
基于文獻挖掘的圖書館智慧化平臺建設研究
2022-08-24 09:47:58河南中醫藥大學圖書館雷天鋒
辦公室業務 2022年15期
文/河南中醫藥大學圖書館 雷天鋒
文獻挖掘是借助數據挖掘技術,從圖書館海量的文獻數據庫中挖掘和整合有用的文獻資料的技術方法和行為過程。在教學、科研行動中,文獻挖掘是精準獲取文獻資料信息的關鍵路徑,也是高校在文獻資料整合利用方面面臨的“瓶頸”。在傳統以紙質文獻資料為主的圖書館運營管理模式中,讀者對文獻資料的挖掘更多依靠人工搜集,不僅效率低,最終獲得的文獻資料的可利用性也欠佳。隨著智慧化圖書館平臺的開發,借助數據挖掘技術,進行精準的文獻挖掘已然成為一種高效的行為。近年來,已有高校圖書館開始將開發具有文獻挖掘功能的圖書館智慧化平臺作為重要關注點。
一、數據挖掘技術概述
數據挖掘技術是大數據技術在智慧化圖書館平臺建設中深度應用的產物,其特點在于數據的精準檢索和高效利用。雖然大數據技術的應用使得圖書館在文獻資料獲取、存儲、分析、挖掘和可視化呈現等方面有了明顯改善,但是,技術作用下產生的海量數據并不都是讀者真正需要的數據,其中不乏一些干擾性的信息。在精準獲取文獻資料需求日益明顯的情況下,有必要通過技術手段為讀者提供短時間內獲取準確文獻資料信息的方法,而這就使得數據挖掘技術有了應用的需求。
(一)數據挖掘技術的概念。數據挖掘技術,是在專家系統、計算機信息處理技術等方法的支持下,從大量無規則的數據中提取出符合特定條件的,具有潛在指導性作用的數據信息的技術。數據挖掘技術的應用包括五個階段:第一階段為數據準備階段,主要內容為確定數據挖掘的目標,并從數據庫中采集大量原始數據;第二階段為數據預處理階段,主要內容是對采集到的原始數據進行科學選擇和合成處理;第三階段為數據變換階段,主要是通過聚集、降維等方式將合成的數據進行格式轉換,使數據在格式上呈現出統一性、規則性;第四階段為數據處理階段,主要是選擇合適的模型和算法對數據進行分析處理,使數據以正確的方式表達出來;第五階段為結果呈現階段,主要是根據讀者在視覺方面的個性化要求,對數據進行可視化的圖表或者模型處理,使數據本身具有的規則能夠更直觀地顯現出來。
(二)數據挖掘技術的特點。數據挖掘技術具有三方面的特點。第一,集成性。數據挖掘技術是在對海量數據進行挖掘、集成基礎上的進一步應用,是從海量數據中挖掘和提取出符合特定規律的內容;第二,隱含性。數據挖掘技術的功能在于發現海量數據中隱藏的深層次信息和規律,而不是直接從數據的表征中提取相關規律;第三,規則性。數據挖掘技術是按照特定的規則或者算法對數據庫中海量的數據進行檢索、整合和處理的技術,其輸出的結果具有明顯的規律性。
二、基于文獻挖掘的圖書館智慧化平臺概述
圖書館智慧化平臺,是以為用戶提供泛在智慧服務為主的平臺,是繼數字圖書館、復合圖書館后,圖書館發展的一個更高級形態。圖書館智慧化平臺主要依托傳感器技術、云計算技術、大數據技術等要素,旨在實現圖書流、人員流、物流、信息流的充分流動和融合,最終充分滿足用戶尤其是讀者在智慧化方面的服務需求。基于文獻挖掘的圖書館智慧化平臺是其中的一項重要功能。在數據挖掘技術的支持下,高校圖書館可以為讀者提供精準的文獻資料信息檢索服務。以下著重對該類平臺的架構以及應用方向進行分析。
(一)基于文獻挖掘的圖書館智慧化平臺的架構。在原有的數字化圖書館系統和平臺的基礎上,加入數據挖掘技術內容,使原本以文獻資料數據信息管理為主的平臺轉變為以文獻資料數據信息精準檢索和推送為主的平臺。圖1展示了基于文獻挖掘的圖書館智慧化平臺的架構。可以看出,基于數據挖掘技術開發的智慧化平臺是通過該平臺中的數據理解、分析和應用,來構建相應的文獻數據模型,以模型為載體,借助精準、高效的數據挖掘技術,為讀者提供更為精準、可靠的文獻資料數據檢索服務。在整個智慧化平臺中,數據的理解和模型的構建是關鍵,其中,數據理解是模型構建的前提,模型構建是數據應用的結果。

圖1 基于文獻挖掘的圖書館智慧化平臺架構
(二)基于文獻挖掘的圖書館智慧化平臺應用方向。目前文獻挖掘的圖書館智慧化平臺的應用主要體現在讀者借閱行為模式分析、讀者個性化文獻資料服務和圖書館文獻排架分析三方面。其中,讀者借閱行為模式分析是平臺借助數據挖掘技術,對讀者在檢索過程中留下的各種記錄進行集中性的分析處理,從中獲得關于讀者對文獻資料閱讀習慣的數據信息,或者某一文獻資料在讀者群體中的受歡迎程度信息,然而根據這些數據構建相應的模型,作為精準化文獻資料檢索或者書籍資料推送的依據。讀者個性化文獻資料服務是通過對讀者的身份信息與讀者的文獻檢索、借閱信息進行關聯性分析,并建立相應的模型,呈現讀者在不同文獻資料閱讀方面的需求,便于圖書館或者智慧化平臺為讀者提供個性化的文獻資料閱讀服務。圖書館文獻排架分析是通過對讀者群體文獻資料借閱行為模式和個性化服務內容進行分析,掌握不同類型圖書在讀者群體中的受歡迎程度和被借閱的記錄情況,為圖書館進行文獻資料的合理排架和陳設提供相應的數據支持。
三、基于文獻挖掘的圖書館智慧化平臺建設策略
從功能上看,基于文獻挖掘的圖書館智慧化平臺是在原有的智慧化平臺中增加數據挖掘技術要素,實現文獻挖掘的精準化和高效化。但真正的文獻挖掘功能實現卻需要有成熟、安全的技術作為支撐。基于上文提出的平臺架構,相關主體要在現有技術框架內,結合數據挖掘技術的特點,科學推進智慧化平臺文獻挖掘功能的開發與應用。具體來說,在平臺建設實踐中,需要重點采取以下幾方面的策略:
(一)做好數據挖掘引擎的開發。通過圖2可以看出,基于文獻挖掘的圖書館智慧化平臺建設的關鍵在于第二層次,即數據挖掘引擎的開發。一方面,數據挖掘引擎是將當前已經形成的圖書館數據庫中的文獻數據進行集中性的管理和挖掘的重要抓手,只有具備在海量數據信息中進行文獻資料數據關聯性分析的引擎功能,才能夠為讀者提供簡潔、快速的文獻挖掘功能支持;另一方面,前期的智慧化平臺建設實際上已經為基于文獻挖掘的圖書館智慧化平臺建設提供了相應的數據庫支持,目前需要做的就是結合相關文獻資料服務需求,開發具體的算法,賦予智慧化平臺更強大的數據整合、挖掘和分析處理能力,進而實現更精準的數據挖掘功能。因此,在當前的智慧化圖書館平臺建設中,相關工作的開展應當重點放在數據挖掘引擎的開發與應用上。
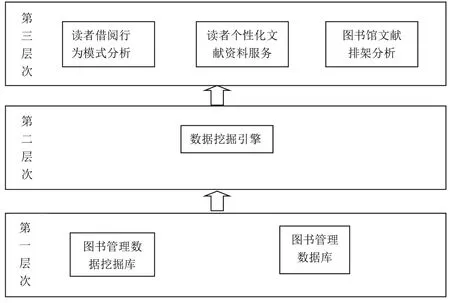
圖2 基于文獻挖掘的圖書館智慧化平臺的技術層次結構
(二)注重用戶行為數據的清洗。基于文獻挖掘的圖書館智慧化平臺的用戶包括管理者和讀者兩類,不同用戶在平臺上的操作行為存在個性化的差異。在平臺運行過程中,雖然用戶的行為都會產生相應的記錄,并被存儲到圖書管理數據庫中,但這些信息中不乏一些格式不規范、內容不完整的數據信息,對文獻挖掘會產生一定的干擾性影響,需要重點剔除和清洗。因此,在平臺建設中,技術人員要注意對用戶行為數據進行有效清洗,將采集到的用戶行為數據進行規范性處理,并在核實數據完備性的基礎上,過濾垃圾數據或者冗余數據,提高文獻挖掘的精準性。在大數據清洗過程中,技術人員可以使用技術手段與人工操作相結合的方式,以確保清洗行為的規范性和科學性。
(三)增強平臺數據轉換集成能力。基于文獻挖掘的圖書館智慧化平臺的運行是基于海量用戶尤其是讀者數據的基礎上實現的。如果無法保證平臺擁有足夠的數據資源,則很難實現深度的文獻挖掘目的。但是,在實際的平臺運行中,由于用戶使用終端設備的多樣性,以及用戶行為數據類型的差異,使得最終錄入到數據庫中的數據的結構和類型存在明顯的差異,難以完全匹配數據挖掘技術應用的要求。因此,在平臺數據庫的運維中,技術人員要注意對平臺的數據轉換集成能力進行優化和提升,形成統一的、標準的數據,供智慧化平臺文獻挖掘時使用。
四、結語
隨著圖書館服務的智慧化發展,開發基于文獻挖掘的圖書館智慧化平臺,逐漸成為高校圖書館發展中重點落實的任務。在數據挖掘技術的支持下,圖書館智慧化平臺可以圍繞讀者借閱行為模式分析、讀者個性化文獻資料服務和圖書館文獻排架等進行高效的文獻資料信息挖掘與利用,進而提高圖書館文獻資料使用的效率和效果。當前,智慧化平臺建設尚處于探索和深化階段,需要在做好數據挖掘引擎開發的同時,注重用戶行為數據的清洗和平臺數據轉換集成能力的增強,以保證基于文獻挖掘的圖書館智慧化平臺建設工作能夠有序推進,發揮實效。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
小太陽畫報(2018年1期)2018-05-14 17:19:25
電力與能源(2017年6期)2017-05-14 06:19:37
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
信息通信技術(2015年6期)2015-12-26 01:16:46
小天使·一年級語數英綜合(2014年6期)2014-07-22 23:32:38
小天使·一年級語數英綜合(2014年8期)2014-06-26 14:42:04
電子設計工程(2014年18期)2014-02-27 12:00:13
智慧與創想(2013年7期)2013-11-18 08:06:04
網球俱樂部(2009年9期)2009-07-16 09:33:54
