輔助聽障人士的一種手語轉情感語音工具的設計
2022-07-02 12:23:13顧穎許琪毛貝思林巧民
電腦知識與技術 2022年15期
關鍵詞:機器視覺
顧穎 許琪 毛貝思 林巧民
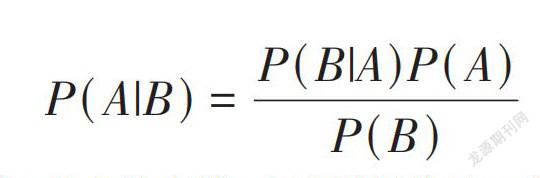
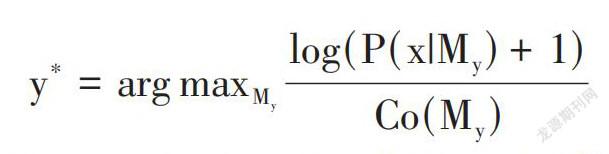
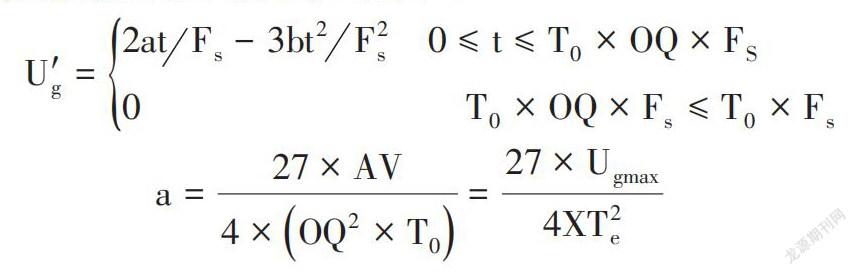


摘要:手語是聽障人士與外界溝通交流的橋梁,如何幫助聽障人士帶有情感地與健聽人正常交流,是當下社會需要解決的問題。輔助聽障人士的一種手語轉情感語音的交流工具,涉及手語識別、表情情感計算、語音情感合成等技術領域,基于機器視覺、動態貝葉斯網絡、共振峰合成法等知識,能夠實現手語同傳、雙向交互、情感表達等目的。文章研究能夠應用在手機上的軟件,方便用戶隨身攜帶,實現由手語轉換成情感語音,改善聽障人士與正常人直接的溝通交流方式。
關鍵詞:情感計算;機器視覺;表情情感識別;語音情感合成;聽障人士
中圖分類號:TP391? ? ? 文獻標識碼:A
文章編號:1009-3044(2022)15-0072-03
1 引言
隨著現代人機交互系統的迅速發展,關于“情感計算”的研究也日益引起了人們的興趣關注[1],并且已經在面部表情、姿勢改變、語言理解等方面取得了相當的進步[2]。聽障人士作為社會特殊群體在語言表達方面存在缺憾,不能夠準確地表達出其及時的想法和情感,而現在市面上的手語翻譯僅僅以中性的語調,將手語翻譯成語言,不能夠充分地表達出聽障人士的情緒變化。
項目旨在研究輔助聽障人士的一種手語轉情感語音交流工具的設計,將該模型集成在手機App上,方便用戶隨身攜帶。利用機器視覺、表情情感計算、語音情感合成等技術,幫助其更加快捷、高效地與正常人搭建友好的溝通平臺。
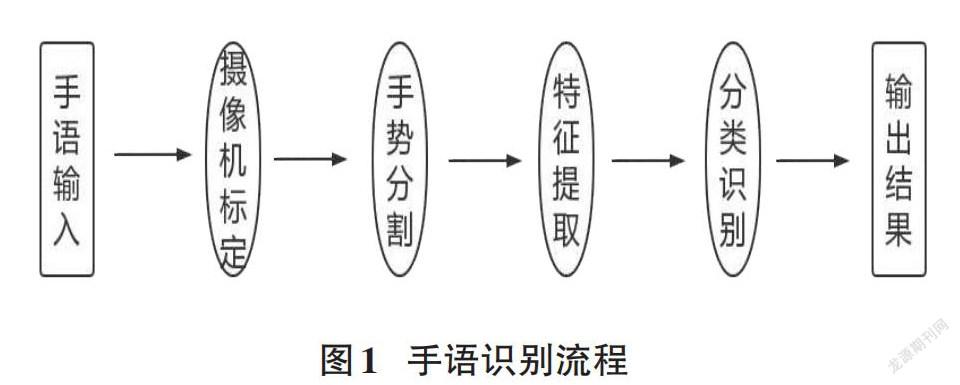
2 手語識別技術
手語識別技術是把聽障人士的手語通過電腦裝置辨識,并翻譯成漢語,它涉及圖像識別、語言分析等多個領域。在視頻中,聽障人士揮手的速度、頻率和幅度、手形的變化和其他相關信息,這些信息的處理和識別對計算機硬件設備有著嚴苛的要求。因此電腦視覺[3]也是手語識別技術中相當主要而且重要的技術手段之一。伴隨近些年來人工智能和計算機科學的蓬勃興起,其也隨之蒸蒸日上。而與此同時,手語識別技術也獲得了來自國外更多的重視。手語圖像識別技術,按照其對識別聽障人士手語的特點處理,可以分成兩種:其一是基于傳統方法的手語識別技術;其二是基于深度學習的手語識別技術[4]。這里采用第一種方法。
1)相機標定:空間中的對象由攝像設備所拍攝的圖片還原而成。假設線性關系存在于三維空間中的實體對象與圖像之間,存在著:[像]=M[物],矩陣M也可認為是攝像機成像的幾何模式,M中的基本參數也就是攝像機基本參數[5]。它利用攝像機標定原理,大大提高了計算機視覺的魯棒性。
2)手勢圖像分割:在處理圖像的過程中,要將目標圖像分割開來,提取其中有價值的那一部分,提供給系統,進行后面的操作。
3)特征提取:在這個階段,數據量通常很小,利用合適的算法對圖片進行二值化處理,從而得到一個僅突出手語信息的單一圖片。
4)手勢估計:采用水平集算法及其改進的分割圖像,以合適的模型提取和跟蹤手部輪廓,采用mean-shift算法跟蹤輪廓內外的圖像特征分布。
5)手勢行為識別:在現有的手語數據庫中,運用適合的分類器對聽障人士的手勢進行識別,以提高識別程度[6]。
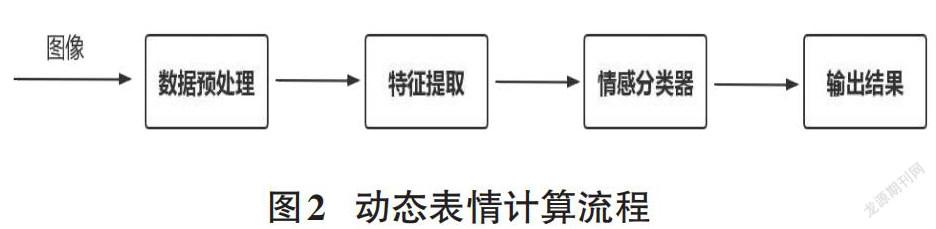
3 動態表情計算技術
世界名著《人與動物情感的表達》中有述,人類臉部表情可以使人形成不同于其他哺乳動物的更高等生物,也成為人們之間可以更有情感地交流溝通的最主要介質[7],在情感計算中,表情識別是一個人機交互研究中重要的方法,是情感計算研究中的基礎。于是,大批研究者都投入到面部表情情感認知研究的隊伍當中。當對人們的情感加以研究時,表情始終是人類情感識別中最主要的特點之一。
簡單的動作表情情感辨識過程,通常包括三部分:數據預處理、情感特征提取、動作表情信息辨識。
1)表情數據預處理、情感提取及情感分類器
對表情數據的預處理是進行情感識別的首要步驟,由于圖像中有太多不相關的背景或物體噪聲,這種干擾條件會直接影響情感識別的有效性。當提供情感特征時,并不能提供有用的情感信息,可能會產生負面影響。如果只想獲得人臉表情的特點或掩蓋背景信息,那么需要檢查每一幀圖片中的人臉信息,并在這些人臉信息中獲得特點。結合人臉對齊操作、高斯模糊、圖像紋理合成與高維隱空間向特征編碼等技術操作,對所采集的表情數據,進行去噪、去除敏感信號等工作處理[8],去掉多余的信息從而關注于最關鍵的特征。
特征提取的目的是獲得能夠表示圖像特征的屬性信息。人臉對表情有關的特征主要來源于人的五官肌肉變化。例如當一個人處于比較開心的時候,就會產生眉宇舒展、臥蠶突顯、嘴角上揚等一系列的動作;當一個人憤怒的時候,會產生眼睛瞪大、眉毛有豎紋等一系列特征。
目前常見的表情特征提取方式主要有三類:基于圖像幾何特性的方法、基于整體統計特性的方法以及基于頻域特性的方式方法[9]。這里,選取了基于圖像或幾何特性的方式:通過定位并檢測人眼、眉毛、嘴巴等器官,比較它們的大小、距離、形狀等表情元素特征,從而識別人臉表情。
人臉表情分類器的主要功用,是通過人臉特征把圖片分類到相應的表情分類中去,利用適當的分類算法識別表情,對其歸類。動態建模依賴于整體像素序列,人們能夠利用研究臉部肌肉的時間變化動態,并運用動態貝葉斯網絡。
2)貝葉斯網絡及結構
每個人表情情緒的表現,都是由一段時間內面部肌肉運動改變所形成的,也因為這種不同的變化運動會形成不同的表情。所以,在動態表情計算中,對面部肌肉之間的運動變化關系識別是很重要的。
貝葉斯網絡也就是貝葉斯公式為基本的,貝葉斯公式還包括:
[P(A|B)=P(B|A)P(A)P(B)]
為了識別N種人的表情,在這里創建了N個區間的代數貝葉斯網絡,使每一種情緒表情對應一種貝葉斯網絡,在這里,每一種實體節點都代表著一種最基本的情緒運動。關于一個采樣x,[My]就是指情緒表情y的貝葉斯網絡模型,這樣情緒表情可以由以下公式來運算得到[10]。因為不同的貝葉斯網絡可能會有不同的結構,因此需要除以模型的復雜度來加以平衡。因此,可以將模型的連線數量視為模型的復雜性,并最終選出了相似量最大的貝葉斯網絡模型[11]。
[y*=arg maxMylog(P(x|My)+1)Co(My)]
在這里,運用一種特殊的貝葉斯網(區間代數貝葉斯網絡)可以進行人臉表情建模,這樣可以把貝葉斯網的概括語義與區間代數的時序性組合起來,能夠捕捉臉部的復雜多變運動變化關系,通過這個方式可以利用基于跟蹤的特性,可提高識別的速度[12]。
4 語音情感合成技術
如果機器的語言不再生硬晦澀難懂,毫無情感語調,而是富有人的語調跟情感,這會是一個巨大的進步在語音交互的領域,這項非常重要的技術應用在日常生活中,代表這項技術不斷發展與進步,人們對情感語音的合成的期待與要求也越來越嚴苛,App基于這些技術更好地將文字與語音相結合。
1)情感語音合成
情感語音合成這個技術在很多領域都是非常重要的,比如語音識別、語音合成等,語音合成顧名思義就是將現有的文字通過語音合成技術變成語音輸出即聲音的形式,通過語音合成技術把文字變成另一種載體:聲音。語音的合成的歷史是從1980年到現在這個階段,技術由簡到繁,更新數據也極快,但是在初期由于技術的限制,在技術合成的方面不會有太高的要求,大多以穩定為標準,這也是語音合成偏向機器語調的原因,并且情感表達的功能也不太完善,所以希望出現一款App能與人類的交流可以自然流暢,它具有人類的情感可以與幫助聽障人士用開心的語調、生氣的語調、疑惑的語調等等,并且富有人類情感程度的復雜性。這樣就可以通過情感語音合成技術讓聽障人士能夠自由并富有感情地跟正常人交流。
2)文字信息與語音信息的轉換
語音合成顧名思義是人為制作的聲音,由手語識別技術得到聽障人士表達中的文字內容,聲音的合成是人機交互中最重要的一個關鍵點,聲音合成技術就是對文本內容的語音描述。
信息轉換過程:
①通過手語識別技術來建模:語言模型,使手語視頻翻譯成文字,可以利用機器視覺將已識別的手勢庫與相符合的圖像,再跟語音庫中對應的情感相結合。
②使用編碼器與譯碼器搭建交互的平臺,可利用FPGA等平臺進行搭建。
③在交互平臺完成手勢識別后,應用遞歸與二分等算法(GRAM)將二維信號矩陣傳入語音系統,并實現輸出的結果。
④語音識別輸出,利用交互平臺,由編碼器與譯碼器轉化的二進制的代碼,通過單片機等設備,對手語識別得到的文本內容實現語音的輸出。
3)情感語音合成的技術實現
情感語音技術的實現其一是通過將情感信息編碼到語言中去,這樣App在合成機器語音時就可以同時識別出語言載體的信息與情感的信息;其二就是先合成一個中性的語調,然后利用聲音的轉換技術,得到情感表達的需求。這里采用共振峰合成法。
共振峰合成法擁有另一個名稱亦基于規則的合成,這個方法主要是依據自然的語音及語調及聲學中與之相對應的規則,在這兩個方面的基礎上合成的,在語音合成的過程中是完全沒有采用真人的語音,利用共振峰合成法可以讓語音輸出的結果更像真人的語音語調,更加流暢與自然,而且共振峰合成法有一個特點就是其具備高度的可控性,它可以極為方便地調控,可以人為控制參數。利用這個方法合成了著名的語音情感合成器——Affect Editor情感語音合成器。
聲源模式的選擇,濁擦聲源使用了經時間脈沖機制處理后產生的噪音,但濁音聲源模式選擇使用了KLGOTT88。濁齒音聲源的波浪狀信號[Ugt]是由下面的函數得到(Te表示聲門處開相位時長,a決定聲援波峰,OQ是聲門信號開相位寬度)[13]。
[Ugt=t2-t3OQ100×Te]
考慮到輻射的特性,通過集成于聲源模型,使用了聲源門波譜的極微分形式,如下式所示:
[U'g=2atFs-3bt2F2s? ? ?0≤t≤T0×OQ×FS0? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?T0×OQ×Fs≤T0×Fs]
[a=27×AV4×OQ2×T0=27×Ugmax4XT2e]
最大的過程為流Ugmax可由下式計算(Fs是采樣率,AV是幅度參數,T0是基音周期)就是通過參數來判斷的源信號波形。
[b=27×AV4×OQ3×T0=aTe]
在聲道模型中,揚聲器模擬的聲道模擬,是用共振峰合成技術將揚聲器分解成諧振腔,諧振腔擁有無數個諧振頻率。不同頻率的共鳴峰的模式分別代表著兩種不同類型的音色音調,可以分別利用其共鳴峰頻譜長度及頻譜寬度來作為判斷依據來建立共鳴峰過濾器。再用若干個這種濾波器串聯起來以改善模擬聲道信號的傳輸特性。對于每個共振峰可以用另一種二階濾波器來進行濾波,如下式所示[14] (Fi為共振峰中心頻率,Bi為共振峰帶寬,T為采樣周期,幅度L=Fi∕Bi L) 。
[Ci=-exp-2πBiT]
[bi=2×exp-πBiTcos2πF?T]
[Gi=1-bi-Ci]
[Viz=Gi1-biz-1-c1z-2]
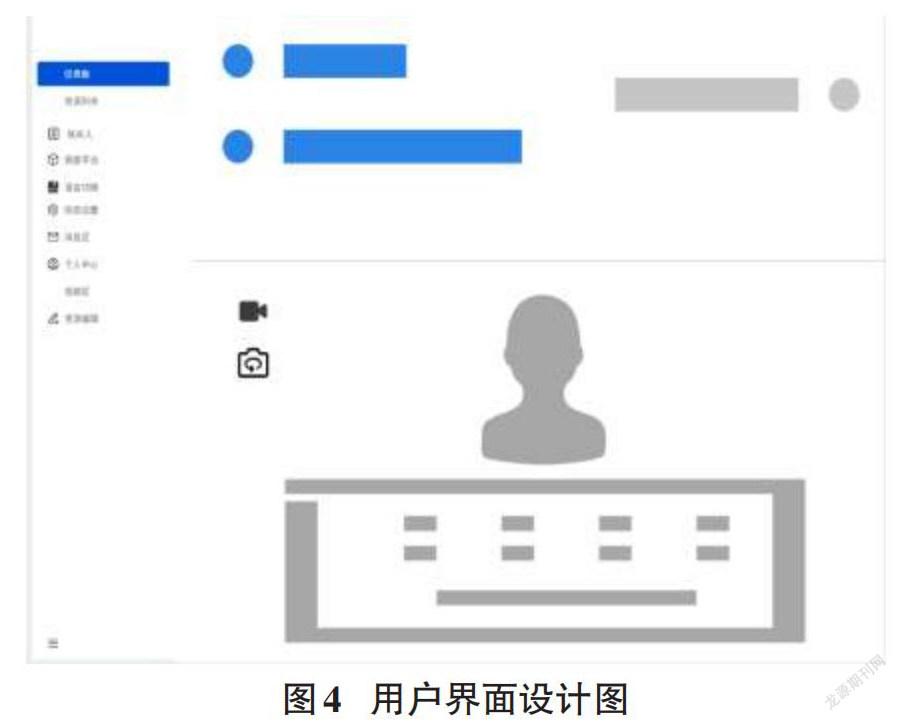
5 App設計模型構建
模型的構建主要基于機器視覺而行。利用貝葉斯網絡捕捉臉部的復雜多變運動變化關系,進而提高識別的速度;再運用共振峰合成法,使得語音合成后輸出的結果更加接近真人的語音語調,流暢自然。建立聽障人士不同情緒和合成語音的關系,通過一系列計算,完成信息輸出載體的轉換:由手語轉換成情感語音,實現語音輸出。
用戶界面模塊主要用于個人信息的設置,包括消息區、視頻區、個人中心、資料編輯和一些簡單功能的介紹,方便用戶上手操作。
6 總結與展望
目前,我國有聽力殘疾人口大約為二千零五十四萬人,占全球人口總數的百分之一點四六[15]。近年來,國家不斷推進助老助殘項目的發展,在我國的政策支持和社會大規模投入資金的大背景下,中國國內助老助殘創新服務項目大批出現,但目前市面上真正針對聽障人士適用的App幾乎很少。
輔助聽障人士的手語轉語音工具是基于iOS平臺,主要以服務聽障人士實現正常情感交流為基礎,為他們提供即時攝像,手語轉情感語音的服務。隨著互聯網和信息技術向著更加寬帶化的目標的進展,移動終端設備普及很快,逐漸地深入到人們日常生活的方方面面[16],人們對情感交流需求的日益增長,聽障人士對于手語翻譯的需求已經不僅僅是簡單的中性語調輸出,還需要加以更多的情感表達。而本文的科研方向恰恰彌補了聽障人士手語識別的部分市場缺口,發展前景巨大,值得深入研究。
參考文獻:
[1] 潘玉春,徐明星,賈培發.面向情感語音識別的建模方法研究[J].計算機科學,2007,34(1):163-165.
[2] 楊瑞請.基于BPSO的生理信號的情感狀態識別[D].重慶:西南大學,2008.
[3] 李杰,劉子龍.基于計算機視覺的無人機物體識別追蹤[J].軟件導刊,2020,19(1):21-24.
[4] 李云偉.基于深度學習的手語識別關鍵技術研究[D].徐州:中國礦業大學,2019.
[5] 楊文峰.光學定標算法抗噪性研究及改進[D].開封:河南大學,2017.
[6] 秦夢現.手語識別研究綜述[J].軟件導刊,2021,20(2):250-252.
[7] 馬銀蓉.基于表情、文本和語音的多模態情感識別[D].南京:南京郵電大學,2021.
[8] 王婧瑤,范飛,劉豪宇,等.基于機器視覺的聾啞人手語識別——語音交互系統[J].物聯網技術,2021,11(12):3-5.
[9] 王志良,陳鋒軍,薛為民.人臉表情識別方法綜述[J].計算機應用與軟件,2003,20(12):63-66.
[10] 邱玉,趙杰煜,汪燕芳.結合運動時序性的人臉表情識別方法[J].電子學報,2016,44(6):1307-1313.
[11] 邱玉.基于動態表情識別的情感計算技術[D].寧波:寧波大學,2015.
[12] 王琳琳,劉敬浩,付曉梅.融合局部特征與深度置信網絡的人臉表情識別[J].激光與光電子學進展,2018,55(1):204-212.
[13] 汪成亮,張玉維.基于共振峰合成和韻律調整的語音驗證碼方法研究[J].計算機應用研究,2011,28(7):2458-2461.
[14] 周自斌.基于互聯網的智能英語聽寫系統設計[J].安徽科技學院學報,2013,27(5):60-62.
[15] 鄭璇.加快推進中國手語翻譯的職業化——基于新型冠狀病毒肺炎疫情的思考[J].殘疾人研究,2020(1):24-32.
[16] 潘浩.基于微信小程序的智能配送系統的設計與實現[J].微型電腦應用,2019,35(7):31-33.
【通聯編輯:謝媛媛】
猜你喜歡
軟件導刊(2016年11期)2016-12-22 21:52:17
電腦知識與技術(2016年28期)2016-12-21 12:13:14
科技視界(2016年26期)2016-12-17 17:31:58
科技視界(2016年25期)2016-11-25 19:53:52
科技視界(2016年25期)2016-11-25 09:27:34
科教導刊(2016年25期)2016-11-15 17:53:37
軟件工程(2016年8期)2016-10-25 15:55:22
科技視界(2016年20期)2016-09-29 11:11:40
科技視界(2016年6期)2016-07-12 09:12:40
科技視界(2016年15期)2016-06-30 19:03:30
