基于FCN-CRF 的醫(yī)療命名實(shí)體識別
2022-09-14 08:19:52潘勝星唐雅娟
電子設(shè)計(jì)工程 2022年17期
潘勝星,唐雅娟
(汕頭大學(xué)電子工程系,廣東汕頭 515063)
在醫(yī)療領(lǐng)域中,存在大量的非結(jié)構(gòu)化文本,如醫(yī)療主題的文獻(xiàn)、病歷記錄等。通過信息抽取技術(shù),可以從大量非結(jié)構(gòu)化文本中高效地抽取出感興趣的信息,在后續(xù)任務(wù)中使用,如自動(dòng)醫(yī)療問答、智能醫(yī)療診斷等。
命名實(shí)體識別(Named Entity Reconition,NER)任務(wù)是信息抽取的一個(gè)基礎(chǔ)任務(wù),旨在從非結(jié)構(gòu)化文本中抽取出特定的實(shí)體。該任務(wù)可以被看作一個(gè)序列標(biāo)注任務(wù)[1]。文獻(xiàn)[2-4]提出以LSTM-CRF 為基本框架的模型進(jìn)行命名實(shí)體識別,該模型主要利用了字級別的信息進(jìn)行標(biāo)注。文獻(xiàn)[5-6]對LSTM 單元進(jìn)行了修改,使其動(dòng)態(tài)地結(jié)合詞信息,但無法并行計(jì)算。文獻(xiàn)[7]延續(xù)該思路,引入rethinking 機(jī)制,并將LSTM 單元換為CNN 單元,從而實(shí)現(xiàn)單樣本輸入的并行計(jì)算,提高GPU 的利用率。文獻(xiàn)[8-9]將圖神經(jīng)網(wǎng)絡(luò)引入NER 中,用節(jié)點(diǎn)之間的路徑表示詞匯信息,對節(jié)點(diǎn)進(jìn)行信息的聚合從而得到標(biāo)注結(jié)果。文獻(xiàn)[10]將表示詞BMES 信息的向量與字級別的向量表示拼接后送入模型中。整體來看,基于詞典增強(qiáng)的方法需要對每一個(gè)輸入模型的句子進(jìn)行潛在詞匹配,該過程的時(shí)間復(fù)雜度通常是O(n2)級別的,而輸入文本長度通常在20~200 個(gè)字符之間,因此訓(xùn)練模型所需的時(shí)間非常長。
語義分割任務(wù)同樣可以看作一個(gè)序列標(biāo)注任務(wù),區(qū)別在于語義分割作用于二維的圖像。語義分割與NER 類似,標(biāo)注都具有連續(xù)性以及平移不變性。基于兩個(gè)任務(wù)的相似性,提出將FCN 模型引入NER 任務(wù)中。實(shí)驗(yàn)結(jié)果表明,F(xiàn)CN 模型應(yīng)用于命名實(shí)體識別時(shí)可以得到與基于詞典增強(qiáng)的方法相似的性能,同時(shí)無需詞信息,因此訓(xùn)練所需的時(shí)間大幅度縮短,更易于在實(shí)踐中使用。
1 任務(wù)比較
從表面上看,語義分割與命名實(shí)體識別是不同的任務(wù),一個(gè)來自計(jì)算機(jī)視覺領(lǐng)域,另一個(gè)來自自然語言處理領(lǐng)域。但事實(shí)上,這兩個(gè)任務(wù)具有頗多相似性。
1.1 標(biāo)注的單位
圖像語義分割任務(wù)處理的對象是二維的圖像,而命名實(shí)體識別任務(wù)所處理的對象是一維的文本。二者都可以被看作是序列標(biāo)注的問題,語義分割標(biāo)注的單位是像素,而命名實(shí)體識別標(biāo)注的單位是字。
1.2 最小單位的表示形式
圖像的像素在計(jì)算機(jī)中一般會(huì)被表示為一個(gè)RGB 三通道的向量,而文字在計(jì)算機(jī)中則會(huì)被映射為表示字符的向量。即兩個(gè)任務(wù)輸入的最小單位都是向量,輸入的是向量的序列。
1.3 平移不變性
兩個(gè)任務(wù)標(biāo)注出的內(nèi)容均具有平移不變性。圖像中,分割出的物體不因位置改變而改變其所屬類別;文本中,抽取出的實(shí)體不因其在文本中位置的移動(dòng)而改變類別。
1.4 語義連續(xù)性
每個(gè)最小單位并非孤立地標(biāo)注,而是受周圍標(biāo)注的影響。在圖像中,被標(biāo)注為天空的像素點(diǎn)附近的像素點(diǎn),其標(biāo)簽更可能依然是天空,而有較小的可能性是人或者汽車。在文本中,被標(biāo)注為B-類別1的文字之后,通常只能接續(xù)位置為M 或者E 的標(biāo)簽,且不能被標(biāo)注為1 之外的類別。由于該特性的存在,語義分割的模型中有引入CRF 優(yōu)化輸出的方法[11],而在NER 中,在最后輸出標(biāo)簽之前使用CRF 則是幾乎目前所有方法的共同選擇。
2 FCN-CRF模型
該節(jié)將原本應(yīng)用于語義分割的FCN 模型的結(jié)構(gòu)進(jìn)行修改,得到FCN-CRF 模型。
2.1 整體結(jié)構(gòu)
FCN-CRF 整體結(jié)構(gòu)與FCN 基本一致,保持了“編碼器-解碼器”結(jié)構(gòu)。編碼器部分由多個(gè)卷積層組成,逐層抽取特征并映射為標(biāo)簽分?jǐn)?shù),在解碼器一側(cè),從最后一層卷積層輸出的標(biāo)簽分?jǐn)?shù)開始,往前逐層使用轉(zhuǎn)置卷積結(jié)合信息,輸出分?jǐn)?shù)。
2.2 輸入層
在輸入層,對于一個(gè)輸入的文本序列X={x1,x2,...,xn}中的每一個(gè)字xk,通過一個(gè)嵌入查找表ec得到對應(yīng)的向量,表示為ek[12],如式(1)所示:

2.3 編碼器
編碼器部分由數(shù)個(gè)卷積層組成。與圖像不同,文本由于長度相差較大,通常不會(huì)被全部填充到一樣長度,而是按照長度排序,分批送入模型前對該批次文本填充到統(tǒng)一長度[13],因此輸入文本長度是不統(tǒng)一的,模型在運(yùn)算過程中需要保持輸入的長度不變。因此在編碼器中,卷積層使用尺寸為3、填充為1 的一維卷積,從而保持文本長度不變。需要注意的是,雖然文本序列可以被表示為向量序列,看作一個(gè)二維矩陣,但每一個(gè)向量是需要被整體看待的,如果使用二維卷積則會(huì)破壞每個(gè)向量的信息完整度,因此需要選擇一維卷積[14-15]。
此外,同樣是考慮到文本長度保持不變,因此池化操作被去除了。
2.4 解碼器
解碼器部分主要由轉(zhuǎn)置卷積層組成,例如,一個(gè)5 層的FCN-CRF。在編碼器的每一層,先抽取特征并映射到類別分?jǐn)?shù),然后將第5 層的分?jǐn)?shù)與第4 層融合,并使用轉(zhuǎn)置卷積重新映射到類別分?jǐn)?shù),得到結(jié)合了兩層信息的結(jié)果。以此類推,然后將該結(jié)果與第3層的分?jǐn)?shù)融合,再次使用轉(zhuǎn)置卷積。其中,轉(zhuǎn)置卷積與在語義分割中的設(shè)置不同,這里不需要對文本序列進(jìn)行上采樣,因此填充設(shè)置為1,使得經(jīng)過轉(zhuǎn)置卷積后的長度與輸入時(shí)相等。
2.5 條件隨機(jī)場
經(jīng)過解碼器后,模型得到了關(guān)于輸入序列的標(biāo)注分?jǐn)?shù)序列。但此時(shí)輸出的標(biāo)簽,對于前后的關(guān)聯(lián)性考慮不夠強(qiáng),因此,與目前的主流方法一致,在最后輸出之前使用條件隨機(jī)場對輸出序列進(jìn)行約束[16-17]。
3 實(shí)驗(yàn)結(jié)果
在瑞金糖尿病數(shù)據(jù)集上,對FCN-CRF 模型的性能進(jìn)行測試,并選取了BiLSTM-CRF、Lattice LSTM、LGN 3 個(gè)模型作為對照。其中BiLSTM-CRF 是基于字級別信息的模型,而Lattice LSTM 與LGN 則是基于詞典增強(qiáng)的模型。
瑞金數(shù)據(jù)集包含493 篇糖尿病領(lǐng)域的醫(yī)學(xué)文獻(xiàn),標(biāo)注者都具有醫(yī)學(xué)背景。首先,對數(shù)據(jù)集進(jìn)行預(yù)處理,包括去除無效字符,劃分句子,限制句子長度在20~200 個(gè)字符之間。防止過長的序列使訓(xùn)練時(shí)中間保存的梯度過多導(dǎo)致顯存不足,也防止過長的序列導(dǎo)致CRF 進(jìn)行解碼時(shí)效率過度下降。
模型的隱藏層單元數(shù)均為200,dropout 設(shè)置為0.1,優(yōu)化器使用Adam,權(quán)值衰減為10-8。每個(gè)模型訓(xùn)練20 個(gè)epoch。對數(shù)據(jù)集做十折交叉驗(yàn)證得到實(shí)驗(yàn)結(jié)果。輸入部分使用word2vec 在中文語料上訓(xùn)練得到的長度為100 維的詞向量。
實(shí)驗(yàn)在Windows10 系統(tǒng)下進(jìn)行,IDE 是Pycharm,深度學(xué)習(xí)框架為Pytorch。評價(jià)指標(biāo)選擇準(zhǔn)確率(P)、召回率(R)以及F1,按照NER 中的嚴(yán)格F1 標(biāo)準(zhǔn)進(jìn)行結(jié)果統(tǒng)計(jì),記S為預(yù)測出的實(shí)體集合,G為句子中真實(shí)的實(shí)體集合,P、R、F1 的計(jì)算方式分別如式(2)-(4)所示。
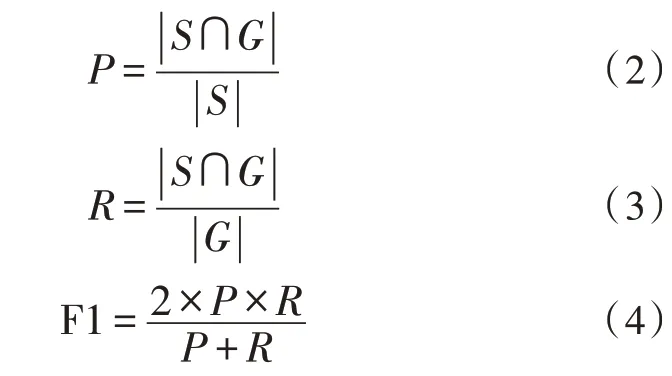
FCN-CRF 模型最佳性能與其他模型對比的結(jié)果如表1 所示。可以看到FCN-CRF 超過BiLSTMCRF 約2.6%。與Lattice LSTM、LGN 模型的表現(xiàn)非常接近,F(xiàn)1 值差距在1%以內(nèi)。表1 中展示的時(shí)間為FCN-CRF 在瑞金數(shù)據(jù)集上訓(xùn)練100 個(gè)epoch 后求得每個(gè)epoch 的平均訓(xùn)練時(shí)間,可以看到FCN-CRF 的時(shí)間僅為基于詞典的方法的不到2%。
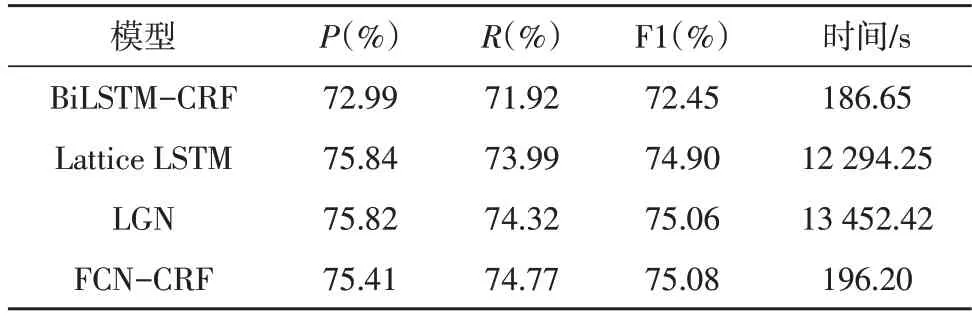
表1 各模型的實(shí)驗(yàn)結(jié)果
接下來,對不同層數(shù)的FCN-CRF 進(jìn)行了實(shí)驗(yàn)。不同層數(shù)的性能如圖1 所示,從圖中可看出在瑞金數(shù)據(jù)集上,7 層的FCN-CRF 可以達(dá)到最好的效果。當(dāng)層數(shù)堆疊更多時(shí),模型性能反而下降,因?yàn)榇藭r(shí)模型的參數(shù)冗余開始產(chǎn)生過擬合。
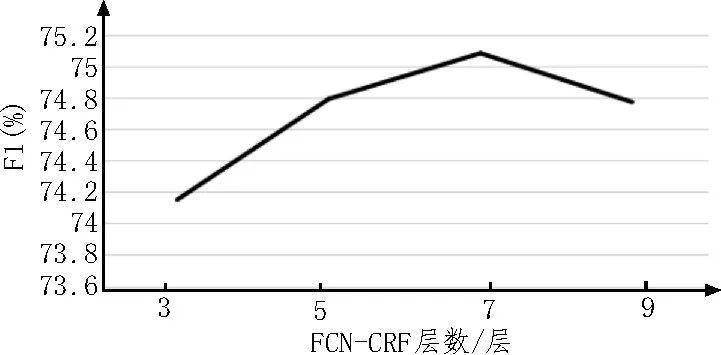
圖1 不同層數(shù)的性能
表2 中展示了轉(zhuǎn)置卷積層對于模型性能的影響。可以看到,將解碼器部分的轉(zhuǎn)置卷積層全部換為卷積層時(shí),在FCN-CRF 為7 層時(shí),性能出現(xiàn)明顯下降。該現(xiàn)象可以解釋為,在解碼器部分使用卷積層時(shí),相當(dāng)于繼續(xù)向更高層次抽取特征,該操作反而使得模型性能下降。
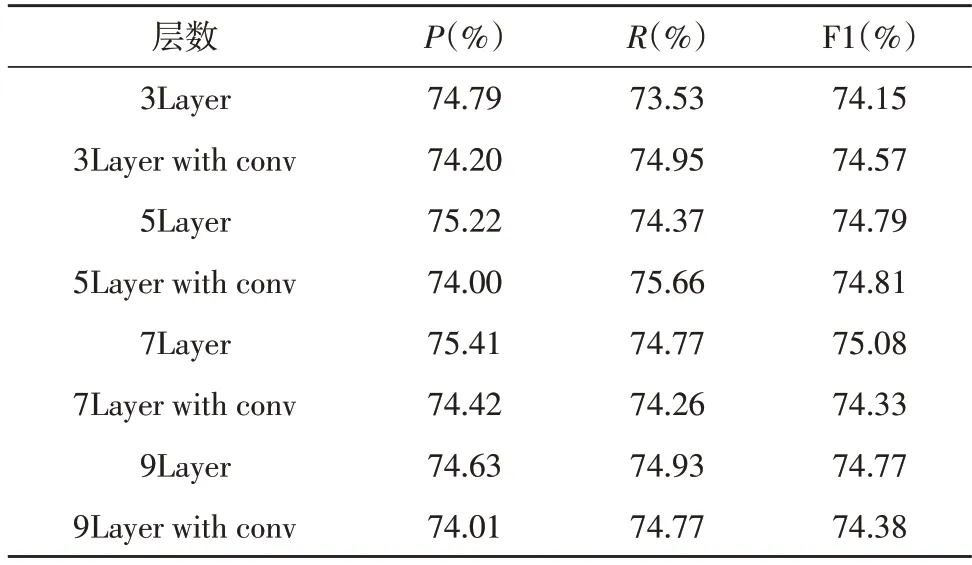
表2 轉(zhuǎn)置卷積對模型的性能影響
在FCN 模型用于圖像語義分割時(shí),實(shí)驗(yàn)結(jié)果顯示,模型從編碼器的最后一層逐層往前結(jié)合淺層的特征,并非越多越好,結(jié)合到過于低層的信息時(shí),反而會(huì)影響模型的性能。對于該現(xiàn)象,同樣希望了解在NER 中是否出現(xiàn),因此對于不同層數(shù)的FCN-CRF模型均進(jìn)行了對比測試,觀察融合特征層數(shù)對模型的性能影響,如圖2 所示。
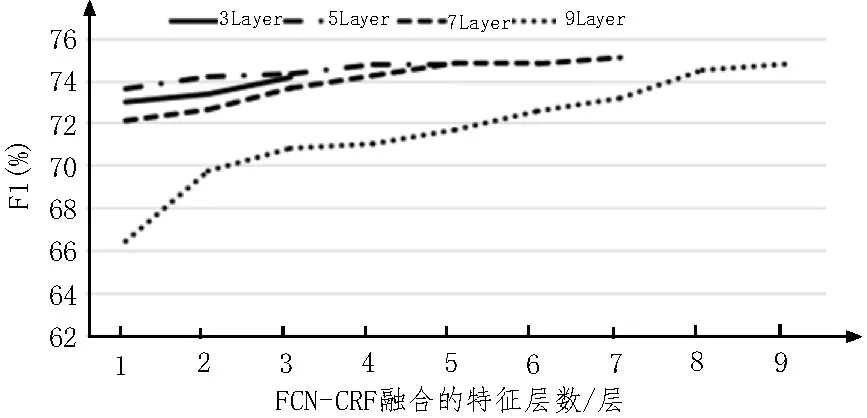
圖2 融合特征層數(shù)對性能的影響
從圖2可以觀察得知,對于不同層數(shù)的FCN-CRF,均有類似的結(jié)果,即隨著往淺層方向融合的特征層數(shù)減少,模型的性能下降。但在圖像語義分割任務(wù)中,融合特征層數(shù)較多反而影響性能。針對這一結(jié)果的解釋是,因?yàn)閳D像的輸入最小單位是像素,像素是僅包含3 維RGB 通道信息的很短的向量,每個(gè)最小單位包含的信息量較少,因此FCN 最初幾層抽取圖像特征時(shí),包含的信息相對較低級,信息量較少,對于最終標(biāo)注結(jié)果影響較小。而在文本數(shù)據(jù)中,輸入的最小單位是字符,每個(gè)字符均會(huì)被映射為高維的詞向量,此時(shí)每個(gè)最小單位所攜帶的信息量較多,在淺層時(shí)抽取的特征已經(jīng)包含較多信息,若不對這部分信息加以融合,則可能較大程度上影響模型的最終性能。該部分實(shí)驗(yàn)結(jié)果說明,在NER 中使用FCN-CRF 模型時(shí),為了得到更好的性能表現(xiàn),應(yīng)該把每一層輸出的特征分?jǐn)?shù)都融合到一起來獲得最終的輸出。
4 結(jié)論
目前,NER 模型大多需要結(jié)合詞典信息,效率較低。該文提出將FCN-CRF 模型應(yīng)用于NER 任務(wù)。實(shí)驗(yàn)結(jié)果證明,F(xiàn)CN-CRF 無需結(jié)合詞典信息,也能達(dá)到和現(xiàn)有模型相似的性能,同時(shí)大幅度降低了模型訓(xùn)練所需的時(shí)間,提高了在實(shí)踐中的應(yīng)用性。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
中外會(huì)展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
外語學(xué)刊(2011年1期)2011-01-22 03:38:33
