基于輕量級模型共享的聯合半監督學習
2022-11-17 10:28:22王世輝莫錦華
企業科技與發展 2022年7期
王世輝,朱 曉,莫錦華
(1.廣西大學信息網絡中心,廣西 南寧 530004;2.廣西工業職業技術學院電子信息學院,廣西 南寧 530001;3 .廣西科技信息網絡中心,廣西 南寧 530015)
0 引言
在傳統的以云為中心的方法中,移動設備收集的數據在基于云的服務器或數據中心集中上傳和處理。具體來說,物聯網設備和智能手機收集的數據,例如測量、照片、視頻和位置信息在數據中心被聚集。此后,這些數據被用來提供見解或產生有效的推理模型。然而,這種方法不再可持續,原因如下。首先,數據所有者對隱私越來越敏感。隨著大數據時代消費者對隱私的擔憂,政策制定者的回應是實施了數據隱私立法,如歐盟的《通用數據保護條例》和美國的《消費者隱私權利法案》。其次,以云為中心的方法涉及很長的傳播延遲,并且對必須做出實時決策的應用(例如自動駕駛汽車系統)會產生不可接受的延遲。最后,將數據傳輸到云進行處理會給主干網絡帶來負擔,特別是在涉及非結構化數據的任務中,例如視頻分析。因此,這可能會阻礙新技術的發展。
為了保證訓練數據保留在個人設備上,并促進分布式設備之間復雜模型的協作機器學習,引入了一種稱為聯合學習(FL)的去中心化機器學習(Machine Learning,ML)方法[1]。在FL中,移動設備使用它們的本地數據協同訓練FL服務器所需的ML模型。然后,它們將模型更新(模型的權重)發送到FL服務器以進行聚合。這些步驟在多個回合中重復,直到達到所需的精度。這意味著FL可以成為移動邊緣網絡中ML模型訓練的使能技術。與傳統的以云為中心的訓練方法相比,在移動邊緣網絡上實現FL的模型訓練具有以下優勢。
聯合學習是近年來研究比較活躍的一種機器學習框架。FL利用客戶的計算能力,在沒有數據共享的情況下實現本地模型培訓,幫助解決隱私問題。主流方法如FedAvg或FedProx,要求客戶端將本地訓練的模型發送到服務器,而服務器使用某種聚合方法更新全局模型。一旦全球模型被更新,全局權重被廣播回客戶,完成一輪訓練。一輪又一輪地重復,直到達到收斂。
然而,在大規模實施FL之前,還有幾個問題需要解決。首先,盡管不再需要將原始數據發送到云服務器,但是模型更新的高度維度和參與的移動設備的通信帶寬有限,通信成本仍然是一個問題。特別是,最先進的DNN模型訓練可以涉及用于聚合的數百萬個參數的通信。其次,在大型復雜的移動邊緣網絡中,參與設備在數據質量、計算能力和參與意愿方面的異構性必須從資源分配的角度得到很好的管理。最后,FL不保證惡意參與者或服務器在場時的隱私。
現有的FL方法大多集中在監督學習(Supervise Learning)設置上[2],客戶端的數據被完整地標記。然而,考慮到已標記數據的獲取成本很高,假設客戶端數據大多是未標記的是可行的。客戶端上的標簽數據不是一個實際的設置,因為在現實世界中,邊緣設備上的數據通常沒有完全標簽。例如,一些用戶可能會在手機中標記圖像,但由于標記數據需要時間和人力,不能指望用戶標記設備中的所有數據。如果數據被采集到服務器,可以聘請一些專家進行標記,但邊緣設備上的數據被用戶標記的可能性較小,可能因為不專業而被錯誤標記。因此,研究聯合半監督學習具有重要意義。聯合半監督學習(FSSL)是為了從未標記的客戶端數據中獲取價值。雖然已經提出了許多半監督學習(SSL)方法,如FixMatch和UDA[3],但是簡單地將本地模型訓練替換為SSL方法的半監督學習應用不太成功。這是因為客戶的數據量有限且異構性(非I.I.D.)數據分布,造成局部模型之間的高度梯度差異。
FedMatch被提出來解決上述問題,使客戶端能夠在使用未標記數據時利用來自其他客戶端的知識,從而防止本地模型發散。然而,它以模型權重的形式進行客戶間知識共享的方法增加了客戶的通信和計算開銷,并且開銷與模型大小呈線性關系。考慮到客戶端比服務器更受資源限制,增加客戶端負擔在FSSL中是不可取的。此外,研究表明,它提供的準確率明顯低于其他不在客戶之間共享知識的FSSL方法,這表明知識共享的想法可能是無效的,因此在客戶端進行模型共享是一個值得研究的問題。FSSL的總體訓練流程圖如圖1所示。

圖1 FSSL的總體訓練流程圖
本文重新審視了客戶之間的知識共享,并開發了一種定制方法,在客戶之間共享知識,而不使用模型權重,以實現有效的客戶間一致性規則;提出了采用輕量級模型共享的方案,引用了最初為基于度量的元學習實現FSSL。在提出的方案中,客戶之間的知識以比模型參數輕得多的文本形式共享。每個客戶利用共享的原型對其未標記數據進行一致性正則化,從而提高了偽標記的質量,減少了非I.I.D中的局部模型發散。考慮到原型的通信成本較低,FSSL允許更多的客戶頻繁地共享知識,以更好地收斂模型。本文的主要貢獻如下:①研究了FSSL,這是FL在客戶上的一個實際應用,具有部分標記的數據。具體地說,我們提出了一種新的方法,將原型、客戶之間的知識共享和一致性正則化與FL相結合,以實現高效和準確的模型訓練。②設計了兩個輕量級組件來利用未標記的數據:模型參數共享和客戶間基于模型參數的偽標注。即使在輕量級ResNet9中,這些組件實現的通信為FedMatch的25%,與FedMatch和其他基于數據增強的一致性正則化方法相比,客戶端計算量減少了75%。此外,它們通過更頻繁地在更多客戶端之間共享知識來提高準確性。
1 基于模型共享的半監督聯合機器學習
本章節描述了FSSL的細節,旨在通過使用輕量級原型作為客戶端間的知識的一種形式,為FSSL提供高效的客戶端間一致性規則化。圖 1說明了FSSL架構。
1.1 有監督的聯合學習
聯合學習已經成為在邊緣網絡中分發機器學習模型的一種有吸引力的范例。雖然在機器學習的背景下有大量關于分布式優化的工作,但是聯合學習與傳統的分布式優化之間存在兩個關鍵挑戰——高度的系統和統計異構性。為了處理異質性和解決高通信成本,允許本地更新和低參與度的優化方法是聯合學習的流行方法[4]。
FedAvg 是一種典型的FL方法[5],該方法操作如下:每輪培訓r包括廣播、本地培訓和聚合。在廣播步驟中,服務器選擇一組m客戶端Mr,并將全局模型r-1發送到Mr中的客戶端。每個客戶端I(∈Mr)使用自己的數據和多個歷元E的基本事實標簽DI將r-1本地更新為。客戶端將本地模型發送回服務器,服務器將全局模型更新如下:
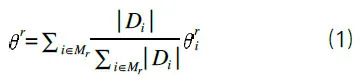
重要的是,假定客戶端數據集具有異構數據(非I.I.D.)分布。
FSSL對本地模型進行訓練,為嵌入空間中的每一類提供良好的嵌入空間和原型。該網絡將數據樣本轉換為嵌入向量,并使用與每個原型的距離對該向量進行分類。將k定義為類的集合,將Dk定義為類k(∈K)的訓練數據集。訓練集DK分為兩個部分:①支持集(SK),它是DK的隨機子集;②剩余的文本集(K)(DK減去 SK)。然后從支持集計算類k的原型:
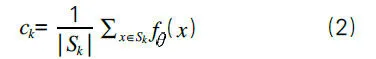
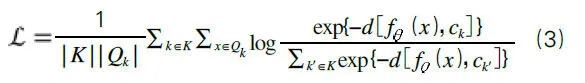
其中,d是歐幾里得距離函數。對模型進行訓練,使得同一類的嵌入向量靠近,而不同類的嵌入向量遠離。該算法結合了原型學習和聯合半監督學習的思想。
1.2 半監督FSSL系統分析
雖然聯合學習可以保護用戶隱私,但是現有的大多數方法都依賴于高度標注的數據。然而,邊緣用戶和設備具有不可預測的可變特性,在邊緣獲得標記數據使得當前的解決方案不切實際[5]。為了解決這些不足,人們提出了介于監督學習和非監督學習之間的半監督學習解決標簽數據不足的問題。半監督學習是機器學習的一個分支,介于監督學習和非監督學習之間,其中有幾個已標記的實例和大量的未標記的實例,并且已標記的數據點的數量不足以訓練期望的監督模型。監督學習框架中的一個主要挑戰是標簽實例的可用性。數據標注通常既耗時又昂貴,而且在每個邊界點都無法訪問。解決半監督學習的一種流行方法是通過在未標記的實例上訓練自動編碼器提取特征。自動編碼器是一種人工神經網絡,它從未標記的數據中學習數據表示。它的目標是將原始數據轉換為其壓縮表示,并在不丟失有價值的信息的情況下將其重建回其原始形式。
在半監督學習中,我們有少量的已標記數據和大量的未標記數據。已經有多次嘗試將聯合學習與半監督學習統一。考慮到用戶有大量的標簽數據,而服務器有一組標簽數據,Saeed等開發了一種自我監督的方法,從用戶的未標記數據中學習有價值的表示[6]。
然而,這些工作都沒有研究解決數據異構性問題的方法。我們考慮一個FSSL問題,其中服務器沒有數據,但每個客戶端I都有一個私有的非I.I.D.數據集,其中是已標記的數據集,而是未標記的數據集。K被定義為類別標簽的集合。對于所有客戶端,假定未標記的數據集比已標記的數據集大得多,即。有了數據設置,這項工作的目標是以聯合方式訓練一個由參數化的輕量級模型共享。在每個通信循環r,對于E局部歷元,每個參與的客戶端i使用其標記和未標記的數據集將全局參數r-1在客戶端本地更新為,并為每個k(∈K)更新其本地原型c。在每個局部i,k歷元中,客戶端I從中隨機抽樣一個帶標簽的支持集,并從中隨機抽樣一個帶標簽的查詢集,從中隨機抽樣一個未標記的查詢集。
如圖2所示,對于每個訓練歷元中關于未標記數據的本地訓練,Mr中的客戶端I使用來自Hr中的助手客戶端的外部原型標記其未標記的查詢數據。假設是客戶端在本地歷元e中的當前權重,客戶端i首先使用本地權重為未標記的數據點u計算嵌入向量。然后計算嵌入向量與每個類(k∈K)和輔助客戶端j(∈Hr)的原型cj,k之間的歐幾里得距離。對于幫助客戶端的原型,使用每個類別的距離的負數的Softmax計算未標記數據u成為類別k的概率,表示為pi,j,k(U)。
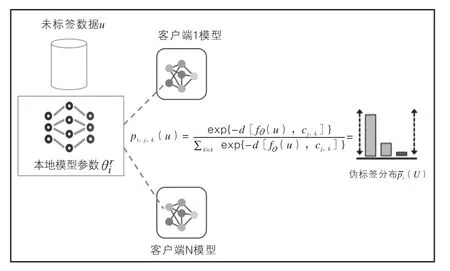
圖2 客戶端共享模型參數流程圖
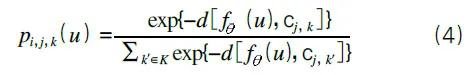
在計算每個幫助客戶端的原型的類概率后,u的平均類概率計算如下:

2 實驗結果
為了進行比較,我們遵循了FSSL中的設置。總共有100個客戶端,每輪隨機選擇5個活躍客戶端(m=5)參加訓練。我們在3個數據集(CIFAR-10、SVHN 和STL-10)進行了評估。我們將CIFAR-10數據分成54 000個訓練集、3 000個驗證集和3 000個測試集,將SVHN數據分成54 000個訓練集、2 000個驗證集和2 000個測試集。將訓練數據點分發給100個客戶端(即每個客戶端有540個數據),其中每個類標記5個實例,其余490個實例未標記。對于未標記的數據,我們使用I.I.D設置,其中每個客戶端每個類具有相同數量的數據,以及非I.I.D設置,每個客戶端具有不平衡的類分布。對于STL-10,每個客戶端有1 080個數據點,其中100個數據點已標記,其余980個未標記。由于STL-10最初是為SSL構建的,它不提供未標記數據的類別信息,因此我們將其未標記數據隨機分布到每個客戶端。由于STL-10未完全標記,因此無法在數據集中評估FedAVGSL和FedProx-SL。
本文比較了FSSL和基線的測試精度,將FedMatch參數設置為|Hr|=2。考慮到FSSL很容易擴展,本文將客戶端helper參數設置為|Hr|=5。經觀察發現,FSSL顯著優于FedAvg和FedProx基線,后者不使用未標記的數據。這表明FSSL能夠通過客戶端之間的原型交換偽標記從未標記的數據中提取知識。FSSL的性能也優于FL和SSL的簡 單 組 合(即FixMatch-FedAvg/FedProx) 和FedMatch,表明基于原型的知識共享優于無共享和基于模型的共享。值得注意的是,它在非I.I.D.環境中的性能下降是微乎其微的,這意味著客戶之間的原型有效地防止了客戶的偏見學習。在SVHN中,FSSL甚至可以與完全監督的學習案例相媲美。相比之下,FedMatch的精確度最低,甚至低于FedAvg和FedProx。這表明基于模型的知識共享的脆弱性。值得注意的是,在FedMatch的原始論文中,CIFAR-10上報告的測試下界精度更差(如圖3、圖4所示)。
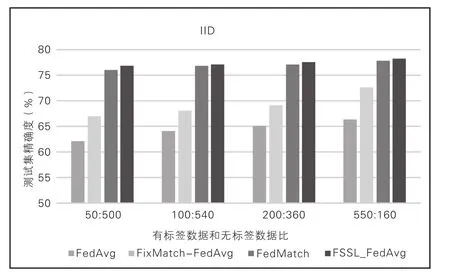
圖3 CIFAR-10測試集精度(I.I.D分布)
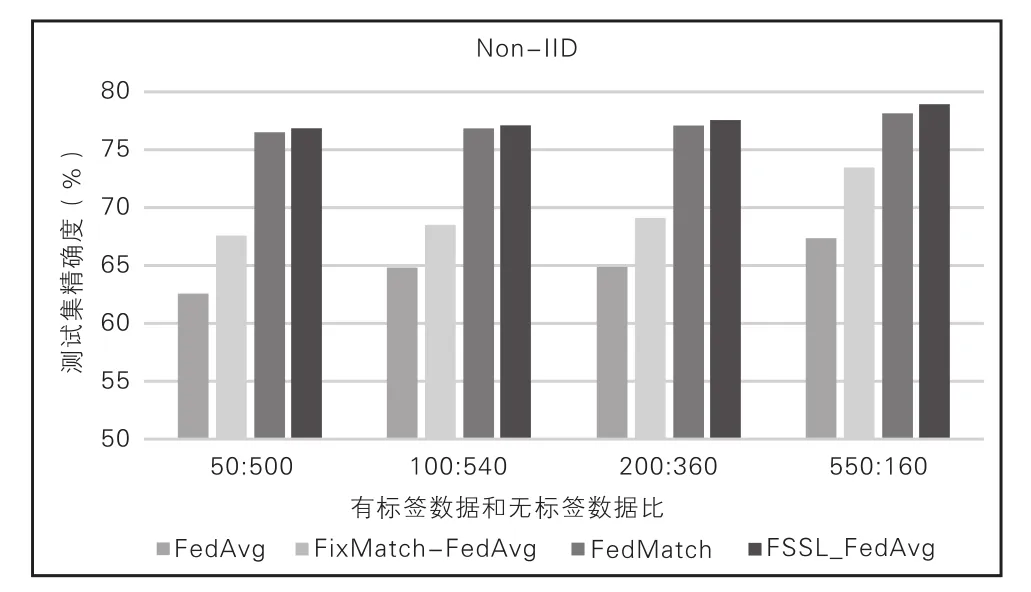
圖4 CIFAR-10測試集精度(Non-I.I.D分布)
3 結語
本文研究了異質數據分布下的聯合半監督學習,重點是在不增加資源受限客戶端的計算/通信負擔的情況下提高模型的收斂速度;提出了通過在客戶端之間交換輕量級模型參數來強制客戶端間一致性的建議;在實驗中,從訓練準確率方面對該方案進行了評估。作為將輕量級模型應用于FSSL的第一次嘗試,所提出的方案比現有的FSSL方法更有效。本文研究結果為未來基于輕量級模型的FSSL框架研究提供了新的思路。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
人大建設(2020年4期)2020-09-21 03:39:12
數學物理學報(2020年2期)2020-06-02 11:29:24
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
