基于多頭自注意力機(jī)制和卷積神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)損傷識別研究
2023-01-03 04:36:48張健飛黃朝東王子凡
振動與沖擊 2022年24期
關(guān)鍵詞:結(jié)構(gòu)模型
張健飛, 黃朝東, 王子凡
(河海大學(xué) 力學(xué)與材料學(xué)院,南京 210098)
為了保證工程結(jié)構(gòu)的安全和正常使用,需要及時發(fā)現(xiàn)結(jié)構(gòu)損傷并進(jìn)行維修處理。基于振動的結(jié)構(gòu)損傷識別方法利用結(jié)構(gòu)的振動測試信號進(jìn)行結(jié)構(gòu)整體損傷狀況檢測,相較于傳統(tǒng)的無損檢測方法具有很大的優(yōu)越性[1],但在實際應(yīng)用過程中,會不同程度地遇到模型依賴性強(qiáng)、系統(tǒng)容錯性差、易受環(huán)境影響等問題。人工神經(jīng)網(wǎng)絡(luò)由大量相互連接的簡單神經(jīng)處理單元組成,可以不依賴于模型,具有較強(qiáng)的容錯性和魯棒性以及學(xué)習(xí)聯(lián)想能力等特征,因而在結(jié)構(gòu)損傷識別領(lǐng)域受到了廣泛的關(guān)注。人工神經(jīng)網(wǎng)絡(luò)用于結(jié)構(gòu)損傷識別的基本原理就是通過建立特征參數(shù)與結(jié)構(gòu)損傷狀態(tài)之間的輸入、輸出映射關(guān)系來實現(xiàn)損傷識別。目前已經(jīng)構(gòu)建了許多結(jié)構(gòu)動力特征作為神經(jīng)網(wǎng)絡(luò)的輸入?yún)?shù),如:固有頻率[2]、振型[3]和模態(tài)曲率[4]等,然而這些人為設(shè)計的特征參數(shù)并不一定是最優(yōu)的,難以在不同類型的損傷識別中都取得最優(yōu)效果[5]。
以卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural networks, CNN)為代表的深度學(xué)習(xí)網(wǎng)絡(luò)可以直接從原始輸入數(shù)據(jù)中挖掘抽象的內(nèi)在特征,避免了人為主觀因素的影響,具有良好的泛化能力。CNN是一類包含卷積計算的深度前饋神經(jīng)網(wǎng)絡(luò),其所具有的局部連接、權(quán)值共享及池化操作等特性可以有效地降低網(wǎng)絡(luò)的復(fù)雜度,減少訓(xùn)練參數(shù)的數(shù)目,從而使模型具有強(qiáng)魯棒性和容錯能力,已經(jīng)在計算機(jī)視覺、語音識別等領(lǐng)域得到了廣泛應(yīng)用[6]。在結(jié)構(gòu)損傷識別領(lǐng)域,近年來CNN也得到了較多的研究。羅雨舟等[7]通過構(gòu)建CNN模型對有限元數(shù)值模擬生成的結(jié)構(gòu)多點加速度信號進(jìn)行特征提取,實現(xiàn)損傷診斷,并研究了結(jié)構(gòu)在不同激勵類型作用下和不同噪聲強(qiáng)度下的損傷診斷精度。李雪松等[8]以IASC-ASCE SHM Benchmark結(jié)構(gòu)的數(shù)值模擬數(shù)據(jù)為研究對象,用CNN直接從加速度信號中自動提取特征,并提出混合噪聲訓(xùn)練模式,加強(qiáng)特征抗噪能力,取得了良好的識別效果。李書進(jìn)等[9]以多層框架結(jié)構(gòu)節(jié)點損傷位置的識別問題為研究對象,構(gòu)建了基于原始信號和傅里葉頻域信息的一維CNN模型和基于小波變換數(shù)據(jù)的二維CNN模型。Khodabandehlou等[10]以一座鋼筋混凝土公路橋縮尺模型振動臺試驗測得的加速度信號作為輸入數(shù)據(jù),采用二維CNN對結(jié)構(gòu)損傷進(jìn)行識別,取得了很好的識別效果,并檢驗了網(wǎng)絡(luò)對微小損傷的魯棒性和敏感性。Lin等[11]采用CNN從簡支梁有限元模擬生成的加速度數(shù)據(jù)中提取損傷特征,在有噪聲情況和多損傷情況下取得了很高的損傷識別精度,同時通過隱層可視化對所提取的特征進(jìn)行了物理解釋。Liu等[12]將傳遞函數(shù)和一維CNN相結(jié)合對結(jié)構(gòu)損傷識別方法進(jìn)行了研究,并以ASCE Benchmark結(jié)構(gòu)動力響應(yīng)的傳遞函數(shù)作為CNN的輸入數(shù)據(jù),對方法的有效性進(jìn)行了驗證,通過與時間序列和FFT (fast Fourier transform)數(shù)據(jù)相比較,顯示了傳遞函數(shù)數(shù)據(jù)中獲取的特征具有更高的損傷敏感性。楊建喜等[13]提出一種聯(lián)合CNN和長短期記憶網(wǎng)絡(luò)(long-short term memory, LSTM)的橋梁結(jié)構(gòu)損傷識別方法,以結(jié)構(gòu)振動加速度響應(yīng)為輸入,通過 CNN 模型提取多時間窗口內(nèi)傳感器拓?fù)湎嚓P(guān)性特征,通過LSTM 模型進(jìn)一步提取時間維度特征,并以某連續(xù)剛構(gòu)橋縮尺模型的試驗數(shù)據(jù)對方法進(jìn)行了檢驗,取得了良好的效果。Yang等[14]將結(jié)構(gòu)振動加速度信號作為多變量時間序列,并行輸入CNN和雙向門控循環(huán)單元提取數(shù)據(jù)特征,然后將這兩種網(wǎng)絡(luò)獲得的特征進(jìn)行組合后用于結(jié)構(gòu)損傷識別,并通過數(shù)值試驗和連續(xù)剛構(gòu)橋縮尺模型試驗驗證了方法相較于CNN和LSTM等方法的優(yōu)越性。
注意力機(jī)制本質(zhì)上和人類視覺機(jī)制類似,其核心目標(biāo)是從眾多信息中選擇出對當(dāng)前任務(wù)目標(biāo)更關(guān)鍵的信息,使得模型在訓(xùn)練過程中關(guān)注重點特征,避免非敏感特征的影響。自注意力機(jī)制是注意力機(jī)制的一種變體,用于捕捉數(shù)據(jù)或特征自身內(nèi)部的相關(guān)性。多頭自注意力機(jī)制最初被用于機(jī)器翻譯,它通過對多次計算得到的自注意力特征的組合,實現(xiàn)不同位置處的數(shù)據(jù)在不同子空間中的表征,從而使得模型可以在多個不同表征子空間中學(xué)習(xí)到相關(guān)的信息[15]。
本文以結(jié)構(gòu)振動加速度信號作為輸入數(shù)據(jù),聯(lián)合多頭自注意力機(jī)制和CNN,提出了一種基于多頭自注意力的CNN模型(multi-head self-attention based CNN,CNN-MA),通過CNN提取加速度信號中的局部特征,通過引入多頭自注意力機(jī)制,在多個不同表征子空間中抽取出信號中重要的全局信息,提高結(jié)構(gòu)損傷識別的效果。
1 基于多頭自注意力的CNN模型
本文構(gòu)建的基于多頭自注意力的CNN模型依次由輸入層、若干個卷積和池化層、多頭自注意力層、全局池化層和Softmax分類層堆疊組成,如圖1所示。模型中輸入層輸入結(jié)構(gòu)受到動力作用后各個測點上產(chǎn)生的加速度信號;卷積層和池化層提取輸入加速度信號中的短期局部特征并實現(xiàn)降維;多頭自注意力層通過關(guān)注池化層輸出序列在不同位置、不同表征子空間中的關(guān)鍵信息,學(xué)習(xí)長期全局特征;全局池化層對序列各個位置的信息進(jìn)行匯總并壓縮;最后將全局池化層的輸出經(jīng)過全連接層后再通過Softmax進(jìn)行分類,類別數(shù)對應(yīng)損傷模式的個數(shù),每個神經(jīng)元輸出對應(yīng)不同損傷模式的發(fā)生概率,最大發(fā)生概率對應(yīng)的損傷模式即為預(yù)測的損傷模式。為了分析CNN-MA的性能,本文與CNN、CNN-LSTM和CNN-BiLSTM(bidirectional LSTM)等模型進(jìn)行了比較,各模型結(jié)構(gòu)見圖1。
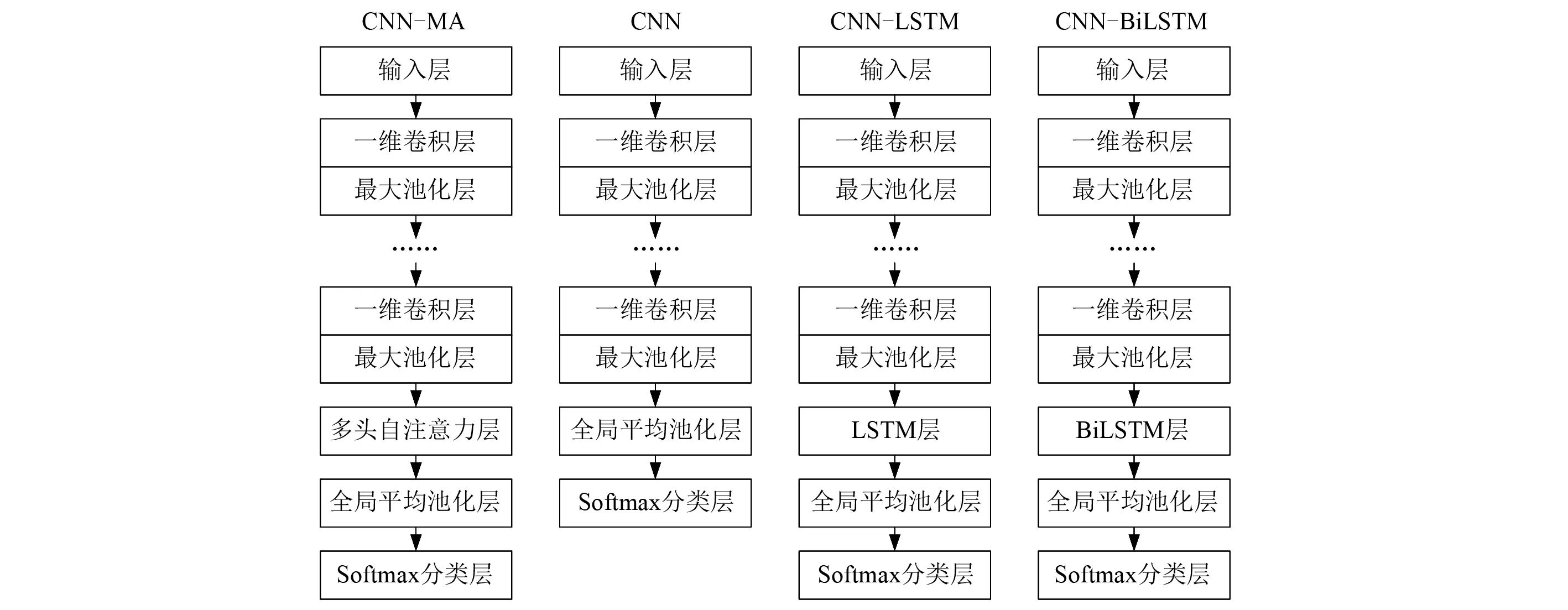
圖1 模型結(jié)構(gòu)Fig.1 Structure of the models
1.1 輸入層
本文直接以結(jié)構(gòu)在外界動力荷載作用下的測點加速度信號作為輸入數(shù)據(jù),由于是多測點問題,因此輸入數(shù)據(jù)可以看作向量時間序列fi(i=1,2,…,N)。其中fi=(fi,1,fi,2,…,fi,L)為L個測點在時刻i的加速度值組成的向量,序列長度N=測試時長×采樣頻率。在輸入模型之前,輸入的加速度信號需要進(jìn)行樣本化和標(biāo)準(zhǔn)化處理。樣本化就是將測點加速度信號序列分割成長度為T的若干段子序列si(i=1,2,…,T),作為模型的訓(xùn)練和測試樣本,T的取值一般至少使得樣本包含一個結(jié)構(gòu)特征自振周期的加速度采樣值。生成樣本后,本文對樣本進(jìn)行Z-Score標(biāo)準(zhǔn)化,其計算如式(1)所示。
(1)
式中:μ為時間序列si(i=1,2,…,T)的均值;σ為標(biāo)準(zhǔn)方差。
1.2 卷積層和池化層
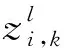
(2)

(3)
典型的激活函數(shù)有sigmoid、tanh和ReLU等,本文采用ReLU激活函數(shù)。
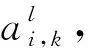
(4)
式中,Ri為第i個位置處數(shù)值周邊的鄰近區(qū)域,常見的池化操作有取平均值和取最大值,本文采用最大池化。
通過卷積和池化計算得到的CNN輸出序列數(shù)據(jù)為xi(i=1,2,…,M),其中xi=(xi,1,xi,2,…,xi,P),P為最后一層卷積層的特征圖個數(shù),輸出序列的長度M由卷積核尺寸、池化尺寸和步長等參數(shù)具體確定。
1.3 LSTM層
LSTM是循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural networks, RNN)的一種變體,主要用于處理序列數(shù)據(jù),能夠保持?jǐn)?shù)據(jù)中的時序依賴關(guān)系。它通過引入了門控單元,解決了普通RNN長程依賴、梯度消失或梯度爆炸等問題,已經(jīng)在自然語言處理等領(lǐng)域得到成功應(yīng)用。LSTM使用記憶細(xì)胞來代替一般網(wǎng)絡(luò)中的隱藏層細(xì)胞,記憶細(xì)胞的輸入和輸出都由一些門控單元來控制,這些門控單元控制流向隱藏層單元的信息。其中:遺忘門決定從上一個細(xì)胞狀態(tài)中遺忘什么信息,輸入門將新的信息選擇性的記錄至細(xì)胞狀態(tài)中,輸出門將信息傳遞出去。本文采用的LSTM網(wǎng)絡(luò)細(xì)胞結(jié)構(gòu),如圖2所示。
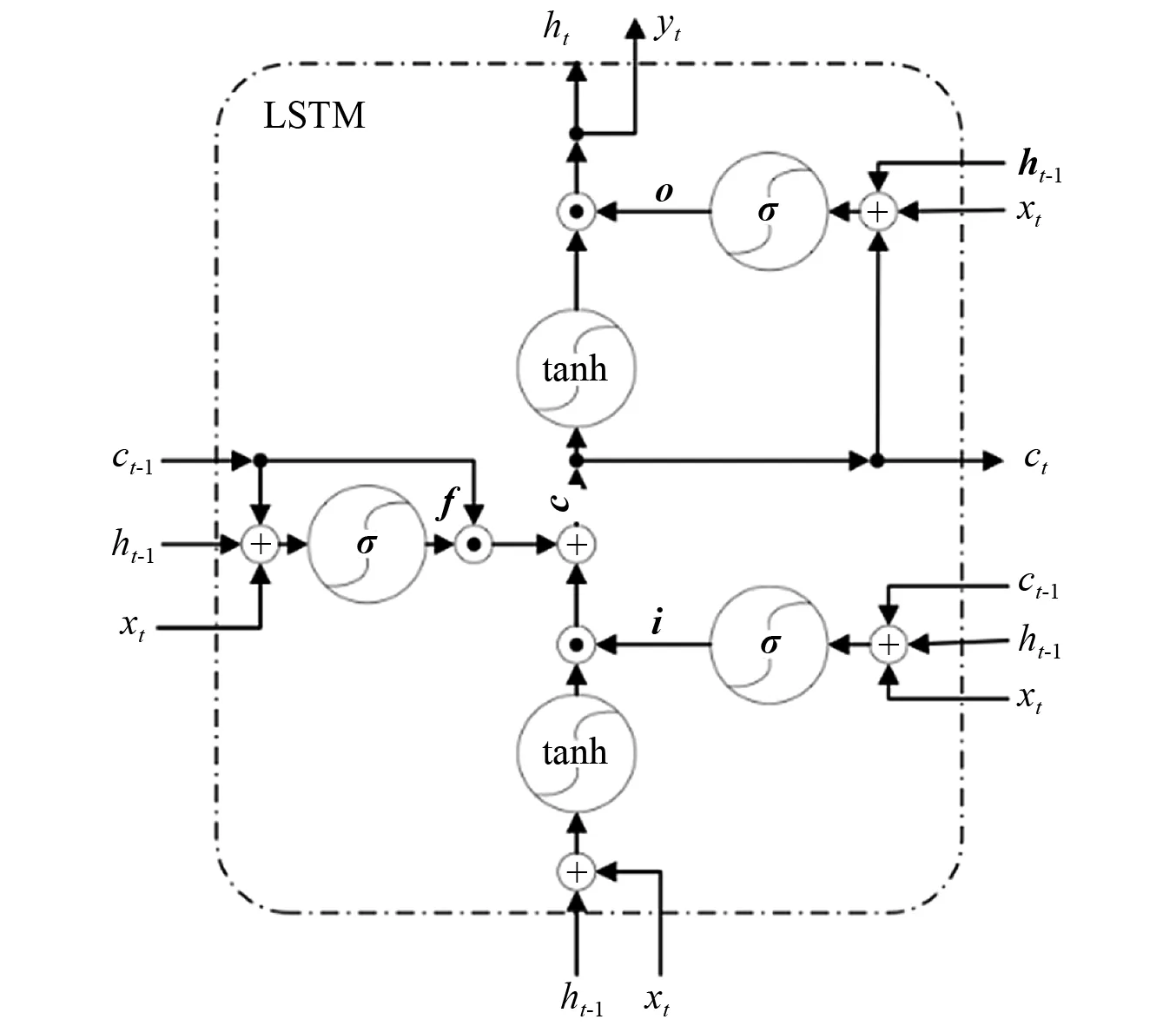
圖2 LSTM細(xì)胞結(jié)構(gòu)Fig.2 Structure of LSTM cell
圖2中的i,f,c,o,h分別為輸入門、遺忘門、細(xì)胞狀態(tài)、輸出門以及隱藏層的輸出向量,其計算方法如式(5)~式(9)所示。
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
(5)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
(6)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
(7)
ot=σ(Wxoxt+Whoht-1+Wcoct+bo)
(8)
ht=ottanh(ct)
(9)
式中:下標(biāo)x,i,f,c,o,h分別為輸入層、輸入門、遺忘門、細(xì)胞狀態(tài)、輸出門以及隱藏層;W和b分別為對應(yīng)的權(quán)重矩陣以及偏置;t為時刻。
通過LSTM層計算得到的輸出序列數(shù)據(jù)為oi(i=1,2,…,M),其中oi=(oi,1,oi,2,…,oi,D),D為輸出門維度。
在有些問題中,當(dāng)前時刻的輸出不僅和之前的狀態(tài)有關(guān),還可能和未來的狀態(tài)有關(guān)系。此時可以采用雙向LSTM(bidirectional LSTM, BiLSTM),將輸入序列按照正序和反序分別輸入LSTM,然后將正向和反向LSTM的輸出相結(jié)合作為最終的輸出,常用的結(jié)合方式有求和、求積、平均和拼接等,本文采用拼接的結(jié)合方式,此時的輸出向量維度為2D。
1.4 多頭自注意力層
注意力可以描述為查詢向量和一系列鍵-值向量對與輸出向量之間的映射,其中:輸出向量通過值向量的加權(quán)求和得到,每個值向量的加權(quán)系數(shù)通過計算查詢向量與對應(yīng)的鍵向量之間的匹配度而得到,本文中的加權(quán)系數(shù)通過計算查詢向量和鍵向量之間的尺度化點積得到。當(dāng)查詢向量、鍵向量和值向量屬于相同的序列時稱為自注意力。對于一系列查詢向量的注意力計算,通常為了提高計算效率將查詢向量、鍵向量和值向量組合成查詢矩陣、鍵矩陣和值矩陣進(jìn)行運算,如式(10)和圖3所示。多頭自注意力層首先采用不同的線性投影矩陣將維度為M×d的輸入矩陣映射為h組矩陣,每組矩陣包含3個不同的矩陣:查詢矩陣Q、鍵矩陣K和值矩陣V,矩陣Q和K的維度為M×dk,矩陣V的維度為M×dv。然后對這h組矩陣分別按照式(10)進(jìn)行自注意力運算,最后將自注意力運算得到的h個輸出矩陣拼接后投影為一個維度為M×d的輸出矩陣R,如式(11)和圖4所示。
(10)
R=Multihead(Q,K,V)=
Concat(head1,head2,…,headh)Whr
(11)
式中,線性投影矩陣Whr∈hdv×d。
多頭自注意力層輸出數(shù)據(jù)為ri(i=1,2,…,M),其中向量ri=(ri,1,ri,2,…,ri,d)。

圖3 尺度化點積注意力Fig.3 Scaled dot-product attention
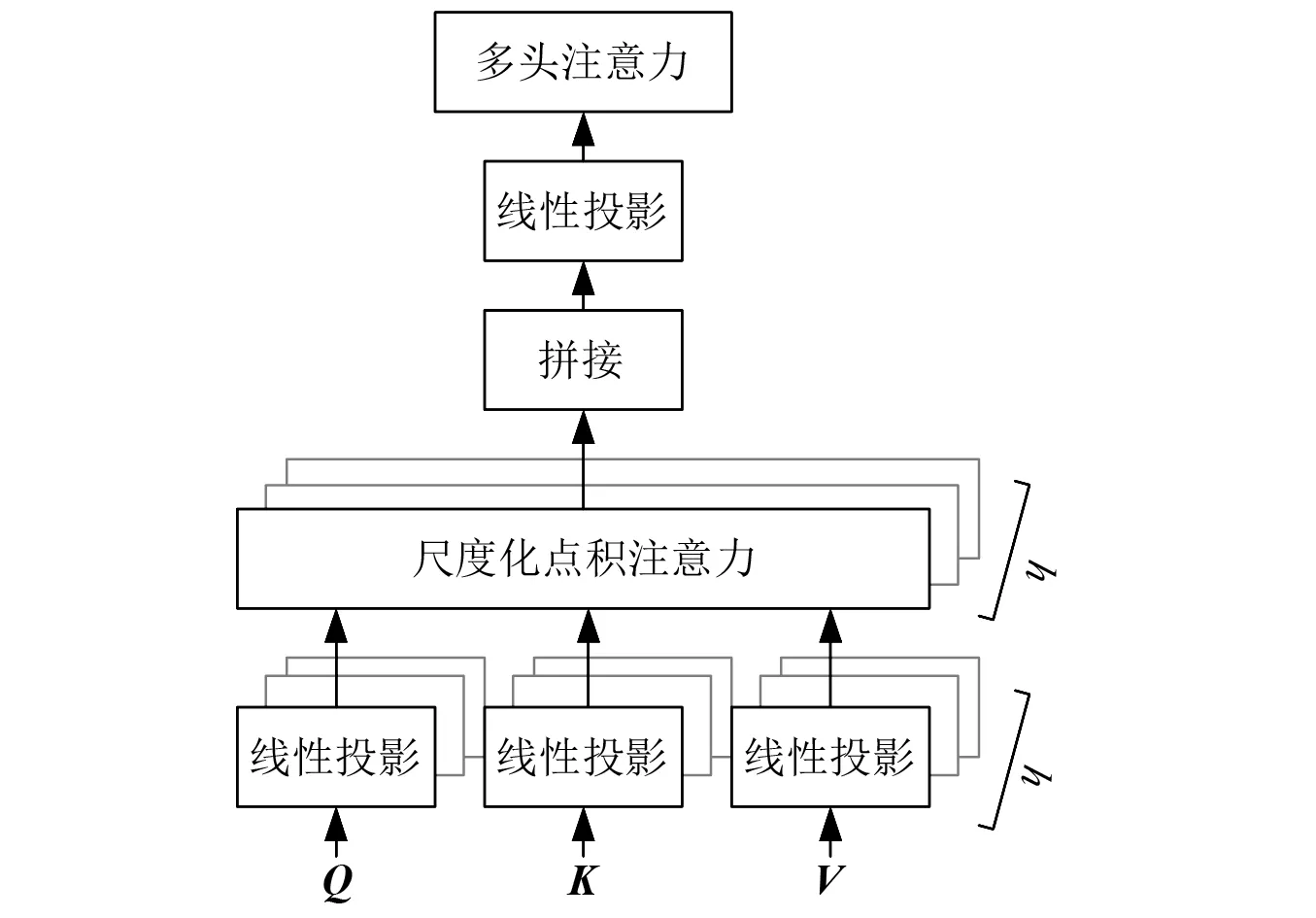
圖4 多頭注意力Fig.4 Multi-head Attention
1.5 全局池化層
全局池化一般分為全局最大池化和全局平均池化,全局池化可以起到減少參數(shù)、防止過擬合的作用。本文采用全局平均池化,即計算向量時間序列中向量各個元素在時間域上的平均值,如式(12)所示,得到輸出向量g=(g1,g2,…,gD)。
(12)
1.6 Softmax分類層
最后將全局池化層的輸出向量輸入全連接層后再通過Softmax進(jìn)行分類,類別的數(shù)量等于損傷模式的個數(shù)nd。Softmax分類層將輸入數(shù)據(jù)轉(zhuǎn)化為一個概率分布,其計算如式(14)所示,然后根據(jù)概率最大的原則進(jìn)行模式識別。
g′=Wgg′g
(13)
(14)
式中,全連接層的權(quán)重系數(shù)矩陣Wgg′∈nd×D。
1.7 基于CNN-MA的結(jié)構(gòu)損傷識別
本文提出的基于CNN-MA的結(jié)構(gòu)損傷識別方法首先采集結(jié)構(gòu)上各個測點的振動加速度信號;然后將這些加速度信號進(jìn)行預(yù)處理,即對其進(jìn)行標(biāo)準(zhǔn)化后分割成一系列具有一定長度的子信號;再將這些子信號及其對應(yīng)的損傷狀態(tài)按照一定的比例劃分成訓(xùn)練集、驗證集和測試集;采用訓(xùn)練集進(jìn)行模型的訓(xùn)練,采用驗證集進(jìn)行模型的驗證,根據(jù)驗證結(jié)果進(jìn)行模型結(jié)構(gòu)和超參數(shù)的優(yōu)化;最后將測試集輸入訓(xùn)練好的模型進(jìn)行損傷識別,測試模型泛化性能。整個結(jié)構(gòu)損傷識別的流程如圖5所示。本文基于其他模型的結(jié)構(gòu)損傷識別流程與CNN-MA相同。

圖5 結(jié)構(gòu)損傷識別流程圖Fig.5 Flow chart of structural damage identification
由式(2)可知,CNN隱藏層中每一個神經(jīng)元只與相鄰層局部區(qū)域的神經(jīng)元相連,這個局部區(qū)域被稱為局部感受野,也就是某一個隱藏層中神經(jīng)元只學(xué)習(xí)了其局部感受野范圍內(nèi)的特征,而要學(xué)習(xí)整個序列的全部特征,需要堆疊多個隱藏層,從而使得CNN模型變得復(fù)雜,訓(xùn)練難度變大。將CNN與LSTM(BiLSTM)相結(jié)合的目的就是通過LSTM(BiLSTM)將當(dāng)前時刻之前(之后)的信息壓縮后傳遞給當(dāng)前時刻,從而能夠獲取全局特征,但是這種信息壓縮會一定程度上導(dǎo)致有用信息的丟失。而CNN-MA將卷積池化層輸出序列中每一個向量與序列中的全部向量進(jìn)行自注意力運算,從而使得每個向量中除了包含局部特征也包含全局特征。
2 試驗驗證
2.1 數(shù)值試驗
2.1.1 數(shù)據(jù)生成與預(yù)處理
為了測試CNN-MA模型的性能,本文首先建立了一個懸臂梁有限元模型進(jìn)行數(shù)值試驗,懸臂梁材質(zhì)為鋼材,長1 200 mm,方形截面尺寸為20 mm×20 mm,底部為固定端,頂部為自由端。在懸臂梁一側(cè)不同高程處設(shè)置深2 mm的水平裂縫(記為C1~C6)模擬不同位置的損傷,另一側(cè)設(shè)置7個測點(記為m1~m7)記錄懸臂梁水平向加速度,懸臂梁裂縫位置和測點位置如圖6所示。每種損傷模式為不同位置處的單個裂縫,如表1所示。
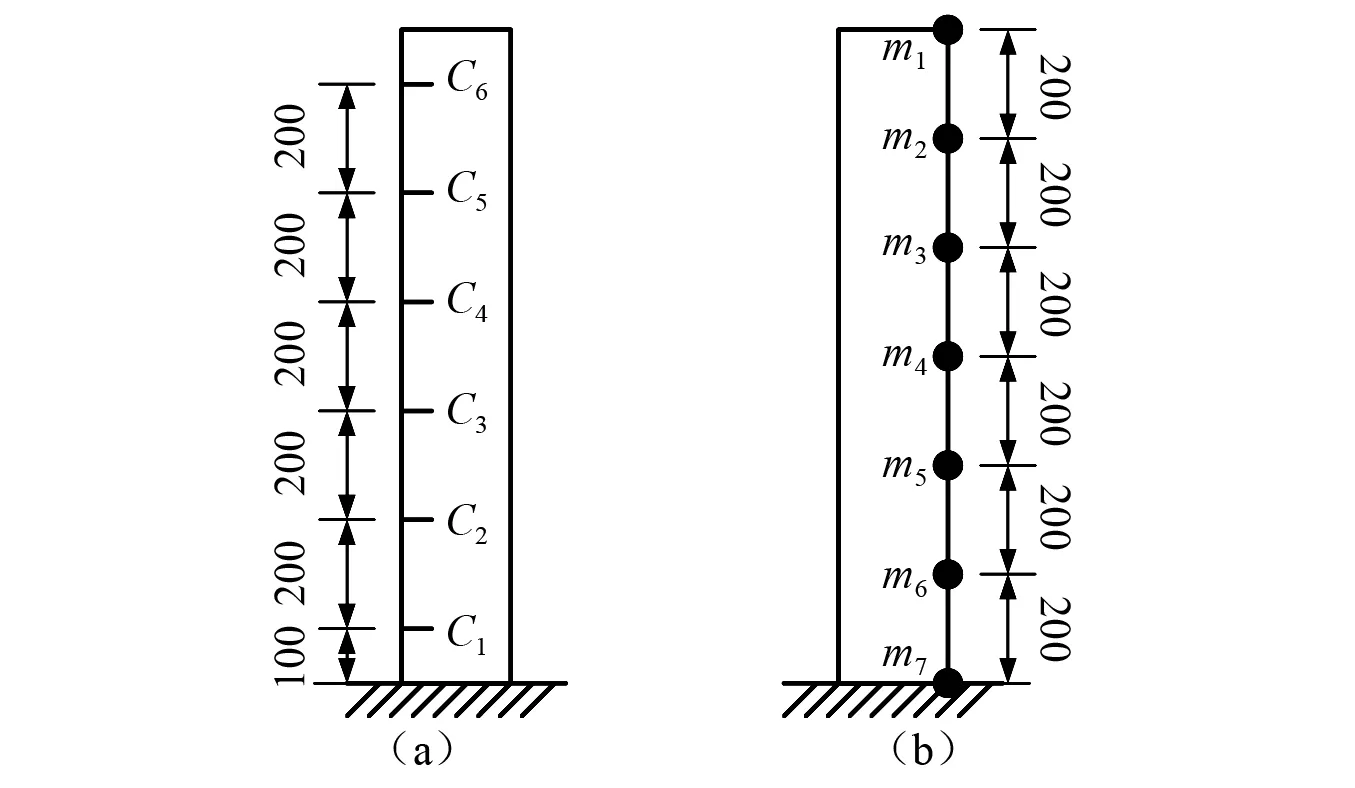
圖6 懸臂梁裂縫位置和測點圖(mm)Fig.6 Positions of the cracks and accelerometers on the cantilever beam (mm)
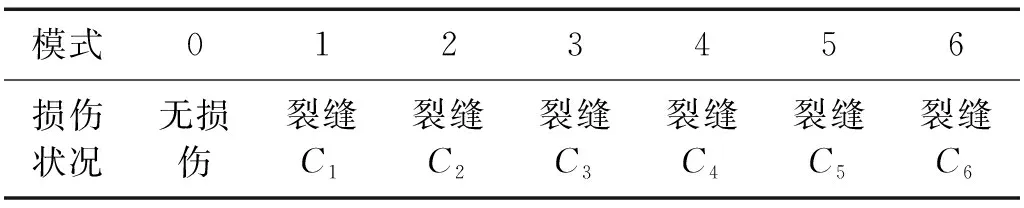
表1 數(shù)值試驗中懸臂梁的損傷模式Tab.1 Damage patterns of the cantilever beam in numerical test
通過在懸臂梁底部施加水平向白噪聲加速度模擬環(huán)境激勵,按照表2所示的損傷情況,生成7種不同損傷模式下7個測點上時長為30 s的加速度響應(yīng)信號,有限元計算時間步長取為0.000 1 s,采用Rayleigh阻尼,則每種損傷模式可得到一個長度為300 000、維度為7的加速度信號序列。然后從每個信號序列中隨機(jī)抽取1 000個長度為1 024、維度為7的子序列作為模型的輸入樣本序列,共得到7×1 000=7 000個樣本序列。
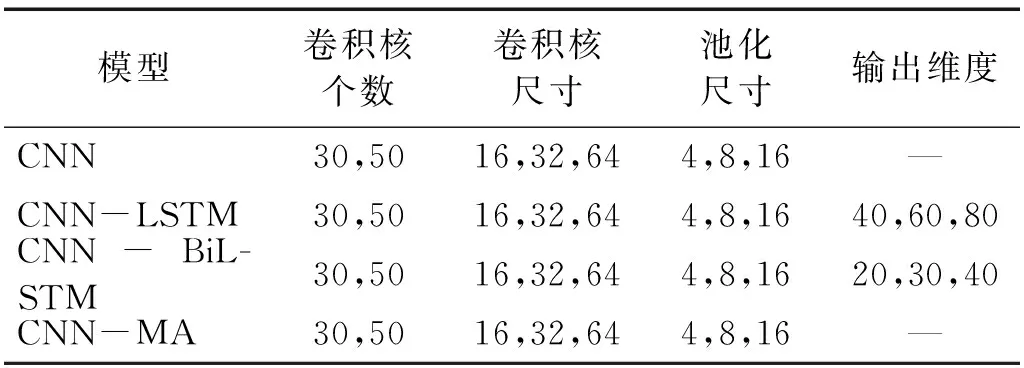
表2 各個模型超參數(shù)取值范圍Tab.2 Range of the hyper-parameters of the models
在實測信號中,噪聲總是存在的,這些噪聲一般可以假設(shè)為符合高斯分布的白噪聲[16]。本文在有限元計算得到的加速度信號中加入白噪聲數(shù)據(jù)來模擬實測信號,即
(15)
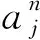
2.1.2 模型結(jié)構(gòu)和參數(shù)
神經(jīng)網(wǎng)絡(luò)模型的結(jié)構(gòu)和超參數(shù)對其性能具有很大的影響,為了獲取較優(yōu)的網(wǎng)絡(luò)結(jié)構(gòu)和超參數(shù),本文在beam-n00數(shù)據(jù)集上采用網(wǎng)格搜索的方法比較了各個模型在不同網(wǎng)絡(luò)結(jié)構(gòu)下多種超參數(shù)組合的性能,各模型的超參數(shù)取值范圍,見表2。模型超參數(shù)優(yōu)選時的性能指標(biāo)采用5-折交叉驗證確定,即將數(shù)據(jù)集平均分成5組,其中每一組子集數(shù)據(jù)分別作為驗證集,其余的4組子集數(shù)據(jù)作為訓(xùn)練集,以得到的5組驗證集上的損傷識別準(zhǔn)確率的平均值作為模型性能評價的指標(biāo)。
對于CNN模型,比較了包含2個卷積池化層的網(wǎng)絡(luò)結(jié)構(gòu)(2層結(jié)構(gòu))和包含3個卷積池化層的網(wǎng)絡(luò)結(jié)構(gòu)(3層結(jié)構(gòu))在卷積核數(shù)量、卷積核尺寸和池化尺寸3個超參數(shù)的不同組合下的損傷識別性能,每種結(jié)構(gòu)共計18種超參數(shù)組合,比較結(jié)果如表3所示。可以看出:在本例中不同的超參數(shù)組合對識別準(zhǔn)確率的影響較大,過大的卷積核尺寸會導(dǎo)致識別失敗,增加卷積池化層數(shù)量反而會降低識別準(zhǔn)確率;當(dāng)CNN模型采用2層結(jié)構(gòu),卷積核數(shù)、卷積尺寸和池化尺寸分別取30,32和4時損傷識別準(zhǔn)確率最高。

表3 CNN在不同結(jié)構(gòu)和超參數(shù)組合下的識別準(zhǔn)確率Tab.3 Accuracy of CNN with different structures and hyper-parameters 單位:%
對于CNN-LSTM和CNN-BiLSTM模型,比較了包含一個卷積池化層的網(wǎng)絡(luò)結(jié)構(gòu)(1層結(jié)構(gòu))和包含2個卷積池化層的網(wǎng)絡(luò)結(jié)構(gòu)(2層結(jié)構(gòu)),每一種結(jié)構(gòu)比較了卷積核數(shù)量、卷積核尺寸、池化尺寸和LSTM(BiLSTM)輸出維度4個超參數(shù)不同組合下的損傷識別性能,共計54種超參數(shù)組合,比較結(jié)果如表4和表5所示。可以看出:1層結(jié)構(gòu)和2層結(jié)構(gòu)在本例中的識別準(zhǔn)確率總體上差別不大,但是同種結(jié)構(gòu)在不同超參數(shù)組合下差異較大;CNN-LSTM模型采用1層結(jié)構(gòu),卷積核數(shù)量、卷積核尺寸、池化尺寸和輸出維度分別取30,64,8和40時識別準(zhǔn)確率達(dá)到最大;CNN-BiLSTM模型采用1層結(jié)構(gòu),卷積核數(shù)量、卷積核尺寸、池化尺寸和輸出維度分別取50,32,8和40時識別準(zhǔn)確率達(dá)到100%。
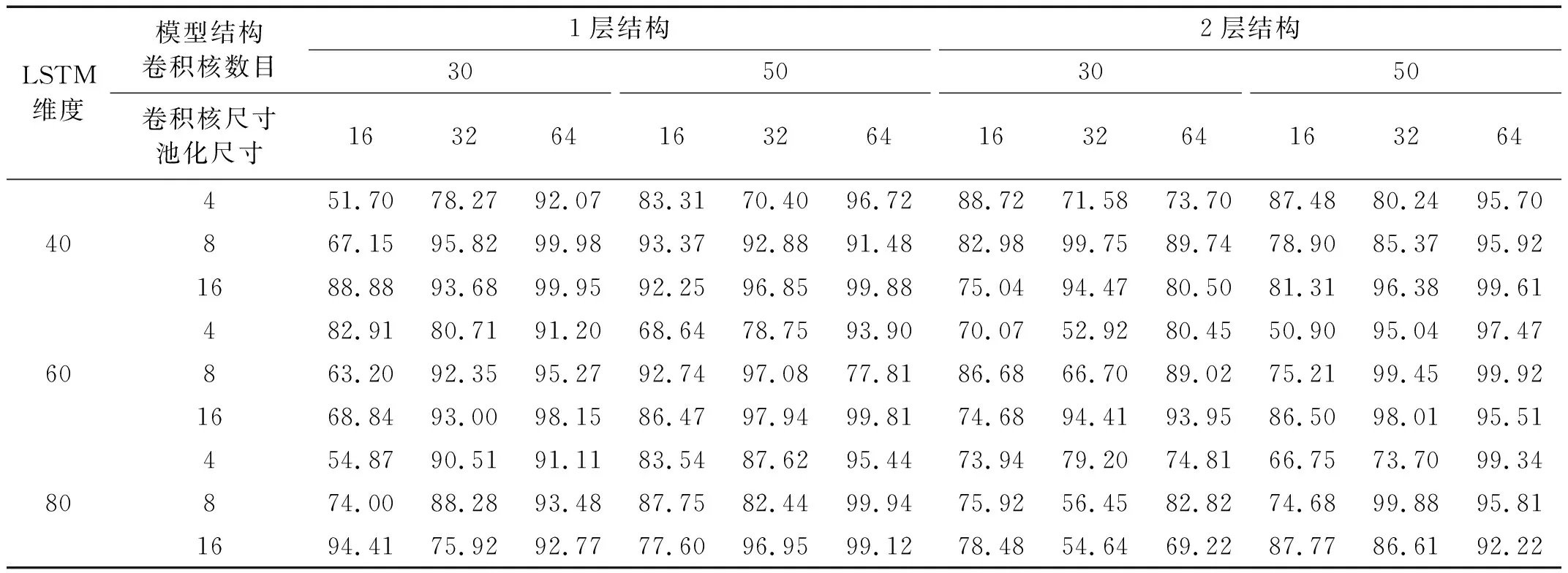
表4 CNN-LSTM在不同結(jié)構(gòu)和超參數(shù)組合下的識別準(zhǔn)確率Tab.4 Accuracy of CNN-LSTM with different structures and hyper-parameters 單位:%
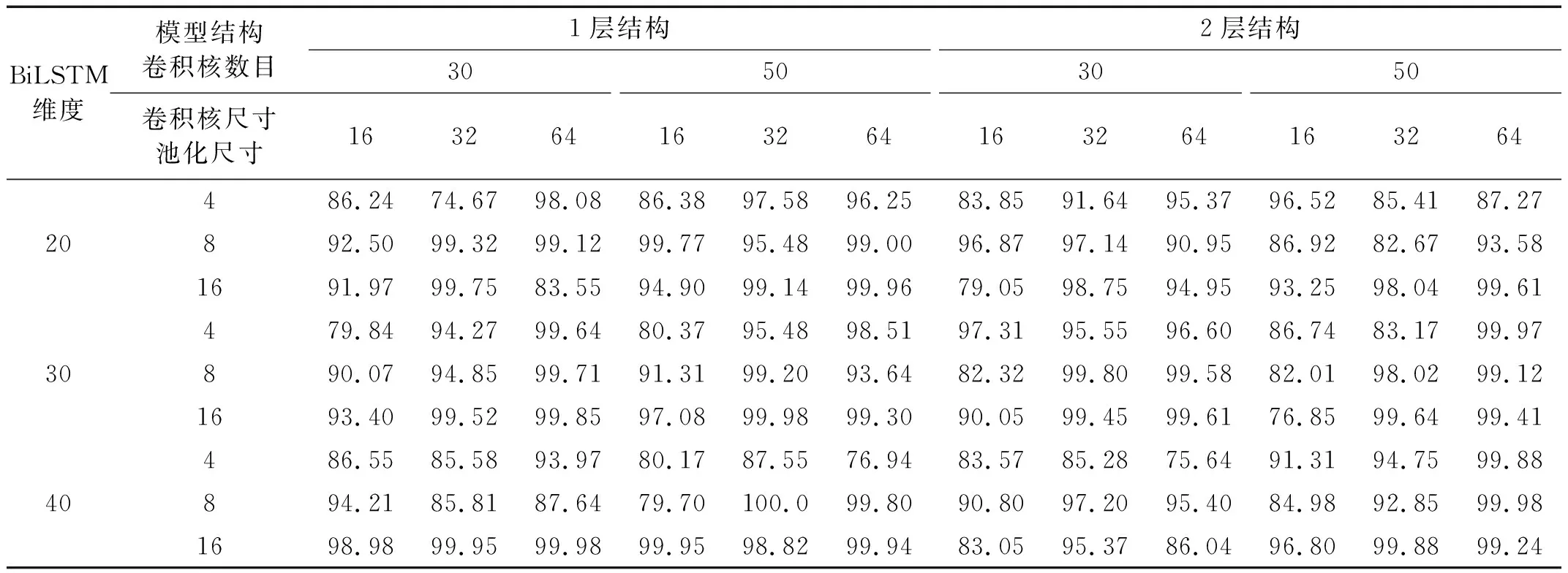
表5 CNN-BiLSTM在不同結(jié)構(gòu)和超參數(shù)組合下的識別準(zhǔn)確率Tab.5 Accuracy of CNN-BiLSTM with different structures and hyper-parameters 單位:%
對于CNN-MA模型,比較了包含1層卷積池化層的網(wǎng)絡(luò)結(jié)構(gòu)(1層結(jié)構(gòu))和包含2層卷積池化層的網(wǎng)絡(luò)結(jié)構(gòu)(2層結(jié)構(gòu))在卷積核數(shù)量、卷積核尺寸和池化尺寸3個超參數(shù)不同組合下的損傷識別性能,共計18種超參數(shù)組合,比較結(jié)果如表6所示。隨后以較優(yōu)的網(wǎng)絡(luò)結(jié)構(gòu)和超參數(shù)為基礎(chǔ),比較了模型自注意力計算次數(shù)分別取1,2,3,5和10時的損傷識別性能,比較結(jié)果如表7所示。可以看出:增加卷積池化層在本例中不能提高識別準(zhǔn)確率,不同超參數(shù)組合對模型性能有較大影響,模型采用1層結(jié)構(gòu)時多個超參數(shù)組合的識別準(zhǔn)確率達(dá)到100%,其中卷積核數(shù)量、卷積核尺寸和池化尺寸3個超參數(shù)分別取30,32,4時不僅識別準(zhǔn)確率達(dá)到最大,而且模型最為簡單,在此基礎(chǔ)上自注意力計算次數(shù)取3和5時識別準(zhǔn)確率均達(dá)到100%。
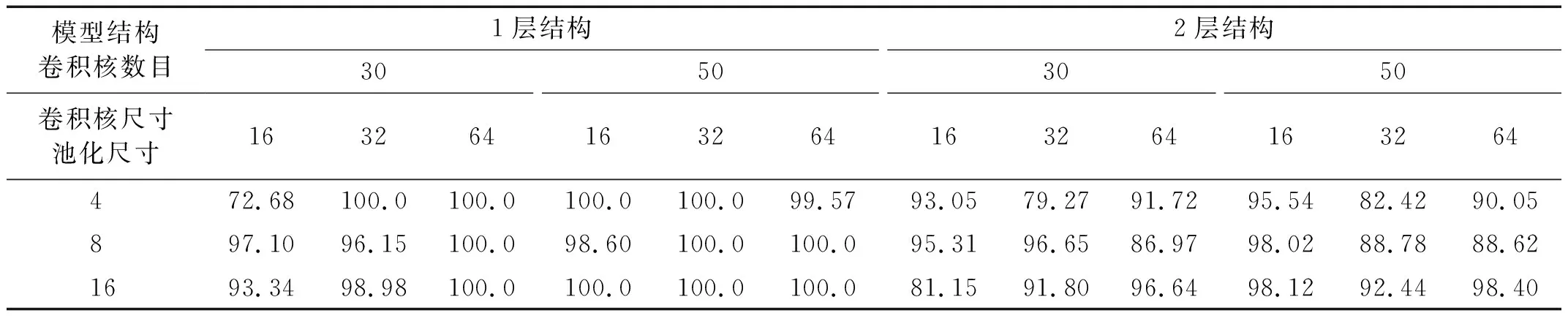
表6 CNN-MA在不同結(jié)構(gòu)和超參數(shù)組合下的識別準(zhǔn)確率Tab.6 Accuracy of CNN-MA with different structures and hyper-parameters 單位:%

表7 不同自注意力計算次數(shù)下的識別準(zhǔn)確率Tab.7 Identification accuracy using different number of heads 單位:%
根據(jù)以上各個模型結(jié)構(gòu)和超參數(shù)的比選結(jié)果,綜合考慮識別準(zhǔn)確率和計算效率選定各個模型較優(yōu)的結(jié)構(gòu)和超參數(shù)。CNN-MA模型的第1層是輸入層,對數(shù)據(jù)進(jìn)行預(yù)處理后輸入模型;第2層是一維卷積和池化層,包含30個尺寸為32的卷積核和尺寸為4的最大池化層;第3層是多頭自注意力層,其中查詢向量、鍵向量和值向量的維度均為10,自注意力計算次數(shù)為3;第4層是全局平均池化層;第5層是Softmax分類層,類別數(shù)對應(yīng)損傷模式的個數(shù),每個輸出對應(yīng)不同損傷模式的發(fā)生概率。除了與CNN-MA模型相同的輸入層、全局池化層和Softmax分類層外,CNN模型包含2層一維卷積和池化層,每一層包含30個尺寸為32的卷積核和尺寸為4的最大池化層;CNN-LSTM模型包含一層由30個尺寸為64的卷積核和尺寸為8的最大池化層組成的一維卷積池化層以及輸出維度為40的LSTM層;CNN-BiLSTM模型包含一層由50個尺寸為32的卷積核和尺寸為8的最大池化層組成的一維卷積池化層以及正反向輸出維度為40、拼接后的最終輸出維度為80的BiLSTM層。
各模型訓(xùn)練時批尺寸設(shè)為64,訓(xùn)練次數(shù)設(shè)為50次,訓(xùn)練時保存訓(xùn)練過程中的最優(yōu)模型用于損傷識別。各模型在本例中的需要學(xué)習(xí)的參數(shù)個數(shù),如表8所示,其中MA-CNN模型參數(shù)最少。由于模型越復(fù)雜、參數(shù)越多,越容易過擬合,因此對于復(fù)雜的模型需要更多的訓(xùn)練數(shù)據(jù)或者采用正則化等技術(shù)抑制過擬合的發(fā)生,本文提出的MA-CNN模型由于參數(shù)更少,因此更加容易訓(xùn)練、泛化性能更好。

表8 各模型參數(shù)數(shù)量Tab.8 Number of the parameters of the models
2.1.3 試驗結(jié)果
將樣本按照8∶1∶1的比例劃分,分別作為模型的訓(xùn)練集、驗證集和測試集,訓(xùn)練集和驗證集用于模型的訓(xùn)練,測試集用于測試模型的泛化性能。各個模型在訓(xùn)練集和驗證集上的訓(xùn)練曲線,如圖7~圖9所示,圖7~圖9中:橫坐標(biāo)epoch為訓(xùn)練次數(shù),縱坐標(biāo)accuracy為訓(xùn)練準(zhǔn)確率。可以看出:各個模型在訓(xùn)練集和驗證集上的訓(xùn)練曲線基本吻合,未出現(xiàn)過擬合現(xiàn)象;在無噪聲數(shù)據(jù)上各模型的訓(xùn)練準(zhǔn)確率都達(dá)到100%,隨著噪聲的增大,各個模型準(zhǔn)確率在訓(xùn)練集、驗證集和測試集上仍能保持較高水平,但均有所下降;CNN-MA模型的收斂速度最快,其余模型收斂較慢,各模型都出現(xiàn)了不同程度的震蕩現(xiàn)象,但是CNN-MA最穩(wěn)定,這是因為CNN-MA模型復(fù)雜度最小,易于訓(xùn)練。各個模型在不同噪聲水平數(shù)據(jù)集上的準(zhǔn)確率,如表9所示。由表9可知:隨著噪聲水平的提高,CNN-MA的準(zhǔn)確率最高,其次是CNN-LSTM和CNN-BiLSTM,CNN的準(zhǔn)確率最低。為了進(jìn)一步檢驗各模型的泛化性能,本文在測試集的每一種損傷模式下隨機(jī)抽取了100個樣本,用于測試各個模型的損傷識別性能。各個模型在測試集各種損傷模式下的識別性能,如表10所示。由表10可知:根據(jù)概率最大損傷判別法則,各個模型在本例數(shù)據(jù)集上均能準(zhǔn)確識別出7種不同的損傷模式,說明各模型均具有較好的抗噪性;隨著噪聲水平的提高,各個模型的損傷識別精度存在不同程度的下降,CNN-MA模型受噪聲影響程度最小,抗噪性最好,其次是CNN-LSTM和CNN-BiLSTM,CNN的識別準(zhǔn)確率受到噪聲影響最大。

圖7 各模型在無噪聲數(shù)值試驗數(shù)據(jù)上的訓(xùn)練曲線FIg.7 Training curves of the models on numerical test data without noise
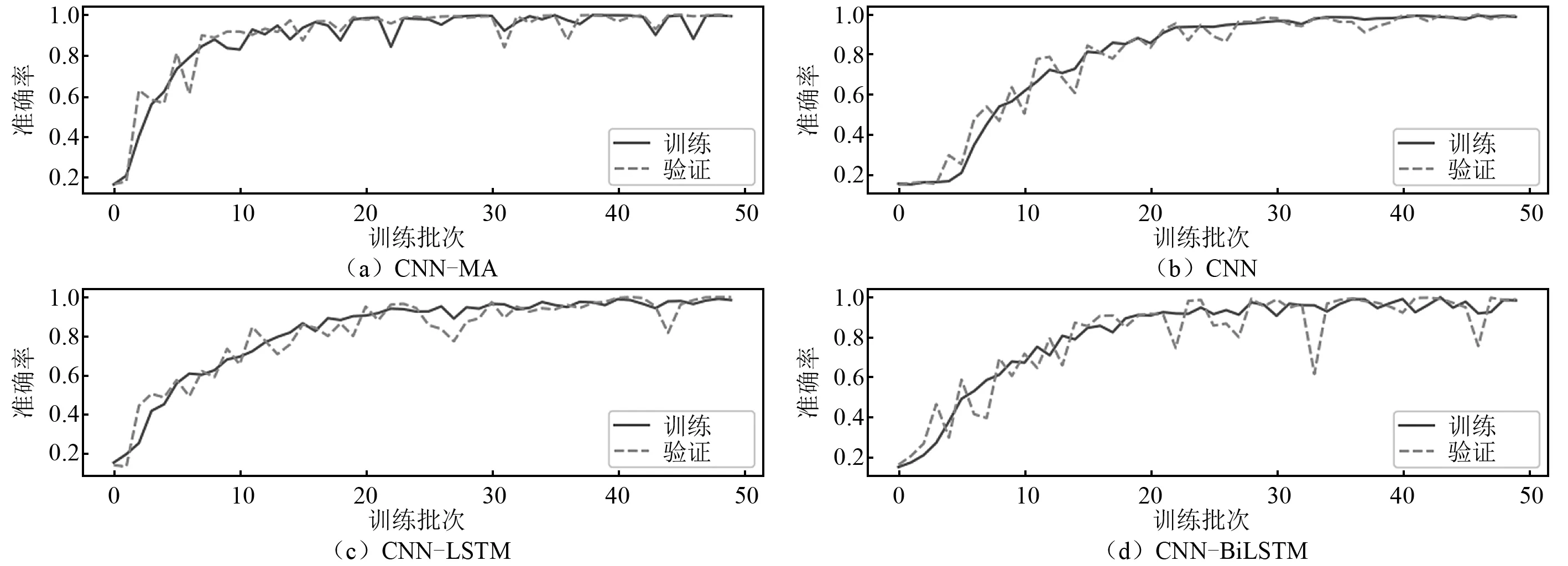
圖8 各模型在含2%噪聲數(shù)值試驗數(shù)據(jù)上的訓(xùn)練曲線FIg.8 Training curves of the models on numerical test data with 2% noise
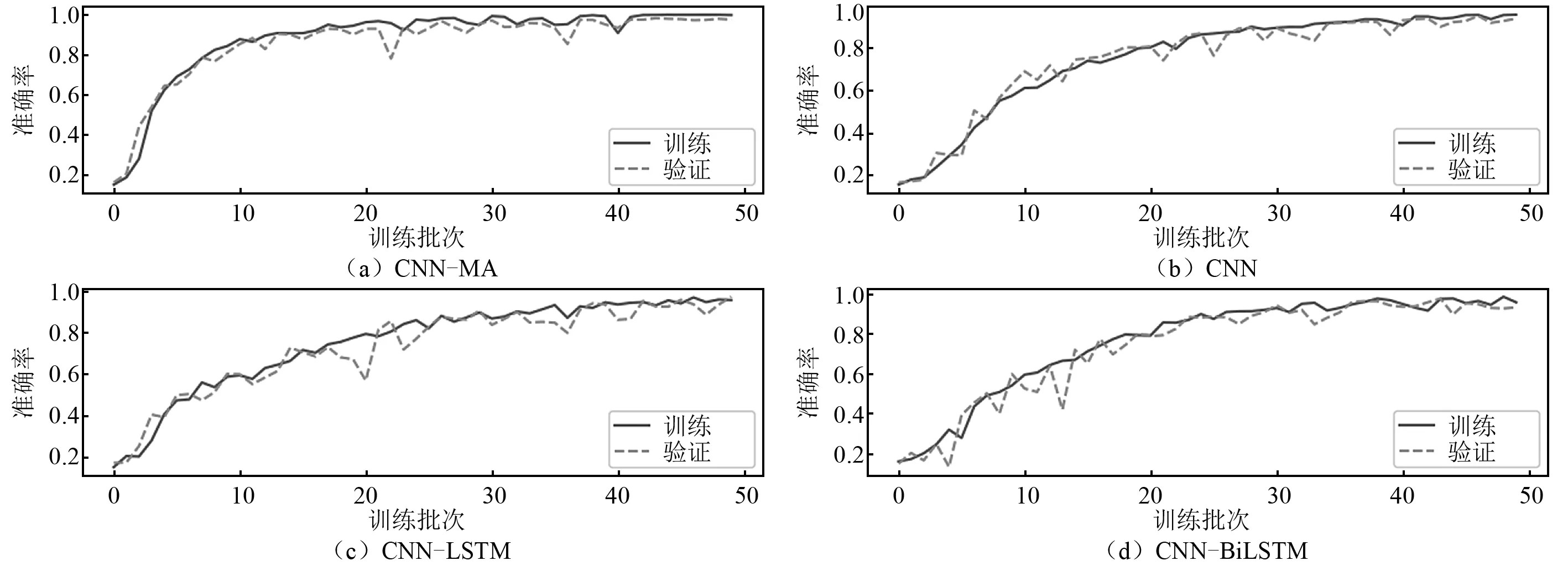
圖9 各模型在含5%噪聲數(shù)值試驗數(shù)據(jù)上的訓(xùn)練曲線FIg.9 Training curves of the models on numerical test data with 5% noise

表9 各模型在懸臂梁數(shù)值試驗數(shù)據(jù)上的準(zhǔn)確率Tab.9 Accuracy of the Models on numerical test data of cantilever beam 單位:%
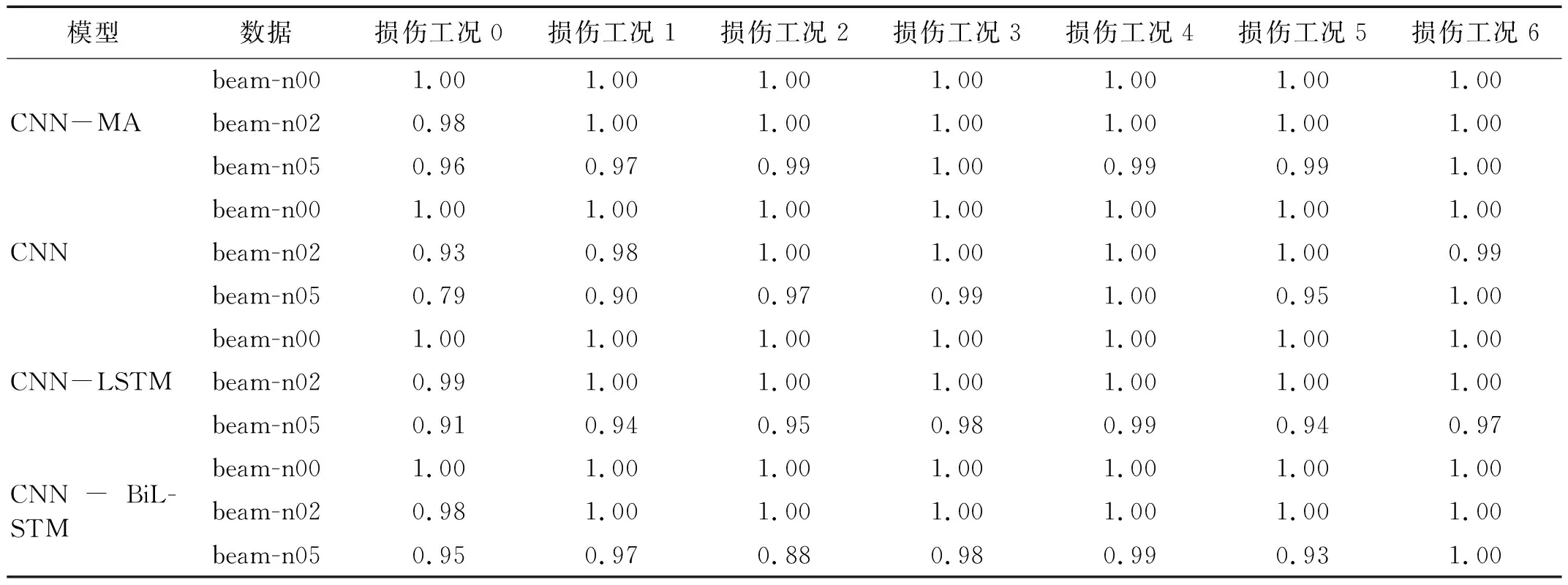
表10 各模型在懸臂梁數(shù)值試驗測試集上的損傷識別概率Tab.10 Damage identifying probability of the models on numerical test data of cantilever beam
2.2 振動臺試驗
為了進(jìn)一步驗證方法的有效性,本文利用實驗室中的懸臂梁振動臺試驗數(shù)據(jù)對模型進(jìn)行測試和比較。試驗所選用的懸臂梁材料和幾何參數(shù)以及邊界約束條件同第2.1節(jié),損傷采用人工切割縫模擬,包括不同裂縫數(shù)量和不同裂縫深度等5種損傷模式,如表11所示。試驗采用電動振動臺產(chǎn)生的隨機(jī)激勵模擬有限帶寬白噪聲振動,激勵的功率譜密度取0.1(m/s2)2/Hz,激振頻率帶寬為5~1 000 Hz。懸臂梁從自由端到固定端布置7個加速度傳感器采集懸臂梁水平加速度,測點布置見圖6,試驗裝置如圖10所示。

表11 振動臺試驗懸臂梁損傷模式Tab.11 Damage patterns of cantilever beam in shaking table test

圖10 懸臂梁振動臺試驗裝置圖Fig.10 Device for shaking table test of cantilever beam
懸臂梁各個測點的加速度信號采樣頻率為5 000 Hz,每一種損傷模式下采集時長為30 s的加速度信號,即每個測點記錄150 000個時刻點的數(shù)據(jù),從而每種損傷模式可得到一個長度為150 000、維度為7的加速度信號序列。然后從每個序列中隨機(jī)抽取1 000個長度為1 024、維度為7的子序列作為樣本,共得到5×1 000=5 000個樣本,按照8∶1∶1的比例劃分成訓(xùn)練集、驗證集以及測試集。
各個模型在訓(xùn)練集和驗證集上的訓(xùn)練曲線,如圖11所示。由圖11可知:各個模型在經(jīng)過一定次數(shù)的訓(xùn)練后均能達(dá)到較高的訓(xùn)練準(zhǔn)確率,訓(xùn)練集和驗證集的訓(xùn)練曲線基本一致,沒有過擬合現(xiàn)象;CNN-MA收斂速度最快、穩(wěn)定性好,CNN的收斂速度最慢但是較為穩(wěn)定,CNN-LSTM和CNN-BiLSTM的穩(wěn)定性較差,震蕩比較嚴(yán)重。各個模型在訓(xùn)練集、驗證集和測試集上的準(zhǔn)確率,如表12所示。由表12可知:各個模型在本例的試驗數(shù)據(jù)上均取得了較好的訓(xùn)練效果,準(zhǔn)確率在90%以上;CNN-MA模型在訓(xùn)練集、驗證集和測試集上都達(dá)到了100%,CNN-LSTM和CNN-BiLSTM在測試集上的識別準(zhǔn)確率均在95%以上,CNN的識別準(zhǔn)確率最低。

圖11 各模型在懸臂梁振動臺試驗數(shù)據(jù)上的訓(xùn)練曲線FIg.11 Training curves of the models on shaking table test data of cantilever beam
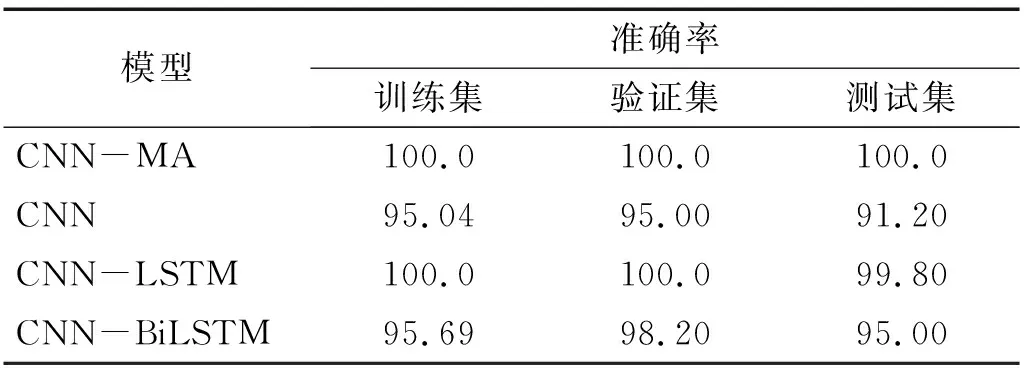
表12 各模型在懸臂梁振動臺試驗數(shù)據(jù)上的準(zhǔn)確率Tab.12 Accuracy of the models on shaking table test data of cantilever beam 單位:%
訓(xùn)練好的各種模型在測試集上對各種損傷模式的識別精度,如表13所示。由表13可知:CNN-MA和CNN-LSTM模型對于各個損傷模式的識別均達(dá)到很高的精度,CNN和CNN-BiLSTM模型識別模式2和模式3時精度相對偏低。各種模型識別各種損傷模式的混淆矩陣,如圖12所示。由圖12可知:CNN-MA和CNN-LSTM能夠不受干擾、非常準(zhǔn)確地識別所有的損傷模式,可以準(zhǔn)確捕捉到相近模式之間的差別,具有很好的損傷識別性能;其他模型在識別損傷模式2和模式3時會出現(xiàn)一定程度的相互干擾:CNN在識別模式2時,100個樣本中90個識別正確,10個被誤判成模式3,在識別模式3時69個識別正確,31個誤判為模式2;CNN-BiLSTM識別模式2時,100個樣本中87個樣本識別正確,13個樣本誤判成模式3,識別模式3時88個識別正確,12個誤判為模式2。

表13 各模型在振動臺試驗數(shù)據(jù)測試集上的損傷識別概率Tab.13 Damage identifying probability of the models on test data set from shaking table test

圖12 振動臺試驗數(shù)據(jù)測試集上的損傷識別混淆矩陣Fig 12 Confusion matrix for damage identification on test data set from shaking table test
3 結(jié) 論
本文基于多頭自注意力機(jī)制和CNN,以結(jié)構(gòu)的振動加速度信號為輸入,構(gòu)建了一種結(jié)構(gòu)損傷識別的CNN-MA模型,并通過網(wǎng)格搜索給出了模型結(jié)構(gòu)和超參數(shù)取值的建議。模型通過CNN提取加速度信號中的局部特征,通過多頭自注意力機(jī)制對信號中不同位置和不同表征空間中的重要信息進(jìn)行關(guān)注,學(xué)習(xí)信號中的全局特征。在懸臂梁數(shù)值試驗和振動臺試驗中,CNN-MA模型由于復(fù)雜度低,更加易于訓(xùn)練;由于能夠?qū)崿F(xiàn)對重要信息的關(guān)注、減少次要因素的干擾,與CNN,CNN-LSTM和CNN-BiLSTM等其他模型相比,CNN-MA模型具有更高的損傷識別精度和抗噪性以及更強(qiáng)的辨識能力和抗混淆能力。目前,本文僅對簡單結(jié)構(gòu)的損傷模式識別進(jìn)行了研究,對于復(fù)雜工程結(jié)構(gòu)的損傷識別以及損傷程度判別等問題需要做進(jìn)一步研究。此外,CNN-MA模型與其他神經(jīng)網(wǎng)絡(luò)模型一樣存在模型優(yōu)化問題,本文僅對有限的網(wǎng)絡(luò)結(jié)構(gòu)和超參數(shù)組合進(jìn)行了比選,需要進(jìn)一步研究高效的模型結(jié)構(gòu)和超參數(shù)的優(yōu)選方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
哲學(xué)評論(2021年2期)2021-08-22 01:53:34
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
現(xiàn)代企業(yè)(2015年9期)2015-02-28 18:56:50
