互聯網數據挖掘與分析平臺設計與實現
2022-04-11 07:46:51李翔坤
科技風 2022年10期


摘?要:面對移動互聯網中龐大的數據量,如何進行挖掘和可視化的分析是當前大數據研究的一個熱點。本文搭建了一個互聯網數據挖掘與分析平臺,首先采用基于Scrapy框架搭建的爬蟲系統從互聯網絡爬取了大量新聞數據與招聘數據,通過Sphinx和CoreSeek經過googlediffmatchpatch算法去重,最后利用R語言對這些數據進行可視化分析,從而為制定決策提供更好的依據。
關鍵詞:互聯網數據;R語言;Scrapy;可視化分析
隨著社會信息化程度的不斷提高,作為信息化的產物目前各種APP和網站層出不窮,然而每一款優秀的APP或者網站其后臺必然存在龐大的數據量。如果能夠對這些數據進行很好的挖掘與分析以及將其可視化,幫助決策者更好地掌握自己的產品和客戶的動向,這毫無疑問會提升其產品在市場競爭上的生命力。因此數據挖掘和數據可視化分析一直是數據分析方向的一個研究熱點。R語言作為數據分析的工具,已經被越來越多地用在數據的可視化分析中。由于R語言是開源的,R的擴展包非常龐大又功能齊全,在這些豐富的擴展包的幫助下,讓數據的可視化分析變得簡單易行。因此,本文從互聯網爬下來的大量數據的分析與可視化采用R語言來實現。
1?數據的獲取
在做數據分析與可視化工作時為了更加準確地說明問題,往往是需要大量實時可靠的數據作為基礎的,數據獲取是進行數據分析與可視化的第一個阻礙,尤其是像新聞和招聘這類數據,單純靠手工收集獲取難度巨大,這時可行的辦法是搭建爬蟲系統來自動爬取實時的互聯網數據,作為數據分析與可視化的基礎。然而現在網站大多都存在反爬蟲機制,Scrapy框架編寫的爬蟲系統在對互聯網網站數據進行爬取時,針對目前網站常用的反爬機制會采取一些措施。它的工作流程如圖1所示。因此本文選取Scrapy爬蟲系統進行爬取新聞數據和招聘數據。
2?除去重復數據
爬蟲是通過URL來定位資源的位置進行數據爬取的,這就會導致一些問題的出現,當然這些問題本身也是不可避免的,因為不同的URL對應的數據可能存在高度的相似性,尤其像新聞信息這樣的數據。為了保證后期數據可視化時效果的合理性與科學性,必須在數據進行可視化之前對爬取的數據去除冗余。本文采取的做法是,在對新爬取的數據進行入庫之前,需要拿新爬取的數據與數據庫中已存在的數據進行文本差異性比較,如果在比較時發現兩條數據差異性比較小則刪除新爬取的數據禁止其入庫,從而避免數據冗余。
本文采用googlediffmatchpatch算法對數據進行差異性鑒定,不是直接用一條數據的全部內容參與差異性分析,而是在比較之前對數據進行關鍵詞提取,如利用Pathon中文分詞組件Jieba分詞,找出最能代表某條數據的全部關鍵詞,通過比較兩條數據的關鍵詞的差異性來間接地確定兩條數據的差異性,從而提高了鑒定的效率。
googlediffmatchpatch算法的思想:使用兩條待比較的數據其中的一條為模板,把作為模板的一條進行復原,統計出復原的步數,再計算出復原成模板最壞情況下的步數,用最壞情況下復原成模板的步數減去實際復原所用的步數,再除以最壞情況下的步數即為兩個帶比較文本的相似度。每個步驟只能做“保持不變”“插入”或者“刪除”操作。
3?數據的可視化分析
完成了數據的獲取以及對獲取的數據進行挖掘與分析工作之后,就可以進一步對數據進行可視化分析。可視化的分析結果能夠顯著地為決策者提供一定的支持。之前爬取的數據已保存在MySQL數據庫中,所以在利用RStudio工具對數據庫中的數據進行分析之前,需要先設置數據源然后利用R語言中的RODBC包提供的相關接口與MySQL數據庫建立連接。最后就是根據要達到的可視化目標,編寫相應邏輯的SQL語句來獲取數據庫中的數據,之后利用R語言豐富的擴展包所提供的相關函數,把獲取的數據轉化成R語言可視化所要求的數據格式便于可視化分析,至此完成對數據可視化分析的工作。
本文主要采用R語言詞云圖對新聞進行了可視化分析,利用餅圖、條形圖和繪制地圖等方式對招聘信息進行了可視化分析。
3.1?新聞數據詞云圖
圖2采用詞云的方式對爬取的所有新聞數據共同提到的關鍵詞匯進行可視化,當鼠標移動到相應的詞匯時,將會顯示該詞匯一共被提及的次數。本文利用wordcloud2這樣一款用于從文本生成詞云圖而提供的工具包進行詞云的生成。
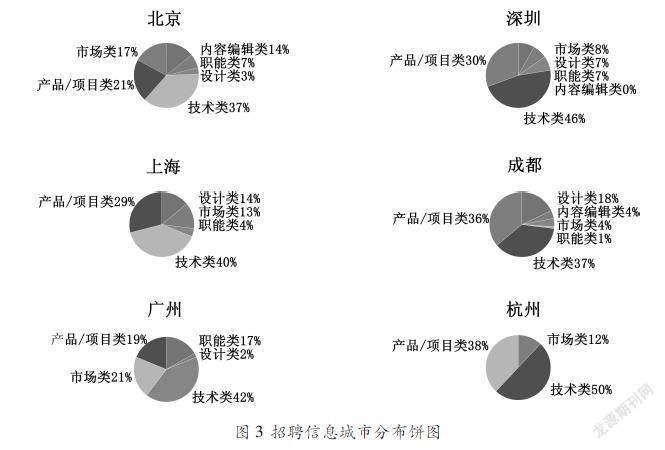
3.2?招聘數據城市分布圖
圖3采用餅圖的形式,展示了數據庫中招聘崗位數量最多的前六位城市的各類崗位的分布情況。利用R語言提取數據和繪制餅圖的代碼如下所示:
library(RODBC)
par(mfrow=c(3,2))
myconn=odbcConnect("MySQLODBC","root","")
works<sqlQuery(myconn,"select?catalog,?count(recruitNumber)?as?recruits?from?newsanalysis_tencent?where?workLocation='北京'?group?by?catalog?order?by?recruits")
city<works['catalog']
recruits<works['recruits']
recruits<as.matrix(recruits)
recruits<as.numeric(recruits)
city<works['catalog']
city<as.character(unlist(city['catalog']))#將數據框類型轉換為字符型
pct<round(recruits/sum(recruits)*100)
lbls2<paste(city,"?",pct,"%",sep="")
pie(recruits,labels=lbls2,col=rainbow(length(lbls2)),radius=1.1,main="北京")
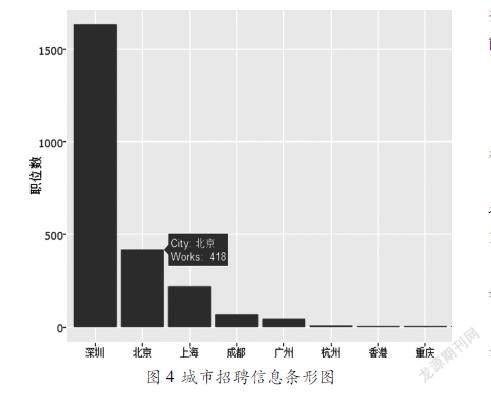
圖4采用條形圖的形式對數據庫中每個城市招聘職位總數進行可視化。當鼠標移動到對應城市的條形圖上時會自動顯示該城市目前的招聘職位總數。利用R語言提取數據和繪制條形圖的代碼如下所示:
library(RODBC)
library(ggplot2)
library(plotly)
library(dplyr)
myconn=odbcConnect("MySQLODBC","root","")
city<sqlQuery(myconn,"select?distinct?workLocation?from?newsanalysis_tencent?order?by?workLocation")
count<sqlQuery(myconn,"select?count(recruitNumber)?as?count?from?newsanalysis_tencent?group?by?workLocation?order?by?workLocation")
city<cbind(city,count)
city$workLocation<reorder(city$workLocation,city$count,function(x){mean(x)})
city<arrange(city,desc(count))
#取前8名
City<city$workLocation[1∶8]
Works<city$count[1∶10]
p<ggplot(data=city[1∶10,],aes(City,Works))+geom_bar(fill='red',stat="identity")+labs(x="城市",y="職位數",title="各地方崗位數量")
p<ggplotly(p,width=672,height=480)
本文基于R語言對比較有代表性的新聞數據和招聘數據進行了可視化分析,并對分析過程中需要注意的重要流程做了詳細的分析與說明。用R語言代碼演示了新聞數據對應的云圖以及招聘數據對應的餅圖、條形圖、城市分布圖的完整繪制過程。R語言是既能處理海量數據,又能提供幾乎整個統計領域的所有前沿算法的強大的數據可視化工具,下一步將對爬取的互聯網數據進行更深入的挖掘,并采用R語言構建一個數據分析和可視化的平臺,能進行更強大的數據挖掘分析和可視化能力。
參考文獻:
[1]劉璐,等.基于topk顯露模式的商品對比評論分析[J].計算機應用,2015,35(10):27272732.
[2]孟詩瓊,孟詩瑤,尹志.基于R語言的汽車消費數據挖掘及可視化方法[J].寧波工程學院學報,2015,27(4):1723.
[3]楊霞,吳東偉.R語言在大數據處理中的應用[J].科技資訊,2013(23):1920.
[4]劉培寧,韓笑,楊福興.基于R語言的Net?CDF文件分析和可視化應用[J].氣象科技,2014,42(4):629634.
[5]孫歆,戴樺,孔曉昀,趙明明.基于Scrapy的工業漏洞爬蟲設計[J].信息安全與技術,2017.8(1):6671.
作者簡介:李翔坤(1978—?),女,漢族,遼寧營口人,碩士,副教授,研究方向:數據存儲、數據挖掘及應用。
