基于數據挖掘技術的工業爐運行優化方法研究
2022-09-26 09:16:34劉彩利
工業加熱 2022年8期
劉彩利
(西安外事學院,陜西 西安 710077)
當前工業領域已實現了分布式控制系統的普遍應用,多數用于采集海量運行數據信息,由于運行數據具備大數據級別的數據量、動態化、多元化、高維度化、強關聯等特性,導致數據挖掘分析難度加大,為獲取正確結論,需在數據挖掘分析前做好篩選等預處理工作。所以為獲取有價值的數據信息,需采取更加成熟完善的數據預處理與挖掘技術[1]。在我國科技發展推動下,數據挖掘技術應用研究獲得了顯著成果,且實現了在工業領域的廣泛應用。然而,多數情況下均是以單一式工業爐效率或者供電煤耗率為主要性能指標,對此在我國積極采取突破行業壟斷與開放式市場等政策的形勢下,工業領域需基于綜合考慮工業爐運行成本,且優化運行[2]。
1 數據挖掘技術原理
數據挖掘即數據庫內的知識發現,是由海量數據中充分挖掘處理有價值的知識規則。數據挖掘主要是為了監控異常模式并尋求最佳模式,以歷史數據信息預言未來發展動態,從而強化管理層決策水平與能力。在數據挖掘技術實際應用時,需安排專業人員加以操作,才可發現并評價知識。數據挖掘處理過程具有反復性,其運行流程[3]具體見圖1。
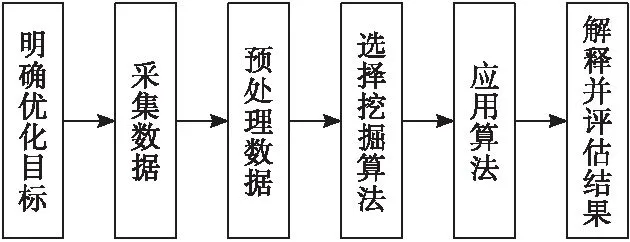
圖1 數據挖掘運行流程
其中,決策樹、神經網絡、K-means聚類與關聯規則算法是最常見的數據挖掘算法。決策樹即根據概率與圖論樹對比分析各決策不同的設計方案,以助于決策者獲取最佳方案的風險分析方法,屬于預測評估模型,為對象屬性與對象值之間的彼此映射。神經網絡即模仿動物大腦神經突觸結構,以處理分析數據信息的一種數學模型,由多種簡單輸入與輸出單元共同構成,各單元均具備各自的權重函數值。
關聯規則負責挖掘數據各項集間的相互關系,表示方式具體為A-B(s,c),其中s與c為規則支持度與置信度,其是關聯規則的關鍵指標,前者代表項集A與B共同處于同一事務內的概率,表示規則實用性,后者代表項集A事務內同時存在項集B的概率,表示規則明確性。關聯規則運算流程[4]具體見圖2。
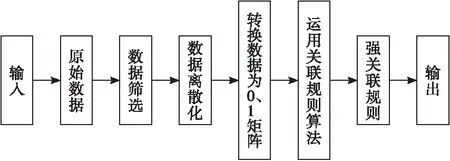
圖2 基于關聯規則的數據挖掘流程
2 基于數據挖掘技術的工業爐運行優化系統
工業爐運行性能指標和煤質、機組負荷、運行參數息息相關,此關系于工業爐歷史運行數據內呈現為煤質、負荷、運行參數、性能指標等數據項的關聯關系,在定量化之后,則展示出工業爐實際運行狀態的關聯規則。基于關聯規則處理運行數據,則可獲取強關聯規則,從中選擇指定工況下相應優異性能指標的規則,各項相關參數最優值便可指導工業爐實現運行優化。以聚類與關聯規則為載體的工業爐運行優化系統架構[5]具體見圖3。
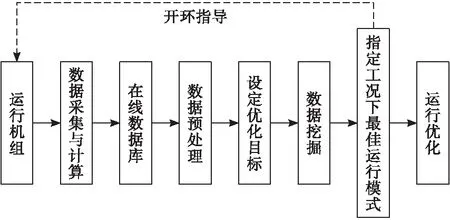
圖3 工業爐運行優化系統架構
3 基于關聯規則的工業爐運行優化最佳值
工業爐運行優化最佳值即現階段工況下工業爐達到最優運行工況時,工業爐的目標函數與運行參數等具體值。運行優化工況涉獵環境、煤質、負荷等等,目標函數通常代表工業爐效率或者供電煤耗率,運行參數通常代表磨煤機組合、一次風量、二次風量、OFA風量、燃燒器二次風門開度等[6]。
工業爐運行參數最佳值確定也就是基于工業爐運行性能空間,以其性能指標達到作為目標函數的尋優問題,前提條件為以現階段運行工業爐設備為載體。運行優化性能指標通常選擇工業爐效率或者供電煤耗率作為性能指標,其合理性選擇是工業爐運行優化的關鍵所在,而綜合性能指標可全方位評估工業爐性能,并實現偏差分析。在確定工業爐運行參數最佳值之后,便可就其和性能指標、運行參數之間的偏差詳細分析工業爐運行狀況,以促使運行人員充分掌握設備運行特征,以調整工業爐運行狀態,確保其長時間保持在最優運行工況下。
機組運行經濟性和運行參數之間表現為繁雜的函數關系,但是具體明確體現機組最佳經濟性的相關運行參數難度較大。在工業爐運行優化時,需充分考慮機組經濟性的影響因素,尤其是可調整可控制因素[7]。
在其他參數既定狀態時,以300 MW機組為例,分析基于排煙溫度變化的工業爐效率,具體見表1。

表1 基于排煙溫度變化的工業爐效率
由表1可知,在排煙溫度上升的趨勢下,其他參數不變,則工業爐效率呈現線性下降態勢。因此,工業爐運行過程中,機組應最大程度上縮減造成排煙溫度上升的因素,從而防止排煙熱損失增加,工業爐效率下降,機組經濟性受影響[8]。
機組在300 MW負荷下基于過量空氣系數變化的工業爐效率具體見表2。

表2 300 MW負荷下基于過量空氣系數變化的工業爐效率
機組在270 MW負荷下基于過量空氣系數變化的工業爐效率具體見表3。

表3 270 MW負荷下基于過量空氣系數變化的工業爐效率
機組在240 MW負荷下基于過量空氣系數變化的工業爐效率具體見表4。

表4 240MW負荷下基于過量空氣系數變化的工業爐效率
由表4可知,在過量空氣系數逐漸增大的形勢下,工業爐熱效率不斷攀升,直到最大值狀態,隨后開始降低。過量空氣系數上升時,出現最佳過量空氣系數。基于排煙溫度與過量空氣系數對工業爐效率的影響作用,以面向300 MW機組歷史數據庫的挖掘提取100%負荷條件下,過量空氣系數與排煙溫度的最優值,表明了關聯規則的實踐應用。
4 基于關聯規則數據挖掘的工業爐優化運行方法
以面向300 MW機組歷史數據庫的挖掘提取100%負荷條件下,過量空氣系數與排煙溫度的最優值,表明了關聯規則的實踐應用[9]。其中,原始數據具體見表5。
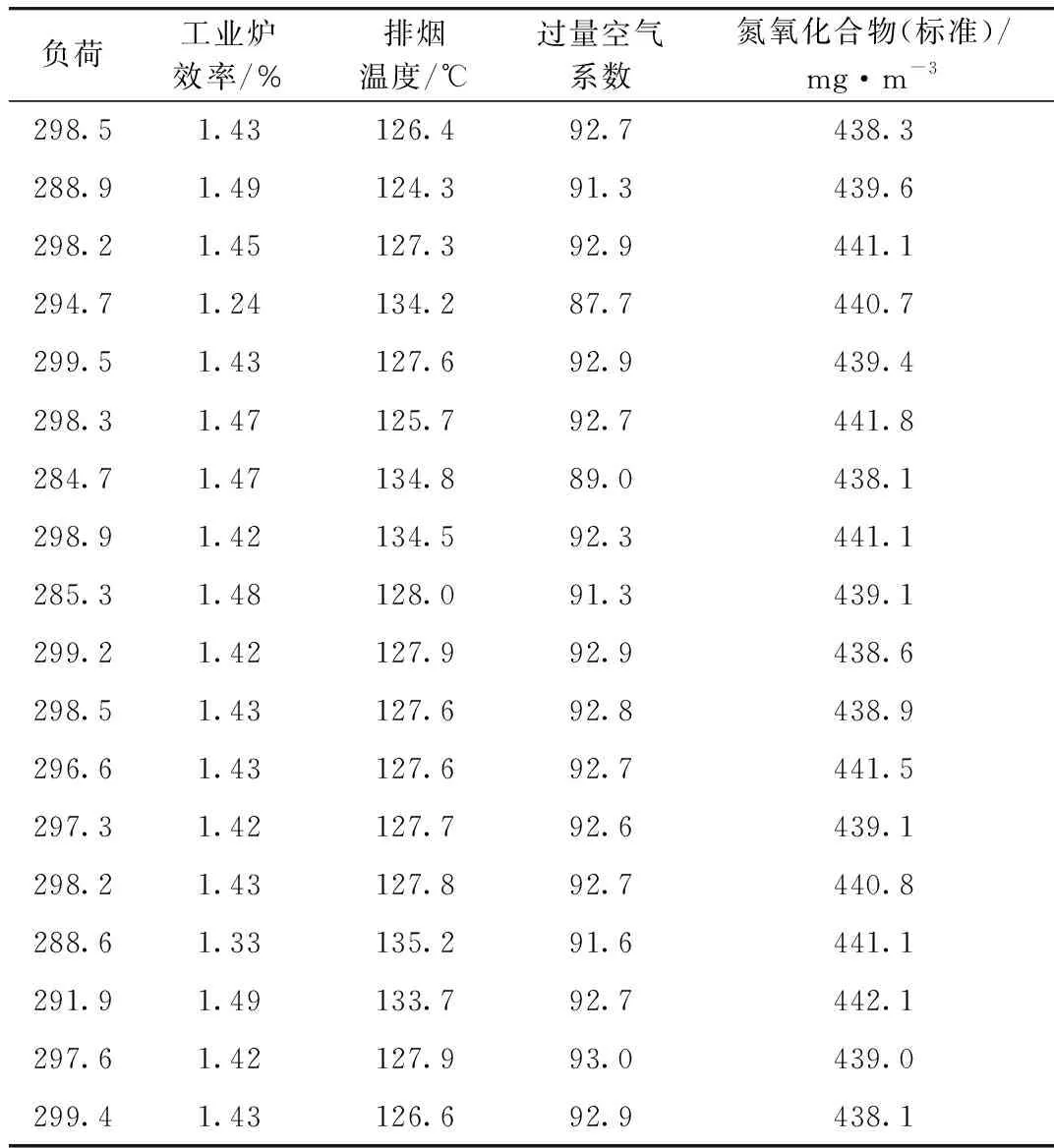
表5 原始數據
其中部分原始數據是無效的,為降低數據挖掘復雜性,提高數據挖掘精確性,需清洗原始數據。在原始數據清洗時,則就用戶在系統設置中設定的參數上下限值進行數據有效性檢測,而針對偏離用戶設定的取值區間數據,則看作無效數據,加以清洗。其中,機組負荷有效區間是[285,300];工業爐效率有效區間值是[1.4,1.5];排煙溫度有效區間值是[124,135];過量空氣系數有效區間值是[91,93];氮氧化合物區間有效值是[438,442]。清洗后的數據具體見表6。
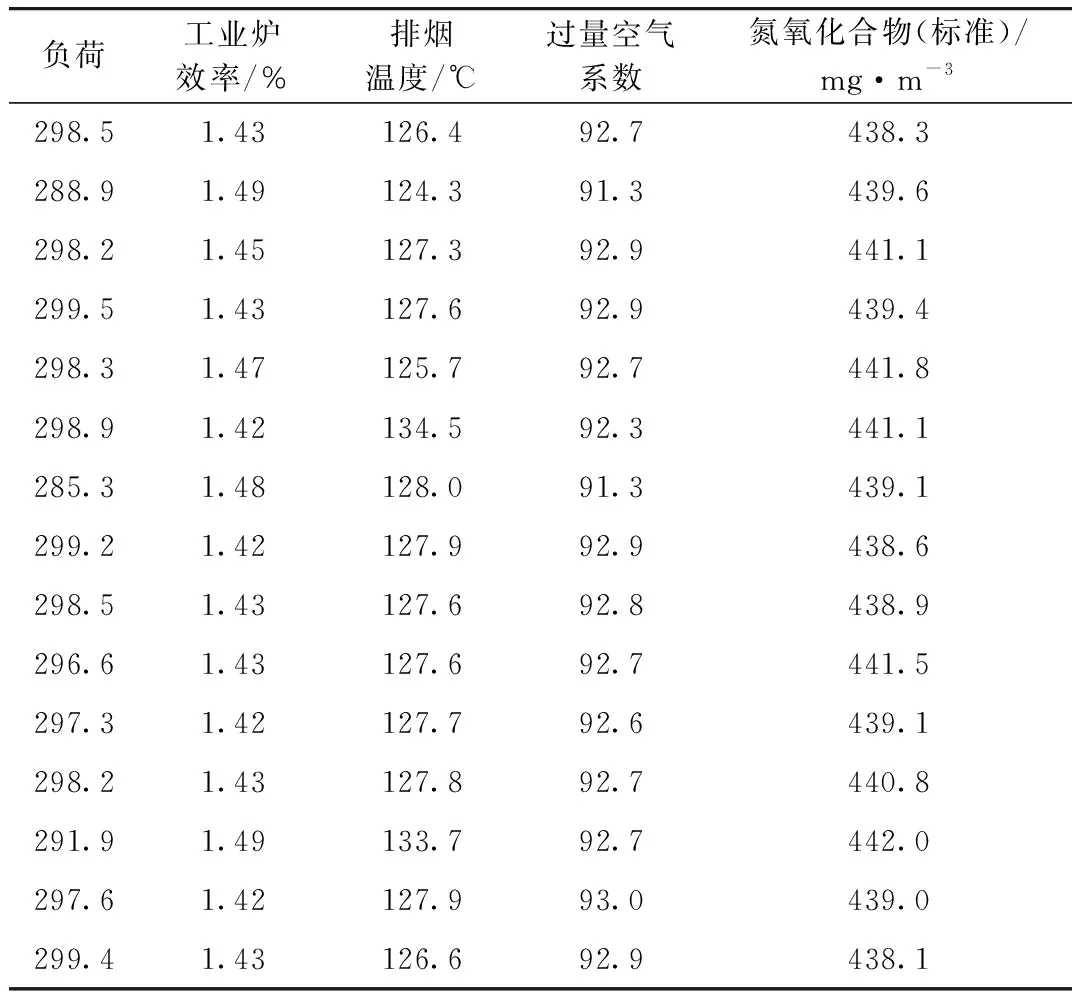
表6 清洗后的數據
以粒度離散化數據,把連續屬性數據值域范圍具體劃分為間隔相同的子區間,以特殊符號或者整數值代表各子區間。系統內機組負荷粒度設定為4,離散之后的數據11表示[296,300],基于設定過量空氣系數粒度為0.02,排煙溫度粒度為2,工業爐效率粒度為0.5,氮氧化合物粒度為1,可獲取對應離散值,即離散后的數據具體見表7。
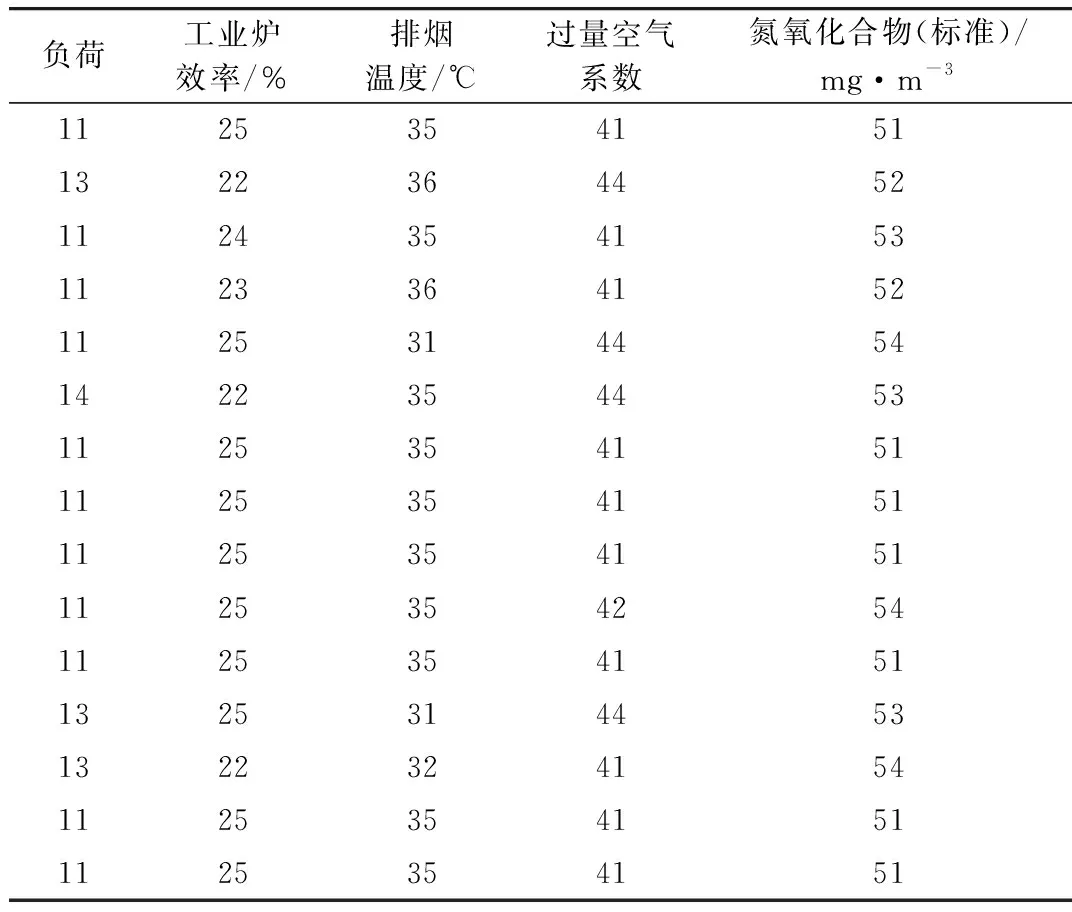
表7 離散后的數據
以關聯規則挖掘技術挖掘離散后數據,以獲取滿足置信度要求的關聯規則11∧25∧35∧51?41。在反離散化之后獲得機組負荷[285,289]∧過量空氣系數[1.48,1.5]∧排煙溫度[132,134]∧氮氧化合物[438,439]?工業爐效率[91,91.5],以區間中心值為目標值,獲取100%負荷下過量空氣系數目標值1.49,排煙溫度目標值133 ℃,氮氧化合物目標值438.5 mg/m3(標準),此時工業爐效率則會達到91.25%。以此數據挖掘方法運用在其他負荷下的最優化目標值確定中,并將運行最優化目標值看作設定值,以開展試驗[10],結果具體見表8。
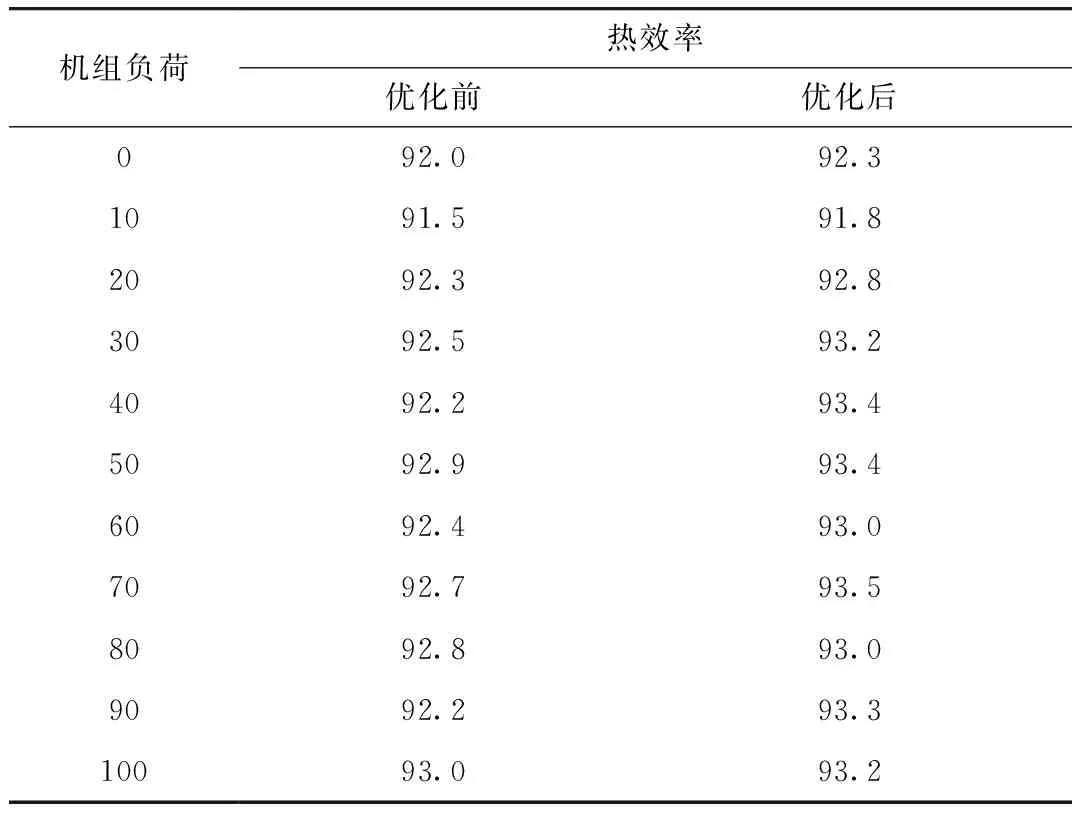
表8 運行優化前后的工業爐效率 %
由表8可知,利用關聯規則挖掘確定的工業爐運行參數最佳值應用在工業爐運行中,可顯著提升工業爐運行效率,還可促使工業爐運行效率維持在較高且較穩定的水平狀態,同時可在很大程度上降低氮氧化合物排放量。
5 結 論
綜上所述,在海量傳感器數據與專家經驗提供了許多機組運行狀態信息,以數據挖掘方法對信息資源進行加工利用,有利于工業爐運行優化,并提高機組經濟性與可靠性。因此,本文在運行優化過程中引進了數據挖掘技術,提出了基于數據挖掘技術的工業爐運行優化方法,并在關聯規則輔助下確定了運行優化最佳值。同時對工業爐運行優化方法進行了實際應用分析,結果表明,利用關聯規則挖掘確定的工業爐運行參數最佳值應用在工業爐運行中,可顯著提升工業爐運行效率,還可促使工業爐運行效率維持在較高且較穩定的水平狀態,同時可在很大程度上降低氮氧化合物排放量。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
