基于注意力機制卷積脈沖神經網絡的目標識別方法*
2022-11-09 02:34:20張軍軍
計算機與數字工程 2022年9期
關鍵詞:分類
張軍軍
(西安工程大學計算機科學學院 西安 710048)
1 引言
了解大腦如何有效地處理信息是現代神經科學研究的關鍵問題之一。由于組成大腦的神經元數目龐大,連接方式多樣,其生理機制復雜。近年來,隨著信息科學的飛速發展,計算機模擬大腦信息處理機制研究逐漸成為可能。如何有效地認知大腦處理信息的機理是神經科學與信息科學交叉研究的一個重要方向,也是類腦計算領域研究的關鍵問題之一。
脈沖神經網絡(Spiking Neural Network,SNN)是目前最具有神經形態的網絡[1],被稱為第三代神經網絡[2]。受神經科學的啟發,SNN具有接近生物神經系統的神經元模型,其特點是通過脈沖序列放電時間來進行信息傳遞[3],SNN提供了稀疏且強大的計算能力[4~5],并實現了超低功耗事件驅動處理的神經形態硬件[6]。目前,最常用的脈沖神經元模型主要是漏積分點火神經元模型(Leaky Intergrate and Fire Model,LIF)[7],它簡化了霍奇金赫胥黎模型(Hodgkin Huxley Model,HH)[8],LIF通過對細胞膜電位隨時間和外部電流輸入的變化進行建模來描述神經元的復雜動態變化,LIF模型簡單但不夠精確仿真神經元的特性。HH模型具有高度仿生性,但模型復雜。2003年,Izhikevich提出了Izhikevich模型[9],它簡化了HH模型,同時又具有較高的仿生性。常用的SNN的學習算法主要有基于梯度下降的監督學習算法和基于突觸可塑性的無監督學習算法。基于梯度下降的學習算法主要以SpikeProp[10]為主,它首次將反向傳播推廣到SNN,但只能訓練單層網絡,隨后,眾多學者對SpikeProp[10]進行改進,如Xin[11]提出了帶動量的梯度下降方 法。Kennoch[12]提出了RProp和Quick-Prop算法,旨在加速網絡學習算法收斂速度。Booij[13]提出了Muitl-SpikeProp在網絡學習性能方面也得到了提升。基于突觸可塑性的無監督學習算法主要有脈沖時序依賴可塑性(Spike-Timing-Dependent Plasticity,STDP)[14]和Ponulak等[15]提出的遠程監督學習算法(Remote supervised method,ReSuMe)。這兩種算法都是基于Hebb學習規則[16]對網絡權值進行調節。
近年來,隨著深度學習的進一步發展,在網絡結構中加入一些重要的模塊進一步提升網絡的學習性能逐漸引起了學者們的關注。其中,注意力機制(Attention Mechanism)作為一個模塊,加入網絡模型構建過程中已成為關注的焦點。2016年,Liu等[17]提出了一種基于強化學習的全卷積注意定位網絡,用于自適應選擇多任務驅動的視覺注意區域。Wang等[18]提出了(Ranking Attention Network,RANet)網絡,將注意力機制引入了殘差網絡中。Hu等[19]提出了(Squeeze-and-Excitation Networks,SENet)網絡,獲得了ImageNet 2017競賽圖像分類任務的冠軍。隨后,Woo等[20]提出了卷積塊注意力模 塊(Convolutional Block Attention Module,CBAM),設計了一種學習通道和空間位置重要性的方法。
為了克服傳統人工神經網絡學習效率低,網絡訓練耗時長等問題,本文融合了脈沖神經網絡和卷積注意力模塊構建了一種基于注意力機制的卷積脈沖神經網絡(AMCSNN)用于目標識別。本文貢獻總結如下:
1)將注意力機制應用于脈沖神經網絡。結合脈沖神經網絡和卷積注意力設計新的AMCSNN,在MNIST和Caltech數據集上取得了較好的識別效果。
2)設計了高斯差分時序編碼方法。所提出的方法能夠對高斯差分濾波器提取的視覺特征進行脈沖時序編碼,從而在AMCSNN中實現快速準確的信息傳遞。
3)采用無監督的生物可塑性算法加監督學習方法來進行網絡的學習和分類,在MNIST和Caltech數據集上的仿真實驗表明,提出AMCSNN網絡具有較強的生物合理性優勢,在保證識別率的同時,具有較高的學習效率和較短的網絡訓練耗時。
2 脈沖神經網絡
2.1 脈沖神經元模型
脈沖神經元的狀態主要受膜電位和閾值電位的控制,而膜電位主要由來自上一層神經元的突觸后電位決定,突觸后電位分為興奮性電位和抑制性電位,分別使神經元的膜電位升高或降低[21]。本文主要采用LIF神經元模型。
LIF神經元模型是一個線性微分方程,如式(1)所示。
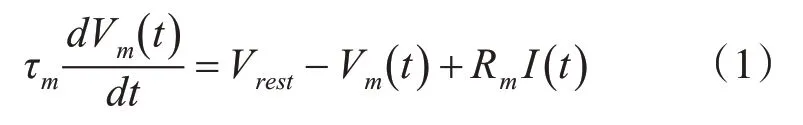
其中,Vm(t)表示神經元的膜電位,Vrest是靜息電位,時間常數τm是膜電阻Rm和膜電容Cm的乘積,I(t)是突觸后神經元的輸入電流。
在LIF模型中,當突觸后神經元接收到突觸前神經元的脈沖信號時,其膜電位會不斷的累積,當膜電位達到閾值電位時,則會發出一個脈沖信號,之后神經元進入不應期,膜電位會被重置為靜息電位。
2.2 突觸可塑性算法
本文使用無監督的STDP學習算法來進行權重的更新,學習是逐層完成的。STDP是基于突觸前和突觸后的脈沖發放時間順序來進行的,它是一種無監督的學習規則。STDP的規則是:如果突觸前神經元比突觸后神經元先受到刺激,則會引起突觸的長時程增強,即兩個神經元突觸之間的連接權值將增大,否則會引起突觸的長時程抑制,即兩個神經元突觸之間的連接權值將減小。我們使用的STDP如式(2)所示。
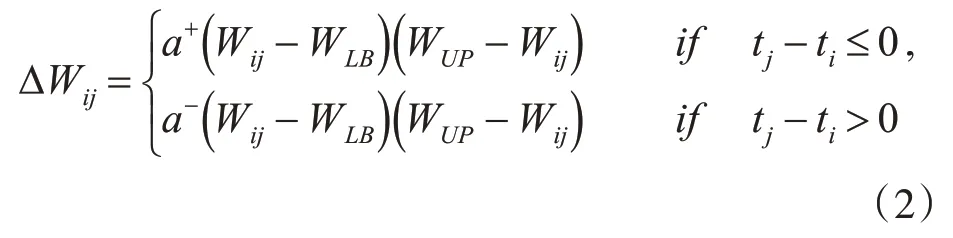
其中,i和j分別表示突觸后和突觸前神經元下標,ti和tj是相應的脈沖發放時間,ΔWij是連接兩個神經元的突觸權重變化量,a+和a-是突觸縮放權重變化的大小,即學習率,乘法項(Wij-WLB)(WUP-Wij)是一個穩定項,當突觸權重接近于較低的權重下限WLB和較高的權重上限WUP時,它會減慢權重變化的速度。
3 基于注意力的卷積脈沖神經網絡
3.1 AMCSNN網絡結構
AMCSNN網絡結構如圖1所示,從上到下依次為高斯差分時序編碼層、卷積層1(C1)、CBAM層1、STDP層1、池化層1(S1)、卷積層2(C2)、CBAM層2、STDP層2、池化層2(S2),最后通過支持向量機(Support Vector Machine,SVM)來完成目標分類。編碼層主要進行簡單的圖像預處理和像素編碼,卷積層主要進行特征提取,CBAM層從通道和空間兩個維度實現卷積層的特征輸出,得到更高維度的特征。STDP層根據神經元輸入的脈沖時序自適應調整連接權重,通過自適應學習方式獲得網絡的共享權值。池化層主要用來降維,以減少信息的冗余。

圖1 AMCSNN網絡結構
3.2 高斯差分時序編碼層
提出的AMCSNN中設計了高斯差分時序編碼層,旨在將目標的視覺特征編碼為脈沖序列。
本文采用時間步長來模擬神經元的首個脈沖時間,因為每次刺激神經元最多發出一個脈沖,按時間步長足以記錄神經元的首個脈沖時間。
為了方便描述,本文假設一個刺激由特征圖F表示,包含H×W個神經元網格,設Tmax是總的時間步長,Tf,r,c表示特征圖f在(r,c)位置的脈沖時間,其中,0≤f<F,0≤r<H,0≤c<W,Tf,r,c∈{0,1,2,…,Tmax-1}U{∞},∞表示沒有脈沖發射。最后產生大小為Tmax×F×H×W的脈沖波張量為S,表示Tmax個時間步長產生的脈沖序列,如式(3)所示。

高斯差分時序編碼步驟如下:
步驟1首先判斷圖像是否為灰度圖像,是轉步驟3,否轉步驟2。
步驟2將輸入圖像轉為灰度圖像。
步驟3將圖像轉換為張量格式,方便數據處理。
步驟4增加時間維度,得到四維張量。
步驟5構造高斯差分函數,兩個二維高斯核函數的核大小和標準差分別為(7,1,2)和(7,2,1),填充為3,將步驟4得到的四維張量與高斯差分核函數卷積,結果記為out,同時設定閾值為50,將out中小于閾值50的像素值設為0,并輸出out。
步驟6將out執行歸一化操作。歸一化半徑r設為8,采用二維卷積計算每個區域(大小為2r+1)的圖像強度均值,并使用該區域中每個像素點的灰度值除以區域均值完成out的局部歸一化。
步驟7將歸一化后的四維張量轉化為脈沖波張量。首先統計圖像強度不為0的像素點的個數記為cnt,輸入的總的時間步長記為Tmax,用cnt除以Tmax得到每個時間步長的神經元網格,然后降序排序每個時間步長的神經元網格,分割排序后的神經元網格,得到每個網格的像素值和其索引,返回每個時間步長的網格值,取其符號值(正的為1,負的為0)作為脈沖,得到最后的脈沖波張量即脈沖序列。
3.3 脈沖卷積層
脈沖卷積層的輸入對象為高斯差分時序編碼層得到的脈沖波張量即神經元的放電時間脈沖序列。一個脈沖卷積運算由式(4)表示。
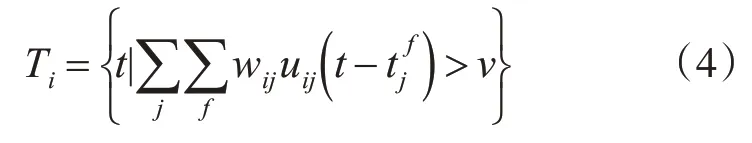
其中,Ti表示神經元i的放電時間序列集合,wij表示突觸前神經元j和突觸后神經元i的突觸權重,uij表示神經元i的突觸后膜電位,tf j表示神經元j在f時刻的放電時間,ν為閾值電位,本文設置靜息電位為0。整個公式表示的是對突觸后電位的加權和,當突觸后電位的加權和超過閾值電位時,就會在時間t產生一個脈沖,之后回到靜息電位。
脈沖卷積采用突觸后膜電位函數uij來進行脈沖放電激活,由式(5)表示。
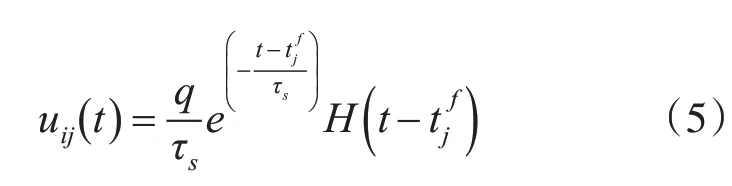
其中,H(*)是赫維賽德階躍函數,q是注入突觸后神經元i的總電荷,tjf表示神經元j在f時刻的放電時間,τs是突觸電流時間延遲常數。
3.4 卷積注意力模塊
本文加入的注意力模型CBAM如圖2所示,是一種結合了空間和通道的注意力機制模塊,它常被加入到一些傳統網絡結構中來提高網絡模型的分類效果。
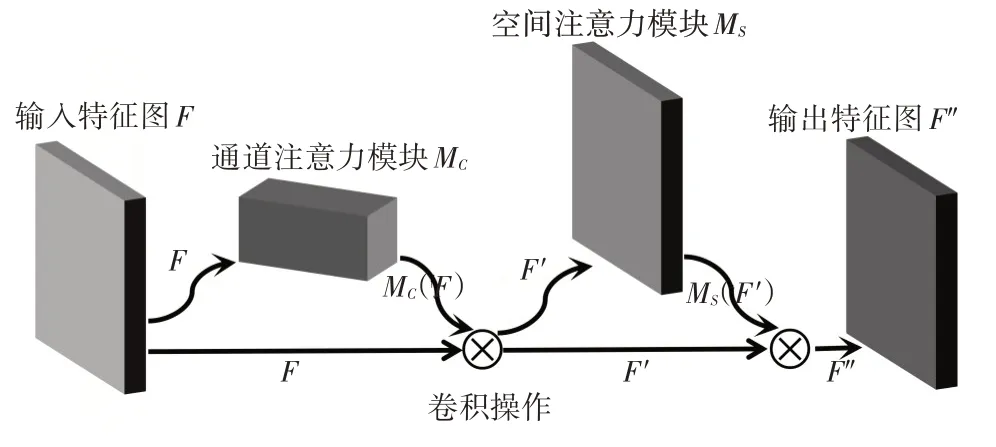
圖2 CBAM模塊的整體計算過程
對來自于卷積層的特征圖F應用CBAM,計算如式(6)所示。
其中,MC表示在一維通道上的注意力提取操作,MS表示在二維空間上的注意力提取操作,?表示卷積操作,F′表示通道注意力的輸出,F′表示最終的注意力輸出。
對于通道和空間注意力的計算如式(7)所示。
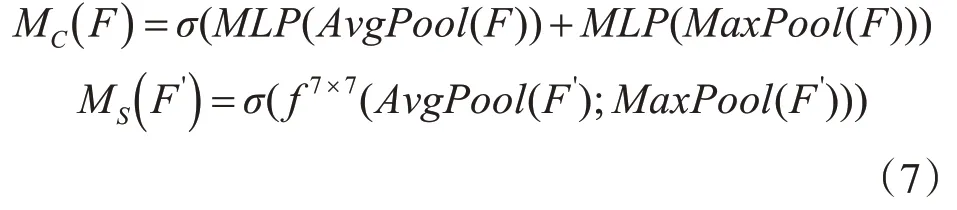
其中,σ表示Sigmoid函數,AνgPool和MaxPool分別表示平均池化和最大池化。MLP表示多層感知器。
4 實驗結果及分析
4.1 實驗數據及網絡配置
本文實驗運行平臺的配置以及Python和Pytorch的版本如下:運行平臺處理器為Intel(R)Xeon(R)CPU E5-2630 v4@2.20GHz,系統為Ubuntu 16.04.6 LTS(64位),內核版本為4.4.0,Python版本為3.6.5,Pytorch版本為1.2。為了保證在短時間內完成模型訓練,模型加速器采用了GPU。為了模擬我們的AMCSNN,使用了SpykeTorch模擬器[22]。
為了驗證AMCSNN網絡的有效性,在兩個公開數據集MNIST數據集和Caltech數據集上進行了實驗。此外,進一步在ETH-80面向圖像集的數據集上驗證了AMCSNN分類任務的有效性。
MNIST數據集是驗證SNN網絡有效性的首選數據集。本文選取數據集的60000張圖片作為訓練集,10000張圖片作為測試集。
Caltech101數據集是常用的計算機視覺數據集,其中包含101個類別圖片,每類不超過80張圖片。本文選取Caltech(FACE/MOTORBIKE)兩類物體進行實驗,首先對Caltech(FACE/MOTORBIKE)數據集隨機劃分,其中每類訓練集含隨機選擇的200張圖片,其余構成測試集。
在整個網絡的訓練中,只有兩個卷積層需要通過學習來更新權重,特征的提取和分類是完全分開的,網絡各層的具體參數如表1所示。本文對兩個卷積層均做了500次的權重更新。

表1 網絡各層的參數
說明:表1中沒有STDP層,是因為STDP主要作用于卷積層,故其參數學習率在卷積層給出。脈沖發放的總時間步長為15,在MNIST數據集上SVM的輸出為10,在Caltech數據集上SVM的輸出為2,在Caltech數據集上SVM的輸出為8,SVM的懲罰參數為2.4。
4.2 評估指標
為定量分析和評估AMCSNN網絡的分類效果,本文將AMCSNN與卷積脈沖神經網絡(Convolutional Spiking Neural Network,CSNN)和卷積神經網絡(Convolutional Neural Network,CNN)在MNIST和Caltech數據集上分別進行了實驗。本文采用分類準確率來評價網絡的分類效果,其計算如式(8)所示。
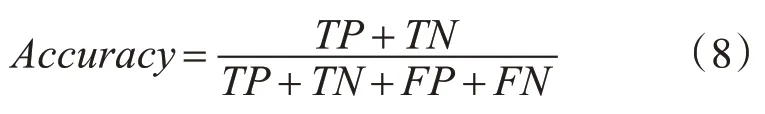
其中,TP(True Positive)即正例識別正確的個數,FP(False Negative)即非正例被錯誤識別為正例的個數,TN(True Negative)即非正例識別正確的個數,FN(False Positive)即正例被錯誤識別為非正例的個數。
此外,采用網絡訓練耗時來評價網絡的計算效率,綜合考慮網絡分類準確率和網絡訓練耗時來評判網絡有效性。即分類準確率高且耗時少的網絡越有效。
4.3 實驗分析
本文提出的AMCSNN網絡與CSNN以及CNN在MNIST和Caltech數據集上的網絡識別準確率如表2所示。
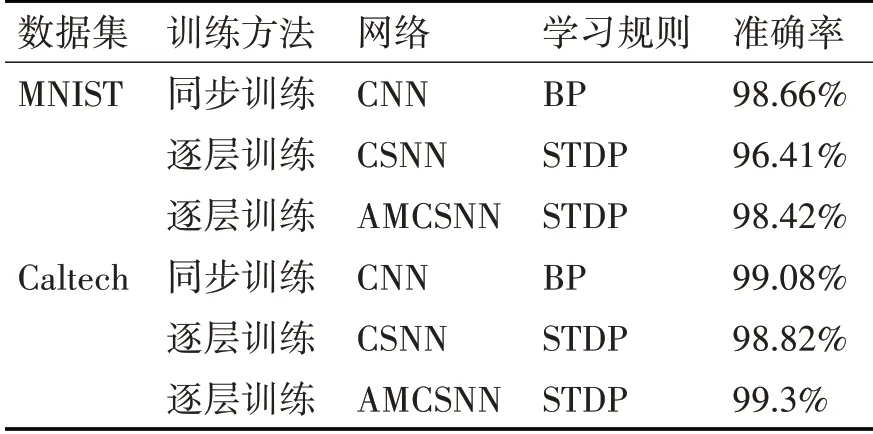
表2 不同網絡在MNIST和Caltech(2類)以及ETH-80數據集上的分類準確率
從表2可以看出,在MNIST和Caltech數據集上,AMCSNN網絡的識別準確率分別為98.42%和99.3%,與使用相同訓練方式和學習規則的CSNN相比,AMCSNN的識別率更高,與基于反向傳播訓練的CNN網絡相比,針對MNIST數據集,提出的AMCSNN識別準確率僅相差0.24%,針對Caltech數據集僅相差0.22%。
此外,圖3可視化了AMCSNN在MNIST數據集上的混淆矩陣,可以看到,AMSCNN除了對類別“3”和“8”的分類準確率在97%以外,其他8種類別的分類準確率均在98%以上,特別是對類別“1”和“4”以及“6”的分類準確率均達到了99%以上,這充分表明了AMSCNN網絡具有良好的分類效果。

圖3 AMCSNN在MNIST上的混淆矩陣
圖4采用ROC曲線對使用同樣訓練方式和學習規則的AMCSNN和CSNN在Caltech數據集上進行了比較。根據ROC曲線,由圖4可以看到,AMCSNN在Caltech上的網絡分類效果要優于CSNN。
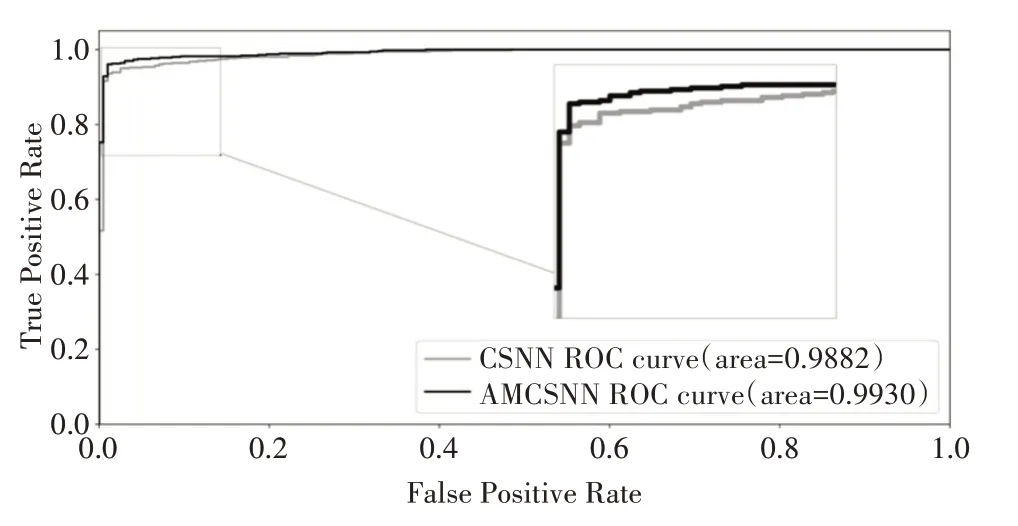
圖4 AMCSNN與CSNN在Caltech(2類)上的ROC曲線
圖5比較了3種網絡的訓練耗時。可以看到,AMCSNN相比于CSNN和CNN網絡耗時較少,一方面得益于SNN的稀疏性和強大的計算能力[4~5],使得網絡功耗比較低,另一方面是因為輕量級的CBAM模塊對平均池化和最大池化的綜合應用,有助于計算性能的提升[20]。因此,CBAM模塊的加入看似增加了網絡的計算量,實則對網絡計算性能的提升裨益良多。通過上述實驗結果,綜合考慮網絡分類準確率和平均訓練耗時,可以看到AMCSNN不僅具有較強的生物合理性優勢,而且在保證準確率的同時,具有較高的學習效率和較短的網絡耗時,充分證明了AMCSNN網絡的有效性。

圖5 MNIST和Caltech(2類)上的網絡訓練耗時比較
5 結語
本文提出了一種基于注意力機制的卷積脈沖神經網絡(AMCSNN)用于目標識別。該網絡加入了輕量級的CBAM模塊,融合了脈沖神經網絡和卷積神經網絡的優勢,有效解決了傳統人工神經網絡因采用反向傳播導致學習效率低、網絡訓練耗時長等問題。本文采用無監督的STDP學習算法分層訓練網絡權重,最后使用支持向量機分類。實驗表明,該網絡具有較強的生物合理性優勢,在保證識別率的同時,具有較高的學習效率和較短的網絡訓練耗時。今后將考慮設計合理的脈沖編碼方式,繼續優化網絡。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
