基于隨機森林算法的廣州白云機場終端區雷暴潛勢預報
2022-08-24 07:06:40楊潔曹正杜宇武凱軍李雅
熱帶氣象學報 2022年3期
關鍵詞:區域
楊潔,曹正,杜宇,武凱軍,李雅
(1.中國民用航空中南空中交通管理局氣象中心,廣東 廣州510405;2.中山大學大氣科學學院,廣東 珠海519082;3.中國民航大學航空氣象系,天津300300)
1 引 言
雷暴在華南夏季經常發生,常伴隨著強降水、風切變、冰雹、閃電、低能見度等天氣現象,對航空飛行正常運行易造成很大的影響。因此,雷暴潛勢預報對航空業務來說具有重要意義。很多學者建立對流指數來預測雷暴潛勢[1-7]。雷暴的產生機制較復雜,具有非線性特征。神經網絡算法具有非線性映射能力和并行性、適應性、容錯性及學習能力,被許多學者應用于雷暴潛勢預報。Agostino[8]采用神經網絡對探空資料和閃電定位資料進行訓練,來預報雷暴的發生以及閃電密度。陳勇偉等[9]基于BP神經網絡采用南京地區2008年的閃電定位資料和探空資料預報了南京地區2009年6—8月的雷暴潛勢。楊仲江等[10]利用閃電定位資料和探空資料,采用雙隱層BP神經網絡對太原地區的雷暴潛勢進行預報,發現雙隱層BP神經網絡比BP神經網絡、多元統計回歸法預報效果更好。周明薇等[11]根據2008—2010年夏季邵陽地區的NCEP全球再分析資料和閃電定位資料,采用支持向量機SVM分類算法建立了6小時雷暴潛勢預報模型。但是BP神經網絡算法為一種局部搜索的優化方法,采用了梯度下降法,學習速度慢,網絡訓練失敗概率大。Fernández-Delgado等[12]應用了179個分類器對UCI數據庫的相應數據集進行分類預測,發現隨機森林分類器的各項性能表現排在前5名,優于BP神經網絡。
隨機森林算法由Breiman Leo[13]和Adele Cutler等[14]提出,該算法結合了Breiman的“Bootstrap aggregating”(自舉匯聚法)思想和Ho[15]的“Random Subspace”(隨機子空間)方法。與BP神經網絡算法相比,隨機森林算法具有以下優點:(1)高準確度的分類器;(2)可處理大量的輸入變量;(3)可評估變量的重要性;(4)可在內部對于一般化后的誤差產生不偏差的估計;(5)可有效地估計缺失的數據并保持精度;(6)對于不平衡的分類資料集來說,可平衡誤差;(7)可計算個例中的親近度,對于數據挖掘、偵測離群點和將資料可視化非常有用;(8)可實現無監督聚類、數據視圖和離群點檢測;(9)可檢測可變相互作用。因此,隨機森林算法在遙感[16]、環境[17]、商業[18]、醫學[19]等方面得到廣泛應用。
廣州白云機場每天要制作兩次未來24小時重要天氣概率預報,其中雷暴是發生頻率最高的重要天氣,雷暴潛勢的預報十分重要。平時預報員分析預報雷暴的資料基本來源于天氣圖、數值模式,空間分辨率較大,都超過100 km。而機場預報要求精細化,100 km(廣州白云機場終端區范圍)內的雷暴潛勢預報基本靠天氣系統分析和經驗判斷,因此期望能有可靠的計算方法得到廣州白云機場終端區范圍內的雷暴潛勢預報。本文使用2014—2015年夏季雷達MAX圖(最大反射率圖)資料來獲得雷暴發生有無數據,結合探空數據建立廣州白云機場終端區內3類區域的12小時隨機森林分類模型,對不同區域的雷暴潛勢進行預報對比,以期獲得更高的預報準確率。
2 數據來源及處理
2.1 探空數據選取
選用2014—2015年夏季(6、7、8月)的探空數據和雷達MAX圖資料。其中探空數據來自美國懷俄明州立大學提供的清遠探空站和香港探空站,一日2次,分別是世界時00:00 UTC和12:00 UTC,共選取20個探空資料對流指數因子(表1)。表2為表1公式中出現的參數的釋意。
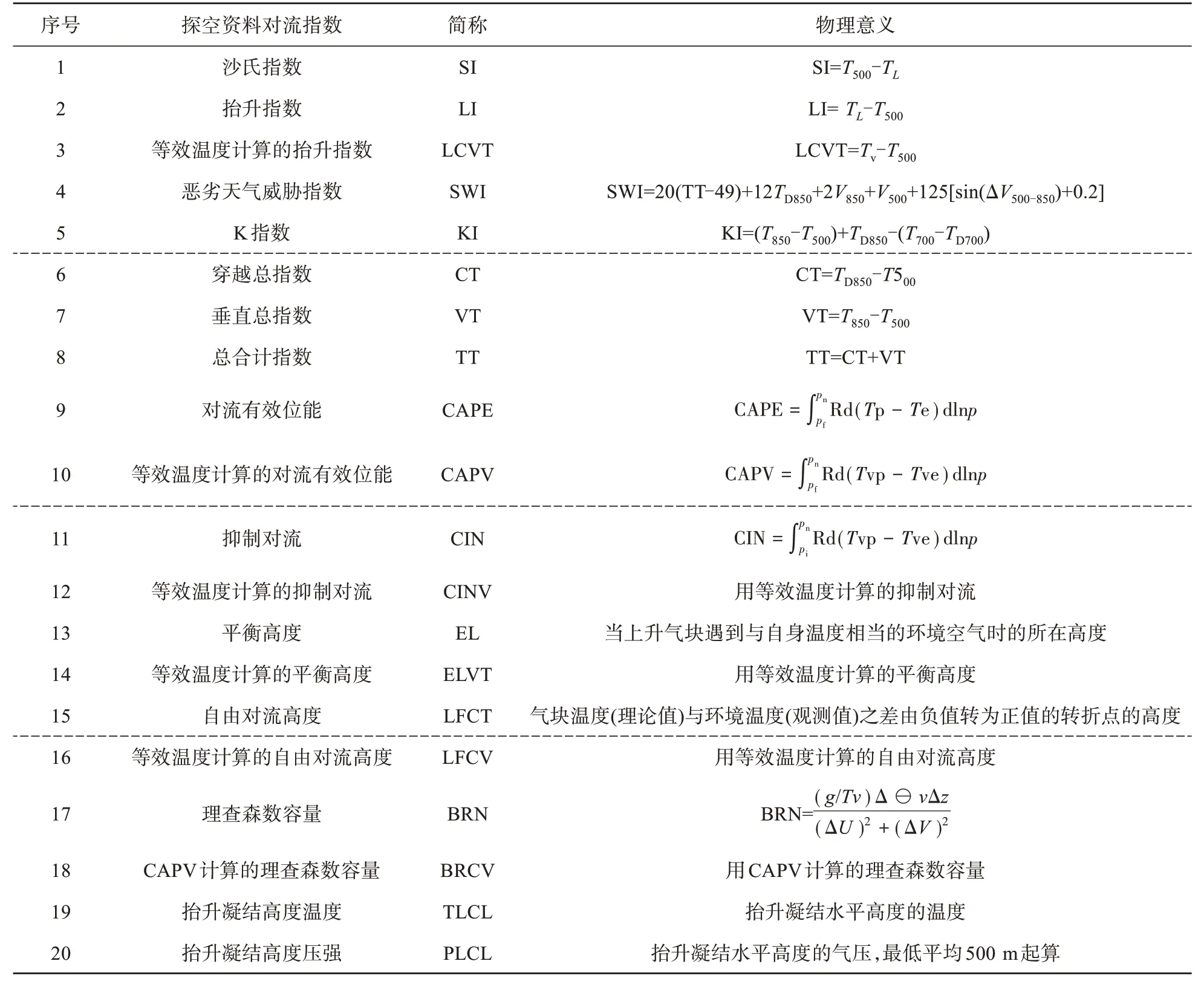
表1 懷俄明大學探空資料對流指數及其物理意義

表2 表1中公式中出現的參數的釋意
2.2 雷暴樣本選取
雷暴樣本在白云機場終端區內選取,以塔臺為中心,分別選取離塔臺8 km(區域1)、50 km(區域2)、100 km(區域3)的3個區域。雷暴發生有無根據雷達MAX圖(圖1)來判定,判別條件如下。
(1)雷達反射率因子大于等于35 dBZ。研究表明35 dBZ與成熟積雨云的降雨強度和閃電有很好的相關關系,而且常被選為識別和追蹤雷暴算法所選的閾值[20-23]。徐慧[24]、郭巍等[25]均利用雷達反射率因子大于等于35 dBZ作為標準來研究中國區域的對流初生,證明了這一標準在中國的適用性。同時在實際飛行中,機組多次反映當機載雷達探測到雷達反射率因子大于等于35 dBZ及其以上的云團就實施繞飛。
(2)雷達反射率因子大于等于35 dBZ區域在10 km以上的連續區域。對應的MAX圖中大于等于35 dBZ的像素點要超過23個。
(3)雷達最大反射率對應高度大于等于6 km,這是為了與低云區別開來。
出現滿足以上3個條件的情況,則判定為有雷暴發生。沒有雷暴發生的樣本記為1,有雷暴發生的樣本則記為2。如圖1所示,2014年6月23日05:40 UTC,區域1、2、3范圍內均有雷暴云團活動。
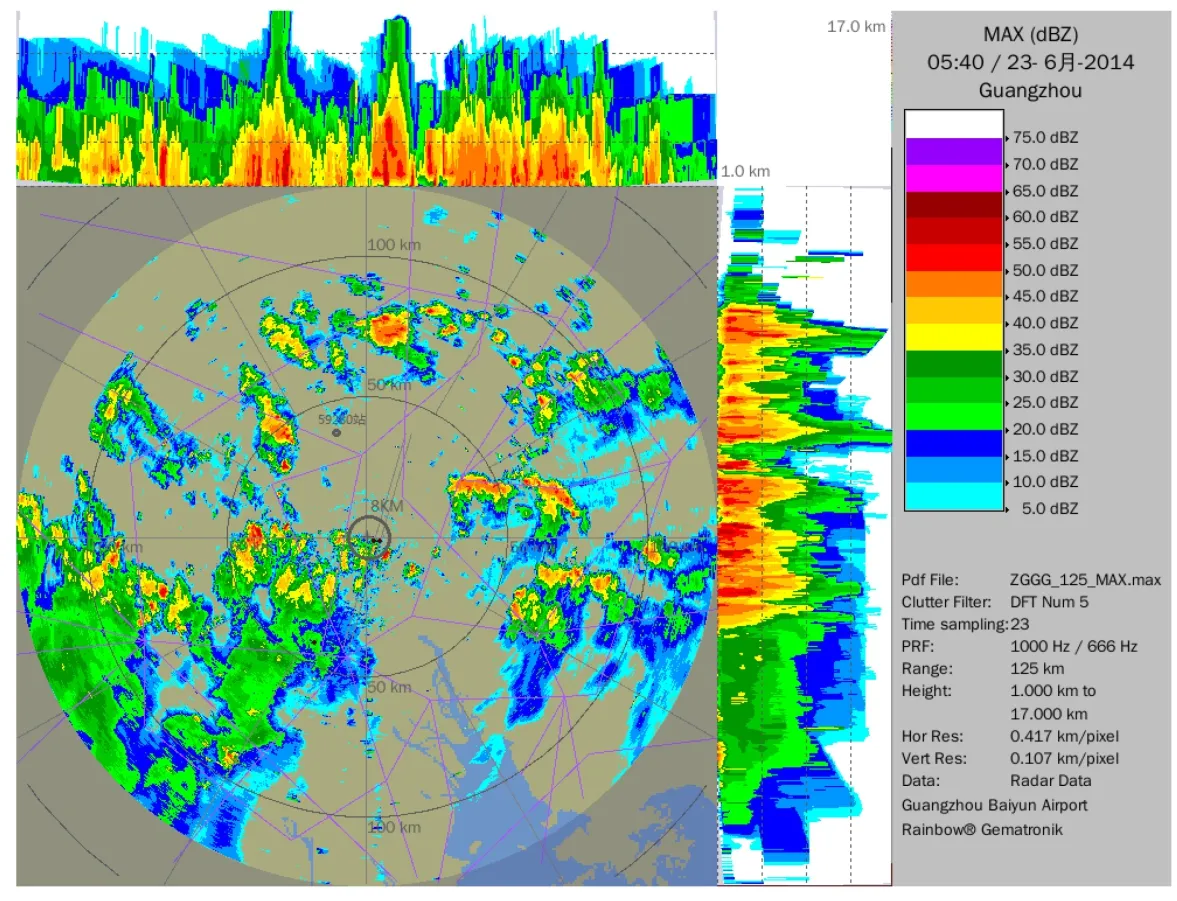
圖1 2014年6月23日05:40 UTC廣州白云機場125 km的MAX雷達回波圖 橫向和縱向1.0~17.0 km子圖為橫向和縱向雷達回波最大反射率對應的高度。三個圓圈分別表示以塔臺為中心,離塔臺8 km、50 km、100 km區域。右側文字說明為雷達的各種參數:時間(世界時),雷達雜波濾波方法(離散傅里葉變換),時間采樣,脈沖重復頻率(1 000 Hz/666 Hz),范圍(125 km),水平分辨率(0.417 km/pixel×0.417 km/pixel),垂直分辨率(0.107 km/pixel),高度范圍(1.0~17.0 km)。
2.3 樣本處理
將清遠探空站和香港探空站的探空數據進行距離線性插值法得到白云機場的探空數據。距離線性插值法如下:
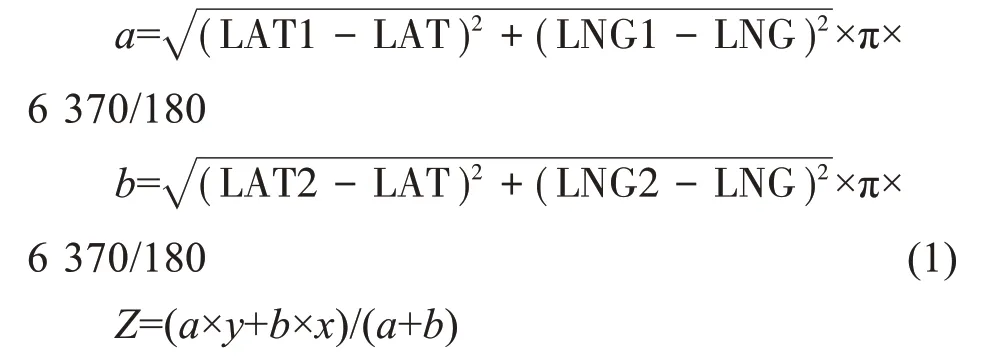
其中,LAT和LNG(本場經緯度)、LAT1和LNG1(清遠探空站經緯度)、LAT2和LNG2(香港探空站經緯度),a為清遠探空站到白云機場的距離,b為香港探空站到白云機場的距離,x為清遠探空站的探空數據,y為香港探空站對應清遠探空站的同一天同一時次的探空數據,Z為插值后的白云機場探空數據。
統計區域1、區域2范圍內、區域3范圍內雷暴發生與否數據共得三組數據。將同一天的00:00 UTC的探空數據與00:00—11:59 UTC雷暴發生與否數據匹配,12:00 UTC的探空數據與12:00—23:59 UTC雷暴發生與否數據匹配,因此每組樣本包含20個探空指數因子和1個雷暴發生與否數據。除去缺失資料的樣本,2014年的數據為183組,2015年的數據為182組,共計365組。其中區域1樣本組雷暴概率為135/365≈37%;區域2樣本雷暴概率為237/365≈65%;區域3樣本雷暴概率為277/365≈76%。
2.4 預報因子的選取
在篩選合適的輸入因子時,由于對流指數是連續型因子,雷暴發生與否為1、2非連續型變量,所以不能采用皮爾森相關系數一類的線性相關系數來衡量兩者的關系。灰色關聯度分析是研究因子間的幾何對應關系(即灰色關聯度),序列曲線的幾何形狀的相似程度與灰色關聯度成正比[26-27],它計算量小,適用于任何類型包括無規律的數據,在多因素,非線性領域得到廣泛應用[28-31]。
灰色關聯分析的步驟如下。
(1)確定雷暴發生與否數列和對流指數因子數列。設雷暴發生與否數列為X0′={X0′(k)|k=1,2,……,n};對流指數因子數列Yi′={Yi′(k)|k=1,2,……,n},i=1,2,……,m。這里m為指數因子個數20,n為樣本組數365。
(2)對指標數據進行無量綱化。由于各因子的物理意義不同,導致量綱不同,為了便于比較,采用均值化法(式(2))進行數據的無量綱處理。
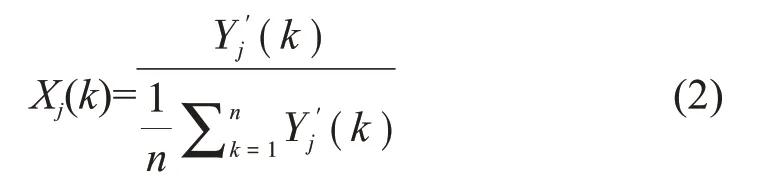
其中,j=0,1,……,20,k=1,2,……,365。
(3)計算每個對流指數因子數列與雷暴發生與否數列對應元素的絕對差值。即|X0(k)-Xi(k)|。
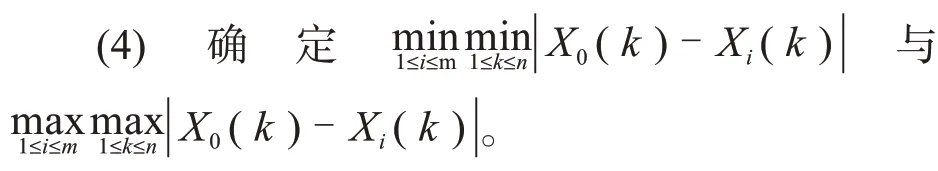
(5)計算每個對流指數因子數列與雷暴發生與否數列對應元素的灰色關聯系數ξi(k):
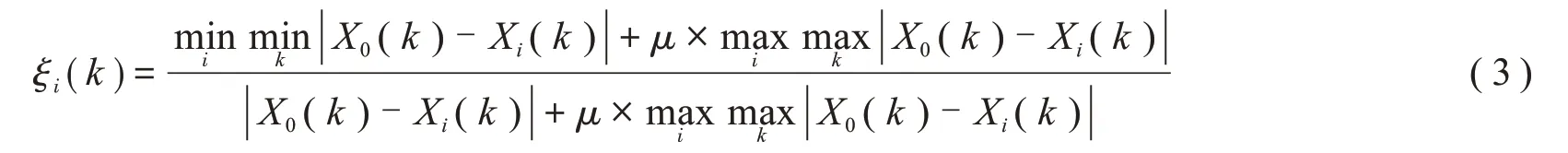
其中μ為分辨系數,此處取μ=0.5。
(6)計算灰色關聯度r0。分別計算各個指數與雷暴發生與否序列對應元素的均值即灰色關聯度r0i:
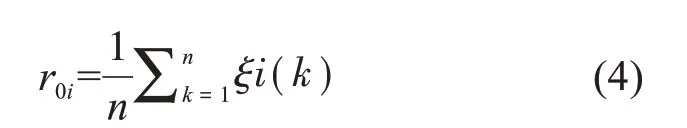
分別將20個對流指數因子與預報量(雷暴發生與否)作灰色關聯度分析,經過計算得到表3,表3為白云機場終端區區域1、區域2、區域3范圍內,20個對流指數與雷暴發生有無的灰色關聯度r0。區域1范圍內的r0平均值為0.968 9,大于平均值的指數由大到小依次為PLCL、SWI、BRCV、CT、KI、LFCV、TT、LFCT、BRN、VT、LCVT、CAPV、CAPE、LI。由于LI和LFCV、CAPE和CAPV物理意義近似,所以保留兩者中的大值LFCV、CAPV,刪去LI、CAPE。最終區域1選取了10個預報因子為PLCL、SWI、BRCV、CT、KI、LFCV、TT、LFCT、BRN、VT。同理,區域2的r0平均值為0.971 4,共選取了10個預報因子為PLCL、KI、CT、BRCV、SWI、LFCV、TT、VT、LCVT、CAPV。區域3的r0平均值為0.973 5,共選取了10個預報因子為
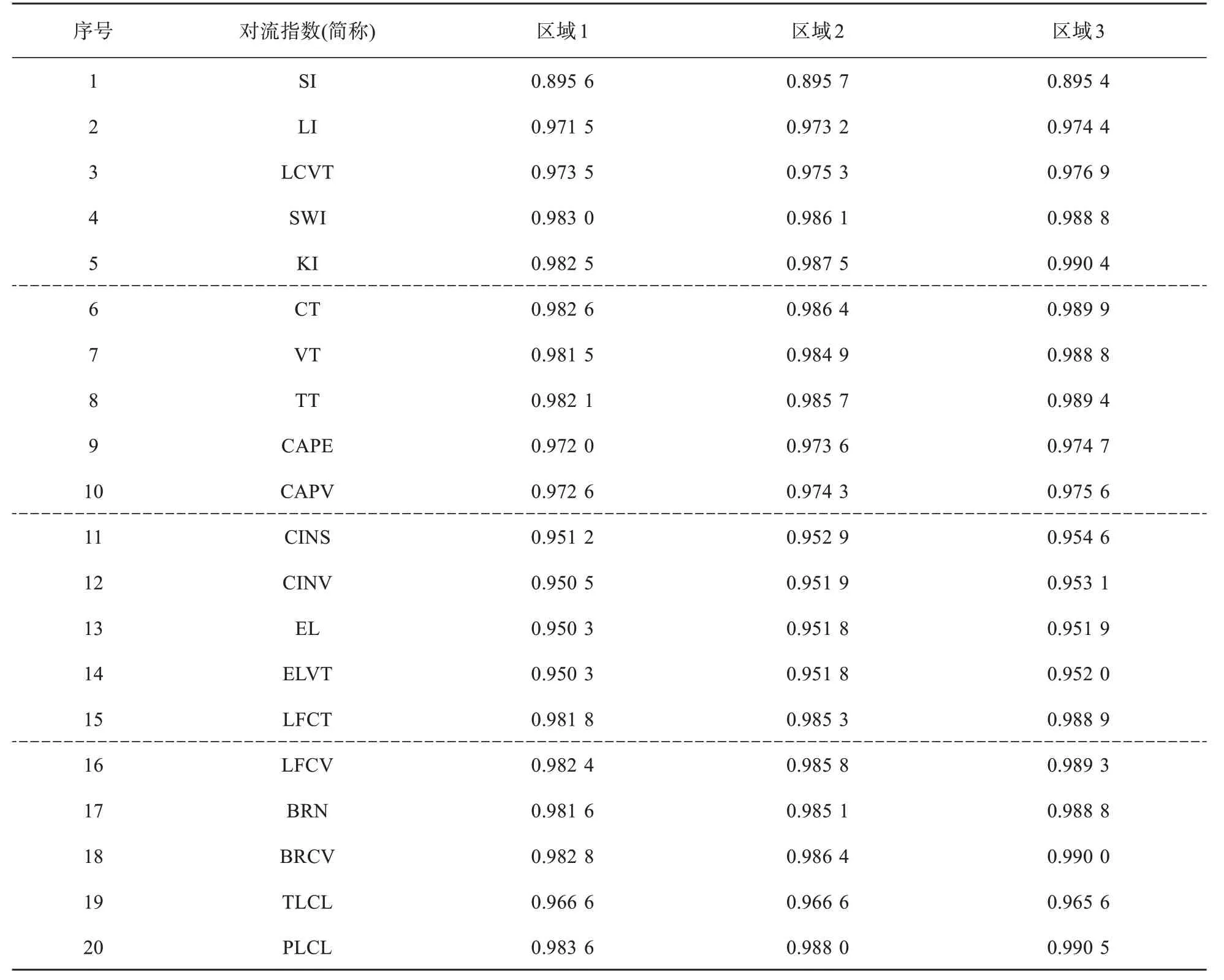
表3 白云機場終端區(區域1、區域2、區域3)20個對流指數與雷暴發生有無的灰色關聯度r0
PLCL、KI、BRCV、CT、TT、LFCV、SWI、VT、LCVT、CAPV。在白云機場終端區三個區域內,PLCL、KI、CT、BRCV、SWI、LFCV、TT、VT、LCVT、CAPV這10個對流參數與雷暴發生有無的灰色關聯度較大,其中PLCL、KI、CT、BRCV這4個指數的關聯度一直排在前五里,表明雷暴產生跟抬升凝結高度氣壓、850~700 hPa的溫度和露點溫度、風切變的關系最緊密。
3 隨機森林算法
隨機森林算法是一種包含多個無關聯的決策樹的分類器,并取所有決策樹中分類結果最多的那類為最終結果,其算法原理如下。
3.1 Bootstrap法重采樣
設集合Z為Z={Z(k)|k=1,2,……,n},若每次有放回地從集合S中抽取一個樣本,一共抽取n次,形成新的集合Z*,則集合S*中不包含某個樣本Z(i)(i=1,2,……,n)的概率為:
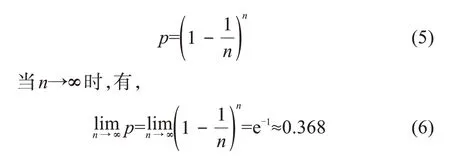
因此,通過Bootstrap法重采樣,除去重復的樣本,新集合Z*約占原集合Z中(1-0.368)×100%=63.2%的樣本。
3.2 隨機森林算法流程
(1)基于Bootstrap方法隨機產生R個訓練集Z1、Z2、……、ZR。
(2)每個訓練集生成對應的決策樹C1、C2、……、CR;設樣本的屬性個數為A,從A個屬性中隨機抽取aa(aa為大于0且小于A的整數)個屬性用最好的分裂方式對當前節點進行分裂,得到分裂屬性集。
(3)所有決策樹不剪枝。
(4)利用每個決策樹對測試集樣本X進行測試,得到對應的測試結果C1(X)、C2(X)、……、C R
(X)。
(5)將R個決策樹中輸出最多的分類類別作為測試集樣本X所屬的分類類別。
3.3 輸入輸出數據處理
為了對比分析,設立3個樣本輸入組:區域1樣本輸入組、區域2范圍內樣本輸入組、區域3范圍內樣本輸入組。其中區域1樣本輸入組包括365組10個預報因子,區域2范圍內樣本輸入組包括365組10個預報因子,區域3范圍內樣本輸入組包括365組10個預報因子。為了簡化計算,縮小量值,加快網絡收斂,將樣本輸入組進行[0.1,0.9]之間的歸一化:
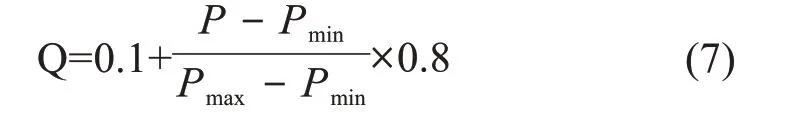
其中,P為歸一化前的樣本輸入數據,Pmin為P的最小值,Pmax為P的最大值,Q為歸一化之后的矩陣。
樣本輸出組為365組雷暴發生有無數據。365組輸入輸出樣本中,將183組用來訓練網絡,182組用于檢驗。
4 結果分析
4.1 區域1預報結果及泛化分析
本文采用randomforest-matlab開源工具箱進行計算。區域1共有10個預報因子,因此樣本的屬性個數A為10,分裂屬性個數aa為的取整數值3。為了減少隨機性的影響,決策樹顆數T分別取{50,100,150,200,……,950,1 000}共20種情況,每種情況運行100次模型,取其準確值(即測試結果里預報值1,實況值1和預報值2,實況值2的總和除以182)的最高值作為當前決策樹顆數下的分類正確率。圖2為區域1樣本輸入隨機森林模型中,決策樹顆數對性能的影響,可看到當決策樹顆數為400時,分類正確率最高。
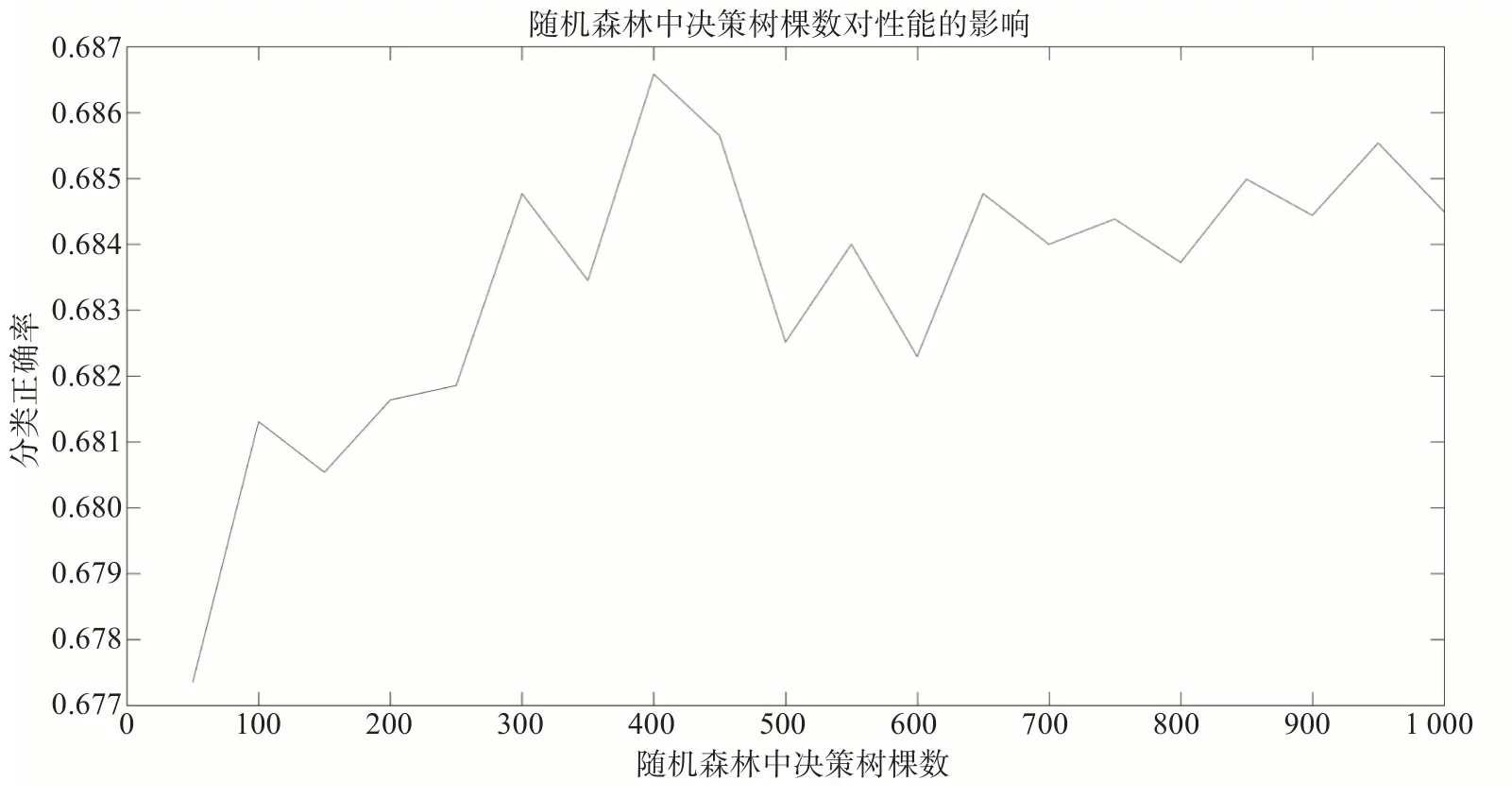
圖2 區域1樣本輸入隨機森林模型中,決策樹顆數對性能的影響
設立T=400,aa=3,運行隨機森林模型,將結果用兩變量預報驗證列聯表[32]表示得到表4。采用4個指數(如式組(8)所示)來評估預報結果,分別為:臨界成功指數CSI[33]、預報準確率AF[34]、虛假報警率FAR[32]和探測概率POD[32]。
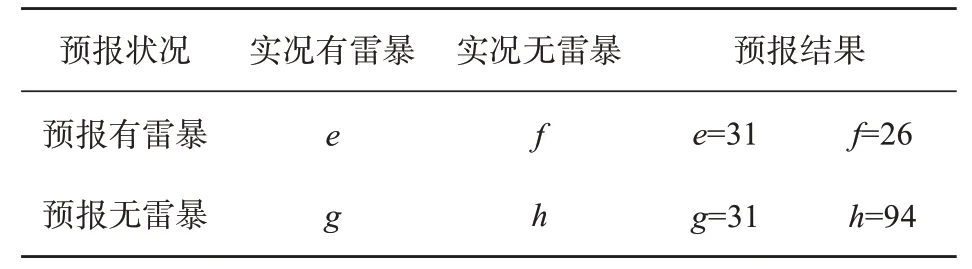
表4 12 h區域1隨機森林分類器預報結果
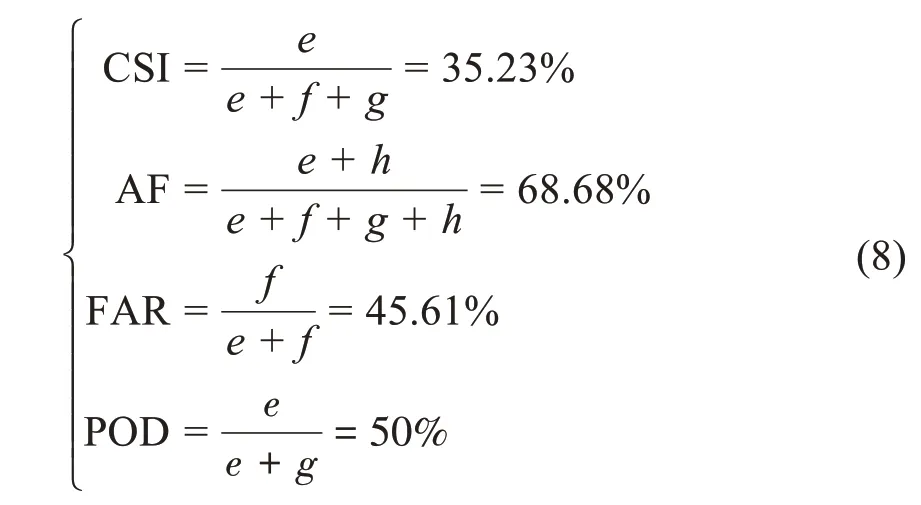
隨機森林有一個重要的特點:沒有必要對它進行交叉驗證或用一個獨立的測試集來獲得誤差的一個無偏估計。它可在內部進行評估,即在生成過程中就對誤差建立了一個無偏估計。袋外錯誤率oob是隨機森林泛化誤差的一個無偏估計,它的結果近似于需要大量計算的k折交叉驗證。如式(9)所示,區域1的袋外錯誤率oob為31.32%,表明超過2/3的樣本能正確分類,泛化性能較好。
4.2 區域2分析結果
區域2共有10個預報因子,因此樣本的屬性個數A為10,分裂屬性個數aa為的取整數值3。圖3為區域2范圍內樣本輸入隨機森林模型中,決策樹顆數對性能的影響,可看到當決策樹顆數為250時,分類正確率最高。
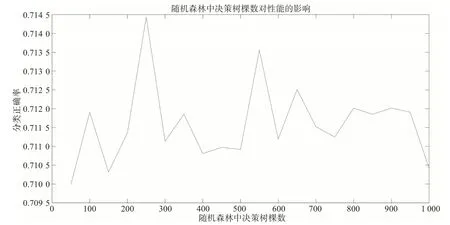
圖3 區域2范圍內樣本輸入隨機森林模型中,決策樹顆數對性能的影響
設立T=250,aa=3,運行隨機森林模型得到的結果為表5和式組(10)。對比區域1預報結果,CSI、AF、POD值都要高,而虛假報警率FAR值偏低,表明雷暴預報效果更好了。當雷暴未來24小時發生可能性大于70%時,航空重要天氣MDRS通報業務將啟動。預報準確率AF和探測概率POD超過70%,開始對業務有指示作用。區域2范圍內的袋外錯誤率為28.57%,泛化性能有提升。

表5 12 h區域2隨機森林分類器預報結果
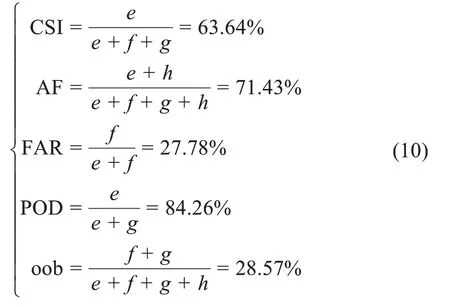
4.3 區域3范圍內分析結果
區域3共有10個預報因子,因此樣本的屬性個數A為10,分裂屬性個數aa為的取整數值3。圖4為區域3樣本輸入隨機森林模型中,決策樹顆數對性能的影響,可看到當決策樹顆數為100時,分類正確率最高。
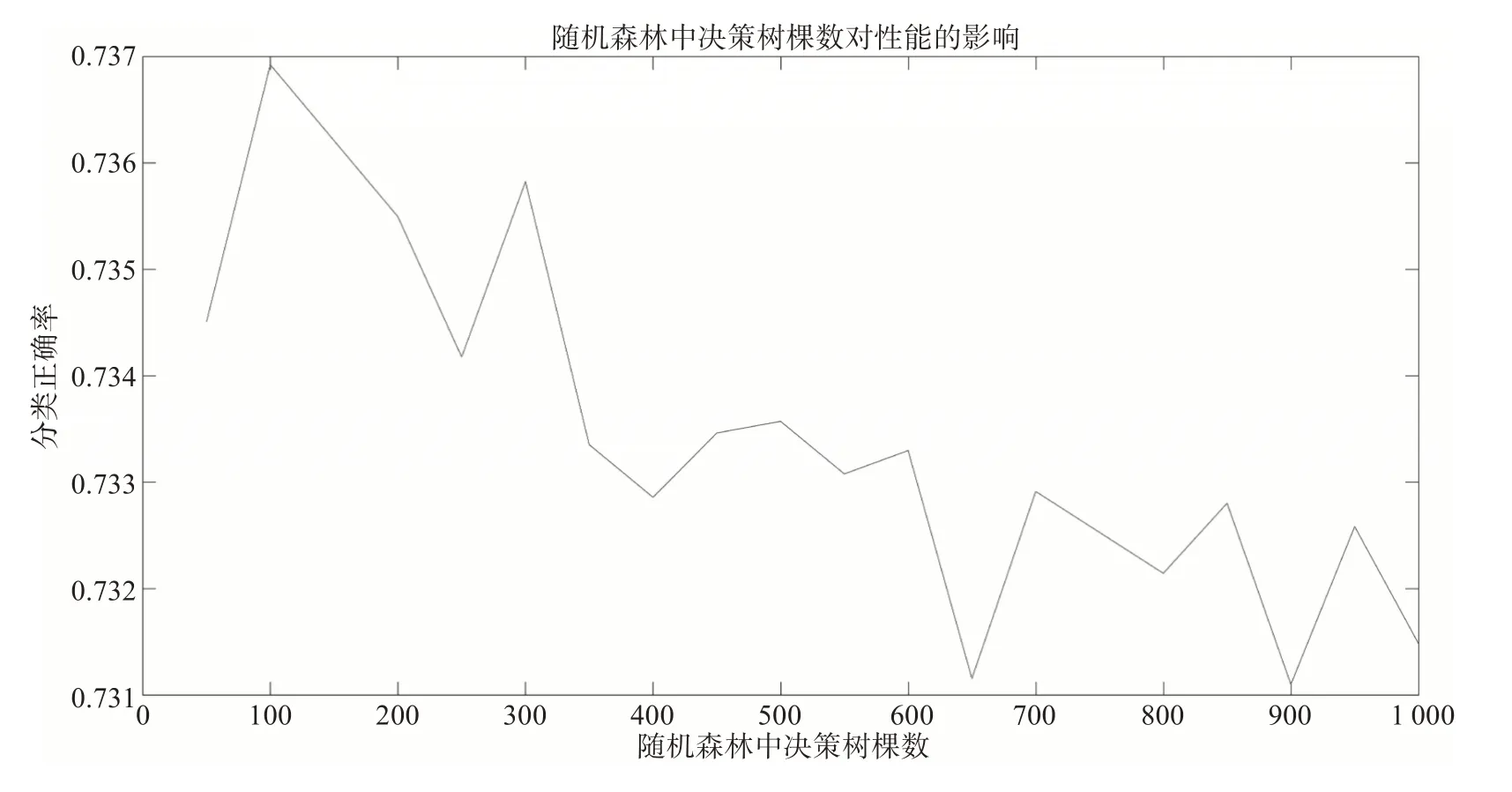
圖4 區域2范圍內樣本輸入隨機森林模型中,決策樹顆數對性能的影響
設立T=100,aa為的取整數值3,運行隨機森林模型得到的結果為表6和式組(11)。三組預報結果里,區域3的預報結果CSI、AF、POD值最高,而虛假報警率FAR值最低,表明雷暴預報效果最好。區域3的袋外錯誤率為24.73%,泛化性能不錯。

表6 12 h區域3隨機森林分類器預報結果

5 結 論
本文將2014—2015年夏季雷達MAX圖資料獲取雷暴發生有無數據,結合美國懷俄明州立大學探空數據建立廣州白云機場終端區3個區域的12小時隨機森林分類模型,通過對比可得到以下結論。
(1)白云機場終端區區域1、區域2、區域3內,PLCL、KI、CT、BRCV、SWI、LFCV、TT、VT、LCVT、CAPV這10個對流參數與雷暴發生有無的灰色關聯度較大。雷暴的產生跟抬升凝結高度氣壓、850~700 hPa的溫度和露點溫度、風切變的關系最緊密。
(2)終端區區域面積越大,雷暴發生樣本比例越高,臨界成功指數CSI、預報準確率AF、探測概率POD越來越高,虛假報警率FAR越來越低,表明預報出來的準確率越來越高。區域2、區域3的預報準確率AF和探測概率POD超過70%,給航空天氣預報員分析預報雷暴提供了參考,對航空重要天氣MDRS通報業務有指示作用。
(3)終端區三個區域的測試樣本超過2/3能得到正確分類,表明隨機森林算法泛化性能較好。區域范圍越大,袋外錯誤率越低,泛化性能越好。
猜你喜歡
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
科學(2020年5期)2020-11-26 08:19:22
軟件(2020年3期)2020-04-20 01:45:18
商周刊(2018年15期)2018-07-27 01:41:20
敦煌學輯刊(2018年1期)2018-07-09 05:46:42
北京教育·普教版(2017年1期)2017-02-05 13:26:23
新疆農墾科技(2016年2期)2016-08-21 13:50:16
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
新疆財經大學學報(2015年3期)2015-12-10 03:49:15
