基于異常檢測的產品表面缺陷檢測與分割
2022-07-03 04:21:46王素琴朱登明
圖學學報 2022年3期
王素琴,任 琪,石 敏,朱登明
基于異常檢測的產品表面缺陷檢測與分割
王素琴1,任 琪1,石 敏1,朱登明2,3
(1. 華北電力大學控制與計算機工程學院,北京 102206;2. 中國科學院計算技術研究所前瞻研究實驗室,北京 100190;3. 太倉中科信息技術研究院,江蘇 太倉 215400)
工業制造中缺陷樣本難以獲得且缺陷表現形式多樣,只用訓練正樣本的異常檢測技術越來越多地被應用于產品表面缺陷檢測。異常檢測一般通過評估產品圖像的異常分數對產品進行有無缺陷的判斷,缺乏對缺陷位置的描述,最新提出的異常分割方法對此進行了改進,但對缺陷區域的分割不夠精確。基于異常檢測方法,使用標準化流來判斷產品表面是否有缺陷,采用多尺度特征融合并對齊來初步定位缺陷位置,結合梯度和最大信息熵,使用分水嶺算法對初定位結果進行優化得到缺陷分割掩碼。在麗盛制板,KolektorSDD和AITEX 3個表面缺陷數據集的檢測與分割結果均優于其他同類方法。此外,在小樣本數據集上也能達到良好的檢測與分割精度。
異常檢測;缺陷分割;多尺度特征融合;特征對齊;分水嶺算法
工業生產中,產品表面質量事關產品性能及安全,因此,需要對其表面質量進行嚴格檢測。人工目視檢測被廣泛應用于表面缺陷檢測中,雖然可以憑借檢測員豐富的經驗對正常和異常零件做出精確判斷,但存在人工成本高昂和不同檢測員檢測標準有差異的局限性。因此,使用機器視覺方案解決表面缺陷檢測問題成為當前研究熱點。
傳統的機器視覺方案通常使用圖像濾波、邊緣提取、閾值分割和形態學處理等圖像處理算法以達到檢測表面缺陷的目的。此類方法雖然檢測速度快、準確性高,但對圖像的質量要求也很高。除此之外,傳統機器視覺圖像處理算法通常是針對某一特定數據集設計,普適性差。基于深度學習的方法學習圖像數據的通用特征表達,在缺陷分類和定位上取得了非常好的效果,越來越多地被應用于表面缺陷檢測領域。
有監督缺陷檢測方法憑借大量缺陷樣本,有效學習缺陷的特征表達,從而達到檢測要求,但實際生產中難以獲得缺陷樣本。此外,由于制造過程的不可預見性,新的缺陷類型隨時可能出現,面對新的、多樣化的缺陷,檢測標準和評估指標往往不同,需要耗費大量人力資源對訓練樣本進行標注以滿足有監督缺陷檢測的訓練需求,尤其是圖像分割的標注。
針對數據集中負樣本極少而正樣本多的問題,無監督方法只需要學習正樣本的特征表達,從而可以對測試樣本進行精確分類。基于無監督學習,BALDI[1]提出了一種異常檢測方法,訓練過程只需提供足夠的正樣本,無需提供缺陷樣本,且無需人工標注,即可達到有監督檢測的效果。異常檢測中常用的模型如變分自編碼器[2]和GANs[3]采用重建圖像的方式來檢測異常,其重心主要放在對圖像的分類問題上。僅僅對圖像做分類并不能直觀地展示缺陷在圖像中的位置及其特征。DifferNet[4]使用標準化流(normalization flow,NF)[5]求得圖像的異常分數并作分類,同時基于梯度信息得到缺陷的大致位置。此方法雖然能夠定位缺陷,但并未分割出缺陷區域,且定位不準確,不能夠真實反映缺陷的特征信息。
針對異常檢測網絡在缺陷定位和分割方面存在的問題,本文主要做了以下幾點工作:
(1) 基于DifferNet網絡,選擇若干特征圖進行多尺度特征融合并對齊,初步定位缺陷位置;
(2) 基于梯度和最大信息熵,采用分水嶺分割算法優化初定位結果得到更貼近缺陷區域的分割掩碼;
(3) 使用結合圖像級統計信息和像素級匹配信息的評價指標E-measure[6]來評估分割結果;
(4) 在自行構建的麗盛制板數據集,公共表面缺陷數據集KolektorSDD[7]和AITEX[8]上進行實驗,并與近三年最優的異常檢測分割方法進行對比,結果表明,本文方法在分割精度和魯棒性方面優于其他同類方法。
1 相關工作
早期有較多傳統圖像處理算法進行缺陷檢測。文獻[9]面對高空間分辨率多光譜遙感影像使用分水嶺分割算法產生過分割的問題,結合各個波段的光譜信息和形態學處理對圖像進行修正,有效克服了分水嶺分割算法的過分割問題,但形態學結構元素的選取直接影響圖像的修正。文獻[10]使用OTSU算法和歐氏距離聚類算法對皮革表面缺陷進行分割和分類,在聚類算法中結合形態學處理對圖像進行腐蝕操作,能夠有效地檢測出皮革表面缺陷。傳統圖像處理算法通常適用于缺陷區域明顯,與背景顏色差異較大,易于分割的圖像,但一個具體的算法往往只適用于一種缺陷圖像或少數幾種缺陷圖像,泛化性差。
深度學習算法通過從大量的圖像數據中學習缺陷特征信息彌補了傳統圖像處理算法的不足。文獻[11]使用馬爾科夫隨機場對晶片圖像缺陷做分割,并基于AdaBoost分類器對分割出的局部缺陷區域進行分類。文獻[12]利用級聯自編碼器結構,基于語義分割將輸入的缺陷圖像轉換成像素級預測掩碼輸出,再通過卷積神經網絡(convolutional neural networks,CNN)對分割區域進行分類。文獻[13]提出雙重聯合檢測CNN,以較少的先驗知識自動提取有效的圖像特征進行缺陷檢測。上述方法均基于有監督的學習,在缺陷圖像數據量充足的情況下能達到很好的檢測效果,但實際生產中有缺陷樣本獲取難度很大,僅使用正樣本的無監督或使用正樣本和少量負樣本的半監督學習方式成為了研究重點。
文獻[14]使用條件生成對抗網絡,在正樣本上學習高維圖像的生成和潛在空間的推理,在UBA數據集[15]的AUC達到了0.643。文獻[2]考慮變量分布可變性的概率度量,利用變分自編碼器重構概率,從而達到異常檢測的目的,在MNIST數據集[16]的AUC和F1分數分別達到0.731和0.383。文獻[17]提出了由生成器和判別器組成的端到端單分類體系結構,生成器學習目標圖像的概率對圖像進行重建,判別器學習區分重建圖像和真實圖像,網絡在MNIST數據集上的F1分數達到0.85以上。文獻[18]對自編碼器偶爾會將異常樣本重建為正常樣本的問題,使用記憶模塊存儲正常數據的原型,因此,在異常檢測中,異常樣本的重構誤差將大大減小,網絡在MNIST數據集上的AUC達到了0.975。以上方法只將圖像分類為正常或異常,并未涉及到對異常區域的定位。
文獻[19]利用師生網絡解決自然圖像中無監督異常分割這一具有挑戰性的問題,教師網絡指導學生網絡的訓練,學生網絡集合的預測方差和回歸誤差得到最終的異常分數和異常分割,在專門為異常檢測準備的MVTec AD數據集[20]上,該網絡的AUPRO達到了0.857。文獻[21]在K近鄰算法的基礎上,將多分辨率特征金字塔與正常圖像相匹配以計算像素間的距離來定位異常位置,在MVTec AD數據集的圖像級和像素級AUROC分別達到了0.855和0.960。文獻[22]描述向量數據,并將其拓展到基于補丁的自監督學習以分割異常像素,在MVTec AD數據集的圖像級和像素級AUROC分別達到了0.921和0.957。文獻[23]利用預處理CNN進行塊嵌入,并采用多元高斯分布獲得正常樣本的概率表示,同時利用CNN不同語義級別之間的相關性對異常進行定位,網絡在MVTec AD數據集的圖像級和像素級AUROC分別達到了0.955和0.973。文獻[24]利用師生網絡學習正常樣本的分布,此外,集成多尺度特征匹配策略檢測各種大小的異常,在MVTec AD數據集的圖像級和像素級AUROC分別達到了0.955和0.970。
2 網絡構建
本文構建的網絡主要分為圖像處理模塊、特征提取器、檢測模塊和分割模塊4個部分,網絡結構如圖1所示。圖像處理模塊首先對輸入圖像進行旋轉操作以擴充數據集,且對擴充后的圖像構建圖像金字塔以獲得不同尺度的結構信息。特征提取器采用AlexNet網絡,將最終輸出特征輸入到檢測模塊實現異常檢測,同時,保存提取到的多尺度特征信息來分割缺陷。檢測模塊基于標準化流將特征映射到潛在空間以求其密度分布,最后得到圖像的異常分數。分割模塊首先利用保存的特征信息進行多尺度特征融合并對齊,初步定位缺陷位置,為了分割出更細致的缺陷區域,再利用圖像級梯度信息,得到缺陷輪廓清晰的梯度圖,接著使用最大信息熵算法確定最大熵的灰度值并以該灰度值為閾值進行分割,這可以將梯度圖中的噪聲干擾去除,最后采用分水嶺算法結合梯度圖和閾值分割圖分割出缺陷區域。網絡輸出的分割掩碼相比初定位結果,在缺陷的外觀輪廓及細節信息上更接近真實缺陷。
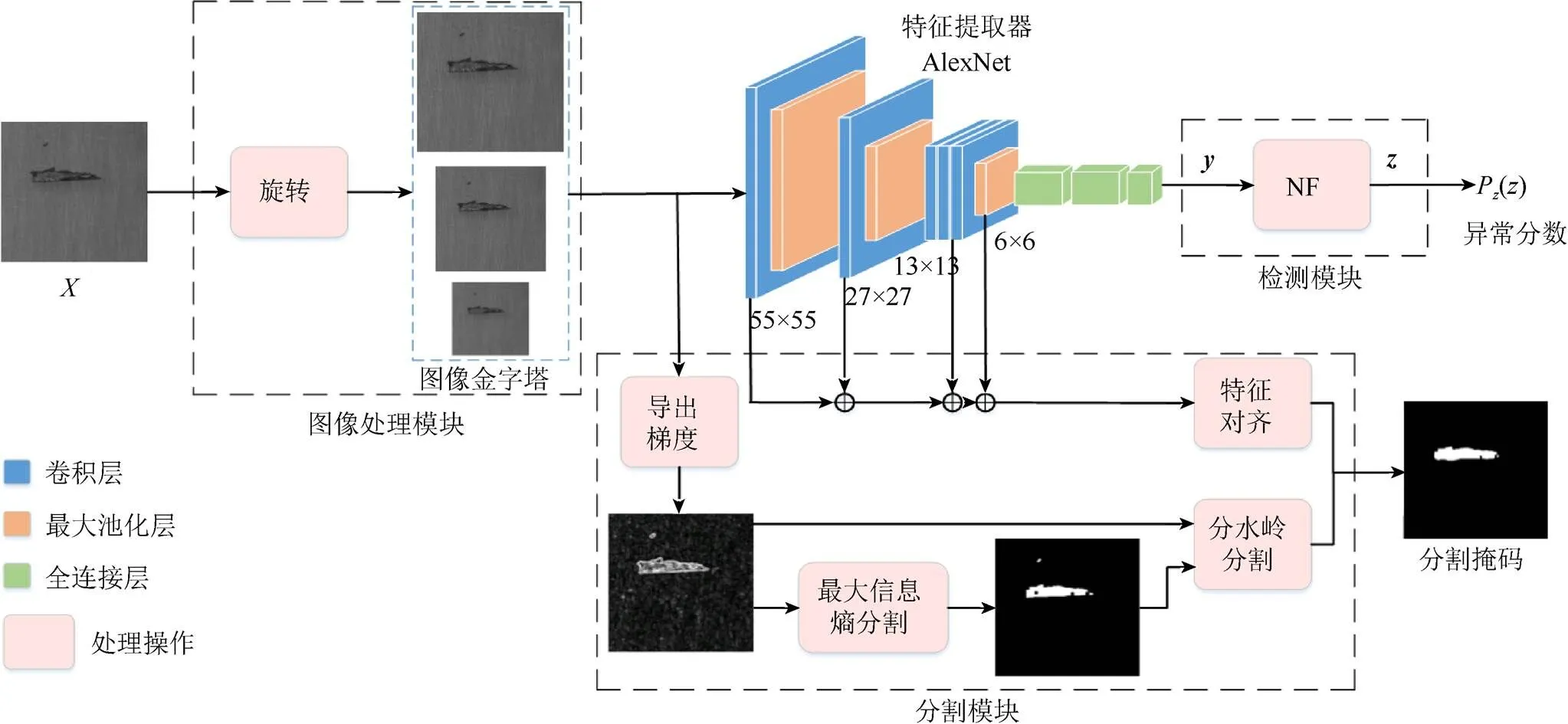
圖1 網絡結構
2.1 圖像處理與特征提取
圖像處理模塊對輸入圖像使用Torchvision庫的Transforms模塊進行轉換,為獲得穩定的異常分數及精確的缺陷分割,將圖像按順時針方向每隔90°旋轉一次以擴充數據集,再對擴充數據集構建448×448,224×224和112×112大小的3個尺度的圖像金字塔以獲得不同尺度的結構信息。
從零開始對輸入的正常圖像訓練一個異常檢測網絡難以得到令人滿意的效果,為此,使用在ImageNet數據集上預訓練過的AlexNet[25]網絡作為特征提取器,該網絡的各層輸入輸出見表1。
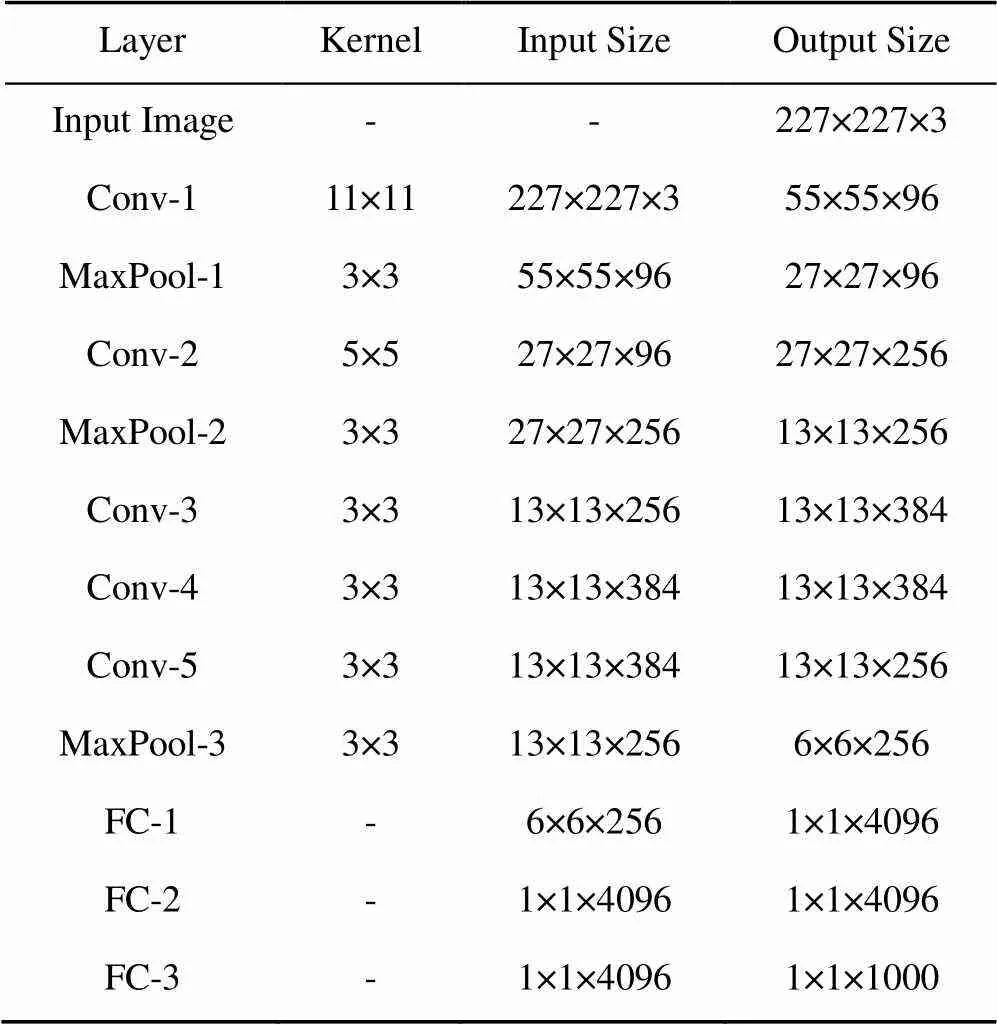
表1 AlexNet特征提取器結構
對于輸入網絡的圖像?,提取的特征為
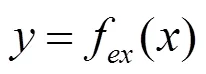
特征提取器在訓練階段提取并保存正常樣本的特征信息,在測試階段將測試樣本的特征與訓練過程中保存的特征信息對齊以定位缺陷。
2.2 異常檢測
對圖像?進行異常檢測,則要計算圖像特征?的概率密度P(),通過標準化流f將映射到使用標準正態分布定義P()的潛在空間:{→|?,?},從P()可以直接計算樣本的似然性。異常樣本的特征應該不在分布范圍內,因此具有比正常樣本更低的似然性,根據計算得到的似然性將一個樣本分類為正常或異常樣本。為了獲得更穩定的異常分數(),使用多重變換T()?求圖像的平均負對數似然性,即
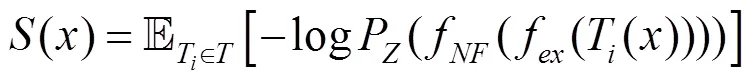
其中,是旋轉、亮度和對比度調整的組合操作。一張圖像的異常分數如果高于閾值,則圖像被分類為異常,該決策可以表達為
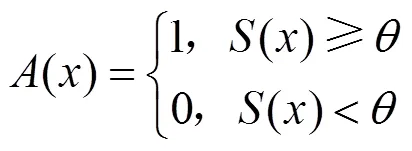
其中,()=1表示分類為異常。
2.3 缺陷分割
在圖像被分類為異常或正常后,下一步目的是定位并分割一個或多個異常像素。本文考慮通過對齊特征圖來定位并分割出異常像素。為了獲得準確的定位和分割結果,使用同一主干網絡在圖像的每個像素位置?提取深度特征圖f(,)。所提取到的特征圖與圖像金字塔類似,較淺層具有較高的分辨率和細節信息,較高層的分辨率較低,但包含更多的特征信息。為了對齊特征圖,使用多尺度特征融合來描述每個位置,即連接不同層的特征輸出,這樣的特征既包含圖像的局部細節信息,也包含圖像全局信息,且能夠保證找到測試圖像和正常圖像之間的對應關系。在個最近鄰的所有像素位置上構建一個特征圖庫,即
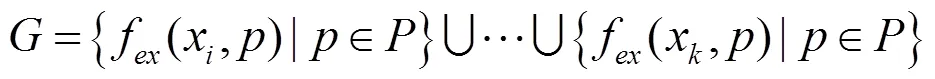
像素的異常分數是通過計算特征(,)與圖庫中最近的個特征之間的平均距離得到的,因此目標圖像中像素的異常分數的計算為
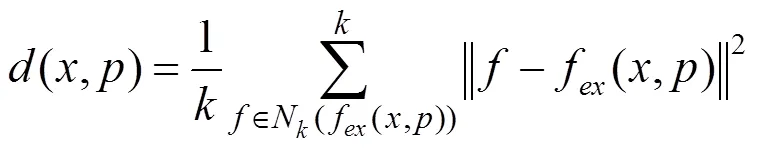
其中,N(f(,))為特征f(,)在訓練階段保存的特征圖中檢索個最近鄰特征;若(,)大于給定的閾值,則該像素為異常像素。
基于無監督訓練的多尺度特征融合并使用對齊來定位缺陷位置,其缺乏對缺陷細節信息的描述。使用梯度衡量圖像灰度的變化率,加強圖像中前景和背景的區別可以有效描繪出缺陷輪廓。因此,對輸入網絡的圖像求其局部梯度值,即
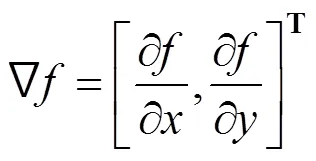
其中,,分別為圖像的方向和方向。
在圖像的局部梯度值中,除缺陷外,還存在一些與背景有顯著區別的噪聲點。為了區分這2種情況,使用最大信息熵算法決策出使得缺陷區域與背景區域2部分灰度統計信息量最大的閾值,使用該閾值對圖像進行閾值分割可以有效消除噪聲點影響,其計算式為
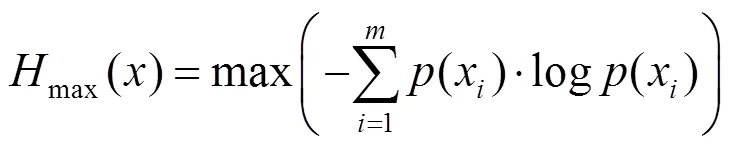
其中,為輸入的梯度圖;為梯度圖灰度值取值范圍。
使用最大信息熵對梯度圖進行閾值分割缺乏對像素在空間關系上的相似性和封閉性的考慮,而分水嶺算法會將鄰近像素的相似性作為重要參考,從而空間位置上相鄰且灰度值相近的像素點互相連接起來構成一個封閉輪廓,即
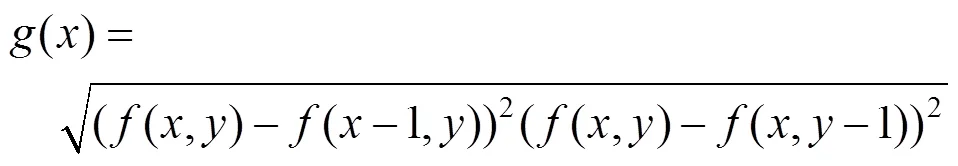
其中,(,)為原始圖像,,分別為圖像的方向和方向。
3 數據構建及預處理
3.1 圖像處理與特征提取
(1) 麗盛制板數據集。該數據集在工廠生產環境中實時采集,其中包括缺陷圖像10種類型,共405張圖像;正常圖像共450張。每張缺陷圖像中包含至少一種缺陷,圖像的分辨率為500×500,數據集缺陷類型及圖像數量見表2。
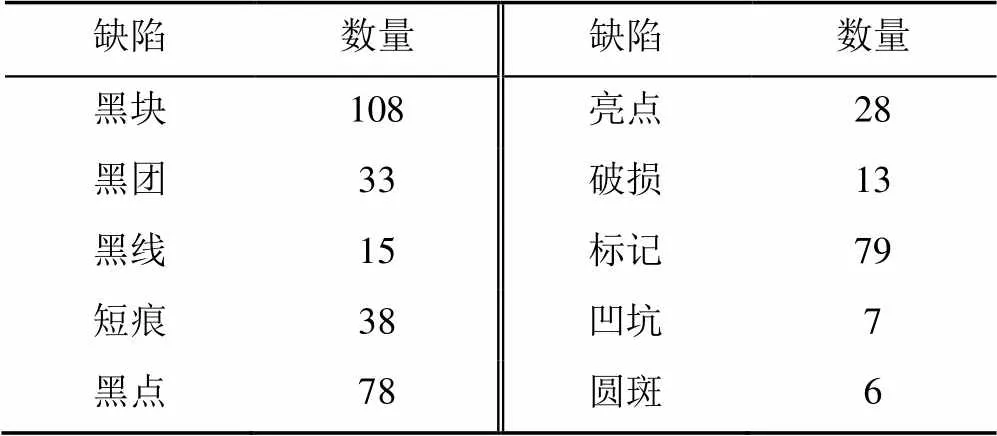
表2 麗盛制板數據集缺陷類型及數量
麗盛制板數據集的缺陷圖像數量不均衡,缺陷表現形式不一,既有條狀缺陷又有團狀缺陷,且部分缺陷占整張圖像面積比例較小,如圖2所示。本文在原始數據集中不足10張的采用旋轉、水平翻轉、平移等組合操作進行數據增強,最終隨機得到的訓練集包含正常樣本200張,測試集包含正常樣本20張,異常樣本共10類,每一類包含10張圖像。

圖2 麗盛制板數據集缺陷樣本及真值圖
(2) 公共表面缺陷數據集。為驗證本文網絡的魯棒性,在背景紋理及光照條件更復雜的公共表面缺陷數據集KolektorSDD和AITEX上進行實驗,其樣本如圖3所示。KolektorSDD數據集中包含了50組電子換向器圖片,其中每組包含8張圖片以及對應的語義分割標簽,圖像寬均為500像素,高為1 240~1 273像素。AITEX數據集由7種不同織物結構的245張圖像組成,圖像尺寸均為4096×256像素,其中無缺陷圖像140張,平均每種織物20張,此外還有105張紡織行業中常見的不同類型的織物缺陷圖像。

圖3 公共表面缺陷數據集缺陷樣本((a) KolektorSDD數據集;(b) AITEX數據集)
3.2 圖像預處理
對圖像進行缺陷檢測易受到背景紋理等因素的影響,因此需要對圖像進行預處理。圖像灰度處理將3通道圖像轉換為1通道圖像,有效降低圖像數據量。原始圖像中存在噪聲,采用均值濾波來去除。圖像經灰度和均值濾波2步預處理后的結果如圖4所示。

圖4 圖像預處理結果((a)原圖;(b)預處理結果圖)
不同數據集、不同缺陷類型圖像的尺寸各異,為方便網絡訓練及處理,使用Opencv將所有圖像縮放到500×500分辨率。
4 實驗結果分析
實驗使用系統環境為Ubuntu16.04LTS的GPU服務器,硬件配置為NVIDIA GeForce RTX 2080Ti和16 G內存,網絡基于Pytorch深度學習框架搭建和訓練。
4.1 評價指標
接受者操作特征曲線下面積(area under the receiver operating characteristic,AUROC)[4]常被用來評價二值分類器的優劣,其值越接近1,說明分類結果越好,其計算與混淆矩陣(表3)有關。
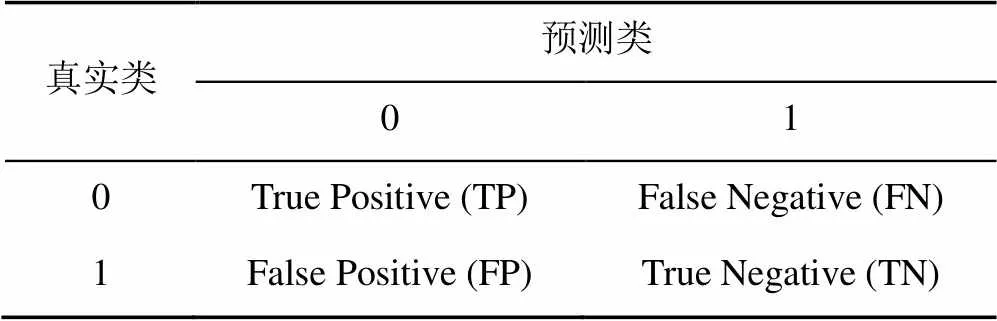
表3 混淆矩陣
注:TP表示正確分類為正樣本的數量;FN表示錯誤分類為負樣本的數量;FP表示錯誤分類為正樣本的數量;TN表示正確分類為負樣本的數量
AUROC指由真陽性率(true positive rate,TPR)作縱軸和假陽性率(false positiverate,FPR)作橫軸繪制的曲線與橫軸所圍面積,即
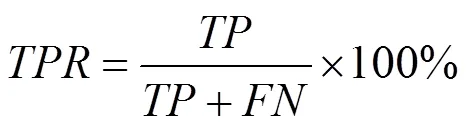
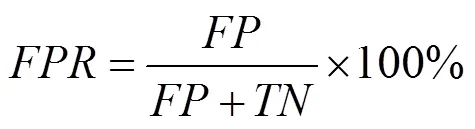
在分割精度評估方面,增強匹配指標(E-measure)充分考慮圖像級統計信息和像素級匹配信息,測量精度顯著優于傳統測量方法,常被用來評估二值前景圖的分割精度。為了能夠同時反映全局統計量和局部像素匹配信息,定義輸入二值映射的每個像素值與其全局平均值間的距離為偏差矩陣,即
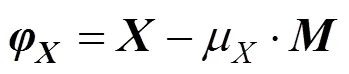
其中,是一個所有元素值都為1的矩陣,且尺寸與輸入二值映射相同。對二值真值圖和二值分割圖計算其偏差矩陣和之間的相似性為
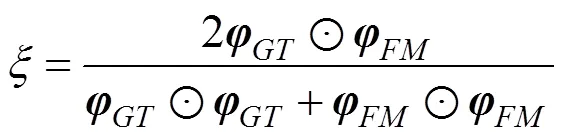
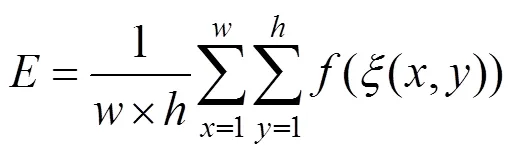
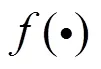
4.2 異常檢測
網絡訓練使用Adam優化器更新和優化模型參數,設為0.000 1,設為True,設為0.2,設為4。初始時,設為500,當數據迭代至200次時模型已經收斂,隨著迭代次數的增加,檢測與分割精度并未提高反而有所下降,因此將訓練迭代次數設為200。
本文方法與GANomaly[14],DifferNet,SPADE[21],STPM[24]和PaDiM[23]方法在異常檢測方面進行了對比,結果見表4。在麗盛制板數據集上,本文方法的平均AUROC達到了0.996,為所有方法的最高精度,在10種缺陷類型中,有9種AUROC達到了1,由于短痕類數據中缺陷弱小且表現形式更豐富,學習難度較大,其檢測精度略低于DifferNet,SPADE,STPM和PaDiM方法。在KolektorSDD數據集上,本文方法的平均AUROC達到了0.871,高于其他對比方法。在AITEX數據集上,本文方法的AUROC達到了0.985,比其他方法提高了至少8.2%。與其他對比方法相比,本文方法在3個表面缺陷數據集上均取得了最優結果,對表面缺陷數據進行異常檢測可以精確地對圖像做分類。
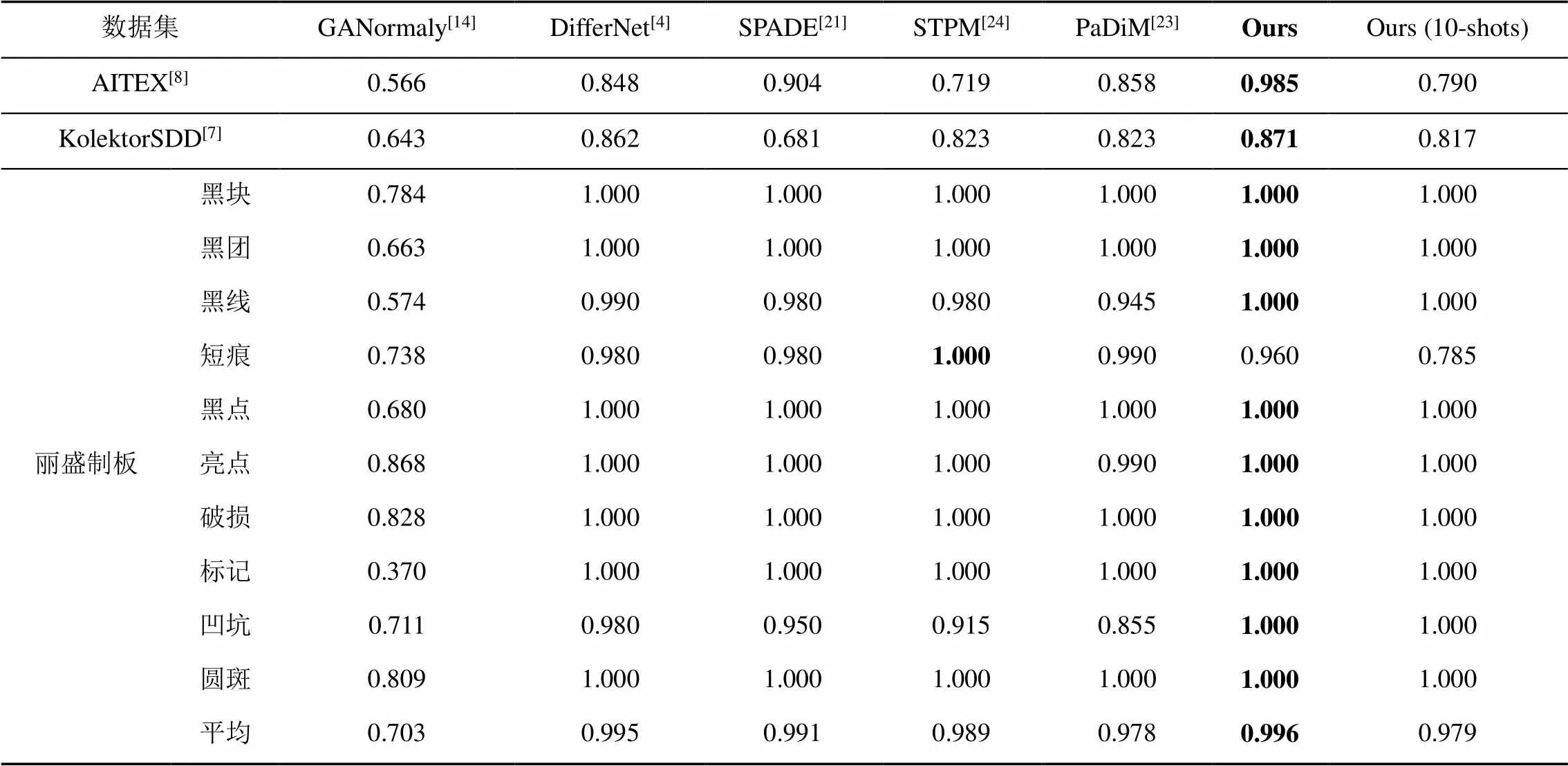
表4 異常檢測結果
注:加粗項表示在該組的最優AUROC
此外,在麗盛制板數據集上,用10張正常樣本訓練得到的模型僅在短痕類缺陷上的AUROC下降到0.785,而其他9種類型缺陷的AUROC仍然為1,平均AUROC達到0.979。在KolektorSDD,AITEX的小樣本實驗中,分類精度AUROC分別達到0.817和0.790。結果表明,本文方法對小樣本數據能保持較高的異常分類精度,適用于小樣本異常檢測。
4.3 缺陷分割
基礎網絡DifferNet只對缺陷進行粗略定位,其定位結果比較模糊,且缺乏對缺陷區域的分割,如圖5第3列所示,因此本文與最近提出的異常檢測分割方法SPADE,STPM和PaDiM在麗盛制板,KolektorSDD和AITEX 3個數據集上進行分割實驗。分割結果如圖5所示,對黑塊、黑線等面積較大或形狀清晰的顯著缺陷,本文方法的分割結果更接近真實缺陷區域,對黑團、圓斑等面積較小的非顯著缺陷,也能對其進行精確分割。對各方法的分割結果使用E-measure評估,見表5。在麗盛制板數據集上的平均分割精度達到0.701 3,高于其他方法,10種缺陷中,在黑團、黑線、短痕、黑點、破損和凹坑這6種缺陷上的分割精度達到了最優。在KolektorSDD數據集上的E-measure值達到0.583 6,相比其他方法至少提高了9.3%。在AITEX數據集上的E-measure值達到0.478 7,相比其他方法至少提高了42.9%,遠優于其他方法。實驗結果表明,在保證圖像高精度分類的基礎上,本文方法分割缺陷區域更精確。
為驗證在小樣本數據集上的分割效果,僅使用包含10張正常樣本的小數據集進行訓練,訓練得到的模型在麗盛制板,KolektorSDD和AITEX3個數據集的分割精度分別達到0.681 1,0.583 4和0.440 5,均優于使用非小樣本訓練集訓練的其他方法。實驗證明本文方法在小樣本表面缺陷數據集上也能得到良好的分割結果。
4.4 對比及消融實驗
本文使用在ImageNet數據集上預訓練過的AlexNet網絡作為特征提取器,為驗證特征提取器的有效性,比較了同樣在ImageNet數據集上預訓練過的VGG16[26]和ResNet50[27]網絡,在3個表面缺陷數據集上的異常檢測和缺陷分割的評估結果見表6。
從實驗結果看,在缺陷分類問題上,AlexNet特征提取器在AITEX,KolektorSDD和麗盛制板3個表面缺陷數據集上的分類精度分別達到了0.985,0.871和0.996,均優于VGG16和ResNet50。對缺陷分割問題,AlexNet 在AITEX和麗盛制板數據集上的分割精度優于VGG16和ResNet50,分別達到了0.478 7和0.701 3,僅在KoloktorSDD數據集上的分割精度低于VGG16,其分割精度為0.583 6。綜合來看,選擇AlexNet作為特征提取器。
根據2.3節提出的方法對缺陷進行粗定位時,不同尺度特征的融合對最終的分割結果有不同的影響,因此,表7中詳細比較了在麗盛制板數據集上,不同尺度融合情況的分割精度。由表1可知,AlexNet特征提取網絡經不同卷積層和最大池化層提取的特征圖分辨率分別為55×55,27×27,13×13和6×6,消融實驗在這4個不同分辨率的特征圖上進行。
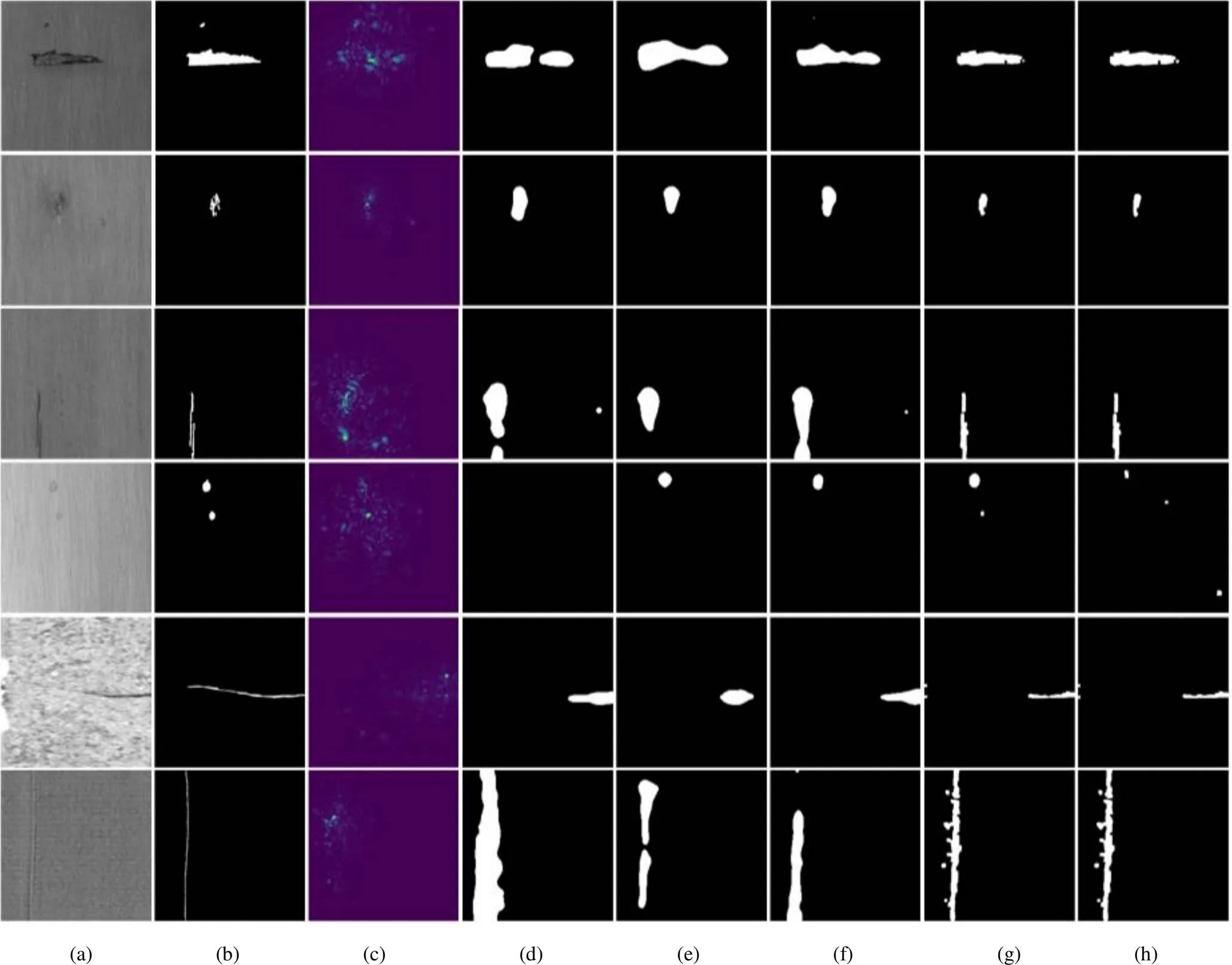
圖5 缺陷定位及分割結果
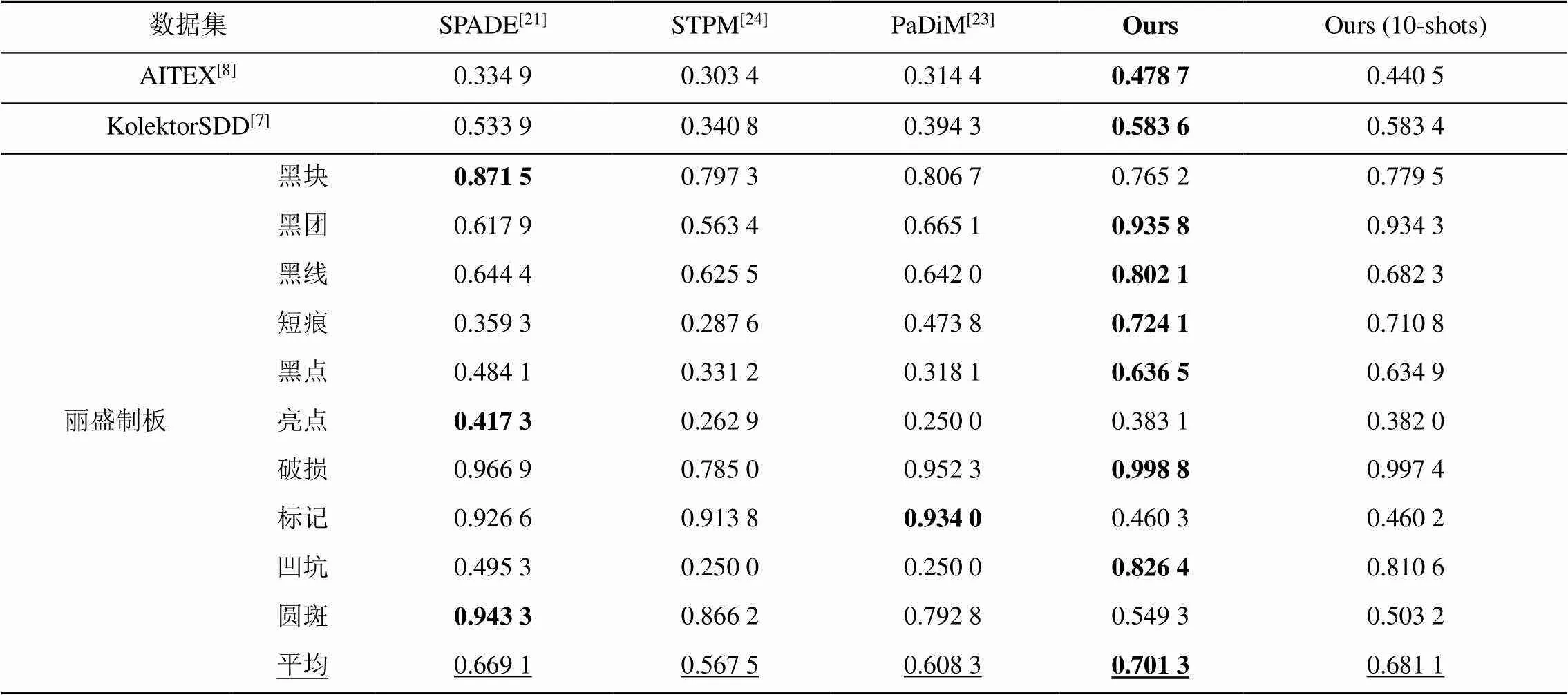
表5 缺陷分割結果
注:加粗項表示該組的最優E-measure

表6 特征提取器對比實驗結果
注:加粗項為最優結果
從實驗1~4可以觀察到,只使用單特征圖對齊,隨著分辨率減小,分割的效果越來越差,因此,應盡可能保留55×55分辨率的特征圖。實驗1和5對比,證明多尺度融合可以提高分割精度。實驗5~15則表示不同尺度特征融合的分割評估結果,當融合4個尺度的特征圖時,分割掩碼的評估結果是最優的,E-measure值為0.701 3。
在融合4個尺度大小的特征圖的基礎上,對AITEX和麗盛制板2個表面缺陷數據集的初定位結果是否進行最大信息熵分割或分水嶺分割優化進行了消融實驗,缺陷分割結果圖和分割精度統計分別如圖6和表8所示。
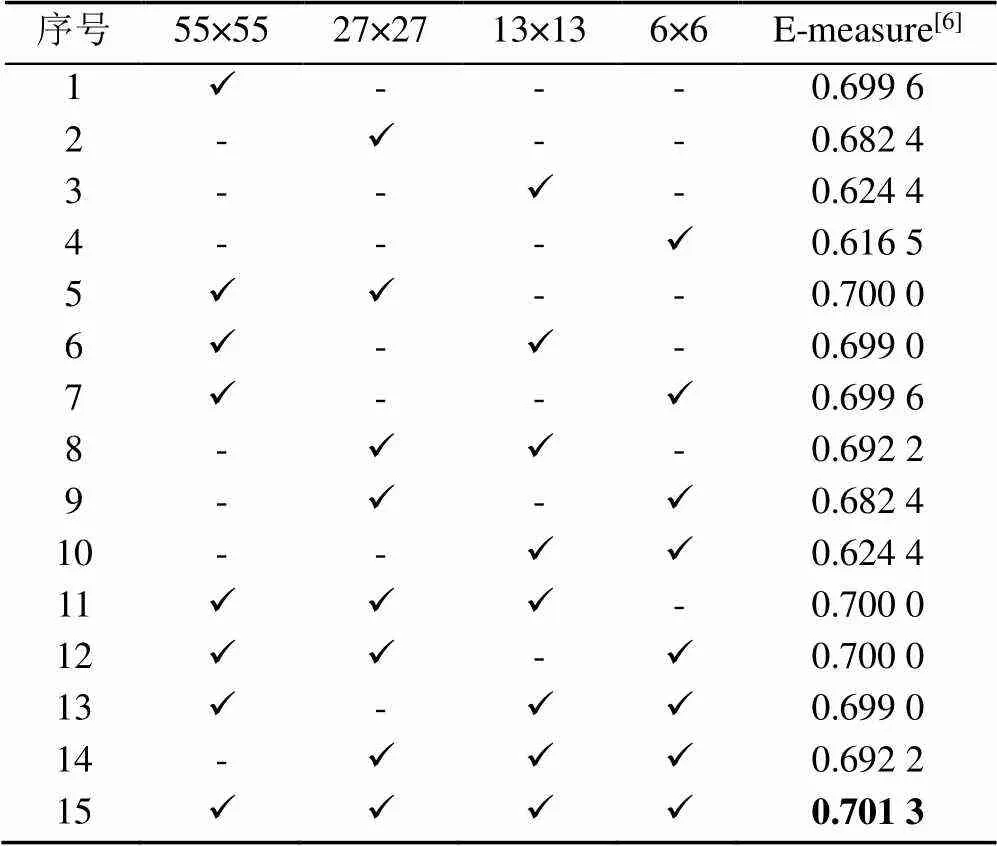
表7 多尺度消融實驗結果
注:加粗數據為最優結果

圖6 分割優化消融實驗結果((a)原圖;(b)真值圖;(c)特征對齊;(d)特征對齊+最大信息熵;(e)特征對齊+分水嶺算法;(f)特征對齊+最大信息熵+分水嶺算法)
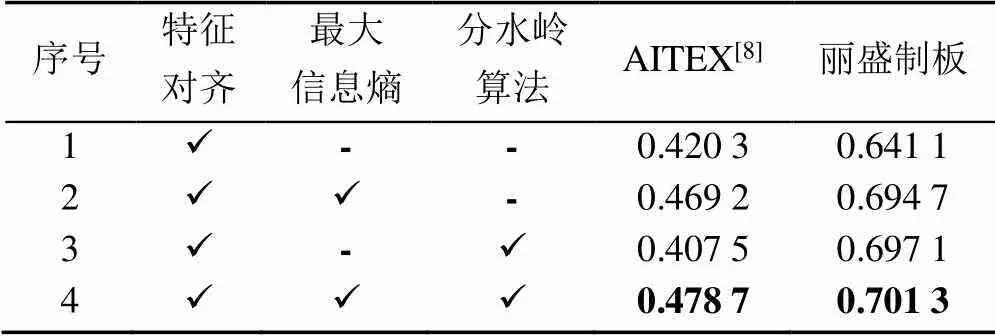
表8 分割優化消融實驗結果
注:加粗數據為最優結果
從4組實驗可以看到,采用基于梯度圖和最大信息熵的分水嶺分割算法在AITEX和麗盛制板2個數據集上均達到最優結果,E-measure值分別為0.478 7和0.701 3。
5 結 論
本文主要針對使用異常檢測方法對表面缺陷圖像進行缺陷分割不精確的問題,提出了一種無監督異常分割方法,采用多尺度特征融合并對齊進行初步定位,再基于梯度和最大信息熵的分水嶺分割算法對初步定位結果進行優化。本文方法在麗盛制板,KoloktorSDD和AITEX 3個表面缺陷數據集上的異常分類精度均達到了當前最優水平,且比現有異常分割最好的方法在分割缺陷區域時對缺陷細節的描繪更好,在結合圖像級統計信息和像素級匹配信息的二值前景分割評估指標E-measure上均優于其他同類方法。除此之外,本文方法在小樣本數據集上也取得了良好的缺陷分類與分割結果。本文提出的缺陷分割方法在背景紋理相似或有規律的表面缺陷數據上表現良好,在背景雜亂或無規律的表面缺陷數據圖像上進行異常檢測與分割將是接下來的研究重點。
[1] BALDI P. Autoencoders, unsupervised learning, and deep architectures[C]//2011 International Conference on Unsupervised and Transfer Learning Workshop. New York: ACM Press, 2012: 37-50.
[2] AN J, CHO S. Variational autoencoder based anomaly detection using reconstruction probability[EB/OL]. [2021-07-28]. http://dm.snu.ac.kr/static/docs/TR/SNUDM-TR-2015-03.pdf.
[3] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks[J]. Communications of the ACM, 2020, 63(11): 139-144.
[4] RUDOLPH M, WANDT B, ROSENHAHN B. Same same but DifferNet: semi-supervised defect detection with normalizing flows[C]//2021 IEEE Winter Conference on Applications of Computer Vision. New York: IEEE Press, 2021: 1906-1915.
[5] KOBYZEV I, PRINCE S J D, BRUBAKER M A. Normalizing flows: an introduction and review of current methods[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(11): 3964-3979.
[6] FAN D P, GONG C, CAO Y, et al. Enhanced-alignment measure for binary foreground map evaluation[EB/OL]. [2021-06-10]. https://arxiv.org/abs/1805.10421.
[7] TABERNIK D, ?ELA S, SKVAR? J, et al. Segmentation- based deep-learning approach for surface-defect detection[J]. Journal of Intelligent Manufacturing, 2020, 31(3): 759-776.
[8] SILVESTRE-BLANES J, ALBERO-ALBERO T, MIRALLES I, et al. A public fabric database for defect detection methods and results[J]. Autex Research Journal, 2019, 19(4): 363-374.
[9] 李攀峰, 黨建武, 王陽萍. 基于多光譜混合梯度的遙感影像分水嶺分割方法[J]. 蘭州交通大學學報, 2019, 38(5): 47-54.
LI P F, DANG J W, WANG Y P. Watershed segmentation of remote sensing image based on multispectral hybrid gradient[J]. Journal of Lanzhou Jiaotong University, 2019, 38(5): 47-54 (in Chinese).
[10] HOANG K, WEN W, NACHIMUTHU A, et al. Achieving automation in leather surface inspection[J]. Computers in Industry, 1997, 34(1): 43-54.
[11] LEE S H, KOO H I, CHO N I. New automatic defect classification algorithm based on a classification-after- segmentation framework[J]. Journal of Electronic Imaging, 2010, 19: 020502.
[12] TAO X, ZHANG D P, MA W Z, et al. Automatic metallic surface defect detection and recognition with convolutional neural networks[J]. Applied Sciences, 2018, 8(9): 1575.
[13] WANG T, CHEN Y, QIAO M N, et al. A fast and robust convolutional neural network-based defect detection model in product quality control[J]. The International Journal of Advanced Manufacturing Technology, 2018, 94(9-12): 3465-3471.
[14] AKCAY S, ATAPOUR-ABARGHOUEI A, BRECKON T P. GANomaly: semi-supervised anomaly detection via adversarial training[EB/OL]. [2021-05-10]. https://arxiv.org/abs/1805.06725.
[15] ROGERS T W, JACCARD N, MORTON E J, et al. Automated X-ray image analysis for cargo security: critical review and future promise[J]. Journal of X-Ray Science and Technology, 2017, 25(1): 33-56.
[16] LECUN Y, CORTES C, BURGES C C.THE MNIST DATABASE of handwritten digits [EB/OL]. [2021-06-19]. http://yann.lecun.com/exdb/mnist/.
[17] SABOKROU M, KHALOOEI M, FATHY M, et al. Adversarially learned one-class classifier for novelty detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 3379-3388.
[18] GONG D, LIU L Q, LE V, et al. Memorizing normality to detect anomaly: memory-augmented deep autoencoder for unsupervised anomaly detection[C]//2019 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2019: 1705-1714.
[19] BERGMANN P, FAUSER M, SATTLEGGER D, et al. Uninformed students: student-teacher anomaly detection with discriminative latent embeddings[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 4182-4191.
[20] BERGMANN P, FAUSER M, SATTLEGGER D, et al. MVTec AD—A comprehensive real-world dataset for unsupervised anomaly detection[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 9584-9592.
[21] COHEN N, HOSHEN Y. Sub-image anomaly detection with deep pyramid correspondences[EB/OL]. [2021-07-11]. https:// arxiv.org/abs/2005.02357.
[22] YI J H, YOON S. Patch SVDD: Patch-level SVDD for anomaly detection and segmentation[EB/OL]. [2021-05-26]. https://arxiv.org/abs/2006.16067v2.
[23] DEFARD T, SETKOV A, LOESCH A, et al. PaDiM: a patch distribution modeling framework for anomaly detection and localization[EB/OL]. [2021-08-01]. https://arxiv.org/abs/2011. 08785.
[24] WANG G D, HAN S M, DING E R, et al. Student-teacher feature pyramid matching for unsupervised anomaly detection[EB/OL]. [2021-04-19]. https://arxiv.org/abs/2103.04257.
[25] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
[26] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2021-08-07]. https://arxiv.org/abs/1409.1556.
[27] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 770-778.
Product surface defect detection and segmentation based on anomaly detection
WANG Su-qin1, REN Qi1, SHI Min1, ZHU Deng-ming2,3
(1. School of Control and Computer Engineering, North China Electric Power University, Beijing 102206, China; 2. Prospective Research Laboratory, Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China; 3. Taicang Institute of Information Technology, Taicang Jiangsu 215400, China)
In industrial manufacturing, it is difficult to obtain defective samples and the defects are in diverse forms. Anomaly detection, which only trains positive samples, is being increasingly applied to defect detection on product surfaces. Anomaly detection generally determines whether the product has defects by evaluating the anomaly score of the product image, while unable to describe the locations of the defects. The latest anomaly segmentation method has been improved, but the segmentation of the defective area is not accurate enough.Based on the anomaly detection method, normalization flow was employed to judge whether the product surface was defective, and multi-scale feature fusion and alignment were adopted to initially locate the defects. Combined with the gradient and maximum information entropy, the watershed algorithm was used to optimize the initial positioning results to obtain the defect segmentation mask. The detection and segmentation results on the three surface defect datasets of Lisheng Board, KolektorSDD, and AITEX are superior to other similar methods. In addition, good detection and segmentation accuracy can also be achieved on few-shots.
anomaly detection; defect segmentation; multi-scale feature fusion; feature alignment; watershed algorithm
TP 391
10.11996/JG.j.2095-302X.2022030377
A
2095-302X(2022)03-0377-10
2021-11-29;
2022-01-20
29 November,2021;
20 January,2022
國家自然科學基金項目(61972379)
National Natural Science Foundation of China (61972379)
王素琴(1970–),女,副教授,碩士。主要研究方向為計算機視覺、數據分析與挖掘。E-mail:wsq@ncepu.edu.cn
WANG Su-qin (1970-), associate professor, master. Her main research interests cover computer vision, data analysis and mining. E-mail:wsq@ncepu.edu.cn
朱登明(1973–),男,副研究員,博士。主要研究方向為虛擬現實、計算機圖形學。E-mail:mdzhu@ict.ac.cn
ZHU Deng-ming (1973-), associate researcher, Ph.D. His main research interests cover virtual reality, computer graphics. E-mail:mdzhu@ict.ac.cn
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
