一種基于深度學習的交通標志識別算法研究
2022-04-09 13:22:48謝豆石景文劉文軍劉澍
電腦知識與技術 2022年6期
關鍵詞:深度學習
謝豆 石景文 劉文軍 劉澍
摘要:針對當前在真實環境中交通標志呈多尺度分布,且圖像背景復雜、天氣光照多變等多種因素造成識別精度低、識別速度慢等情況。提出了一種基于深度學習神經網絡的交通標志識別的設計與實現。首先從公開數據集TT100K中選取出現次數最多的45類交通標志進行識別,接著對圖像進行mosaic等圖像增強及圖像處理。然后在深度學習神經網絡中的YOLOv4網絡結構上進行改進,使用聚類劃分需要檢測的目標框尺寸和CIOU對預測結果進行優化,最后使用遷移學習對模型進行訓練。通過對模型的評估發現,與現有的方法相比,該模型的識別精度更高,識別速度更快。
關鍵詞:深度學習;目標檢測;交通標志檢測;YOLOv4
中圖分類號:TP393? ? ?文獻標識碼:A
文章編號:1009-3044(2022)06-0116-03
開放科學(資源服務)標識碼(OSID):
1 概述
近年來,交通標志識別作為智能駕駛中一個重要的組成部分,引起了人們的廣泛研究。準確快速地識別出各種交通標志能幫助駕駛員規范行駛,從而能夠提高出行效率,降低交通事故的發生。
傳統的交通標志識別方式主要采用基于計算機視覺和機器學習模型的方法 [1-2]。如Nandi等人[1]通過圖片的不同色彩空間進行識別、對交通標志的形狀及輪廓進行分割提取交通標志、融合交通標志的形狀與色彩特征和采用深度學習中的神經網絡進行識別。Gao等人[2]根據每個交通標志的顏色和形狀的不同來區分。采用色彩模型CIECAM97和形狀模型提取出不同的交通標志進行判別。這些研究方法需要對圖像做復雜的圖像處理,減慢了檢測速度。且靈活性弱,不能應用在多種不同的應用場景下。
當前基于深度學習的交通標志識別逐漸成為研究的主流[3-5]。張傳偉等人[3]使用目標檢測模型YOLO構建交通標志識別模型,魏龍等人[4]則采用改進的YOLO模型進一步優化交通標志識別的效果。基于神經網絡識別交通標志的優勢是在不對原始圖像進行過多的圖像處理的情況下,滿足在差異性大的環境中正確識別交通標志的需求。
當前的目標檢測算法主要分為兩類:一階檢測算法和二階檢測算法。二階檢測算法將分開進行的檢測步驟合二為一,具有更好的實時性。一類代表性的為YOLO系列[6-7]。本文提出的一種基于改進的深度學習的交通標志識別算法研究。對傳統的YOLOv4模型進行改進,并采用遷移學習進行模型訓練。在大大縮短訓練時間的情況下,保證了模型精度的提升。
2 檢測算法設計
2.1 準備數據集
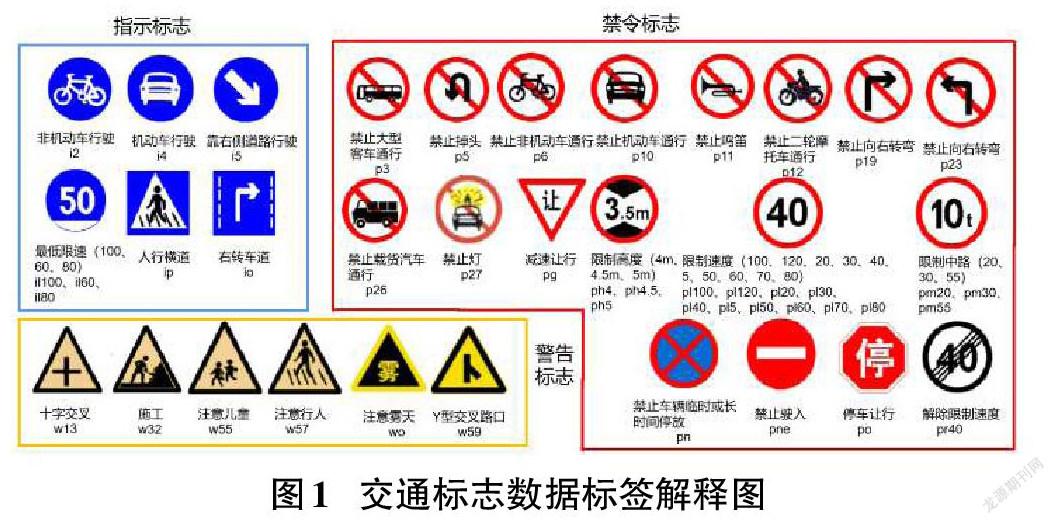
在訓練深度學習目標檢測模型之前,選擇適合的數據集尤為重要。在交通標志數據集方面,當前公開且滿足一定數量的數據集主要有五個。分別是針對美國交通的LISA數據集、針對比利時交通的BTSD數據集和針對德國交通的GTSDB數據集和TT100K數據集。本文選擇針對中國交通的數據集TT100K數據集作為模型訓練的數據集。如圖1所示,從數據集中選出最常見的三類交通標志(包括禁令標志、指示標志和警告標志)。由于原始數據集數據巨大,本文從中選取在道路中出現次數最多的45類交通標志進行訓練。
2.2 數據集標注
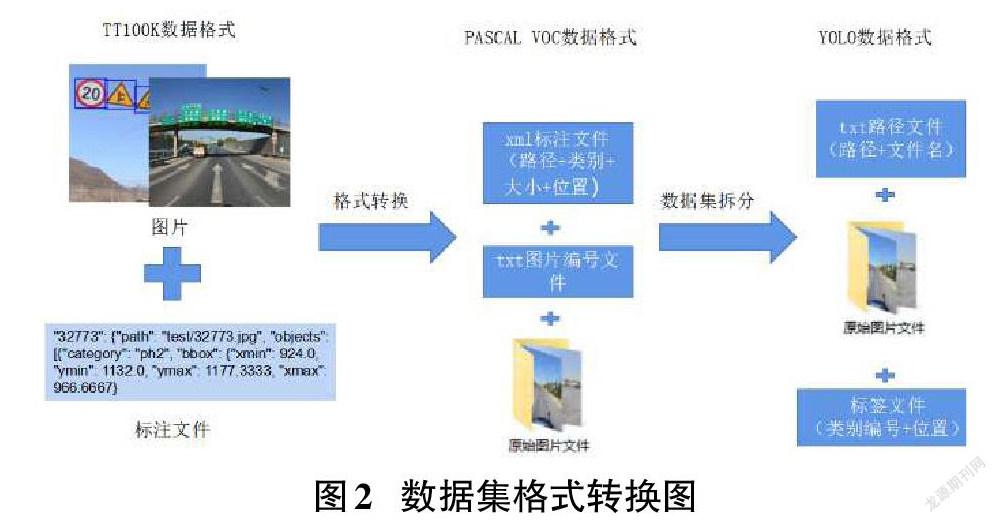
與進行圖片分類的數據集不同,進行圖片目標檢測的數據集不僅需要給圖片打標簽,還要對圖片中物體的位置信息進行標注。需要在標注文件中標明每張圖片所在文件夾、圖片名稱、路徑、大小(以像素為單位)、深度(圖片通道數,通常為3)、特別是圖中所出現的交通標志的標簽、交通標志的坐標位置等。
關于圖片中物體位置的標注需先將原始數據集的格式轉換為PASCAL VOC數據格式,再轉換為YOLO數據格式,如圖2所示。兩種數據格式存在不同:PASCAL VOC數據包含了物體左上角橫縱坐標和右下角橫縱坐標。YOLO格式關于物體的位置信息則為目標的中心點橫坐標與圖片總寬度之比、目標的中心點縱坐標與圖片總高度之比、目標框的寬度與圖片總寬度之比、目標框的高度與圖片總高度之比。
2.3 訓練模型構建
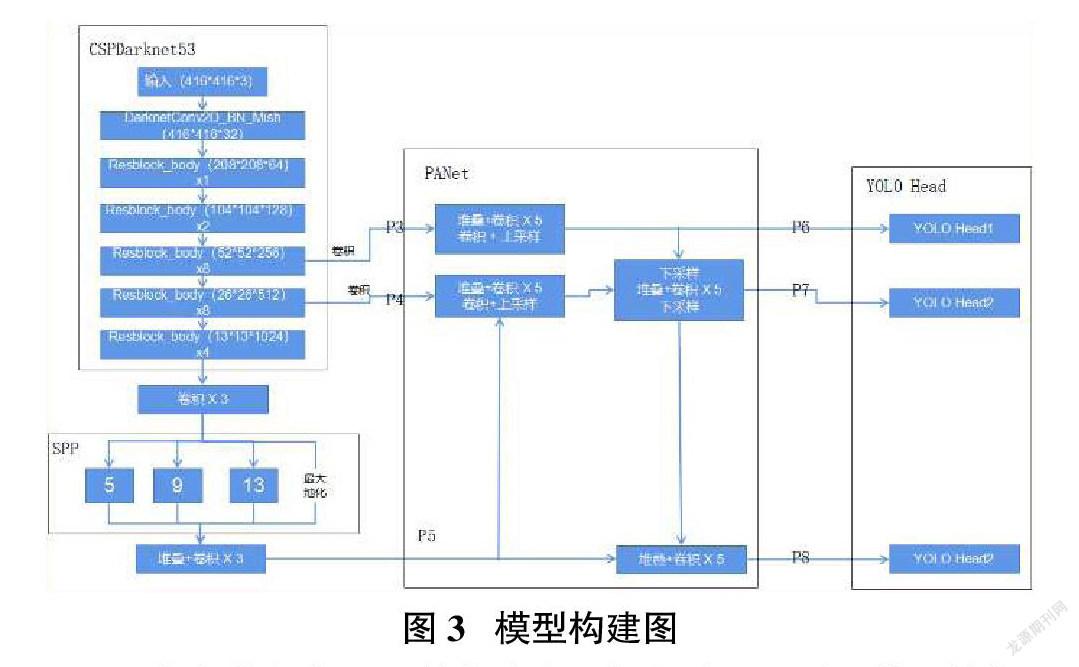
準備好數據集后開始構建交通標志檢測所需的模型結構。如圖3所示,本文使用模型的主要結構有4個,分別是CSPDarknet53、SPP、PANet和YoLoHead結構。CSPDarknet53負責對接收的圖片數據進行初步的特征處理,接收的圖片數據大小為416px*416px。使用連續堆疊的卷積能夠提取更高維度的特征信息。SPP和PANet為特征金字塔,對不同大小的卷積輸出進行差異化處理。
YOLOHead結構負責對接收的特征層進行分類檢測。經過前面結構的特征提取后,會輸出三類不同尺寸大小的卷積層。YOLOHead分別將這三類卷積特征換分成不同大小的網格。每個網格對類別進行預測,將最后得到的3個預測框與預先設置好的anchor尺寸大小進行NMS(非極大值抑制),保留尺寸最佳的預測框。最后,將預測框送入回歸算法中進行分析,得出預測框的最終類別。
2.4 模型訓練
模型參數設置是不斷測試與調整的過程。經過多次訓練調整,設置最優的模型訓練參數。接收的訓練圖片格式為3通道、大小為416px*416px。每一批訓練的樣本數量為16,總共訓練90000批次。學習動量為0.949、學習率為0.001,在訓練批數達到1000次后采用余弦退火衰減的方式更新學習率。訓練批數迭代到72000次和81000次時,依次在原來的學習率基礎上衰減10倍。
為了在提高模型精度的同時減少訓練時間,采用特定模型預訓練后進行遷移學習予以輔助。本文預訓練為學習完COCO數據集后獲得的模型。COCO數據集包含的數據種類多、且多為真實場景中的數據,與本系統模型要訓練的數據集更貼合。
2.5 模型優化
要想使模型檢測達到理想的精度,除了高質量的數據集和選擇正確的神經網絡結構還需要對模型進行不斷的優化。常見的模型優化方法有變換激活函數、更換學習率、增加數據集多樣性等。本文采用的模型優化方法有使用mish激活函數、采用masaic對樣本進行數據增強、使用余弦退火衰減變換訓練時的學習速率和在選擇預測框時使用CIOU策略進行計算。
本系統中除了對圖片進行自適應對比度變換還進行了masaic處理。masaic是一種可以完整進行圖片數據增強的策略。如圖4所示,在圖中最左端的原始圖像中,masaic對每一張圖片隨機進行方向上的轉變、圖片大小的調節和圖片色域的變換,豐富圖片類型。每張圖片進行第一輪處理后會歸為合適大小,由原來的四張圖片合成為一張圖片。如此一來,原本單一的圖片背景將更加多樣,模型從一張圖片中學習到的信息也更多。在節省訓練計算資源的同時也提高了模型的泛化效果。
2.6 模型評估
對模型進行評估有利于對模型進一步的優化,保障模型的質量。本文中的模型評估通過Map值、損失率、平均精確度等對模型進行多方位的考量。
如圖5給出了模型評估實驗,橫坐標為模型訓練的批次數,縱坐標為損失值與Map值。損失曲線用藍色表示,Map值曲線為紅色表示。
[AP=R∈(0,0.1...1)maxρ(R)] (1)
[Map=APC] (2)
如公式(1)所示,R為召回率(recall),召回率為正樣本中預測正確的數量與所有正樣本之比。準確率則為預測正確的數量與所有預測結果之比。一個模型中有多個召回率與準確率,為了使評價系數更全面,使用公式(1)將召回率與準確率結合運算得出平均準確率AP。將所有的召回率R平分為11個區間,每個區間內包含多個準確率。將這些在同一個區間內的準確率集合用表示。每個區間內最大的準確率用maxρ(R)表示。最后將得到的11個數值求得均值結果就是平均準確率。而Map值則可以用公式(2)得出。AP為平均準確率、C表示模型需要識別的類別數。平均準確率與類別數之比為Map值。在訓練完成后,平均損失低至0.1774,Map值也達到了89.8%。效果良好,優于大多數預測模型。
將模型與訓練相同樣本的其他模型進行對比。如圖6中與Fast-rcnn模型對比,柱形圖表示Fast-rcnn模型的平均準確率、折線圖表示本系統給出的模型平均準確率。橫坐標為預測的標簽名稱,縱坐標為平均準確率數值。檢測結果顯示本系統模型的檢測效果精度高,每類標簽識別精度差距小且都優于Fast-rcnn模型。
3 系統實現
在模型實驗情況良好的情況下,為了將模型部署在終端中進行簡單操作即可使用:運用PyQt5語言搭建桌面程序。終端程序包含三個主要功能:對圖片進行交通標志檢測、對視頻進行交通標志檢測和對攝像頭進行交通標志檢測。如圖7所示,顯示了終端進行視頻交通標志檢測的畫面。當用戶運行軟件時,點擊視頻檢測按鈕即可選擇對應的視頻文件進行檢測。與攝像頭檢測與圖片檢測相似,程序會將檢測的原始畫面與檢測后的畫面同時顯示。并將檢測到的交通標志截圖放大顯示。在文本框中,會顯示對應的檢測結果,顯示順序為交通標志對應的標簽名和交通標志在畫面中的坐標位置。程序還能夠對檢測信息進行保存與錄像,大大方便了用戶使用。
4 結論
基于目標檢測YOLOv4模型,在TT100K數據集上進行訓練,并且在經過模型訓練、優化與評估后取得了Map值為89%的良好性能,實驗表明,模型在速度與精度上具有較好的競爭力,通過PyQt對模型進行集成,給出了初步的應用系統方案,后續將深入對模型檢測速度與精度的進一步提升。
參考文獻:
[1] Nandi D,Saifuddin Saif A F M,Paul P,et al.Traffic sign detection Based on color segmentation of obscure image candidates:a comprehensive study[J].International Journal of Modern Education and Computer Science,2018,10(6):35-46.
[2] Gao X W,Podladchikova L,Shaposhnikov D,et al.Recognition of traffic signs Based on their colour and shape features extracted using human vision models[J].Journal of Visual Communication and Image Representation,2006,17(4):675-685.
[3] 張傳偉,李妞妞,岳向陽,等.基于改進YOLOv2算法的交通標志檢測[J].計算機系統應用,2020,29(6):155-162.
[4] 魏龍,王羿,姚克明.基于改進YOLO v4的小目標檢測方法[J].軟件導刊,2021,20(7):54-58.
[5] 何銳波,狄嵐,梁久禎.一種改進的深度學習的道路交通標識識別算法[J].智能系統學報,2020,15(6):1121-1130.
[6] Redmon J,Divvala S,Girshick R,et al.You only look once:unified,real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition.June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:779-788.
[7] Bochkovskiy A, Wang C Y, Liao H Y M. Yolov4: Optimal speed and accuracy of object detection[J]. arXiv preprint arXiv: 2004.10934, 2020.
【通聯編輯:梁書】
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
