走向可解釋性:打開教育中人工智能的“黑盒”
2022-05-13 23:31:53劉桐顧小清
中國電化教育 2022年5期
關鍵詞:模型
劉?桐 顧小清
摘要:教育是人工智能的重要應用領域,探索教育中人工智能的可解釋性,是讓人工智能在教育領域中更具“責任感”的重要議題。該文從教育中人工智能應用的現實問題出發,重點回應教育中人工智能的可解釋性是什么,做了什么,以及未來走向三個問題。首先,以數據、任務、模型、人四個關鍵要素為切入點,分析闡述教育中人工智能的可解釋性內涵;之后縱觀教育中人工智能的可解釋工作的演進過程,分析得出已有工作在教育意義注入、模型趨于復雜以及單向解釋信息傳遞等方面的局限性;最后,從知識聯邦、模型融生、人在回路三個角度,闡釋教育中人工智能可解釋性的未來發展方向。
關鍵詞:教育人工智能;可解釋性;“黑盒”模型;人在回路
中圖分類號:G434 文獻標識碼:A
* 本文系2020年上海市科學技術委員會科研計劃項目“教育數據治理與智能教育大腦關鍵技術研究及典型應用”(項目編號:20511101600)研究成果。
縱觀歷史,20世紀70年代出現的專家系統(Expert System)是人工智能應用教育領域的早期標志[1][2],時至今日,以個性化差異化為目標的自適應學習系統,以及軟硬兼備的智能教育設備走進人們視野,人工智能成為有效推動教育教學變革的重要工具[3]。觀其背后,教育與人工智能從以專家知識管理為主的初步結合階段,走到以智能算法、教育大數據、云計算等技術交叉助力的應用爆發階段,這使得人工智能賦能教育的倫理問題逐步凸顯[4]。因此,在對人工智能存有一種理性防備的情況下,安全可靠的應用人工智能成為教育領域中亟待解決的問題。聚焦當下,人工智能呈現出一種“大數據+高算力+深度學習+小任務”的應用形態。深度學習算法作為人工智能的主要核心,是一種“端到端”式的知識挖掘模式,雖然取得優異的任務表現,但計算過程與求解結果難以被人理解,因此有學者提出“我們生長在一個‘黑盒世界’”[5]的言論。
站在教育立場當中,可解釋性的缺位引發出以下三點問題:首先,人工智能應用難以落地。由于最終結果不可解釋,造成人們難以理解最終結果,無法提供可靠的確定性信息,在實驗室環境中的人工智能難以在教育情景中尋找認同,缺少落地的先決條件;其次,增加教育決策的潛在風險。由于算法決策過程不透明,機器在數據中如何學到知識以及學到哪些知識不可而知,因此,在計算結果上存在較大的不可預見性,影響教育決策者的判斷依據,增加教育決策風險;最后,增加教育不公平與倫理風險。算法模型的不可解釋,忽視了人的知情權益,影響了人的主體地位,同時,會造成算法開發者與使用者之間的信息不對稱,造成被“算法綁架”的不公平現象。
因此,為了避免人工智能弱解釋性所帶來的消極影響,可解釋性問題獲得廣泛而持久的研究[6][7]。諸多國家與國際組織也圍繞此話題進行了相關政策的制定。例如,我國在2017年印發的《新一代人工智能發展規劃》中提到要“重點突破自適應學習、自主學習等理論方法,實現具備高可解釋性、強泛化能力的人工智能”[8]。美國國防部高級研究計劃局設立“可解釋人工智能(Explainable AI)項目,旨在提高人工智能算法的可解釋性[9]。歐洲《通用數據保護條例》(General Data Protection Regulation,GDPR)中賦予其公民受算法決策影響后“獲得解釋的權利”,從而降低“黑盒”所帶來的公民權力侵犯與隱私問題的風險[10]。
探討教育中人工智能的可解釋性問題,可使其在未來走的更加可靠安全、更具“責任感”。因此,本文主要回應較為關心的幾個問題,即,教育中人工智能的可解釋性是什么?在教育領域中,我們做了哪些與可解釋性有關的工作?存在哪些局限和問題?我們未來又該走向何處?由此,才可將人工智能與教育情景適切性地結合,讓人工智能在教育應用之路走得更為深遠。
本部分回應前文提出的“教育中人工智能的可解釋性是什么?”這一問題。首先系統闡述“可解釋性”的內涵,進一步探討教育中人工智能的可解釋性,從而更加清晰明確教育中人工智能可解釋性的內涵與特征。
(一)可解釋性的內涵
談及解釋的概念,在科學哲學中,早期對于“解釋”的理解,常常會把實用主義和語境擱置,而把重點放在構成“解釋”的形式關系或特征的說明上,例如,Hempel認為解釋的本質是一種“演繹法則”[11]。在這種觀點下,解釋就像邏輯上的證明,復雜的規律和演繹順序構成了解釋。雖然此觀點在科學哲學中獲得了較多批評,但卻是許多解釋理論討論的起點,衍生出更多層次的解釋理論,例如將解釋作為一種機械的因果推理形式[12],將解釋作為一種統計推斷的形式[13]等。而隨著解釋理論的發展,實用主義的觀點也逐漸獲得人們認可,他們認為“解釋”通常與解釋的情境有關[14],即在不同的背景下,需要不同的解釋來闡明同一種觀察結果。但總的來說,解釋是一組陳述,通常用來描述一組事實,闡明這些事實的原因、背景和結果。
可解釋性是在解釋的基礎上的進一步擴展,不僅是解釋者的思維產物,還會涉及到被解釋者。對于可解釋性的內涵,當前主要有以下三種觀點:
1.從技術開發的角度。將可解釋性視為一個系統工程,通過開發相關的技術工具,達到理解與管理人工智能技術的目的。例如,xAI(Explainable Artificial Intelligence)項目中將可解釋性定位為,使人類用戶能夠理解、適當信任和有效管理人工智能的機器學習技術[15]。
2.從計算過程的角度。從操作的層面理解可解釋性,通過調整數據輸入、模型參數等關鍵要素,從結果的變化來尋找其中的因果關系,達到人可理解的“尺度”。例如,加州大學伯克利分校在《人工智能系統挑戰的伯克利觀點》中將可解釋性定義為“解釋人工智能算法輸入的某些特性引起的某個特定輸出結果的原因”[16]。
3.從人理解的角度。更多的學者是從人的角度定義可解釋性,認為可解釋性是為人提供解釋的過程。例如,Bao等人提出可解釋性是指人類具有足夠的可以理解的信息來解決某個問題[17]。再如Arrieta等人認為可解釋性是面向特定受眾,通過提供模型的細節和原因,以使其功能清晰或易于人的理解[18]。
綜上而言,可以說解釋是解釋者的產物,而可解釋性取決于被解釋者。它受到被解釋者個人經驗(例如專業背景)的影響,個體間的差異會影響可解釋性的深度。由此我們認為,可解釋是人工智能的固有屬性,而可解釋建立在人可理解的“尺度”上,通過恰當的方式,傳遞人能讀懂的信息,其目的在于建立人機之間的信任關系。
(二)教育中人工智能的可解釋性
前文給出了解釋以及可解釋性的內涵,聚焦在教育領域中,可解釋性的內涵相應也會發生變化。因此,本文結合教育自身特性,抽取可解釋工作的關鍵要素,從操作層面進一步理解教育中人工智能的可解釋性。
谷歌大腦團隊的首席專家Been Kim,將可解釋性的主要工作歸納在評價性公式之內[19]:
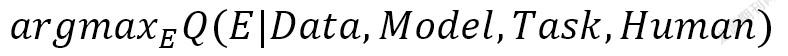
其中Q為可解釋性的評價方程,E是實現可解釋性的具體方法,可解釋性工作即,在一定的數據(Data)和任務(Task)范圍內,通過實現可解釋性的方法,來訓練機器模型(Model),從而達成人(Human)的最大程度的理解。在實際操作過程中,數據、任務、模型以及人的理解是開展可解釋工作不可忽視的四個關鍵要素,據此,教育中人工智能的可解釋也具有更為多樣的內涵。
首先,教育領域中存在教學、學習、管理、評價等諸多教育情境,不同情境中發生的教育教學活動處于動態同步發生的過程,具有碎片化、多維度、時序性的特點,大范圍的數據采集會帶來諸多問題,例如,教育數據采集工作已成為投入與產出之間的動態博弈,因為增加一個新的數據采集維度,就可能增加巨大的建設成本,但卻難以保證數據的有效性。可以說,教育數據是在一定教育情境中對教育現象的數值化描述。而教育數據角度的可解釋性是在數據特征級別上圍繞教育現象的表述,即以“先驗知識+數據驅動”的形式抽取采集維度中的關鍵特征維度,在節省數據采集成本的同時,以數值化的形式融合多源數據,從而進一步明確數據采集方向。本質上,教育數據角度的可解釋性以挖掘數據特征為目標,從而推斷“采集哪些數據”這一關鍵問題。
其次,認識發現教育中的客觀規律,是教育研究與實踐的主要目的。在當下,以數據為工具研究教育的客觀發展規律,是時代背景下的新興研究范式。在大量數據輸入的情況下,機器自動化計算為我們提供了一定置信區間內的關系可信度。因此,在預測基礎上,通過與教育現象的結合,發現教育現象間的相關關系,關聯關系,再到因果推理,而最終結論是在確定性與概率性之間往復權衡,建立出相對完備的解釋關系。進一步說,教育任務角度的可解釋性工作重點探索教育現象中的復雜多樣關系,與先驗假設之間建立關聯,形成邏輯自洽的時空一致性結論,即對教育規律的關切。
再次,教育算法模型是挖掘教育數據價值的主要表現形式,模型設計的透明程度與最終解釋方法與理解效果有直接關系。因此,教育算法模型角度的可解釋性大致可分為三種類型:(1)參數模糊模型的解釋性,作為一種技術手段,如果可明確人工智能技術的具體功能屬性,無需解釋其內部結構或模型內部處理數據的計算方法,使人類能夠理解其功能,知道模型如何工作,滿足功能使用需要,但是具體的參數設置并未有比較扎實的數理基礎。例如當前的主流深度學習模型就具有此特征。(2)參數明確模型的解釋性。此類模型可通過研究者或者數據科學家來解釋,例如在教育測量中廣泛使用的項目反應理論(IRT模型),通過對數學公式的解讀以及相關圖示的形式,達到模型本身的可解釋。(3)參數外顯模型的解釋性,滿足完全理解的算法模型。這與模型本身的屬性相關,主要用于解釋本就透明的模型,或稱白盒模型,例如決策樹模型的結果以“if/ then”的表達形式呈現,是人類能夠讀懂的自然語言。模型映射結構,換句話說模型的參數設置,參數設置形式不同,可解釋性也不相同。
最后,從教育中“人”的角度考慮最終的解釋效果。人工智能在教育中的應用主體涉及到決策者、學生、教師以及研究者等人群,但個體所具備的人工智能經驗有所不同,由此造成可解釋的最終效果不盡相同。結合不同教育算法模型的透明程度,理解程度也可分為三個層次:(1)“黑盒”理解層次,對應參數模糊的算法模型,由于無需了解詳盡的模型信息與實現機制,可解釋性的重點在于將模型輸出結果與特定教育情境結合,合理控制數據輸入與結果輸出即可。(2)局部理解層次,對應參數明確的算法模型,主要關注模型的局部效果,以一種“控制變量”的方式,建立模型給出的預測值和某些特征之間的作用關系,可能是線性關系,也可能是單調關系,更加關注單條樣本或一組樣本。例如1970年,Salmon在試圖解釋概率現象時,通過移除模型的組成部分來尋找改變概率的因素來篩選因果影響,從而獲取高概率結果[20]。(3)全局理解層次,對應參數外顯的算法模型,由于模型是以通俗易懂的自然語言方式呈現,應用主體能夠了解模型的內部規則與計算流程,從而建立輸入特征數據與最終結果,以及輸入特征間的相互作用關系,進一步達成解釋和理解模型決策過程的效果。
綜上所述,教育中人工智能的可解釋性更加側重教育語義的注入,是解釋者借助機器模型,通過人能夠理解的自然語言的解釋方式,闡述教育現象中的因果關聯,尋求被解釋者的意義共鳴的過程。在這之中,主要涉及到人、人工智能以及二者之間的交互過程,解釋者使用的數據輸入,設計的算法結構與解釋方式,以及被解釋者的接受程度,交互決定了教育中人工智能的可解釋程度。
從20世紀70年代到21世紀初,人工智能在教育中的應用范圍與用戶群體在不斷擴大,為了更加安全可靠的使用人工智能技術,在歷史演進過程中,人們圍繞可解釋性陸續提出了許多方法與策略,也在不斷修正已有做法。本部分在教育中人工智能的可解釋性內涵的基礎上,分析討論已有的工作進展,從而可更加明確現有做法的優劣勢,為后續可解釋性工作的開展提供借鑒依據。
(一)教育中人工智能可解釋性的演進過程
本部分基于可解釋性的關鍵要素,從數據利用、模型算法、解釋方式以及用戶接納四個維度,分析討論人工智能在教育中可解釋性的演進過程,如表1所示。
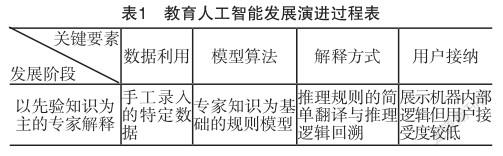

1.以先驗知識為主的專家解釋
在20世紀70年代左右,人工智能的概念被提出,第一代專家系統(Expert System)應運而生,例如SOPHIE-I[21],BUGGY[22]等,它們是人工智能在教育領域應用的初始形態。早期的專家系統設計較為樸素,主要用于特定問題的診斷以及決策輔助。系統通常由專家知識以及推理引擎構成,專家知識以條件規則的形式出現,推理引擎主要用于條件判斷以及邏輯的推演,由此也掀起了可解釋工作在教育人工智能領域的探索。
在數據利用層面,受到時代技術條件的限制,數值形式的數據并未被大規模的采集存儲,數據通常是通過手工方式錄入系統,例如XPLAIN系統,它會要求用戶輸入特定類型數據,從而依靠固定模板解釋正在做的事情,同時,系統也會扮演導師的角色,為經驗不足的用戶提供詳細的解釋信息[23]。
在模型算法層面,早期系統設計較為簡單,此階段的系統較少使用數學模型進行計算,規則模型是整個系統的運行基礎,同時也是系統可解釋工作的主要知識來源。通過專家知識間的邏輯規則形成簡單的語義網絡,根據條件概率完成信息傳遞流程。例如斯坦福大學在1975—1980年開發的Mycin系統,里面包含了超過600條專家知識規則,它會提問用戶一系列簡單的是/否或文本問題,最終提供一份包含診斷概率的結果列表[24]。
在解釋方式層面,當時的人工智能主要用于推理任務,如何解釋機器推理過程成為當時主要的可解釋方向。當時可解釋工作大多將機器內部的推理邏輯展示給用戶,通過回溯與數據及解釋相關的推理鏈,用人類可讀的語言表達用于做出決定的規則[25],例如,它們通常是將LISP語言中的if-then產生式規則,簡單翻譯并提供給用戶。
在用戶接納層面,由于機器內部的規則最初由專家制定,有的規則是針對模型正常工作而設計,并不旨在讓用戶讀懂,并且反饋給用戶的可解釋信息是對規則的簡單翻譯,因此,即使提供了決策規則和步驟,但也不一定是用戶所關心和需要的。
綜合來看,早期的解釋工作集中在表達機器內部的狀態、目標以及執行計劃等內容,雖然模型足夠透明,但當時的工作具有時代的局限性,首先,解釋力較差,由于專家知識庫的不足,使得可解釋工作限定在特定專家規則之上,靈活性以及可擴展性較差,僅能對給定問題進行程序化描述;其次,知識表示存在缺陷,缺少豐富的術語基礎和領域因果知識,如果用戶使用與知識庫相異的其它知識表示方式,系統將會無法響應用戶的解釋請求。
2.以統計學習為主的數理解釋
隨著時代技術的進步,第一代專家系統逐步被智能導師系統(ITS)所替代。此時的算法模型更加關注對學習情境的感知理解[26],學習情境包括學習者個人信息、學習歷史、學習目標和領域知識等內容,同時,模型還可利用學習數據不斷迭代改進,進行自我更新,這也為可解釋性工作帶來了難度。
在數據利用層面,此階段能夠利用的數據類型有所增加,包含學生的個人信息、學習行為以及系統對學生的診斷數據等數據。例如,Wick和Thompson利用學生行為數據,提出了一種重建解釋(Reconstructive Explanation)方法[27],該方法存在兩個知識庫,第一個知識庫包含所要學習的專家知識,第二個知識庫中是學生學習狀態點以及假設出錯情況的集合。系統會記錄學生問題解決路徑,之后,結合過程行為數據以及第二個知識庫進行系統結果解釋。
在模型算法層面,概率模型的應用。例如,貝葉斯知識追蹤模型(BKT)[28],學生對知識點的動態掌握狀態影響著題目的作答結果,整個過程非常符合隱馬爾可夫模型的建模過程,借此模擬學生知識狀態的轉移,從而預測學生知識掌握程度。與之前不同的是,此時的模型已經從固定的規則模型,發展成為能夠基于統計信息學習更新的機器學習模型,由于參數較為固定,可以達到前文所提到的參數明確模型的解釋性。
在解釋方式層面,不同于為用戶提供推理規則簡單翻譯文本的方式,此階段的人機交互能力有所提升,機器能夠讀懂用戶的問題,更加貼近人類之間的交流溝通。例如,Scholar系統使用了面向信息結構的ISO(Information-Structure-Oriented)解釋框架[29],它可以結合交互情境特征,生成文本、問題和相應的答案,使人機交互變得更加自然。同時,反事實的解釋、對比性的解釋也出現在此階段的解釋方式中。
在用戶接納層面,此時教育人工智能的任務更加多樣復雜,不僅包含決策推理等早期任務,同時也包含幫助學習者進行復雜技能提升的任務[30]。因此,可解釋的目標不僅停留為用戶解釋,而是讓用戶信服,越來越多的研究者以及開發者意識到,為了讓用戶接受模型結果,千篇一律的解釋并不能解決用戶需求,而可以通過建立學習者模型,為用戶提供個性化的解釋信息。例如,有的研究者提出從評估用戶水平、定制化學習內容以及定制化學習目標三個層面建立學習者模型[31],診斷評估學習者當前知識水平等信息,為之生成特定的學習目標及內容,從而達到學習者的心理預期,建立學習者與機器之間的信任關系。
綜合來看,此階段的解釋工作意識到上一代工作的不足,發現僅表述系統內部狀態與推理邏輯并不能與用戶達成共識,并且用戶可能也不需要此種解釋。因此,在繼承上一年代工作的基礎上,此階段解釋工作在用戶與系統兩個角度進行了改進,首先,強調學習情境,建立用戶模型,為每個用戶提供個性化的解釋內容,其次,將解釋任務看作為系統自身的問題解決過程[32],Brézillon認為解釋是用戶和系統之間的合作問題解決過程,雙方都需要理解對方的目標才能實現可解釋性[33]。
3.以深度學習為主的歸納解釋
隨著信息技術手段不斷更新,教育數據持續積累,學習分析技術的出現,建立了數據科學與教育的新連接。同時,人工智能浪潮再次襲來,“人工智能+教育”成為新的增長點,對可解釋性的需求卷土重來。為了追求算法的高效能,在研究領域與工業界出現了越來越多的復雜人工神經網絡,由于深層網絡自身不夠“透明”,神經元之間的信息傳遞人們無法解釋,算法模型從數據中如何學到知識以及學到了哪些知識不可而知。并且,數據特征過于復雜,人們難以理解高維度輸入數據的真實意義,也就無法進行合理解釋。
在數據利用層面,教育數據捕獲和處理技術的進步,多模態數據被廣泛應用于教育場景之中。Lane和D’Mello總結了使用不同的生理數據(例如凝視、面部表情、fMRI、EMG、EEG)來衡量學習者注意力、專注力、認知負荷和學習策略的方法[34]。例如,Beardsley等人使用EEG和行為數據(例如反應時間)[35],使用機器學習算法來預測學生的在回憶任務上的表現。與之前不同是,多模態數據增加了數據來源通道,不同通道數據的相互映證,增強了模型結果的可信度。
在模型算法層面,統計學習模型依舊在被廣泛應用,例如,卡耐基梅隆大學提出PFA(Performance Factors Analysis)算法,基于統計方法,利用試題難度和學生歷史成績預測學生成績[36]。進一步,深度學習模型成為當前主流方法之一,例如,盧宇等人在循環神經網絡基礎上,加入逐層相關傳播方法(Layer-wise Relevance Propagation)[37],解釋學生知識學習的過程。Nakagawa等人通過數值化學生知識建構過程中潛在的圖表示結構[38],利用圖神經網絡建立學生深度知識追蹤模型,并將預測結果利用網絡結構圖表示,達到較高的解釋與預測效果,與之類似的還有AKT[39]、RKT[40]等,但由于算法本身的限制,大部分算法并不具有較強的可解釋性。
在解釋方式層面,計算機技術在視覺、自然語言、語義標注等方面的進步,為解釋方式提供了諸多可行方法。例如,朱軍等人提出可視化解釋系統CNNVis[41],通過數據預處理模塊、聚合模塊以及可視化模塊,提取神經元的特征、連接,分析網絡學習的特征、激活特征以及對結果的貢獻等,同時還具有交互功能,可以人為改變數據聚合過程,從而更好地觀察模型內部的運作過程。再如Ribeiro等人提出較為通用的可解釋框架LIME[42],其核心是在算法模型的結果附近訓練一個可解釋的模型,比如線性模型,實現原模型預測結果的局部可解釋性。
在用戶接納層面,以用戶為中心的解釋性成為當前研究的重點。例如有學者提出面向設計師的可解釋AI框架,從而幫助游戲設計師在設計任務中,更好地利用人工智能技術[43]。Bauer與Baldes提出一種基于模型本體的用戶界面[44],通過交互的方式幫助用戶更加深入地理解模型結果。Wang等人基于哲學與心理學理論[45],構建以用戶為中心的可解釋AI框架,并在此基礎上,確定了人類認知模式驅動建立可解釋AI的需求途徑,以及如何減輕常見的認知偏差。
(二)教育人工智能可解釋性的局限性
回望教育中人工智能可解釋性的發展過程,雖然已經提出很多方法,但依舊存在瓶頸與局限性:
1.教育數據生命周期缺少教育意義的注入。隨著人工智能技術與理念的不斷進步,其所利用的教育數據經歷了關注學習者個體基本屬性(如年齡、學習風格等)到基于系統客觀記錄數據(如在線學習行為流等)再到多模態數據(如眼動數據、生物電數據等)的過程。本質上,經歷了從主觀走向客觀,從單通道走向多通道,從個體走向環境的過程。
但隨著所能采集的數據類型源源不斷的增加,在處理過程中存在兩點問題:首先,高維度數據難以被常人理解,目前大多數人工智能算法數據輸入為矩陣形式,例如將圖片轉化為二維矩陣或者多維張量的形式輸入,此做法易于算法理解,但缺失了與元數據之間的實際意義關聯。例如,在自然語言處理中用到的詞嵌入(Word Embedding)技術,通過機器訓練的方式,學習每一個字或詞在向量空間中的唯一表示,通常是一個高維向量,并且每一維都缺少對應的實際意義,但人是無法理解的。其次,數據融合過程成為現實困境,不同數據流從橫向跨度上描述了教育現象發生的過程,但是如何在多模態數據間實現信息匹配與意義建構極具挑戰性,當前的主流做法是將高維向量進行拼接,而數據意義建構則依賴于后續的模型計算,但為何這樣拼接很難解釋。綜合來看,從數據采集、清洗到模型輸入、訓練以及輸出,在整個數據利用的生命周期中,缺少教育意義的注入,由此帶來教育活動意義的描述偏差,將會損失可解釋的空間。
2.模型設計趨于參數模糊的復雜模型。教育中的人工智能算法模型的解釋性發生了從基于規則模型解釋到基于數據學習模型解釋的轉變。本質上,規則模型屬于演繹方法,而數據學習模型屬于歸納方法[46],前者將專家知識符號化,以演繹的方式得出結果,后者通過大量的數據,無限逼近某種未知的規則,因此存在可解釋性差異。具體來說,規則模型更接近因果關系,調整規則會帶來顯而易見的變化,可解釋性更強;數據學習模型具有非線性特征,雖然帶來了較好的系統涌現效果,然而過于依賴參數設置與調整,無法主動思考與決策,大部分情況下很難解釋。
不難發現,復雜算法模型逐漸成為數據挖掘的主流力量,但卻增加了解釋工作的難度。例如,在知識追蹤任務中,深度知識追蹤模型可建立復雜知識點之間的關聯,反映學生知識點掌握程度的連續變化,預測效果也明顯高于傳統貝葉斯知識追蹤模型,但由于深度模型的“黑盒”屬性,卻難以給出預測結果的依據與原理,降低了結果的可信度;由此,也造成了第二個問題,復雜模型與教育場景的適切性匹配問題,主要考慮針對一定的教育現象,合理建立模型參數與教育現象特征之間的映射關系。當前,在計算機視覺、自然語言處理領域取得優異效果的算法,被應用于教育情境之內,缺少對教育現象的獨特分析理解,例如,深度知識追蹤中用到的卷積神經網絡(CNN)、長短時記憶網絡(LSTM)以及其它更為復雜的模型,由于算法設計階段所考慮的應用任務不同,但被解釋者的差異也會造成結果認同感的降低。
3.解釋過程是解釋者的單向信息傳遞。解釋過程以“如何得到此結果”為問題核心,從為用戶展示機器內部邏輯的形式,再到模型內部可視化等人類“尺度”的形式,其最終目標是尋求被解釋者意義認同,但整體過程普遍是由人工智能技術本身驅動,而非來自真實用戶的需求。被解釋者作為解釋過程的重要一環,一直處于被動接受的狀態,解釋信息的單向傳遞,難以形成解釋的閉環,會造成以下兩點問題:首先,模型修正效率降低,在模型部署應用階段,由于模型訓練階段缺少被解釋者的主動參與,造成數據與模型參數不可修改的情況,因此會增加模型修正調整的周期,降低部署應用效率;其次,容易造成倫理風險,由于解釋內容與方式受解釋者控制,容易造成被解釋者與解釋者之間信息的不對稱,走進倫理道德誤區。因此,現有的解釋過程只停留在技術層面,缺少一種以用戶為中心的務實且自然的方式,不利于利益相關者之間的對話。
針對前文所提到教育中人工智能可解釋性的局限性,本部分探討未來可解釋性的發展方向,主要包括:以知識聯邦為主要思路的數據合成,可為人工智能的可解釋性提供教育意義;以透明“白盒”與追因溯源的模型融生,可推動教育中的人工智能從可解釋性走向可信賴;以人在回路為中心的混合智能,可為教育中人工智能的可解釋性提供質量保障。
(一)知識聯邦:融入教育語義的數據合成
正如前文所述,分布式、碎片化是當前教育數據的主要特征,隨著此類數據體量與來源的逐步擴張,數據豐富度增加的同時也為可解釋工作帶來困難。不僅考慮“數據解釋了什么”并要考慮“用哪些數據解釋”。因此,在未來,如何有效處理融合數據、提取數據特征成為可解釋性工作的一大挑戰。
首先,由于數據產生在的不同教育場景中,采用中心化匯聚的形式不僅容易造成成本浪費,同時也易造成數據泄露。因此,可通過建立一套的教育語義編碼規范與語義數據交換標準,在特征級別實現數據一致化與標準化,將數值數據轉換為人類與機器都可理解的語義數據。之后,利用分布式的思路,建立知識聯邦,將語義信息存儲于本地,通過語義數據交換標準,在數據利用階段進行分布式數據抽取。不僅有利于在語義層面進行可解釋性數據融合,也在保障數據安全的前提下,節省后續數據利用成本。
其次,從模型輸入的角度來看,以“理論+數據”雙驅動的特征工程方式蒸餾數據,依據專家先驗知識,為數據的采集、清洗加入理論約束,在數據中融入教育教學理論知識,提取數據顯式特征,在計算源頭建立可解釋性基礎。其次,表示學習是機器自動學習數據中的隱式特征的過程,在表示學習中加入教育教學理論知識,一方面可降低數據維度,同時可與專家知識結合,調整模型學習策略,減輕認知負荷,增強結果的可解釋性。
(二)模型融生:從可解釋走向可信賴
可解釋性是在模型精準度與透明度之間權衡后的結果。當前,衡量一個好的算法模型的標準是結果的精確度與準確度,因此,開發者更關切模型是否達到SOTA(State of the Art)水平,缺少對可解釋性的關注。而在未來,教育領域對可解釋性的關注,會從目標導向的角度,影響到最初的算法模型設計與后續應用。
首先,可在教育情境當中,創新應用可解釋的“白盒”模型,讓模型參數或者數據特征的教育內涵更加外顯,從而可在計算過程中了解模型學習的過程,減輕可解釋的難度。例如,有學者在貝葉斯知識追蹤模型中融合布盧姆教育目標分類[47],通過衡量每個教育目標對其他教育目標的影響,提出解釋模型輸出的新方法。
其次,算法結果可溯源,走向可信賴的人工智能。在當前的教育情境中,使用者對機器決策結果不相信、難認同是在模型應用層面的困境。因此,可在模型設計階段設立溯源機制,例如,借用區塊鏈技術思想,建立分布式的算法賬本,不僅可保障結果的不可篡改性,也可以幫助人們有效追溯所有的機器決策步驟[48],將解釋邏輯自然地包含于算法流程中,從而在出現錯誤時明確人與機器的責任歸屬,讓使用者更好地明確算法流程的執行過程。
(三)人在回路:促進人機對話的混合智能
解釋過程離不開所要解釋的內容和方式,而理解在于被解釋者。從以“人”為本的角度來看,解釋的過程在與被解釋者的特點、所處環境、被解釋者的反饋等多元信息整合后,綜合達成可解釋的目標。
首先,解釋過程需要滿足人對于解釋信息的接受習慣。例如,人們所能接受的解釋是對比性的,Miller在綜合哲學、心理學和認知科學等領域的研究發現,事件A發生后,人們可能會問為什么是事件A而不是事件B發生;人們所接受的解釋是選擇性的,人們可能會關注諸多原因中的部分而非全部;以及人們在對話與社會交互的過程中接受解釋[49]。由此可見,面對復雜的“人”,如果缺少被解釋者自身特點的考量,教育中人工智能的可解釋性發展也會受到限制。
其次,設計以“人”為中心的解釋通道,形成人在回路(Human in the Loop)模式。機器善于從海量數據中學習知識,而人更善于在信息較少的情況下做出決策。因此,在從數據輸入、模型訓練、模型測試、模型部署的周期內,可設計并行的反饋通道,讓人參與到全過程中,形成機器與人頻繁交互的混合智能。通過人的引導,在交互節點之間,機器自動化構建決策結果,從而加速從模型訓練到模型部署的過程,增加任務過程透明度,走向可信賴、具有“負責感”的人工智能。
隨著人工智能技術逐步融入在教育情境的過程,可解釋性必將是教育人工智能未來不可回避的重要問題,也是一個重要的研究方向。本文在對教育中人工智能可解釋性的現實需求基礎上,站在教育的立場中,分析闡述了教育人工智能的可解釋性內涵,并從歷史演變的視角,從算法模型、解釋方式、數據、用戶接納四個關鍵要素總結了教育人工智能的已有工作,并分析了其局限性。最后,在回望歷史的基礎上,提出了教育人工智能可解釋性的未來發展方向。
參考文獻:
[1] Richer,M.H.,Clancey,W.J.GUIDON-WATCH:A Graphic Interface for Viewing A Knowledge-Based System [J].IEEE Computer Graphics and Applications,1987,5(11):51-64.
[2] Clancey,W.J,Letsinger,R.NEOMYCIN:Reconfiguring A Rule-Based Expert System for Application to Teaching [M].Stanford,CA:Stanford University,1982.
[3] 李子運.人工智能賦能教育的倫理思考[J].中國電化教育,2021,(11):39-45.
[4] 黃榮懷,王運武等.面向智能時代的教育變革——關于科技與教育雙向賦能的命題[J].中國電化教育,2021,(7):22-29.
[5] Pasquale,F.The Black Box Society [M].Cambridge:Harvard University Press,2015.
[6] Swartout,W.R.Explaining and Justifying Expert Consulting Programs [M].New York:Springer,1985.
[7] Scott,A.C.,Clancey,W.J.,et al.Explanation Capabilities of ProductionBased Consultation Systems [R].Fort Belvoir:STANFORD UNIV CA DEPT OF COMPUTER SCIENCE,1977.
[8] 國務院.國務院關于印發新一代人工智能發展規劃的通知[EB/OL]. http://www.gov.cn/zhengce/content/2017-07/20/content_5211996. htm,2021-07-20.
[9] Matt,T.Explainable Artificial Intelligence (XAI) [EB/OL].https://www. darpa.mil/program/explainable-artificial-intelligence,2021-07-20.
[10] Goodman,B.,Flaxman,S.European Union Regulations on Algorithmic DecisionMaking and A “Right to Explanation” [J].AI Magazine,2017,38(3):50-57.
[11] Hempel,C.G.,Oppenheim P.Studies in the Logic of Explanation [J]. Philosophy of Science,1948,15(2):135-175.
[12] Sober,E.Common Cause Explanation [J].Philosophy of Science,1984, 51(2):212-241.
[13][20] Salmon,W.C.Statistical Explanation and Statistical Relevance [M]. Pittsburgh:University of Pittsburgh Press,1971.
[14] Vasilyeva,N.,Wilkenfeld,D.A.,et al.Goals Affect the Perceived Quality of Explanations [A].Noelle,D.C.,et al.Proceedings of the 37th Annual Meeting of the Cognitive Science Society [C].Austin:Cognitive Science Society,2015.2469-2474.
[15] Gunning,D.,Aha,D.DARPA’s Explainable Artificial Intelligence (XAI) program [J].AI Magazine,2019,40(2):44-58.
[16] Stoica,I.,Song,D.,et al.A Berkeley View of Systems Challenges for AI [R].Berkeley:Electrical Engineering and Computer Sciences,UC Berkeley,2017.1-13.
[17] Bao,W.,Yue,J.,et al.A Deep Learning Framework for Financial Time Series Using Stacked Autoencoders and Long-Short Term Memory [EB/OL].https:// journals.plos.org/plosone/article/file id=10.1371/journal.pone.018094 4&type=printable,2017-07-14.
[18] Arrieta,A.B,Díaz-Rodríguez,N.,et al.Explainable Artificial Intellige nce(XAI):Concepts,Taxonomies,Opportunities and Challenges Toward Responsible AI [J].Information Fusion,2020,58:82-115.
[19] Been,K.Interpretability [EB/OL].https://www.youtube.com/ watch v=JkaF997hyB4,2021-07-20.
[21] Nicolosi,S.L.Sophie:An Expert System for the Selection of Hazard Evaluation Procedures [M].Boston:Springer,1988.
[22] Brown,J.S.,Burton,R.R.Diagnostic Models for Procedural Bugs in Basic Mathematical Skills [J].Cognitive Science,1978,2(2):155-192.
[23] Swartout,W.R.XPLAIN:A System for Creating and Explaining Expert Consulting Programs [J].Artificial Intelligence,1983,21(3):285-325.
[24] Van,M.W.MYCIN:A Knowledge-Based Consultation Program for Infectious Disease Diagnosis [J].International Journal of Man-Machine Studies,1978,10(3):313-322.
[25] Moore,J.D.,Swartout,W.R.Explanation in Expert Systems:A Survey [R].Fort Belvoir:UNIVERSITY OF SOUTHERN CALIFORNIA MARINA DEL REY INFORMATION SCIENCES INST,1988.1-55.
[26] Mueller,S.T.,Hoffman,R.R.,et al.Explanation in Human-AI Systems:A Literature Meta-Review,Synopsis of Key Ideas and Publications,and Bibliography for Explainable AI [R].Fort Belvoir:DARPA XAI Program,2019.49-60.
[27] Wick,M.R.,Thompson,W.B.Reconstructive Expert System Explanation [J].Artificial Intelligence,1992,54(1-2):33-70.
[28] Corbett,A.T.,Anderson J R.Knowledge Tracing:Modeling the Acquisition of Procedural Knowledge [J].User Modeling and User-Adapted Interaction,1994,4(4):253-278.
[29] Carbonell,J.R.AI in CAI:An Artificial-Intelligence Approach to Computer-Assisted Instruction [J].IEEE Transactions on ManMachine Systems,1970,11(4):190-202.
[30] McKendree,J.Effective Feedback Content for Tutoring Complex Skills [J]. Human-Computer Interaction,1990,5(4):381-413.
[31][32] Swartout,W.R.,Moore,J.D.Explanation in Second Generation Expert Systems [M].Berlin,Heidelberg:Springer,1993.
[33] Brézillon,P.Context in Problem Solving:A Survey [J].The Knowledge Engineering Review,1999,14(1):47-80.
[34] Lane,H.C.,D’Mello,S.K.Uses of Physiological Monitoring in Intelligent Learning Environments:A Review of Research,Evidence,and Technologies [A].Parsons,T.,et al.Brain and Technology.Educational Communications and Technology:Issues and Innovations [C]. Cham:Springer,2019.67-86.
[35] Beardsley,M.,Hernández‐Leo,D.,et al.Seeking Reproducibility:Assessing A Multimodal Study of the Testing Effect [J].Journal of Computer Assisted Learning,2018,34(4):378-386.
[36] Pavlik,Jr.P.I.,Cen,H.,et al.Performance Factors Analysis—A New Alternative to Knowledge Tracing [A].Darina,D.,et al.Proceedings of the 14th International Conference on Artificial Intelligence in Education [C].Berlin,Heidelberg:Springer-Verlag,2009.531-538.
[37] Lu,Y.,Wang,D.,et al.Towards Interpretable Deep Learning Models for Knowledge Tracing [A].Bittencourt I.,et al.Proceedings of the 21st International Conference on Artificial Intelligence in Education [C]. Cham:Springer.2020.185-190.
[38] Nakagawa,H.,Iwasawa,Y.,et al.Graph-Based Knowledge Tracing: Modeling Student Proficiency Using Graph Neural Network [A]. Payam,B.,et al.Proceedings of WI ‘19:IEEE/WIC/ACM International Conference on Web Intelligence [C].New York:Association for Computing Machinery,2019.156-163.
[39] Ghosh,A.,Heffernan,N.,et al.Context-Aware Attentive Knowledge Tracing [A].Rajesh,G.,et al.Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining [C]. New York:Association for Computing Machinery,2020.2330-2339.
[40] Pandey,S.,Srivastava,J.RKT:Relation-Aware Self-Attention for Knowledge Tracing [A].Mathieu,D.,et al.Proceedings of the 29th ACM International Conference on Information & Knowledge Management [C]. New York:Association for Computing Machinery,2020.1205-1214.
[41] Liu,M.,Shi,J.,et al.Towards Better Analysis of Deep Convolutional Neural Networks [J].IEEE Transactions on Visualization and Computer Graphics,2016,23(1):91-100.
[42] Ribeiro,M.T.,Singh,S.,et al.”Why Should I Trust You ” Explaining the Predictions of Any Classifier [A].Balaji,K.,et al.Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining [C].New York:Association for Computing Machinery,2016.1135-1144.
[43] Zhu,J.,Liapis,A.,et al.Explainable AI for Designers: A HumanCentered Perspective on Mixed-Initiative Co-Creation [A]. Cameron,B.,et al.Proceedings of the 2018 IEEE Conference on Computational Intelligence and Games (CIG) [C].Maastricht:IEEE,2018.1-8.
[44] Bauer,M.,Baldes,S.An Ontology-Based Interface for Machine Learning [A].Rob,St.A.Proceedings of the 10th International Conference on Intelligent User Interfaces [C].New York:Association for Computing Machinery,2005.314-316.
[45] Wang,D.,Yang,Q.,et al.Designing Theory-Driven User-Centric Explainable AI [A].Stephen B.,et al.Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems [C].New York:Association for Computing Machinery,2019.1-15.
[46] 黃閃閃,林田.歐洲通用數據保護條例(GDPR)視角下深度學習算法的理據性問題芻議[J].系統科學學報,2021,29(1):31-34+66.
[47] Miller,T.Explanation in Artificial Intelligence:Insights from the Social Sciences [J].Artificial Intelligence,2019,267:1-38.
[48] Shruthi,C.,Daniel,M.G.et al.Directions for Explainable KnowledgeEnabled Systems [A].Ilaria,T.et al.Knowledge Graphs for eXplainable AI—Foundations,Applications and Challenges.Studies on the Semantic Web [C].Amsterdam:IOS Press,2020.245-261.
[49] Lalwani,A.,Agrawal,S.Validating Revised Bloom’S Taxonomy Using Deep Knowledge Tracing [A].Penstein,R.C.,et al.Proceedings of the 19th International Conference on Artificial Intelligence in Education [C]. Cham:Springer,2018.225-238.
作者簡介:
劉桐:在讀博士,研究方向為學習分析、教育數據挖掘。
顧小清:教授,博士,博士生導師,研究方向為學習科學與技術設計、學習分析與學習設計、智能教育。
Opening the “Black Box”: Exploring the Interpretability of Artificial Intelligence in Education
Liu Tong, Gu Xiaoqing(Department of Education Information and Technology, East China Normal University, Shanghai 200062)
Abstract: Education is an important application field of artificial intelligence. Exploring the interpretability of Artificial Intelligence in education is an important issue that makes artificial intelligence more “responsible” in the field of education. This article starts from the practical problems of artificial intelligence application in education, and focuses on three questions about what is the interpretability of artificial intelligence in education, what has been done, and the future direction. First, the four key elements of data, tasks, models, and people are used as the starting point to analyze and explain the explainable connotation of Artificial Intelligence in education; The work has limitations in terms of the injection of educational meaning, the complexity of models, and the transmission of one-way interpretation information; Finally, the future development of artificial intelligence interpretability in education is explained from the three perspectives of knowledge federation, model integration, and human-in-the-loop.
Keywords: educational Artificial Intelligence; interpretability; “black box” model; human in the loop
責任編輯:李雅瑄
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
