基于信息矩陣估計的極化碼參數盲識別算法
2022-02-23 07:49:16劉鑒興張天騏柏浩鈞葉紹鵬
系統工程與電子技術 2022年2期
關鍵詞:信息
劉鑒興, 張天騏, 柏浩鈞, 葉紹鵬
(1. 重慶郵電大學通信與信息工程學院, 重慶 400065;2. 重慶郵電大學信號與信息處理重慶市重點實驗室, 重慶 400065)
0 引 言
極化碼是2009年由Arikan根據信道極化現象提出的一種理論上可以達到香農極限的信道編碼方案,該編碼技術相比于Turbo碼和低密度奇偶校驗(low-density parity-check,LDPC)碼,其優勢體現在編譯碼復雜度低、理論可達香農極限以及在中短碼下擁有更好的誤塊率(block error rate,BLER)性能等。由于極化碼優異的性能,我國提出的極化碼方案被選定為5G中eMBB(增強移動帶寬)場景控制信息信道的編碼方案。現在中國的IMT-2020(5G)推進組已經在實用的場景下對極化碼進行了測試,測試結果滿足國際電信聯盟對于傳輸速率、低通信時延和海量終端連接等要求。極化碼在衛星通信和深空探測方面也有不錯的應用前景。
近幾年來,信道編碼參數盲識別已成為非合作信號處理領域中的研究熱點問題。極化碼是一種非系統線性分組碼,針對線性分組碼的盲識別研究比較多且較成熟。文獻[4]提出秩準法,利用秩虧的現象識別線性分組碼碼長,但是該算法只能用于無誤碼的情況。文獻[5]利用高斯列消元后的分析矩陣,計算出各列列重及其均值和方差,并根據均值差值和方差差值來識別碼長。文獻[6]將循環碼的候選校驗矩陣與二進制流構造的截獲矩陣相乘,并根據判決門限得到的校驗矩陣識別出碼長、同步時刻和生成矩陣。文獻[7]針對里德-所羅門(Reed Solomon,RS)碼提出了一種軟判決算法,遍歷本原多項式進行初始碼根匹配并利用平均校驗符合度識別碼長和本原多項式。除此之外,對于其他信道編碼的盲識別研究也較成熟,比如遞歸型系統卷積碼(recursive systematic convolutional code,RSC)、LDPC碼和Turbo碼。但是目前國內外針對極化碼參數的盲識別研究很少,文獻[14]采用遍歷碼長和刪除概率的方法來構造零空間矩陣,通過與碼字比特流迭代相乘的匹配度來識別碼長和信息比特位數。該方法需要遍歷兩個參數,復雜度較大。文獻[15]通過刪除生成矩陣的一行來構造對偶向量,根據不同碼長的碼率特性來識別碼長和信息比特位數和位置。該方法復雜度也較大,識別碼長時需要正確識別每個碼長下的碼率,這會大大降低可靠性。
由于極化碼屬于非系統碼,其分析矩陣不具有系統碼的一般性質,且沒有Turbo碼碼字與生成多項式之間的關系。所以傳統的方法無法有效地識別極化碼參數。針對極化碼識別困難的問題,本文利用其生成矩陣已知且滿秩這一特性,提出了一種基于信息矩陣估計的極化碼參數盲識別算法。該算法首先利用生成矩陣的逆矩陣和截獲比特流構造的碼字矩陣得到估計的信息矩陣,在無誤碼情況下根據映射之后的分析矩陣所含的信息識別出碼長、信息比特位數和位置分布,在有誤碼的情況下利用分析矩陣在零均值比下的峰值識別出碼長,再根據該碼長的分析矩陣識別出信息比特位數和位置分布。
1 極化碼原理
1.1 信道極化理論
信道極化理論是Arikan在2008年提出的,信道極化分為信道合并和信道分裂兩部分。信道合并指以遞歸的方式將給定的B-DMC(二進制輸入離散無記憶信道)組合成矢量信道::→,這里的,分別表示輸入輸出符號集合,=2,≥0。遞歸從第0階(=0)開始,遞歸的第1階(=1)是將兩個獨立的信道組合成信道:→,如圖1所示。
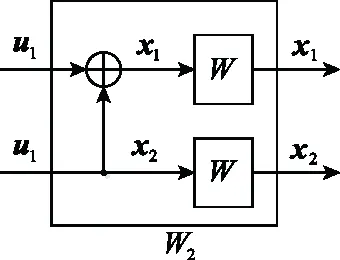
圖1 信道W2Fig.1 Channel W2
根據以上的遞歸規律,可以依次得到信道,,…,,…的結構。信道的結構如圖2所示。
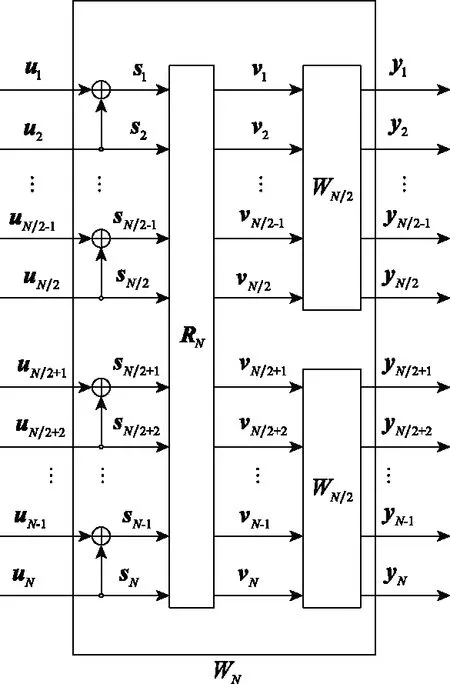
圖2 信道WN的結構Fig.2 Structure of channel WN
圖2中,表示比特翻轉操作,目的是將輸入序列進行重排,先排奇數元素,再排偶數元素。經過Arikan教授的證明,當趨近無窮的時候,子信道的容量會呈現兩極分化,一種是信道容量為1的無噪聲信道,另一種是信道容量為0的純噪聲信道。
信道極化是極化碼的理論依據,其編碼思想就是將信息比特用信道容量為1的無噪聲信道傳輸,凍結比特用信道容量為0的噪聲信道傳輸。
1.2 極化信道可靠性估計
信道可靠性估計是為了挑選出適合傳輸信息比特的信道。Arikan提出使用巴氏參數和對稱信道容量來計算B-DMC的可靠性和信道的傳輸速率。首先介紹巴氏參數()和對稱信道容量()的定義:
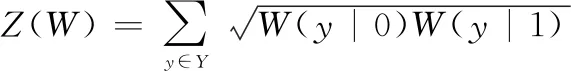
(1)
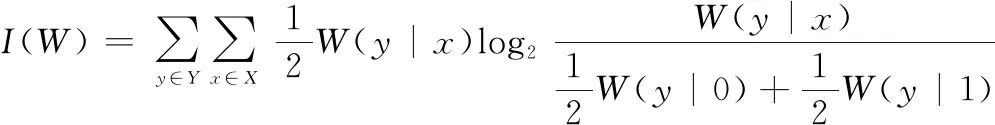
(2)
式中:(|)表示信道轉移概率;()是使用信道等概率傳輸0、1時的最高速率;()是當傳輸0或1時最大似然判決錯誤概率的上限。當刪除概率為時,就有()=,則()∈[0,1]。
對于任意B-DMC對稱容量和巴氏參數之間都有如下關系:
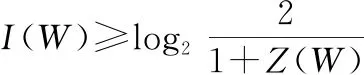
(3)
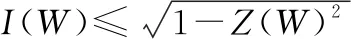
(4)
可以得到當巴氏參數()越小,對稱信道容量()越大,信道就越可靠,反之則()越小,信道就越不可靠。
對于任意B-DMC子信道的巴氏參數計算遞歸過程如下:
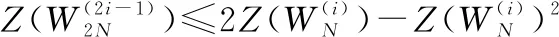
(5)
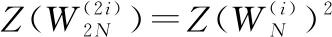
(6)
當信道為二進制刪除信道(binary erasure channel, BEC)時式(5)中可以取等號。根據式(5)和式(6)可以計算出BEC各個子信道的錯誤概率,比較大小就能得到錯誤概率最小的個子信道。圖3給出了BEC信道在刪除概率為0.5時,各個子信道的巴氏參數分布情況。從圖中可以看出經過信道極化后巴氏參數趨近于0和1,即信道的可靠性呈現為兩個極端。
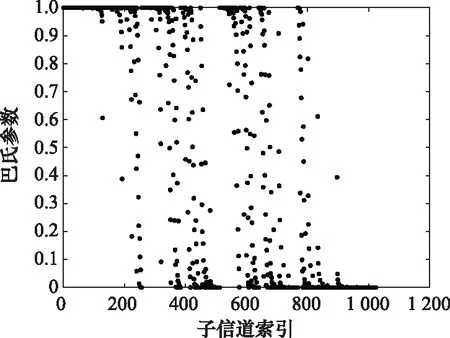
圖3 BEC巴氏參數分布Fig.3 Bhattacharyya parameter distribution in BEC
1.3 極化碼編碼
極化碼是一種二元線性分組碼,其碼字序列可以用信息序列和生成矩陣相乘得到:
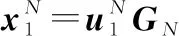
(7)
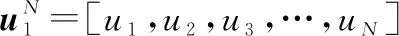
=?
(8)
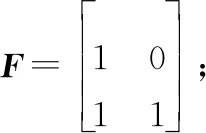
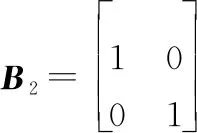
(9)
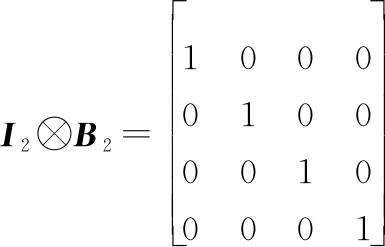
(10)
式中:表示2階單位矩陣。矩陣由變化得到,先將中奇數列排入前2列,再將偶數列排入后2列,和分別表示為
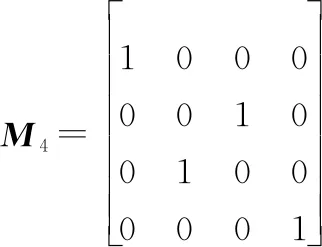
(11)
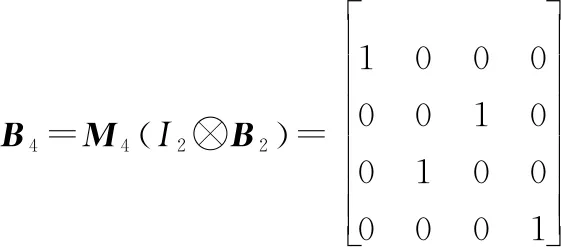
(12)
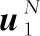
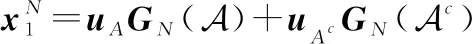
(13)
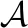
2 極化碼盲識別原理
2.1 識別數學模型
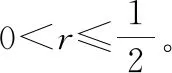
2.2 識別原理
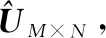
??=,表示=2階單位矩陣。
采用數學歸納法證明
容易證明·=
假設?·?=2
根據克羅內克積運算可以得到?(+1)
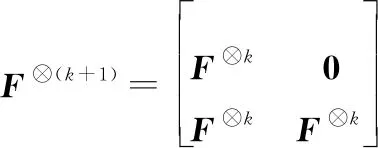
(14)
那么

(15)
則有?·?=。
證畢
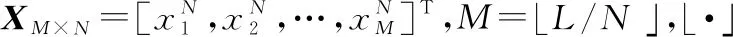
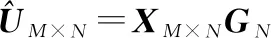
(16)
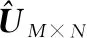
證畢
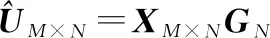
證畢
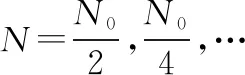
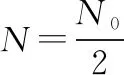
證畢
2.3 極化碼參數識別方法

(17)
式中:×表示×階的全1矩陣。定義()為×第列中元素1的比例減去元素-1的比例,即
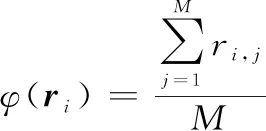
(18)
式中:(=1,2,…,)表示×中第列向量;, 表示×中第行第列元素。當不存在誤碼時,×中凍結比特所對應的列()=1,信息比特所對應的列()會接近于0。當誤碼較小的時候,凍結比特所對應的列中1的比例將遠大于-1的比例,即()值會大于0。當誤碼較大時,凍結比特所對應的列中-1的比例會接近1的比例,即()值會接近0。這時就需要設定合適的門限值來區分對應凍結比特所在位置還是信息比特所在位置。如果在進行碼長遍歷的時候每個碼長下都進行門限的求取和判決,不僅會大大增加復雜度而且還會降低可靠度,當遍歷其中一個碼長時,信息比特位數識別錯誤將會導致整體碼率的識別錯誤。為了規避這個問題本文引入了零均值比的概念:
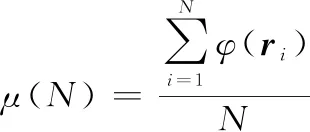
(19)
式中:()表示該碼長下矩陣×中元素1的比例減去元素-1的比例,由于當遍歷碼長小于真實碼長時,碼率會大于真實碼率,這會導致矩陣×中信息比特位置對應的列數增多,×中元素1的比例就會降低,則()會小于真實碼長對應的()。當遍歷碼長大于真實碼長時,碼率等于真實碼率,但是×會包含更多的誤碼,導致其中元素1的比例降低,則()也會小于真實碼長對應的()。所以可以得出結論,當遍歷碼長等于真實碼長時,()會出現峰值。因此,可以作為識別碼長的依據,即
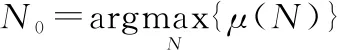
(20)
識別出碼長后,再根據×中各列的()值以及門限識別出信息比特位數以及位置。
2.4 求取門限
由于在實際通信過程中,分析矩陣×會受到誤碼影響,通過分析×中信息比特和凍結比特對應列的(),可以得到兩種不同的分布特性。再根據極大極小準則得到判決門限,×中()<對應列的索引就為信息比特位置,反之為凍結比特位置。具體過程如下。
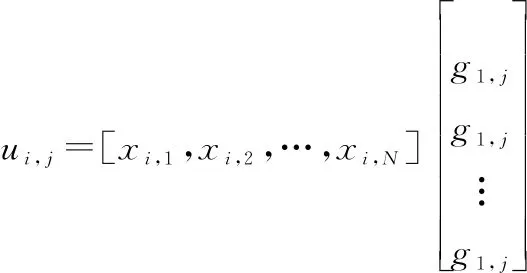
(21)
那么,×中第行第列元素, 就可以表示為
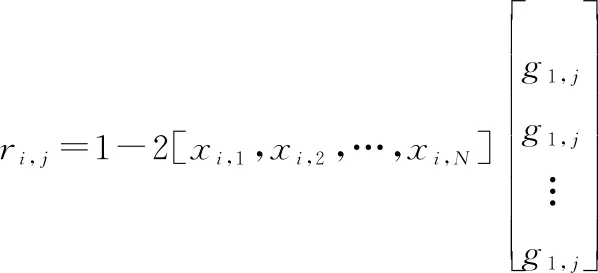
(22)
當誤碼率為時,對應凍結比特所在的位置。, =0要成立,需要誤碼的位置發生在生成多項式系數不為0的位置上,且誤碼個數為0或者為偶數。所以, =0的概率就為
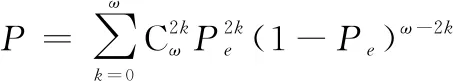
(23)
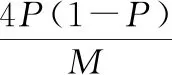

因為在非合作信道中不知道先驗信息,所以采用極大極小化準則來求解門限。假設對應信息比特所在的列的事件為H,對應凍結比特所在的列的事件為H。在二元通信系統中通常采用==0,==1的代價因子。極大極小化代價的條件為
(|H)=(|H)
(24)
又因為似然函數為
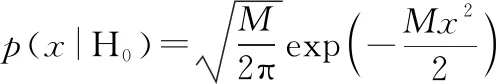
(25)
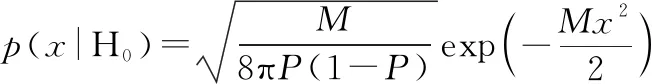
(26)
設判決門限為,則有

(27)
求解出極大極小化準則下的判決門限為
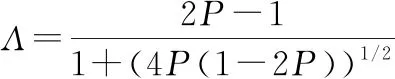
(28)
2.5 極化碼參數識別步驟
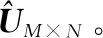
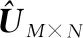
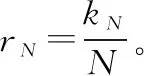
根據式(19)得到該遍歷碼長下的()。如果=10遍歷結束執行步驟6;反之,=+1執行步驟1。
比較所有遍歷碼長下的碼率,并根據遍歷碼長大于等于真實碼長后碼率不變這一特點識別碼長,輸出該碼長下的信息比特位數以及位置。
比較所有遍歷碼長下的()值,根據式(20)識別出碼長,根據識別出的碼長計算信息矩陣的各列門限值,統計分析矩陣中()<的數量和位置,其值就為信息比特位數,其位置就為信息比特位置。
3 仿真分析
3.1 無誤碼仿真驗證
本節的仿真實驗是以參數(32,12)、(64,32)和(128,64)的極化碼為例來進行分析,接收端接收到了無誤碼的500組碼字比特流,且通過二進制刪除信道進行傳輸,二進制刪除概率=01。各個遍歷碼長求出的碼率和分析矩陣各列()如圖4所示。

圖4 無誤碼碼長、信息比特位數以及位置識別Fig.4 Error free code length, information bits and location identification
從圖4(a)可以看出當遍歷碼長指數<5時,碼率大于0375,這與推論1是一致的,當≥5時,碼率一直保持0375不變,那么真實碼長=2=32,這與第22節分析的結果一致。同理可得圖4(b)和圖4(c)的真實碼長分別為64和128。同時可以發現當真實碼長較長與碼長較短的極化碼相比,變成同樣較小碼長的極化碼時,其碼率會越大。這就說明推論2中碼率的大小也有遞推關系,碼率會隨著碼長變短而增大。圖4(d)、圖4(e)和圖4(f )中凍結比特所對應的列()值都為1,信息比特所對應的列()值都接近于0,這與第23節分析的結果一致。無誤碼情況下的識別由于不需要做門限的判決,各遍歷的碼長下分析矩陣各列的()=1的就識別為凍結比特的位置,其余都為信息比特的位置。
3.2 誤碼仿真驗證
誤碼條件下的識別仿真也選取參數為(32,12)、(64,32)和(128,64)的極化碼進行分析。條件設置與第31節相同,誤碼率=002。各遍歷碼長對應分析矩陣的零均值比(),估計碼長對應的()如圖5所示。
從圖5(a)~圖5(c)可以看出,當遍歷碼長小于真實碼長時,()會小于真實碼長對應的(),當遍歷碼長大于真實碼長時,()也會小于真實碼長對應的(),這與第33節分析的結果一致。峰值對應的碼長就為真實碼長64和128。圖5(d)、圖5(e)和圖5(f )分別是碼長32、64和128對應的()值。圖中顯示各列的門限值,可見()小于門限值的個數就為信息比特位數,對應位置就為信息比特位置,這與推論1和推論2是一致的。
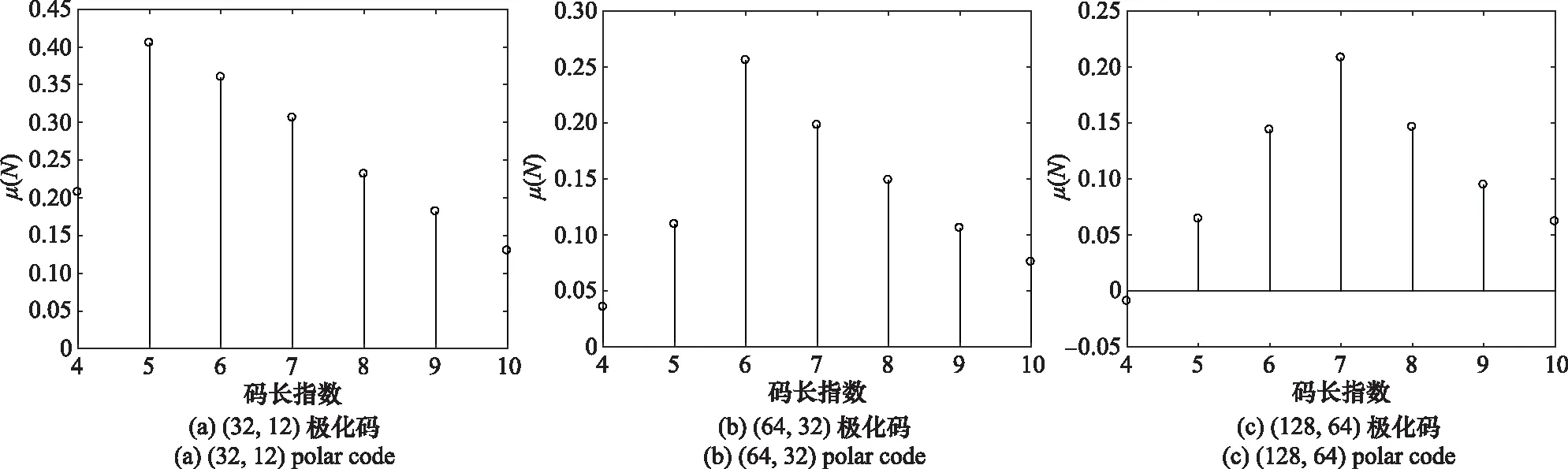
圖5 有誤碼碼長、信息比特位數以及位置識別Fig.5 Error code length, information bits and position recognition
3.3 性能分析
碼字組數對識別性能的影響
本實驗選取(64, 30)的極化碼進行仿真分析,設定截獲碼字組數分別為100、300和500,采用本文算法同時對碼長、信息比特位數和位置進行估計。刪除概率=0.4,蒙特卡羅實驗次數為500。仿真結果如圖6所示。
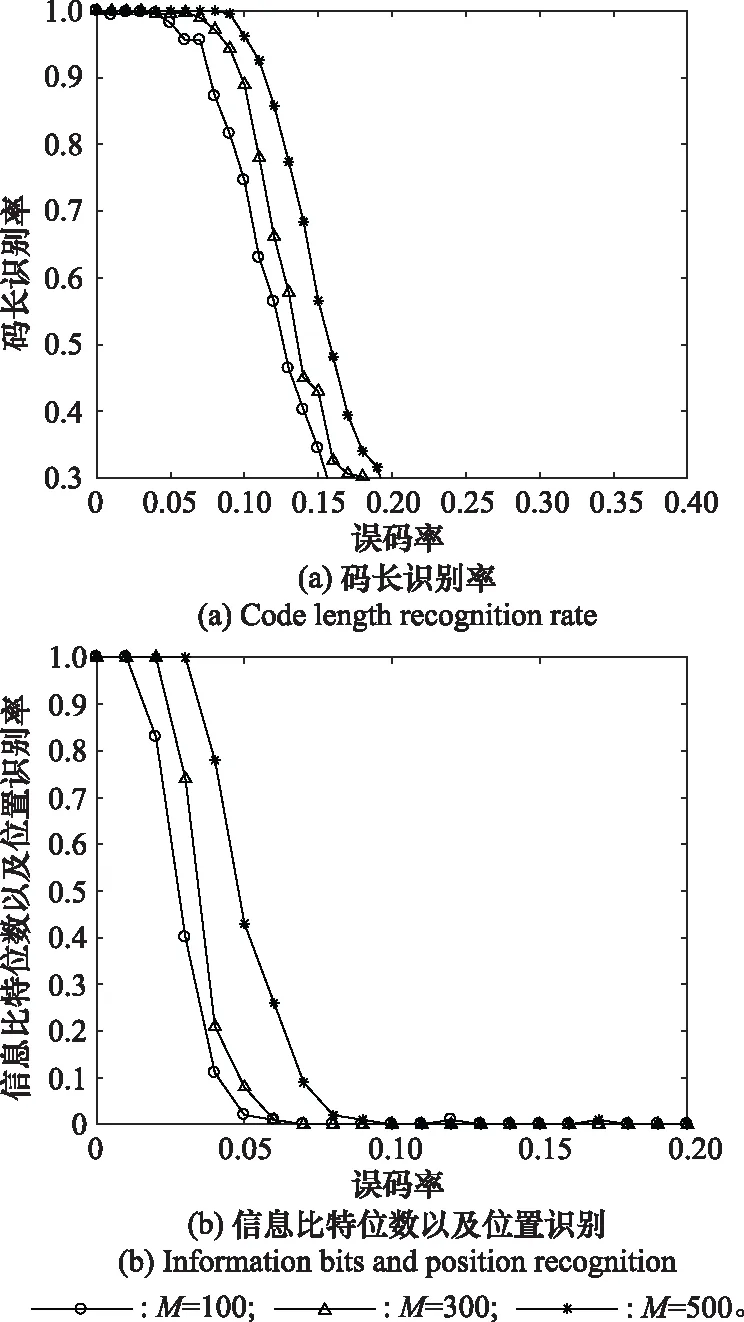
圖6 不同碼字組數的識別率Fig.6 Recognition rate of different code word groups
從圖6可以看出碼長和信息比特的正確識別率隨截獲碼字組數增加而提高。所以可以通過增加碼字組數來提高算法的容錯性。并且本算法在截獲碼字組數為100時,仍然有較好的容錯性。
碼長對識別性能影響
本實驗選取碼長為32、64和128的極化碼進行仿真分析,設定碼率都為1/2,碼字組數為500。采用本文算法同時對碼長、信息比特位數和位置進行估計。其余參數設置與實驗1相同。仿真結果如圖7所示。
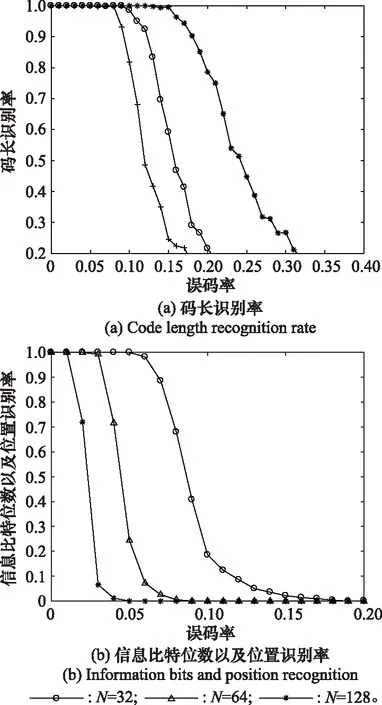
圖7 不同碼長的識別率Fig.7 Recognition rate of different code lengths
從圖7結果中可以看出,碼長為32時,在同誤碼率下,碼長、信息比特位數以及位置的識別率是最高的,隨著碼長的增加,相關參數識別率逐漸降低。這是因為碼長越長,分析矩陣中誤碼出現的次數也就越多,對參數的正確識別影響也就越大。但是,對于碼長為128的極化碼,在誤碼率為9×10的條件下,碼長識別率依然能達到90%以上。
不同算法識別性能對比
本實驗將對比分析本文算法和文獻[14]算法對碼長的識別性能。選取的極化碼參數分別為(32,12)、(64,30)和(128,60),刪除概率=0.5,截獲碼字組數為200,蒙特卡羅實驗次數為500,對比結果如圖8所示。
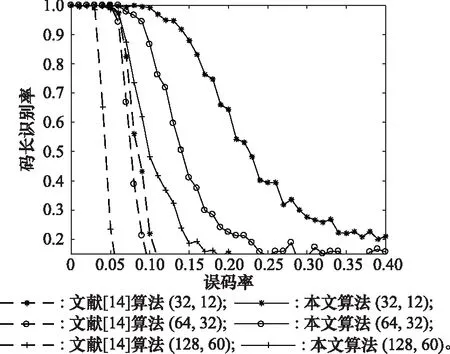
圖8 不同算法的碼長識別率Fig.8 Code length recognition rate of different algorithms
從圖8結果來看,本文算法對碼長的識別性能要遠好于文獻[14]算法。設定碼長識別率為80%以上,對于3組極化碼,文獻[14]算法所允許的誤碼率分別為7.09×10、6.52×10、3.56×10,而本文算法所允許的誤碼率分別為1.65×10、1.06×10、7.54×10。由于本文算法規避了在遍歷碼長時對每個信息比特位置搜索這個問題,引入零均值比提高了整體碼長的識別性能。所以本文算法針對碼長的識別時,在誤碼率高的時候有更好的穩健性。
3.4 計算復雜度對比分析
文獻[14]算法的計算復雜度主要集中在求零空間矩陣和計算匹配度。參數設置與本論文算法相同,該算法在不同遍歷碼長都會求取零空間矩陣,其計算復雜度約為(23),再與信息比特流迭代相乘并計算匹配度,其計算復雜度約為(2)。信息比特位數以及位置是通過遍歷信息位數構造零空間矩陣來識別的,其復雜度約為(23),于是總的復雜度約為(23)。綜上,本文算法計算復雜度更低。
4 結束語
本文利用極化碼生成矩陣的逆矩陣為自身這一性質,與截獲比特流構造的碼字矩陣相乘得到估計的信息矩陣,在無誤碼情況下利用分析矩陣所含的信息推出碼率隨碼長的分布情況,從而完成對碼長和信息比特位數和位置的識別。為了提高在有誤碼情況下識別的可靠性,引入了零均值比計量,根據峰值識別出碼長,再根據分析矩陣各列的統計特性識別出信息比特位數和位置。與其他算法相比,本文算法對碼長的識別效果更好,抗噪聲性能更強,復雜度更低,具有更高的工程應用價值。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
