基于偏移最小和的LDPC譯碼改進算法
2022-06-25 13:16:14陳發堂李賀賓李平安
系統工程與電子技術 2022年7期
陳發堂, 李賀賓, 李平安
(重慶郵電大學通信與信息工程學院, 重慶 400065)
scheduling
0 引 言
低密度奇偶校驗碼(low density paritycheck, LDPC)是1963年由Gallarger提出[1],后又被MacKay和Neal研究的線性分組碼[2]。LDPC碼的校驗矩陣具有稀疏特性,其碼長與復雜度呈線性關系,當碼長足夠長時,其性能可以接近理論香農極限[3],目前已經被多種通信標準所采用[4-6]。
LDPC碼可以使用消息傳遞性算法迭代譯碼,該算法可以被分類為最優、準最優和次優。最優迭代譯碼由置信傳播(belief propagation, BP)算法[7-8]執行,代價是復雜度增加、計算不穩定以及對熱噪聲估計誤差的依賴。最小和(min-sum, MS)算法[9]執行次優迭代譯碼,比BP算法簡單,并且獨立于熱噪聲估計誤差。MS算法的次優性是由于對校驗節點消息的高估,造成了譯碼性能的損失。為了恢復MS算法相對于BP算法的性能損失,學者們提出了不同的優化算法,稱這種算法為準最優算法。準最優算法的性能既非常接近BP算法,同時又保留了MS算法的主要特征,即低復雜度和相對于噪聲方差估計的獨立性。最基本的校正優化算法是歸一化最小和(normalized min-sum,NMS)算法和偏移最小和(offset min-sum,OMS)算法,分別通過引入歸一化因子和偏移因子來修正校驗節點消息的幅度,提高譯碼性能[10-11]。文獻[12]利用參數估計理論對MS算法進行改進,使用文獻[13]中的線性最小均方誤差(linear minimum mean square error,LMMSE)準則提出LMMSE-MS算法,該算法使用黃金分割搜索算法對參數進行優化,在增加少量復雜度的情況下,提高譯碼性能。文獻[14]在OMS算法的基礎上,提出了一種基于新型偏移因子的MS(new offset min-sum,NOMS)算法,該偏移因子通過最小均方誤差估計過程公式化,然后通過優化均方誤差獲得最優的偏移因子值,使用該偏移因子可以提高算法的譯碼性能和收斂速度。文獻[15]在NMS算法的基礎上,提出了基于密度進化(density evolution,DE)理論[16]的DE-NMS算法,該算法通過密度進化理論求出歸一化因子序列,通過對歸一化因子序列做加權平均處理得到更精確的歸一化因子以提高譯碼算法的譯碼性能。
雖然以上優化算法都提高了譯碼性能,但在校驗節點的更新過程中沒有考慮第一最小值和第二最小值的區別。因此,譯碼性能有待進一步提高。本文在OMS算法的基礎上提出了一種基于次序統計量的OMS(order statistics OMS, OR-OMS)算法,使用兩個不同的偏移因子分別對第一最小值和第二最小值進行修正,利用次序統計量理論推導出兩個偏移因子的值,并且使用分層調度的消息傳遞方式。仿真結果表明所提算法與其他改進的MS算法相比,擁有更好的譯碼性能和收斂速度。
1 BP算法及其改進算法
令H=[hmn]為LDPC碼的校驗矩陣,ρ和γ分別為其行重和列重。變量節點集合N(m)={n:hmn=1}代表校驗矩陣第m行中所有的非0元素;校驗節點集合M(n)={m:hmn=1}代表校驗矩陣第n列中所有的非0元素;N(m) 定義為集合N(m)中除了第n個元素以外的所有元素;M(n)m定義為集合M(n)中除了第m個元素以外的所有元素。令c={c0,c1,…,cN}為經過編碼后的二進制LDPC碼字,經過BPSK調制后得到傳輸序列x={x0,x1,…,xN},其中xn=1-2cn(n=1,2,…,N)。傳輸序列經過加性高斯白噪聲(additive white Guassian noise, AWGN)信道傳輸后得到接收序列y={y0,y1,…,yN},其中yn=xn+vn,vn為均值為0、方差為N0/2的高斯白噪聲。
1.1 BP算法
BP譯碼算法的譯碼過程以校驗矩陣H為基礎,校驗矩陣中的每一個非0元素在Tanner圖[17]中分別代表一條邊,對數似然比(log likelihood ratio,LLR)消息沿著Tanner圖中的邊在變量節點和校驗節點之間進行迭代。在每一次迭代的過程中,首先將變量節點消息傳遞給校驗節點并更新校驗節點消息,然后將更新后的校驗節點消息傳遞給變量節點更新變量節點消息,接著進行下一次迭代,直到達到最大迭代次數或者得到正確碼字。BP算法譯碼過程如下。
(1)初始化
將校驗矩陣中每一個非0元素hmn對應的變量節點消息Zmn初始化為接收到的信道消息:
(1)
(2)迭代處理
步驟 1校驗節點消息更新(C2V)
(2)
式中:i為第i次迭代過程。
步驟 2變量節點消息更新(V2C)
(3)
步驟 3譯碼判決
(4)
硬判決規則
(5)
(3)終止準則
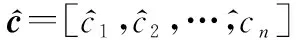
1.2 MS算法
BP算法是一種理想算法,在實現過程中有兩個難點:一是在式(1)中,噪聲方差應該是已知的,但是在實際應用中很難估計噪聲的精確值,尤其是當信噪比比較低時,噪聲估計的偏差將極大地惡化譯碼性能。二是式(2)的計算過于復雜,不利于硬件實現。
針對第二個問題提出了MS算法,其C2V過程簡化為
(6)
MS算法將C2V過程中的非線性計算修改為比較過程,計算復雜度大大降低。
1.3 OMS算法
雖然MS算法降低了譯碼復雜度,但在C2V過程中擴大了校驗節點消息的幅度值,導致譯碼性能損失。OMS算法通過使用偏移因子對式(6)的結果進行修正,其C2V為
(7)
偏移因子可以通過下式獲得:
β=E(|L2|)-E(|L1|)
(8)

2 提出的OR-OMS算法
2.1 次序統計量理論
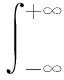
設X1,X2,…,XN為N個獨立、同分布的隨機變量,概率密度函數(probability density function, PDF)為f(x),累積分布函數(cumulative distribution function, CDF)為F(x)。通過遞增的順序排列這些變量,獲取相應的次序統計量排序后的結果記為X1:N,X2:N,…,XN:N,其中X1:N為最小值,XN:N為最大值[18]。X1:N,X2:N,…,XN:N中第i個次序統計量Xi:N的PDF為
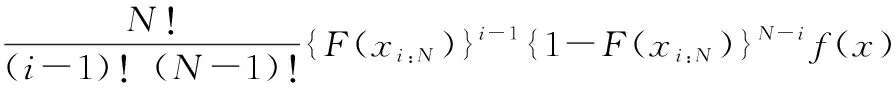
(9)
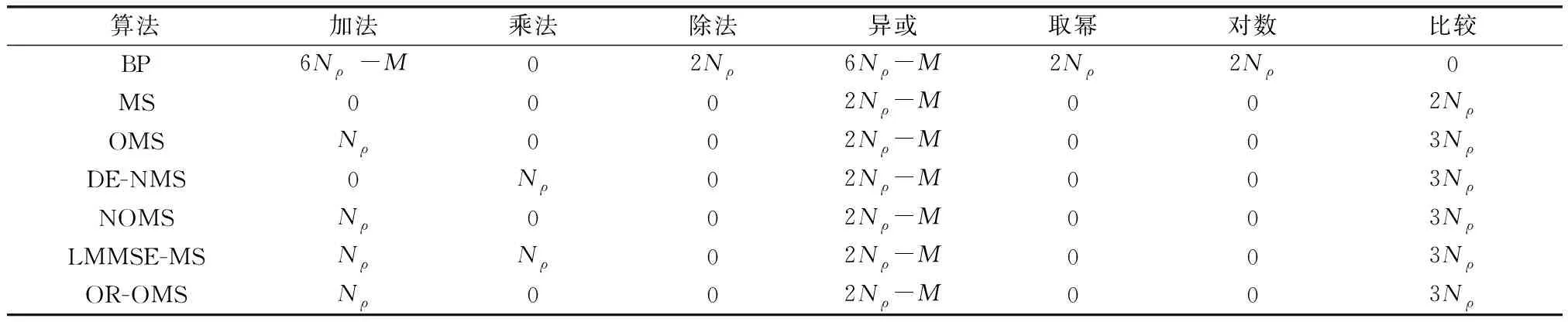
Xi1:N,Xi2:N,…,Xik:N(1≤i1 (10) (11) (12) 式中:β1和β2分別為第一最小值偏移因子和第二最小值偏移因子;L21和L11是在n≠index的情況下分別通過式(11)和式(2)獲取;L22和L12是在n=index的情況下分別通過式(11)和式(2)獲取。 (13) Xi的CDF為 (14) 根據式(9),集合{Xi}的第一最小值的PDF為 fX1:ρ(x1:ρ)=ρ(1-FXi(x1:ρ))ρ-1fXi(x1:ρ) (15) 集合{Xi}的第二最小值的PDF為 fX2:ρ(x2:ρ)=ρ(ρ-1)FXi(x2:ρ)(1-FXi(x2:ρ))ρ-2fXi(x2:ρ) (16) 因此,E(|L21|)和E(|L22|)的計算公式為 (17) (18) 在給定信噪比Eb/N0和碼率的情況下,根據式(17)和式(18)可以求出E(|L21|)和E(|L22|)的值。同時可以得到E(|L2|)的表達式為 E(|L2|)=pE(|L21|)+(1-p)E(|L22|) (19) 式中:p為變量Xi為集合N(m)第一最小值的概率,p=1/ρ。 接下來開始推導E(|L11|)和E(|L12|)的表達式,當n=index時,根據式(2)可知L12的表達式為 (20) (21) 由式(21)可以得到E(|L12|)的表達式為 (22) 很明顯可以看出,式(22)只適用于ρ值較小的情況,當ρ值過大時,計算過于復雜,很難計算出實際值。此處可以借助大數定理[19]對E(|L12|)的值進行估計,大數定理的定義如下: (23) 根據上述定理,可以證明當重復次數非常大時,|L12|的平均值最終會收斂于E(|L12|)。由此可以得出E(|L12|)具體估計過程如下: 步驟 1生成一組滿足式(14)分布的隨機變量X1,X2,…,Xn。 步驟 2找出這組隨機序列的最小值Xmin。 步驟 3通過式(20)計算L12。 步驟 4重復上述過程,直至達到最大重復次數。 步驟 5計算E(|L12|)的值。 在實際應用中,當ρ值較小時可以使用式(22)計算E(|L12|)的值;當ρ值較大時,通過大數定理估計出E(|L12|)的值。 對于E(|L11|)的計算,如果通過次序統計量進行推導,從E(|L12|)的計算可以看出,E(|L11|)的計算會更加復雜。可以通過E(|L1|)、E(|L12|)對E(|L11|)進行求解,由式(19)可以得出 E(|L1|)=pE(|L11|)+(1-p)E(|L12|) (24) (25) 由式(24)和式(25)可知,只要計算出E(|L1|)就可以得到E(|L11|),根據式(2)可以得到E(|L1|)的計算公式如下: (26) 為了方便計算E(|L1|),定義 (27) 由泰勒級數可知 (28) 因為式(28)中α,α3,α5,…符號相同,所以 (29) 令μk=E(|α|k),因為{Xi}為獨立、同分布,所以 (30) 通過式(13)和式(30)可以計算出對應的μk,由式(29)可知 (31) 一般取式(31)的前幾項就可以估算出E(|L1|)的值,然后通過式(25)可以計算出E(|L11|)的值,進而可以求出最優的β1和β2的值。校驗節點消息更新由式(7)可以優化為 (32) 傳統OMS算法的消息傳遞采用洪泛(flooding)調度[20]方式,所有校驗節點和變量節點消息并行傳播,每次迭代更新的外部消息只能用于下一次迭代過程,外部消息利用率低。為了充分利用新產生的外部消息,提出的OR-OMS算法采用分層調度[20]的消息傳遞方式,在迭代的過程中一次只更新一個校驗節點消息,然后將新產生的校驗節點消息傳遞給與它關聯的變量節點。文獻[21]已經證明分層調度相比于洪泛調度收斂速度提升一倍,并且沒有增加復雜度。 針對OR-OMS算法設計了合適的分層譯碼結構,如圖1所示。圖中FIFO代表先入先出(first input first output)。 首先將每一層的V2C消息并存于FIFO,并且將V2C消息的符號進行存儲。然后對于校驗節點,篩選出V2C消息的第一最小值和第二最小值及其索引,并將它們輸入到C2V selector中更新校驗節點信息。最后通過更新后的校驗節點信息生成判決消息,同時將更新后的校驗節點信息存儲在C2V registers中,此時完成了一層的譯碼。由上可知該譯碼器結構不需要為判決消息分配內存空間,并且在V2C消息更新的過程中,可以直接使用C2V registers中的校驗節點信息和V2C Sign FIFO中的符號值進行計算,避免對校驗節點進行多次計算,降低了計算復雜度。OR-OMS算法具體流程如算法1所示。 算法 1 OR-OMS算法1:初始化所有L0mn=0,Z0mn=Z0n and Imax2:for m=1:M3: for every n∈N(m)4: 使用式(32)計算Limn5: end for6: for every n∈N(m)7: 使用式(3)計算Zimn8: 使用式(4)計算Zin9: end for10:end for11:通過式(5)得到硬判決譯碼結果c^=[c^1,c^2,…,c^n]12:ifA·c^T=0 or i=Imax13: 輸出譯碼結果c^=[c^1,c^2,…,c^n]14:else15: 返回到步驟216:end if 本次仿真使用5G NR標準中的準循環LDPC(quasi-cyclic LDPC, QC-LDPC)碼[22],并在Matlab平臺通過模擬AWGN信道,使用二進制相移鍵控(binary phase shift keying, BPSK)調制方式進行傳輸。通過大量的仿真對所提出的OR-OMS算法性能進行評估,并將它與BP算法、MS算法、OMS算法、LMMSE-MS算法、NOMS算法、和DE-NMS算法的性能進行比較分析。 圖2和圖3為各譯碼算法在不同信噪比下的誤碼性能對比,圖2使用的是基圖1情況下的(2 176,704)QC-LDPC碼,偏移因子β1和β2分別為0.304和0.373,最大迭代次數設置為20。 從圖2中可以看出,OR-OMS算法、LMMSE-MS算法、NOMS算法、DE-NMS算法4種基于MS算法改進的譯碼算法相對于OMS算法性能都有明顯的提升,其中OR-OMS算法和LMMSE-MS算法的譯碼性能優于NOMS算法和DE-NMS算法,但OR-OMS算法的性能更加接近于BP算法。圖3使用的是基圖2情況下的(3 328,640)QC-LDPC碼,偏移因子β1和β2分別為0.326和0.389,最大迭代次數設置為20。 從圖3中可以看出,各譯碼算法的譯碼性能相對于圖2都有所提升,并且分布趨勢基本相同,所提出的OR-OMS算法譯碼性能更加優于LMMSE-MS算法。從圖2和圖3可以看出在誤比特率為10-5時,OR-OMS算法與OMS算法相比可以獲得約0.35 dB左右的增益。 基于MS算法改進的OMS算法、DE-NMS算法、NOMS算法、LMMSE-MS算法、OR-OMS算法本質上還是MS算法。主要的區別在于OMS算法通過蒙特卡羅方法計算偏移因子的最優值。DE-NMS算法通過DE理論推導出最優偏移因子值。NOMS算法通過最小均方誤差估計將偏移因子公式化,然后通過優化均方誤差獲得最優的偏移因子值。LMMSE-MS算法通過利用最小均方誤差估計準則對校驗變量信息的大小進行建模并計算估計參數,進而利用黃金分割搜索算法確定最優參數值。OR-OMS算法則通過次序統計量理論推導出第一最小值和第二最小值分別對應的最優偏移因子值。 表1為一次迭代過程中,各算法校驗節點更新所需的計算復雜度。Nρ為校驗矩陣中元素‘1’的總個數,M為校驗矩陣的列數。從表中可以看出,BP的復雜度最高,MS算法的復雜度最低。由于在硬件實現的過程中,偏移因子的值先通過Matlab工具計算,再存儲到硬件中。因此,OMS算法、DE-NMS算法、NOMS算法、OR-OMS算法的復雜度相同,LMMSE-MS算法的復雜度略高于這些算法。 表1 一次迭代過程校驗節點更新計算復雜度 在硬件實現的過程中,算法的整體復雜度不僅與單次迭代過程中校驗節點更新的復雜度有關,還和算法總的迭代次數有關。圖4為各算法在不同信噪比下的平均迭代次數。 由于OR-OMS算法采用分層調度的信息傳遞方式,從圖4中可以明顯看出,OR-OMS算法的收斂性能最好,所需的平均迭代次數最少,其次為BP算法、OMS算法、DE-NMS算法、NOMS算法、LMMSE-MS算法的收斂性能近似,MS算法的收斂性能最差。結合單次迭代過程中校驗節點更新所需的計算復雜度,可以得出在實際應用過程中,所提出的OR-OMS算法總體上來說要擁有更低的復雜度,具有實際應用價值。 本文提出了一種改進的OMS算法,所提算法針對校驗節點更新過程中第一最小值和第二最小值的問題,分別使用兩個不同的偏移因子對第一最小值和第二最小值進行校正,利用次序統計量理論推導出兩個偏移因子的最優值,提高譯碼算法的譯碼性能。所提算法使用分層調度的消息傳遞方式,擁有更快的收斂速度。仿真結果表明,對于5G NR標準的QC-LDPC碼,所提算法相比OMS算法擁有更好的譯碼性能,并且降低了譯碼迭代次數;與目前譯碼性能最好的LMMSE算法相比,在具有相似譯碼性能的情況下,擁有更低的計算復雜度。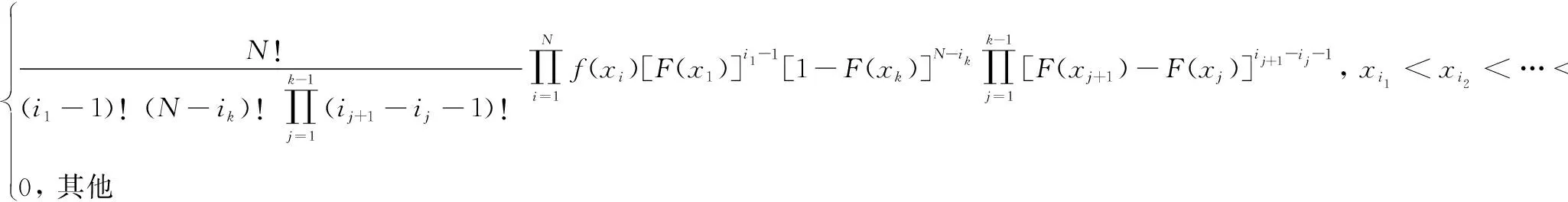
2.2 OMS算法分析
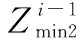
2.3 最優β1和β2值計算



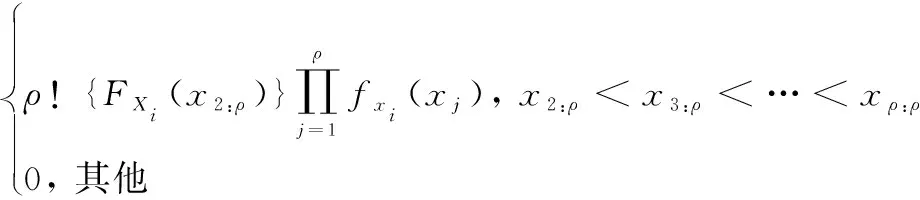
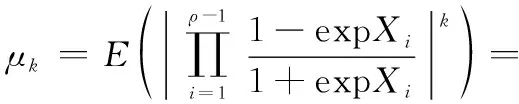
2.4 分層譯碼結構

3 仿真分析
4 復雜度分析
5 結 論
