基于多級特征圖聯合上采樣的實時語義分割
2022-03-16 03:36:42王小瑀
計算機技術與發展 2022年2期
宋 宇,王小瑀,梁 超,程 超
(長春工業大學 計算機科學與工程學院,吉林 長春 130012)
1 概 述
近年來,對于無人駕駛視覺感知系統,大多使用語義分割技術來處理感知到的物體。因此語義分割在無人駕駛領域有著極其重要的作用。由于無人駕駛的特殊性,使其不僅對語義分割網絡的準確度有要求,對實時性的需求也非常迫切。
Long等人提出了最原始的語義分割網絡FCN。繼FCN之后應用于無人駕駛的語義分割算法總體來說可以分為兩大類:第一類是基于編碼器-解碼器結構的網絡,例如Ronneberger等人提出的Unet網絡,在進行少類別分割任務時速度快、精確高。但是當分割類別增多,網絡分割速度將大幅度降低;劍橋大學提出的SegNet,網絡中采用最大池化索引指導上采樣存在特征圖稀疏問題,進而導致算法雖然達到了實時分割速度,但分割精度低;Paszke等人提出的Enet網絡通過減少神經元權重數量以及網絡體積使得網絡可以達到實時分割的要求,但是算法的擬合能力弱導致分割精度較低。第二類是基于上下文信息的網絡,例如Zhao H等人提出的PSPNet網絡,通過引入更多上下文信息提高了網絡的場景解析能力,但是由于多次下采樣操作導致特征圖丟失大部分空間信息。針對這個問題,Zhang H等人提出了EncNet,但是由于采用Resnet101網絡作為主干,參數量龐大,網絡實時性較差;Chen等人提出的DeepLab網絡,引入了空洞卷積來保持感受野不變。并且后續又提出了DeepLab v2以及DeepLab v3+網絡,其中DeepLab v3+結合了兩大類網絡的優點,使用DeepLab v3作為編碼器并且在最終特征圖的頂部采用了空洞金字塔池化模塊(atrous convolution spatial pyramid pooling,ASPP),在避免下采樣操作的同時獲取了多感受野信息。但是網絡在分割速度方面存在不足,主要是因為引入空洞卷積帶來了大量的計算復雜度和內存占用。以Restnet-101為例,空洞卷積的引用使得其中23個殘差模塊,需要占用4倍的計算資源和內存,最后3個殘差模塊需要占用16倍以上的資源。
針對以上各種網絡無法同時兼顧準確度以及實時性的問題,該文提出了一種實時語義分割網絡,采用參數量較少的輕量卷積網絡FCN8s代替DeepLab v3+中的ResNet101作為網絡的主干。文中算法主干與DeepLab v3+的區別在于最后兩個卷積階段。以第四個卷積階段(Conv4)為例。在DeepLab v3+中首先對輸入圖片進行卷積處理,然后再進行一系列的空洞卷積處理。不同的是,文中方法首先使用跨步卷積來處理輸入的特征圖,然后使用幾個常規卷積來生成輸出特征圖。并且使用多級特征圖聯合上采樣模塊(multi-scale feature map joint pyramid upsamping,MJPU)來代替DeepLab v3+中耗時、耗內存的空洞卷積,大大減少了整個分割框架的計算時間和內存占用。最重要的是,MJPU在大幅度減少運算量的同時,不會造成性能上的損失,讓算法應用在無人駕駛實時語義分割場景中變得可行。
2 文中算法
為了獲得高分辨率的最終特征圖,DeepLab網絡中的方法是將FCN最后兩個下采樣操作刪除,這兩個操作由于擴大了特征圖的感受野而帶來了大量的計算復雜度以及內存占用量。該文的目標是尋找一種替代方法來近似最終的特征圖。
為了實現這一目標,首先將所有被DeepLab v3+刪除的跨步卷積全部復原,之后用普通的卷積層替換掉空洞卷積。如圖1所示,文中方法主干與原始的FCN相同,其中五個特征圖(Conv1-Conv5)的空間分辨率逐漸降低2倍。
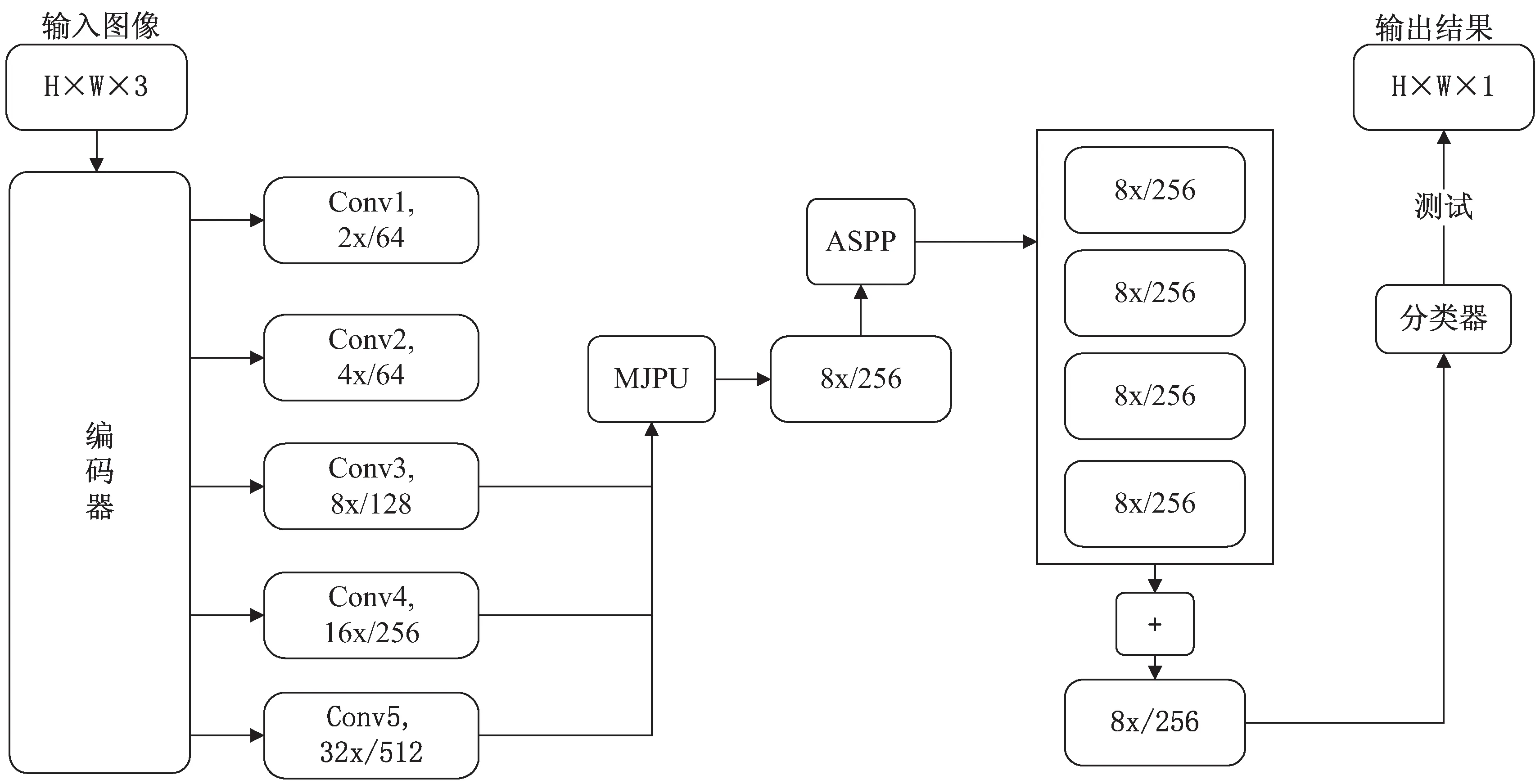
圖1 網絡執行流程
為了得到與DeepLab v3+相似的特征圖,提出了一個新的模塊,叫做多級特征圖聯合上采樣模塊(MJPU),它以編碼器最后三個特征圖(Conv3-Conv5)為輸入,然后使用一個改進的多尺度上下文模塊(ASPP)來產生最終的預測結果。在算法執行過程中,輸入圖片的格式為H
×W
×3,經過文中設計的編碼器網絡,編碼器網絡由輕量級網絡構成,可以減少算法在編碼階段的計算時間;其次使用MJPU模塊來生成一個特征圖,該特征圖的作用類似于Deeplab v3+主干網絡中最后一個特征圖的激活作用。MJPU的使用避免了DeepLab v3+中參數量龐大的空洞金字塔池化網絡與高分辨率的最終特征圖做卷積運算而大幅度降低了分割速度。MJPU模塊是該文可以大幅度增加實時性的重要因素。最后網絡經過ASPP獲取不同大小的感受野信息,增加網絡對不同尺度物體的分割能力,提升算法的分割精度。下面將詳細介紹替換空洞卷積的方法以及多級特征圖聯合上采樣模塊的結構。2.1 空洞卷積的替代

f
做普通卷積,得到中間特征f
;(2)刪除索引為奇數的元素,得到f
。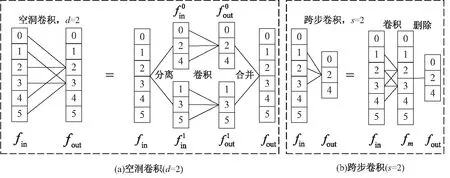
圖2 一維空洞卷積與跨步卷積示意圖
形式上,給定輸入特征圖的x
,DeepLab v3+網絡中得到輸出特征圖的y
如下: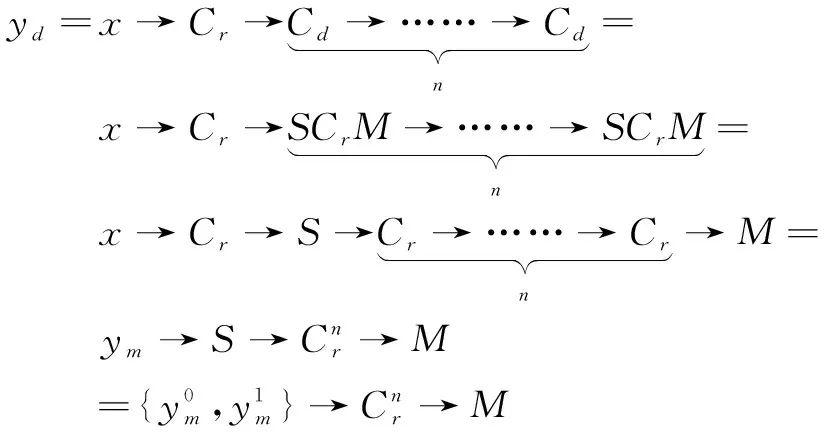
(1)
而在文中方法中,生成的輸出特征圖y
如下: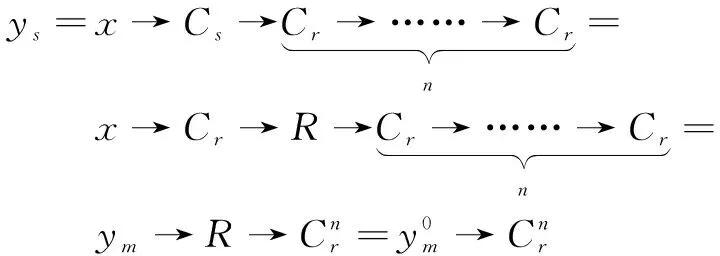
(2)
其中,C
代表普通卷積,C
代表空洞卷積,C
代表跨步卷積。S
、M
、R
分別代表圖2中的分離、合并、刪除操作。相鄰的S
和M
操作是可以相互抵消的。為了簡單起見,上述兩個方程中的卷積是一維的,對于二維卷積可以得到類似的結果。2.2 多級特征圖聯合上采樣模塊
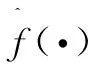
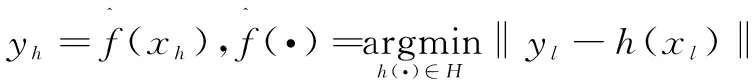
(3)
其中,H
是所有可能的變換函數集合,‖.‖是一個給定的距離度量。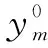
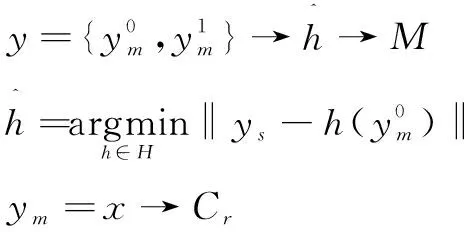
(4)
根據上述分析,設計了如圖3所示的MJPU模塊。
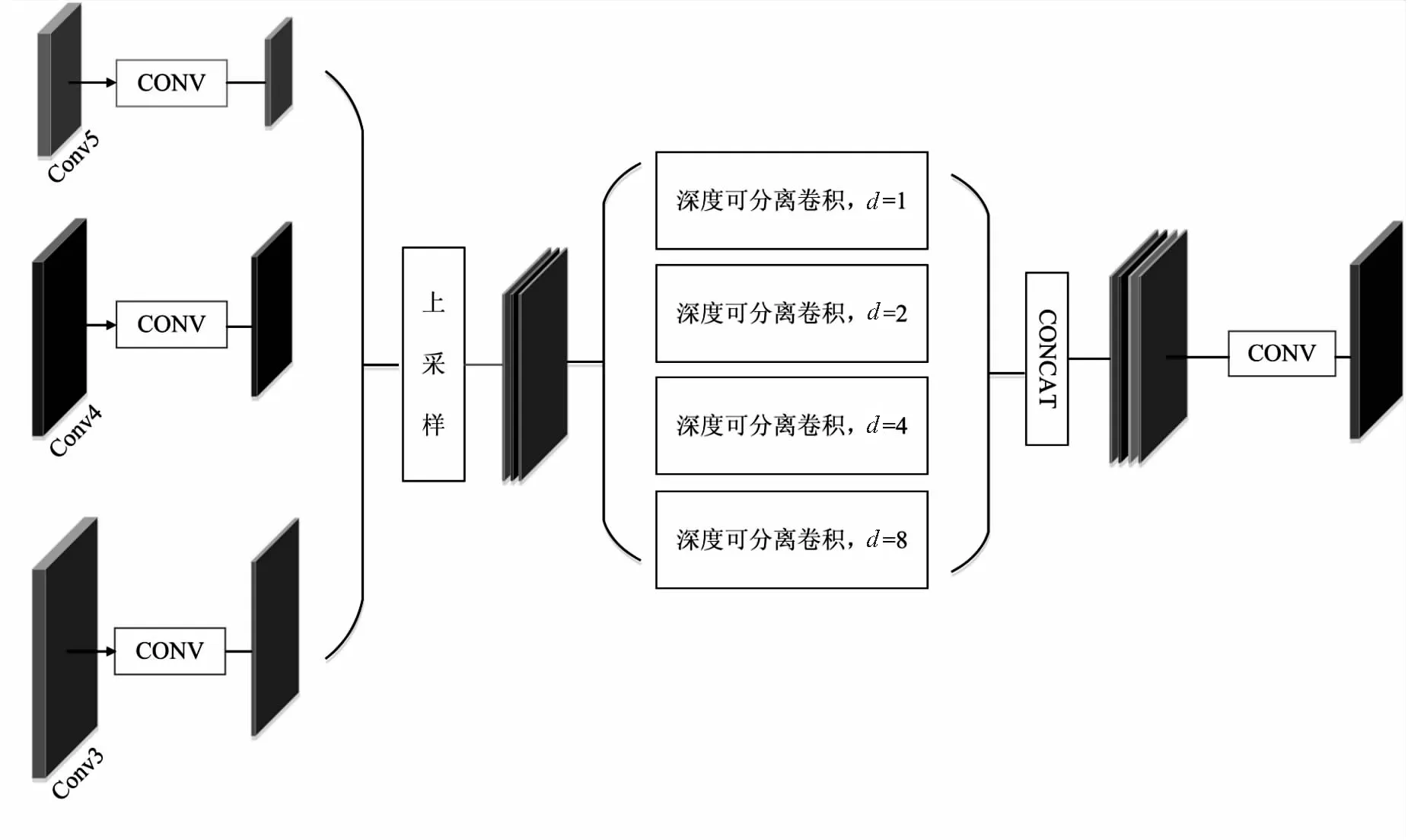
圖3 MJPU模塊
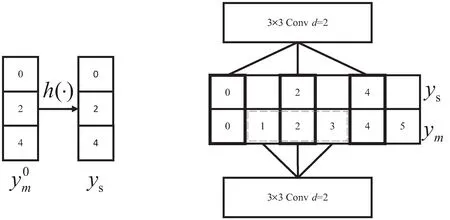
圖4 深度可分率卷積作用示意圖
3 實驗與分析
3.1 評價指標
實驗主要是在準確率以及速度兩方面對網絡進行了評價。在準確率方面使用的是像素精度(PixAcc)以及平均交并比(mIoU)作為評價指標。在速度方面則使用的是每秒處理幀數(FPS)作為評價指標。
PixAcc是語義分割中正確分割像素占全部像素的比值,而mIoU指的是真實分割與預測分割之間重合的比例,其計算公式如下:
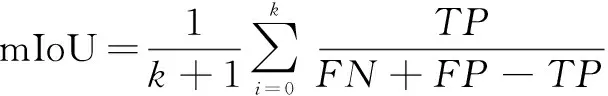
(5)
式中,k
表示類別數量,文中為34類。TP
表示正類判斷為正類的數量,FP
表示負類判斷為正類的數量,FN
表示正類判斷為負類的數量。FPS作為常見的測量網絡速度的評價指標,計算公式如下:
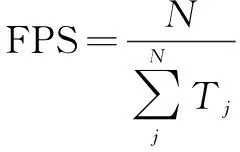
(6)
其中,N
表示處理圖像數量,T
表示處理第j
張圖像所用的時間。3.2 實驗環境
語義分割模型使用TensorFlow2.0深度學習網絡框架搭建,在訓練和測試階段的服務器配置均具有英特爾 Core i9-9900K 5.0 GHz的CPU、32 G DDR4 2 666 MHz的內存和RTX-2080TI(具有11 GB顯存)的GPU,并且基于Window10的操作系統,在CUDA10.0架構平臺上進行并行計算,并調用CuDNN7.6.5進行加速運算。
在訓練過程中網絡采用Adam優化器,初始學習率是0.001,學習率策略為逆時間衰減策略,權重衰減使用L2正則化。其中decay_steps=74 300、decay_rate=0.5,代表每過100個epoch,學習率衰減為原來的三分之二。圖5是網絡應用此種學習策略的loss值衰減曲線。可以清楚看出逆時間衰減策略可以使模型在較少的epoch次數內達到全局最優。
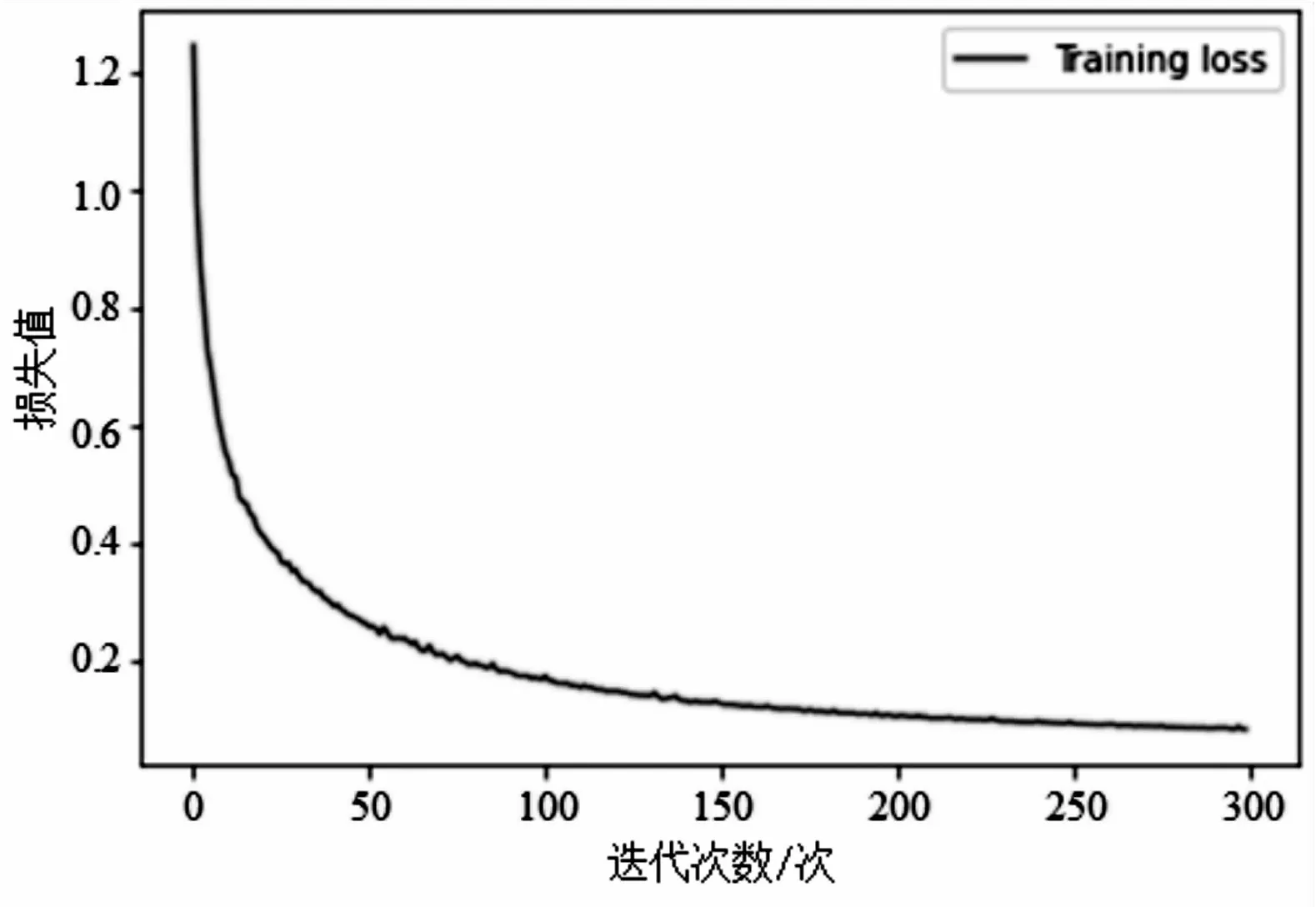
圖5 網絡訓練過程中loss值展示
3.3 數據集
文中選擇的無人駕駛數據集為國際公開的由奔馳公司推動發布的數據集Cityscapes。Cityscapes是在無人駕駛環境語義分割中使用最廣泛的一個數據集。它包含了50個城市的不同場景、背景、季節的街景圖片,具有5 000張精細標注的圖像、20 000張粗標注的圖像。在實驗過程中,文中只使用了5 000張精細標注的圖像,將其劃分為訓練集、驗證集和測試集。分別2 975張、500張、1 525張圖像,并且使用了全部34類物體作為分割對象。由于原有圖像分辨率為2 048×1 024,分辨率過高導致硬件無法進行大批量訓練,因此對圖像進行縮放并裁剪成512×512大小。
3.4 實驗結果分析
為了驗證該網絡的分割性能,選取了六種網絡與文中算法做對比,選取的網絡分別為Unet、SegNet、ENet、PSPNet、EncNet、DeepLab v3+。算法性能對比見表1。

表1 各算法在Cityscapes數據集(val)上的不同評估指標對比
首先與表1中的前三種輕量級網絡進行對比,文中網絡的mIoU分別高出6.72%、10.03%和13.32%,PixAcc也有平均5%以上的提升。在網絡實時性方面雖然略低于Enet,但這是由于Enet通過減少神經元權重數量的結果,雖然Enet的實時性較好但是算法嚴重非線性,網絡分割精度較低。而對比以分割精度為主要指標的PSPNet、EnecNet和DeepLab v3+,由于文中主干網絡采用的是輕量級網絡,導致網絡精確度略微落后,但是在分割速度方面最多高出200%。
圖6展示了不同算法的分割結果。從圖6中可以看出,文中算法對樓房、道路、樹、汽車、天空等都具有較好的分割效果,對于這些大物體該網絡均未產生分類錯誤區域;從圖中還可以看出該網絡對路燈等桿狀物體以及遠處車輛等小目標分割效果良好,這主要受益于所提出的MJPU模塊結合了多層特征圖的語義信息。
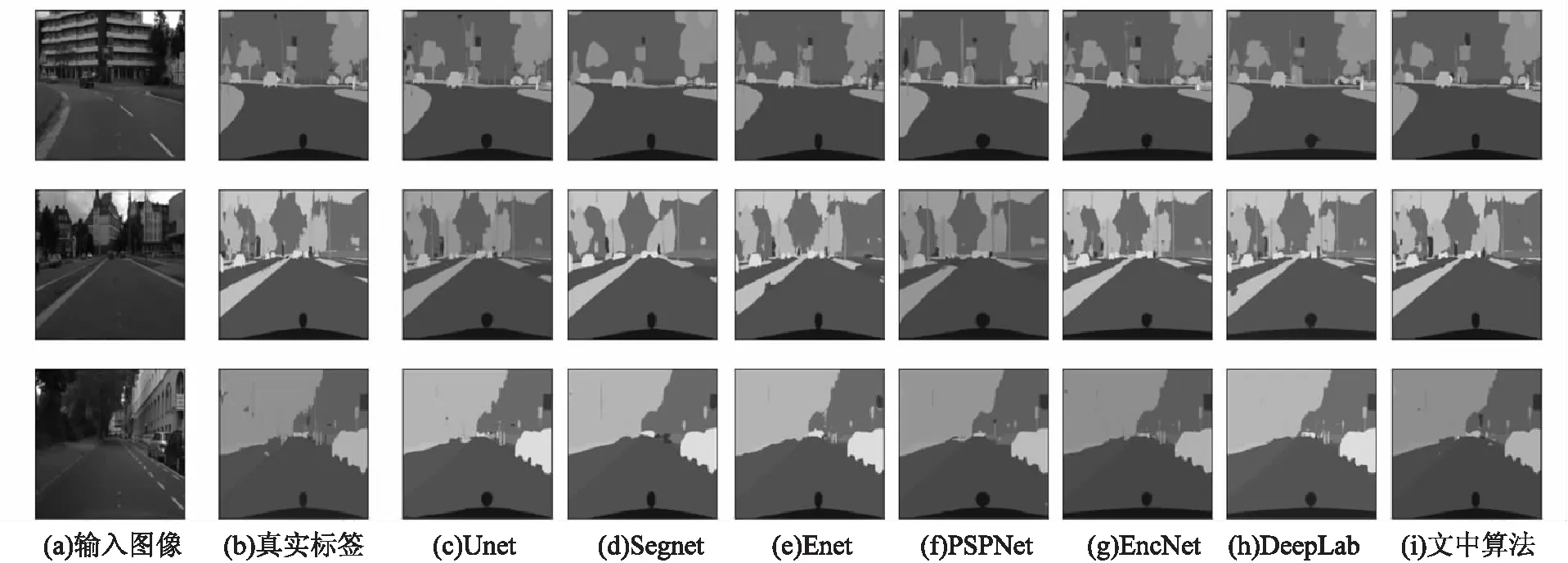
圖6 不同算法在Cityscapes數據集上語義分割效果
3.5 網絡結構分析
為了進一步驗證MJPU的有效性,該文將其與經典的雙線性插值上采樣和特征金字塔網絡(FPN)進行了對比實驗。使用FPS作為評價指標,在GPU上以512×512圖像作為輸入進行測量。結果如表2和表3所示。對于ResNet-50,文中方法的測試速度大約是Encoding結構(EncNet)的兩倍。當主干更改為ResNet101時,文中方法的檢測速度比Encoding結構的快三倍以上。并且可以由圖看出文中方法的檢測速度可以和FPN相媲美。但是對于FPN來講,MJPU模塊可以獲得更好的性能。因此對于DeepLabv3+(ASPP)和PSP,文中提出的模塊可以在提高性能的同時,對網絡進行一定程度的加速。
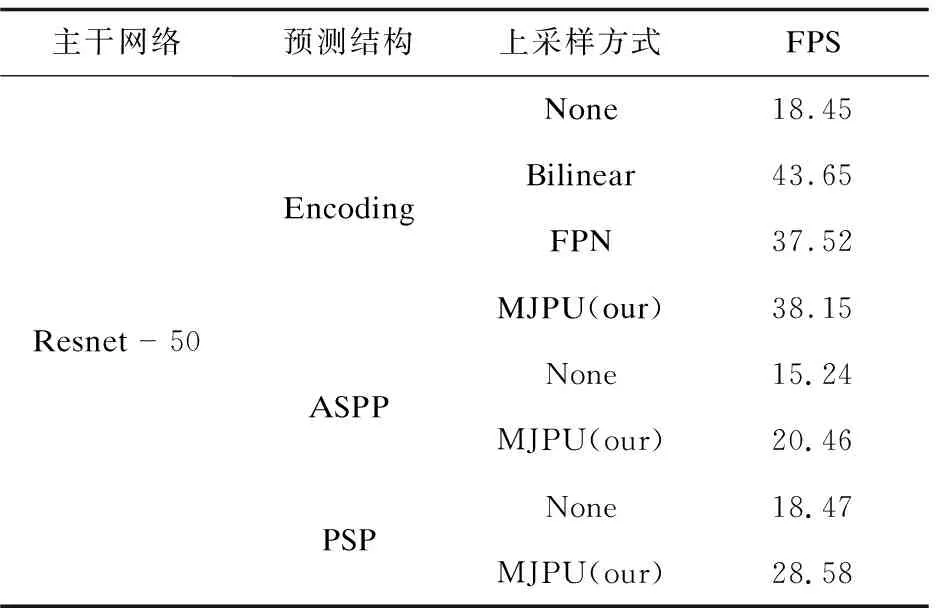
表2 Resnet-50中不同上采樣方式計算復雜度對比
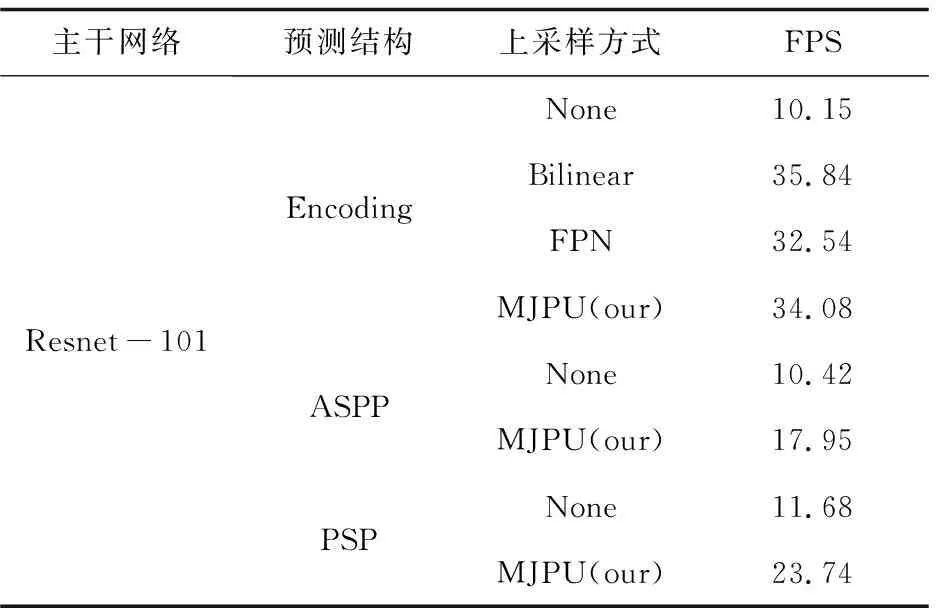
表3 Resnet-101中不同上采樣方式計算復雜度對比
4 結束語
為了使語義分割網絡更加滿足無人駕駛實時分割任務的需求,提出了一種新的實時語義分割網絡。首先,采用了一種輕量級的卷積神經網絡作為編碼器。并且分析了空洞卷積和跨步卷積的區別和聯系,使用跨步卷積和普通卷積的組合代替了耗時、耗內存的空洞卷積。在此基礎上,將高分辨率特征圖的提取問題轉化為一種聯合上采樣問題,提出了一種新的多級特征圖聯合上采樣模塊,通過該模塊可以在獲得近似與DeepLab v3+相似的特征圖的前提下,將網絡計算復雜度最多降低三倍以上。通過在Cityscapes數據集上的實驗表明(mIou=43.78%,FPS=32.3),所提出的實時分割算法在大幅度降低計算復雜度的同時,取得了較好的分割效果。從而使該網絡更加適合應用于無人駕駛場景當中。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
當代修辭學(2011年6期)2011-01-29 02:49:50
