開始、中間和結束,O表示非實體,S表示單字符實體。數據標注格式示例見表2。
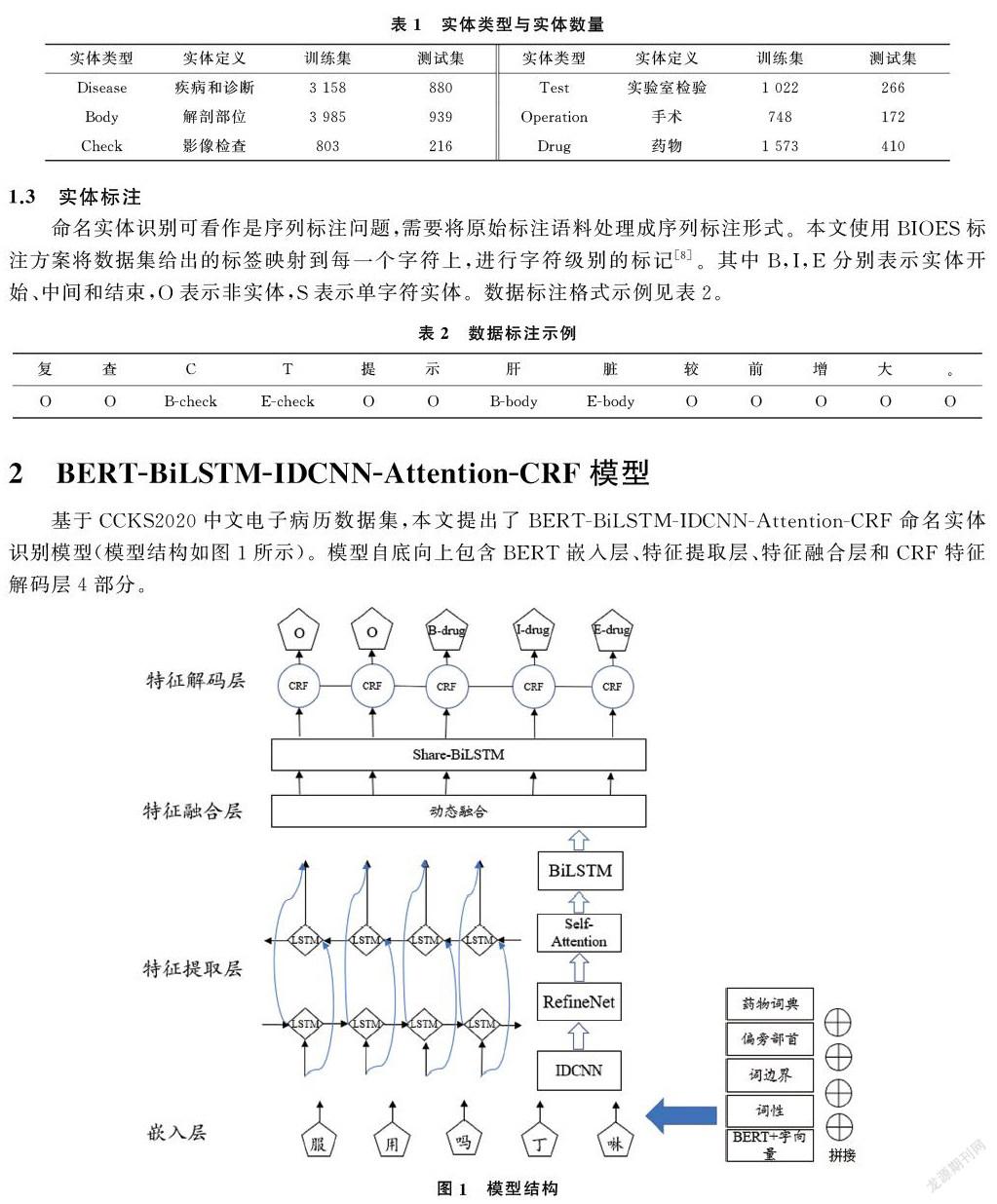
2 BERT-BiLSTM-IDCNN-Attention-CRF模型
基于CCKS2020中文電子病歷數據集,本文提出了BERT-BiLSTM-IDCNN-Attention-CRF命名實體識別模型(模型結構如圖1所示)。模型自底向上包含BERT嵌入層、特征提取層、特征融合層和CRF特征解碼層4部分。
2.1 嵌入層
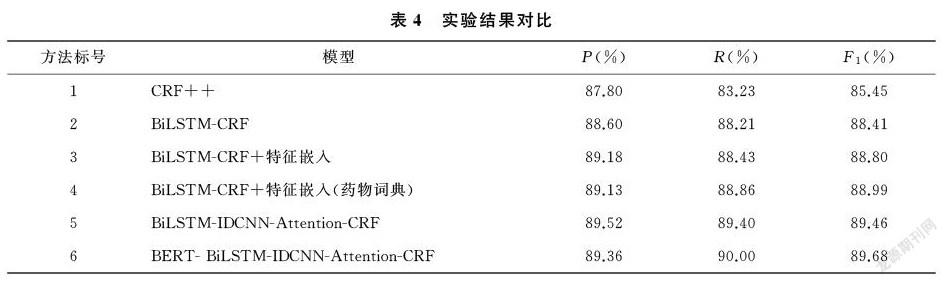
2.1.1 BERT字向量嵌入 將文本數據送入模型之前需將文本數據進行向量化表示,傳統的文本表示模型存在表征靜態、表征能力不足以及缺乏領域性特征等問題,而BERT[9]模型很好的解決了此類問題。首先經過預訓練后的BERT不僅可以從大量無標簽的非結構化文本中學習豐富的先驗語義知識,同時通過多層的transformer對輸入序列的每個單詞建模上下文語義知識,使得同一個單詞在不同的上下文中得到不同的詞向量表示。其次對預訓練模型使用領域數據集進行微調,使得模型融入領域知識,適應領域任務需求。
本文選擇在預訓練模型RoBERTa[10]基礎上對其參數進行微調,得到微調后的RoBERTa-FT模型。然后固定該模型參數,BERT只作為字向量的特征生成器,將輸入的文本序列轉化為字向量序列[11],在此基礎上拼接字嵌入embedding作為BERT生成字向量部分不進行訓練的補充。
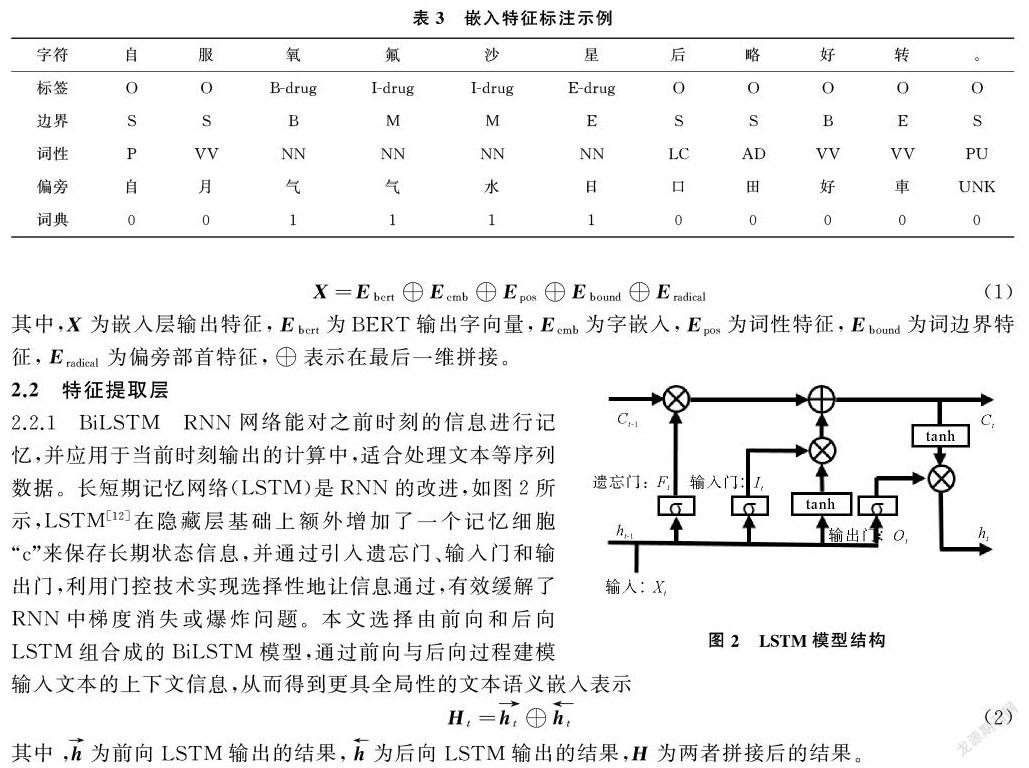
2.1.2 特征嵌入 在電子病歷文本中,命名實體如“解剖部位”“疾病與診斷”“藥物”中多為名詞詞性,而“影像檢查”“手術”實體前通常會有動詞“行”來表示這一動作的發生。因此詞性與命名實體有著較強關聯關系。本文使用fastHan工具(https://github.com/fastnlp/fastHan/)提取文本的詞性特征與詞邊界特征,同時提取了偏旁部首特征作為補充信息,由于繁體部首相比簡體部首在字形字構上更具解釋性,且數量更少,實驗中將構建繁體部首映射表,獲取每一個字的繁體部首特征。
為提高特定實體的識別準確率,制作了藥物詞典特征輔助模型的識別。從搜狗詞庫(https://pinyin.sogou.com/dict/)下載藥物詞典后去除非藥物名稱后得到相對干凈的藥物詞典,再加入訓練集中所有藥物實體。使用雙向最大匹配算法,從測試集中匹配出在詞典中出現的實體并標注,匹配到的標記為1,剩下的標記為0,從而構建藥物詞典特征。嵌入特征的標注示例如表3所示。
4 結論
本文通過使用BERT作為嵌入層生成蘊含豐富語義信息的動態字向量,針對單一BiLSTM缺乏局部特征提取能力,使用IDCNN提取文本的局部特征并將抽取到的多層特征經RefineNet整合,充分利用了抽取到的各層信息;然后將整合后的特征使用注意力機制增強對實體識別起重要作用的特征,提升模型識別性能。最后將抽取的兩類特征使用動態融合方法后送入CRF解碼層得到最優的標簽序列。通過測試CCKS2020醫療電子病歷數據集,結果表明,基于BERT的多特征融合模型對醫療命名實體識別有明顯提升。
參考文獻
[1]黃建英.電子病案管理發展現狀趨勢[J].醫學綜述,2009,15(13):2078-2080.
[2]林莉,云紅艷,賀英,等.基于企業知識圖譜構建的可視化研究[J].青島大學學報(自然科學版),2019,32(1):55-60.
[3]LIU Z J, YANG M, WANG X L, et al. Entity recognition from clinical texts via recurrent neural network[J]. BMC Medical Informatics and Decision Making, 2017,17(2):53-61.
[4]YANG H M, LI L, YANG R D, et al. Named entity recognition based on bidirectional long short-term memory combined with case report form[J]. Chinese Journal of Tissue Engineering Research, 2018,22(20):3237-3242.
[5]CHIU J P C, NICHOLS E. Named entity recognition with bidirectional LSTM-CNNs[DB/OL]. [2021-05-05]. https://arxiv.org/abs/1511.08308.
[6]STRUBELL E, VERGA P, BELANGER D, et al.Fast and accurate entity recognition with iterated dilated convolutions[DB/OL]. [2021-04-30]. https://arxiv.org/abs/1702.02098.
[7]YIN M W, MOU C J, XIONG K N, et al. Chinese clinical named entity recognition with radical-level feature and self-attention mechanism[J]. Journal of Biomedical Informatics, 2019, 98:103289.
[8]LIU Z J, CHEN Y X, TANG B Z, et al. Automatic de-identification of electronic medical records using token-level and character-level conditional random fields-ScienceDirect[J]. Journal of Biomedical Informatics, 2015, 58:S47-S52.
[9]DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[DB/OL]. [2021-04-30]. https:// arxiv.org/pdf/1810.04805. pdf&usg= ALkJrhhzxlCL6yTht2BRmH9atgvKFxHsxQ.
[10] LIU Y H, OTT M, GOYAL N, et al. Roberta: A robustly optimized bert pretraining approach[DB/OL]. [2021-05-02]. https://arxiv.org/pdf/1907.11692.pdf.
[11] JAWAHAR G, SAGOT B, SEDDAH D. What does BERT learn about the structure of language?[C]//ACL 2019 57th Annual Meeting of the Association for Computational Linguistics. 2019.
[12] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8):1735-1780.
[13] LIN G S, LIU F Y, MILAN A, et al. RefineNet: Multi-path refinement networks for dense prediction[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 42(5): 1228-1242.
[14] YAN H, DENG B, LI X, et al. Tener: Adapting transformer encoder for named entityrecognition[DB/OL]. [2021-04-30]. https://arxiv.org/pdf/1911.04474.pdf.
Abstract:
In order to solve the problems that traditional word vectors were difficult to express the context semantics and extract multiple features, a multi feature fusion model named BERT-BiLSTM-IDCNN-Attention-CRF was proposed, which used BERT to model the context semantic relationship of word vectors and fused the context features and local features extracted by BiLSTM and IDCNN respectively. The model was tested on CCKS2020 Chinese EMR dataset, and compared with the baseline models such as BiLSTM-CRF, the F1 value is increased by 127%. The experimental results show that the proposed model can better identify the medical entities in EMR.
Keywords:
named entity recognition; multi feature fusion; BERT; BiLSTM; IDCNN
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
