紅外光譜數(shù)據(jù)融合對(duì)栽培滇重樓產(chǎn)地鑒別*
2022-09-02 03:56:50丁于剛張慶芝
云南中醫(yī)學(xué)院學(xué)報(bào) 2022年1期
丁于剛,張慶芝
(云南中醫(yī)藥大學(xué)中藥學(xué)院,云南 昆明 650500)
作為百合科多年生草本植物,滇重樓(Paris polyphylla var.yunnanensis)的根莖被廣泛應(yīng)用于中國(guó)、印度、不丹、尼泊爾等國(guó)家[1]。重樓在中國(guó)有超過(guò)兩千年的藥用歷史,最早被名為“蚤休”記錄于《神農(nóng)本草經(jīng)》中[2]并記其“味苦微寒,主驚癇搖頭弄舌,熱氣在腹中,癲疾,癰瘡陰蝕,下三蟲,去蛇毒”,現(xiàn)代藥理研究表明重樓具有抗腫瘤、凝血、抗氧化、抗炎鎮(zhèn)痛、抗微生物活性等[1]藥理活性。中國(guó)是重樓最大的生產(chǎn)國(guó)和消費(fèi)國(guó),在過(guò)去的40年間,重樓藥材的市場(chǎng)價(jià)從2.7元/kg增漲到了600~750元/kg[3]。隨著市場(chǎng)需求的增大,野生重樓藥材已經(jīng)不能滿足市場(chǎng)的需要。多樣的環(huán)境因素使得不同產(chǎn)地的栽培滇重樓化學(xué)成分也各有不同,且影響滇重樓的分布的主導(dǎo)因子與其地理環(huán)境息息相關(guān)[4]。因此,藥材的產(chǎn)地溯源對(duì)其質(zhì)量控制及合理開(kāi)發(fā)利用具有重要意義。滇重樓化學(xué)成分的差異主要體現(xiàn)在次生代謝產(chǎn)物甾體皂苷類化合物上,有研究表明不同產(chǎn)地、不同年份的滇重樓其化學(xué)成分具有較大的差異[5-6]。裴藝菲等采用多光譜技術(shù)對(duì)云南不同產(chǎn)地滇重樓進(jìn)行了分析,結(jié)果表明單一光譜建立的模型正確率較高[7]。目前為止,不同類型的檢測(cè)分析技術(shù)被成功應(yīng)用于鑒別滇重樓的來(lái)源,例如高效液相色譜法(HPLC,High performance liquid chromatography)[8-9]、超高效液相質(zhì)譜聯(lián)用(UHPLCMS/MS,Ultra-performance liquid chromatographytandem mass spectrometry)等[6]。然而,這些技術(shù)需要對(duì)樣品進(jìn)行復(fù)雜的預(yù)處理、有害試劑的使用、對(duì)實(shí)驗(yàn)員的高要求等,基于濕法的液相色譜法的方法不適于大量樣本的快簡(jiǎn)分析。振動(dòng)光譜結(jié)合化學(xué)計(jì)量學(xué)已然成為一種綠色、快捷的方法,這使得利用紅外光譜結(jié)合化學(xué)計(jì)量學(xué)對(duì)不同產(chǎn)地的栽培滇重樓的快速鑒別成為了可能。中級(jí)數(shù)據(jù)融合能減少大量的冗余和無(wú)關(guān)變量,在模式識(shí)別分析中更具有可靠性。通過(guò)采集云南和四川共8個(gè)產(chǎn)地的滇重樓根莖的近紅外和中紅外光譜數(shù)據(jù),光譜數(shù)據(jù)表征不同產(chǎn)地植物樣品的化學(xué)信息差異。結(jié)合多元變量提取方法,建立一個(gè)穩(wěn)定可靠的產(chǎn)地模式識(shí)別方法,以促進(jìn)云南不同產(chǎn)地栽培滇重樓的合理開(kāi)發(fā)利用。
1 材料與方法
1.1 實(shí)驗(yàn)材料 本研究實(shí)驗(yàn)樣品為栽培滇重樓的干燥根莖樣品,原植物采自我國(guó)西南的云南和四川省,包括保山、楚雄、大理、紅河、麗江、文山、玉溪和成都。所有采集原植物均經(jīng)云南中醫(yī)藥大學(xué)張慶芝教授鑒定為滇重樓(P.polyphylla var.yunnanensis)。所有樣品信息如表1所示,樣品采集后經(jīng)清洗干凈后切片,在50℃下烘干。后經(jīng)打粉機(jī)粉碎后過(guò)100目篩,所有樣品均置于干燥皿中待下一步分析。
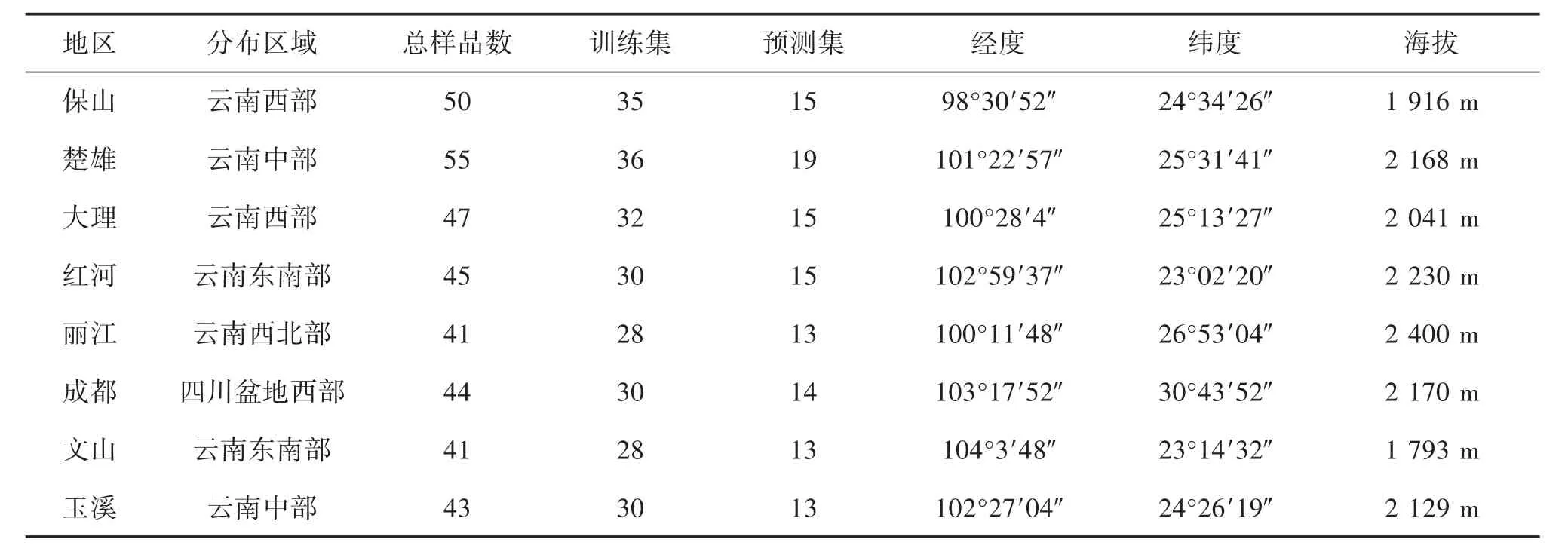
表1 重樓樣品信息表
1.2 紅外光譜采集
1.2.1 衰減全反射傅里葉變換中紅外光譜 衰減全反射傅里葉變換中紅外光譜采集自配備氘化三甘氨酸硫酸鹽(DTGS)檢測(cè)器和ZnSe衰減全反射元件的中紅外光譜儀。光譜采集范圍為4 000~650 cm-1,分辨率為4 cm-1,每個(gè)樣品累積掃描16次。經(jīng)過(guò)3次重復(fù)掃描后,得到了所有樣品的光譜數(shù)據(jù)。光譜采集室恒定的溫度和濕度由溫濕度控制儀進(jìn)行調(diào)控,所有采集得到的光譜數(shù)據(jù)由SIMCA-P+14.1進(jìn)行分析。
1.2.2 傅里葉變換近紅外光譜 重樓樣品的近紅外光譜由AntarisⅡ型光譜儀檢測(cè),儀器結(jié)合漫反射附件。光譜采集波數(shù)范圍為10 000~4000 cm-1,分辨率為4 cm-1。樣品采集室的溫度和濕度維持恒定的值,溫度(25℃,30%RH)。每次采集樣品光譜之前,空氣背景(CO2和H2O)會(huì)被校正以減小誤差。每個(gè)樣品平行檢測(cè)3次,3次后的平均光譜將用于進(jìn)行下一步分析。
1.2.3 紅外光譜數(shù)據(jù)預(yù)處理 從光譜檢測(cè)儀獲得的原始數(shù)據(jù)往往會(huì)包含一些干擾信息,它們來(lái)自環(huán)境因素、檢測(cè)器和其它因素等[10-11]。在本研究中,采用標(biāo)準(zhǔn)正態(tài)變量變換(SNV,standard normal variate transformation)[12]以減少由樣品物理狀態(tài)帶來(lái)的散射干擾,同時(shí)可以將變量平衡在0~1之間。
1.3 模式識(shí)別技術(shù) 在最初,偏最小二乘算法(PLS,partial least squares algorithm)被應(yīng)用于回歸問(wèn)題的處理。在偏最小二乘回歸中,變量矩陣Y(Y block)與訓(xùn)練集X(X block)按照常規(guī)方法配對(duì)[13]。一般來(lái)說(shuō),偏最小二乘判別分析(PLS-DA)應(yīng)用于特定情況如Y是類別數(shù)據(jù)。偏最小二乘判別模型的建立主要分為4步:數(shù)據(jù)預(yù)處理、降維、模型驗(yàn)證和決策。本研究運(yùn)用了7折交叉外部驗(yàn)證,R2(Coefficient of determination of model fitting)、Q2(Prediction)、RMSEE(Root mean squared error of estimation)、RMSEP (Root mean squared error of prediction)、RMSECV (Root mean squared error of calibration validation)等參數(shù)被用來(lái)評(píng)價(jià)模型的優(yōu)劣。一般來(lái)說(shuō),Q2大于0.5表明模型具有較好的預(yù)測(cè)能力,而模型的穩(wěn)定性則與R2有關(guān)。所有數(shù)據(jù)處理和建模均在SIMCA-P+14.1軟件完成。
1.4 特征變量提取 變量投影重要性(VIP,Variable importance for the projection)是衡量PLS-DA模型中單個(gè)變量對(duì)整個(gè)模型的影響的參數(shù)。VIP值為數(shù)值的均方根,一般來(lái)說(shuō),它代表了相關(guān)性[14]。選取VIP值大于1的變量建立模型能減少其他不重要變量帶來(lái)的干擾,從而提高分類效果。SPA的優(yōu)勢(shì)是能夠消除大量的冗余信息,適合于光譜特征波長(zhǎng)的篩選,并已被證實(shí)結(jié)合分類算法(如SPA-PLS-DA)具有較好的效果[15-16]。競(jìng)爭(zhēng)性自適應(yīng)再加權(quán)算法(CARS,Competitive adaptive reweighted sampling),有別于其他的特征變量篩選方法,主要通過(guò)自適應(yīng)再加權(quán)采樣技術(shù)選擇出偏最小二乘回歸系數(shù)絕對(duì)值較大的波長(zhǎng)點(diǎn),根據(jù)交叉驗(yàn)證選出RMSECV值最小的子集[17]。序列正交協(xié)方差特征變量選擇(SO-CovSel,sequential and orthogonalized covariance selection),通過(guò)對(duì)每個(gè)預(yù)測(cè)變量與所有變量之間的協(xié)方差進(jìn)行評(píng)估,篩選出協(xié)方差最高的變量作為特征變量[18]。基于以上原理,所有的預(yù)測(cè)因子和相應(yīng)的響應(yīng)值將會(huì)被統(tǒng)計(jì),并將重復(fù)以上過(guò)程,直至選擇出適當(dāng)?shù)淖兞繑?shù)。
光譜數(shù)據(jù)具有復(fù)雜、多維的特點(diǎn),本研究采用多種不同的特征變量提取方法旨在從不同的角度簡(jiǎn)化和提高模型的可解釋性。
1.5 多源數(shù)據(jù)融合策略 當(dāng)處理來(lái)自多傳感器的數(shù)據(jù)時(shí),多源數(shù)據(jù)融合策略(MSDF,Multi-sensor data fusion)是比較適用的方法。數(shù)據(jù)融合策略通過(guò)結(jié)合不同模塊的數(shù)據(jù),進(jìn)而分析可以得到相比單一來(lái)源數(shù)據(jù)更準(zhǔn)確和有效的決策[19]。總的來(lái)說(shuō),根據(jù)融合策略的不同,數(shù)據(jù)融合方法可分為數(shù)據(jù)級(jí)融合(Low level)、特征級(jí)融合(Mid-level)和決策級(jí)融合(Decision-level)。在本文中采用了2種數(shù)據(jù)融合策略進(jìn)行對(duì)比,以提高實(shí)驗(yàn)結(jié)果的準(zhǔn)確性。
2 結(jié)果與分析
2.1 光譜的特征解釋 根莖樣品的傅里葉變換中紅外光譜圖能夠反映化學(xué)信息,體現(xiàn)不同產(chǎn)地滇重樓的差異。在本研究中,來(lái)自8個(gè)產(chǎn)地的滇重樓中紅外和近紅外光譜數(shù)據(jù)均做了平均處理。如圖1所示,經(jīng)過(guò)二階導(dǎo)數(shù)的光譜相比于原始光譜更能反映出樣品的化學(xué)信息[20]。在二階導(dǎo)數(shù)的光譜中,共有20個(gè)顯著的吸收峰(2 927,2 852,1 745,1 459,1 415,1 372,1 336,1 240,1 204,1 154,1 106,1 079,1 049,1 020,995,925,896,863,767,711 cm-1)[21]。其中,3 334 cm-1的峰為羥基的伸縮振動(dòng)吸收,2 927、2 852、1 459、1 415 和 1 312 cm-1的吸收主要為來(lái)自亞甲基碳?xì)滏I的彎曲和伸縮振動(dòng)。在1 745 cm-1的較大吸收峰為碳氧雙鍵的伸縮振動(dòng),推測(cè)與甾體皂苷、黃酮、揮發(fā)油及多糖類物質(zhì)相關(guān)[22]。1 300~400 cm-1范圍的峰較為密集且復(fù)雜,為樣品的指紋圖譜區(qū)。
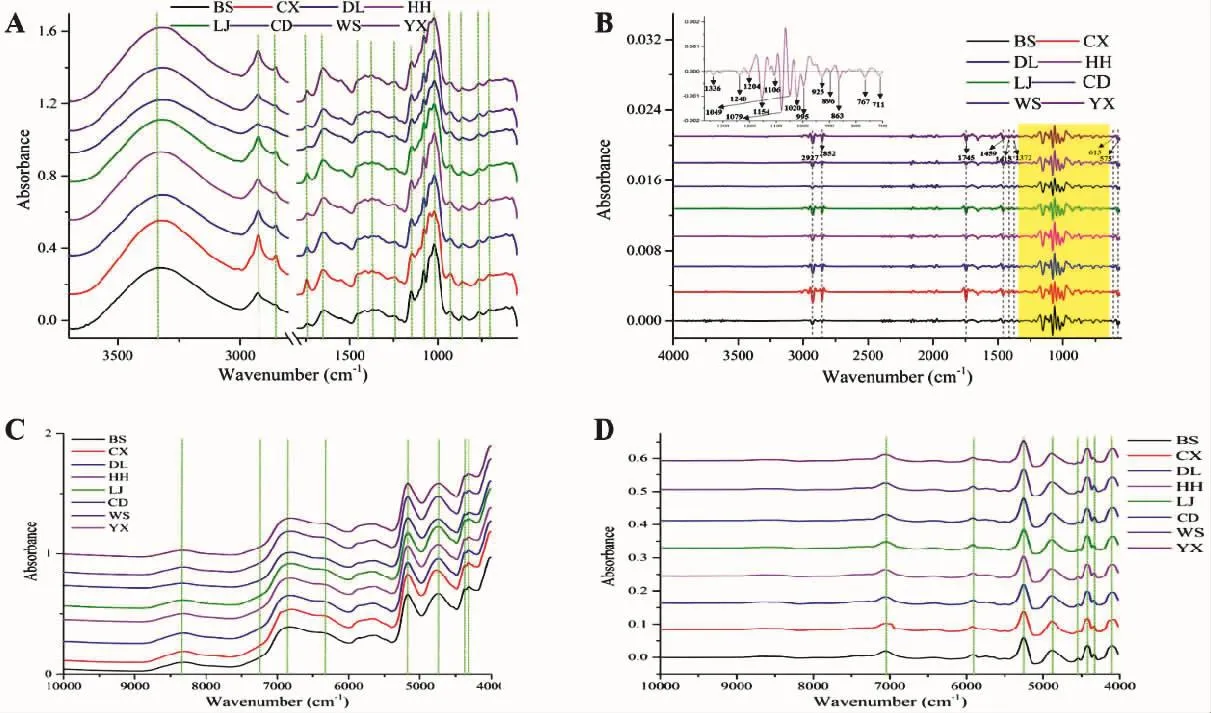
圖1 保山、楚雄、大理、紅河、麗江、成都、玉溪、文山的ATR-FTMIR和FT-NIR
相較于中紅外光譜,來(lái)自8個(gè)地區(qū)的平均近紅外光譜吸收峰較少。5 500 cm~4 200-1光譜區(qū)域?yàn)槠渲饕詹ǘ危摬ǘ蔚奈湛赡芘c碳?xì)滏I的變形和氧氫、氮?dú)洹⑻細(xì)浣M合模式的第二泛音有關(guān)[23]。位于7 200~5 500 cm-1的低頻區(qū)的2個(gè)吸收峰歸屬于碳?xì)洹⒀鯕浜偷獨(dú)滏I伸縮振動(dòng)的泛音,而碳?xì)洹⒀鯕浜偷獨(dú)滏I伸縮振動(dòng)的第二泛音則位于9 000~7 500 cm-1的弱吸收峰處[24]。整體上看,不同產(chǎn)地的中紅外和近紅外光譜吸收峰位置相同,但是強(qiáng)度略有差異,僅憑平均光譜圖的差異難以實(shí)現(xiàn)不同產(chǎn)地滇重樓的鑒別。
2.2 多源數(shù)據(jù)融合策略結(jié)合PLS-DA判別滇重樓產(chǎn)地
2.2.1 基于低級(jí)數(shù)據(jù)融合的PLS-DA 在本次實(shí)驗(yàn)中,通過(guò)SIMCA-P+14.1對(duì)采集自樣品的中紅外和近紅外光譜數(shù)據(jù)進(jìn)行轉(zhuǎn)換,共得到3 346個(gè)變量(FTNIR:1 557個(gè)變量,ATR-FTMIR:1 789個(gè)變量)。在進(jìn)行建模之前,先對(duì)所有來(lái)自8個(gè)大類的樣品進(jìn)行KS訓(xùn)練,將樣品分為2/3的訓(xùn)練集和1/3的預(yù)測(cè)集。在對(duì)原始數(shù)據(jù)進(jìn)行SNV預(yù)處理之后,中紅外和近紅外的數(shù)據(jù)被串聯(lián)建立PLS-DA模型。PLS-DA模型的最佳潛在變量數(shù)則是根據(jù)模型的交叉驗(yàn)證均方根誤差和Q2決定的,如圖2所示所有模型的最佳潛在變量數(shù)均已確定。模型參數(shù)如表2所示,訓(xùn)練集和預(yù)測(cè)集的正確率均達(dá)到了100%。
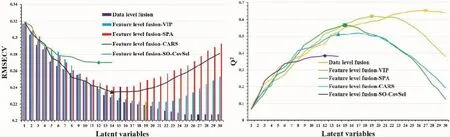
圖2 PLS-DA模型的最佳潛在變量數(shù)
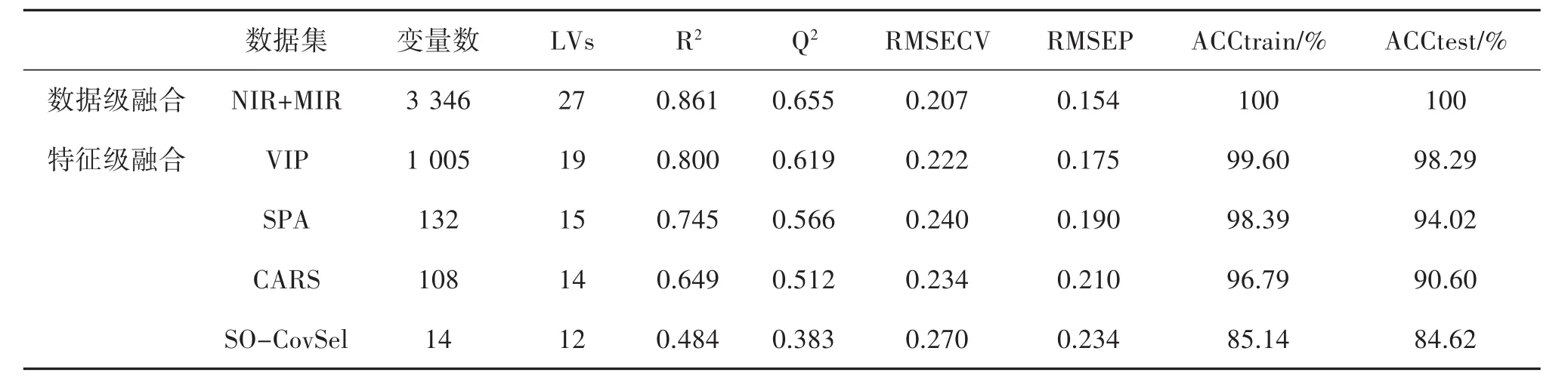
表2 基于數(shù)據(jù)融合的多種PLS-DA模型的參數(shù)值
2.2.2 中級(jí)數(shù)據(jù)融合結(jié)合PLS-DA 區(qū)別于低級(jí)數(shù)據(jù)融合較為龐大的計(jì)算量,特征級(jí)融合摒除了大量的冗余變量從而使模型較為簡(jiǎn)單[25]。基于VIP的特征變量選擇方法分別從中紅外和近紅外數(shù)據(jù)中篩選出VIP值大于1的變量,這505和500個(gè)變量將被視為重要變量進(jìn)行下一步分析[26-27]。根據(jù)VIP-PLS-DA模型可知,最佳潛在變量數(shù)為19,訓(xùn)練集正確率達(dá)到100%,訓(xùn)練集正確率達(dá)到99.60%,只有預(yù)測(cè)集中有2個(gè)樣品被錯(cuò)誤分類。
基于SPA選擇的特征變量來(lái)自光譜的各個(gè)波段。來(lái)自不同傳感器的特征變量組成一個(gè)新的366×132的數(shù)據(jù)集,根據(jù)模型可知,其最佳LVs為15,模型預(yù)測(cè)集正確率為94.02%。根據(jù)競(jìng)爭(zhēng)性自適應(yīng)再加權(quán)算法的原理可知,在交叉驗(yàn)證均方根誤差最低時(shí)篩選的變量為最佳變量數(shù)。隨著模型運(yùn)行次數(shù)的增加,交叉驗(yàn)證均方根誤差呈高-低-高的變化趨勢(shì),無(wú)關(guān)冗余變量被剔除,均方根誤差減小,在最佳變量數(shù)時(shí)達(dá)到最低值。但隨著采樣的繼續(xù)進(jìn)行,RMSECV增加是因?yàn)橄吮匾淖兞俊W罱K共有32和76個(gè)變量參與模型的建立。采用SO-CovSel特征變量篩選方法篩選的變量數(shù)較少,分別為(10×366)和(4×366)變量并進(jìn)行下一步建模分析。結(jié)果表明,基于低級(jí)數(shù)據(jù)融合的效果最佳,訓(xùn)練集和預(yù)測(cè)集正率均達(dá)到了100%。而基于SO-CovSel方法的模型效果最差,預(yù)測(cè)集正確率僅有84.62%。
3 討論
從8個(gè)產(chǎn)地的滇重樓平均中紅外光譜圖可以得出,來(lái)自四川成都的樣品在3 000~2 800 cm-1與其它產(chǎn)地具有較為明顯的差異,這可能是四川盆地相對(duì)獨(dú)特的氣候條件所致。Yang等通過(guò)超高效液相色譜-紫外串聯(lián)質(zhì)譜法(UHPLC-UV-MS,Ultra-performance liquid chromatography-ultraviolet spectroscopy-tan-dem mass spectrometry)檢測(cè)了不同產(chǎn)地滇重樓的皂苷類成分含量,結(jié)果顯示云南省南部地區(qū)總皂苷的平均值顯著高于中部地區(qū)[6]。表明不同產(chǎn)地的滇重樓,其有效成分的差異較為明顯。
根據(jù)模型正確率和參數(shù)表明(表2),基于低級(jí)數(shù)據(jù)融合建立的偏最小二乘判別分析模型效果最優(yōu),低級(jí)數(shù)據(jù)融合通過(guò)串聯(lián)不同傳感器的信息能最大限度的保留樣品的化學(xué)信息。在中級(jí)數(shù)據(jù)融合中,最終變量數(shù)較多的模型其參數(shù)較優(yōu),正確率較高。這可能是因?yàn)樵谌コ罅咳哂嘈畔⒌耐瑫r(shí),許多對(duì)建立模型有效的變量也被去除。令人意外的是,基于SPA變量選擇方法的模型效果達(dá)到了94.02%,因其只在較少的變量上進(jìn)行分析,表明該方法具有較好的泛化能力。
4 結(jié)論
本研究通過(guò)紅外光譜技術(shù)結(jié)合數(shù)據(jù)融合方法,采用PLS-DA模型對(duì)來(lái)自四川和云南8個(gè)產(chǎn)區(qū)的栽培滇重樓進(jìn)行了鑒別分析。在特征級(jí)數(shù)據(jù)融合中采用了多種特征變量提取方法,結(jié)果表明基于VIP特征變量提取方法模型結(jié)果較優(yōu),其正確率達(dá)到99.60%,預(yù)測(cè)集中只有2個(gè)樣品被錯(cuò)誤分類。綜合兩種數(shù)據(jù)融合類型,初級(jí)數(shù)據(jù)融合的模型效果最優(yōu),分類正確率達(dá)到了100%。綜合模型可知不同傳感器來(lái)源的數(shù)據(jù)具有協(xié)同性,該方法能夠成功應(yīng)用于不同產(chǎn)地滇重樓的鑒別。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
無(wú)線電工程(2020年11期)2020-10-29 01:25:46
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
