多模態(tài)公文的結構知識抽取與組織研究
2022-06-25 13:16:48徐瑞麟耿伯英劉樹衎
系統(tǒng)工程與電子技術 2022年7期
徐瑞麟, 耿伯英, 劉樹衎
(1. 海軍工程大學電子工程學院, 湖北 武漢 430033; 2. 中國人民解放軍91001部隊, 北京 100036;3. 東南大學計算機科學與工程學院, 江蘇 南京 211189)
0 引 言
目前,以司法機器人等為代表的面向規(guī)范性文本的智能問答應用實踐中,最普遍使用的方式是針對常見問題(frequently asked questions, FAQ)構建問答對,但所構建的問答對難以涵蓋所有的問題。同時,基于知識庫問答(knowledge based question answering, KBQA)的方法也存在解答效率低的問題。由于法律法規(guī)和政策文件等文檔數(shù)據(jù)條目清晰,法理邏輯和思想路線等內(nèi)涵蘊藏于文檔結構中,因此針對文檔的結構知識抽取和組織研究成為了一個值得探索的方向。然而,此類文檔數(shù)據(jù)一般通過網(wǎng)頁、電子文檔、掃描件等非結構化的形式被獲取到,如何將此類非結構化文檔轉(zhuǎn)換成為結構化的、層次邏輯清晰的文檔,成為了一個重要的研究課題。
以知識圖譜為代表的知識網(wǎng)絡是最通用的知識結構化表示形式,例如FreeBase、DBpedia和YAGO等。這些大規(guī)模知識庫一般通過實體識別和關系抽取等技術,從文本中大量抽取“實體,關系,實體”的三元組知識而構建。然而,此類知識圖譜往往存在關系稀疏、結構上缺乏層次性等特點,難以形成與人類知識組織相似的知識體系,無法針對智能問答等下游任務提供技術支撐。為解決三元組知識結構邏輯性不強的問題,本文對文檔的結構知識抽取與組織展開研究,將文檔各級標題、摘要、作者、成文時間、文檔編號等要素稱為文檔的知識結構要素。通過將上述文檔知識結構要素按照文檔的結構邏輯組織起來,更有利于厘清文檔知識的層次邏輯,并建立知識體系。
在文檔的結構信息抽取任務中,傳統(tǒng)方法大多面向文本單一模態(tài),采用基于規(guī)則的方法或基于自然語言處理(natural language processing, NLP)的方法實現(xiàn)。文獻[8]利用正則表達式實現(xiàn)對金融公告文檔中章節(jié)標題的抽取。文獻[9]針對法律裁判文書構建規(guī)則,將非結構化的裁判文書轉(zhuǎn)換成結構化的XML格式文檔。文獻[10]提出了一種基于雙向長短記憶(bidirectional long short-term memory, BiLSTM)網(wǎng)絡和條件隨機域(conditional random field, CRF)模型的端到端模型,以從庭審筆錄中抽取證據(jù)信息。文獻[11]研究了利用命名實體識別和關系抽取方法從病歷中抽取結構信息的方法。文獻[12]設計了一種結合規(guī)則和NLP模型的文檔結構信息抽取方法。文獻[13]提出了一種基于隱馬爾可夫模型方法和深度神經(jīng)網(wǎng)絡的文檔版面分析方法。然而,這些文本模態(tài)的方法沒有考慮文檔的視覺特征,無法有效利用文檔標題等視覺特征明顯的關鍵要素。
視覺豐富文檔分析(visually-rich document analysis, VRDA)任務旨在對文檔頁面圖像或PDF文檔進行分析,以識別文檔中的標題、插圖、表格、公式等各類結構要素。該任務與文檔的知識結構抽取具有相似性。為了實現(xiàn)對視覺豐富文檔(visually-rich documents, VRDs)的結構信息抽取,文獻[14]針對銀行文檔頁面提出了一種先進行光學字符識別(optical character recognition, OCR),再通過NLP模型抽取文檔結構信息的方法;文獻[15]提出了一種從VRDs中提取信息的通用方法,將文檔頁面分割為不同語義區(qū)域進行信息抽取;文獻[16]提出了一種端到端的多模態(tài)全卷積網(wǎng)絡;文獻[17]提出了結合文檔中文本與視覺信息的圖卷積模型;文獻[18]提出了大規(guī)模預訓練語言模型與圖神經(jīng)網(wǎng)絡相結合的抽取方法。LayoutLM及其改進模型則將文本模態(tài)和圖像模態(tài)結合起來,以更好地抽取文檔結構信息。
上述模型和方法大多聚焦于商業(yè)領域文檔,對公文這一具有規(guī)范成文規(guī)則且應用廣泛的文檔類型鮮有研究。并且,目前的研究和應用局限于抽取知識結構要素,而沒有將知識結構要素按照文檔的結構邏輯組織起來。因此,為了解決知識結構要素的抽取和組織中存在的問題,本文以公文為研究對象,構建文本和圖像多模態(tài)公文文檔數(shù)據(jù)集,在文本模態(tài)通過構建規(guī)則抽取知識結構要素,在圖像模態(tài)利用目標檢測和OCR抽取知識結構要素;并提出多模態(tài)知識結構要素抽取模型,將文本和圖像兩個模態(tài)的抽取結果綜合考慮,得到最終的抽取結果。本文利用所抽取出知識結構要素的層次結構特征,將非結構化的公文文檔按結構邏輯組織形成文檔結構樹并構建結構化的文檔網(wǎng)絡。實驗驗證了對多模態(tài)文檔知識結構要素抽取和組織的有效性。
本文的主要貢獻如下:① 針對目前鮮有研究的公文結構知識要素抽取問題,提出一個多模態(tài)公文結構知識要素抽取模型;② 設計文檔結構樹(document structure tree, DST)模型,將抽取的知識結構要素組織形成結構化圖網(wǎng)絡;③ 構建多模態(tài)公文文檔數(shù)據(jù)集,填補了多模態(tài)公文文檔的數(shù)據(jù)空白。
1 多模態(tài)公文知識結構要素抽取
本文以公文為例(本文所稱公文,是指依據(jù)文獻[21-22]中的規(guī)定所擬制的機關公文),從文本和圖像兩個模態(tài)分析抽取公文知識結構要素的方法。由于書籍、論文、技術報告和法律法規(guī)文檔中的知識結構要素同樣具備與公文類似的規(guī)律性特征,因此也可以采用相同方法實現(xiàn)抽取。
1.1 文本模態(tài)的知識結構要素抽取
文本模態(tài)的公文文檔知識結構要素抽取,即從無結構的公文文本中抽取“正文標題、一級標題、二級標題、三級標題、密級、緊急程度、發(fā)文機關標志、發(fā)文字號、主送機關、抄送機關”等要素。由于公文文檔具有嚴格的成文標準,因此可以通過建立規(guī)則實現(xiàn)知識結構要素的抽取。
1.1.1 公文知識結構要素的規(guī)則分析
文獻[21-22](以下簡稱“《標準》”)對公文的各級標題進行了規(guī)定,這些標題具備典型的上下級層次關系,且按照“數(shù)詞+特殊符號”的方式進行編號。因此,通過分析這些編號模式并建立詞典(見表1),可以實現(xiàn)對一級、二級、三級標題的識別。

表1 公文各級標題的編號方法
此外,依據(jù)機關公文的行文和用語習慣,可以得到表2所示的公文常用的其他形式的各級標題編號方法。

表2 公文各級標題的其他編號方法
類似地,對于密級、緊急程度、發(fā)文字號、主送機關等其他各類結構要素,從文本的角度看,可以分析和歸納為表3所示的識別規(guī)則。
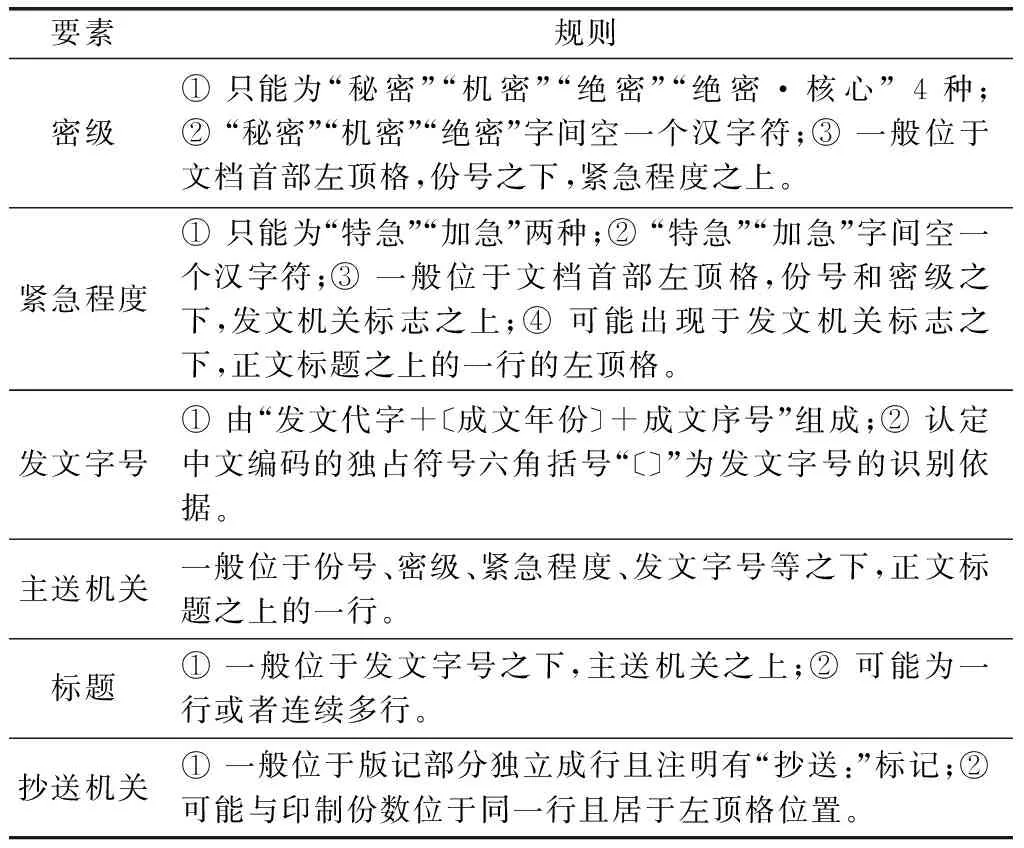
表3 公文知識結構要素的抽取規(guī)則
1.1.2 公文知識結構要素的抽取流程
(1) 數(shù)據(jù)預處理
數(shù)據(jù)預處理包括文本清洗和文本分句兩個部分。文本清洗,即清除不符合格式規(guī)范的換行符、空符、縮進和英文標點等字符的過程。文本分句,首先以換行符為標志,將文本所成自然段進行分割并賦予標簽,隨后在分段的基礎上,以中文常用句終標點(如句號、感嘆號、省略號等)為標志對段落進行語句分割并賦予標簽。數(shù)據(jù)預處理算法如算法1所示。

算法 1 數(shù)據(jù)預處理輸入 公文文本數(shù)據(jù)Document輸出 賦標簽的句子集Sentences1 lines ← readlines(Docunment)2 for line in lines do3 Paragraph ← line.strip(‘tab’)4 end for5 for para in Paragraph do6 Sentences←Paragraph[para].cut(punctuation)7 end for8 return Sentences
通過數(shù)據(jù)預處理,使得整篇數(shù)據(jù)文本轉(zhuǎn)化為以句子為單位、每個句子由標簽索引的自由文本集合={(,),(,),…,(,)},其中(,)表示文中每一個句子所被賦予的唯一標簽,也即該句位于文中第自然段的第句。
(2) 建立抽取規(guī)則
由于《標準》在文本層級上對各級標題的規(guī)定嚴格到了具體的字符級別,因此可以簡單地認定,對文本中的每個語句,僅需遍歷前文所構建的標題詞典,若存在匹配的文本對象,則記錄其所處級別和語句的坐標位置。各級標題識別算法如算法2所示。
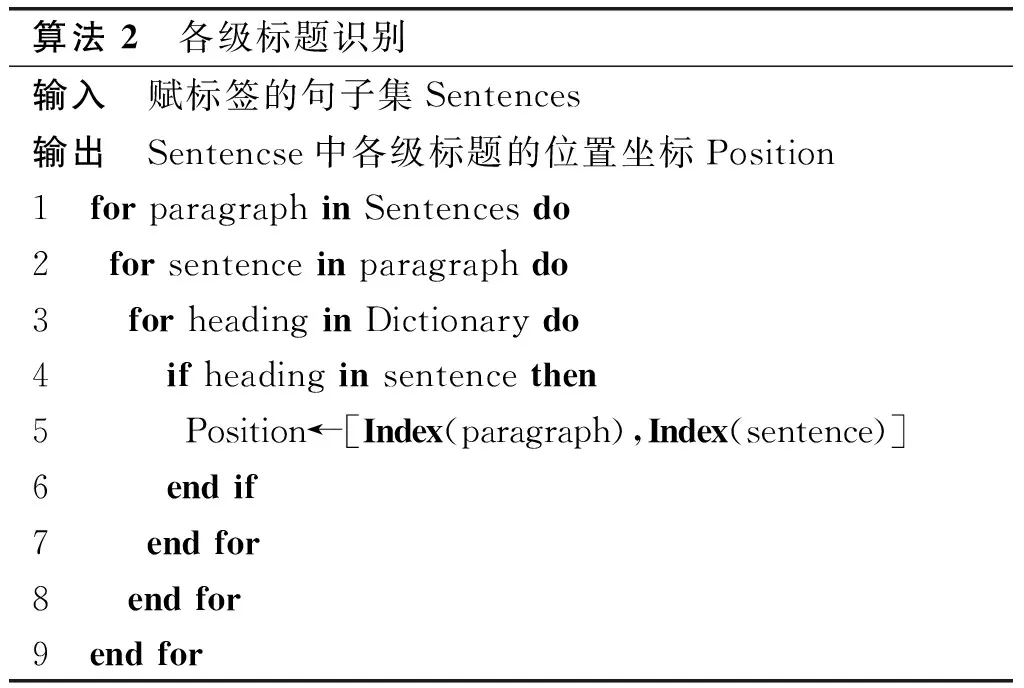
算法 2 各級標題識別輸入 賦標簽的句子集Sentences輸出 Sentencse中各級標題的位置坐標Position1 for paragraph in Sentences do2 for sentence in paragraph do3 for heading in Dictionary do4 if heading in sentence then5 Position←[Index(paragraph),Index(sentence)]6 end if7 end for8 end for9 end for
算法2中Dictionary代表前述的5類標題詞典;Index(·)函數(shù)的功能是返回當前對象所在列表的標號。
在上述過程中,將識別得到的各級標題整理得到兩種基本類型:一是具有明顯級別特征的一級、二級、三級和四級標題,分別記錄于表Position_1,Position_2,Position_3,Position_4中;二是其他難以確定級別的標題,記錄于表Position_0中。
通過分析《標準》的具體規(guī)定,以及給出的若干樣例,分析考慮單署公文、聯(lián)署公文、信函、通知、命令等各類格式的盡可能多的成文情形,以及可能出現(xiàn)的識別歧義情況。因此,從標點符號、縮進、句長、相對位置等方面入手,歸納建立文檔描述要素的識別規(guī)則。知識結構要素的抽取算法如算法3所示。

算法 3 知識結構要素的抽取輸入 賦標簽的句子集Sentences輸出 知識結構要素集合{密級、緊急程度、發(fā)文字號、主送機關、抄送機關、正文標題}1 for paragraph in Sentences do2 for sentence in paragraph do3 if “×密” in sentence then4 密級 ← sentence5 end if6 if “×急” in sentence then7 緊急程度 ← sentence8 end if9 if “〔 ” in sentence and “〔 ” in sentence do

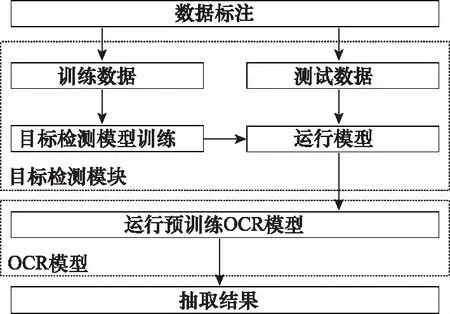
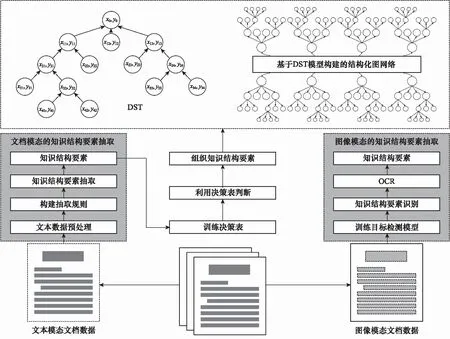
10 if “簽發(fā)人:” in sentence do11 發(fā)文字號 ← sentence[: sentence.find(“號”)]12 elif sentence.endswith(“號”) do13 發(fā)文字號 ←sentence[sentence.rfind(“”)+1:]14 elif “” in sentence:15 發(fā)文字號 ← sentence[: sentence.find(“”)]16 else 發(fā)文字號 ← sentence17 end if18 end if19if (sentence.endswith(“:”) and Index(paragraph)<=8) or (“主送:” in sentence) do20 主送機關 ← sentence21 end if22 if “抄送:” in sentence do23 抄送機關← sentence24 if 發(fā)文字號 and 主送機關 do # 判斷是否存在25 ifIndex(paragraph[Index(發(fā)文字號)]) 算法3中find(·)函數(shù)的功能是返回左起第一個與對象字符匹配字符的標號,endswith(·)函數(shù)的功能是判斷字符串是否以對象字符結尾,rfind(·)函數(shù)的功能是返回右起第一個與對象字符匹配字符的標號,“”表示空格符。 通過前述算法構建的規(guī)則,對以句子為單位的公文字符串進行操作,即可實現(xiàn)對符合《標準》規(guī)定的文檔知識結構要素的抽取。 人在判斷所閱讀的文本屬于何種類別時,除了從語義上分析外,人的視覺也在文本閱讀中起到了直接作用。計算機在模擬人的閱讀過程時,也可以模擬人的視覺角度對文檔進行分析。 在文本模態(tài),基于規(guī)則的抽取方法依賴于規(guī)范性的文本數(shù)據(jù),容錯性能有限,尤其對于識別規(guī)則復雜的文檔描述要素,在文本數(shù)據(jù)存在不規(guī)范性的情況下,所構建的規(guī)則無法保證知識結構要素抽取的準確性。同時,文檔的字體、字號、文字顏色和相對位置特征無法通過文本表現(xiàn)出來,也就需要考慮在語義分析之外,加入視覺分析手段,以提升知識結構要素抽取的容錯能力。 基于計算機視覺(computer visualization, CV)的知識結構要素抽取,是OCR與目標檢測兩類計算機視覺任務的組合應用。具體而言,就是先通過目標檢測,判斷找到要素所在區(qū)域并判斷要素的類別,再從這些區(qū)域中識別出文檔要素所對應的文本內(nèi)容。 圖1是圖像模態(tài)的知識結構要素抽取模型的基本結構,該模型由目標檢測模塊和OCR模塊兩部分構成。對于圖像模態(tài)的文檔數(shù)據(jù),例如文檔的掃描件或PDF格式的文檔,將其轉(zhuǎn)化為圖像處理。目標檢測模塊使用目標檢測算法YOLO v4網(wǎng)絡模型。YOLO v4充分借鑒了深度殘差網(wǎng)絡(deep residual network, ResNet)、稠密卷積網(wǎng)絡(dense convolutional network, DenseNet)和特征金字塔(featur pyramid networks, FPN)的思想,在識別準確性和識別速度上都達到了目前目標檢測領域的領先水平。OCR模塊使用經(jīng)漢字符和拉丁字符預訓練的Tesseract-OCR開源識別引擎。 圖1 圖像模態(tài)的知識結構要素抽取模型Fig.1 Structural elements of knowledge extraction in image modal 當圖像模態(tài)的文檔數(shù)據(jù)輸入后,目標檢測模塊進行多目標識別,輸出圖像中各目標(文檔要素)的視覺特征向量=(,,,,,),其中表示目標的要素類型標簽,表示目標屬于該類要素的概率,,,,是目標所在位置的邊界框坐標,分別表示中心點(,),寬度和高度。隨后,OCR模塊將根據(jù)向量中的邊界框坐標分割圖像區(qū)域,并按區(qū)域進行OCR識別,讀出各要素的具體內(nèi)容。通過上述兩個模塊的操作,即得到了圖像模態(tài)的文檔數(shù)據(jù)中知識結構要素的類型和文本內(nèi)容。 由于單一模態(tài)的抽取在面對不同類知識結構要素時的效果表現(xiàn)存在優(yōu)劣差異,因此需要從兩個模態(tài)出發(fā),同時考慮兩個模態(tài)的抽取結果,補足單一模態(tài)抽取的容錯性問題,以改善知識結構要素的抽取質(zhì)量。 圖2是基于跨模態(tài)分析的知識結構要素抽取模型的總體結構,其中兩類知識結構要素抽取模型分別對兩個模態(tài)的文檔數(shù)據(jù)進行抽取,隨后綜合兩類模型對不同文檔要素的抽取能力,對兩類模型的抽取結果進行綜合考量,通過訓練得到?jīng)Q策表,利用決策表在不同情況下?lián)駜?yōu)采納,優(yōu)化知識結構要素抽取結果。 圖2 多模態(tài)的知識結構要素抽取模型Fig.2 Multi-modal document knowledge structural elements extraction model 對于知識結構要素,設文本模態(tài)的抽取結果為One-Hot表示的向量_text,圖像模態(tài)的抽取結果為One-Hot表示的向量_image,若文檔知識結構要素的總數(shù)為,要素類別總數(shù)為,則兩個模態(tài)抽取結果的所有可能組合共種。若設×2矩陣為決策矩陣,=[1,2]×2,其中每行表示一種抽取結果組合。設中第行表示“文本模態(tài)對要素的抽取結果為第類,圖像模態(tài)對同一要素的抽取結果為第類”的情況,其中=×。若文本模態(tài)的抽取結果正確而圖像模態(tài)的抽取結果不正確,則令1=1,2=0,反之則令1=0,2=1,若兩個模態(tài)的抽取結果均正確,則令1=2=05這樣,對于要素,兩個模態(tài)最終的抽取結果為=1_text+2_image。經(jīng)過一定樣本訓練后得到后,對于輸入的兩個模態(tài)的抽取結果(第類和第類),只需查矩陣的第×行,加權求和即得最終的抽取結果。 前文構建的知識結構要素抽取模型實現(xiàn)了對文檔知識結構要素類別的識別,但是并沒有明確要素之間,尤其是各級標題之間的并列關系和包含關系,沒有形成層次性的文檔結構。 從人的行文和閱讀習慣出發(fā),要解決各級標題之間的相互關系問題,僅需考慮各級標題在全文中的出現(xiàn)順序。在屬于“包含”關系的各級標題間,先出現(xiàn)的標題級別一定高于后出現(xiàn)的標題級別;在屬于“并列”關系的同級標題間,在文中出現(xiàn)的先后順序亦可反映其關系。概括地說,就是通過各級標題在文中出現(xiàn)的先后順序,解決屬于“包含”關系的各級標題間的分級問題和屬于“并列”關系的各級標題間的排序問題。 算法1實現(xiàn)了將自由文本集合轉(zhuǎn)換成為具有“段落標號+段內(nèi)分句標號”標簽結構的句子集合。段落標號越小,說明該句所在段落在前;段內(nèi)分句標號越小,說明該句在段內(nèi)的順序在前。這種分句方式體現(xiàn)著明顯的先后關系,也就為解決文本結構化問題提供了參考和依據(jù)。 樹是不包含簡單回路的無向或有向連通圖。有根樹是一個頂點被指定為根,每一條邊都指向遠離或趨近根的方向的樹。排序有根樹是每個分支節(jié)點的所有子節(jié)點按照從左至右排序的有根樹。 精確子圖枚舉樹(exact subgraph enumeration tree, ESU-Tree)是為解決網(wǎng)絡模體識別問題所設計的結構模型。該模型用于搜索網(wǎng)絡中指定規(guī)模的子圖。由于ESU-Tree的結構設計能夠較好地反映層次和結構關系,因此在ESU-Tree的基礎上,本文針對文檔的層次化表示問題設計了一種樹形結構,該結構在本文中稱為DST,如圖3所示。 圖3 DST模型Fig.3 DST model DST是一顆有向有根樹,其特點如下: (1) 每個子代節(jié)點都指向各自的親代節(jié)點; (2) 根節(jié)點位于第0層,全樹層數(shù)為4,深度為4,高度為5; (3) 第4層全為葉子結點; (4) 節(jié)點具有權重而邊沒有權重,且節(jié)點權重由(前權,后權)兩部分組成,比較權重時優(yōu)先比較前權,前權相等時比較后權; (5) 左節(jié)點權重小于右節(jié)點,親代節(jié)點權重小于子代節(jié)點。 將一個節(jié)點的親代節(jié)點的同層右節(jié)點定義為該節(jié)點的右親節(jié)點。類似地,將一個節(jié)點的親代節(jié)點的同層左節(jié)點定義為該節(jié)點的左親節(jié)點。 用表示親節(jié)點,表示子節(jié)點,LP標志左親節(jié)點,RP表示右親節(jié)點,ST表示子樹,DST表示整顆DST,RST表示相對于ST的右子樹,表示標題級別,用“←”表示“賦值為”weight(·)表示節(jié)點權重。顯然,分析DST的特點,可以歸納出以下3條基本性質(zhì)。 在DST的任意一顆子樹內(nèi),存在如下的權重關系: weight() 對DST中的任意節(jié)點node,存在?node∈DST,?ST?DST,←Root(ST),RP←Root(RST)。若weight() 對DST中的任意節(jié)點node,其層級歸屬滿足?node∈DST,?,,且=+1;若min weight() DST的建立順序和遍歷順序與中文閱讀順序一致,基本按照“根節(jié)點→相對左節(jié)點→相對右節(jié)點”的順序進行。其建立問題可以抽象為下述的表示形式。 已知:① 部分節(jié)點(各級標題的節(jié)點)所屬層;② 各節(jié)點權重。 求解:① 各節(jié)點的親子關系;② 部分節(jié)點(其他標題的節(jié)點)歸屬。 根據(jù)性質(zhì)1和性質(zhì)2所述規(guī)則,通過比較節(jié)點權重的大小關系,可以完成各級節(jié)點之間并列和歸屬關系的確定。需要注意的是,在比較權重時,應當按照定義,優(yōu)先比較節(jié)點的前權,也即節(jié)點標簽的第一個坐標值,當前權相同時,再比較第二個坐標值。 實際上,一個DST就是結構化知識網(wǎng)絡的一個子網(wǎng),或是知識結構要素圖譜(網(wǎng)絡)中的一個子圖。在大量文檔數(shù)據(jù)支持的情況下,結合主題識別和關鍵詞抽取,通過DST(文檔子圖)的聚類,就具備了構建大規(guī)模文檔知識網(wǎng)絡的基礎。 使計算機實現(xiàn)對文檔知識結構要素的組織,需要考慮對前述DST模型的數(shù)據(jù)結構進行設計。而進行設計的主要問題是要在計算機中實現(xiàn)“親節(jié)點<子節(jié)點<右親節(jié)點”的關系判定。要完成這一任務,需要從左至右、自頂向下地訪問每個節(jié)點,判斷左右級、上下級節(jié)點(子樹)之間的并列和包含關系。 對于不等式“親節(jié)點<子節(jié)點<右親節(jié)點”,考慮條件不完備的情況,由于采用自頂向下遍歷,因而親節(jié)點一定在子節(jié)點之前得到訪問,即不等式左端一定成立,故僅需考慮右端條件不完備的情況,即右親節(jié)點(右子樹)不存在的情況。 顯然,若采用分類討論方法,單獨為右親節(jié)點不存在的情況追加補充規(guī)則的成本較高,因此,考慮構造使得不等式右端恒成立的條件以適應原規(guī)則,而非建立新規(guī)則。為此引入絕對右子樹(absolute right subtree, ARS)的概念。 ARS是根節(jié)點權重為充分大數(shù),子節(jié)點為空的DST。其實際上是所在層最右端的一個權重充分大的葉子節(jié)點,只參與權重比較,但不會被訪問。 由于第4層屬于四級標題項,均為葉子結點,子樹為空,因此僅需在第1、2、3層建立ARS。并且,通過設置遍歷條件,可以使得ARS參加權重比較而不被訪問,這就解決了右親節(jié)點不存在的情況。 例如,圖4所示的節(jié)點權重是2019年政府工作報告的文檔結構要素所建立的DST的一部分。顯然,對于節(jié)點的所有子節(jié)點到,都沒有右親節(jié)點,而使得性質(zhì)1不再成立。為了確保性質(zhì)1恒成立,則weight(ARS)應當是一個充分大數(shù)。本文將16進制數(shù)0×3F3F3F3F設置為該充分大數(shù),該數(shù)值既避免了數(shù)據(jù)溢出,又與32位整型數(shù)據(jù)最大值0×7FFFFFFF同處于10量級。由于ARS的引入,使得子節(jié)點到的右親節(jié)點成為了,權重為充分大數(shù)0×3F3F3F3F;而其左親節(jié)點的權重為38;進而使不等式38 圖4 ARSFig.4 ARS 因此,DST的最小數(shù)據(jù)單元就是一個包含根節(jié)點屬性和所有子節(jié)點屬性的結構體,并通過遞歸定義,即可實現(xiàn)DST的構建。 在VRDA任務中,目前已經(jīng)公開的單模態(tài)和多模態(tài)數(shù)據(jù)集主要集中在商業(yè)文檔和科學文獻數(shù)據(jù)上。文獻[29]構建了一個圖像模態(tài)的大規(guī)模文檔數(shù)據(jù)集PubLayNet,文獻[30]構建了一個多模態(tài)的科學文獻數(shù)據(jù)集DocBank。文獻[31]和文獻[32]中分別使用了各自獲得的圖像模態(tài)公文文檔,但并沒有將數(shù)據(jù)公開。因此,目前針對公文的公開多模態(tài)文檔數(shù)據(jù)集仍是一個空白。 為了填補多模態(tài)公文文檔分析任務中的數(shù)據(jù)空白,并驗證本文提出模型的有效性,本文從國務院政策文件庫以網(wǎng)頁文本格式獲取公文文檔,經(jīng)數(shù)據(jù)清洗后,設計符合《標準》規(guī)定的LaTeX模板并將無格式的網(wǎng)頁文本批量排版編譯為PDF文檔,隨后轉(zhuǎn)換為圖像模態(tài)的文檔數(shù)據(jù)。本文將構建的多模態(tài)公文文檔數(shù)據(jù)集命名為GovDoc-CN,并將該數(shù)據(jù)集開源發(fā)布。流程如圖5所示。 圖5 GovDoc-CN數(shù)據(jù)集的數(shù)據(jù)處理流程Fig.5 Data processing flow of GovDoc-CN 本文共標注了6 816個文檔頁面,“發(fā)文機關標志、發(fā)文字號、正文標題、主送機關、一級標題、二級標題、三級標題、發(fā)文機關、成文日期和正文”10類共29 942個文檔知識結構要素。數(shù)據(jù)集統(tǒng)計信息如表4所示。 表4 數(shù)據(jù)集統(tǒng)計信息 本文中基于計算機視覺的文檔要素實體抽取,將YOLO v4模型的學習率設置為2e-5,Batchsize設置為64,迭代次數(shù)26 000,訓練集包括4 090個文檔頁面,驗證集包括2 045個文檔頁面,測試集包括690個文檔頁面。 為評價模型的抽取效果,用TP表示“實際為正例,預測為正例”的數(shù)量;用FP表示“實際為負例,預測為正例”的數(shù)量;用FN表示“實際為正例,預測為負例”的數(shù)量;用TN表示“實際為負例,預測為負例”的數(shù)量。 于是,定義模型的精確率為 Precision=TP/(TP+FP) (1) 定義模型的召回率為 Recall=TP/(TP+FN) (2) 模型的精確率反映了模型預測結果的準確性,因此也稱查準率。模型的召回率反映了模型預測全面性,因此也稱查全率。 為了使用一個綜合考慮“查準”與“查全”的指標,本文使用1分數(shù)評估抽取模型的效果,其計算方法為 (3) 在同一測試集下,基于規(guī)則的知識結構要素抽取方法和基于計算機視覺的知識結構要素抽取方法取得的結果如表5所示。 表5 知識結構要素抽取結果 在表5中,A表示方法1為基于規(guī)則的抽取方法;B表示方法2為基于計算機視覺的抽取方法;C表示方法3為方法1與方法2的組合運用。 通過表5可知,基于規(guī)則的抽取方法(文本模態(tài))和基于計算機視覺的抽取方法(圖像模態(tài))在知識結構要素抽取上的效果表現(xiàn)互為補充。在1分數(shù)表現(xiàn)上,多模態(tài)抽取方法相比文本或圖像單一模態(tài)的抽取方法分別提升了10.80%和10.83%,各類要素的抽取效果也為最優(yōu),證明了本文所提出的多模態(tài)文檔知識結構要素抽取方法的有效性,與單一模態(tài)的抽取方法相比具有明顯的效果提升。 本文從GovDoc-CN數(shù)據(jù)集中隨機選擇了1 000篇公文文檔,利用第2節(jié)提出的知識結構要素組織方法,將每篇文檔抽取的知識結構要素組織形成DST,再將DST利用“發(fā)文機關”建立文檔關聯(lián),最后存儲至Neo4j數(shù)據(jù)庫中,得到了如圖6所示的結構化文檔知識網(wǎng)絡。該網(wǎng)絡共包含22 377個節(jié)點(要素實體), 22 621條邊(要素實體間關系)。 利用圖數(shù)據(jù)庫管理系統(tǒng),可以對構建的結構化知識網(wǎng)絡進行管理。例如,用戶使用Cypher語句: MATCH (:發(fā)文機關{name:“科技部”}) RETURN 其中,為“發(fā)文機關”。即可查詢到圖7所示的共33篇科技部發(fā)文。類似地,利用Neo4j等圖數(shù)據(jù)庫管理系統(tǒng),可以通過創(chuàng)建、刪除、合并實體和關系等操作,實現(xiàn)對結構化知識網(wǎng)絡中結構要素實體以及它們之間關系的管理。 圖6 大規(guī)模DSTs構建的文檔網(wǎng)絡Fig.6 Document network built from large scale DSTs 圖7 以“科技部”為關鍵詞檢索到的文檔Fig.7 Documents retrieved with the keyword “Ministry of Science and Technology” 綜上所述,本文通過對文檔知識結構要素的抽取、組織和管理設計并進行實驗,證明了本文提出的多模態(tài)抽取方法的有效性;通過構建公文文檔的結構化知識網(wǎng)絡,分析了本文提出的DST模型在知識組織和管理方面進行應用的可行性和有效性。 本文以公文為例,提出了從多模態(tài)文檔中抽取知識結構要素并組織生成結構化知識圖的方法。在文本模態(tài),本文針對公文文檔的擬制標準和行文特點,提出了公文知識結構要素的抽取規(guī)則,實現(xiàn)了對公文文檔中知識結構要素的抽取。在圖像模態(tài),本文利用目標檢測和OCR方法,對基于規(guī)則抽取方法的短板弱項進行補足。同時,本文提出了一個多模態(tài)文檔知識要素抽取框架,利用決策表實現(xiàn)多模態(tài)知識結構要素抽取結果的擇優(yōu)。經(jīng)實驗驗證,多模態(tài)抽取方法在1分數(shù)上從單一模態(tài)的0.835 0和0.834 7提升到了0.943 0。同時,本文提出了DST模型,按照文檔的結構邏輯實現(xiàn)了對知識結構要素的組織,并將得到的結構化文檔輸入圖數(shù)據(jù)庫進行管理。實驗結果證明,本文提出的知識結構要素抽取與組織方法具有良好的效果表現(xiàn),在解決目前基于三元組知識構建的知識網(wǎng)絡結構邏輯性弱的問題,以及文檔智能問答、公文自動化管理等方面具有重要的研究和應用價值。1.2 圖像模態(tài)的知識結構要素抽取
1.3 多模態(tài)知識結構要素抽取
2 公文知識結構要素的組織
2.1 公文知識結構要素組織問題分析
2.2 公文知識結構要素組織的數(shù)學模型
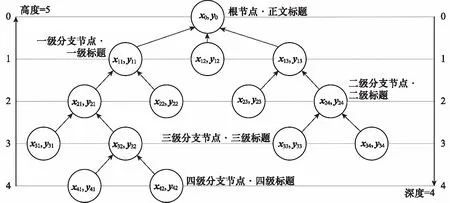
2.3 公文知識結構要素組織的數(shù)據(jù)結構
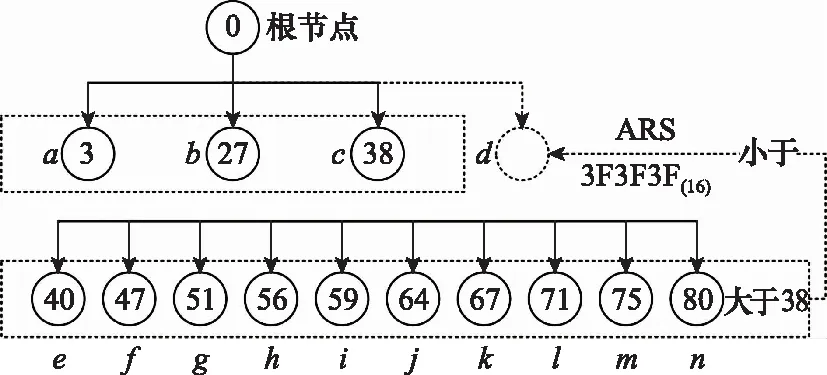
3 多模態(tài)公文數(shù)據(jù)集構建


4 實驗與分析
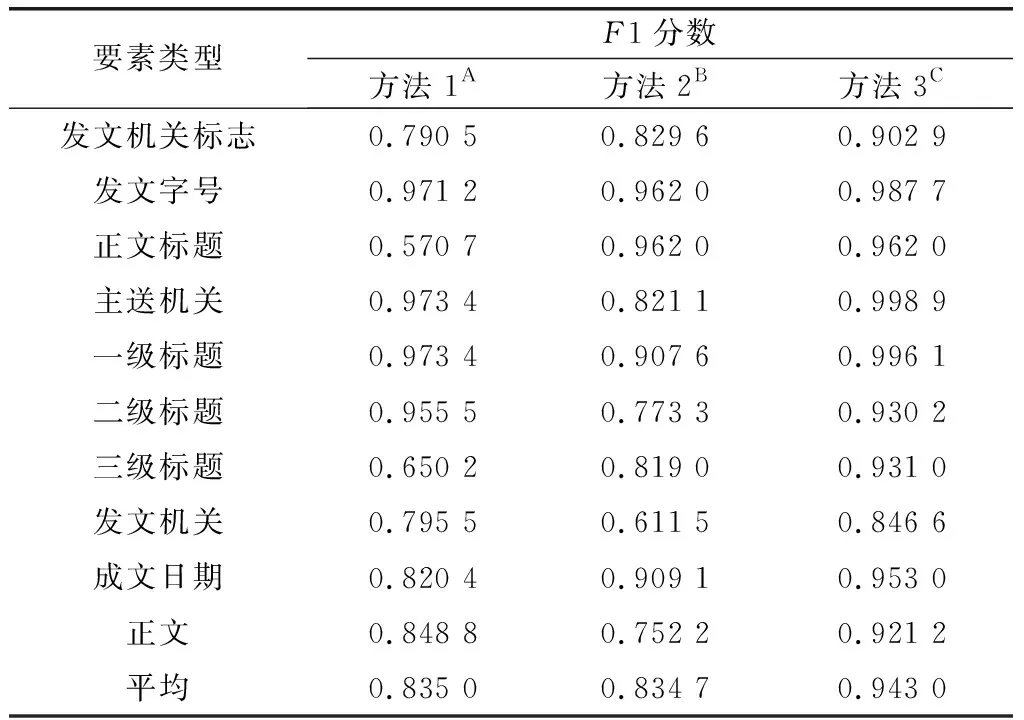
4.1 公文知識結構要素抽取
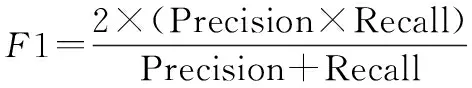
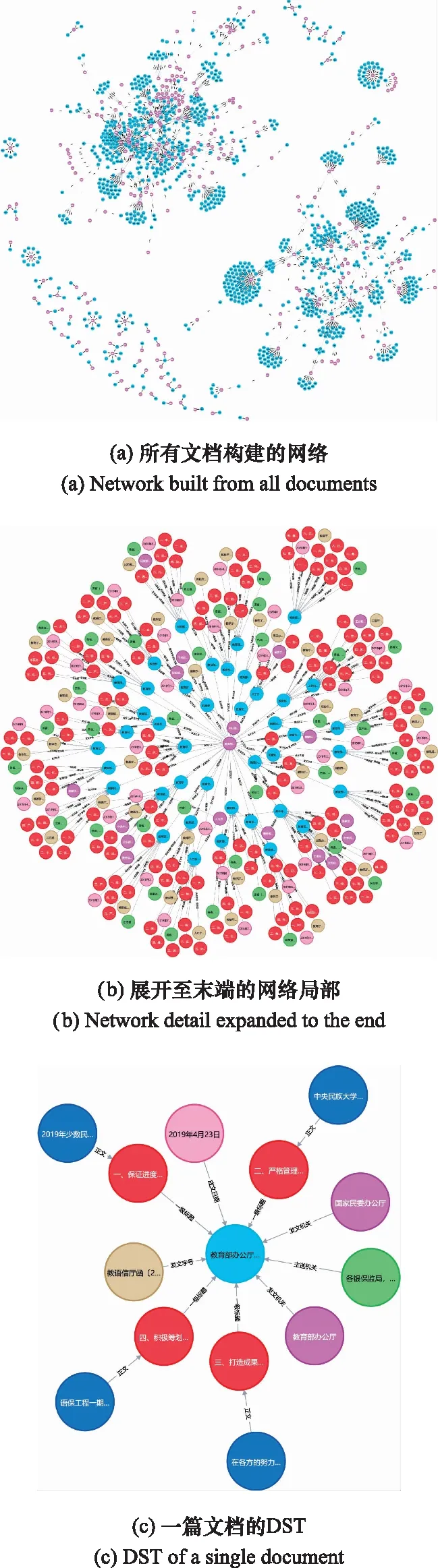
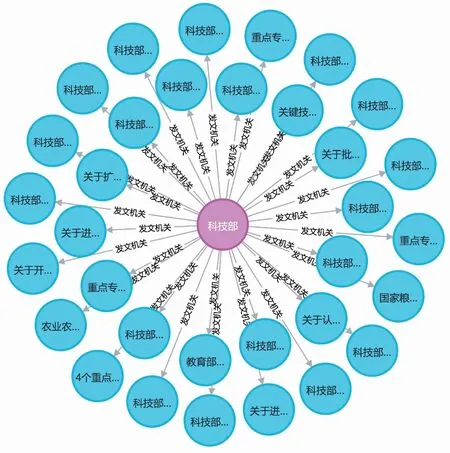
4.2 公文知識結構要素的組織與管理
5 結 論
猜你喜歡
制造技術與機床(2019年10期)2019-10-26 02:48:08電子制作(2018年18期)2018-11-14 01:48:06Coco薇(2016年2期)2016-03-22 02:42:52小學教學參考(2015年20期)2016-01-15 08:44:38湖北經(jīng)濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年4期)2015-05-19 14:47:56上海電機學院學報(2015年4期)2015-02-28 14:30:00計算物理(2014年2期)2014-03-11 17:01:39語文知識(2014年1期)2014-02-28 21:59:13
