基于相似樣本特征提取的裝備性能退化研究
2022-06-25 13:04:28張東東艾小川
系統工程與電子技術 2022年7期
關鍵詞:特征
張東東, 艾小川,*, 劉 暢
(1. 海軍工程大學基礎部, 湖北 武漢 430033; 2. 海軍工程大學管理工程與裝備經濟系, 湖北 武漢 430033)
0 引 言
高新技術的發展引領著裝備向高密封性、高安全性方向發展,工廠生產中,各類功能不同、質量不同的裝備構成一個完整的裝備生產系統。現階段,對于裝備系統中的各類裝備的生產狀態的判斷是由在線監控預警系統完成的。監控設備定時采集各個子裝備的實時性能參數,在線預警系統根據實時數據和歷史樣本數據及時對短時間內裝備的性能情況做出預測,判斷裝備短時間內是否會出現故障風險,從而實現預維護的目的。
工程實際上,實時狀態數據所包含的信息冗雜且多噪聲,為了增加預測的準確性,提取更多有價值的信息,其性能退化研究多建立在歷史樣本數據上。然而歷史數據來源廣泛,不同樣本的歷史數據存在采集時間不同、數據長短不一等問題,過去的相關研究把狀態數據視作理想的完美數據,忽略了數據不規范對研究的影響。
目前,基于實時數據的性能退化研究主要是使用數據驅動手段進行的,其性能退化研究主要涉及指標構建和時間序列預測問題,其中指標構建主要通過對高維數據的去噪和降維完成,常見的降維方法包括經典的降維方法和機器學習方法,經典降維手段包括主成分分析、局部線性嵌入等;機器學習方法的核心手段為神經網絡。目前的指標構建手段多為對高維狀態數據直接去噪和降維,無法充分體現退化的狀態數據的時序性,且由于性能指標序列無法呈現單一的規律性,性能退化預測問題仍是研究中的側重點。
針對目前裝備性能退化研究中的難點,本文兼顧歷史樣本數據信息冗雜、數據不規范、性能變化不規律等問題,提出了一整套的研究方法和思路。該方法通過對歷史樣本數據進行規整,得到研究所用的規范數據,基于自組織映射(self-organizing maps, SOM)算法對相似樣本集的相似樣本特征進行提取,并利用堆棧自編碼器(stacked autoencoder, SAE)對相似樣本特征進行降噪和重構,根據最小特征圓法建立性能退化指標,最后采用了雙指數模型對性能指標進行處理,得到了測試樣本的性能退化軌跡。
1 樣本數據預處理
復雜裝備系統的性能退化指標構建涉及多參數多樣本時間序列的處理問題,裝備系統中同類傳感器不同子系統及不同傳感器記錄的數據對應著時間序列中的不同參數,而每一個樣本的狀態數據對應著一個高維時間序列,由于樣本的狀態數據來源廣泛,數據采集的時間點較難規范,故在性能指標構建之前需要對數據進行規整化處理。
1.1 時間標準化
單個裝備系統的各個傳感器一般在相同的時刻點采集數據,在線系統會設置間隔相同的時間進行數據采集,本文的數據規整主要考慮歷史樣本數據存在的數據采集時間間隔不規范問題。
假設已有個樣本的狀態數據,數據源自不同工廠的同一時期的裝備,數據采集時間間隔不完全相等,為了盡量減少數據規整帶來的誤差,采用基于K-means聚類的方法來選擇規整數據后的時間間隔,對數據采集時間間隔進行聚類,優選合理的聚類中心作為數據規整后的樣本時間間隔。數據規整流程如圖1所示。

圖1 數據規整流程Fig.1 Data alignment process
本文使用的插值方法為B樣條插值,B樣條插值具有較好的收斂性、穩定性和光滑性,相比分段線性插值,在節點處可導,更加光滑,次樣條曲線表達式為

(1)
式中:,()為次B樣條基函數,其求解方法由Cox-de Boor遞歸公式決定;為第+1個控制點。3次B樣條插值已經具有了完美的擬合原數據分布的能力,且高次插值會增加計算難度,故選擇3次B樣條插值進行數據規整。
這樣,綜合考慮了樣本的狀態數據采集時刻點的分布特點,利用插值的方法使得每一個樣本的規整后數據擁有相同的時間間隔,能夠較好地保持原樣本數據的分布特性,便于之后的降維運算,之后對裝備系統性能退化軌跡建模所涉及到的狀態數據均為規整后的新數據集。
1.2 多維時間序列的相似性匹配
多維時間序列匹配為相關領域較為麻煩的問題,其復雜度和準確度對之后結果會產生較大的影響。為了消除大樣本數據對于單個樣本的隨機性差異不敏感的問題,本文利用一種基于大間隔最近鄰(large margin nearest neighbor, LMNN)和動態時間規整(dynamic time warping, DTW)的多維時間序列相似性匹配的方法對樣本空間進行篩選,優選出與測試樣本相似的序列。
對于樣本集中任意兩個多維的時間序列和,=(,,…,),=(,,…,),其中(1≤≤)和(1≤≤)都是維列向量,表示樣本的某一時刻的參數值,則和之間的距離用馬氏距離定義為
(,)=(-)(-), 1≤≤;1≤≤
(2)
式中:為一個對稱半正定矩陣,稱為馬氏矩陣,通過LMNN學習得到。這樣,定義完多維時間序列的局部距離后,其最優規整路徑通過如下動態規劃問題解得

(3)
假設樣本集為,測試樣本為,在進行相似性匹配之前需要對數據進行區間切割處理,由于所研究裝備系統為同類型裝備系統,故可認為在相近的時間內不同樣本的相似程度更高。若測試樣本的時間區間為[,],對樣本集中的單個樣本的狀態序列進行時間區間切割,保留在[-,+]之間的數據,再進行匹配,匹配后的相似樣本集記作。
2 性能退化模型的構建
2.1 相似樣本特征提取
基于SOM的相似樣本集的樣本特征提取,是利用其良好的保拓撲能力,通過對相似樣本集進行無監督學習獲得勝出神經元的權值矢量,此時的獲勝神經元的權值矢量能夠代表相似樣本集的總體相似樣本特征。
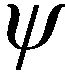

(4)
歐式距離最小的權值對應的神經元為獲勝神經元,通過不斷輸入重組后狀態的列向量,對權值和鄰域不斷更新,當重組后的單個狀態數據的列向量訓練完畢后代表一次完整的迭代結束,最后獲勝神經元的權重代表此時刻的樣本特征。
2.2 時序特征度量
2.2.1 特征降噪
利用SOM算法進行相似樣本訓練,提取到的是相似樣本集的樣本特征信息,得到的仍是高維時序序列,在度量其時序性特點之前,仍需要進一步對處理后的狀態數據進行降噪和去冗余操作。
SAE通常包含多個自編碼器,類似于深度置信網絡的訓練法則,采用逐層貪婪訓練單個自編碼器的方法,將單個自編碼器進行單獨訓練尋優,把抽象的特征作為下一個自編碼器的輸入,在獲得更抽象的輸出的同時降低了運算復雜程度,尤其適合處理復雜數據的深層特征提取問題。
圖2為典型的堆棧自編碼器原理示意圖,第一層為降噪自編碼器,狀態數據向量=經過降噪自編碼器(denosing autoencoder, DAE)過濾,利用逐層貪婪訓練方法進行訓練學習,將得到的抽象特征向量輸入第二層的稀疏自編碼器進行訓練,最終得到稀疏特征=(,,…,)。

圖2 SAE示意圖Fig.2 SAE schematic
2.2.2 指標建立
利用SOM和堆棧自編碼器的狀態數據進行訓練操作,可以提取裝備在具體時刻的性能特征,需要進一步對特征處理變成具體的性能指標,并將時序變化特征融入其中。性能指標的建立一直是本文方法中的重點,良好的性能指標應該要能夠反映產品的退化趨勢,過濾掉一些次要的因素,也要能反映出裝備在退化時產生的性能波動,由此,本文建立一類基于最小特征圓的指標方法。
假設裝備系統剛開始時處于較為穩定的狀態,可以認為是健康狀態,隨著時間推移,裝備會慢慢發生退化,偏離健康狀態。故對上述訓練得到的特征變量{},提取出正常運行時的特征集合,利用聚類分析得到中心特征,并以此為圓心作一個高維最小圓,將所有健康特征包裹在內。三維最小特征圓示意圖如圖3所示。

圖3 三維最小特征圓示意圖Fig.3 Three dimensional minimum characteristic circle diagram
由于裝備正常運行時會存在正常的數據波動,故可假設此最小圓內的特征為健康特征,故第時刻的性能指標為

(5)
基于最小特征圓法可以將SAE提取的退化特征轉化為具體的性能指標,但得到的一維時序數據存在隨機性因素的干擾,數據仍然存在大量噪聲,需要選擇合適的時序數據擬合和預測算法對裝備的性能退化規律和壽命進行預測。
2.3 性能退化軌跡擬合與壽命預測
2.3.1 退化軌跡預測
復雜裝備系統的性能變遷受到多種復雜因素的共同影響,其性能變化軌跡無法呈現單一的規律性,且性能指標的變化包含大量的噪聲。為了描述和預測性能指標的退化過程,采用動態的雙指數模型來處理得到的性能指標,雙指數模型廣泛應用于多類型時間序列的擬合和預測問題,在金融、醫療等領域發揮了重要作用。
根據上文構建的性能退化指標,動態雙曲線模型可以表示為
=1,·exp(1,·)+2,·exp(2,·)+
(6)
其中,1,,2,和1,,2,為時刻的狀態參數,由于本文的指標序列為非規律變化的信號,此處默認為1,≠2,,為時刻的噪聲。在大數據條件下,擬合誤差一般均服從正態分布,且時間序列具有時序相關性,可構造狀態參數空間如下:

(7)
故本文對于退化軌跡的擬合和預測問題可以等同為一個由上述狀態空間描述的動態系統,此系統的狀態轉移方程可以概括為

(8)


(9)

232 閾值設置
對復雜裝備系統進行性能退化研究需要對系統的故障時間和指標閾值進行估計和選擇,本文研究裝備的退化規律主要是基于相似樣本進行的,每一個相似樣本對應一個故障時間和狀態數據,將這些數據信息輸入到SAE可以計算得到一個閾值集合,設置該集合為{,,…,}。
本文基于高維時序數據的相似樣本選取得到了基于馬氏距離的相似度,對于同一個測試樣本,將相似度等比例縮小,且相似度之和為1,此測試樣本的退化閾值由下面的表達式給出:

(10)
式中:,為相似樣本集中樣本與測試樣本的相似度。
3 案例計算
3.1 數據說明
本文對某大型自動高壓加熱裝備系統進行仿真,主要數據采集包括溫度、鍋內壓力、出氣口壓力、渦輪轉速等26項參數,數據采集時裝備均處于運行狀態,總隨機因素主要考慮了電流沖擊、溫度、材料腐蝕,以及各項參數對應子系統中存在的環境因素,采集時間間隔均不相同,共采集了70個全壽命樣本數據,另隨機選取3個測試樣本,測試樣本均采集了前120個數據,為了體現個體差異,測試樣本的初始監測時刻時間間隔較大,由于不同參數間數據差別較大,故模型訓練前對原始數據進行了歸一化處理。
3.2 模型訓練與指標建立
(1) 數據預處理。根據本文的數據規整原則,對73個樣本數據進行重建,對73個樣本數據的采集時間間隔的聚類結果如圖4所示。

圖4 采集時間間隔聚類結果圖Fig.4 Collecting time interval clustering result
73個樣本數據共得到3個聚類中心,從小到大3個類別含樣本數分別為13、40和20,故本文采取位于中間類別的聚類中心作為數據規整后的時間間隔,初始采集時間間隔為6.22 h,利用B樣條插值即可得到規整后的新數據集。
(2) 相似性匹配。基于B樣條插值得到73個樣本的新狀態數據集,在衡量樣本數據間的相似度之前,對70個歷史樣本數據進行截斷處理,僅保留前130個樣本數據,設置相似閾值即最大相似距離為20。3個測試樣本分別編號c -1、c -2、c -3,c -1共選取了23個相似樣本,c -2共選取了19個相似樣本,c -3選取了28個相似樣本,將得到的3個測試樣本集分別輸入SOM網絡,提取相似樣本集的相似樣本特征。
(3) 退化特征提取與重構。本文采用的SAE共存在3層,一層降噪自編碼器,兩層稀疏自編碼,SAE的3個隱藏層分別有18、16、12個神經元,DAE采用Srivastava等人提出的Dropout技術來完成加噪過程,稀疏自編碼器L2正則化權重衰減稀疏為0.000 1,稀疏性懲罰權重因子均為4,稀疏性系數為0.05。將3個測試樣本的相似樣本特征數據集依次輸入訓練,得到了3個12維的時間特征序列。3個測試樣本部分退化特征如圖5所示。


圖5 測試樣本部分退化特征Fig.5 Partial degeneration of the test sample
圖5為經過SAE重構后的部分抽象退化特征,代表了測試樣本退化過程中具有的突出退化特征,從結果可以看出,重構后的退化特征已經具有明顯的退化特性,且在裝備運行初期,退化特征波動較小,裝備處于安全運行狀態,驗證了基于最小特征圓的指標構建方法的可行性。
3.3 結果分析
本文使用流行的深度學習方法對仿真后的樣本數據進行處理,作為本文方法的對比實驗。主要處理過程為利用SOM算法提取核心特征,使用卷積神經網絡(convolutional neural network, CNN)對高維的核心特征直接進行降維成一維的性能指標集,最后采用非線性自回歸網絡(nonlinear auto regressive with extra input, NARX)對使用壽命進行預測。
利用雙指數模型對最小特征圓得到的指標序列擬合結果如圖6所示。從圖5和圖6可以看出,不同樣本的退化軌跡既存在相似性,也存在差別,其最終失效的閾值也各不相同,表明本文基于相似樣本集去研究裝備退化規律是合理的。圖6(a)中,裝備預測指標在達到故障閾值之前,含噪聲的原始退化軌跡存在兩次達到閾值的情況,實際工程中,裝備極有可能在此時刻周圍遭受極端沖擊,應該在該時刻附近注意裝備的異常反應,以便及時應對可能的突發情況。

圖6 測試樣本退化軌跡與壽命預測圖Fig.6 Test sample degradation trajectory and life prediction
圖6中,裝備的退化曲線會出現暫時的峰值,對應著實際生產中的外部載荷沖擊導致性能發生變化,可以發現,在此后的一段時間內,裝備的性能指標曲線會發生緩慢回落,體現了裝備遭受外力沖擊導致的性能突變會隨著時間逐漸恢復;比較峰值左右的性能指標的平均大小,可以看出雖然突變的性能會隨著時間恢復,但無法恢復到沖擊前的水平。
從3個樣本的退化軌跡可以看出,測試樣本c -2和c -3在運行不久后性能發生了明顯的退化,原因是樣本在運行初期便遭受到了劇烈的沖擊,而樣本c -1的退化軌跡則相對較為緩慢,在850 h后才發生迅速的退化,這使得測試樣本c -1的壽命和失效閾值要明顯高于測試樣本c -2和c -3。3個測試樣本的估計壽命如表1所示。

表1 測試樣本估計壽命對比
根據表1的估計壽命對比,本文模型的預測精度總體上比基于深度學習的直接降維方法的預測精度要高,且本文所提出的退化趨勢分析方法對于略微平穩的系統,所得結果較為準確,對于遭受劇烈不規律沖擊的裝備系統,預測誤差會稍大。
使用深度學習方法在估計樣本c -3時誤差比其他樣本要明顯,比較數據處理的過程,發現CNN直接將數據降維成一維的指標集,對周期性特征不敏感,無法充分體現數據特征時序性變化。
4 結 論
本文考慮了性能退化研究中大樣本數據形式不規范、存在隨機性誤差等問題,建立了一類基于相似樣本特征提取的最小特征圓的指標構造方法。方法主要立足于相似樣本的相似特征提取,良好的相似特征提取方法可以有效提高預測精度,SOM算法在凝練核心特征方面具有非常大的優勢,通過多樣本學習,能夠提取充分反映相似樣本整體規律的特征。
經與流行的利用深度學習直接降維的方法進行對比,本文提出的指標構建體系,能夠充分提取退化特征的時序性,過濾掉冗雜無關的信號。對比結果表明,本文所建立的模型可以很好地反映裝備性能變遷過程,能夠突出體現裝備性能退化過程中受到外力作用時的變化特點,有助于實時監控裝備的性能特性,對可能發生的潛在威脅實時預警。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
