基于可變形卷積與特征融合的機場道面裂縫檢測算法
2021-12-31 02:21:14李海豐韓紅陽
南京航空航天大學學報 2021年6期
李海豐,景 攀,韓紅陽
(中國民航大學計算機科學與技術學院,天津 300300)
機場道面裂縫一直是場道管理部門關注的焦點。根據《民用機場道面評價管理技術規范》[1],裂縫是由于重復荷載、溫度翹曲應力和溫度收縮應力等綜合作用引起的板塊開裂造成的。裂縫作為機場道面最主要的病害之一,嚴重影響著機場的安全運營。因此,對機場道面裂縫進行有效檢測至關重要。
傳統的道面裂縫檢測是通過人工檢測,該方法效率低、成本高、安全性差。隨著圖像處理技術的發展,道面裂縫自動采集與識別技術成為當前主流。為了從圖像中高效、準確、快速地提取裂縫,國內外學者對此進行了廣泛而深入的研究。Liu等[2]使用基于閾值分割的方法來提取裂縫區域,此方法雖簡單,但易受光照、紋理、噪聲的影響,適用范圍有限。針對此問題,Landstr?m等[3]利用形態學方法和邏輯回歸統計方法來檢測鋼鐵產品上的裂縫,雖然噪聲得到抑制,但是造成了過度分割,誤檢嚴重。孫波成等[4]通過使用小波技術對道面圖像進行多分辨率二維小波分解,突出邊緣位置,增強裂縫邊緣提取效果,該方法雖然一定程度上可以抑制噪聲,但是需要調整小波與分解水平。Nguyen等[5]提出的自由形式各向異性裂縫檢測算法(Free?form anisotropy,FFA)在綜合考慮了亮度和連通性后對道路進行裂縫檢測,該算法在背景簡單的裂縫圖像上檢測效果較好,但是對圖像中陰影與標線區域比較敏感,容易形成誤檢。Shi等[6]提出了基于隨機結構化森林的道路裂縫自動檢測算法(Automatic road crack detection using random struc?tured forests,CrackForest),該算法融合了多個層次的互補特征來表征裂縫,在某種程度上可以將裂縫與噪聲進行區分,但是CrackForest算法是基于人為設定的特征進行裂縫檢測,對于復雜背景、低對比度的裂縫識別能力不佳。機場道面具有紋理復雜、噪聲強、對比度低的特點,同時跑道上還存在飛機輪痕和橡膠污染等干擾因素,因此,傳統的裂縫檢測算法與機器學習算法并不能對機場道面裂縫進行有效檢測。
伴隨深度學習技術廣泛應用于各領域,其在圖像分類與識別等方面取得了巨大成功,研究者對基于深度學習的圖像裂縫檢測進行了深入研究。Deng等[7]使用Faster R?CNN[8]算法用于復雜背景的混凝土橋梁裂縫檢測,存在漏檢和精度差的問題。針對此問題,Fang等[9]提出了一種基于深度學習模型和貝葉斯概率分析的圖像裂縫檢測方法,精度得到了一定程度提升。Fan等[10]首先將采集的圖像分割成帶有裂縫的圖像塊,然后使用深度學習網絡分割裂縫,但是裂縫分割結果太寬,精度較差。曹錦綱等[11]通過在編碼器?解碼器結構中加入注意力機制,構建了一種基于注意力機制的裂縫檢測網絡,提高了公路路面裂縫檢測的性能。文青[12]使用Mask R?CNN[13]算法檢測建筑物表面裂縫,裂縫的分割結果是源于檢測結果,由于候選框提取不準確,導致裂縫分割結果較差。Liu等[14]提出了一種深層次卷積神經網絡(A deep hierarchi?cal feature learning architecture for crack segmenta?tion,DeepCrack),通過引入監督網絡與條件隨機場進行像素級端到端的語義分割,該網絡在一定程度上提高了裂縫分割能力,但是存在較多誤檢的問題,尤其當病害與背景對比度變化不大時,誤檢較重。Dung[15]使用全卷積網絡(Fully convolutional networks for semantic segmentation,FCN)[16]對 混凝土裂縫進行檢測,采用編碼器?解碼器結構,在一定程度上提升了裂紋檢測能力,然而由于反卷積只采用了最后一層卷積層的特征,導致其在裂縫分割階段邊緣模糊,細節信息未能得到較好的表達。但是多尺度特征融合[17?18]可以生成語義信息更加豐富的高分辨率特征圖,有助于對裂縫這種小目標特征的提取。
因此,本文構建了一種基于可變形卷積與多尺度特征融合的機場道面裂縫檢測網絡(Deformable convolution and feature fusion neural network,DF?Net)。該網絡基于編碼器?解碼器網絡框架,在編碼器階段通過可變形卷積[19]模塊與多尺度卷積模塊加強對形態多樣的裂縫特征的學習,在編碼器階段使用特征融合模塊融合低層特征與高層特征,達到抑制噪聲,恢復裂縫細節的目的,從而提升機場道面裂縫檢測性能。
1 基于可變形卷積與特征融合的裂縫分割模型
本文提出的DFNet網絡模型包含了3個模塊,分別為可變形卷積模塊(Deformable convolution module,DCM)、多尺度卷積模塊(Multi?scale con?volution mudule,MCM)和特征融合模塊(Feature fusion module,FFM),其詳細網絡模型結構如圖1所示。首先,將原始彩色圖像輸入可變形卷積模塊,根據所設計的可變形卷積模塊來提取形態各異的裂縫特征,增強網絡對裂縫形態特征的學習;其次,使用多尺度特征提取模塊獲得不同感受野下的裂縫特征,使得提取的裂縫特征包含更多的全局信息;最后,在特征融合模塊中,將不同階段低級特征與高級特征進行融合,細化裂縫分割結果。

圖1 DFNet模型結構圖Fig.1 Structure diagram of DFNet model
1.1 可變形卷積模塊
裂縫分割的一大挑戰在于裂縫具有形態多樣、方向多變的細線性特征,即使通過大量的數據也很難使常規的卷積網絡完全學習到各種形態的裂縫特征。因為構造卷積神經網絡所用的模塊幾何結構固定,其幾何形變建模能力有限,這種局限性決定了常規卷積只能在輸入特征圖固定位置提取裂縫特征,大大減弱了裂縫特征的表征能力。針對此問題,本文引入了具有空間幾何形變能力的可變形卷積,可變形卷積通過可變形的接收場自適應地捕獲裂縫的各種形態與尺度信息,如圖2所示,展示了普通卷積與可變形卷積提取裂縫信息的方式。

圖2 3×3普通卷積與可變形卷積示意圖Fig.2 3×3general convolution and deformable con?volution
可變形卷積計算建立在普通卷積之上,且不需要額外的監督機制。普通的二維卷積計算包括兩個步驟:(1)使用規則網格G對輸入特征圖x進行采樣;(2)對采樣點進行加權求和。網格G定義了感受野的大小和膨脹率。此處定義了一個3×3大小、膨 脹 率 為1的 網 格G,G={(-1,-1),(-1,0),…,(0,1),(1,1)}。因此,對于輸入特征圖x上p0的輸出特征映射y可以定義為
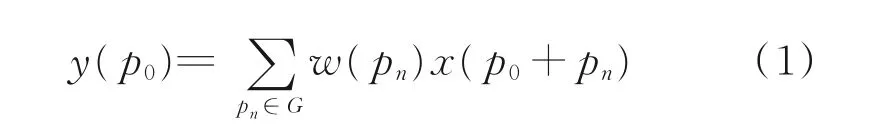
式中:pn為枚舉G中的點,w(*)為采樣點權重。而可變形卷積是在標準卷積的常規網格采樣位置G上增加了Δpn偏移量,{Δpn|n=1,2,…,N},其中N=|G|。此時,特征圖采樣位置變為pn+Δpn,因此式(1)可變為

由圖2與式(2)說明卷積層利用與輸入特征映射具有相同空間分辨率的偏移矢量,使得原采樣點向外擴展以聚焦于裂縫輪廓。可變形卷積提取裂縫特征的過程如圖3所示,對于輸入網絡的裂縫特征圖,為了學習偏移量Δpn,可變形卷積在原有卷積上附加一層卷積。在訓練期間,生成輸出特征的卷積核與偏移量同時學習裂縫的特征信息,而偏移量由附加卷積層學習得到,組成了偏移域,其中通道維度2N對應于N個2維偏移量(包括x方向與y方向)。由于Δpn通常不是整數,為了有效地學習偏移量,采用雙線性插值算法確定偏移后采樣點的值。由于可變形卷積可使采樣點自由變換,因此在提取特征過程中就可以根據裂縫的形態進行動態調整,從而學習不同形態裂縫的幾何形變,這種自適應確定裂縫形變尺度與位置的方法對裂縫特征提取具有較大的影響。

圖3 可變形卷積特征提取過程Fig.3 Deformable convolution feature extraction process
1.2 多尺度卷積模塊
由于裂縫分布不均,長短不一,裂縫檢測常存在較大尺度上的變化,而單一尺寸卷積核具有固定尺度,在提取目標特征上存在一定的局限性。針對該問題,本文設計了多尺度卷積模塊,如圖4所示。模塊中引入了4種不同大小的卷積核,可以獲得多種尺度感受野,對輸入特征圖在不同卷積核上提取裂縫特征,并對其進行特征融合。

圖4 多尺度特征提取模塊Fig.4 Multi?scale feature extraction module
通過1×1卷積操作,在不改變特征圖大小的情況下有效減少參數量,增加非線性特征和增強通道之間信息的交流。該模塊使用不同大小的卷積核并列提取裂縫特征,不僅增加了網絡的深度也增加了網絡的寬度。更深的網絡具有更強的非線性表達能力,可以學習裂縫更復雜的特征;增加網絡的寬度,使每一層學習到更多的裂縫特征,包括亮度、頻率、紋理等特征。多尺度特征提取模塊通過控制不同大小感受野,可以提取裂縫更加全面的信息,對于裂縫特征的學習具有增強作用。
1.3 特征融合模塊
卷積神經網絡不同層次的特征旨在編碼不同層次的信息,高層特征聚焦于目標的語義信息,而低層特征包含更多細節信息,低層特征提取器可以捕獲局部實例級別的細節信息。由于裂縫具有細而長的特征,在提取裂縫特征過程中,保留邊緣信息至關重要,因此在特征融合模塊中融合了裂縫的語義信息和細節信息。
該模塊的設計采用由牛津大學視覺幾何組(Vi?sual geometry group,VGG)提出的VGG?19模型。本文期望得到不同尺度的有意義的側輸出,由于5次池化后產生的特征圖很小,通過反卷積得到的裂縫預測特征圖比較模糊,無法生成精確的分割結果,而且全連接層屬于計算密集型網絡,會大大增加計算時間與內存消耗,因此舍棄了第5次池化后產生的特征圖與全連接層。另外,不同卷積層之間的信息可以互補,而傳統的網絡結構特征融合的方法存在信息利用率不足的問題,多數網絡只采用了池化前的最后一層卷積層。由于每一層的卷積網絡都保存了本次卷積所提取的特征,為了充分利用特征信息,達到更好的分割效果,在DFNet模型中改進了該網絡,結構如圖5(a)所示,對側輸出進行上采樣之前,先把每一個階段產生相同尺寸的特征圖進行相加融合,然后對其進行反卷積操作,得到與原圖相同尺寸的特征圖,再使用Concatenate函數融合特征向量,最后,得到DFNet模型預測的分割結果。
特征融合模塊每個卷積階段的側輸出結果,如圖5(b)所示,其側輸出分別對應圖5(a)中的側輸出,將其進行融合后的效果明顯優于某一階段效果,可發現融合后裂縫邊緣更明顯,圖像噪聲更少,更接近標簽。

圖5 特征融合模塊Fig.5 Feature fusion module
對于輸入圖像,低層特征很好地保留了裂縫區域邊界,適用于提取細節信息,但是噪聲較多。相反,高層特征顯示出更好的抗噪聲能力,但無法保留精確的分割邊界。因此,線性融合不同卷積階段提取的特征可以達到抑制噪聲,明確分割邊界的良好效果。
2 實驗結果與分析
本文算法基于深度學習開源框架TensorFlow實現,使用Python編程語言,程序的運行環境是主頻為3.2 GHz的i7?8700CPU處理器,64GB的運行 內 存,GPU為GeForceGTX1080ti,11GB顯 卡內存,操作系統為Ubuntu18.04 。
2.1 數據集
本文所用裂縫數據來源于國內多個機場,裂縫數據是由合作單位成都圭目機器人有限公司自主研發的機場道面檢測機器人自動采集完成。道面檢測機器人搭載的相機是加拿大Teledyne DAL?SA公司研發的CMOS面陣相機nano m1920。具體的采集方法是將相機以某一高度固定在機器人上,提前為機器人設定行駛路線,機器人以20~30km/h的速度在機場跑道連續拍照,采集圖像,機場道面檢測機器人如圖6所示。本文從拍攝的圖像中選取了960張帶有裂縫的圖像,圖像為1800像素×900像素大小。為了方便訓練模型,采用窗口滑動算法將數據集按照512像素×512像素大小進行裁剪,然后經過水平翻轉、垂直翻轉、旋轉變換等操作來增強數據,得到12960張512像素×512像素大小圖像。最后采用隨機分類算法按8∶1∶1的比例將數據集分為訓練集10368張,驗證集1 296張以及測試集1296張。

圖6 機場道面檢測機器人Fig.6 Airport road surface detection robot
2.2 實驗參數設置
本文算法在訓練過程中,Batch size設置為2,優化器選用Adam,初始學習率為le-5,損失函數為交叉熵損失函數(Cross entropy loss),網絡激活函數選用ReLu,Shuffle設置為True。
2.3 訓練過程分析
圖7展示了DFNet模型在訓練過程中訓練損失和驗證損失的變化情況,藍色曲線代表訓練損失,黃色曲線代表驗證損失。從圖中可看到,在訓練過程中損失函數值迅速下降,在訓練初期兩個損失函數值有較大波動,隨著迭代輪數增加兩個損失值逐漸穩定趨于收斂,并且在第50次時驗證損失取得了最佳值,隨后訓練次數增加驗證損失函數值逐漸發散,可能導致過擬合。因此根據損失函數值變化情況,本模型在迭代50次時,性能最佳。

圖7 訓練過程中損失值曲線變化Fig.7 Loss value curve change during training
2.4 算法評價指標
為了對本文提出的機場道面裂縫檢測算法DFNet進行量化評估,本文采用精確率(Pixel ac?curacy,PA)、交并比(IoU)、準確率(Precision)、召回率(Recall)和F1?Score對結果定量分析。精確率PA是指正確預測像素的個數與圖像中的像素總數的比值;交并比是指裂縫預測區域和標簽區域兩者之間交集與并集的比例;準確率Precision表示裂縫區域被正確檢測出來的像素個數占被檢測出來的像素總數的比例;召回率表示裂縫區域被正確檢測出來的像素個數占應該被準確檢測出來的裂縫 區 域 像 素 個 數 的 比 例;F1?Score是Precision與Recall的綜合評價指標。在二分類分割任務中,評價指標分別定義如下

式中:TP表示裂縫區域被正確檢測出來的像素點個數,FP表示背景區域被預測為裂縫像素點的個數,FN表示裂縫區域被預測為背景的像素點的個數,TN表示背景區域被正確檢測出來的像素個數。
2.5 對比算法
為了驗證DFNet的有效性,在所采集的機場道面裂縫數據集上,將DFNet與Canny、FFA、CrackForest、FCN、U?net[20]以及DeepCrack六種算法進行了對比分析。其中,Canny算法是一個多級邊緣檢測算法,通過采用高斯濾波來平滑圖像,去除噪聲,應用雙閾值的方法來決定潛在的邊緣。在該實驗中雙閾值設置為100和200,使用Python語言調用Opencv中Canny函數實現。FFA算法考慮了裂縫圖像亮度與連通性,是一種專門用于路面裂縫檢測的算法。CrackForest是一種基于隨機結構化森林的新型道路裂縫檢測框架。DeepCrack算法是專門用于裂縫分割的,通過引入監督網絡與條件隨機場以端到端方法像素級預測裂縫區域。FCN使用VGG16為骨干網,使用跳躍連接結構進行特征提取,采用全卷積網絡輸出與原圖相同大小的裂縫預測圖。U?net網絡采用對稱式編碼器?解碼器框架提取裂縫特征。
2.6 對比實驗結果
本實驗將從定量和定性兩個方面評估DFNet算法。表1展示了各個算法在機場道面裂縫數據集中定量比較的結果。從表1中可以看出,DFNet算法在精確率、IoU、準確率、召回率以及F1?Score上均取得最優的結果,分別為99.59 %、56.20 %、92.21 %、89.72 %和90.95 %。由于所用機場道面裂縫數據集背景復雜,在所對比的算法中,Canny算法、FFA算法和CrackForest算法受道面噪聲影響較大,在圖像背景對比度低時檢測效果不佳,無法準確分割裂縫區域與背景區域,誤檢漏檢嚴重,因此導致Precision、Recall和F1?Score較低。從表1中可知深度學習算法整體表現優于傳統算法與機器學習算法,FCN、U?net、DeepCrack和DFNet在該數據集上均取得了較好的分割結果。其中DFNet性能最佳,Precision高達92.21 %,遠遠領先于其他算法。

表1 DFNet與其他算法對比結果Table1 Comparison results between DFNet and other algorithms %
圖8所示為部分數據可視化結果,由圖8可以看出:當圖像背景良好,裂縫區域與背景區域有顯著差異時,7種算法均可將裂縫較好地提取出來(如圖8第1列數據)。當道面圖像受到標線、噪聲、水漬和拉毛影響時,Canny算法、FFA算法以及CrackForest算法受到本身算法的局限性,均未能較完整地提取裂縫區域,同時出現了多處誤檢與漏檢。U?net算法在有水漬背景時檢測效果較差,出現不同程度的漏檢(如圖8第3列與第5列數據),這是由于U?net網絡屬于淺層網絡,在提取裂縫高維特征時回歸效果較差,未能全部檢測出水漬中的裂縫。DeepCrack算法受到標線的影響,在標線與裂縫重疊區域出現漏檢,因此導致該算法精度較高,召回率較低。FCN算法存在分割邊緣模糊的問題。由于FCN網絡將特征圖直接還原為原始尺寸圖像,使其細節表達不佳,導致分割結果不精確。從圖8可視化效果中可以看到DFNet可以準確地提取不同背景下裂縫的特征。通過從定量與定性兩方面的分析,DFNet算法在機場道面裂縫數據集上取得了更優的檢測效果。

圖8 不同算法結果對比Fig.8 Comparison results between different algorithms
2.7 消融實驗
DFNet架構設計采用了模塊化的概念,每個模塊都是相對獨立設計的,允許根據需要來設定與升級網絡。為了驗證DFNet模型中可變形卷積模塊(DCM)、多尺度模塊(MCM)以及特征融合模塊(FFM)的有效性,本文開展如下消融實驗,實驗結果如表2所示。從DFNet中去掉可變形卷積模塊,裂縫的IoU、Recall與F1?Score均有不同程度的下降,實驗結果表明,具有空間幾何形變能力的可變形卷積具有更強的捕獲裂縫特征的能力。DFNet網絡去掉多尺度模塊后,裂縫的IoU、Precision、Re?call與F1?Score分別下降1.42 %、0.83 %、1.54 %與1.19 %,這表明使用不同大小卷積核的多尺度模塊有助于DFNet在較大感受野下獲得更多的裂縫病害信息。保持其他不變,去掉特征融合模塊后,雖然準確率取得了最高值,但是召回率下降較多,因此導致綜合評價指標IoU與F1?Score分別下降2.2 %與0.77 %。由表2消融實驗可知,同時加入這3個 模 塊,DFNet在 綜 合 評 價 指 標IoU與F1?Score上取得最高值,且召回率達到了最高,驗證了DCM、MCM和FFM的有效性。從工程應用的角度來看,必須有效地檢測所有裂縫。因此,提高機場道面檢測中裂縫分割的召回率,顯得更加重要。

表2 DFNet不同模塊有效性的驗證Table2 Verification of the effectiveness of different DF?Net modules %
3 結 論
本文針對機場道面裂縫檢測效果不佳的問題,采用深度神經網絡,通過設計可變形卷積模塊、多尺度模塊和特征融合模塊,構建了一種基于可變形卷積與特征融合的機場道面裂縫檢測網絡。實驗結果表明,本文算法能準確地對機場道面裂縫進行分割,提高了機場道面裂縫檢測的性能,為機場道面檢測人員減少工作量以及對道面的養護與管理提供了一定的理論依據。但該模型距離實時檢測仍有一段差距,同時模型的檢測精度與準確性仍有改善空間,需要進一步研究。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
中華詩詞(2020年1期)2020-09-21 09:24:52
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(中高年級適用)(2018年5期)2018-06-11 01:22:56
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中學生數理化·七年級數學人教版(2017年11期)2017-04-23 07:18:00
