基于深度強化學習的高速飛行器攻防博弈
2022-09-09 01:50:20何湘遠余卓陽
航天控制 2022年4期
何湘遠 塵 軍 郭 昊 余卓陽 田 博
空間物理重點實驗室,北京 100076
0 引言
高速飛行器以其飛行速度快,變軌能力強而受到世界各軍事大國的廣泛研究[1]。機動突防是高速飛行器一種有效的突防手段[2]。傳統程序式機動由于手段較為固定,未能根據攔截彈實際情況有的放矢,因此突防效果欠佳,存在一定的局限性。微分對策是近些年發展較快的一種智能突防方法,與傳統程序式機動策略相比,兼具實時性與智能性[3]。文獻[4]將脫靶量和能量消耗作為EKV與彈頭對抗指標,考慮彈頭機動過載和控制變量約束,建立了該方法下的突防決策模型。文獻[5]將彈道導彈攔截問題描述為二人零和微分對策模型,并得到了在捕獲區無論突防彈采取何種策略都將被攔截,反之在逃脫區突防彈采取最優策略則必定突防成功的結論。文獻[6]考慮在目標有防御器時的三星博弈場景,采用博弈切換策略將其分解為分段雙星博弈,使得攔截器在不被防御器反攔截的情況下實現對目標的快速攔截。文獻[7]設計了一種基于狀態相關Riccati方程的微分對策制導率,得到的結果優于經典微分對策。針對經典微分對策計算量較大的問題,文獻[8]將深度神經網絡與微分對策相結合,采用經典微分對策生成樣本用于訓練,生成的機動策略與傳統策略基本一致,且兼具較好的實時性。
深度強化學習是近年興起的人工智能領域中的研究熱點,并在例如游戲博弈[9]、機器人控制[10]、制導控制技術[11]當中取得了十分驚人的效果。2013年谷歌DeepMind團隊提出了Deep Q-learning算法,該算法也被視為是第一個深度強化學習算法[12]。文獻[13]提出了一種改進的DQN算法,被稱之為雙重深度Q網絡算法(DDQN)。該算法很好的緩解了DQN在采取最大化操作時造成的Q值過估計問題。深度強化學習的發展為高速飛行器機動突防提供了一種新的解決方案。深度強化學習以其能夠處理高維抽象問題,且可迅速給出決策[14]等優點,有望被應用于攻防博弈決策控制中。文獻[15]對經典DQN進行了改進,設計了一種深度神經網絡架構競爭雙深度Q網絡(D3Q),實現了對彈道導彈中段突防最優控制模型的逼近。文獻[16]利用深度確定性策略梯度算法(DDPG)對巡飛彈突防控制決策進行了求解,并驗證其有效性。文獻[17]以智能小車追逃來模擬導彈攻防過程,在二維平面上采用經典DDPG算法實現了智能小車的控制,并能夠較好地完成追捕任務。面對經典DDQN算法隨機均勻抽樣易忽視罕見且具有高學習價值樣本的問題,文獻[18]提出了基于時序差分誤差(TD-error)的優先經驗回放技術,有效提高了學習過程中的樣本利用效率。文獻[19]提出了基于累積回報值的優先級經驗回放方法。然而高速飛行器攻防博弈場景動作空間和狀態空間維度大,非線性強,以TD-error計算優先級時優先級較高的往往是對抗轉移至終端狀態時刻的樣本,這使得智能體容易過多關注臨近結束時的策略學習而缺乏對其余樣本的學習。而以獎勵值計算優先級容易使智能體過多關注成功樣本,訓練樣本缺乏多樣性。
針對上述問題,本文設計了一種基于經典DDQN的改進算法,通過結合累積獎勵值與累積TD-error,采用模糊推理將一輪對抗樣本整體存儲至不同經驗池中,并通過積分抽樣器從中抽取樣本進行學習。仿真結果表明,該方法能有效提高智能體對樣本的利用效率。
1 攻防對抗模型
1.1 攻防對抗場景
一對一突防是一種典型的攻防對抗場景,本文考慮逆軌攔截,建立地面坐標系odxdydzd下的攔截器與飛行器的三自由度運動模型,其示意圖如圖1所示:
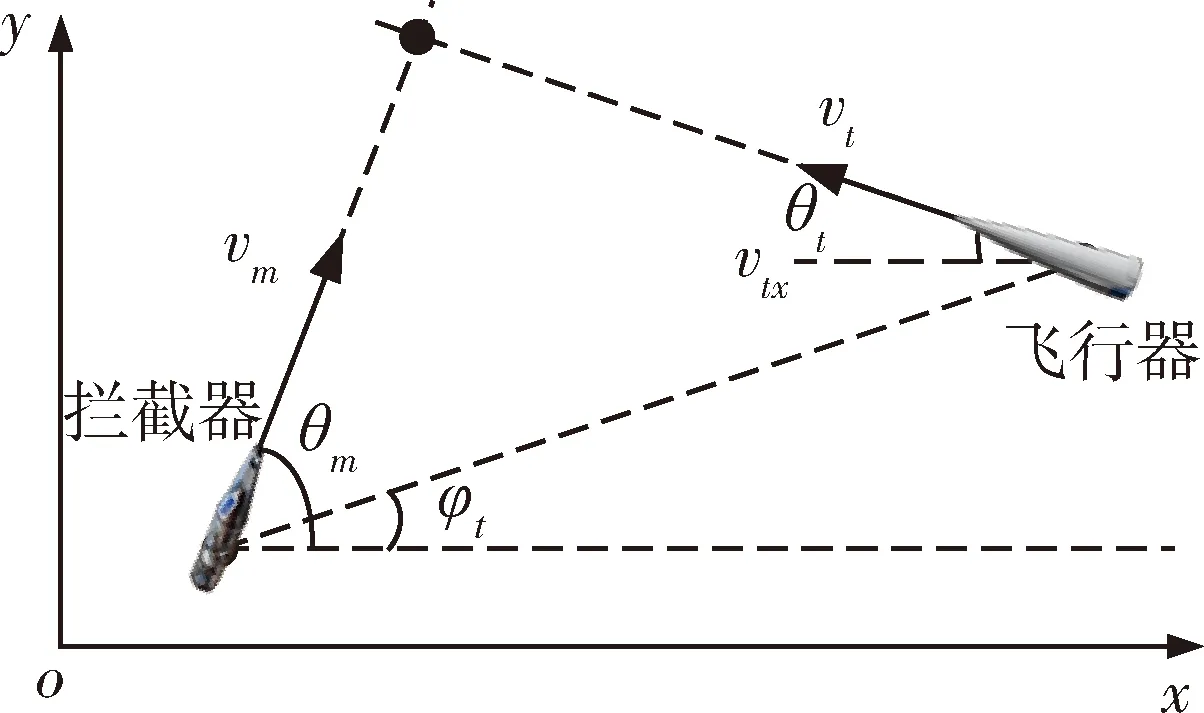
圖1 攻防對抗示意圖
攔截器在初始狀態下飛向預測交會點,由于對抗過程時間較短,為簡化模型,預測交會點由飛行器和攔截器在零控狀態下按照勻加速直線外推得出。
攔截器采用4臺液體軌控發動機進行機動,其推力為2300N,比沖2900N·s/kg,攔截器橫縱向導引率采用的是真比例導引,其制導指令分別為:
(1)
其中,導引系數ky=kz=4,突防成功判據為脫靶量Rf>3m。
2 攻防博弈決策算法
2.1 MDP決策控制模型
馬爾科夫決策過程(Markov Decision Process,MDP)是強化學習的基礎,其決策過程如圖2所示:
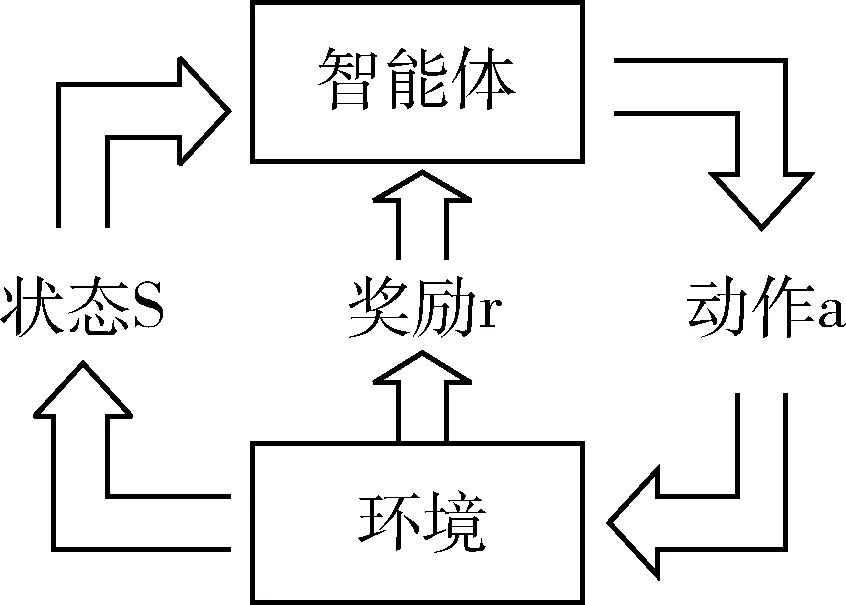
圖2 馬爾科夫決策過程
MDP一般由五元組
在本文中,狀態轉移由攻防雙方動力學方程唯一確定,因此可認為狀態轉移概率P為1。飛行器需要不斷通過與攔截器對抗,并從中獲取經驗和獎勵,用于改進自身策略,以達到成功突防并減少自身機械能消耗的目的。
1)狀態空間設計
狀態空間應盡可能完整地描述攻防雙方的位置、運動特征以及自身的飛行狀態等關鍵信息,而攻防對抗往往更關注的是其相對運動信息,用相對參量代替絕對參量能夠減少狀態空間維度,提高模型訓練效率,這里設計狀態空間為:
(2)
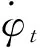
2)動作空間設計
由于DDQN的動作空間是離散的,因此需要將飛行器原本連續的動作空間離散化。高速飛行器氣動外形一般為面對稱結構,主要通過控制攻角和傾側角完成機動。若直接將指令攻角、指令傾側角離散,則會導致動作空間隨指令攻角、指令傾側角的細分而過于龐大,給動作搜索帶來困難。且受限于飛行器姿控系統能力,將有大量動作因超出控制系統閾值而等效。無法體現出不同動作的差異性,給模型的訓練帶來困難。因此這里設計動作空間為:
(3)
即在某時刻,指令攻角和指令傾側角可選擇增加、不變或減少其在決策周期內調姿能力的最大值。這樣隨著決策周期縮短,攻角和傾側角曲線將逼近真實曲線,且動作空間維度不變,避免了動作空間過于龐大的問題。
3)獎勵函數設計
強化學習的核心概念是獎勵,強化學習的目標是最大化長期的獎勵[20]。一個良好的獎勵函數應能正確反映設計人員的目的,且能夠給予智能體正確的引導,避免智能體僅關心獎勵值,卻違背設計人員預想目標的“獎勵黑客”問題[21]。對于進攻方,其目的主要有2個:1)成功規避攔截器的攔截;2)在目的1)的基礎上盡可能減少自身躲避機動時的機械能損耗。因此設計人員只關注其對抗結束時的終端狀態,但若只引入終端狀態下的獎勵,則會導致獎勵過于稀疏,且訓練時不能給智能體以正確的過程引導,給智能體訓練帶來極大困難。因此這里設計獎勵函數為:
(4)
即獎勵函數由過程獎勵rc和終端獎勵rf組成,過程獎勵包括決策周期內攔截器燃料消耗Δmm和飛行器機械能損失ΔEt,km和kt為比例因子。終端獎勵包括突防失敗和成功2種情況:若突防失敗,則獎勵值為-10,若突防成功,則獎勵值為10+log2(Rf-2),其中Rf為脫靶量。這里引入脫靶量獎勵是為給智能體訓練進行引導,讓其適當追求較大脫靶量。
2.2 DDQN損失函數
DDQN(Double Deep Q Network)是DQN的一種改進算法,其通過改進損失函數解決了DQN出現的過估計問題[13]。在DQN中,損失函數計算如下:
(5)
即DQN對動作的未來價值由狀態st+1下目標網絡計算所有動作中Q值最大值來評價。而DDQN將損失函數修改為:

(6)
即DDQN在評價狀態-動作值函數時不再用參數為θ′的網絡計算最大Q值,而是用參數為θ的網絡選取動作,用參數為θ′的網絡評估狀態-動作值函數。
2.3 樣本模糊推理模型
在攻防博弈問題中,樣本Q值的TD-error和樣本獎勵值均可評價樣本的重要程度。TD-error越大的樣本意味著神經網絡所擬合的Q值誤差越大,也就越值得學習。DDQN算法的TD-error計算如下:
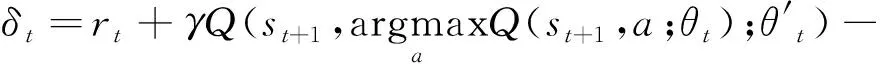
(7)
定義樣本的優先級為:
pi=|δt|+ε
(8)
其中,ε為一非零小量,以保證TD-error為0的樣本也有概率被采到。
樣本的優先級雖然一定程度上體現了樣本的重要程度,但以TD-error評價樣本優先級時忽略了獎勵值對智能體的作用。并且在飛行器攻防博弈場景下,優先級較大的樣本往往是飛行器轉移至對抗終端時刻的樣本,而攻防對抗過程早期所采取的策略對終端狀態有較大影響,因此僅以TD-error為標準進行抽樣會使智能體過多關注對抗結束時刻的策略。而好的策略在對抗初期雖然獎勵值較小,優先級較低,但依然擁有較大學習價值。獎勵值雖也可用于評價樣本重要程度,但若單獨依靠獎勵值評價樣本,又會使智能體僅關注突防成功的樣本,學習樣本缺乏多樣性。
針對上述問題,本文將一次對抗的所有樣本作為一個完整單元,以一個單元的累積獎勵與累積TD-error作為模糊推理的輸入,并依靠模糊推理評價該單元樣本的好壞程度。
模糊計算過程可以劃分為模糊規則庫、模糊化、推理方法和去模糊化4個部分[22]。根據仿真經驗,設計獎勵值對應論域為[-0.5,1],TD-error對應論域為[0,1.2],本文設計隸屬度函數為如圖3所示,其中{PS,PM,PN}分別對應模糊標記{正小,正中,正大}。
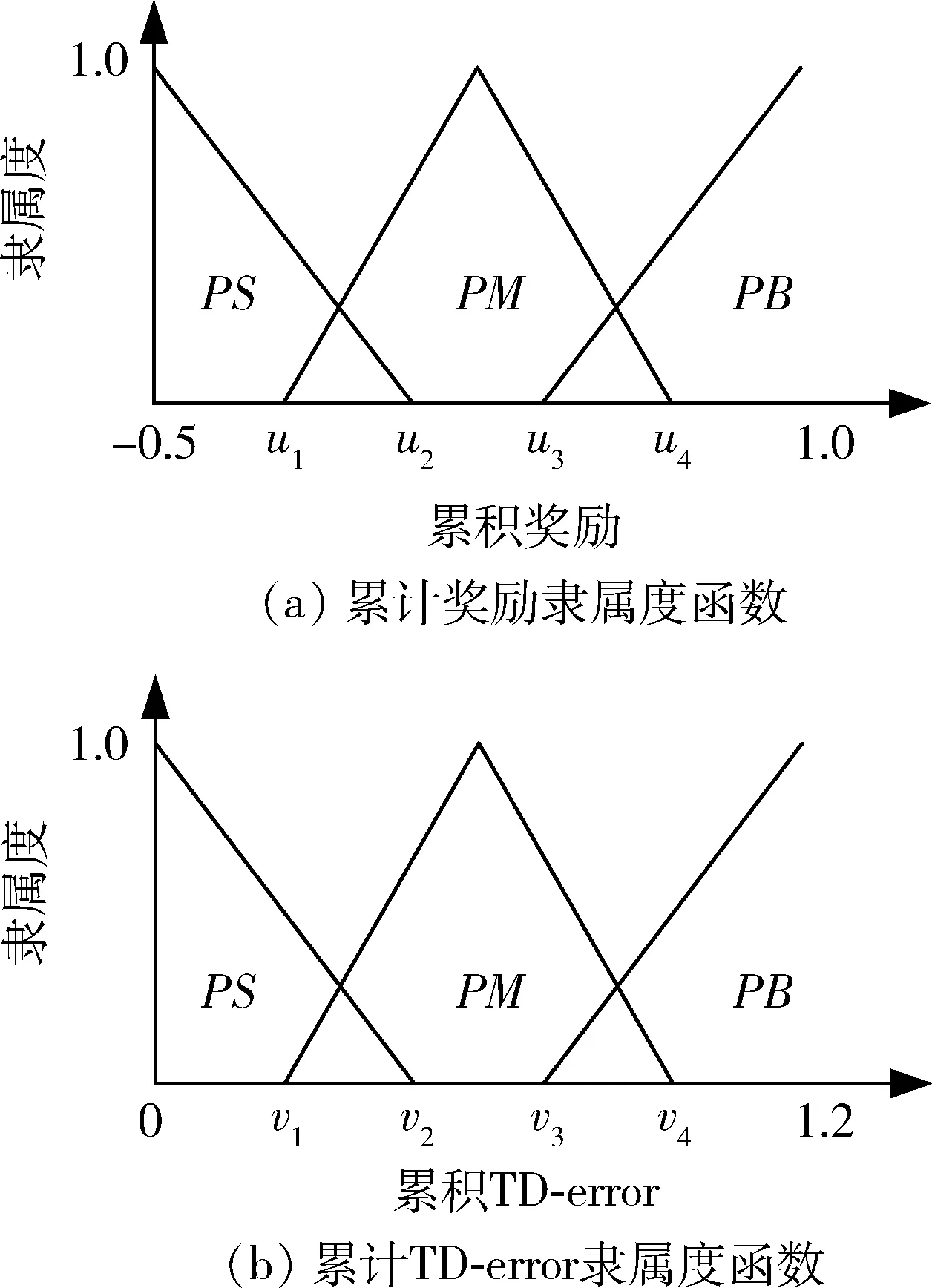
圖3 輸入值與輸出值隸屬度函數
根據累積獎勵與累積TD-error所計算出的隸屬度,需要根據專家經驗建立模糊推理規則表。根據仿真經驗,本文設置模糊推理規則如下:
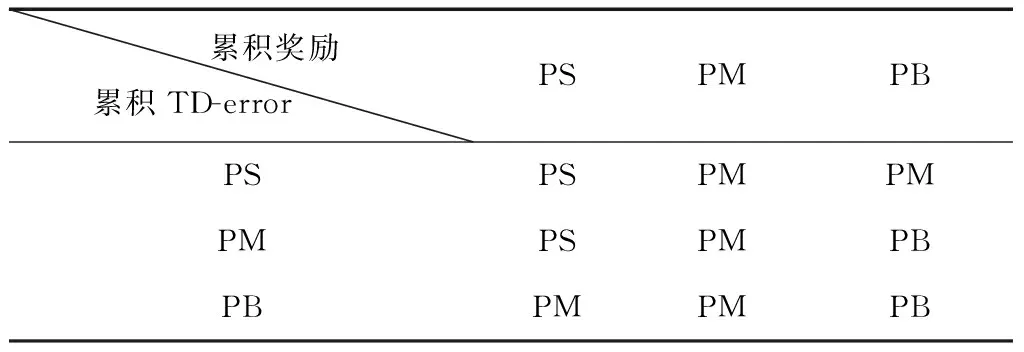
表1 模糊推理規則
表中采用IF-THEN模糊規則得到模糊集到輸出之間的關系:
(9)
去模糊化過程是將模糊值轉換成精確值的過程。本文通過最常用的面積重心法來實現去模糊化,即樣本價值越高,其存儲在經驗池1中的概率越大。一個單元的經驗存儲至經驗池1的概率為:
(10)
通過式(10),可以得出一個單元樣本存儲至經驗池1中的概率,樣本存儲至經驗池2的概率計算過程與之類似。這樣就實現了樣本分類存放的目的。
2.4 積分抽樣器
通過模糊推理實現了將樣本進行分類存儲的目的,但以固定概率從這些經驗池中抽樣會導致智能體難以根據訓練過程調整學習的重點。訓練初期由于尚未形成穩定的策略,因此應該保證訓練樣本的多樣性。而訓練后期由于策略已初見端倪,智能體應該更多關注那些罕見且高價值的樣本,用于進一步改進自身策略。因此本文設計了一種積分抽樣器,對累積獎勵的時序差分誤差進行積分,用于判斷智能體策略是否已經形成,并調整從不同經驗池中抽樣的概率,進而調整智能體的學習重心。定義第τ輪對抗的累積獎勵時序差分誤差為:
(11)
則抽樣器從經驗池1中抽樣概率為:
(12)
其中,P為經驗池1與2抽樣的概率之和,為一常值,kI為積分系數。為避免從經驗池1和2中抽樣過多引起過擬合,設置總經驗池用于保存對抗過程中的所有樣本,并保證抽樣器以1-P的概率從總經驗池中抽取樣本,以保證抽樣的多樣性。圖4給出了改進DDQN的算法框圖。
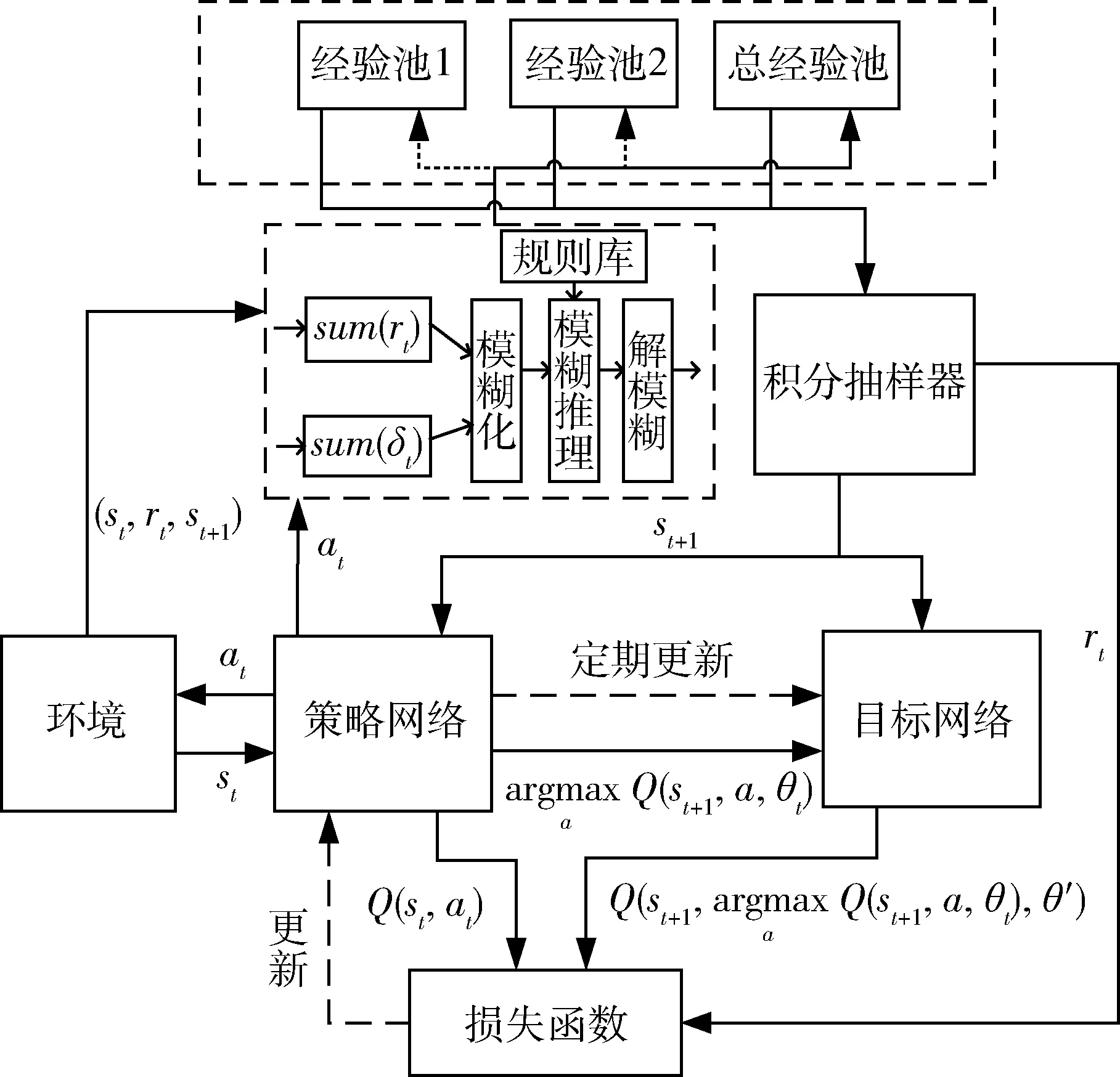
圖4 改進DDQN算法框圖
3 仿真試驗及結果
3.1 仿真參數設置
實驗在python3.6+tensorflow2.4環境下運行,設計神經網絡為包含3個隱含層的全連接神經網絡,隱含層結構為512×256×128,激活函數選擇Leaky-relu函數,神經網絡學習率η=0.00001,折扣因子γ=0.9,經驗池1大小為D1=1000,經驗池2大小為D2=2000,總經驗池大小為D3=5000,樣本批大小minibach=32。
為提高模型的泛化能力,防止模型過擬合,這里令攻防雙方的初始參數分別在各自區間內隨機生成,飛行器初始參數如表2所示:
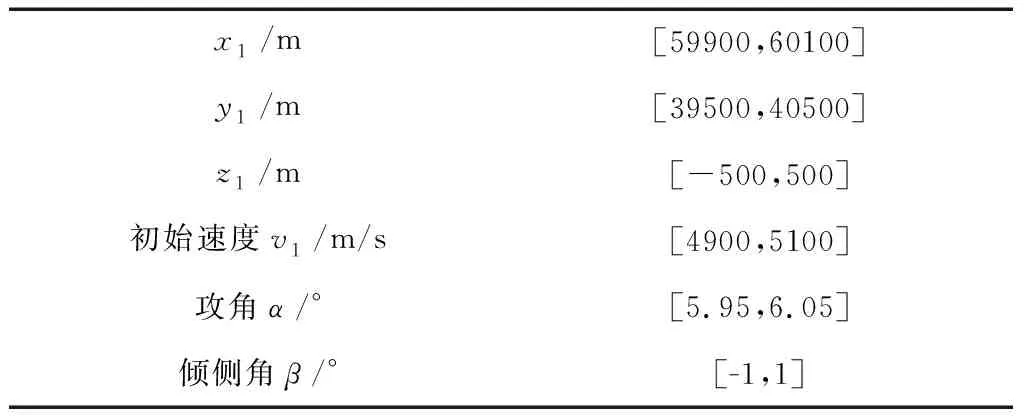
表2 飛行器初始參數
攔截器初始參數如表3所示:

表3 攔截器初始參數
3.2 實驗結果及分析
對智能體進行10h訓練,共完成約25000輪對抗,圖5展示了訓練過程中每100次對抗平均突防概率的變化情況,圖6展示了每100次對抗平均累積獎勵值變化情況。可以看出,經典DDQN算法與改進DDQN算法均能有效處理飛行器與攔截器的攻防博弈問題,訓練后平均突防概率均提升至95%以上。
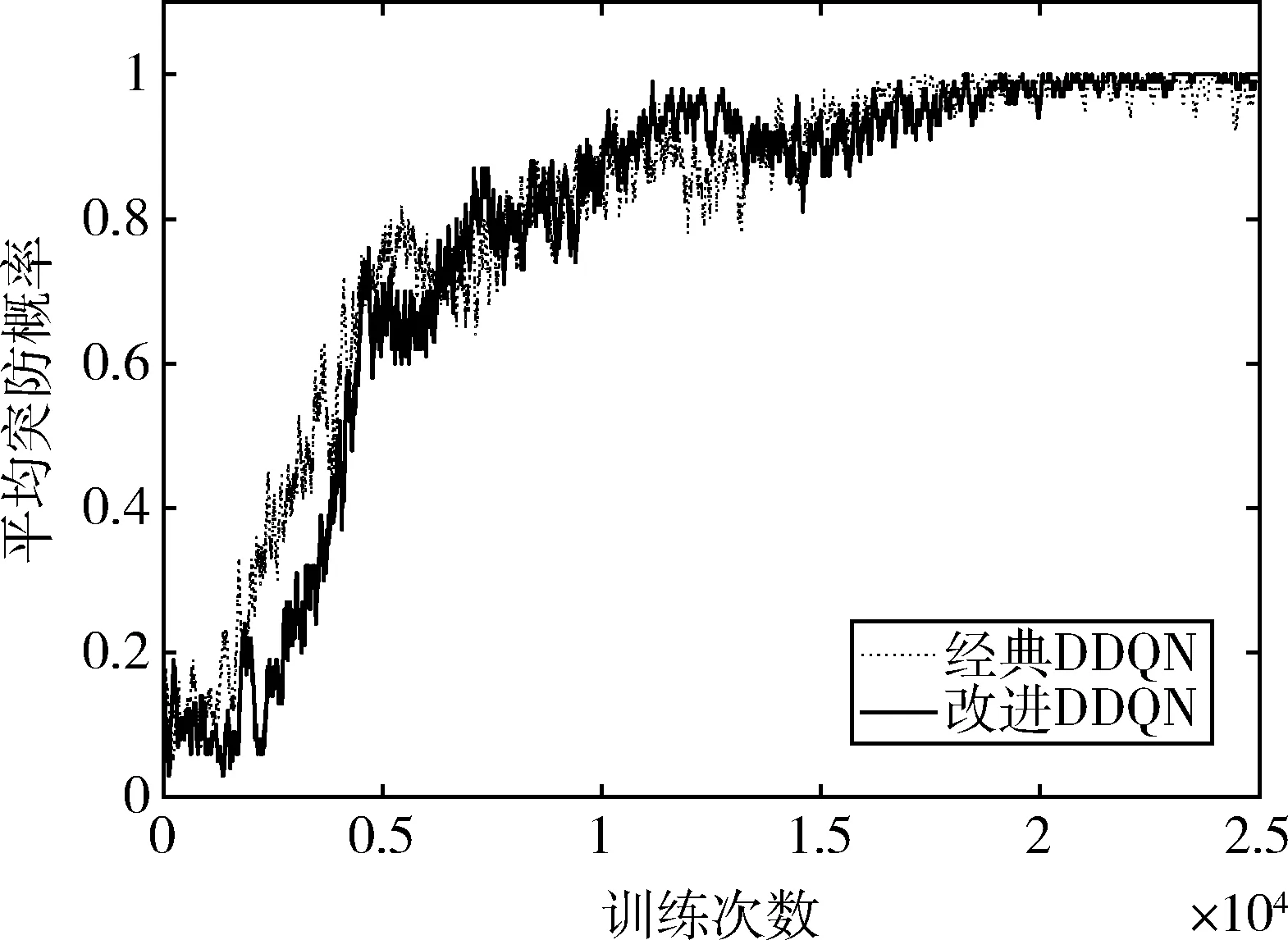
圖5 平均突防概率隨回合數變化
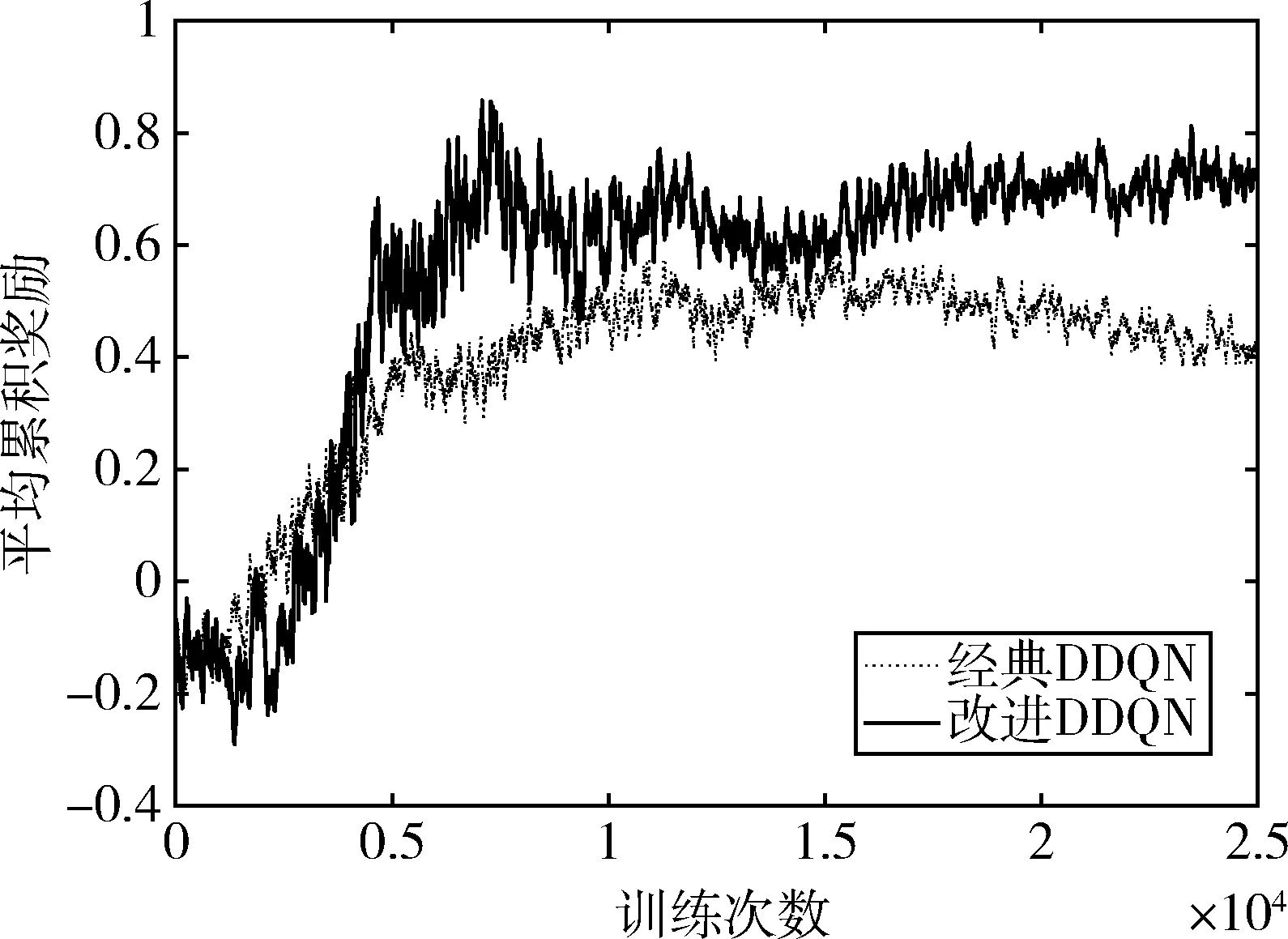
圖6 平均累積獎勵隨回合數變化
智能體在訓練初期由于采用隨機搜索策略,對抗中存在大量突防失敗經歷,突防概率和獎勵值較低,此時智能體還未形成較好的策略。隨著訓練的進行,智能體隨機搜索的概率逐漸下降,突防概率和獎勵值也呈現上升趨勢,說明智能體能夠不斷從對抗過程中學習并改進自身策略。
相比于經典DDQN算法,改進的DDQN算法能夠收斂于更高的平均累積獎勵值,說明改進DDQN算法搜索到了更優的策略,能以更小的機械能損耗完成突防。
訓練前攻防雙方的飛行軌跡由圖7給出,此時智能體由于還未形成穩定策略,機動后仍然被攔截器所攔截。
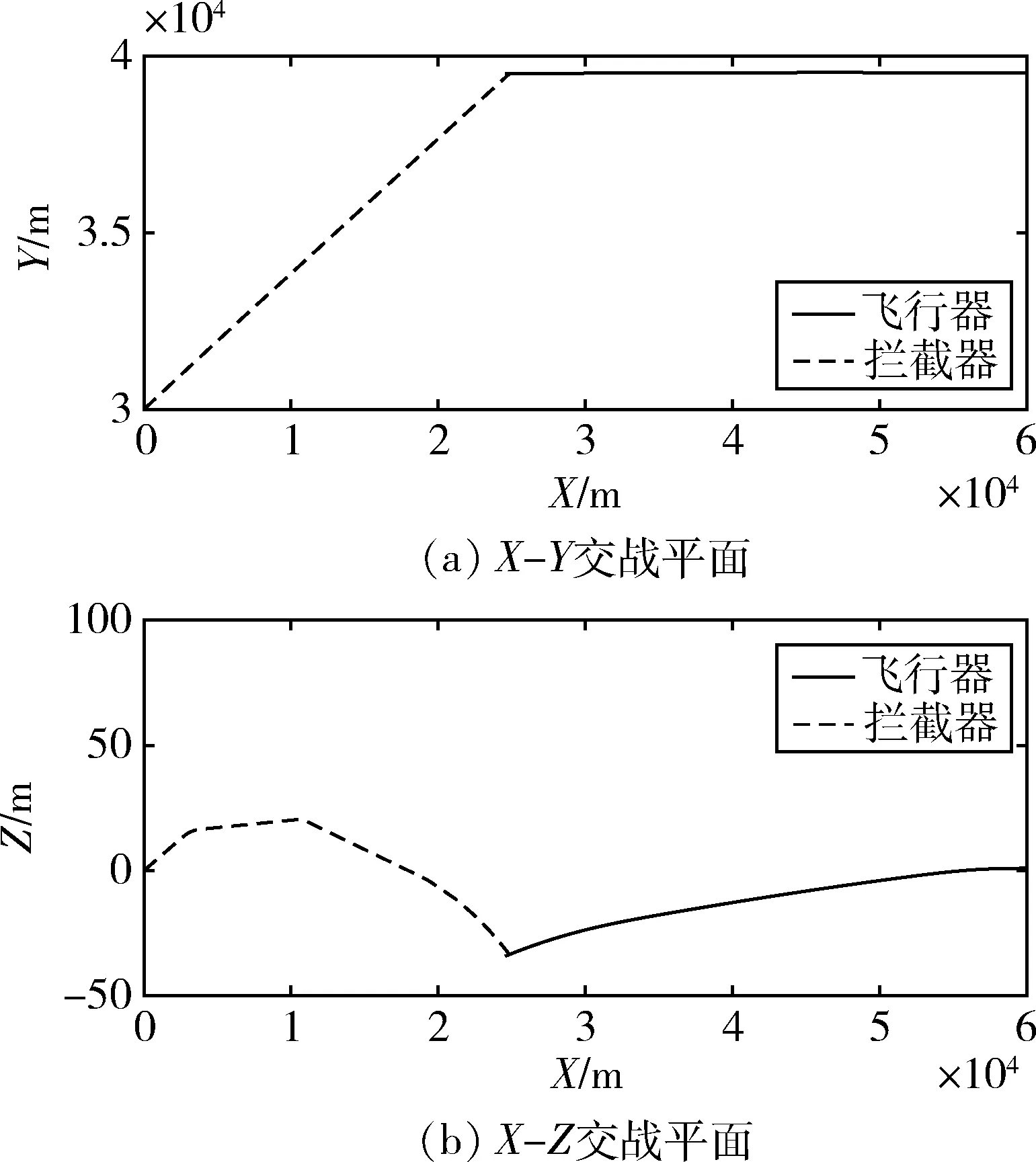
圖7 訓練前攻防雙方飛行軌跡
圖8給出了訓練后的攻防雙方飛行軌跡。可以看出,初始狀態下攔截器飛向預測碰撞點,飛行器不斷機動以躲避攔截器的攔截,同時攔截器在比例導引作用下修正自身軌跡,最終飛行器以12.7m脫靶量完成突防。
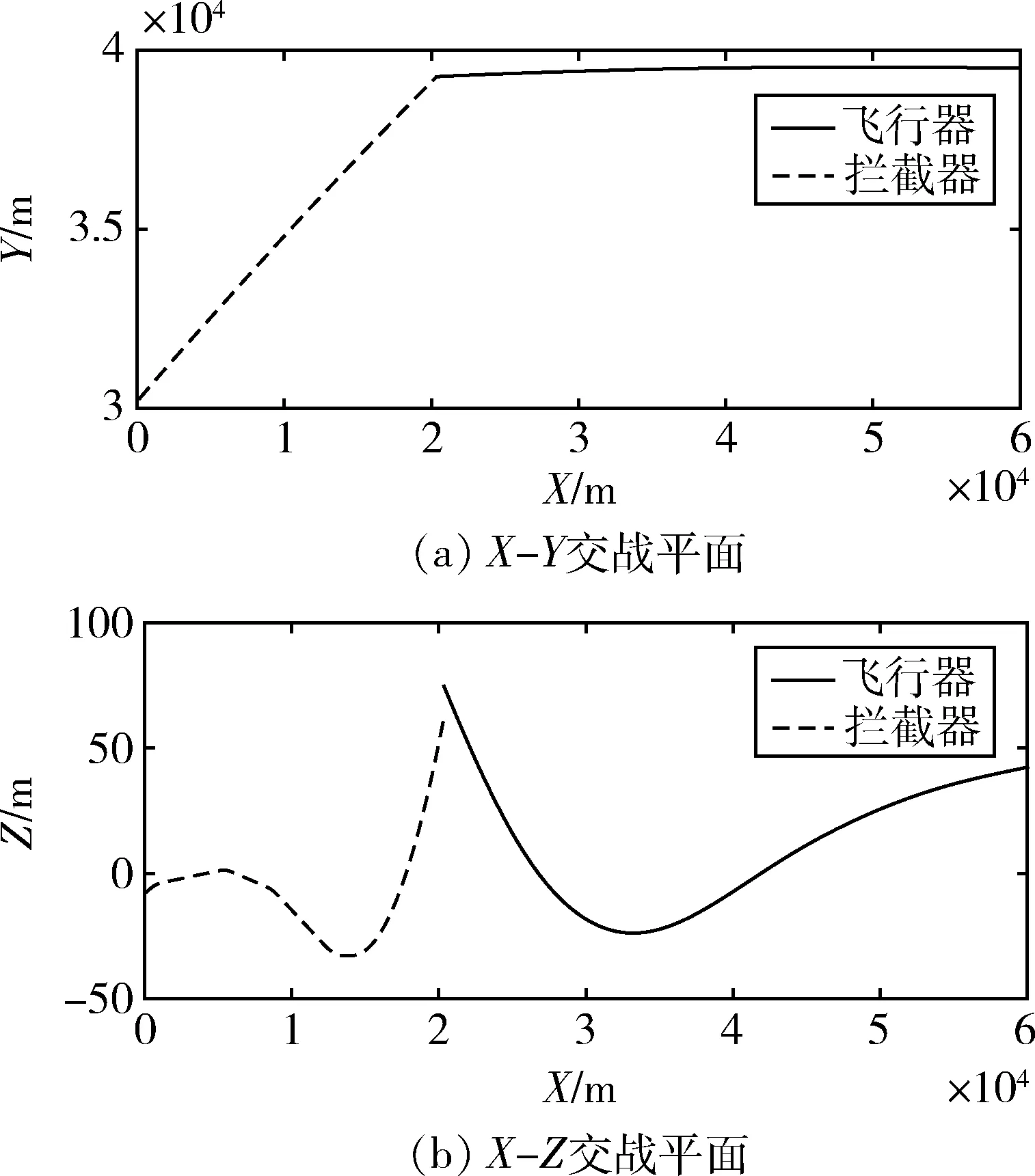
圖8 訓練后攻防雙方飛行軌跡
圖9展示了飛行器攻角和傾側角變化情況,智能體所采取的策略是在對抗初期采取小攻角飛行以節約自身能量,隨后在2.4s時開始不斷加大攻角直至28°,同時傾側角繼續旋轉至100°左右,以類橫向機動進行飛行,迫使攔截器大量消耗自身燃料以調整軌跡。在6.5s時再次減小攻角降低自身能量消耗,最終在7.9s完成該次對抗。
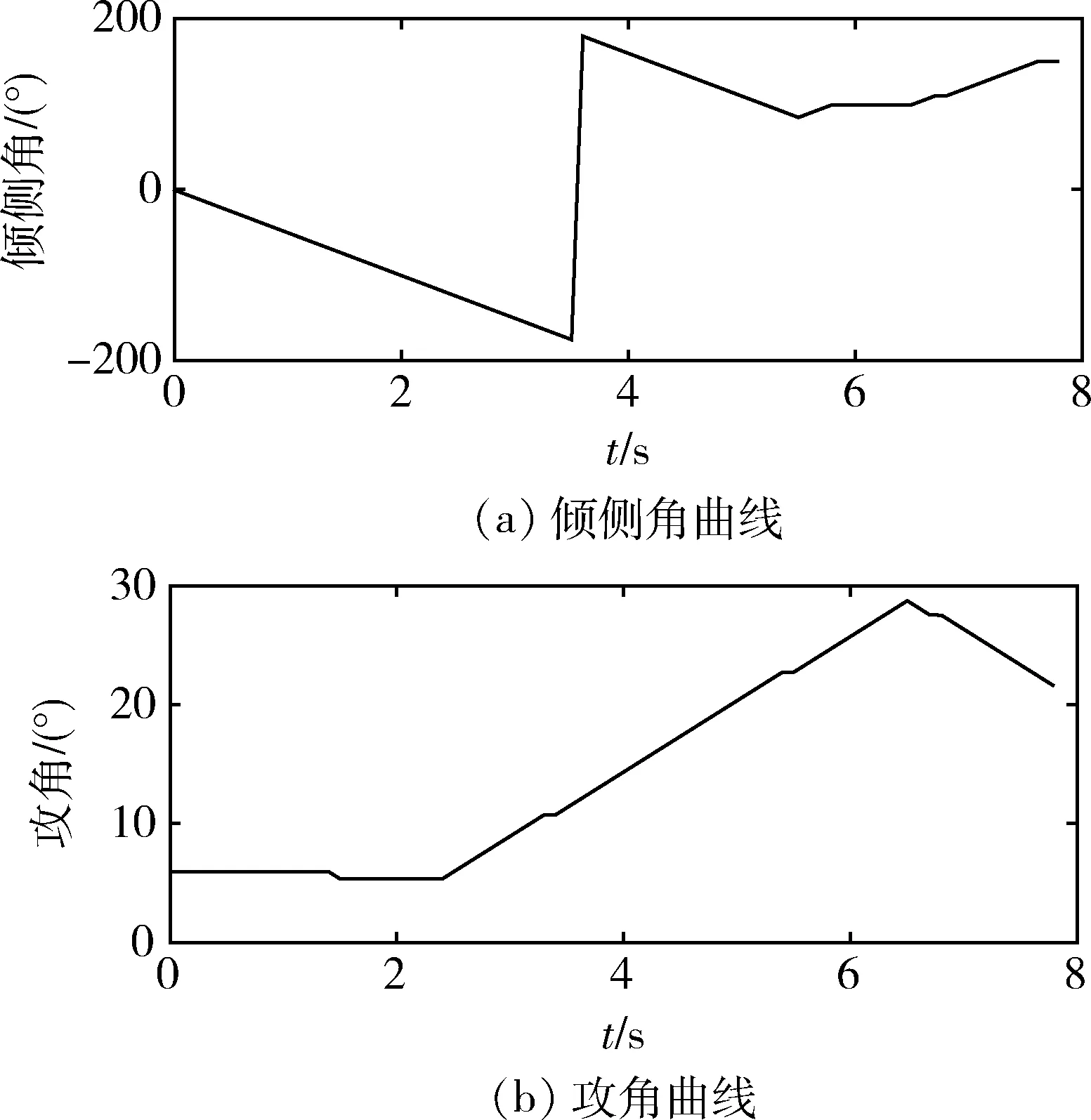
圖9 飛行器控制指令曲線
4 結論
針對高速飛行器攻防博弈決策控制問題,提出了一種基于DDQN的改進算法。該算法針對樣本回放過程,利用模糊推理評價樣本好壞程度并分類存儲,再根據訓練過程中的累積獎勵時序差分設計了積分抽樣器,根據訓練過程調整抽樣的側重點。結果表明,改進DDQN算法收斂時平均累積獎勵值高于經典DDQN算法,該算法能夠使智能體不斷學習并改進自身策略,訓練后平均突防概率高于95%,且在成功突防的前提下減少了自身的能量消耗,形成的策略符合設計人員的預期。這為解決高速飛行器攻防博弈決策問題提供了一種新思路。
猜你喜歡
黨課參考(2021年20期)2021-11-04 09:39:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小哥白尼(軍事科學)(2019年6期)2019-03-14 05:49:56
文苑(2018年23期)2018-12-14 01:06:06
黨課參考(2018年20期)2018-11-09 08:52:36
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
數學大世界(2018年1期)2018-04-12 05:39:14
