煙草市場規模估計的分層抽樣策略研究
2022-06-07 06:01:05劉佳
中國市場 2022年14期


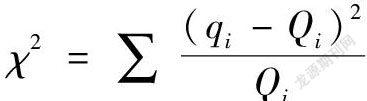


摘 要:當前,數據化經營成為生產力發展的重要方向,但以線下運營為主體的煙草行業,其數據采集能力仍有待進一步提高。隨著行業市場分析的緊迫性日益加劇,煙草行業需要找到一條兼顧數據采集工作量與分析結果準確性的數據化市場規模評估機制。文章從門店抽樣出發,在樣本設計、樣本檢驗、還原算法等層面進行了深入研究,提出了完整的市場評估方案并采用真實數據通過了方案測試,為今后煙草行業的市場規模研究提供了行之有效的解決辦法。
關鍵詞:分層抽樣;還原算法;市場評估
中圖分類號:F416.8文獻標識碼:A文章編號:1005-6432(2022)14-0184-07
DOI:10.13939/j.cnki.zgsc.2022.14.184
近年來,隨著全行業推進供給側結構性改革、加強市場監管和內部管理、完善專賣體制等政策,我國煙草行業整體保持良好穩定發展[1]。但在不同地區由于市場特點各不相同,其市場表現、發展模式、管理形式也不可避免的有所差異。因此,精準的地區市場狀態的反映及評估,是進一步深化地市級煙草公司發展的有力武器。
市場狀態評估主要受兩個維度的影響:市場數據采集與還原算法。一個市場的狀態是否良好,需要通過市場狀態指標對投放效果進行回顧分析,從而予以判斷。當前,卷煙市場狀態指標主要包括條毛利率、社會庫存與周存銷比。筆者以西安市為例,由于門店機器采集普及率較低,大部分門店仍為人工采集,又由于人工采集受環境、人為因素的影響較大,人工操作的不確定性使得市場狀態計算科學性存在一定的提升空間。
同時,在還原算法層面,現行方法也存在一些問題。當前還原算法根據樣本門店的存銷比對社會庫存進行推估,這樣并沒有很好地考量樣本可能包含的多維度特征,致使市場狀態計算存在一定誤差。
因此,本文從細化市場數據采集、改進還原算法的角度出發,以西安市為例對目前煙草行業市場狀態評估所采用的抽樣策略系統進行了細致探討與優化設計,旨在為后續市場狀態分析打好基礎,用更有效的“系統大數據”幫助業務人員掌握更準確的“市場活情況”。
1 抽樣方案設計
1.1 方案重點概述
當下,中國數據產業蓬勃發展,各行業紛紛擁抱數據化所帶來的精細化管理、預判、執行等業務賦能。但目前國內商業數據采集尚未成熟,部分行業仍然極大地依賴人工采集,從而在數據精確度與可用性方面存在不足。面對煙草行業線下運營數據采集能力的不充分發展與行業市場分析的緊迫性之間的矛盾,探索出適合當下市場發展條件的數據修正一體化方案,對于煙草市場規模評估具有很強的實用與輔助指導意義。
為此,首先,根據煙草市場規模評估所需數據的處理過程,制定了“修正市場狀態數據源+升級抽樣還原算法”的兩步走方案。筆者規范了樣本門店選取規則,同時重新設計門店抽樣方案:①設計分層抽樣算法,確保可抽樣性的同時提高抽樣效率;②采用非等比例抽樣,分配中心城區和非中心城區樣本數;③生成檔位合集,提升抽樣代表性;④利用卡方檢驗,保證樣本能夠合理反映市場情況;⑤分布指數檢驗,檢查樣本門店地理分布的可操作性。
其次,在完成數據修正后,根據抽樣方案對還原算法進行相應調整:①細化還原計算層級;②設計科學推總還原算法。筆者根據上述策略方案在西安市進行了可行性驗證,其誤差率與可操作性均達到并超過預期水平。
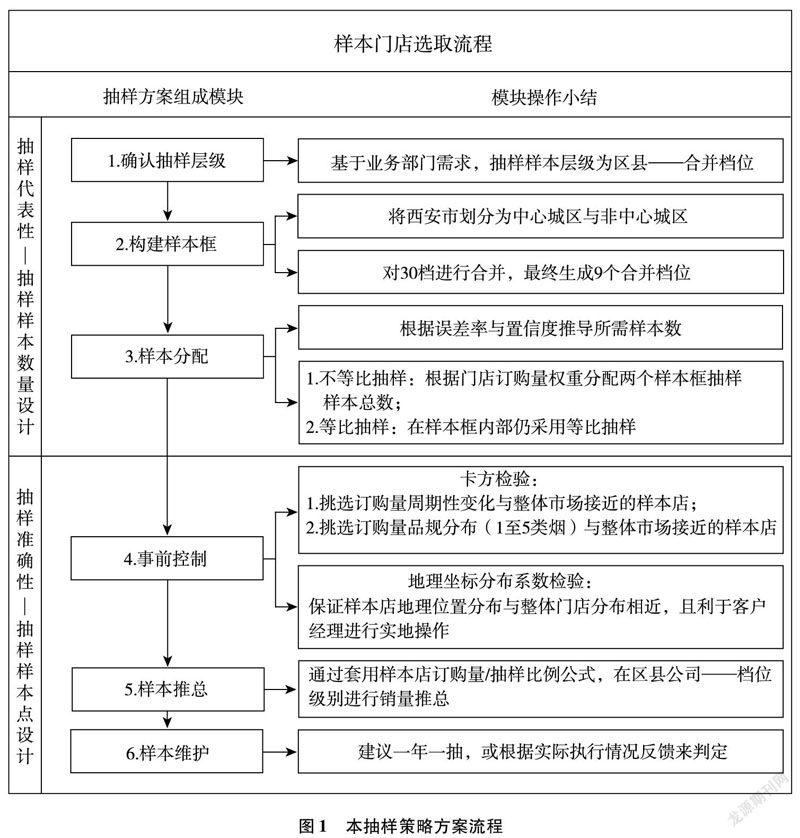
1.2 方案流程設計
本方案從門店抽樣的代表性與準確性出發,針對目前抽樣中遇到的問題,諸如權重分配過于單一、樣本框劃分只依賴地區因素等,重點對樣本數量與樣本點進行設計與優化[2],從而在低成本的前提下實現了提高評估精度、改善評估描述力、增強抽樣系統可維護性等目標。方案流程如圖1所示。
1.3 方案測試范圍
筆者選取了西安市數據進行抽樣策略測試:①全量門店訂購數據:2020年8月1日至9月6日;②全量門店靜態標簽數據(行政區、地址、門店編號、門店經緯度、門店檔位),門店檔位更新時間為2020年8月28日;③商品數據字典(卷煙代碼,卷煙名稱,品牌等)。
2 方案詳述與結果
2.1 確認抽樣層級并構建樣本框
2.1.1 城區劃分
西安市行政區劃可分為中心城區和非中心城區:
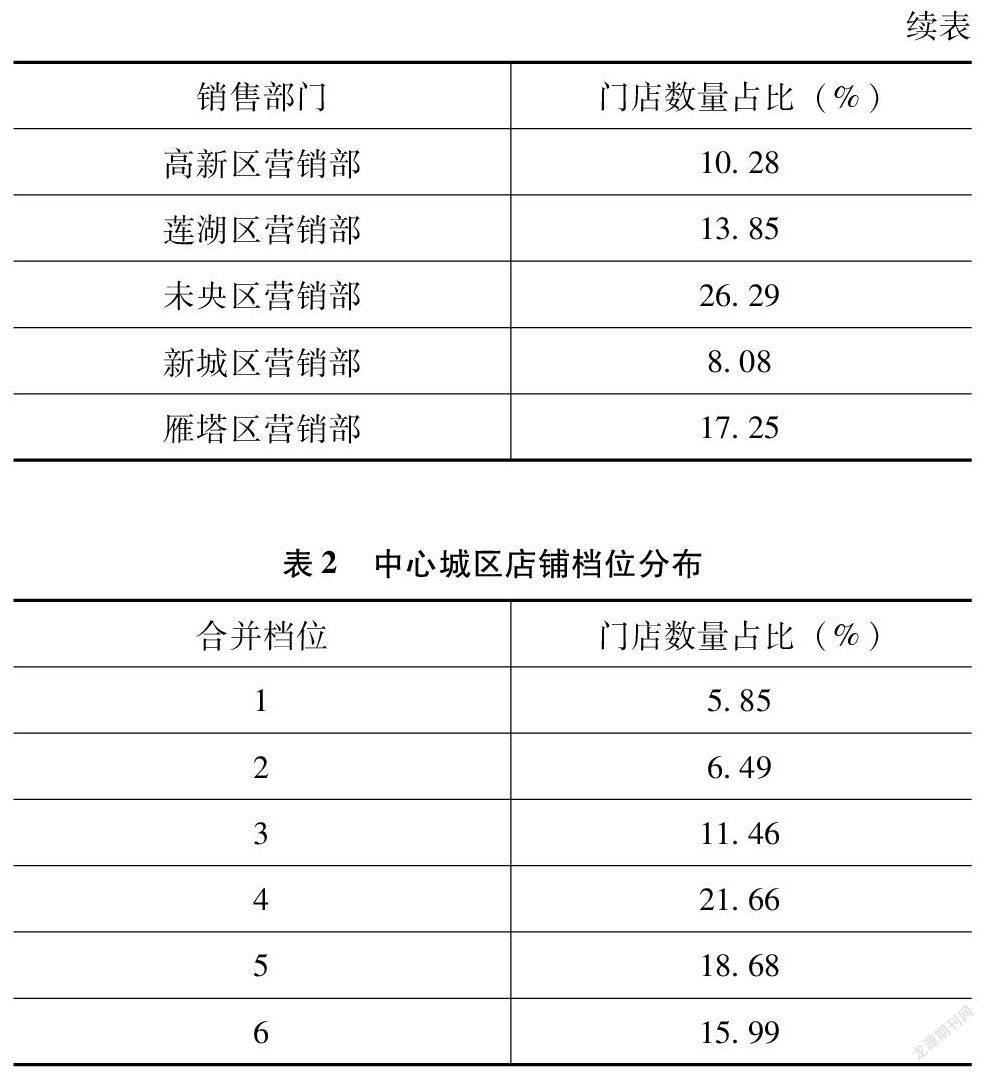
中心城區:未央區、新城區、碑林區、蓮湖區、灞橋區、雁塔區、高新區。
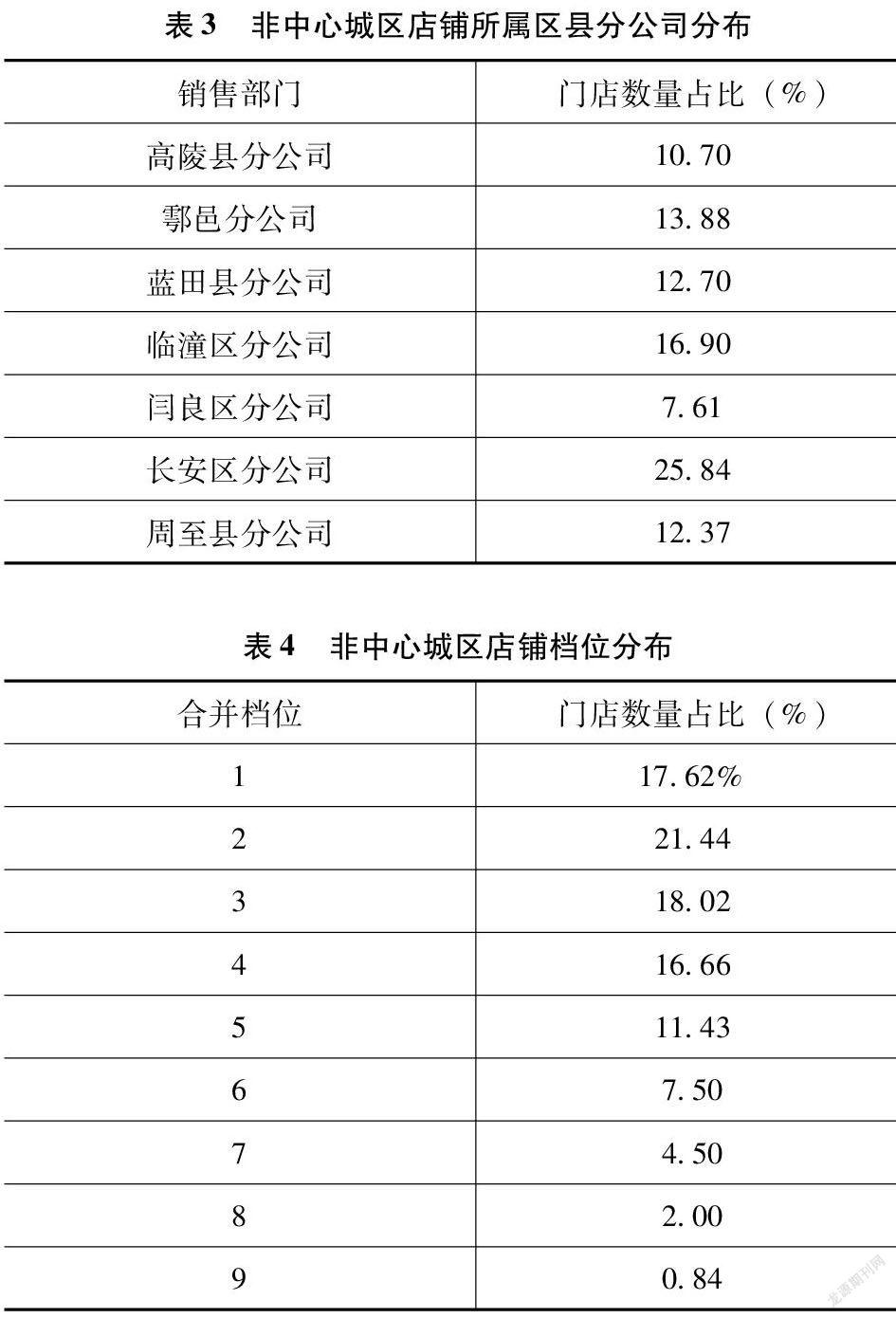
非中心城區:閻良區、臨潼區、長安區、高陵區、鄠邑區、藍田縣、周至縣。
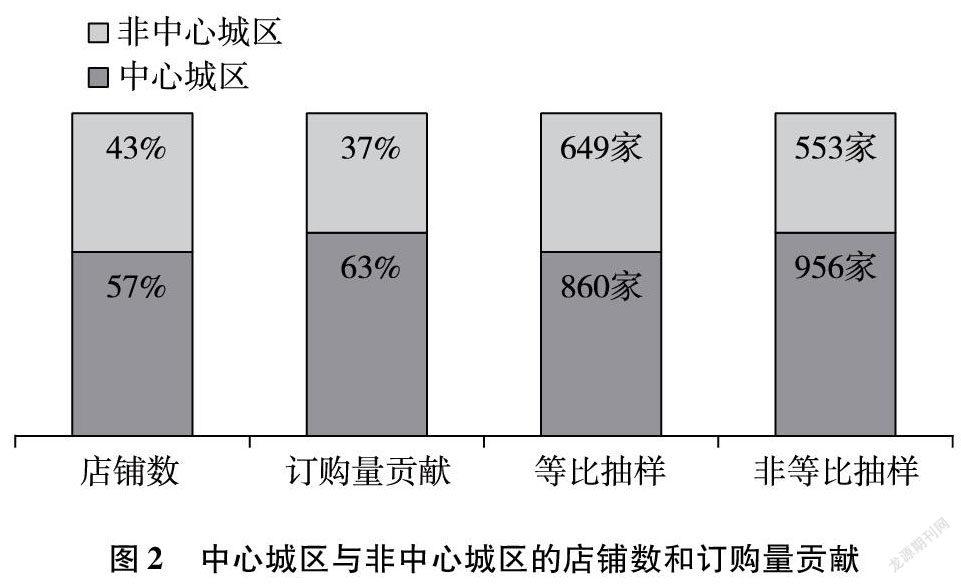
為了精準分析市場行情,抽樣店鋪需要充分考慮市場需求分布。傳統抽樣方法多采用簡單直接的等比方式,即依照中心/非中心城區店鋪總數比例分配抽樣店鋪,忽略了不同城區的商業發展狀態。因此選擇了考慮訂購量貢獻的非等比抽樣[3]。圖2對比了傳統等比抽樣和非等比抽樣的抽樣比例差異。
2.1.2 檔位合并
除了地區屬性外,門店同時還具有檔位屬性。傳統抽樣方法會直接對每一檔進行抽樣,導致分類過多,不利于后續分析。因此,需要在抽樣前對檔位進行優化合并處理。
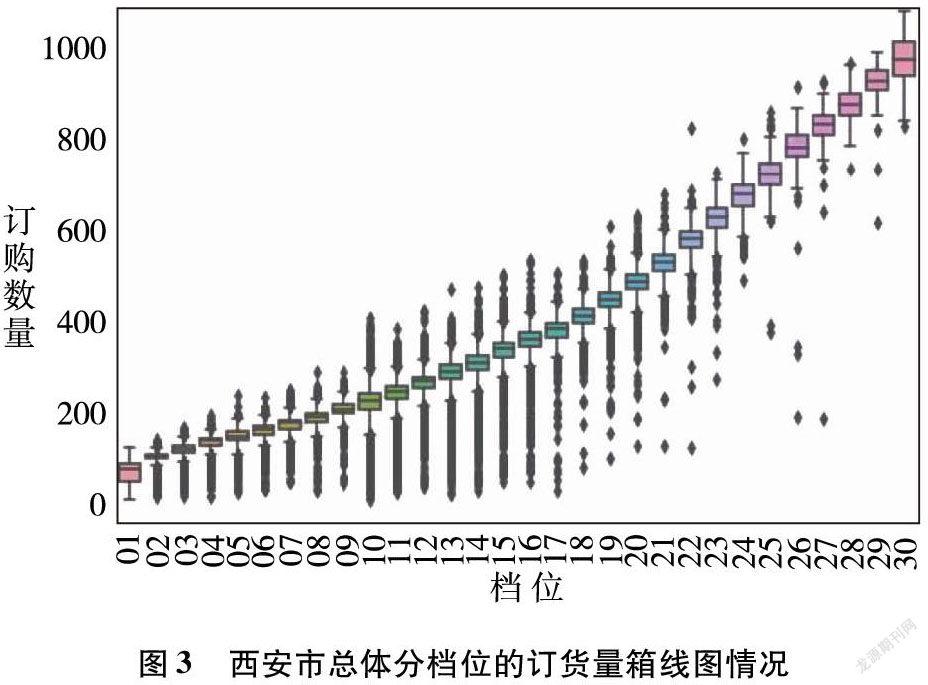
由圖3可以看出,全市總體訂購數量和檔位數呈正相關,并隨檔位數遞增。曲線平滑說明臨近檔位的訂貨量相近。因各區縣內趨勢和西安市整體趨勢一致,故后續變異系數只針對全市計算。
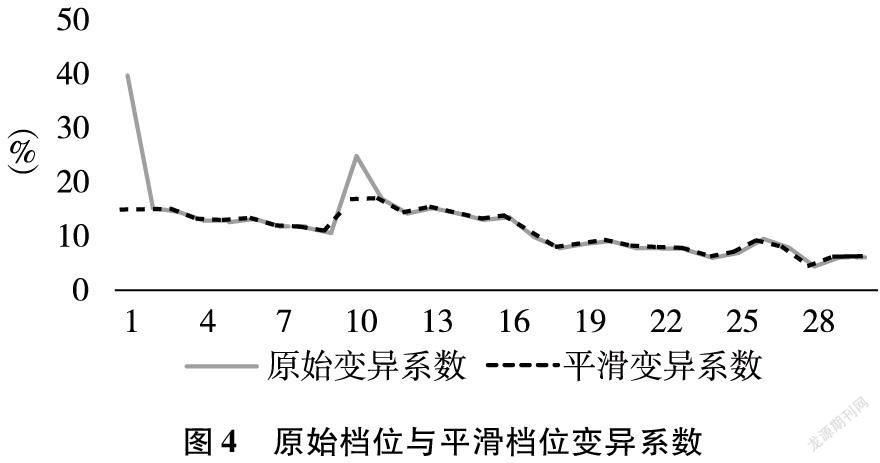
各檔位的原始變異系數(變異系數 = 標準差/均值)如圖4所示。變異系數能夠量化檔位零售店訂購量的離散程度,可看到檔位1和檔位10訂購量離散程度大。但檔位1是訂購表現差的門店集合,檔位10則為新入市門店集合。 由于后續會對抽樣門店進行事前控制篩選,且僅抽取開店6個月以上的門店,因此可忽略這兩個檔位的異常分布。
后對異常分布進行平滑處理,即用檔位2、11的變異系數分別替換檔位1、10,如圖4虛線所示。
合并檔位時,檔位集合總數和集合中的檔位數量會顯著影響數據采集工作量與后續分析。筆者在測試后選擇了“三檔合一”為主的方案,即按照1-3,4-6,7-9,10-12,13-15,16-18,19-21,22-24,25-30合并檔位。一方面可以契合圖4平滑變異系數呈現的階梯分布;另一方面平衡了抽樣精確性與總人工工作量。
2.1.3 抽樣框設置
第一,抽樣框1:中心城區。表1、表2為分區域和檔位的門店計數占比。
第二,抽樣框2:非中心城區。表3、表4為分區域和檔位的門店計數占比。
2.2 抽樣樣本數及誤差估算
計算需抽取的樣本量n0:
其中,d為抽樣絕對誤差,本方案取值2%;α為顯著性水平,通常可以取α=0.05,此時置信度1-α=0.95;uα為標準正態分布在置信度為1-α時的分位數,在置信度為0.95時為1.96;p(0<p<1)是樣本成數,一般在未知時,p通常取0.5,即p(1-p)可取0.25。按上述取值,可得n0=1536。
關于抽樣設計的效率,可通過設計效應 (deff) 來確定[4]。對于本方案,分層設計效應可表示為:
當抽樣方式為按比例的分層抽樣時,nin=Wi , 分層設計效應為:
其中ρiccst=σ2bσ2是層間變差在總變差中所占的比重。可見本抽樣的設計效應小于1,說明設計效率高于不放回的簡單隨機抽樣。
綜上,本抽樣方案總樣本需求個數在1500左右,符合西安煙草發展1500戶樣本的需求,故設定為1500;同時抽樣誤差控制在2%,顯著低于省級文件要求的3%。
2.3 樣本分配
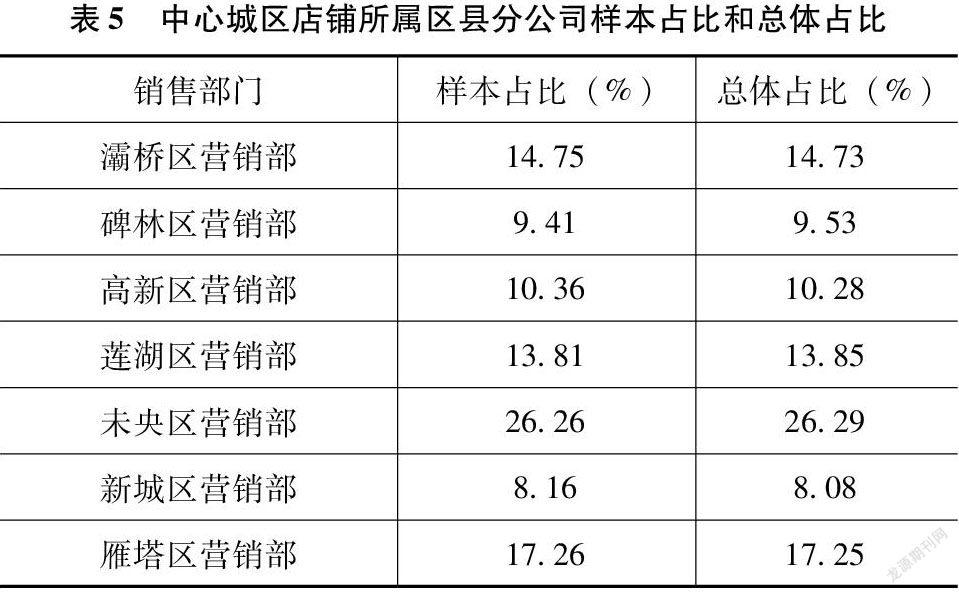
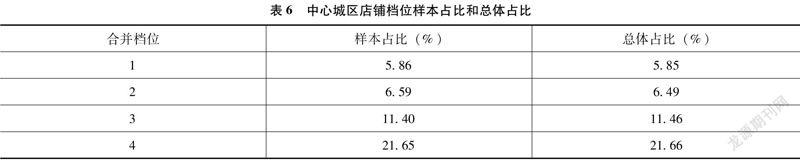
確定樣本總量后,筆者將樣本等比例分配至各樣本框。抽樣框1(中心城區)需要抽出956個樣本。
從銷售部門來看,見表5。
從檔位來看,見表6。
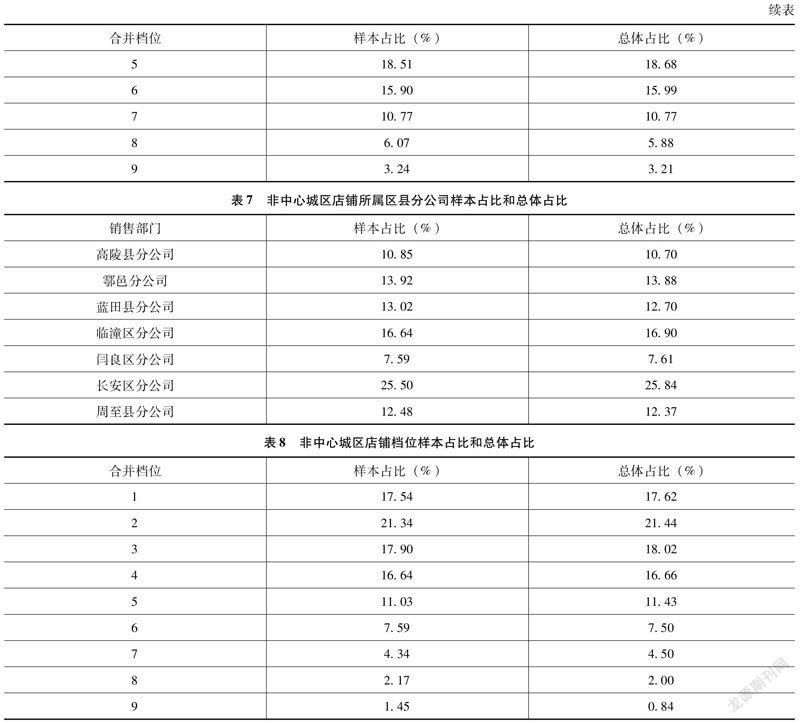
抽樣框2(非中心城區)需要抽出553個樣本。從銷售部門的分布來看,見表7。
從檔位的分布來看,見表8。
2.4 事前控制
事前控制的目的是在選點前進行數據測算,確保所選樣本點的個體對整體市場具有代表性及可操作性。
2.4.1 卡方檢驗
卡方檢驗是非參數檢驗的一種,可以統計樣本的實際觀測值和理論推斷值之間的偏離程度,如果卡方值越大,則兩者的偏差程度越大,反之則越小。卡方檢驗可以幫助選出與總體差異最小的樣本,常用于分層抽樣結果的檢驗[5]。
首先提出檢驗的原假設和備選假設:
原假設:該客戶與該區域總體客戶訂購量,在半年與價類的分布保持一致。
備選假設:該客戶與該區域總體客戶訂購量,在半年與價類的分布保持不一致。
卡方值表達式為:
其中,q代表的是每個客戶的訂購量的歸一化值,Q代表的是每個區域×合并檔位的總銷售情況的歸一化值,卡方值度量了每個客戶的銷售情況與其所在區域×合并檔位的訂購量差異大小。
χ20.95是常用的95%置信區間的卡方分布臨界值,當計算出來的卡方值小于χ20.95(k-1),則在統計學意義上可以接受原假設。在本方案中,自由度k指代訂購的煙類計數。
以未央區2檔位為例,其每個店鋪一共只有1-3類煙,自由度為2,卡方臨界值為0.102587。未央區2檔位應抽取12個樣本,挑選卡方最低的前12個非新店鋪,其卡方值都小于臨界值,即證明試抽的樣本店與區域×檔位總體的訂購量分布是一致的。
2.4.2 樣本位置分布指數檢驗
為了保證抽取的樣本店鋪在地理位置上分布合理,利于客戶經理進行實地操作,還需要進行經緯度分布的檢驗。
筆者通過觀察店鋪經緯度散點圖來直觀判斷,但為了定量判斷位置分布的一致性,仍需要繼續計算樣本分布指數。這里引入矩量母函數(mgf)的概念。mgf值對分布有唯一代表性,當mgf值相等時,這兩個分布也相等。通過這個原理,就可以簡單的利用二階矩來進行檢驗[6]。
定義一個隨機變量X的二階距中心距為:
可以看到,二階距就是X的方差。只需要比較抽樣的樣本和總體的經緯度的方差-協方差矩陣,即可判斷兩者的位置分布是否大致相近。
某區域經度方差=∑i(經度i-某區域經度的均值)2某區域店鋪的個數-1
某區域緯度方差=∑i(緯度i-某區域緯度的均值)2某區域店鋪的個數-1
某區域經緯度協方差=∑i(經度i-某區域經度的均值)(緯度i-某區域緯度的均值)某區域店鋪的個數-1
由此,繼續計算樣本分布指數:
總體與樣本的經度誤差=總體經度方差-樣本經度方差總體經度方差
總體與樣本的緯度誤差=總體緯度方差-樣本緯度方差總體緯度方差
總體與樣本的經緯度協方差誤差=總體經緯度協方差-樣本經緯度協方差總體經緯度協方差
樣本分布指數=總體與樣本的經度誤差+總體與樣本的緯度誤差+總體與樣本的經緯度協方差誤差3
最終,筆者得到了每個區域的經緯度坐標的方差-協方差矩陣和樣本分布指數,并發現其均小于100%。再結合每個區域的店鋪散點圖,可認為抽取的樣本店鋪位置分布大致符合原本店鋪的位置分布情況。
2.5 樣本推總
2.5.1 推總方法
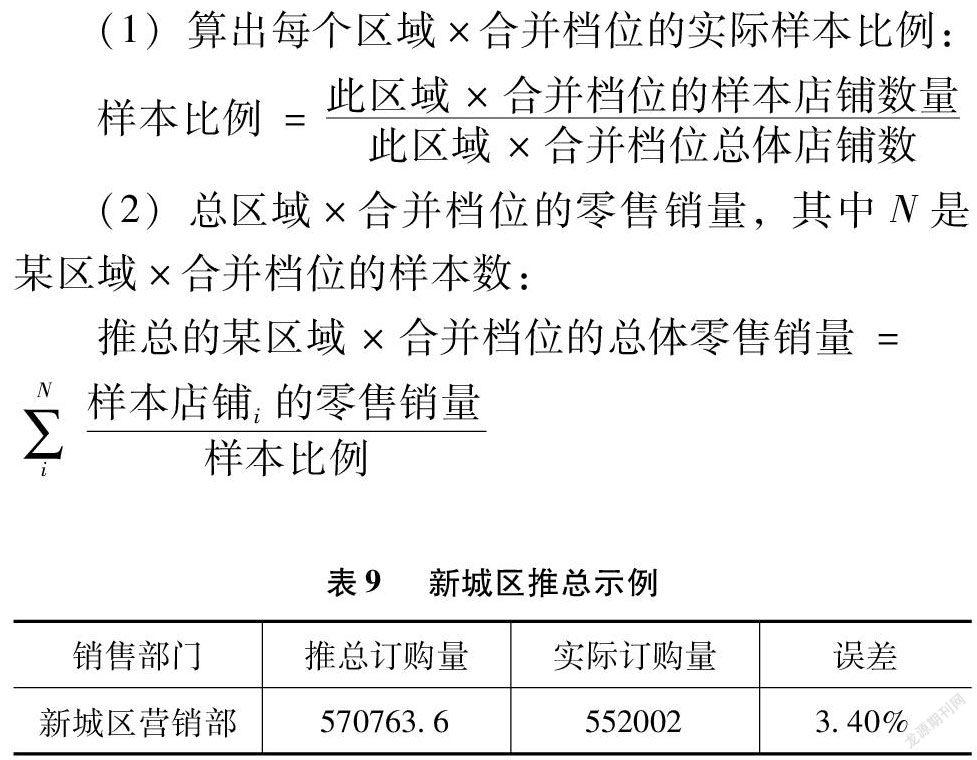
采用分層抽樣后,整體零售店鋪可以按區縣分公司×合并檔位這兩個維度進行劃分。每一個區縣分公司×合并檔位,通常將其定義為一個MBD,其中包含的若干店鋪的總訂購量推總可由其中的樣本訂購量除以樣本比例得到。
在表9中,實際訂購量是新城區所有店鋪的總訂購量,誤差=(推總訂購量-實際訂購量)/實際訂購量。在誤差較低時,可認為抽取的樣本店與總體訂購量情況一致。所得推總步驟如下。
(1)算出每個區域×合并檔位的實際樣本比例:
樣本比例=此區域×合并檔位的樣本店鋪數量此區域×合并檔位總體店鋪數
(2)總區域×合并檔位的零售銷量,其中N是某區域×合并檔位的樣本數:
推總的某區域×合并檔位的總體零售銷量=∑Ni樣本店鋪i的零售銷量樣本比例
(3)推總某區域的零售銷量,其中n是某區域內合并檔位的個數:
推總的某區域零售銷量=∑ni某區域×合并檔位i的零售銷量
(4)推總西安市總體店鋪的零售銷量:
推總的西安市零售銷量=∑14i區域i的零售銷量
2.5.2 最細統計顆粒度
由于受到樣本個數的限制,并非每一個MBD推總時都擁有足夠的樣本點。當MBD中樣本個數較低時,該MBD的推估結果將不具有統計意義。在當前樣本量級的基礎上可以接受的最細顆粒度為:區縣分公司×合并檔位。
2.6 樣本更新和退出邏輯
從數據來源穩定性出發,樣本來源最好保持穩定,但由于卷煙銷售是一個動態過程,為了獲取市場的最新情況,建議樣本一年刷新一次,或根據實際執行情況反饋判定。
在一年之中,如果抽中的樣本店鋪經營異常,如關店、不配合數據采集,應該查詢本年度制定抽樣方案時,該店鋪所在的區域×合并檔位的未抽中店鋪,按照卡方值從小到大的原則,選擇卡方值最小的1個店鋪作為替代樣本。
3 結論
高質量的數據是高質量分析的保證,在了解西安煙草當前樣本門店選取和省級信息采集示范方案后,制定了當前的分層抽樣方案,在可操作的前提下,有效提升了樣本選擇的代表性、覆蓋面和準確性。該方案緊扣西安煙草當前數據執行現狀,通過應用分層抽樣算法,控制門店抽樣誤差率在2%,相比省級文件要求的3%誤差率,提升了門店抽樣準確率。另外通過對樣本進行訂購量結構、地理坐標位置驗證,確保樣本代表性及可操作性。
考慮到西安煙草目前使用樣本門店銷售數據進行市場銷售狀況還原,科學樣本點選取可以提升市場還原精度,最大程度地復現市場卷煙營銷現狀,服務后續市場營銷指標分析。
參考文獻:
[1]王煒.精益管理理念在煙草專賣市場監管的應用研究[J].現代商貿工業,2019,40(29):118-119.
[2]方文玉. 抽樣技術在煙草需求量調查中的應用[J].市場統計與信息, 2000(8):12-14.
[3]劉愛芹, 吳玉香. 分層抽樣中樣本量的分配方法研究[J].山東財政學院學報, 2007(4):49-53.
[4]L.基什.抽樣調查[M].倪加勛,譯.北京:中國統計出版社,1997.
[5]陳子玥,譚銀亮,石芳慧,等. 上海市大學生電子煙和卷煙的使用現狀及其影響因素[J].環境與職業醫學,2020(8).
[6]劉文. 隨機條件概率的一個極限性質與條件矩母函數方法[J].應用數學學報,2000, 23(2):275-279.
[作者簡介]劉佳,女,漢族,陜西西安人,碩士研究生,工程師,現就職于陜西省煙草公司西安市公司信息中心,研究方向:通信與信息系統、網絡安全與信息化。
