基于支持向量機的區域物流需求預測研究
2022-06-10 02:24:32于凱麗
中國經貿導刊 2022年5期
于凱麗
為了提高區域物流需求預測的精確度,本文利用蟻群優化訓練參數的支持向量機算法(SVM),得到優化后的支持向量機預測模型對區域物流需求進行預測。以青島市物流需求預測為例,實驗結果表明,蟻群優化的支持向量機模型預測結果精度更高、穩定性更強、誤差率更小,為青島物流需求預測提供了保障。
區域物流需求預測有利于現代物流體系的優化和改進,實現降低成本、提高物流效率的目標。新形勢下,科學預測區域物流需求,對提高經濟競爭力,促進可持續發展具有重要的指導意義,是合理制定物流發展政策、完善物流基礎設施建設和物流服務體系建設的重要依據。因此,準確預測區域物流需求顯得尤為重要,其準確性將決定區域物流規劃是否合理。及時掌握有效物流需求發展趨勢的信息,有利于城市現代物流體系的優化和改進,實現降低成本、提高物流效率的目標,對提高城市經濟競爭力,促進可持續發展具有重要的指導意義。
一、物流需求指標選擇
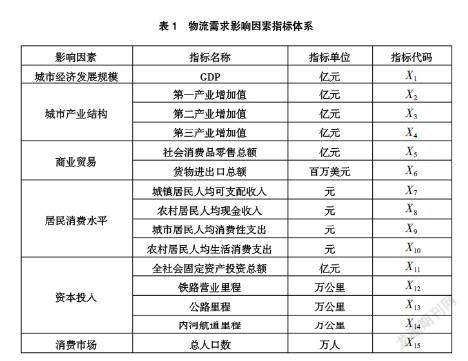
區域物流需求預測指標的準確選擇是預測成功實施的關鍵。為了保證物流需求的預測結果更接近實際結果,本文分析了影響區域物流需求復雜多樣的因素。本文在查閱相關文獻和實際情況的基礎上,分別從經濟影響和非經濟影響兩個角度分析了區域物流需求的影響因素。
經濟影響因素:
1、經濟發展的規模。“十四五”以來,隨著城市經濟的發展,物流需求增速加快,城市經濟的發展速度與物流業的發展密切相關。
2、工業結構。產業結構調整將對物流需求規模和結構產生重大影響。城市通常與當地具有相同的工業結構。要穩定城市產業,城市必須確保服務業能夠實現穩定、積極、長期的發展。
3、商業貿易。商業貿易對城市的物流需求有重大影響,商業貿易的發展也需要高標準的城市物流支持。
4、當地居民的消費水平。隨著城市化的發展,隨著當地人民消費和購買力的增加,電子商務分銷服務取得了進展。
5、資本投資。資金投入在很大程度上影響物流需求,需要優化資源配置和政策指導,優化資本投資環境,提高物流服務水平。
6、消費者市場。消費者市場的大小受到人口密度的限制。在人口密度高的地區,商業流通的增加導致了物流活動的發生。
由于非經濟因素、宏觀經濟政策和外部環境等影響物流需求的因素,短期內對物流需求的影響較小,因此,本文僅重點關注經濟指標與物流需求之間的關系,并利用貨運量來衡量區域物流需求的規模,構建表1所示的影響因素指標體系。
二、區域物流需求預測模型構建
(一)目標函數的建立
支持向量機(SVM)是一種基于統計學習理論,利用結構風險最小化的原則,避免局部最小值,有效地解決過度學習問題。它可以獲得有意義的法律信息,保證人們獲得泛化能力,并具有較好的預測準確度。
假設在給定的K個樣本數據集中,{(xi,yi),i= 1,2,…,n},n表示樣本數目,根據支持向量機原理,為每個樣本點引入一個松弛變量來標記。
對于凸二次優化問題,通過引入拉格朗日乘子,將目標函數和約束條件集成到拉格朗日函數中,方便求解為每個不等式約束引入拉格朗日乘子a的最大或最小值,得到拉格朗日函數。
(二)參數優化
初始化確定蟻群算法的基本參數,蟻群為m個,每個螞蟻k定義了一個具有n個元素的一維數組路徑。k個螞蟻通過的n個節點的坐標按順序存儲在路徑中,可用于表示k個螞蟻的爬行路徑,其中n是優化參數的總有效位。螞蟻k在t時刻在路徑(i,j)上節點i的信息素濃度為τij(t),得到從城市i選擇城市j這條路線的概率轉換規則。
每只螞蟻t在時刻選擇下一個城市,并在t+1時刻到達那里。得到路徑(i,j)的信息素更新規則。當完成最大迭代次數后,取所有螞蟻所走路徑中的最短路徑作為最終路徑來進行優化。
(三)預測模型的構建步驟
本文選用Libsvm-3.22工具箱,應用Matlab軟件進行了預測和分析。Libsvm-3.22工具箱是一個用于支持向量機預測模型的訓練、學習、數據分析和參數優化的多功能軟件包,該工具箱簡單、實用、快速、有效。
步驟1:根據給出的指標體系重建數據,對原始數據進行歸一化。
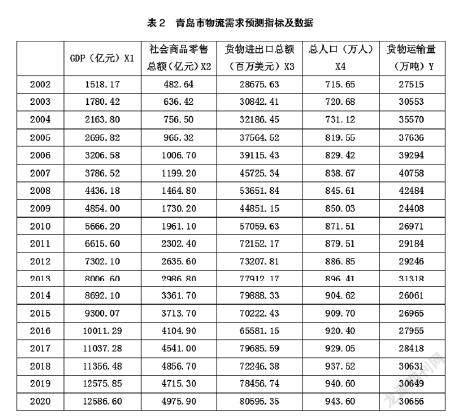
步驟2:數據集分為訓練數據和測試數據,訓練數據集用于建模,測試數據集用于驗證開發的模型。本文中2002年至2017年青島市的各數據作為訓練集,2018年至2020年青島市的各數據作為測試集。
步驟3:優化參數和訓練模型。使用ACO算法確定SVM中的懲罰系數和內核寬度的RBF作為核函數。訓練SVM模型,如果不滿足停止條件,新參數將用于重建ACO-SVM模型。計算適合度值,直到滿足停止條件。
步驟4:模型預測。訓練后,使用最優參數組合建立預測模型。將測試樣本輸入到建立的模型以獲得預測值。
步驟5:將預測數據重新歸一化以獲得實際的物流需求預測數據。
三、實證研究
(一)預測模型的MATLAB實現
本文對青島市物流需求現狀及特點進行了總結,從經濟總量、社會居民消費情況、當地居民的總人數和對外貿易情況等幾個方面構建了一個適合于本文的預測指標體系,選取貨物貨運量指標來量度青島市物流需求規模,如表2所示。
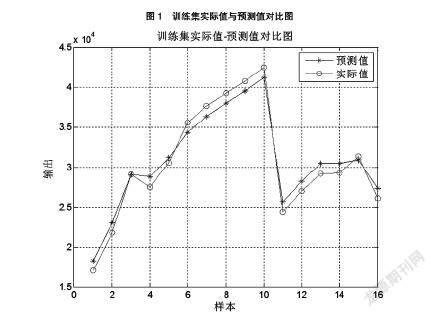
由于各指標數量級和單位不同,本文將樣本數據縮至[-1,1]之間,對統計數據進行規范化處理。設置模型參數c,g范圍為[0.1,1000],交叉驗證t為6,對模型訓練的最終結果如圖1所示。
從運行過程可以得出,參數C=271.8591,g=3.5748,擬合優度R2=0.9747,R2值越接近1,說明模型的實際值與觀測值的擬合程度越好,平均百分比誤差為MAPE=0.0343,模型參數經過訓練優化,預測結果比較準確。可以看出,該預測模型表現出良好的預測效果。
科學的區域物流需求預測為現代物流系統規劃提供發展依據,為區域宏觀產業經濟政策提供理論基礎。如果需求沒有得到充分的估計,物流企業將失去很多盈利機會。準確預測區域物流需求是物流規劃的重要依據,是區域物流綜合規劃的前提和基礎。
〔本文系青島濱海學院人文社會科學研究項目(項目編號:2021RY05)研究成果〕
(作者單位:青島濱海學院商學院)
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
物流技術與應用(2019年8期)2019-09-04 03:29:56
汽車觀察(2018年12期)2018-12-26 01:05:44
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
現代企業(2015年2期)2015-02-28 18:45:09
