基于混合神經網絡模型的企業行業分類
2022-12-23 12:03:12陳鋼
電子設計工程 2022年24期
陳鋼
(長三角信息智能創新研究院,安徽蕪湖 241000)
我國目前已有數千萬家企業,并且每年都有大量新企業設立。市場監督管理部門在企業注冊時都會強制要求其注明經營范圍,但是從分散的經營范圍中并不能直觀地得出該企業的行業歸屬[1]。除了上市公司會在網上公開自己的行業類別以外,其他大部分企業的行業類別都是未公開的。企業所屬行業由其經營范圍描述而得,經營范圍描述往往涉及到多個行業的描述,在現如今龐大的行業規模下人工進行行業分類存在效率低下、準確性不高等問題[2]。
行業分類自動化的一般過程是從企業的經營范圍文本中提取特征,然后使用分類器完成預測。企業經營范圍文本需要向量化后才能作為分類模型的標準輸入。Word2vec、glove 等詞向量模型可以通過將自然語言中的詞轉換為稠密的詞向量嵌入到神經網絡模型中,從而使神經網絡模型可以獲取更多、更精確的語義信息,以提升分類的準確率[3]。然而這類模型無法關注到上下文的關聯信息,在出現存在歧義的特征詞時可能無法正確表征,而包含大量先驗知識的預訓練語言模型可以有效解決這類問題[4]。門控循環單元(Gate Recurrent Unit,GRU)適合對文本建模、獲取文本全局的結構信息[5]。注意力機制(Attention)可以為經營范圍中重要的詞賦予更高的權重,進而更好提取關鍵信息[6]。基于此,提出一種基于混合神經網絡模型的企業行業分類方法,融合RoBERTa 預訓練語言模型、GRU 網絡和注意力機制構建候選集生成網絡和外部知識嵌入網絡。
1 相關研究
為解決企業行業分類問題,通常會借助自然語言處理和機器學習的手段對經營范圍進行數據挖掘,從而自動完成行業分類。主流分類方法分有兩種:基于機器學習的方法和基于深度學習的方法。基于機器學習的方法首先人工提取特征,然后將多個特征串聯起來組成一個高維度的特征向量,之后便可以使用傳統的機器學習的各種分類器,如樸素貝葉斯[7]、支持向量機、決策樹等完成行業分類。這種方法需要做大量的特征工程,特征的選取和分析方式復雜,需要耗費較多的成本,并且這些特征都是針對常規文本分類問題提出的,不存在對具體問題的依賴,這就會造成前端特征與后端任務的脫節,導致前端花費大量精力構思出來的特征可能根本與指定的任務不相關。另一種是基于深度學習的方法,如卷積神經網絡(Convolutional Neural Networks,CNN)[8]、循環神經網絡(Recurrent Neural Network,RNN)[9]、基于長短期記憶的循環神經網絡(Long Short Term Memory,LSTM)[10]完成自動的特征提取和分類任務。相比行業門類,屬于不同行業小類的企業在經營范圍描述上存在很多相似性,利用常規方法很難發現這種微小的差異,進而較難作出正確的判斷。
使用深度學習方法雖然免去了一些人工特征提取的工作,但是由于經營范圍的描述信息通常很分散,包含了多個行業的內容,單從經營范圍無法確定哪些信息對判斷行業類別是有效的。為克服上述行業分類方法的缺陷,提出一種基于混合神經網絡的行業分類模型,首先將企業經營范圍文本序列輸入RoBERTa 預訓練語言模型,并將輸出的特征向量作為輸入到下一層網絡的語義表征向量;通過引入企業外部知識,結合雙向門限循環神經網絡(BiGRU)和注意力機制的外部知識嵌入網絡,有效提高模型的理解層次,提升行業分類的準確性。同時,提出一種基于GRU 的候選集生成網絡,通過GRU 生成分類候選集用于增強算法的分類能力,在此基礎上引入跳層連接機制,以解決深度網絡訓練中的信息丟失和網絡退化問題。
2 模型結構
行業分類模型主要由三個部分組成,如圖1 所示。語義表征部分使用RoBERTa 模型作為基本模型,該模型相對BERT 模型進行了多項改進。為了使RoBERTa 模型適用于中文環境下的企業行業預測,使用RoBERTa-wwm-ext 作為文本特征提取模型,并將企業經營范圍文本序列輸入其中[11]。處理后的文本表征向量被送入到候選集生成網絡,產生包含類別候選集的特征向量,外部知識作為補充信息,在使用BiGRU 向量化后與特征向量進行拼接,得到融合的特征向量,融合后的特征向量最終輸入到分類器進行類別預測,以實現行業類別預測。
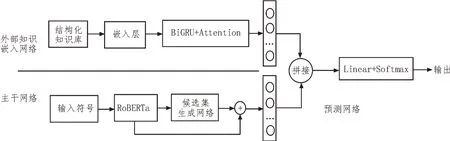
圖1 模型結構
2.1 候選集生成網絡
候選集是一種對企業行業類別可能判斷的候選選項的集合,模型使用GRU 網絡作為候選集的生成網絡。GRU 使用門機制跟蹤序列狀態,重置門和更新門共同控制當前狀態要更新的信息量。基于GRU的候選集生成網絡結構如圖2 所示。
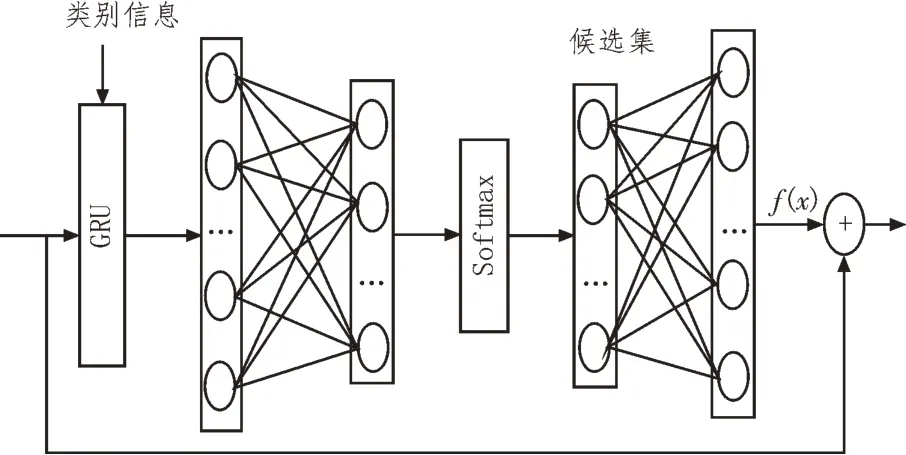
圖2 候選集生成網絡結構
經過預訓練模型編碼后的語義向量結果xt構成集 合X={xt|t=1,2,…,n},將X與類別語義信息Cs={|i=1,2,…,m}作為模塊的輸入。更新門zt、重置門rt均由輸入向量xt與上一步隱藏狀態ht-1線性組合并經過sigmod 激活函數非線性化處理后得到。候選狀態的計算方式與傳統的RNN 類似,由重置門rt與隱藏狀態ht-1的哈達瑪積和輸入向量xt線性組合后,經過tanh 激活函數非線性化處理得到。新的隱藏狀態ht由更新門zt、隱藏狀態ht-1和候選狀態共同計算得到:
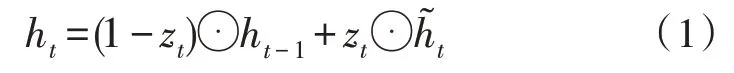
將不同時間節點隱藏狀態ht構成集合H={ht|t=1,2,…,n,n+1,…,n+m},經由全連接層以及softmax 函數后得到候選集C={ci|i=1,2,…,m}。對候選集使用全連接層進行維度轉換,輸出與預訓練語言模型同維度的結果VC={|t=1,2,…,n}。為了防止訓練過程中網絡層數加深后可能存在的信息丟失和網絡退化問題,在候選集生成網絡中添加跳層連接[12],其主要過程是通過將網絡的輸入部分與輸出結果使用門控機制進行相加,得到最終網絡輸出結果Vout:

其中,f(X)是主干網絡,它是由多個網絡層組成的非線性變換得到的。
2.2 外部知識嵌入網絡
完成候選集生成后,構建了基于企業描述信息的Query-Tag 預測模型。除了經營范圍描述外,企業也包含大量其他存在相關性的標簽,單純利用某一類標簽可能存在難以理解某些模糊描述的情況,理解層次偏低。通過引入企業外部知識,可以有效提高模型的理解層次,提升行業分類準確性。因此,將企業其他信息作為外部知識信息引入分類模型,以鍵值對形式構建出結構化外部知識。輸入到模型中的結構化知識庫表示為一個鍵值對列表:
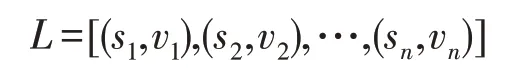
其中,si表示企業信息對應類型(例如企業名稱、注冊資本),vi表示對應企業信息的具體內容(例如安徽某有限公司、100 萬元人民幣)。
在單向神經網絡結構中,狀態是從前向后輸出的,難以抓取整個知識庫中的上下文信息。然而在文本分類中,當前時刻的輸出可能與前一時刻的狀態和后一時刻的狀態都存在相關性。因此,使用BiGRU 網絡作為信息提取網絡,為輸出層提供輸入序列中每一個點的完整上下文信息。注意力機制能選擇性地對這些外部信息進行篩選并聚焦到有效信息上,因此在分類模型中還引入注意力機制來增強補充外部知識后的預測效果。外部知識嵌入網絡主要包括結構化知識庫(Structured KB)、BiGRU 網絡和Attention 機制,外部知識嵌入網絡如圖3 所示。

圖3 外部知識嵌入網絡
將L經過Embedding 得到向量L=[I1,I2,…,In]。向量L中的元素Ii分別輸入前向GRU 和反向GRU,得到前向隱藏狀態和反向隱藏狀態,拼接前向和反向隱藏狀態得到BiGRU 的隱藏狀態對BiGRU 的隱藏狀態hi應用注意力機制,并引入知識庫上下文向量u來衡量知識的重要性,從而得到有助于增強行業分類的外部知識向量V。最后,通過全連接網絡將外部知識向量V的維度轉換為與主干網絡相同維度的結果向量。
2.3 預測網絡
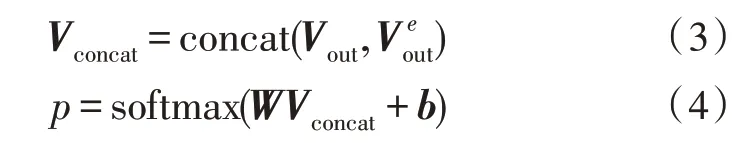
使用正確類別的負對數似然作為訓練的損失函數:
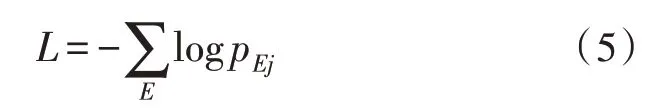
其中,j是企業E的分類類別。
3 實驗結果分析
3.1 實驗環境
使用基于CUDA 9.0 的深度學習框架PyTorch 1.1.0 搭建網絡模型,實驗操作系統為Ubuntu 18.04,內存32 GB,Intel(R)Core(TM)i7-7700CPU@3.60GHz,GeForce GTX 1080 Ti GPU。
3.2 數據集
為評估行業分類模型的有效性,構建了由企業數據組成的數據集。數據集中的信息包括企業名稱、注冊資本、成立時間、經營范圍、行業類別、行政許可、產品信息等。數據集中有60 000 條數據,隨機選取了其中50 000 條數據作為訓練集,5 000 條數據作為驗證集,5 000 條數據作為測試集。
3.3 實驗設置
在超參數設置上,RoBERTa 模型的嵌入維度為768維,多頭注意力機制的設置為12 個注意力頭,隱藏層維度同樣設置為768維,隱藏層層數設置為12,詞匯表大小為21 128字,GRU 的隱藏層維度設置為128。在訓練設置上,批處理大小設置為16,批處理以token 為單位,每個輸入文本的token 個數設置為200。同時,模型使用學習率為1e-5 的Adam 優化器。訓練輪數設置為10 輪(epoch=10),并且使用學習率優化策略,每兩個epoch 學習率下降為原來的80%。為了更好地說明模型的分類性能,采用準確率(acc)和F1 值作為評價指標。
3.4 基線模型對比
在數據集上與多種基線分類方法進行了對比,對比結果如表1 所示。
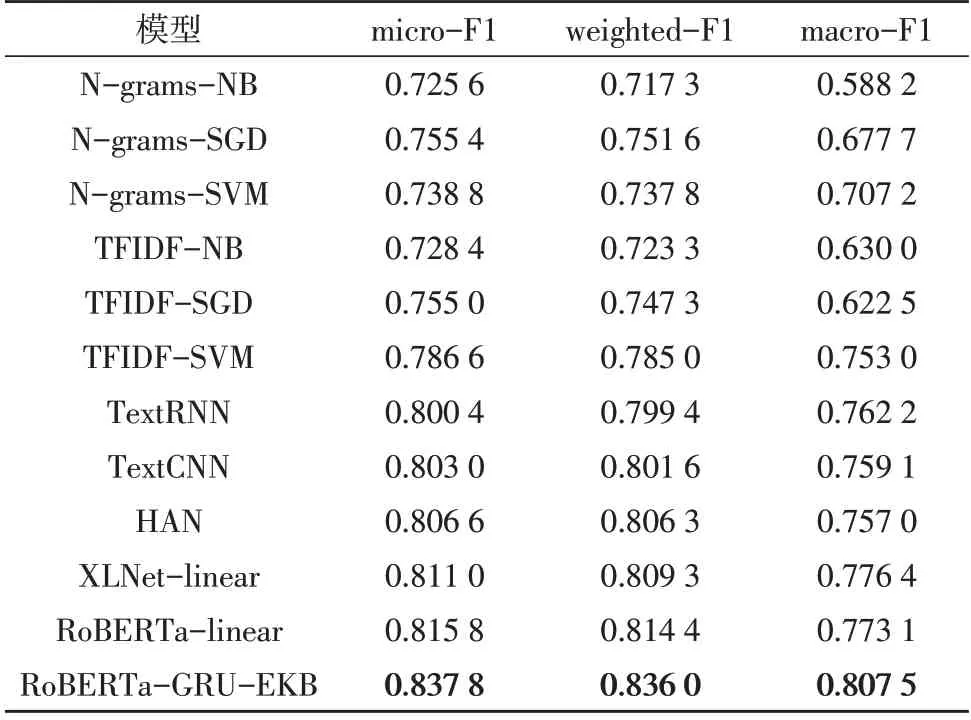
表1 對比實驗結果
1)機器學習方法
使用TF-IDF 和N-grams 作為特征提取方法,分別以機器學習方法MultinomialNB、SGD 和SVM 作為分類器對特征進行分類。
2)深度學習方法
TextCNN[13]:使用卷積核窗口大小分別為2、3、4的三個卷積層和相應的池化層提取特征并進行拼接,以此來獲得更豐富、不同粒度的特征信息。
TextRNN[14]:使用經過詞嵌入之后的詞向量作為輸入,經過RNN 網絡和池化層進行分類。
HAN[15]:使用基于單詞層面注意力機制的BiGRU模型和基于句子層面注意力機制的BiGRU 模型提取文本多層面的特征進行文本分類。
XLNet-linear:采用預訓練語言模型XLNet模型[16]提取特征,并使用linear 分類器進行行業分類。
RoBERTa-linear:采用預訓練語言模型RoBERTa模型提取特征,并使用linear 分類器進行行業分類。
可以看出,RoBERTa-GRU-EKB 模型在兩個數據集上均取得了比其他基線模型更好的分類效果。在RoBERTa 的基礎上增加候選集生成網絡和外部知識嵌入網絡,能夠有效提升行業分類性能。
3.5 消融實驗
為說明候選集生成網絡和外部知識嵌入網絡的有效性,定量地比較了是否使用候選集生成網絡和外部知識嵌入網絡的實驗結果。將未使用候選集生成網絡的結果命名為RoBERTa-EKB,將未使用外部知識嵌入網絡的結果命名為RoBERTa-GRU,對比結果如表2 所示。
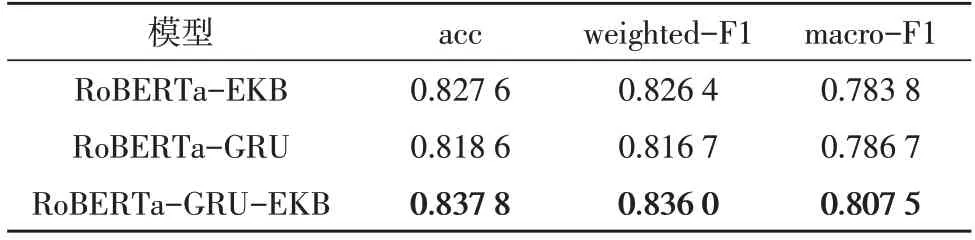
表2 消融實驗結果
由表2 可見,RoBERTa-GRU-EKB 模型在兩個數據集上的分類效果總是優于RoBERTa-EKB 模型和RoBERTa-GRU 模型。圖4 展示了候選集生成網絡消融實驗性能對比。圖4(a)中曲線②幾乎總是在曲線①之下,曲線④幾乎總是在曲線③之下;圖4(b)中曲線②幾乎總是在曲線①上方,曲線④幾乎總是在曲線③上方,這表明模型加入了候選集生成網絡后,其損失值和準確率均優于未加入候選集生成網絡的模型。因此,基于GRU 的候選集生成網絡可以有效提升分類準確率。
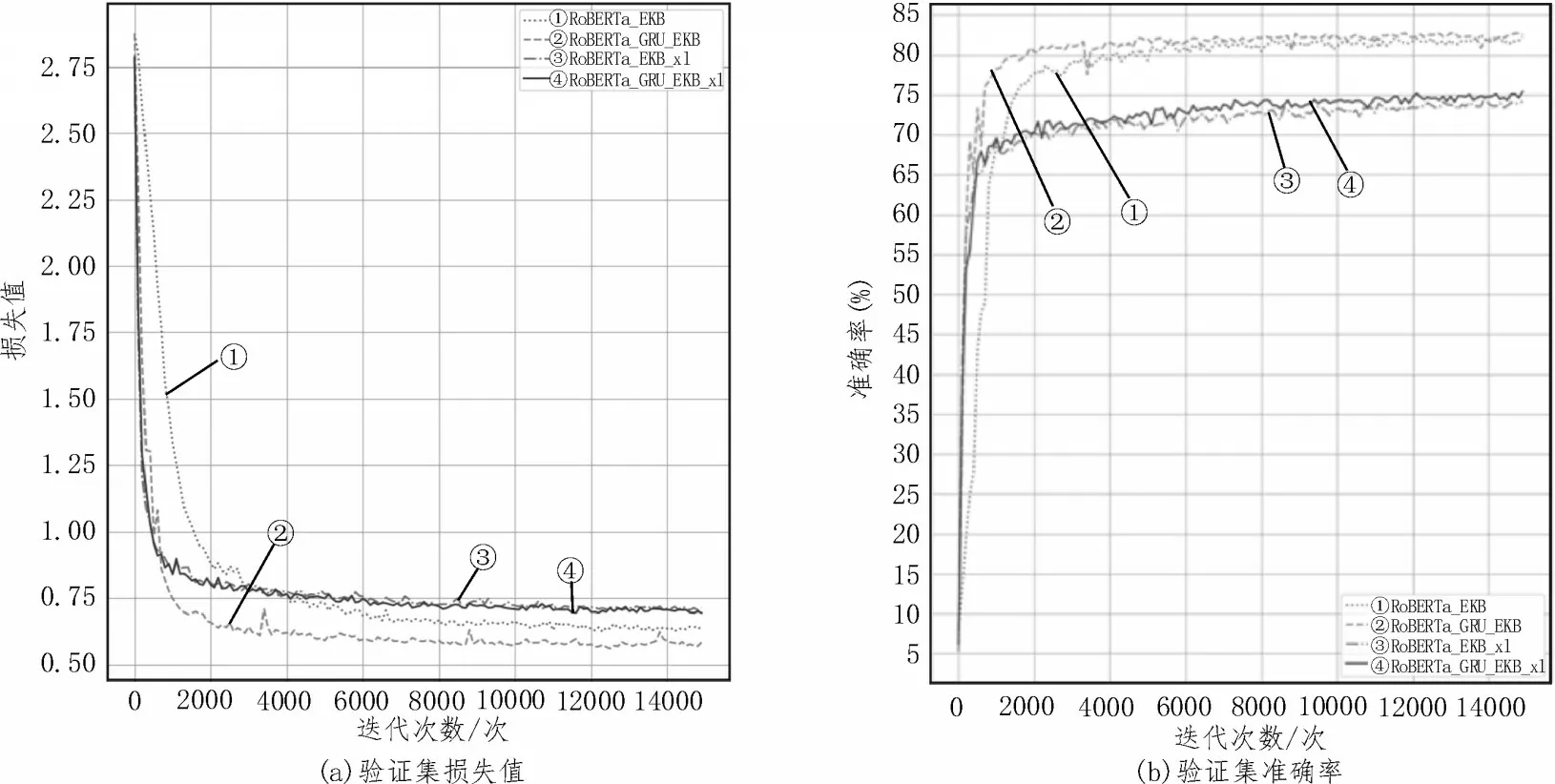
圖4 候選集生成網絡消融實驗性能對比
圖5 展示了候選集生成網絡消融實驗性能對比。圖5(a)中曲線②幾乎總是在曲線①之下,曲線④總是在曲線③之下;圖5(b)中曲線②幾乎總是在曲線①上方,曲線④總是在曲線③上方,這表明模型加入了外部知識嵌入網絡后,其損失值和準確率均優于未加入外部知識嵌入網絡的模型。因此,外部知識嵌入網絡可以有效提升分類效果。
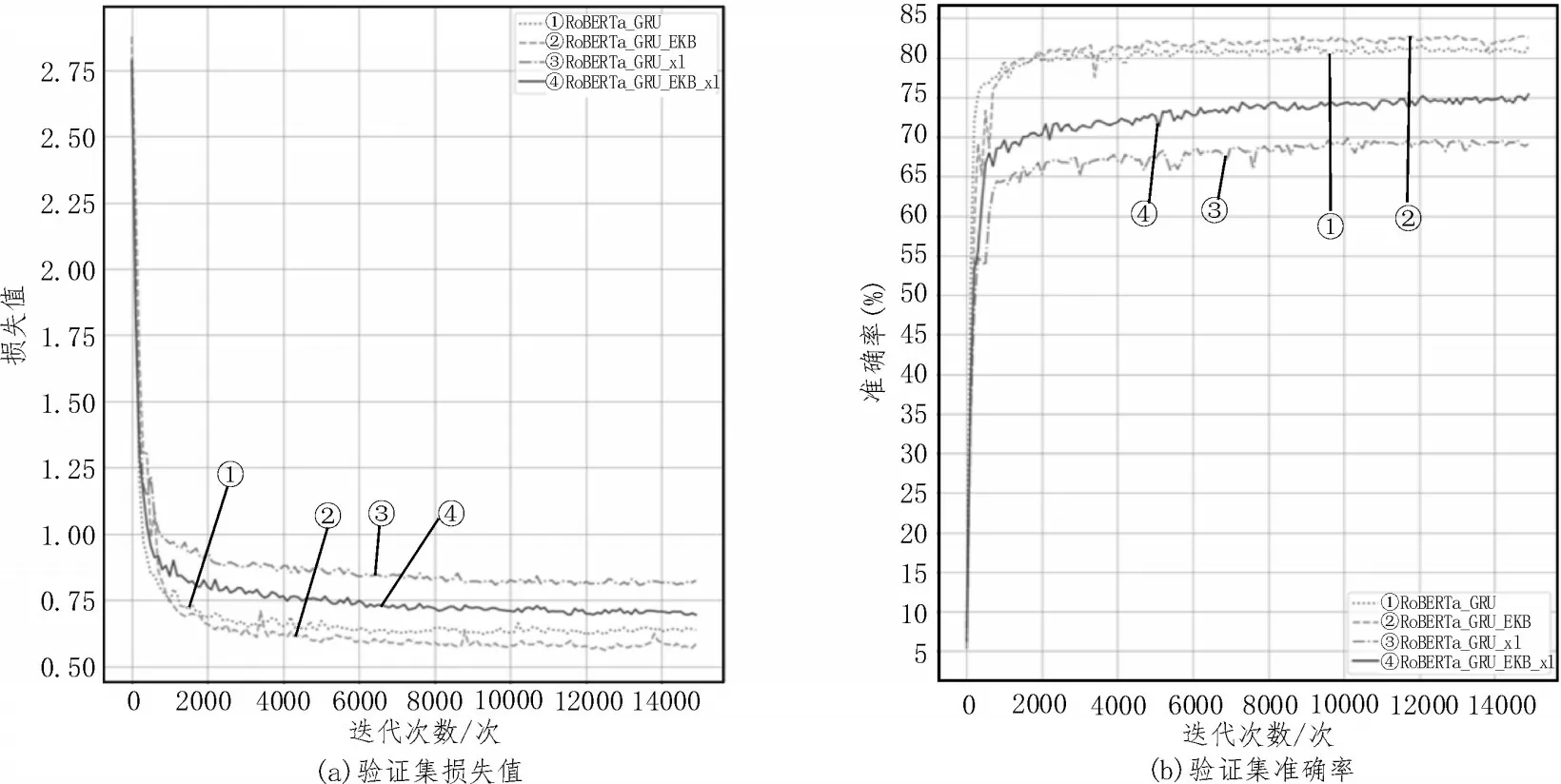
圖5 外部知識嵌入網絡消融實驗性能對比
3.6 混淆矩陣和類別準確率
為更加直觀有效地展示行業分類效果,在實驗部分給出了RoBERTa-GRU-EKB 模型測試結果的混淆矩陣熱力圖,如圖6 所示,圖6 中給出了部分類別預測準確率各模型對比直方圖(其中A、B、C 等代表某個特定行業類別),圖中方格顏色深淺表示預測率大小,從圖6 可知對角線上的方格顏色較深,這表明RoBERTa-GRU-EKB 模型在每個類別上的分類性能均較好。

圖6 混淆矩陣熱力圖
4 結論
該文提出了一種用于企業行業分類的混合神經網絡模型,該模型采用RoBERTa 預訓練語言模型提取企業經營范圍的文本特征,使用候選集生成網絡與跳層連接模塊增強分類性能。此外,還利用BiGRU 與注意力機制實現了結構化的知識庫嵌入,通過引入企業外部知識金額提升行業類別預測準確性。實驗結果表明,該文提出的行業分類模型相較于其他幾種基線模型都取得了最好的分類效果。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
