基于FPGA的YOLOv3-tiny卷積神經網絡加速設計
2022-05-06 04:57:04梅志偉丁興軍劉金鵬
艦船電子對抗 2022年2期
梅志偉,丁興軍,劉金鵬
(中國船舶集團有限公司第八研究院,江蘇 揚州 225101)
0 引 言
YOLO(You Only Look Once)是用于目標檢測的一種卷積神經網絡模型,與網絡模型區域卷積神經網絡(RCNN)、單步多框檢測算法(SSD)等相比,YOLO在確保檢測精度的前提下,大幅度提升檢測速度。在2018年提出的YOLO第三代版本中,包括了YOLOv3和YOLOv3-tiny,相比YOLOv3,YOLOv3-tiny精簡了網絡層數,減少了計算量,屬于輕量級的神經網絡模型,更適合應用在嵌入式終端進行硬件加速。
卷積神經網絡模型包含訓練和推理2個過程。訓練包含forward和BP(backward propagation)2個步驟,通過對已知大量樣本的學習,迭代計算損失函數更新網絡節點權重得到最終網絡模型,訓練過程包含大量的數據計算,通常在高性能的圖形處理器(GPU)上運算。推理只包含forward過程,沒有迭代計算和反饋,計算量相對較低,適合應用在計算資源和存儲資源相對受限的嵌入式終端。現場可編程門陣列(FPGA)開發周期短,性能高,編程靈活,通過設計合適的硬件電路對卷積神經網絡進行推理加速,能夠取得大幅度的性能提升。
對于卷積神經網絡硬件加速,國內外學者進行了廣泛研究。通過設計大規模的乘加陣列,谷歌團隊的張量處理器(TPU)引進脈動陣列,增加數據復用,減少數據流動,提升計算性能,但對不同規格卷積核的數據重組難度高,代價大,效率偏低。麻省理工學院(MIT)的Eyeriss為了減小能耗,最大化局部數據復用,通過數據復用與編碼壓縮數據來減少數據搬移,從而達到能效優化的目的,但不同的網絡計算需要重新配置映射到陣列,而且乘加陣列中扇出較多,陣列時序和規模提升難度較大。針對YOLO系列算法的卷積神經網絡硬件加速,重慶大學張麗麗基于高級綜合(HLS)開發工具對YOLO算法進行定點運算,探索網絡結構并行和卷積計算并行,速度上提升6~7倍,但在設計上脫離了硬件架構,加速性能有進一步提升的空間。華南理工大學羅聰研究了數據復用和網絡二值化處理方式,達到了高運算性能,但在檢測精度上有所下降。電子科技大學張雲軻等研究了壓縮網絡結構,利用流水線和并行運算,達到了車輛檢測的實時性要求,但它只針對車輛檢測,相對原YOLO算法其應用面較窄。針對上述情況,在保證通用目標檢測應用場景的前提下,根據YOLO-tiny網絡層設計精度可變的定點量化,對定點數進行重訓練,同時設計特定而高效的硬件架構,在保證檢測精度的情況下,減少了資源使用,提升了加速效率。
1 YOLOv3-tiny網絡特性分析
YOLOv3-tiny網絡層結構如表1所示,YOLOv3-tiny一共包含13個卷積層(conv)、6個池化層(pooling,均為最大值池化)、1個上采樣層(upsample)、2個路由層(route)和2個yolo層。其中對于weight和output列中數據量計算中選取的均為量化后的8 bit定點數。網絡結構中yolo層主要是對數據做logistic變換。logistic變換是一種非線性變換,其計算中包括指數等運算,不適合在FPGA上實現。考慮到其在網絡前向計算過程中的時間消耗較少,因此加速模塊中不包含對yolo層的加速,將這一層計算放到CPU中完成。網絡結構中route1層是將前面某一層的輸出作為下一層的輸入操作,route2層是將前面2層在通道數上進行拼接,硬件實現上控制讀取數據的地址即可進行拼接操作。池化層與上采樣層計算模式簡單,池化層都是對輸入特征圖中的2×2個數據進行比較,得到一個最大值,保存到輸出特征圖中。上采樣層將輸入特征圖中的每個數據復制4次,得到2×2的數據,保存到輸出特征圖中,這2種類型的網絡層在硬件上進行數值比較和數據復制,即可完成加速。
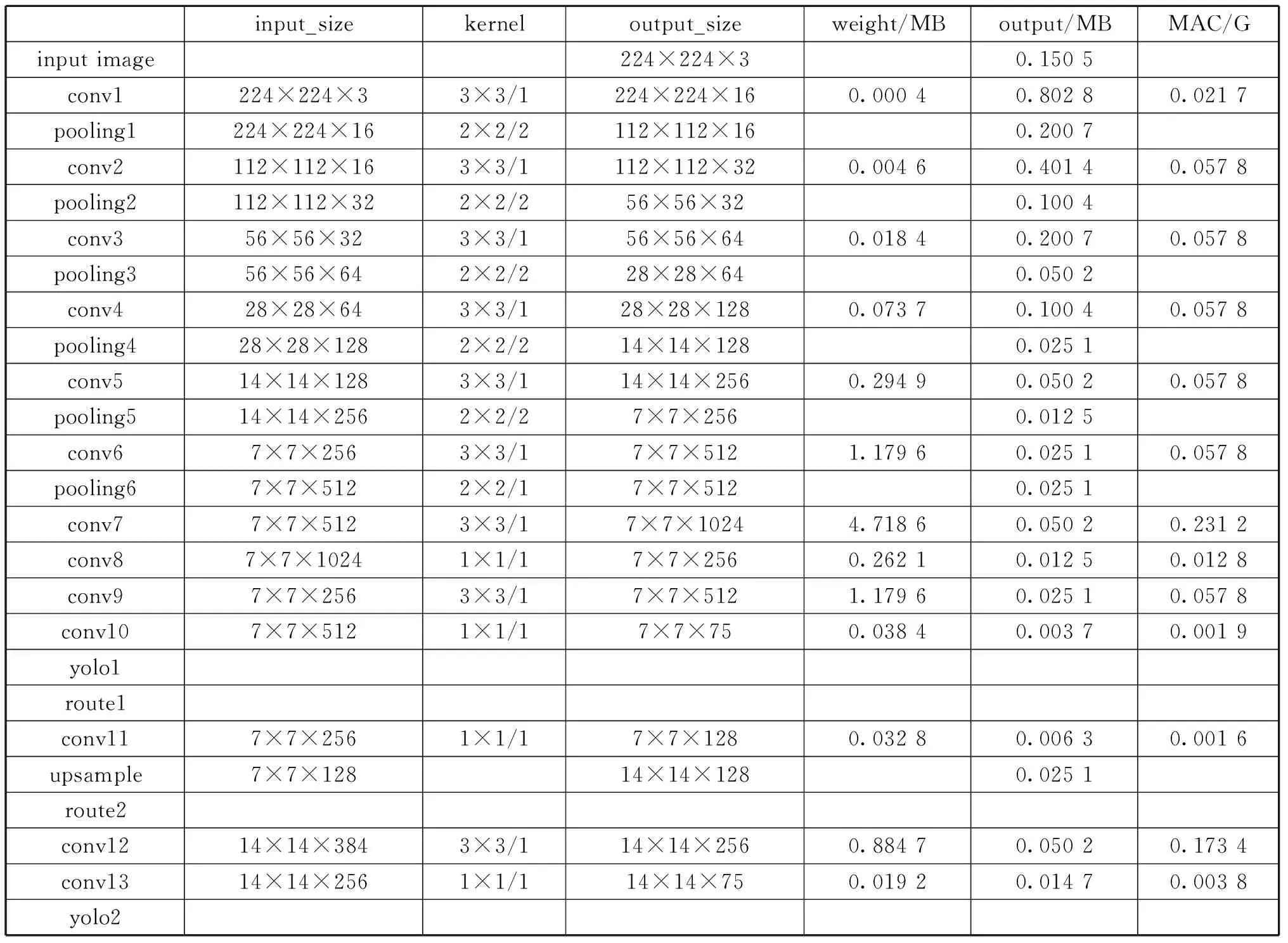
表1 YOLOv3-tiny網絡層結構
卷積層是YOLOv3-tiny網絡的核心網絡層,YOLOv3-tiny的計算量絕大部分集中在卷積層。卷積層中包含大量的乘累加運算和一部分非線性運算。非線性運算在FPGA中均可通過查表法實現,硬件加速重點關注卷積層中的乘累加運算。與AlexNet網絡的卷積層比較,YOLOv3-tiny網絡的卷積層在結構上卷積核有3×3和1×1 2種規格,卷積核步長(stride)均為1,結構較為規整,輸入輸出通道數均為16的倍數。輸出特征圖的寬和高經過最大值池化后,整體呈下降趨勢,最大的規格為224×224,最小的規格為7×7。從數值上分析,為了提升計算性能,增加輸入輸出維度上的并行計算設計。為了提升乘加陣列的計算效率,設計基本乘加陣列計算單元,適應特征圖尺寸。
2 YOLOv3-tiny硬件加速設計
2.1 可變定點數量化
卷積神經網絡往往存在數據冗余,在訓練時通常使用32 bit浮點類型來表示權重參數,數據在參數精度上存在冗余。神經網絡對低精度權重值有非常高的容忍度,較低精度的權重值也不會降低神經網絡的性能。在推理時將32 bit浮點參數量化為低比特定點數,可以在幾乎不損失網絡性能的條件下,顯著降低參數存儲需求和數據傳輸帶寬需求。YOLOv3-tiny原始的權重參數用32 bit浮點數表示,其平均精度(mean Average Precision,mAP)為59.16。測試了權重由不同位寬表示下的性能損失情況,如圖1所示。可見,當位寬減少到12時,性能略微下降,從8 bit開始,位寬每減少一位,性能下降明顯。根據不同數據位數的網絡檢測精度和計算機中常用的存儲位數,選擇將32位浮點數量化為8位定點數。
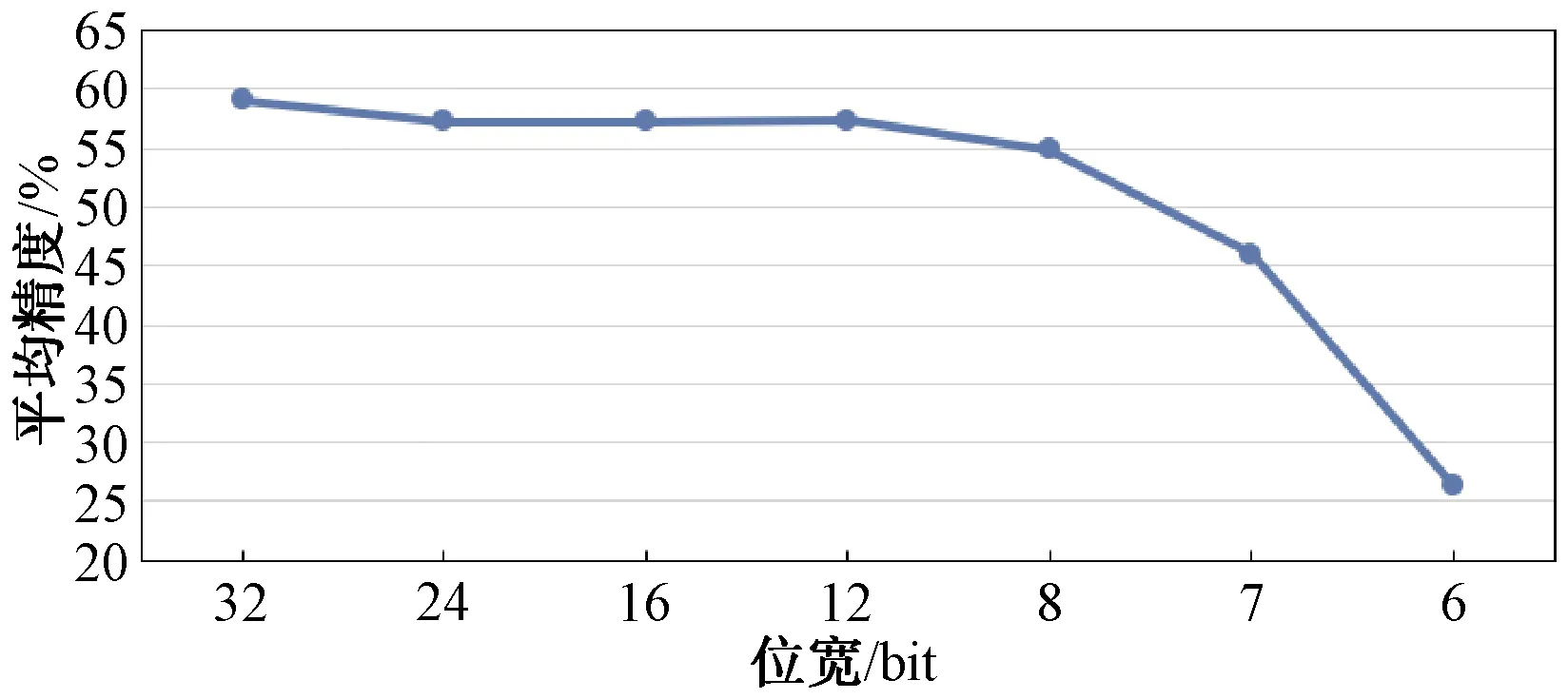
圖1 不同參數位寬下的性能下降情況
定點數是指小數點位置固定的數值表達方式。一個位(一般為2的整數冪)定點數可以表示為(-1)××2-,其中是符號位,是(-1)位的數值部分,代表了十進制小數點的位置,起到比例因子的作用。例如,一個8 bit的整數,當=0時,表示范圍為-128~127,精度為2=1;當=5時,表示范圍為-4~3.968 75,精度為2=0.031 25。在8 bit情況下,不同下的數值表示范圍和精度不同。在位寬確定的情況下,定點數的數值范圍和精度相互矛盾,需要合理選擇比例因子。
為了保證網絡檢測精度,在量化時要選擇合理的比例因子。對YOLOv3-tiny網絡每層的權重參數和輸出特征圖的范圍進行了統計,每層輸出特征圖的原始數值范圍和量化后可表示的數值范圍如表2所示。針對YOLOv3-tiny中各個網絡層不同的數據分布,選擇可變精度的定點數表示量化后的數據,對每層的權重參數、批歸一化參數等進行了統計,并確定了比例因子。

表2 YOLOv3-tiny網絡每層的輸出特征圖數值范圍
2.2 定點數重訓練
當量化后參數位寬下降至8時,網絡性能也存在小幅度下降。引入了重訓練機制,對量化后的權重參數進行重新訓練,可將性能恢復至與高精度參數性能相當的地步。將二值化神經網絡的重訓練方法應用在YOLOv3-tiny卷積神經網絡上,對8 bit量化參數進行重訓練,訓練流程為:
//1.forward propagation
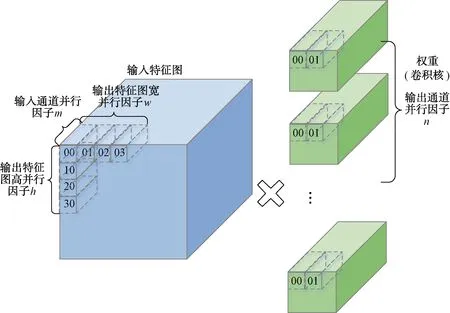
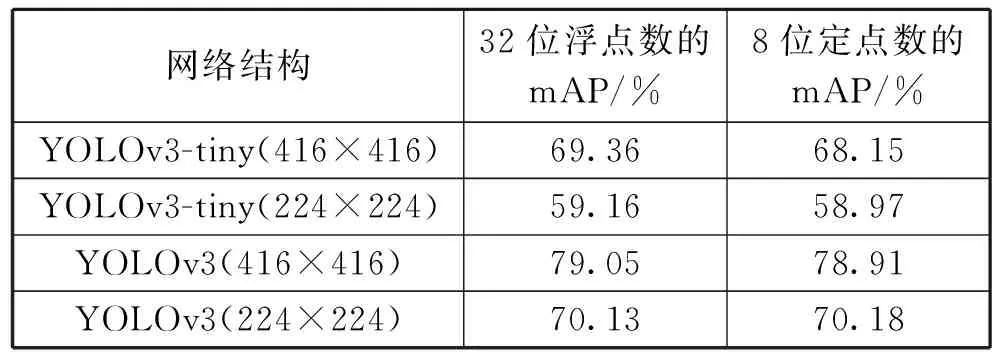
for(=0; { } //2.backward propagation and update for(=layer_max;>=0;--) { } 并行計算設計是硬件加速模塊設計的關鍵。為了提升硬件加速模塊的性能,在卷積神經網絡加速上需要盡可能讓基本計算單元同時進行計算,同時還要兼顧FPGA的資源消耗、硬件加速模塊的工作效率和數據吞吐量。并行計算設計是以上各個因素綜合考慮的結果。并行設計可在卷積計算過程中參與的數據維度上進行選擇設計,卷積核的寬和高在YOLOv3-tiny網絡中有3×3和1×1 2種尺寸。在并行設計上兼容2種尺寸會導致效率的下降,因此選擇在輸入通道、輸出通道、輸出特征圖寬和輸出特征圖高4個維度同時進行并行計算設計。在輸入通道和輸出通道2個維度上,通道數多為16的倍數且數值相對較大。同時考慮到資源消耗和數據吞吐,在輸入通道和輸出通道2個維度上,并行因子均選擇8,能夠讓基本計算單元取得較高的計算效率。類似綜合考慮后,輸出特征圖寬和輸出特征圖高選擇的并性因子均為4。并行計算對應的示意圖如圖2所示。 圖2 并行計算示意圖 大規模的并行計算需要對應大量數據同時參與。在YOLOv3-tiny網絡conv7中參與計算的權重經8 bit量化后為4.7 MB,數據量較大,每一層網絡層的權重等參數儲存在外部雙倍數據速率同步動態隨機存儲器(DDR SDRAM)中。數據通過AXI總線從外部存儲器DDR輸入到FPGA片上緩存。為了方便計算,單元從FPGA片上緩存讀數后直接參與運算,選擇與英偉達深度學習加速器(NVDLA)類似的數據存儲格式對數據進行儲存,減少數據轉換。圖3為權重的存儲格式示意圖,其中為卷積核寬高,為輸入通道數,為輸出通道數,為輸入通道并行因子,為輸出通道并行因子。在設計中、均為8。在數據復用上,由于在YOLOv3-tiny網絡前3層卷積層中,特征圖參數量大于權重參數量,選擇進行輸入特征圖復用。不同輸出通道上的卷積核復用同一輸入特征圖,輸入特征圖復用次數為輸出通道數次。在YOLOv3-tiny網絡后10層卷積層中,權重參數量大于特征圖參數量。選擇進行權重復用,在輸入特征圖上的不同卷積窗口中的數據復用相同的卷積核,得到輸出特征圖平面維度的不同點,權重復用次數為輸出特征圖寬高乘積×。 圖3 權重存儲格式 在FPGA上對YOLOv3-tiny卷積神經網絡進行推理加速時,設計與網絡結構緊密結合的硬件模塊能夠提升運算的計算效率,相比于CPU能夠大幅度減少運行時間,相比于GPU能夠降低能耗,更適合在移動端進行應用。針對YOLOv3-tiny網絡設計的硬件加速結構如圖4所示,主要分為3個部分:數據通路、計算模塊和控制邏輯。在數據通路上,FPGA內部緩存分為對應輸入特征圖、權重和輸出特征圖的片上緩存,FPGA片上緩存作為外部存儲器DDR和計算模塊數據的緩沖橋梁,通過雙緩沖機制與數據復用方法,使得取數與計算以流水的方式不斷進行。各級緩存之間的傳輸通過握手的方式進行,當讀寫雙方的valid與ready信號同時拉高時,數據按照指定方式進行傳輸,當傳輸完成指定數量的數據后,complete信號拉高,完成傳輸任務。 圖4 硬件加速架構 在硬件加速結構,計算模塊完成對conv層、pooling層、upsample層的硬件加速,計算模塊重點在于對卷積運算的加速。卷積運算可以拆分為六重循環的乘累加運算和非線性運算,非線性運算Non-Linearity模塊主要包含了3個步驟:Batch Norm、Add Bias、Activate。在神經網絡訓練過程中,一般會引入Batch Norm(批歸一化)操作,將輸入數據進行歸一化處理,使數據均值變為0、標準差變為1的分布。Batch Norm可以加快訓練速度,提高模型訓練精度。Batch Norm主要是以下的計算: (1) 式中:為輸入數據;為輸出數據;和為當前輸入批次的數據分布均值和方差;為一個為了避免除數為0的很小的常數;和為訓練過程中需要學習的參數。 在推理過程中,往往是輸入單個樣本,因此和為訓練階段記錄下來的均值和方差,和為訓練得到的參數。第2步Add Bias操作對輸入數據加上一個偏移量bias。第3步Activate是對數據進行非線性的激活操作,常見的激活函數有ReLU、Sigmoid、LeakyReLU等。YOLOv3-tiny網絡使用到了LeakyReLU激活函數,公式為: (2) 乘累加運算涉及6個數據維度上的乘累加計算,計算方式簡單,但涉及數據量大。其中3個數據維度上是乘累加計算,3個維度上是并行計算。乘累加運算在硬件加速結構的計算模塊中,分為乘累加陣列(MAC陣列)和累加器2個部分。為了適應在輸入通道、輸出通道、輸出特征圖寬和輸出特征圖高4個數據維度上的并行計算設計思想,乘累加陣列分為16個8×8的塊計算陣列,每一個塊計算陣列為8個并行的乘加樹結構,塊計算陣列映射為輸入通道和輸出通道。每個塊計算陣列的行做乘累加運算,計算結果輸入到累加器中,累加器中通過計數器計算完成3個數據維度上的乘累加運算后得到輸出特征圖二維平面上的點,送入輸出特征圖片上緩存,通過AXI總線將輸出結果傳輸到片外DDR。 在卷積神經網絡硬件加速結構中,由于數據量和計算量過大的原因,通常是每一層網絡層進行加速,輸入數據從片外DDR中輸入,在FPGA上完成加速運算后輸出到片外DDR中。但對于pooling層和upsample層,運算模式相對簡單,主要操作為對數據的比較、篩選和復制。通過對該2類網絡層的硬件加速與卷積層加速模塊進行融合,可以減少一次網絡層數據與片外DDR的往返傳輸,減少了數據傳輸總量。在硬件加速結構計算模塊中,完成卷積層的乘累加運算和非線性運算硬件加速后,加入上下采樣計算模塊完成對pooling層和upsample層的加速運算。route層操作主要對已完成計算的2層網絡層在輸入通道上進行拼接計算,在片外DDR中預留專用route操作層存儲區域,利用控制模塊完成對route操作的拼接運算。控制邏輯的主要分為分塊傳輸控制和網絡層控制2個部分,分塊傳輸控制是根據數據復用方式劃分數據從片外DDR到FPGA片上緩存的分塊傳輸大小和次序,網絡層控制將需要加速的網絡層分為conv層、conv+pooling層、conv+upsample層和route層4類,根據不同類型網絡層調用計算模塊中加速單元完成對應的硬件加速。 在量化重訓練上,在YOLO系列網絡的訓練過程中,對不同輸入圖像尺寸的YOLOv3、YOLOv3-tiny網絡進行了量化重訓練,結果如表3所示。可以看到,量化后的網絡性能損失在可接受范圍內,但是其參數量卻僅為原來的1/4,降低了存儲需求和數據傳輸需求。 表3 量化前后性能對比 經過用8-bit可變精度定點數對32-bit浮點數量化后,代入到YOLOv3、YOLOv3-tiny卷積神經網絡進行重訓練后,我們發現在YOLOv3-tiny網絡檢測精度上,224×224輸入尺寸的圖像比416×416輸入尺寸的效果更好,網絡檢測精度下降到僅為0.19 mAP,網絡性能下降基本可以忽略。224×224輸入尺寸的圖像不經過重訓練后,網絡檢測精度為55 mAP,精度下降為4 mAP;經過重訓練后,量化后的低精度參數網絡的性能可以恢復到和原始高精度網絡相當的性能。 選擇在FPGA上對224×224輸入尺寸的YOLOv3-tiny卷積神經網絡進行硬件加速。YOLOv3-tiny硬件加速結構設計基于Xilinx公司的FPGA開發平臺VC707。開發平臺有Virtex-7型號的FPGA和1 GB容量的DDR3,FPGA具體型號為xc7vx485t2ffg1761C,開發環境為Vivado2 017.04,開發語言為Verilog硬件編程語言。下面從FPGA資源消耗、網絡加速性能和乘加陣列(MAC)計算效率3個方面評估設計的硬件加速結構對YOLOv3-tiny卷積神經網絡的加速效果。對設計的硬件加速結構,設置FPGA的運行時鐘為125 MHz。經過Vivado綜合與實現后,得到的資源消耗如表4所示。其中使用塊隨機存儲(BRAM)數量為136,數字信號處理模塊(DSP)數量為576,Vivado實現相應電路后給出的功耗為2.952 W,硬件資源消耗少。 表4 FPGA資源使用情況 在硬件加速結構內部設置計數器,在網絡層數據從片外雙倍數據速率存儲器(DDR)傳入FPGA片上緩存時開始計數,在網絡層硬件加速完成后,所有輸出特征圖數據傳出到片外DDR后停止計數,統計網絡層在FPGA上運行時間和網絡層總的乘累加數量,計算得到網絡層的加速性能和MAC陣列計算效率。各個網絡層的加速運行時間和MAC效率匯總如表5所示。YOLOv3-tiny卷積神經網絡中除yolo網絡層外,conv、pooling、upsample和route網絡層均可在設計的硬件加速結構中運行。從表5中可以看出:網絡層MAC計算效率為37.03%~99.21%分布,各個網絡層效率相差較大,主要原因在于不同的網絡層分塊計算劃分帶來的差異;除此之外,數據傳輸、非線性運算也會占有一定的影響因素。分析conv1+pooling1網絡層的37.03%,由于輸入通道數為3,在輸入通道并行因子為8的MAC陣列中,理論上最高效率只能達到37.5%;對于conv10網絡層,7×7×75的輸出特征圖在對應并行因子維度為4×4×8的并行維度上,實現MAC計算效率僅為50.28%;而conv3+pooling3網絡層,各個并行維度都能整數劃分;MAC陣列在分塊計算時不存在資源的浪費,對應計算效率能達到99.21%。 表5 YOLOv3-tiny網絡層加速性能 YOLOv3-tiny在設計的硬件加速結構上運行的網絡層總乘累加數量為0.793 2 G,網絡加速時間總共約為8.5 ms,所有加速的網絡層算力約為186.6 GOPS,加速網絡層MAC計算效率平均值達到74.54%。在對輕量級yolo網絡進行加速的研究中,將本文設計的硬件加速結構與其他文獻的加速結構在性能上進行比較。對比張麗麗、黃智勇的加速研究,本文結構在硬件上專為YOLOv3-tiny網絡設計,從大規模并行計算設計到大范圍數據復用,加速設計更為深入,相比1 s的運行時間提升了2個數量級;對比張雲軻的加速結構40.8 ms的加速時間,本文加速結構使用的MAC陣列并行度大,運行頻率高,運行時間有4.8倍的提升,并且不局限于車輛檢測,應用范圍更廣;對比羅聰的研究,相比二值化YOLO網絡后的加速時間僅為6.88 ms,與本文加速結構8.5 ms的加速時間相差不大,但網絡檢測精度相比其在mAP上有5%的下降,本文加速結構相比原網絡檢測精度基本保持同一水平。 本文對YOLOv3-tiny卷積神經網絡硬件加速進行研究,在深入分析網絡特性后,提出一種基于FPGA的YOLOv3-tiny硬件加速結構。本文通過對YOLOv3-tiny網絡參數進行可變精度定點量化來減少網絡計算量和數據存儲量,針對量化后出現網絡精度下降的問題采取量化重訓練的方法保證量化后的網絡精度,數據從32 bit浮點數量化為8 bit定點數,數據存儲和計算量下降,網絡檢測精度基本不變。本文在輸入輸出通道和輸出特征圖寬高4個維度上進行并行計算設計,設計了4×4×8×8規模的計算陣列,提升網絡加速性能,加速算力約為186.6 GOPS;通過沿用類似NVDLA的數據存儲格式,針對不同網絡進行不同類型的數據復用,減少數據傳輸,網絡加速時間約為8.5 ms;對網絡層提取共性、區分不同特性,設計了除yolo層外的YOLOv3-tiny高效網絡加速硬件架構,MAC整體計算效率為74.54%。本文基于FPGA設計的針對YOLOv3-tiny卷積神經網絡的硬件加速結構,在綜合性能上優于目前出現的研究方案,并且計算資源和存儲資源相對較少,在移動端人工智能加速應用是一個相對不錯的選擇。





2.3 并行計算與數據存儲

2.4 硬件加速架構



3 實驗結果與分析


4 結束語
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
現代裝飾(2020年7期)2020-07-27 01:27:42
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
流行色(2020年1期)2020-04-28 11:16:38
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術啟蒙(2018年7期)2018-08-23 09:14:18
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
