改進進化算法的貝葉斯網絡結構學習及其應用
2022-01-13 10:23:48郭文強毛玲玲黃梓軒肖秦琨郭志高
河南科技大學學報(自然科學版) 2022年2期
郭文強,毛玲玲,黃梓軒,肖秦琨,郭志高
(1.陜西科技大學 電子信息與人工智能學院,陜西 西安 710021;2.西安工業大學 電子信息工程學院,陜西 西安 710021;3.倫敦瑪麗女王大學 電子工程與計算機科學學院,倫敦 E1 4NS)
0 引言
貝葉斯網絡(Bayesian network,BN)是概率圖模型的重要研究方向,主要用于表征和解決不確定性問題[1],并在故障溯源、醫療診斷和金融學習等領域得到了廣泛的應用[2]。BN研究主要由結構學習、參數學習和推理3部分組成[3],其中,結構學習是BN構建與應用的基礎與核心[4]。文獻[5]提出了最大最小爬山(max-min hill-climbing,MMHC)算法,通過條件獨立性構建初始結構,并結合爬山法學習貝葉斯網絡結構,但算法存在學習耗時過長,且容易陷入局部最優的問題。進化算法(evolutionary algorithms,EA)使用啟發式搜索策略能夠在一定程度上避免算法陷入局部最優,主要通過種群中個體的選擇、重組和變異等基本操作實現優化問題的求解。文獻[6]基于最大信息系數和微生物遺傳算法提出了一種新的貝葉斯網絡結構學習,但耗時長,初始種群數目等先驗參數的確定缺乏客觀依據,存在一定的進化搜索盲目性等問題。
為解決上述問題,本文基于最大支撐樹(most weight supported tree,MWST)[7]和EA,提出了一種新的貝葉斯網絡結構學習算法MWST-EA。該算法將結構學習轉化為進化問題后,先建立最大支撐樹來得到種群中節點的父節點數目上限,采用本文設計的種群數目計算函數可以計算出種群數目;同時,采用條件獨立性測試獲得初始結構來限制搜索空間。其次,采用設計的變異函數來控制基因突變,可以提高算法的局部搜索能力,防止陷入局部最優。最終,通過種群的迭代操作學習出BN結構。
糖尿病是一種不可治愈的慢性疾病,據國際糖尿病聯盟統計,截至2020年,全球糖尿病患病率約為9.3%[8]。目前糖尿病的發病機制尚未完全明確,多數學者認為在糖尿病病程發展的過程中,有多種因素對其產生作用,具有極大的不確定性。僅僅依靠醫生個人經驗的診斷方式,容易出現病情診斷不及時的情況。將糖尿病與機器學習相結合來輔助醫生診斷,將在很大程度上提高診斷的智能性和實時性。文獻[9]運用正余弦優化算法和神經網絡相結合,為糖尿病的自動化診斷提供了一種智能方法。文獻[10]提出了一種遺傳算法模型用于糖尿病風險預測,輔助醫生進行早期干預。文獻[11]使用樸素貝葉斯(naive Bayes,NB)和支持向量機(support vector machine, SVM)等分類技術對糖尿病進行了預測。
本文將MWST-EA應用于加利福尼亞大學歐文學院分校David Aha博士搭建的UCI數據庫中的糖尿病數據集[12]上,建立貝葉斯網絡結構分類模型,取得了較好的結果。
1 貝葉斯網絡結構學習改進算法MWST-EA
在貝葉斯網絡結構中,事件節點容易確定,但節點間的關系錯綜復雜難以確定,并且從數據中學習貝葉斯網絡結構是一個難題。因此,本文提出了一種改進型進化算法MWST-EA,來確定貝葉斯網絡節點和節點間的依賴關系。
1.1 初始種群建立及個體父節點上限確定
進化算法的種群難以確定,且會影響算法的執行效率和穩定性。本文結合BN結構特點設計了一種確定進化算法種群數目下限的函數,如式(1)所示:
(1)
其中:A為所需的種群數量;λ為變量概率分布的偏度,本文取1;d為BN模型中節點最大父節點個數;ζ為節點的最大狀態數;σ為BN模型的Kullback-Leibler(KL)距離,常取0.1;ζ為置信度,常取0.05。
設計的MWST-EA算法從完全無向圖開始,為縮小BN結構的搜索空間,將條件獨立性測試應用于所有的節點之間。當兩個節點之間相互獨立,移除節點之間的邊,并據此得到初始結構BN0。采用式(1)中的A作為初始種群大小。然后,對初始結構中邊連接的兩個節點,隨機選擇邊狀態,以生成初始種群,并采用GR算法[13]對初始種群個體中產生的環即非法結構進行修正,從而得到結構BN1。
個體在交叉、變異的過程中,一個節點可能會存在多個父節點,顯然,初始父節點的個數影響著算法的收斂速度。本文利用互信息構建MWST確定可能的個體父節點上限(individual parent node upper limit, IPI)數目,實現對種群中節點的父節點數量的限制,從而提高學習算法的效率。互信息[14]表示兩個變量間的相互依賴關系,以任意兩個變量X、Y為例,互信息I(X,Y)為:
(2)
其中:p(X,Y)為變量X和Y的聯合概率;p(X)為變量X的概率;p(Y)為變量Y的概率。
MWST算法首先根據節點數據計算所有節點之間的互信息,通過把所有節點間的互信息從大到小進行排列,不斷選取互信息最大的邊加入最大生成樹,并且遍歷所有的節點,來完成MWST的建立。本文依據MWST中最大節點度,選擇具有最大節點度的節點作為算法中的個體父節點上限數目。圖1為個體父節點上限確定。以圖1a所示的經典貝葉斯網絡中的ASIA網絡模型為例,根據MWST算法得出最大支撐樹(見圖1b),可看出節點6具有最大節點度(見圖1c),因此該網絡的IPI由節點6決定,其值為3。

(a) ASIA網絡模型 (b) 圖1a的MWST (c) 最大節點度圖1 個體父節點上限確定
1.2 MWST-EA新個體的產生及種群更新
1.2.1 評分函數及個體的選擇、交叉
本文采用BDeu評分函數對個體評分,以評分最高的個體作為精英個體x*。設X={X1,X2,…,Xn}是一組變量集合,D={D1,D2,…,Dn}是關于變量的樣本集合,G是關于變量集的BN結構。假設數據集滿足獨立同分布條件假設,則BDeu評分如式(3)所示[15]:
(3)

為提高種群的局部尋優能力,挑選評分高的一半個體進行交叉操作。均勻交叉算子的性能較為優越[16],利用均勻交叉算子組合生成新的個體,在搜索空間進行有效搜索,同時降低對種群有效模式的破壞概率。
1.2.2 精英集構建及候選父節點數目限制
建立精英集e,以精英集中的每個個體作為種群的領導者,可以保證算法的尋優能力。
(4)
其中:精英資格閾值β∈[0.5,1];f(xk)為每個個體的評分;fbest為精英個體的評分。為了保持精英集的多樣性,以增加進化算法的搜索能力,β在每次種群更新時的變化依據DiG-SiRG算法[17]。
MWST-EA將個體具有可變狀態的邊定義為位點,位點中每組有值的組成部分被定義為等位基因。構建邊頻次權重EFW=(wi,j),wi,j對應于等位基因i∈{b,←,→},即“無邊”、“反向邊”、“正向邊”出現的概率,j∈{1,2,…,L}(L為個體長度)。wi,j是精英集合中位置j處等位基因i出現的概率。
其中:當個體xk在位點j的等位基因等于i時,δ函數δ(xk,j=1)等于1。
有效地限制候選父節點數目,能加快BN結構尋優速度。采用父節點重復權重來選擇要刪除的邊以限制父節點數量。父節點重復權重是為每個節點定義的鍵值向量,其中鍵值由其父集中節點的索引給出,代表整個精英集中邊(父節點→節點)出現的概率,由個體的評分決定。為每個節點Xt填充與邊相關的概率(父(Xt)→Xt),通過隨機排序為每個節點Xt構建父節點重復權重,刪除出現概率最小的邊。ASIA網絡父節點限制如圖2所示。

圖2 ASIA網絡父節點限制
以圖1a的ASIA網絡模型為例,個體父節點上限設置為3,精英集由圖2中的3個精英集個體組成,對其他非精英個體的6節點進行父節點數目限制。要刪除的邊是在精英集中頻率出現最低的邊。個體1要刪除節點2至節點6的有向邊;個體2要刪除節點1至節點6的有向邊和節點5到節點6的有向邊;個體3滿足父節點數量為3的要求,所以不需要刪除節點。通過上述操作來保證每個個體中節點6參與進化、尋優的父節點初始數目不超過3。
1.2.3 個體變異率函數
為避免算法陷入局部最優,本文提出了一種新的變異函數來更新種群。通過上述EFW和精英集為種群中的每個個體xk的每個點j∈{1,2,…,L}計算個體變異率υi,j,如式(6)所示:
(6)
其中:wi,j為EFW的第(i,j)個元素;f(xk)為當前個體的評分;fbest為精英個體的評分;ε為一個極小正數,避免零概率。每個突變率都是基于邊在精英群體中的分布以及個體的評分函數來衡量的。
1.3 MWST-EA結構學習算法步驟
本文提出的MWST-EA結構學習算法步驟如下:
步驟1 設置算法最大迭代次數Iter,利用互信息建立最大支撐樹MWST,由最大節點度得到個體父節點上限數目IPI;采用式(1)計算種群數目。
步驟2 采用條件獨立性測試獲得初始結構,生成初始種群P0,利用GR算法[13]修正種群中個體產生的非法結構。
步驟3 依據式(3)對每個個體進行評分,挑選評分高的一半個體作為新種群P1進行均勻交叉操作,得到種群P2。
步驟4 對種群P2評分得到精英個體,將個體評分與P2代入式(4)構建精英集e。
步驟5 依據個體評分函數和將精英集e代入式(5)構建邊頻次權重。
步驟6 構建父節點重復權重對種群P2中個體的父節點個數進行限制,得到種群P3。
步驟7 利用式(6)計算個體的突變率,對種群P3進行變異操作增加種群的多樣性,得到新種群P。
步驟8 若當本次迭代達到迭代次數Iter, 則輸出精英個體對應的BN結構模型;否則轉至步驟3, 進行迭代計算。
2 MWST-EA結構學習算法仿真實驗
實驗采用的編程環境為Windows10系統,處理器為Intel 酷睿i7 4712MQ(2.3 GHz),8 G內存,開發語言為MATLAB R2016b。為驗證MWST-EA的BN結構學習性能,基于經典BN模型-Alarm網[2]進行仿真實驗,Alarm網包含37個節點和46條邊。為體現本文算法的優越性,在相同實驗條件下,與MMHC算法、傳統EA進行實驗對比及結果分析。
實驗中以Alarm網絡作為基礎,隨機生成數據容量分別為500、1 000、3 000和5 000的訓練數據樣本集,利用MWST-EA進行10次仿真實驗,結果取平均值以減少隨機性影響。實驗中設置種群迭代次數Iter為100,模型置信度ζ取0.05,精英資格閾值α為0.9。由式(1)計算得到種群數目為101。
表1為不同數據量下各算法學習Alarm網的BDeu平均評分對比,表2不同數量下為各算法學習Alarm網的平均運行時間。
由表1可知:MWST-EA在不同數據量的情況下,得到的BDeu評分優于MMHC和傳統EA等算法。
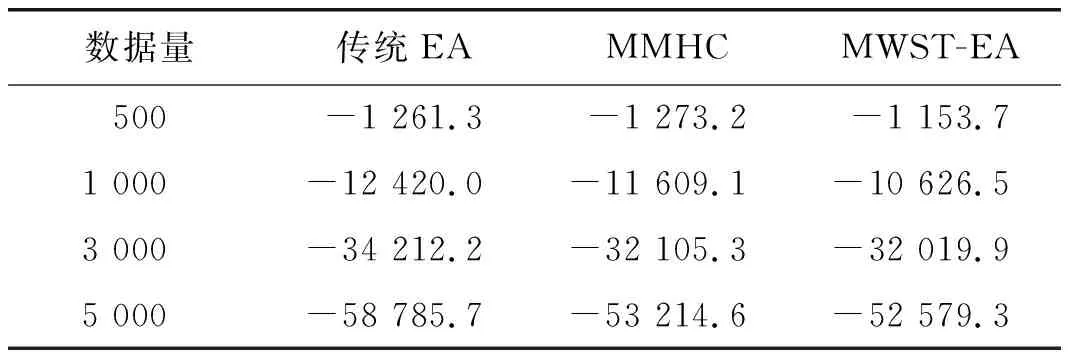
表1 不同數據量下各算法學習Alarm網的BDeu平均評分
原因是MMHC算法搜索能力有限,而傳統EA啟發函數容易陷入局部最優。本文提出了改進的變異函數來更新種群,可以有效防止進化過程陷入局部最優,從而學出更好的BN模型。
由表2可知:MWST-EA運行時間明顯小于MMHC算法耗時,同時也優于傳統EA。原因是MWST-EA采用了有效的種群數目和節點的個體父節點數目限定策略,縮小了算法的搜索空間,因此算法的執行效率較高。

表2 不同數據量下各算法學習Alarm網的平均運行時間 s
將本文算法學習得到的網絡結構與Alarm網原模型進行對比,計算得到網絡與標準網中相同邊的數量(samesides,SS)、增加邊的數量(added sides,AS)和丟失邊的數量(missing sides,MS)。Alarm學習得到的相同邊、增加邊和丟失邊數量統計如圖3所示。
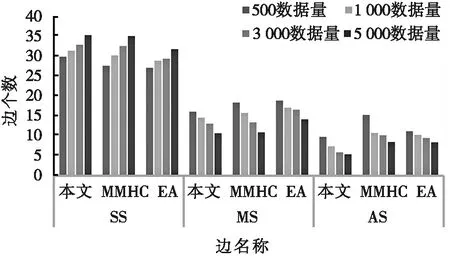
圖3 Alarm網絡仿真對比
通過圖3對比可知:在Alarm網絡中,MWST-EA的相同邊個數,在不同數據量下,均大于MMHC算法和傳統EA;MWST-EA的丟失邊、增加邊個數也小于其他算法。這是由于算法生成了較好的初始種群,用改進的變異函數來更新種群,提高了算法尋優的能力。
綜上所述,MWST-EA結構學習算法速度快于MMHC算法和傳統EA,且結構尋優能力更強。
3 MWST-EA在糖尿病診斷中的應用
3.1 實驗設置
本節實驗條件與上節實驗的設置相同,所采用的UCI數據庫中糖尿病數據集[12]包含520個實例信息,每個實例中包含17條屬性,對數據庫中的屬性做屬性標簽,其中,節點1設置年齡段19~35歲為狀態1,36~59歲為狀態2,60歲及以上為狀態3;節點2設置性別Male為狀態1,Female為狀態2;節點3~16中,Yes為狀態1,No為狀態2;節點17設置Positive為狀態1,Negetive為狀態2。數據集描述如表3所示。
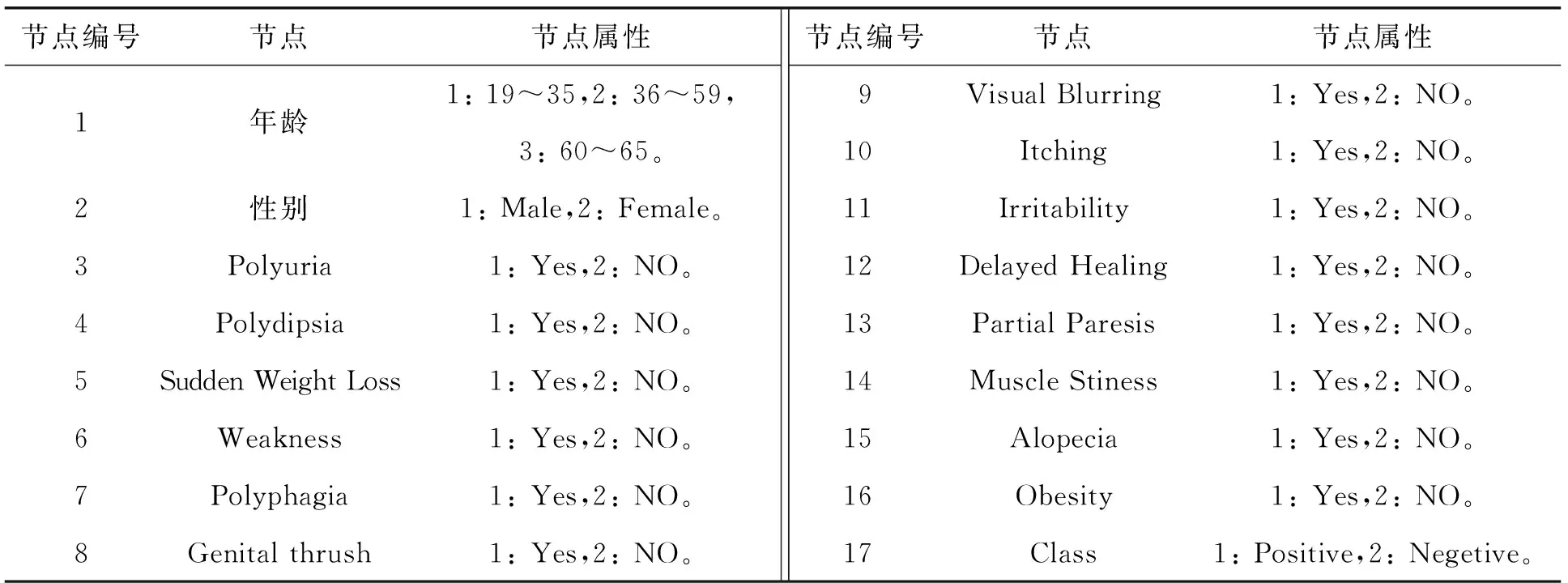
表3 數據集描述
為了驗證本文提出的基于MWST-EA結構學習算法的糖尿病診斷方法的有效性,采用十折交叉驗證法,將糖尿病數據庫中的468組數據用來訓練,52組數據用來測試。對10次實驗結果取平均值進行性能評價。
3.2 基于MWST-EA的糖尿病分類模型
采用MWST-EA,首先依據樣本中各節點的數據來計算互信息。圖4為糖尿病數據模型構建。將互信息從大到小排序,遍歷所有的節點來確定糖尿病數據構成的最大支撐樹模型,以此確定種群中每個個體的各節點的父節點數量上限數目,如圖4a所示;接下來,對所有節點之間進行獨立性測試,據此得到初始結構用來構建種群,其初始結構如圖4b所示;依據3.1節參數設置,由式(1)計算得到種群數量為108,初始化種群之后,采用MWST-EA對種群進行多次迭代得到最優的貝葉斯網絡結構圖,如圖4c所示。
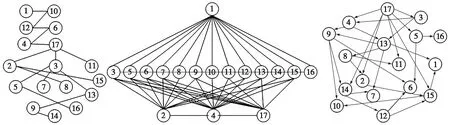
(a) 最大支撐樹模型 (b) 初始結構 (c) 糖尿病分類模型的BN結構
由文獻[12,18]可知,糖尿病與性別、多尿、多飲、體質量突然減輕、煩躁、肌肉僵硬、脫發等有關。由圖4可直觀地看到:糖尿病與節點2、3、4、5、11、14、15有直接依賴關系。由此可見,MWST-EA學到的模型與專家經驗相吻合,具有較強可解釋性。
3.3 實驗分析
貝葉斯網絡結構學習完成后,用最大期望(expectation maximization,EM)算法[19]對糖尿病分類模型進行參數學習。設置EM算法實驗迭代次數為5 000次,以得到BN模型的參數。在BN結構和參數確定之后,利用BN對是否有糖尿病進行診斷。本文采用聯合樹精確推理算法[20]來進行BN推理。將推理結果與MMHC、傳統EA、NB[11]和SVM[11]等算法進行對比,實驗結果如表4所示。
由表4可以看出:SVM算法是目前4種算法中識別率最高的,但MWST-EA與SVM算法相比平均識別率提升了1.54%;與MMHC算法相比,MWST-EA性能提升了11.15%。本文的MWST-EA算法構建出的BN模型結構進行糖尿病診斷識別率有明顯提高。
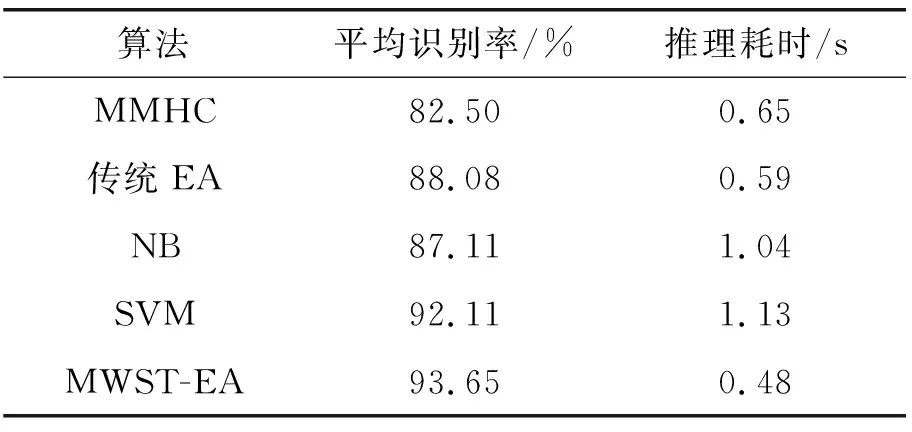
表4 不同建模方法的實驗結果對比
為進一步驗證本文算法的性能,實驗對不同方法在十折交叉驗證情況下的時間進行對比,結果如圖5所示。從圖5中可以看出:本文算法的推理耗時與傳統EA和MMHC算法基本相同,相比NB算法和SVM算法的耗時則明顯降低。這表明MWST-EA算法構建出的BN模型在推理速度方面性能優良。

圖5 不同建模算法推理耗時對比
4 結束語
針對傳統進化算法學習貝葉斯網絡結構存在收斂速度慢、局部搜索能力差以及種群數目確定缺乏依據的問題,本文提出了一種改進進化算法的BN結構學習算法MWST-EA。該算法利用條件獨立性構建初始結構和設計的個體父節點上限數目函數共同作用,減少了搜索的盲目性,縮減了BN結構的搜索空間,提升了算法的尋優效率和收斂速度。采用改進的變異函數可避免算法陷入局部最優。對比實驗結果表明了本文算法在BN結構學習性能的優越性,為智能系統的建模提供了一條新途徑。未來工作將考慮把進化算法與其他算法相結合,學習得到更優的貝葉斯網絡結構。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2022年5期)2022-08-24 02:35:42
中老年保健(2022年1期)2022-08-17 06:14:56
中老年保健(2021年5期)2021-08-24 07:07:20
中老年保健(2021年11期)2021-08-22 03:15:16
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華詩詞(2019年7期)2019-11-25 01:43:04
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
