基于聲發射信號EMD-WPD特征融合的航天器在軌泄漏辨識方法
2022-02-28 12:49:44梁真馨丁紅兵芮小博
振動與沖擊 2022年4期
綦 磊, 梁真馨, 丁紅兵, 鄭 悅, 芮小博, 張 宇
(1.北京衛星環境工程研究所, 北京 100094;2.天津大學 精密測試技術及儀器國家重點實驗室, 天津 300072;3.天津大學 電氣自動化與信息工程學院, 天津 300072)
隨著航天技術發展和人類航天活動日益頻繁,航天器扮演著越來越重要的角色,其運行狀態直接維系著航天任務的成敗。長期運行在復雜空間環境中的航天器,將受到振動、高低溫交變、空間碎片、太陽輻射及宇宙射線的作用,艙體可能產生松動變形、表面氧化、腐蝕、損傷穿孔等進而引發氣體泄漏事故[1],若不及時發現將釀成慘重后果。因此,航天器在軌泄漏的快速、準確辨識是航天系統安全運行的重要保障技術。
傳統泄漏檢測手段包括聲發射法、紅外熱成像法、真空氦質譜吸槍法,其中聲發射檢測技術是一種原理簡單、穩定、高靈敏的動態無損檢測技術[2],以泄漏引起的結構高頻應力波為檢測目標,已經廣泛應用于泄漏識別領域。2017年,Yu等[3]通過聲發射技術結合支持向量機(support vector machine, SVM)算法檢測并識別了室內氣體管道的微小泄漏;2018年Li等[4]基于聲發射技術成功檢測了水管道泄漏信號,從中提取泄漏特征參數并利用人工神經網絡實現了泄漏識別;2020年,Diao等[5]提出一種改進的變分模式分解(variational mode decomposition, VMD)方法并應用于水管道泄漏辨識,進一步提高泄漏辨識準確度。上述文獻雖然在泄漏檢測領域取得一定成果,但航天器泄漏具有氣體從大氣向真空流動的特點,氣體分子間碰撞減少,泄漏產生的聲發射信號較常規泄漏更加微弱,泄漏辨識難度增大。
現階段已有研究學者針對航天器在軌泄漏展開研究。2006年,Holland等[6]研究了航天器在軌泄漏聲發射信號特征,并提出了一種基于陣列信號處理的泄漏定位方法;2014年,李唯丹等[7]利用空氣耦合聲發射傳感器研究了真空泄漏產生的聲波中心頻率與聲壓衰減關系,但是由于空耦傳感器頻率感知范圍有限,未得到通用性結論;2015年,綦磊等[8]綜合考慮泄漏信號的時域和頻域能量特征,利用參數特征分析法研究了不同孔徑與聲發射信號之間的關系,但能量特征在實際應用中受到信號傳播距離、傳感器耦合狀態等因素的影響,其特征的不穩定性制約了泄漏辨識精確度的進一步提高。
綜上,本文提出了一種基于聲發射信號經驗模態分解(empirical mode decomposition, EMD)和小波包分解(wavelet packet decomposition, WPD)并行特征融合的泄漏發生識別方法,該方法從分解的聲發射信號中提取時域無量綱因子和頻域特征參數進行泄漏分類模型訓練,有效避免能量特征的誤差和不穩定特性,進一步提高了辨識的識別精確度。
1 泄漏辨識算法
1.1 聲發射信號分解
當航天器真空密封結構發生氣體泄漏時,氣體會在壓力差的作用下穿過微小孔徑并發生高流速的湍流射流[9]。本項目利用壓電聲發射傳感器獲取氣體泄漏引起的結構彈性波,并進行分析處理以監測識別泄漏現象發生,流程如圖1所示。
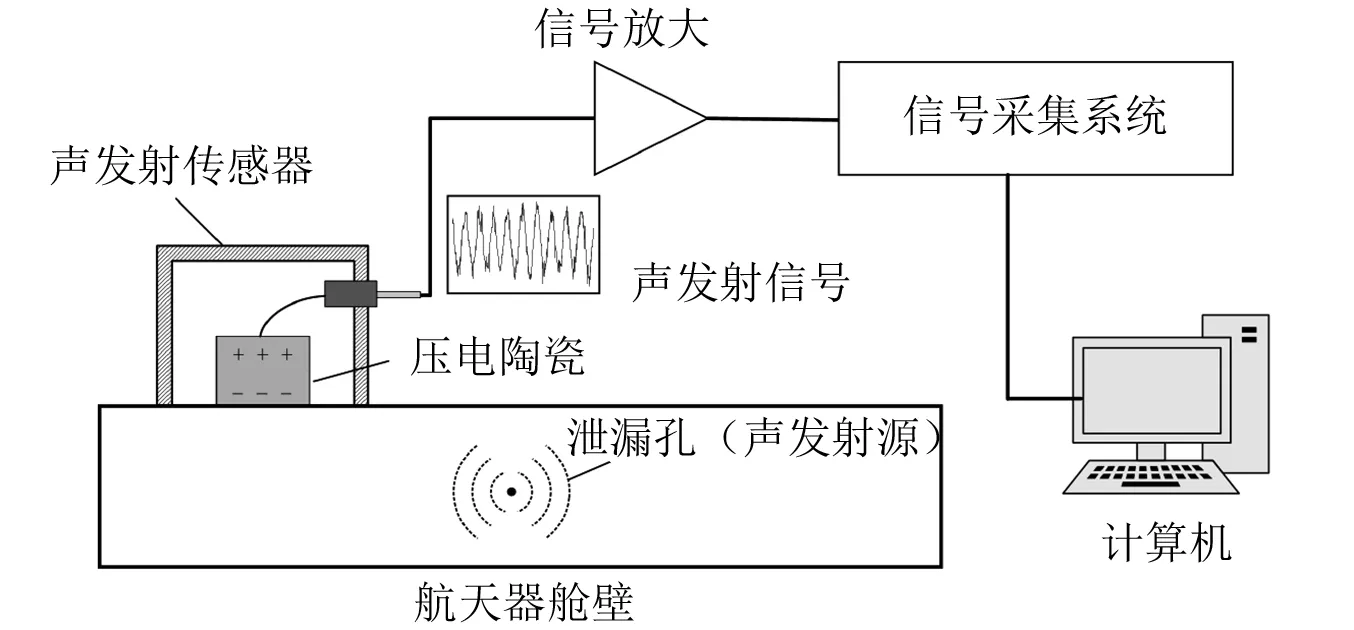
圖1 航天器泄漏聲發射檢測示意圖Fig.1 Schematic diagram of spacecraft leakage acoustic emission detection
本文提出的基于聲發射信號EMD-WPD特征融合的氣體泄漏識別方法流程,如圖2所示,主要包括信號分解、特征提取、特征鑒別、模型分類等步驟。
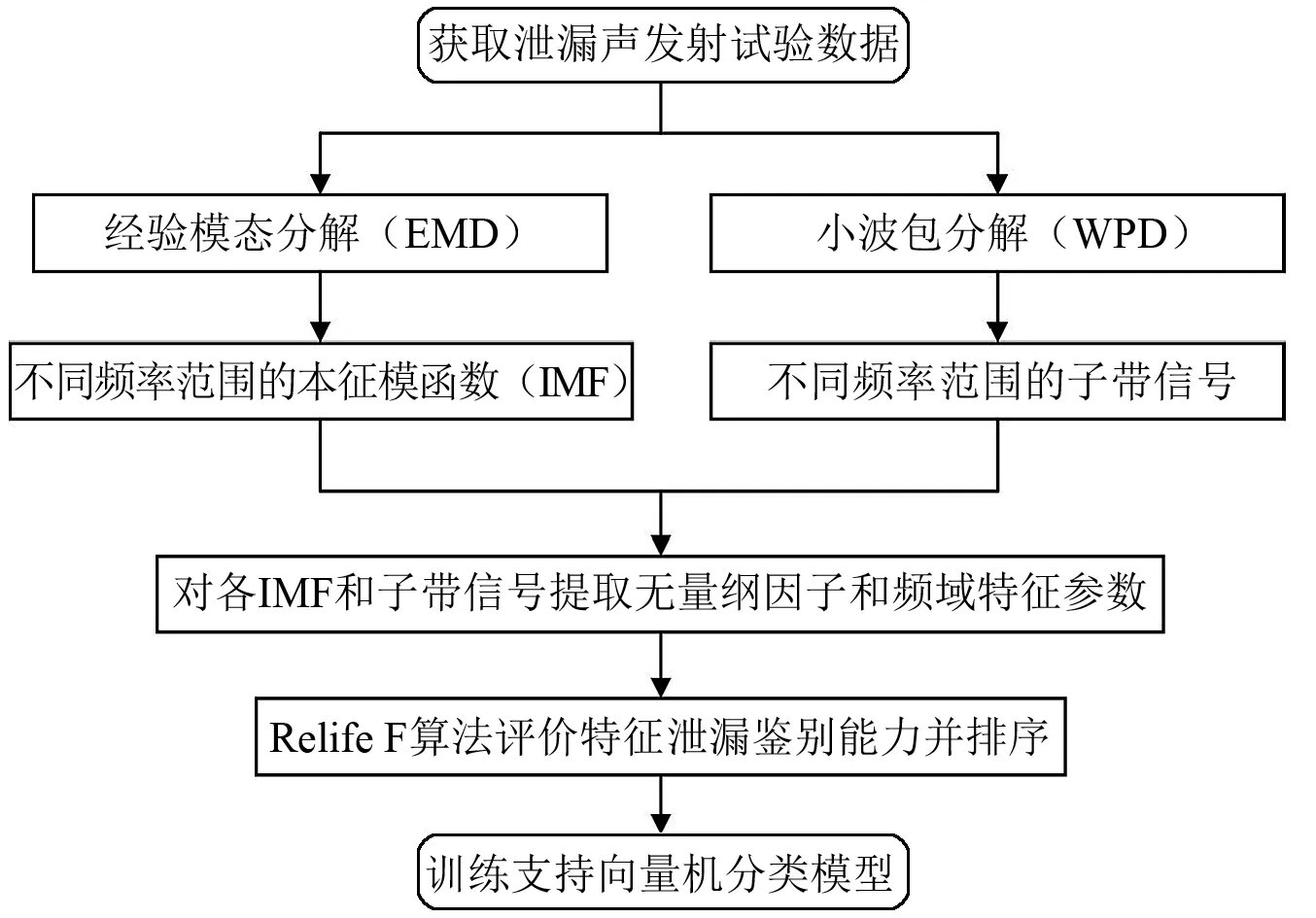
圖2 泄漏識別方法流程圖Fig.2 Flow diagram of leak identification method
首先,將聲發射信號分別通過EMD和WPD分解成為不同頻率范圍內的子帶信號。EMD基于局部尺度分離理論,無需預定基函數。因此,EMD可以將泄漏信號自適應地分解為一系列頻率分量稱為本征模函數(intrinsic mode function, IMF)。IMF是通過篩選原始數據而產生的,這是一個反復的過程[10]。泄漏信號經EMD可以分解為若干個IMF和一個殘差函數之和
(1)
式中:x(t)為泄漏原始信號;imfi(t)為分解獲得的第i個IMF;rn(t)為經分解得到n個IMF后的泄漏信號殘余分量。IMF具有從高頻到低頻的多尺度特性,對分解得到的IMF進行適當篩選可以剔除高頻干擾,保留泄漏信號的主要信息,不同的IMF包含泄漏信號不同頻段的特征信息。
小波包分解是建立在小波分解基礎之上的分解方式,可以對包含大量中、高頻信息的信號進行更好的時域局部化分析[11]。設{hn}n∈Z是尺度函數φ(t)對應的低通系數濾波器,{gn}n∈Z是小波函數ψ(t)對應的高通系數濾波器,其中gn=(-1)nh1-n,并定義遞推關系
(2)
當n=0時,w0(t)=φ(t),w1(t)=ψ(t),則函數集合{wn(t)}n∈Z為由w0(t)=φ(t)確定的小波包。不同的小波包基具有不同的泄漏信號時頻局部化能力,因此在分小波包分解系數{uk}上定義代價函數M,泄漏信號若在小波包基B下的分解系數具有最小的代價函數值,則B為泄漏信號在代價函數M下的最佳基。通過選擇小波函數ψ(t)并設定分解層數N,WPD將泄漏原始信號頻段平均分為2N個子頻段信號,選合適的子頻段信號可以濾除噪聲影響,保留主要頻段信息。
1.2 特征提取
為避免能量特征的誤差和不穩定特性,本文從無量綱因子和頻率參數角度進行分析,提取了泄漏信號經頻域分解后各子信號的時域峰度因子、偏度因子、波形因子,同時還提取了頻域峰度因子、偏度因子、波形因子、峰值頻率、頻譜帶寬、帶寬質心頻率共計9種特征參數。時域峰度因子(K)和偏度因子(S)的計算方法可參考文獻[12-13]。波形因子的計算公式如式(3)和式(4)所示
F=xrms/xarv
(3)
Ff=yrms/yarv
(4)
式中:F為時域波形因子;Ff為頻域波形因子;x為時域泄漏信號;y為泄漏信號快速傅里葉變換(fast Fourier transform,FFT)后的頻域幅值序列;下標rms為信號有效值;下標arv為信號整流平均值。峰值頻率fmax計算方法如式(5)所示
fmax=max(y)|f
(5)
式中:f為泄漏信號FFT變換后的頻率序列;max()為信號最大值。頻譜帶寬fdB的計算方法如式(6)所示
fdB=0.3max(y)|fup-0.3max(y)|fdown
(6)
式中,Y|f為幅值為Y時的頻率值。帶寬質心頻率fC計算方法如式(7)所示
(7)
1.3 特征評價與分類算法
在對所提取的泄漏特征進行分類模型訓練之前,需要對泄漏特征進行評價和選擇,以剔除不相關、沒有差異刻畫能力的特征,降低特征維度,減少訓練時間。Relief F算法是一種原理簡單,運行效率高的特征挑選算法,在泄漏特征集D中隨機選擇一個樣本R,并從R同類的樣本中尋找k個最近鄰樣本H,從R不同類的樣本中尋找k個最近鄰樣本M,然后根據式(8)、式(9)更新每個泄漏特征的權重
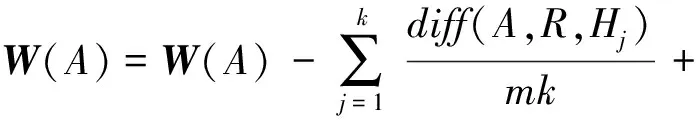
(8)
(9)
式中:A為泄漏特征;m為隨機選擇次數;W為泄漏特征權重矩陣,初始值為0;diff(A,Ri,Rj)為樣本Ri和樣本Rj在泄漏特征A上的差。以上過程重復m次,最后得到泄漏特征的平均權重,權重越大表示該泄漏特征的區分能力越強。利用特征評價算法得到1.2節中9種泄漏特征參數的權重,選取權重較高的特征并剔除權值較低的特征,有助于降低特征維度,減少訓練時間,提高泄漏辨識準確度。
確定輸入特征后,利用SVM算法進行泄漏辨識[14]。其核心思想是求解的n維特征權重w和實數偏置b,得到以最大間隔把泄漏與不泄漏兩類樣本分開的最佳超平面wTx+b=0,x為泄漏特征向量。為避免異常數據影響,引入松弛因子ξi>0,i=1,2,…,N和懲罰系數C,SVM求解的最優化問題抽象為帶不等式約束條件的極值問題,如式(10)所示
s.t.yi(w·xi+b)≥1-ξi,ξi≥0,i=1,2,…,N
(10)
當數據集并非線性可分時,則使用映射函數將數據映射至高維空間,轉化為線性可分問題。SVM利用核函數方法避免求解過程中映射函數的復雜內積運算,徑向基核函數(radial basis function,RBF)是SVM中較常用的核函數之一,如式(11)所示,其中σ為核參數。本文采用網格搜索方法確定SVM分類模型中懲罰系數C和核參數σ的最優值。
(11)
2 真空泄漏采集試驗
2.1 真空泄漏信號采集平臺
試驗平臺由真空泄漏試驗臺和聲發射信號采集系統兩部分組成,試驗裝置主要有真空泵、抽氣管、緩沖罐、真空計、帶孔金屬板,聲發射信號采集系統包含聲發射傳感器、前置信號放大器、信號采集儀和計算機,采集現場如圖3所示。聲發射傳感器為Nano30諧振型傳感器,頻帶范圍為1 kHz~1 MHz,靈敏度大于-70 dB,信號采集儀為DS2-16A全信息信號分析儀,采樣精度16位,采樣頻率3 000 kHz,前置放大器是增益為40 dB的直通濾波,信號觸發閾值為25 dB。金屬板上設計有直徑為0.38 mm,0.50 mm,0.80 mm,1.00 mm 4種圓形通道型漏孔。傳感器安裝在板子中心位置(0,0)點,4個漏孔分別位于(20 cm,20 cm)、(20 cm,-20 cm)、(-20 cm,-20 cm)、(-20 cm,20 cm)處,如圖4所示。傳感器與各漏孔之間聲波傳播路徑相同,避免其他因素對漏孔辨識的影響。真空泵運行時不斷抽取緩沖罐內氣體,穩定后金屬板下側形成準真空環境,通過真空表讀取氣壓約為1 000 Pa,上側為常壓大氣環境,氣壓為101 kPa。不移除漏孔上覆蓋的聚酰亞胺膠帶直接采集到的信號為無泄漏時的本底噪聲,包含機械泵運轉噪聲和電噪聲,該信號更接近航天器未發生泄漏時運轉的真實情況,而移除聚酰亞胺膠帶后,在壓力差作用下空氣從漏孔泄漏至緩沖罐,泄漏產生的聲信號和本底噪聲一同被耦合在金屬板表面上的聲發射傳感器獲取。試驗依次采集4種泄漏孔發生穩定泄漏的信號及不發生泄漏的信號,每種條件重復試驗40次,共計320組試驗數據,信號采集儀采集時間設定0.1 s,僅保留每次試驗的中間部分穩定信號約17 ms做后續處理。
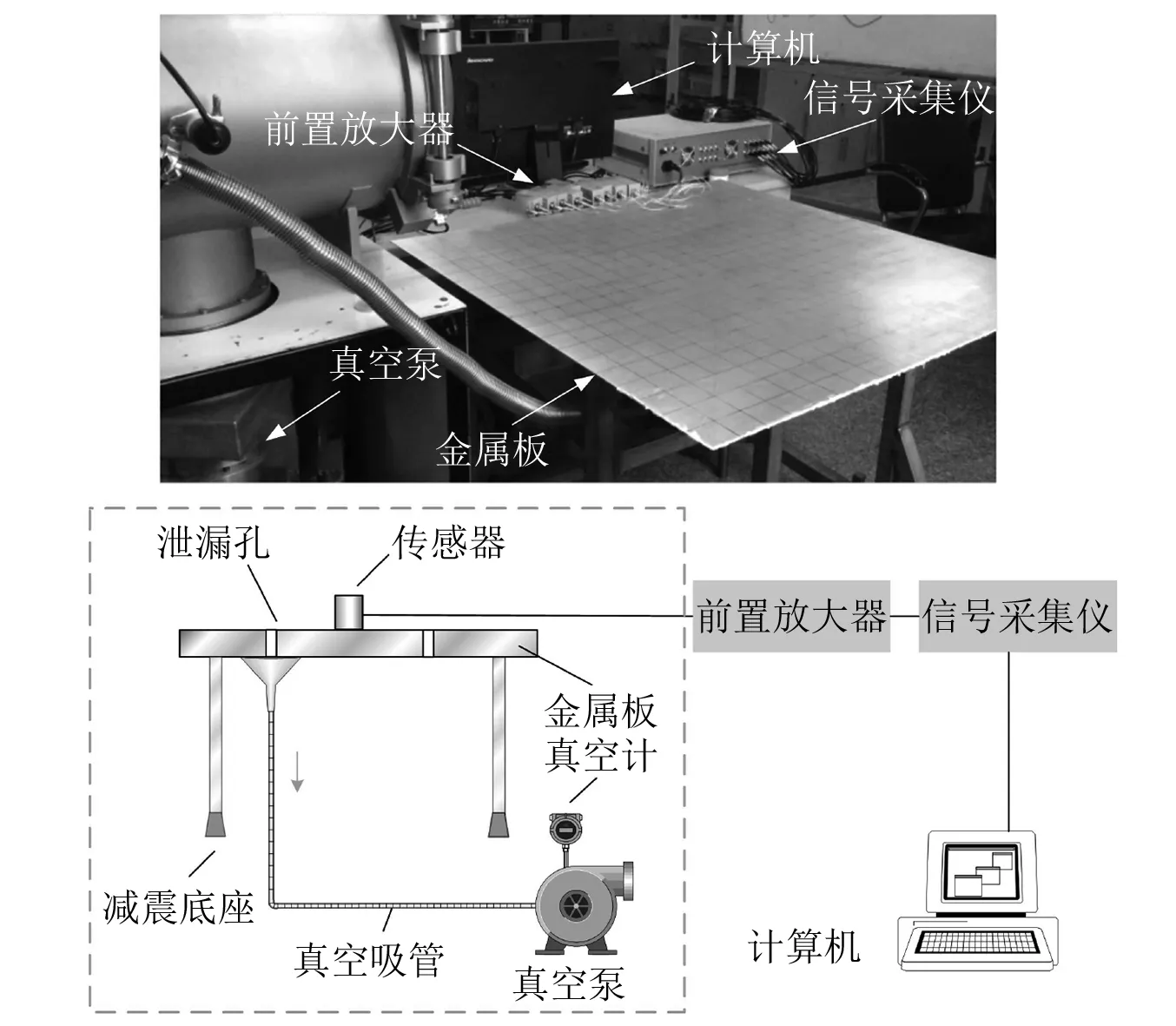
圖3 聲發射泄漏檢測試驗系統Fig.3 Acoustic emission leak detection experiment system

圖4 試驗平臺漏孔分布圖Fig.4 Distribution map of the leakage platform
2.2 泄漏信號時-頻域特征分析
以0.50 mm漏孔采集的信號為例,無泄漏與泄漏狀態的信號時頻域分別如圖5(a)和圖5(b)所示,泄漏與未泄漏信號的頻率分布范圍接近,很難通過簡單頻域特征加以區分。若不進行頻域分解直接提取1.2節中的9種特征參數,結果見圖5(c),泄漏與未泄漏信號的特征參數高度相似,僅偏度因子S和峰值頻率fmax存在一定區分度。訓練得到的SVM泄漏辨識模型準確度僅為79.2%,需要結合頻域分解進一步提高辨識精度。

圖5 0.5 mm漏孔信號特征提取Fig.5 Feature extraction of 0.5 mm leakage signal
3 泄漏辨識試驗結果
3.1 泄漏信號EMD與WPD分解
將試驗數據利用EMD分解為10個IMF和一個殘差函數,計算各IMF與原始信號的互相關系數,結果如圖6所示,可以發現IMF3、IMF4、IMF5、IMF6系數明顯高于其他IMF,故選擇上述4個IMF以排除其他無效模態和噪聲的影響。
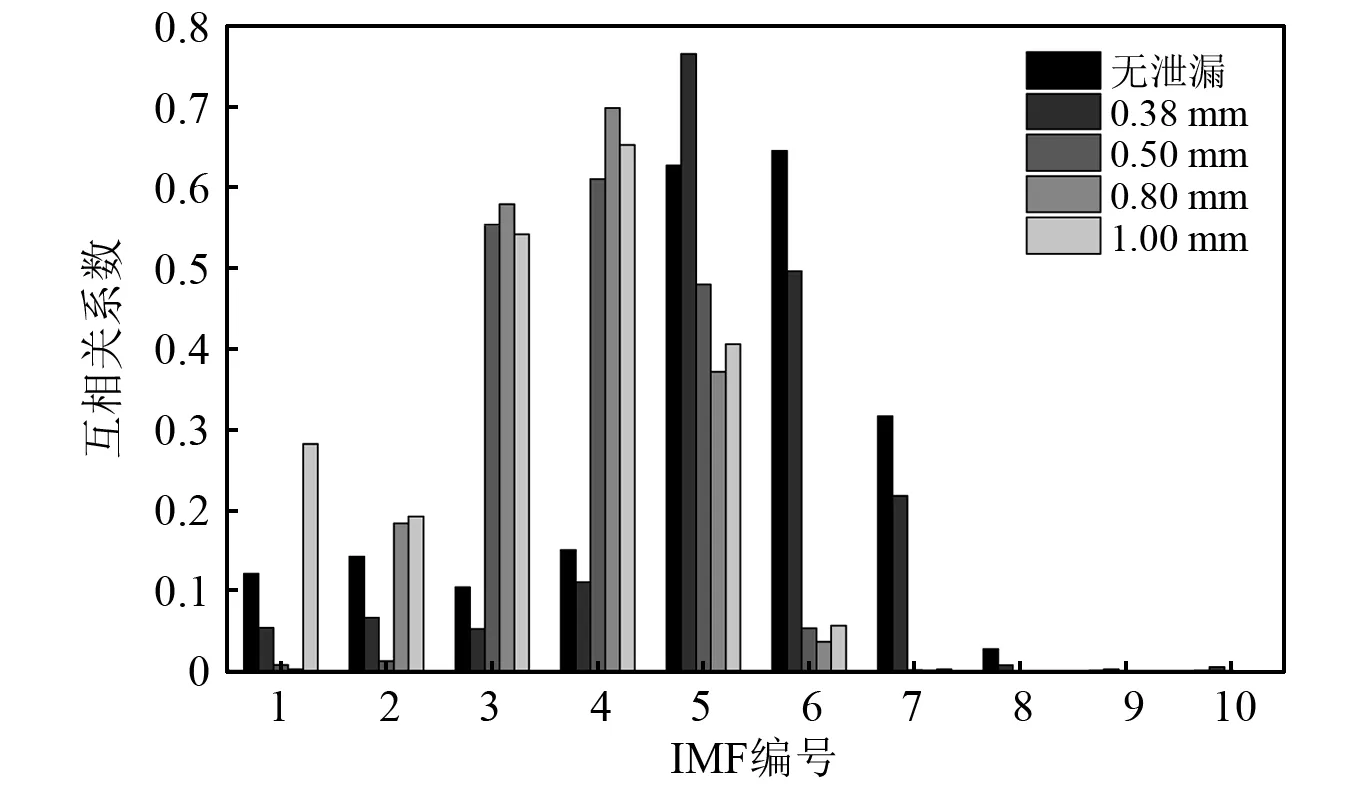
圖6 IMF與原信號互相關系數Fig.6 Correlation between IMF and original signal
試驗數據用WPD進行頻域分解,選擇dmey小波作為小波母函數,分解層數設定為8層,選擇信息熵代價函數如式(12)所示
(12)
式中,uk為小波包分解系數序列。選擇分解得到的前4個子頻帶信號從中提取特征參數分頻段反映信號特點。
每組試驗數據經過上述2種分解方式成為8個子帶信號,以0.50 mm漏孔的實驗數據為例,其EMD和WPD分解結果時域圖如圖7所示,頻域圖如圖8所示,可以看出,經EMD或WPD分解后的子信號具有從高頻到低頻的多尺度特性,且每段子信號包含原始數據主要頻帶范圍內的部分信息,頻域分解有助于后續的多維度特征提取。
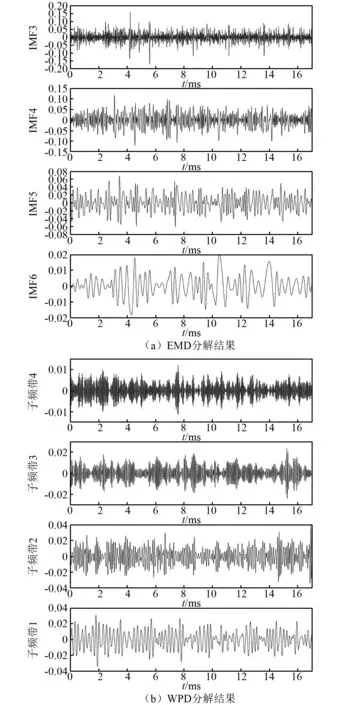
圖7 0.50 mm漏孔泄漏信號的EMD與WPD分解結果時域圖Fig.7 Time domain diagram of EMD and WPD decomposition results of 0.50 mm leakage signal
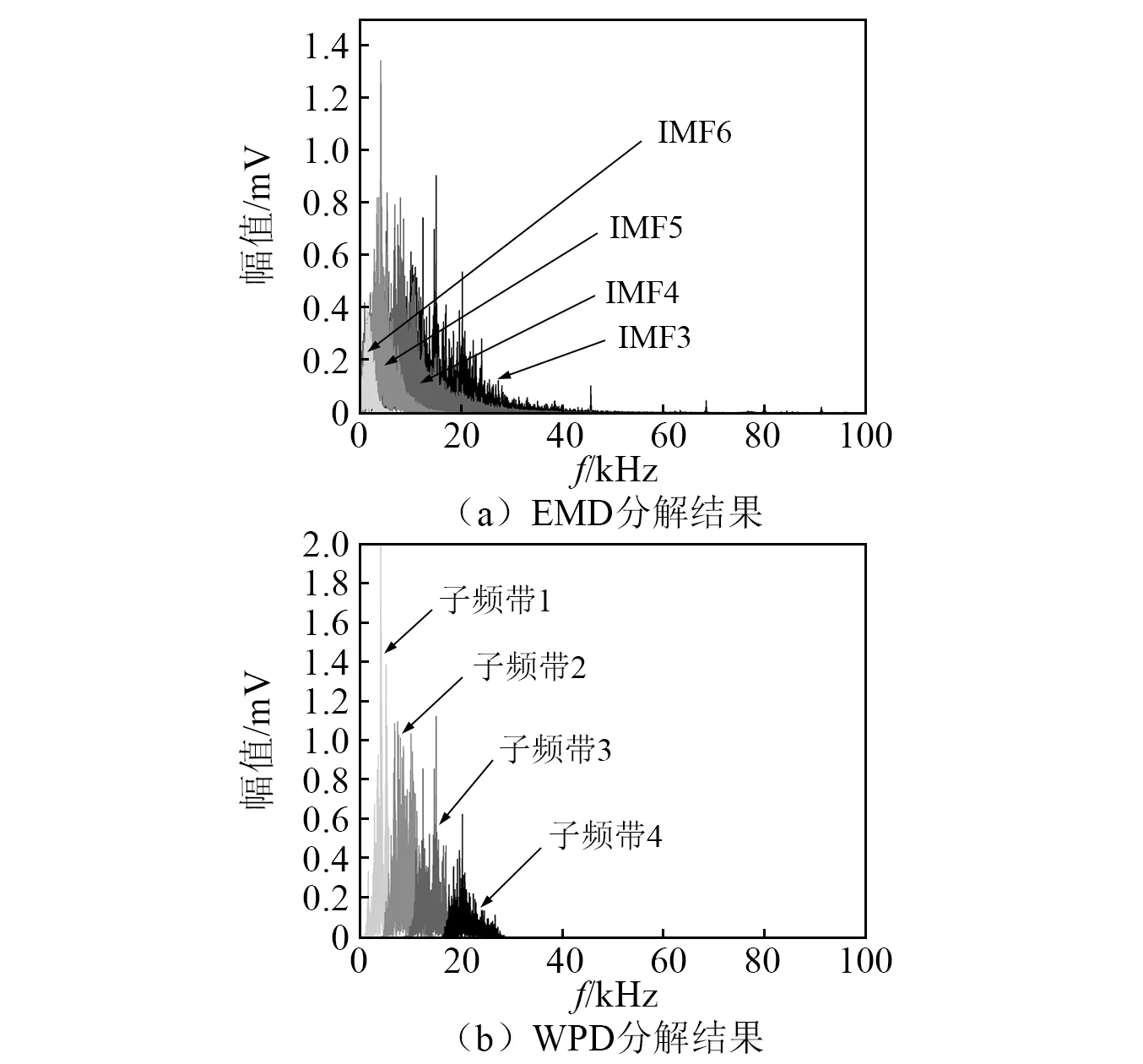
圖8 0.50 mm漏孔泄漏信號EMD和WPD分解結果頻域圖Fig.8 Frequency domain diagram of the decomposition results of EMD and WPD of the leakage signal of the 0.50 mm
3.2 無量綱因子和頻率特征提取及評級
分解得到的各IMF和子頻帶信號中提取1.2節所述9種特征參數,并對提取結果歸一化處理,最終形成640×36的數據矩陣作為機器學習數據庫。以0.50 mm試驗數據的特征提取結果為例,如圖9和圖10所示,可以看出相同試驗下的特征參數具有較好一致性和穩定性,不同子信號的特征之間則有一定區分度,利用特征選擇和SVM分類算法可以進一步量化泄漏發生與不發生特征的差別,達到泄漏發生識別的目的。
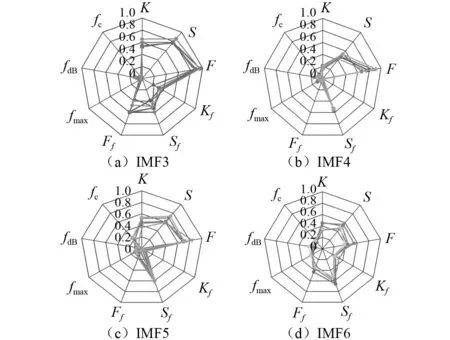
圖9 0.50 mm漏孔泄漏信號特征提取結果Fig.9 0.50 mm leak leakage signal feature extraction results
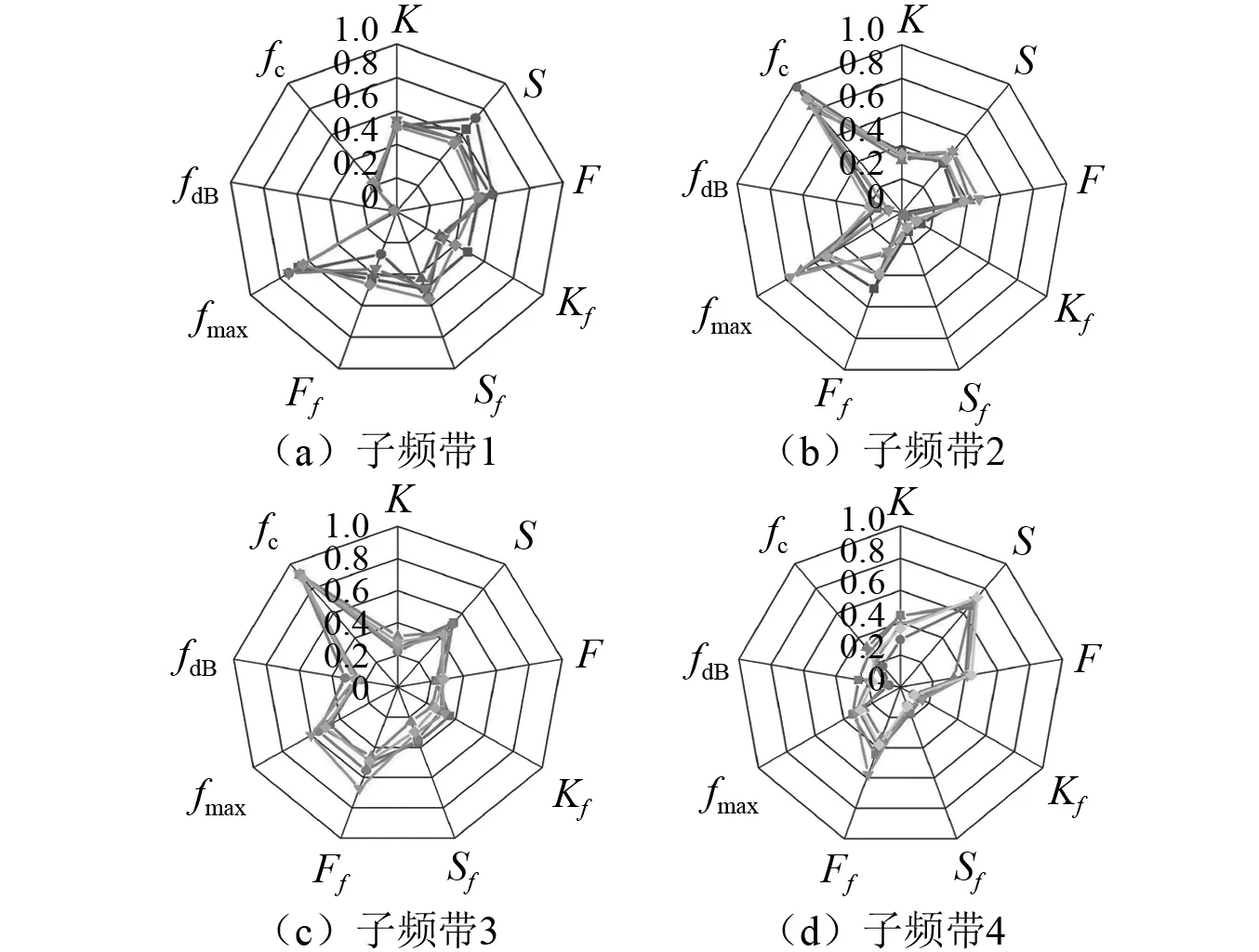
圖10 0.50 mm漏孔泄漏信號特征提取結果Fig.10 0.50 mm leak leakage signal feature extraction results
按照Relief F算法原理對640×36數據矩陣中各特征泄漏區分能力進行量化評價并排序,部分計算結果如表1所示,表中IMF編號取值為3、4、5、6,子頻帶序號取值為1、2、3、4,符號含義詳見論文1.2節,計算方式見式(3)~式(7)。表中可知特征IMF5的頻譜帶寬fdB和子頻帶4的頻率峰值因子Kf權值最高,由Relief F算法原理可知上述2種特征的泄漏區別能力最高。
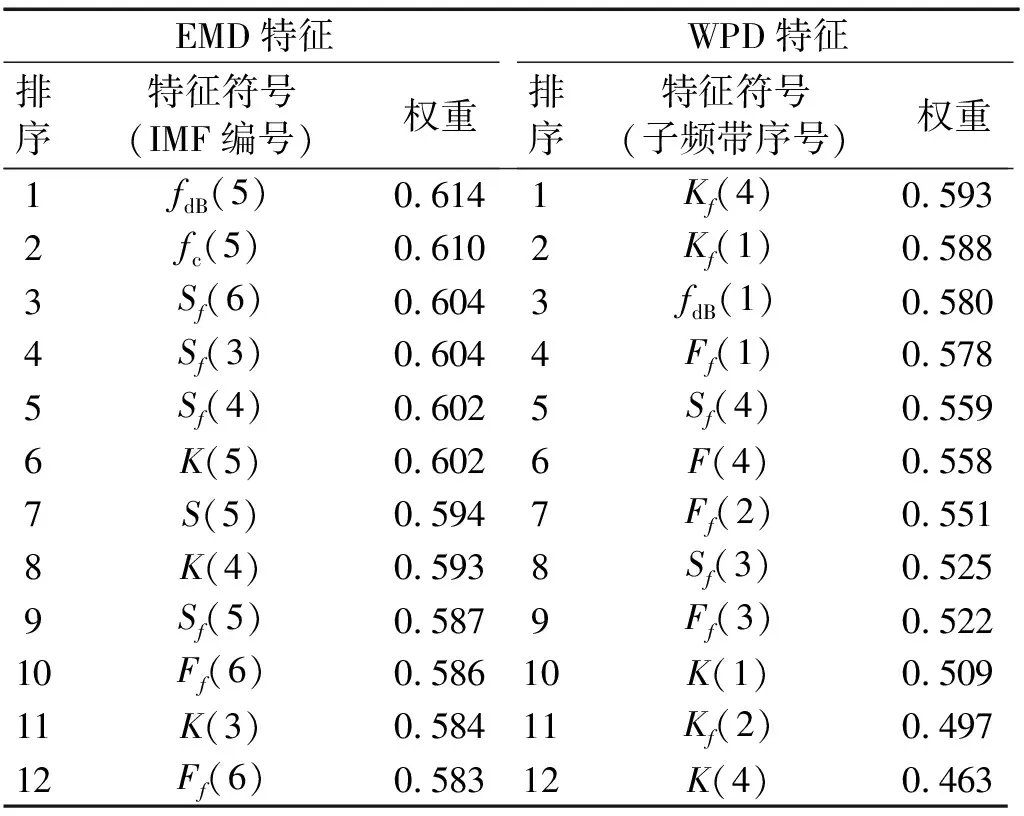
表1 基于Relief F算法的特征權重排序表
3.3 泄漏辨識結果
在640×36的機器學習數據庫中,隨機選定其中70%的數據作為訓練數據集,其余30%作為測試數據集,徑向基核函數RBF作為SVM泄漏分類模型的核函數,使用交叉驗證方式來評估分類器性能。對于SVM分類模型的懲罰系數C和核參數σ,利用網格搜索方法確定其最優值,網格搜索范圍設定為0.1~10.0,步長設定為0.1。基于Relief F算法對特征的評估結果,選擇不同泄漏特征組建SVM訓練集,驗證不同特征對模型分類的影響。
當使用EMD分解方式提取得到的全部特征用于SVM分類訓練時,泄漏分類模型精度為90.6%;而使用WPD分解方式提取得到的全部特征用于SVM分類訓練時,泄漏分類模型精度為94.8%;若從原始數據中直接提取3.2節中的特征用于SVM分類訓練,略過頻域分解步驟,則分類模型精度為79.2%。可以發現經過EMD或WPD頻域分解后的泄漏識別精度得到了提高,模型分類精度分別提高了11.4%和15.6%,表明通過頻域分解以分頻段多角度分析信號方法的有效性。
以Relief F算法對特征權值的排序為順序,隨著輸入特征數量的增加,分類器泄漏識別精度曲線如圖11所示,由圖11可見在前3種特征中,2種特征組合方訓練得到的分類器精度隨特征數量遞增,在前6種特征中,泄漏分類器精度均保持較高水平,表明Relief F算法有助于篩選區分能力好的特征并保持模型分類精度。但隨著輸入特征數量的繼續增加,WPD分解方式訓練的分類器精度下降且波動較大,對特征的選擇較為敏感,表明從WPD分解中提取的特征存在噪聲特征數據,導致模型計算誤差增大分類精度波動。相比之下EMD分解方式訓練的分類器精度緩慢上升,達到最高精度需要輸入前18種特征,由于過多的特征數量會影響模型的泛化能力[15-16],需要結合2種分解方式所得特征,進一步提高分類器精度的同時減少輸入特征數量。
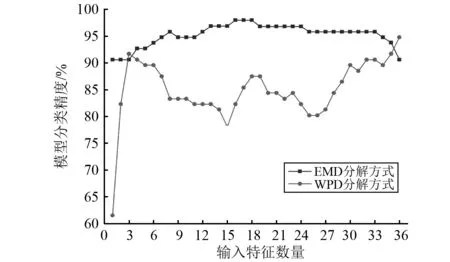
圖11 模型分類精度隨特征數量變化曲線Fig.11 The curve of model classification accuracy with the number of features
采用EMD-WPD并行特征融合的方式組建訓練集,分別選擇EMD和WPD中Relief F評價結果權值較高的特征并行融合作為SVM輸入訓練集,模型分類準確度如圖12所示。表2中對比了在不同輸入特征數量下,3種訓練特征集組建方式的模型泄漏識別準確度,可以看出在相同輸入特征數量下,EMD-WPD并行特征融合訓練得到的分類器精度均高于其他特征組合方式,并在輸入特征數量為8時,即EMD和WPD分解所得特征權值排序中各前4種特征,分類器精度達到96.9%,是一種可行的航天器泄漏識別方法。
4 結 論
本文提出了一種基于聲發射信號EMD-WPD并行特征融合的氣體泄漏發生識別方法并開展了試驗驗證,得到如下結論:
(1)在分類模型相同的條件下,通過EMD或WPD頻域分解提取特征的方法,比原始數據直接提取特征的分類精度分別提高了11.4%和15.6%,證明了通過分解方式以分頻段多角度分析信號方法可以有效提高泄漏辨識準確度。
(2)Relief F算法有助于篩選區分能力好的特征,減少訓練特征數量并提高模型分類精度。
(3)EMD-WPD特征并行融合方法訓練分類器,分類器能夠保持較高分類精度的同時輸入特征數量進一步減少,最高辨識精度可達96.9%,是一種具有應用潛力的航天器泄漏辨識方法。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年11期)2018-08-04 03:25:42
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
