基于決策樹的銀行目標客戶預測算法
2022-09-21 07:55:26夏安林杜董生盛遠杰劉貝
電腦知識與技術 2022年24期
夏安林,杜董生,盛遠杰,劉貝
(淮陰工學院,江蘇淮安 223003)
1 引言
互聯網金融的興起,使人們在日常消費中的支付更加便捷,為人們的儲蓄和借貸服務帶來了極大的方便和高效。在互聯網金融的沖擊與推動下,傳統銀行既要面對困難,也要面對機會。為了在日趨激烈的競爭中取得有利地位,傳統銀行應從根本上適應時代發展的潮流和需要[1]。由于網絡金融產品在利率、費用、時間等方面相對于傳統銀行理財產品具有明顯的優越性,因此,人們更愿意選擇將存款資金投資到網絡理財產品中,從而導致了銀行客戶資源的大量流失。而銀行是傳統的金融業,雖然有著龐大的用戶基數,卻不能完全利用這些數據,因此,大量的數據并沒有給銀行提供更多的信息,更沒有發現海量的有用資料。
大數據時代,以互聯網、大數據、人工智能為代表的信息技術與各行各業的結合越來越緊密,隨著大數據對傳統金融行業的革新,我國傳統銀行面臨著新的機遇和挑戰[2]。傳統銀行系統具有豐富的數據量,但是獲得的信息卻很匱乏,銀行許多重要決策依舊是通過經驗做出的,而不是根據通過分析數據的結果科學決策,因此利用機器學習的方法對數據進行分析,做出科學的決策才能使銀行巨大的數據庫發揮真正的作用[3]。
決策樹是一種廣泛應用于數據挖掘的分類技術,通過對顧客進行歸類、對顧客進行顧客關系的處理,并采用不同的市場策略,理解顧客的需要,降低顧客的損失,并提升企業的使用效率,降低費用,增加效益。
2 決策樹相關理論
決策樹是一種實現分治策略的層次數據結構[4]。該算法是一種能夠進行分類與回歸的高效非參數學習算法。該算法可以從一組具有特點和標記的資料中歸納出一套判別準則,并利用樹型的形式將其表示出來,從而求解出一種歸類與回歸問題,決策樹算法的本質是一種圖結構。
決策樹的產生是一個遞推的過程,在三種情況下都會產生回歸。一是目前結點所含的所有樣品都是一個類,不需要進行分類;二是當前的屬性集合為空白,或者在全部的數據中都具有同樣的屬性值,則將目前的數據作為一個葉子的節點,并且設置它為數據樣本最大的一個分類;三是目前節點所含的樣本集為空白,無法進行分割,因此,將目前節點作為“葉節點”,設置該節點的類型為其父結點中數據樣本最大的一個類。
2.1 CART決策樹
CART 決策樹的生成包含分裂,剪枝和樹選擇三個步驟。分裂:分裂過程是一個二叉樹劃分過程,其特征可以是連續型或離散型的,CART沒有停止準則,會一直生長下去;剪枝:利用成本復雜性進行修剪,首先從最大的一棵樹中選取子樹,然后對其修剪,直至僅有一棵根結點為止,最終生成一棵最優的決策樹;樹選擇:每個剪樹枝的預測效果分別采用一組試驗集合進行評價(也可以用交叉驗證)。
CART 決策樹使用“基尼指數”(Gini index) 來選擇劃分屬性[5]。可以通過基尼值來衡量數據集X的純度。假定當前樣本集合X中第k類樣本所占的比例為pk(k=1,2,3,…,y),則基尼值為公式1所示。
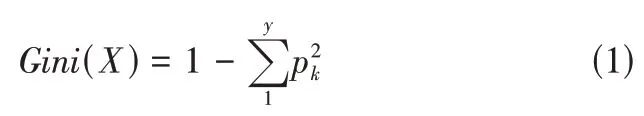
Gini(X) 表明了在兩個不同類型標簽之間的不一致性的隨機抽樣的可能性。基尼不純度是指該樣品被選擇的概率乘上錯誤的概率。Gini(X)越小,則數據集X的純度越高。當一個結點中所有的樣本都是一個類時,基尼不純度為0。
屬性a的基尼指數定義為
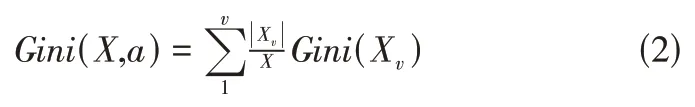
基尼指數Gini(X,A)表示經過A=a分割后集合X的不確定性。基尼指數越大,樣本的不確定性就越大。在候選集合A中,選取劃分后基尼指數最小的特征作為最佳分割屬性,即:
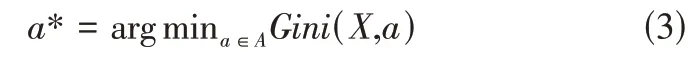
2.2 剪枝
在決策樹學習中,剪枝是處理“過擬合”問題的重要方法,為使訓練樣本得到最準確的歸類,需要反復進行分割,導致決策樹中出現大量的分支;在這種情況下,由于學習的樣本學習太好,以至于將某些特征視為所有的資料都具有的普遍特性,從而造成了過度擬合。決策樹剪枝的基本策略有“前剪枝”和“后剪枝”[6]。
前修剪算法是將決策樹的結構預先終止而進行修剪,因為它不能預先得到停止的臨界點,因此不經常采用。后修剪技術是在決策樹發育成熟后,將一些結點上的分叉修剪,從而實現了對大型決策樹的裁剪。最有代表性的后修剪方法是成本復雜度修剪。其基本思想是:對每個內部的結點進行運算,假設結點的子樹經過修剪后,可以得到預期的錯誤率。在修剪后,如果期望錯誤率增加,就會保持這個子樹,否則就修剪這個子樹。該算法生成了一套修剪過的樹,然后利用一套單獨的試驗系統對樹進行評價,最后正確率最高的樹被保留為結果。
3 基于決策樹算法的銀行客戶預測
通過對數據集的預處理,采用決策樹模型對數據進行歸類,并對其進行評估、分析,并將其與原始模型進行對比,然后利用該模型對數據進行了預測。測試流程包括:數據預處理,決策樹分類訓練集,用訓練后決策樹模型進行預測,并將其輸出。
3.1 數據預處理
該文以銀行機構直接營銷的海量真實數據,分析各類屬性預測客戶是(1類)否(0類)會購買定期存款(y),所有決策屬性中還有客服人員與客戶聯系的信息以及其他屬性。
本數據集共有25317行,18列。前幾行示例如表1所示。

表1 數據集示例
數據說明如表2所示。
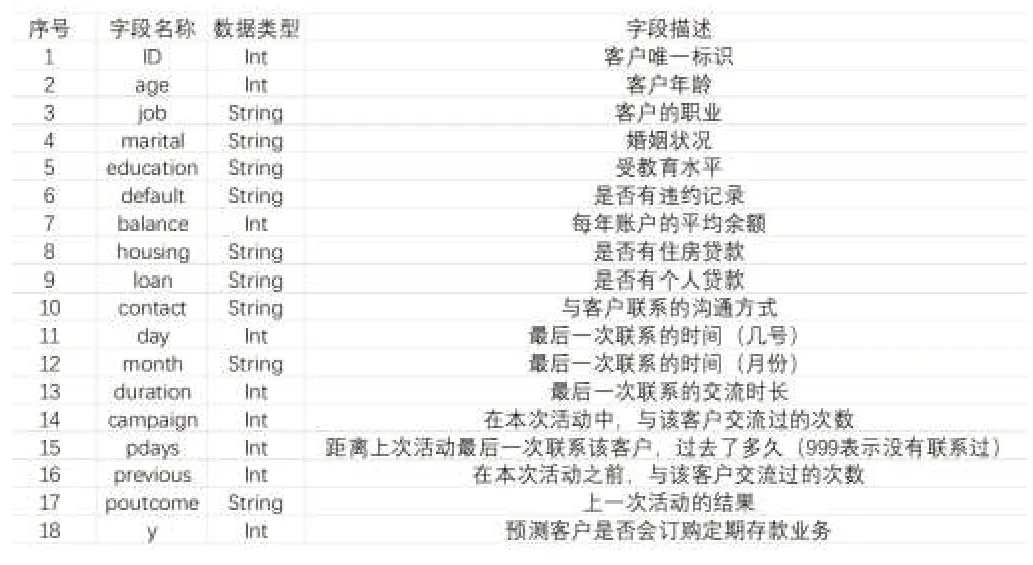
表2 數據說明
其中,客戶唯一標識(ID)和預測客戶是否會訂購定期存款業務(y)不作為分類屬性,則選擇的分類屬性共有16種,選擇預測屬性一種(y)。在選定了這些屬性之后,每個屬性都會被檢查規范性和合理性,并且篩選出合格的屬性。
首先區分出連續型和離散型屬性,其中連續型屬性有{age,balance,day,duration,campaign,pdays,previous},離散型屬性有{job,marital,education,default,housing,loan,contact,month,poutcome}。
對每個連續屬性繪制箱線圖查看離群點的分布。可以提供數值型變量的最小值、最大值、四分位數、中位數和的值。將n 個數從小到大排序,四分位數是四分位置對應的數,以此類推:
下四分位:Q1=(n+1)/4
中分位:Q2=(n+1)/2
上四分位:Q3=3(n+1)/4
四分位距:IQR=Q3-Q1
上界:Q3+1.5IQR
下界:Q1-1.5IQR
通過圖1所示的箱線圖檢查連續型屬性是否存在離群點。
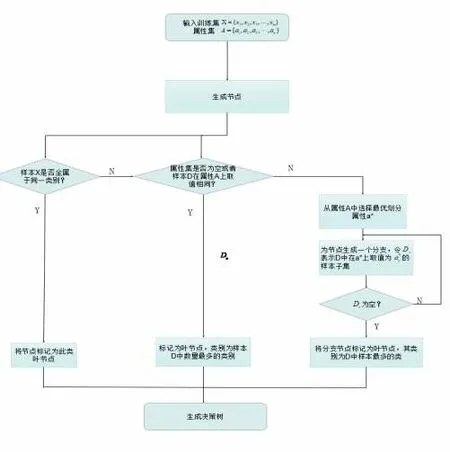
圖1 決策樹生成流程圖

圖1 連續型屬性箱線圖
由箱線圖可知:
1)age屬性刪除大于70的記錄。
2)balance刪除大于3763和小于-1965的記錄。
3)duration屬性刪除交流時長大于639秒的記錄。
4)campaign刪除聯系數量大于6的記錄。
5)day屬性沒有離群點不做刪除。
6)pdays屬性為客戶最近一次與之前活動聯系后經過的天數,pdays屬性中有20000 條左右值為-1,剩余越5000 條是不為-1,處于1~854 之間的一些值。這列數據的中位數,上四分位數,下四分位數均為-1,如果刪除離群點,這個屬性全為相同值,就沒有意義了,所以不做刪除。
7)previous此活動開始前與客戶的聯系數量,previous屬性中有20000 條左右值為0,剩余約5000 條是不為0,處于1~275之間的值,此列屬性的上四分位數,下四分位數和中位數都是0,所以也不做刪除。
對于離散型的變量,存在一些值為unknown的值,首先是進行頻率的統計,將少量的數據進行剔除,大量的刪除會對分類的結果造成一定的干擾。
離散型的變量中存在值為unknown的有以下屬性:
1)job工作類型,unknown值較少,進行刪除。
2)education教育水平,unknown值較少,進行刪除。
3)contact聯系人通信類型,unknown值有7000 多條,為了避免影響結果,所以不做刪除。
4)poutcome以前的營銷活動的結果,unknown值有20000多條,為了避免影響結果,所以不做刪除
不存在unknown值的離散型變量有以下屬性:
1)marital婚姻狀況,三個取值,無異常值。
2)default,二元變量,無異常值。
3)housing是否有住房貸款,二元變量,無異常值。
4)loan是否有個人貸款,二元變量,無異常值。
5)month每年的最后一個聯系月份,十二個月份,無異常值。
3.2 建模過程
決策樹分類方法適合銀行數據量大、數據屬性多等特性[7]。以3/4 的數據集為訓練集合,1/4 的數據集作為測試集合,利用混淆矩陣中的各個度量指標和ROC 曲線來觀測模型的錯誤率,并對測試集合進行預測。
該文采用CART決策樹,剪枝后決策樹可視化如圖2所示。除了葉節點之外的所有節點都由五個部分組成。基于一個特征的值的有關數據的問題。每個問題的答案要么是True,要么就是False,根據問題答案數據點會在該決策樹中移動;gini:基尼不純度;samples:節點中的數量;value:每一類別中的數量;class:節點中大多數點的類別。
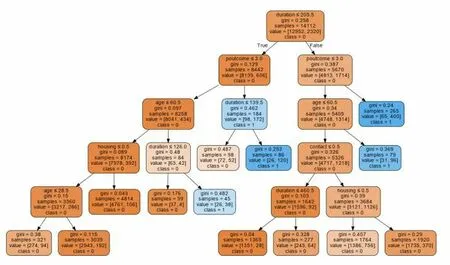
圖2 決策樹可視化圖
通常使用混淆矩陣來描述決策樹的性能,建模結果如表3所示。
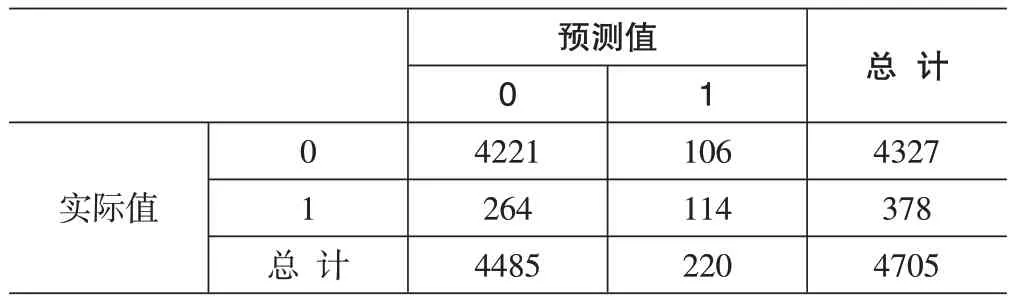
表3 混淆矩陣
根據上表混淆矩陣可得以下指標:
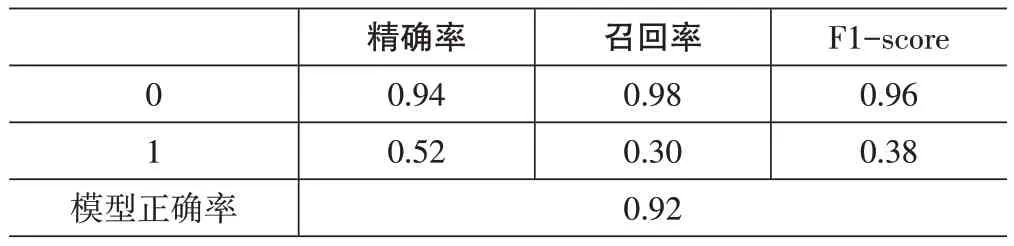
表4 模型準確率
其中,精確率為分類正確的數目與分類器判定為該類的數目所構成的比率,召回率為分類正確的數目與該類實際樣品數量的比率,F1-score是精確率與召回率的協調平均。
結果表明:該模型具有92%的準確率,但1類樣品中只有30.1%的數據被正確分類,從圖3的ROC曲線可以得出ACU 為0.89。因此,所建立的模型不夠完善,需要對其進行優化,以克服數據不平衡的問題[8]。
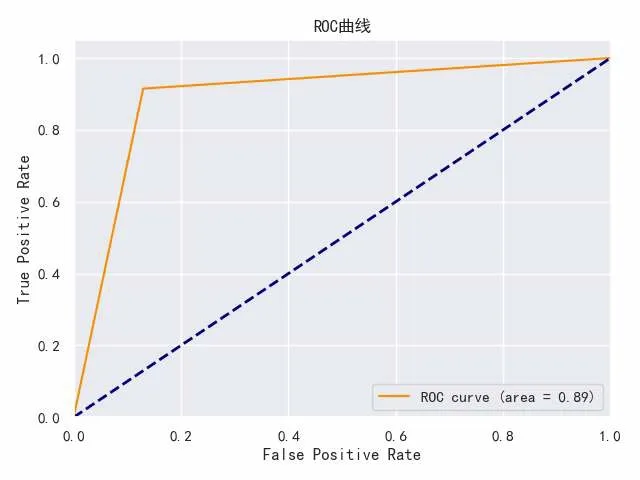
圖3 ROC曲線
3.3 模型優化
采用決策樹對不平衡的數據進行分類預測,總體準確率雖然高,但1 類預測準確率偏低;就銀行來說,對1 類數據錯誤的判斷會產生很大的影響,在這個案例中,1 類顧客很有可能會訂購銀行的定期存款,但是,模型認為顧客不太可能訂購。這種數據不均衡的情況下,通常可以用采樣技術解決。
首先,對數據進行過采樣、欠采樣、人工合成法進行數據處理,得到的數據如表5所示。

表5 采樣數據分布
從表中可以看出,在采樣技術的作用下,兩種類型的數據均得到了平衡,建立決策樹模型,結果如表6所示。
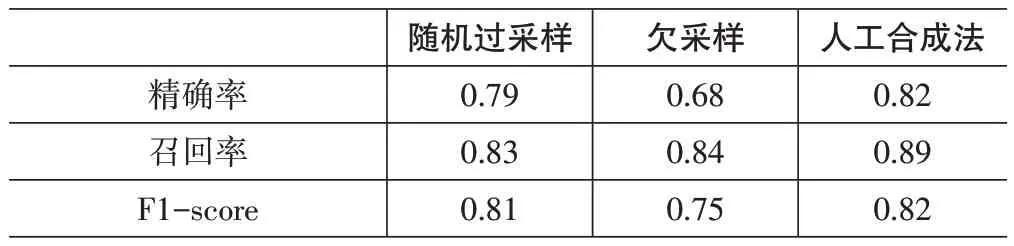
表6 采樣后模型1類準確率
由表6可知,模型的總體準確率相比之前有所降低,但1類樣本召回率有了極大的上升,1類樣本的預測正確率大幅提高,為了在最小的代價下獲得最優的準確度,一方面考慮1類正確率帶來的客戶效益,另一方面考慮0類正確率帶來的成本效益,因此采用人工合成法處理得到的數據集訓練模型,由圖4優化后ROC曲線可得ACU值提高到0.98,模型測試結果較為滿意。
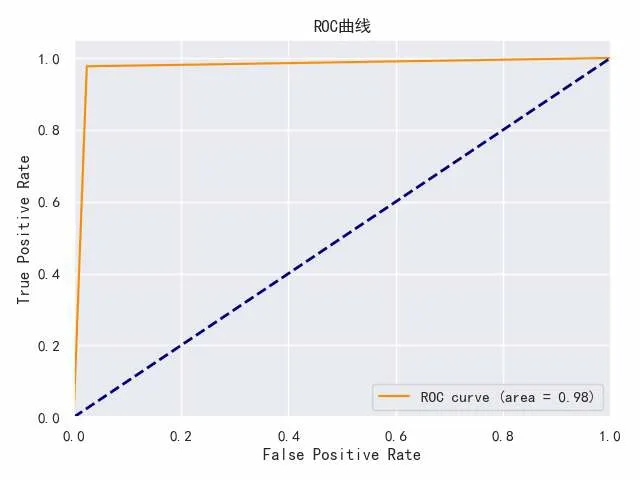
圖4 優化后ROC曲線
最終得到的決策樹如圖5所示。
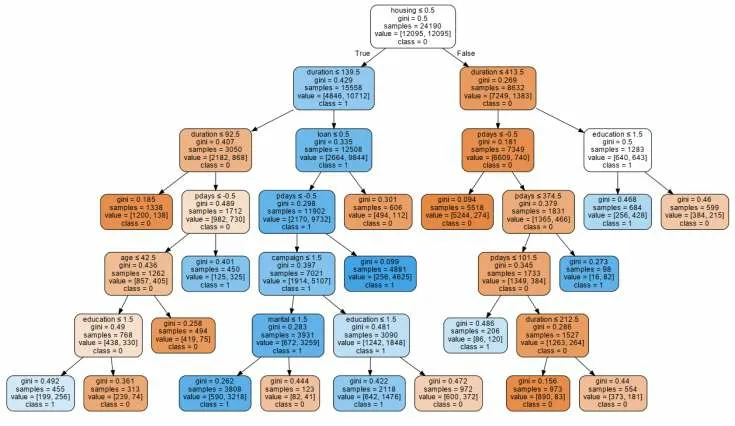
圖5 優化后決策樹可視化圖
4 結束語
互聯網金融的產生與發展對于銀行業存款業務產生了巨大的沖擊,如何有效地控制成本的同時增加其自身競爭力尤為重要[9]。銀行具有巨大的數據庫,對客戶信息挖掘有著極大的優勢,對于客戶信息的提取與挖掘對于銀行制定差異化策略具有很大的參考意義,在對客戶存款營銷時,如何能夠在成本最小化,利潤最大化的情況下拉到更多存款對于銀行來說有著重要意義。
該文介紹了CART決策樹算法,同時提出了在數據預處理過程中對數據缺失值、不一致值、噪聲數據的處理及對于不均衡數據的處理方法。首先將數據進行預處理,剔除了噪聲數據以及不一致數據,同時運用采樣方法解決了不均衡問題,最后運用的是CART 算法建立決策樹并最終得到了預測結果較好的模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
High Technology Letters(2017年3期)2017-09-25 12:53:30
中國老區建設(2016年3期)2017-01-15 13:53:21
光學精密工程(2016年6期)2016-11-07 09:07:19
