基于深度學習原子特征表示方法的Janus過渡金屬硫化物帶隙預測*
2023-02-18 06:39:00孫濤袁健美
物理學報 2023年2期
孫濤 袁健美?
1) (湘潭大學數學與計算科學學院,湘潭 411105)
2) (科學工程計算與數值仿真湖南省重點實驗室,湘潭 411105)
隨著人工智能的發展,機器學習在材料計算中的應用越來越廣泛.將機器學習應用到材料性質預測等任務中首要實現的是獲得有效的材料特征表示.本文采用一種原子特征表示方法,研究一種低維、密集的分布式原子特征向量,并用于材料帶隙預測任務.按照材料化學式中原子種類和原子個數,使用Transformer 編碼器作為模型結構,通過訓練大量的材料化學式數據,從而提取參與訓練元素的特征.利用該方法預測Janus結構過渡金屬硫族化合物MXY (M 代表過渡金屬,X,Y 是不同硫族元素)二維材料帶隙.基于深度學習得到的原子特征向量比傳統的Magpie 方法和Atom2Vec 方法的預測平均絕對誤差更小.可視化分析和材料性質預測數值實驗表明,本文提出的基于深度學習提取的原子特征表示方法,可以有效表征材料特征,并且應用到材料帶隙預測任務中.
1 引言
傳統的材料科學研究通常需要經過大量的計算得到材料的目標屬性,這通常會消耗大量時間和資源.隨著人工智能的快速發展,深度學習技術已經被廣泛應用在圖像識別[1]、目標檢測[2]和自然語言處理[3]等領域.深度學習技術不需要了解從特征空間到目標值的具體函數關系,而是通過訓練大量的數據,得到了一組神經網絡權值來構建從特征空間到目標值的映射關系.近年來,深度學習技術被應用到材料的發現和設計、材料性質預測[4,5]等方面.Hu 等[6]通過在OQMD 數據庫上訓練了一個WGAN模型,利用訓練好的鑒別器模型,得到了一種材料表征方法,并且通過在公共 數據集上對材料的帶隙、形成能和臨界溫度進行預測驗證了其有效性.Chen 等[7]利用圖神經網絡建立MEGNet 來預測分子和晶體的性質,在QM9 數據集上預測了13 個目標性質,其中11 個性質優于之前的預測效果.Li 等[8]提出了一種結合卷積神經網絡和長短期記憶神經網絡的混合神經網絡,用于超導體的臨界溫度預測.此外,深度學習技術也被用于分子動力學模擬中,如鄂維南課題組[9]提出了一種基于神經網絡的分子動力學模擬方案,克服了與輔助量(如對稱函數或庫侖矩陣)相關的限制,通過構造深度學習原子勢來描述原子周圍的環境.從大量的材料數據中學習潛在的物理規律,可以用于材料性質的預測,這通常會節省大量的時間和資源.
機器學習模型最重要的兩個方面是數據表示和學習算法.在材料性質預測任務中,機器學習模型的數據表示就是確定材料的特征描述符.在之前的研究工作中,特征描述符的確定通常是先根據預測材料的特性,按經驗從已有的原子特征或者材料結構特征中初步選擇一些特征,然后再利用特征選擇方法通過嘗試和試錯逐步確定最終的特征[10].為了得到材料的通用特征描述符,越來越多的材料表征方法被不斷提出.Zhou 等[11]提出Atom2Vec方法得到原子向量表示,用材料數據建立原子-環境矩陣,通過奇異值分解降維方法得到原子20 維向量表示.Li 等[8]利用Atom2Vec 方法得到的原子向量構建了超導體材料的稀疏矩陣數據表示.Calfa 等[12]提出One-hot 方法得到二元金屬氧化物和晶體材料數據表示,利用核回歸預測了金屬氧化物的電子性質和晶體的彈性性質.One-hot 方法可以簡單地為其他類型材料提供數據表示,有很多學者利用One-hot 方法得到的材料表征作為材料的數據表示,進行下一步機器學習任務.例如Hu 等[6]通過One-hot 方法將OQMD 數據庫中材料表示成一個稀疏矩陣.Ward 等[13]提出Magpie 方法表征材料,通過開發一組基于組合的通用屬性集,得到材料的一維向量數據表示.在文獻[14]中,使用Magpie 方法表征材料,采用支持向量機模型建立了預測無機固體的帶隙機器學習模型.
在之前的材料信息學研究中,材料的數據表示方法通常為以下兩種: 一是先得到原子的數據表示(Atom2Vec),然后通過材料化學式中原子的組成和數量拼接原子向量得到材料的數據表示;另一種是直接通過材料化學式或材料的物理化學性質數據,得到材料的數據表示,例如One-hot 方法.本文利用開放量子材料數據庫的大量材料數據,以自監督的方式訓練Transformer 編碼器模型,提取嵌入層參數得到原子特征向量.然后,通過對主族元素原子的特征向量進行聚類分析,實現了提取的原子特征向量可以區分元素的類別;對主族元素原子特征向量的主成分進行降維分析可以看到,原子特征向量在第一主成分上的投影基本反映了該元素對應的最外層電子數;最后,將其應用在Janus 結構的過渡金屬硫族化合物二維材料帶隙的預測任務中,驗證了原子特征向量在材料預測任務中的有效性.
2 原子特征提取模型介紹
2.1 模型結構
該模型是一種預訓練的機器學習模型.用機器學習模型解決材料問題時,常常面臨數據量不足的問題.如果直接用該數據進行下游任務(材料性質預測等),訓練效果可能一般.在材料性質預測任務中,模型輸入特征一般包括原子特征和材料結構特征[15].本模型的主要作用就是在大量的材料數據中提取原子特征,為用機器學習模型進行材料性質預測等任務得到可靠的輸入.
本模型基于性質相似的原子可以和同樣的原子形成結構和性質相似的化合物的觀點.例如氟和氯是同族原子,都可以和氫以1∶1 的比例結合形成氟化氫(HF)和氯化氫(HCl).
在自然語言處理任務中,Transformer 是一種經典的神經網絡框架[16].Transformer 包括編碼器和解碼器兩部分.本模型結構使用Transformer 的編碼器部分,如圖1 所示,圖中藍色矩形代表原子向量.每個Block 輸入原子向量和輸出原子向量的個數是相同的,因此可以疊加多個Block.在樣本輸入Block 進行訓練前,首先會生成一個原子詞匯表,原子詞匯表包含了訓練數據中全部的原子和特殊符號.對每一個材料化學式中的原子使用One-hot編碼得到一個原子詞匯表長度的向量.通過一個神經網絡嵌入層,讓原子的向量維度從原子詞匯表長度減少到嵌入層神經元個數,在將其輸入Transformer 的Block 中進行訓練.在損失函數的控制下,通過反向傳播算法更新模型中各個節點的參數,待損失函數值趨于穩定,提取了模型前面的嵌入層參數,即原子詞匯表中每個原子的特征表示.
每個Block 內部結構如圖1 右圖所示,每個Block 的輸出向量都由輸入Block 的向量經過同樣的處理方式得到輸出向量.以圖1 左圖從下往上第一個Block 的橙色輸出向量為例,介紹每個Block內部機制(橙色向量僅僅用于介紹Block 內部機制,和藍色向量都代表原子特征向量).輸入Block的橙色向量首先會經過注意力機制得到一個包含其他輸入向量信息的輸出向量,然后將輸入注意力機制的橙色原子向量和該輸出向量相加,得到的新向量經過層歸一化操作,輸入到全連接層中得到輸出向量;該向量和輸入全連接層的向量相加,再經過層歸一化操作得到Block 的對應輸出向量.圖1右圖中僅展示一個Block 的輸出向量,對于其他輸出向量,由輸入向量經過同樣的計算過程得到.
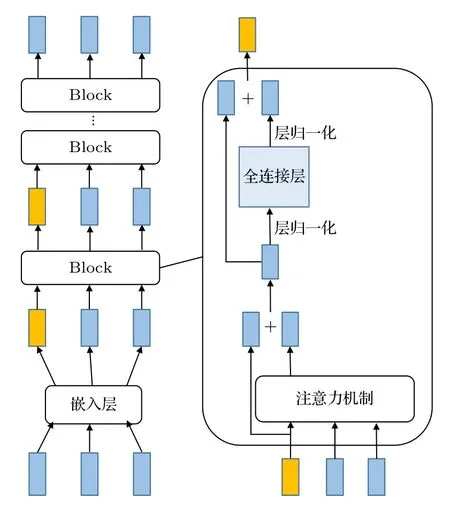
圖1 Transformer 編碼器結構Fig.1.The Transformer encoder structure.
圖1 中注意力機制由一個多頭注意力機制組成,如圖2 所示.對于輸入注意力機制的全部向量組成的矩陣M ∈Rd×f(d為向量個數,f為向量維度),分別與可訓練矩陣Q ∈Rf×f,K ∈Rf×f,V ∈Rf×e(e為向量線性變換到v矩陣的維度)相乘得到q ∈Rd×f,k ∈Rd×f,v ∈Rd×e,公式如下:
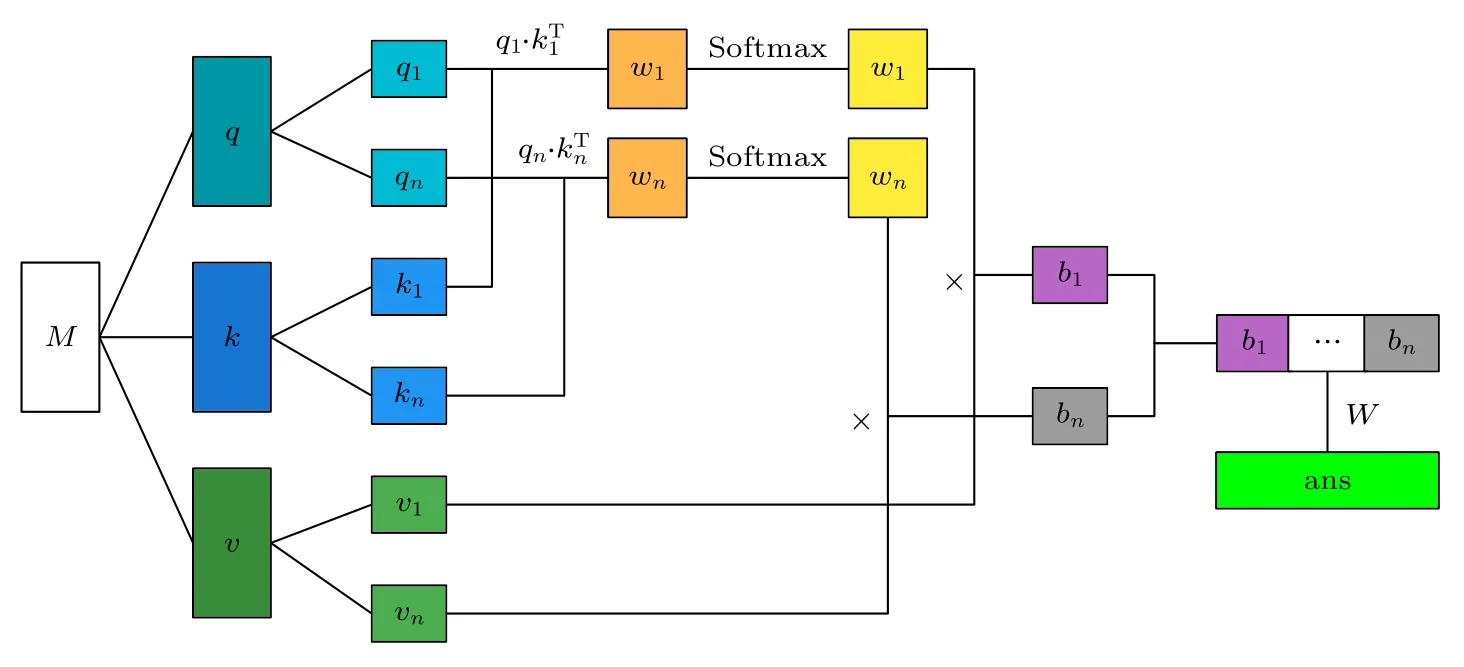
圖2 多頭注意機構模塊結構[16]Fig.2.Multi-attention mechanism module structure[16].
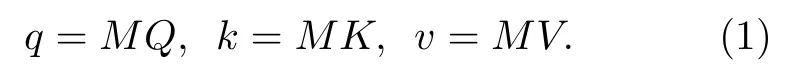
注意力機制輸出矩陣的計算公式如下:
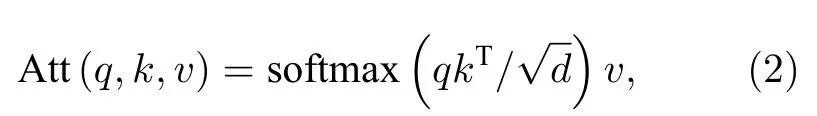
多頭注意力機制每個hea d 對q,k,v分別進行線性變換,對每個head 執行注意力函數.將 headi得到的結果向量記為bi,所有head 得到的結果拼接起來再進行線性變換,得到最終多頭注意力機制的輸出向量ans.
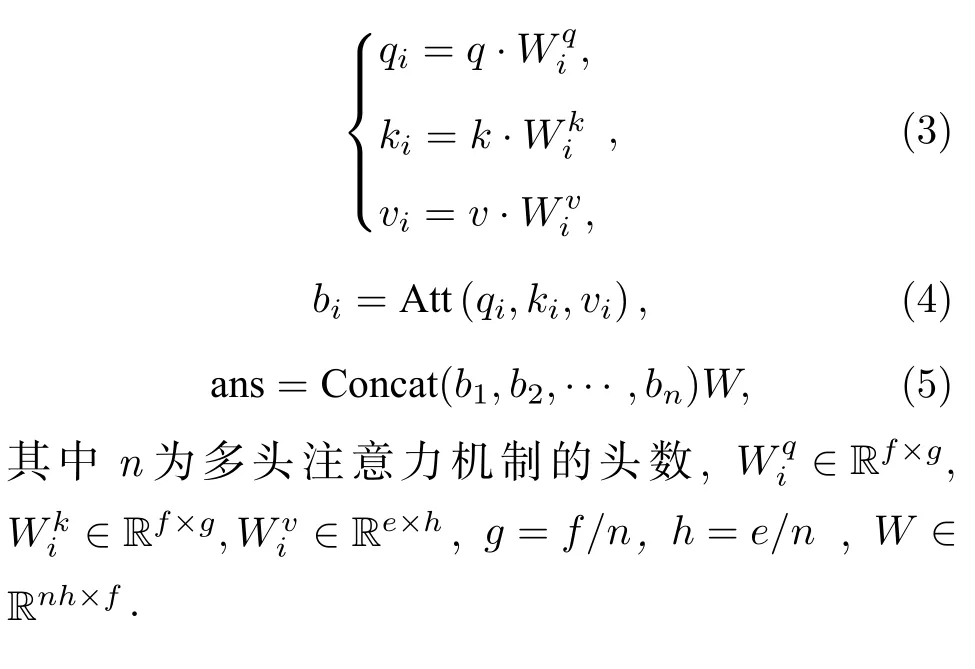
2.2 模型訓練方法
如圖3 中示例輸入樣本所示,將輸入樣本表示成材料化學式1、分隔符、材料化學式2、樣本標簽4 部分.受到自然語言處理領域表現出良好性能的Bert 模型[3]的啟發,使用的訓練方法有兩種,如圖3 所示.第一種訓練方法是隨機遮蓋掉一條輸入樣本15%的原子,讓模型來預測這些被遮蓋掉的原子.如果某個原子被遮蓋,在訓練時該原子位置的輸入有3 種情況: 有80%的概率替換成特殊字符[MASK],有10%的概率隨機替換成一個原子,另外10%概率替換為原子本身.被遮蓋掉的原子對應的輸出向量會經過一個線性多分類器,用softmax 函數得到預測結果的概率分布,然后與該原子的真實標簽用交叉熵損失函數計算損失值,得到 l osslm(原子真實標簽可以在模型訓練過程中遮蓋原子操作時產生).這樣的訓練方式將具有相似性質的原子得到相似的原子向量.
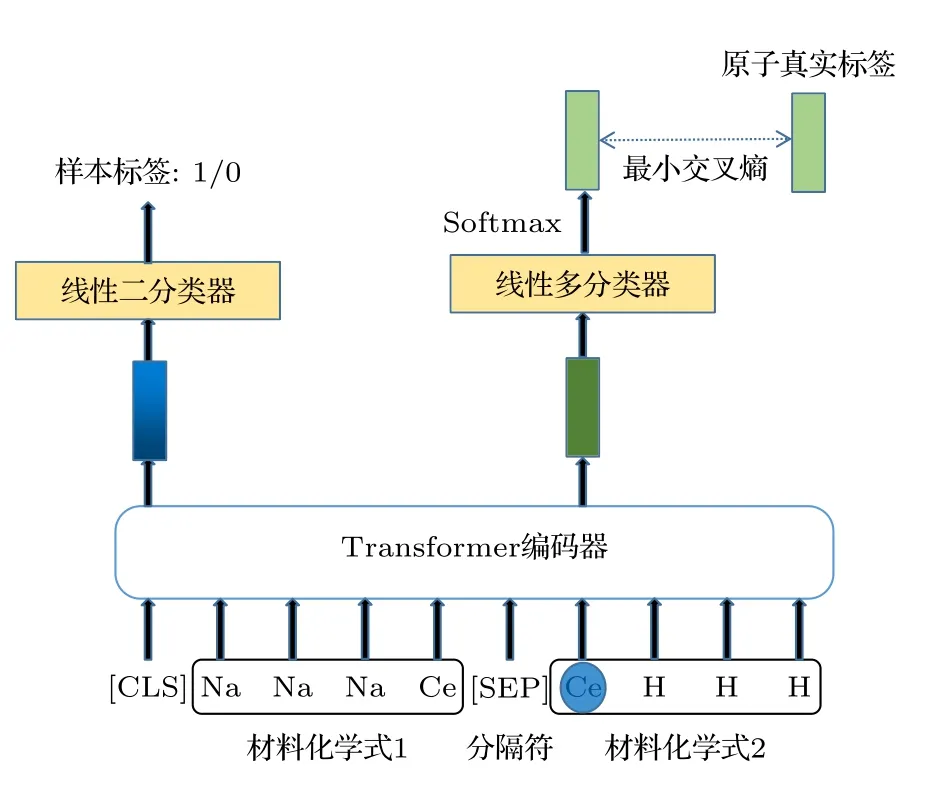
圖3 模型訓練示意圖Fig.3.Model training diagram.
第二種訓練方法是對化合物做類別預測.若兩個材料化學式中包含的元素屬于化學元素周期表中同樣的族,則將兩個材料認為是同一類.若一條樣本中兩個材料是同一類別,則該樣本的標簽為1;反之,若一條樣本中兩個材料不是同一類別,則該樣本標簽為0.在實際訓練時,在每條樣本開始會加入一個特殊字符[CLS].由于模型中加入了注意力機制,該特殊字符在在參與訓練時考慮到了整個樣本,所以對特殊字符[CLS]輸出結果做一個二分類任務,判斷同一條樣本中的兩個材料是否屬于同一類別.該二分類任務的損失函數也是交叉熵損失函數,通過計算損失值得到 l osslabel.
在訓練過程中,以上兩種訓練方法同時進行,然后對目標模型做如下優化:
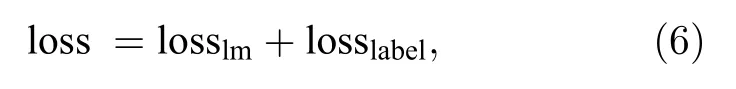
通過反向傳播算法,對模型中的參數進行更新,來減少總損失值,直到總損失值收斂.
3 數值實驗和結果分析
模型需要材料化學式數據作為輸入數據進行訓練,使用開放量子材料數據庫[17](OQMD)的數據來訓練模型.開放量子材料數據庫包含大量由密度泛函理論計算的晶體結構數據,從OQMD 數據庫中提取561888 個材料的化學式,按照模型輸入樣本格式,將其重組成560130 條樣本用于訓練模型.
模型基于Pytorch[18]框架,利用其自動微分和GPU 加速計算動態張量,同時保持較快的計算速度.將提取的樣本中包含的所有元素組成一個原子詞匯表,為了得到原子詞匯表中的所有元素的分布式向量表示,需要先確定向量維度.由于得到的向量應具備密集、低維的特點,所以向量維度不能高于所有元素的個數,但是向量維度太低可能不能包含學習到的全部信息,所以將嵌入層神經元個數調整為16,最終也將得到元素的16 維原子向量.Transformer 編碼器模型已經在自然語言處理領域廣泛應用,其中一個重要的模型應用就是BERT模型[3].本文深度神經網絡的參數設置參考BERT模型參數,并在實際訓練過程中進行參數微調.最終將模型中Transformer 的Block 數設為8,多頭注意力機制head 數目設為8,訓練80 代.
以主族元素為例,分析提取的原子向量代表的物理化學性質.對參與訓練的34 個主族元素進行了基于余弦距離(見 (7)式)的層次聚類,聚類結果如圖4 所示.
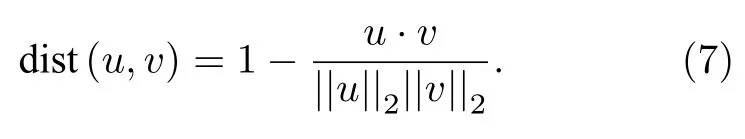
在圖4 中,將相似的原子特征向量用紅色矩形標出.可以看到,第I 主族堿金屬元素(Li,Na,K,Rb,Cs)和II 主族堿土元素(Be,Mg,Ca,Sr,Ba)全部元素被分為一組;第 III 主族金屬元素(Al,Ga,In,Tl)被分為一組;非金屬元素(H,C,N,P,O,S,Se,F,Cl,Br,I)除氧元素為都被分為一組,包含典型的非金屬元素——鹵素;類金屬元素(B,Si,Ge,As,Sb,Te)中,元素B,Ge,As,Sb 被分為一組,同組還有第IV 主族金屬元素(Sn,Pb),第V主族金屬元素(Bi),因為同族元素具有相似的化學性質,這也許是模型更傾向于學習Sn,Pb,Bi 和同族元素的化學性質而不是元素類別.除此之外,利用深度學習得到的原子特征向量也提取了部分原子序數相鄰的元素的關系.例如Al 和Si 的原子序數分別為13 和14,由圖4 可以看出,模型提取的原子特征向量也極為相似.
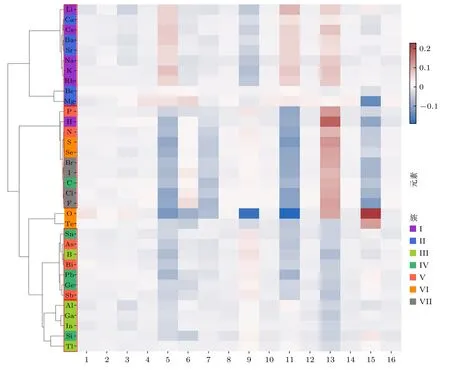
圖4 主族元素層次聚類圖Fig.4.A hierarchical clustering diagram of the main family elements.
另外,為了更好地理解原子特征向量在高維空間中的內涵,利用主成分分析的方法,將16 維原子特征向量降維到4 個主成分.分別做出第一主成分(PCA1)、第二主成分(PCA2)和第三主成分(PCA3)、第四主成分(PCA4)的散點圖,如圖5 和圖6 所示.在圖5 中,可以看到,原子特征向量在第一個主成分上的投影基本上可以反映原子最外層價電子數目,最外層價電子數目越多,第一主成分值越大.在圖6 中,第三、四主成分的散點圖可以將主族元素按同族元素的相似的化學性質進行聚類.
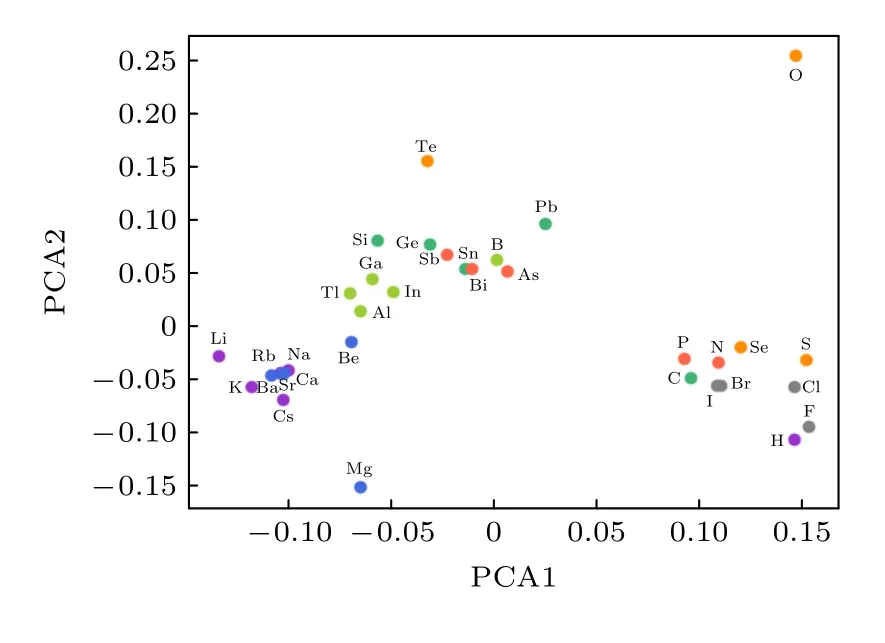
圖5 PCA1 和PCA2 散點 圖Fig.5.PCA1 and PCA2 scatter maps.
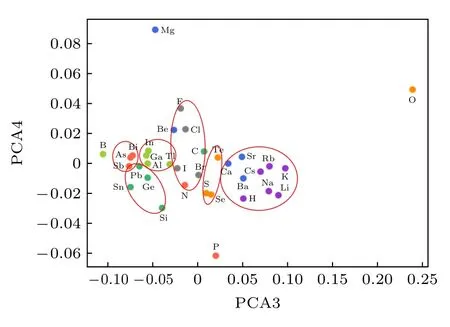
圖6 PCA3 和PCA4 散點圖Fig.6.PCA3 and PCA4 scatter maps.
綜上所述,利用深度學習在大量材料中提取的原子特征向量可以表示元素的信息,在下一節中將驗證本文提取到的原子特征向量在材料信息學的下游任務中有較好的應用.
4 用于預測任務
為了驗證基于深度學習得到的原子特征向量(Atom_DL)的有效性,利用得到的原子特征向量對MXY Janus 單分子層材料的帶隙進行預測.MX2型過渡金屬硫化物(其中M 代表過渡金屬,X是硫族元素)在大量文獻中得到討論[19].最近實驗[20]表明,可以通過用兩個不同的鹵族、硫族或磷族元素來合成金屬原子M 兩側的X,這形成了一類新二維材料,稱為MXY Janus 單分子層.從C2DB數據庫[21?22]中得到216 個MXY Janus 單分子層材料數據,用機器學習的方法來預測MXY Janus單分子層的帶隙.由于C2DB 數據庫中材料帶隙值的缺失,最終篩選出93 條MXY Janus 單分子層材料數據進行預測任務.
機器學習模型的輸入包括材料的原子特征和材料結構特征.分別將基于Magpie 方法、Atom2Vec方法和深度學習的方法得到的原子特征向量作為材料的原子特征輸入模型,其中Magpie 方法①https://github.com/hackingmaterials/matminer/tree/46d6a90664dc9e804e81c2c22cbee9e7221e8315/matminer/utils/data_files/magpie_elementdata和Atom2Vec 方法②https://github.com/idocx/Atom2Vec的數據分別可以在兩個開源項目中獲得.Magpie 方法利用已知的原子物理化學性質,可以簡單高效地構造每個材料的特征向量;但是使用該方法進行預測任務時,往往難以統一特征向量不同分量的量綱.Atom2Vec 方法是一種分布式表示方法,這種方法得到的原子特征向量是連續的、低維的,并且特征向量各分量量綱統一;但是這種方法使用前需要先在大型數據集上預訓練.對于材料的結構特征,考慮到MXY Janus 單分子層具體的結構性質,選擇材料3 個原子的歸一化相對位置和晶胞面積作為材料的結構特征輸入模型.在輸入模型時,將材料的原子特征和材料結構特征拼接起來作為輸入特征,來預測材料的帶隙值.
利用3 種機器學習方法(隨機森林、核嶺回歸、支持向量回歸)對MXY Janus 單分子層的帶隙性質進行建模和預測.隨機森林回歸模型[5]通過隨機抽取樣本和特征,以并行的方式獲得多棵相互不關聯的決策樹的預測結果,對所有決策樹的預測結果取平均值,作為隨機森林回歸模型的預測結果.
核嶺回歸[23]就是基于核函數并且包括l2范數的線性回歸.對于線性回歸模型,可以使用最小二乘法計算回歸模型的參數,但是當樣本數據中存在多重共線性的問題時,參數數值會變得非常大.在最小二乘法回歸模型的基礎上添加參數的l2范數,即為嶺回歸的目標函數:
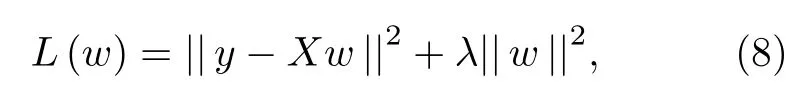
其中λ大于0.為了最小化目標函數,對(8)式右邊關于參數w求導,并且令導數為0,即可得到參數w的最優解為
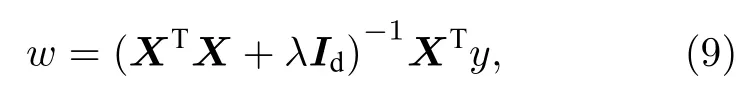
這里Id為單位矩陣.對于非線性數據,通過非線性映射函數Φ將低維空間的數據映射到高維空間,也就是用Φ(X) 代替X,使數據線性可分.在嶺回歸中加入核函數K,即為核嶺回歸.重復嶺回歸求解過程,可以得到核嶺回歸參數的最優解為
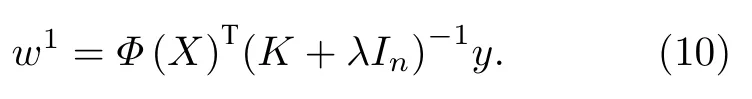
支持向量回歸[24]求解一個線性超平面,使得特征空間中的所有樣本點到該超平面的幾何間隔最大.本質上是求解一個有約束的優化問題,其目標函數為
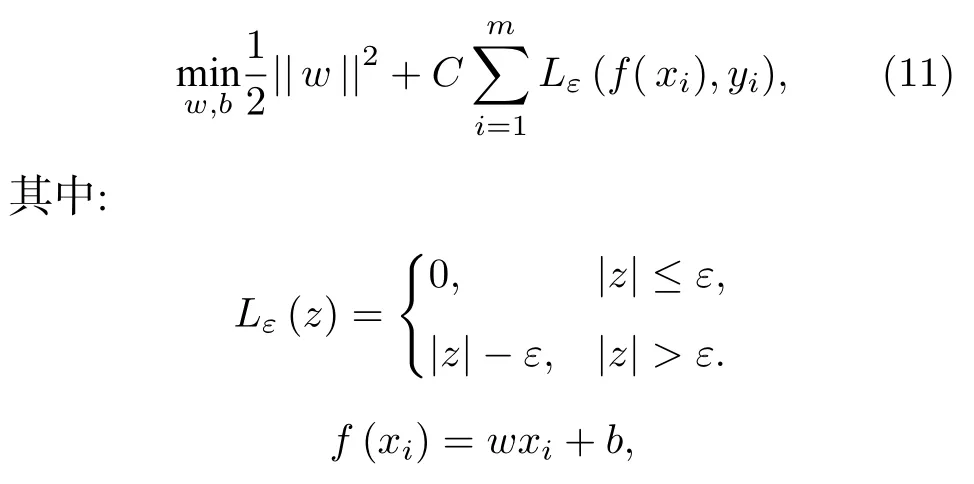
其中w是回歸模型的參數,ε是容忍偏差,y是樣本真實值.支持向量回歸和線性回歸的一個重要區別就是,支持向量回歸存在一個容忍偏差,只有當回歸模型預測值和真實值的差大于容忍偏差,才計算損失.在求解優化問題時,通過拉格朗日乘子法求解.對于非線性數據,支持向量回歸和核嶺回歸類似,通過引入核函數將數據從低維空間映射到高維空間,使之可以求解.
以上3 種機器學習模型各有特點,隨機森林回歸由于隨機性,可以有效降低模型的方差,具有較好的泛化能力和抗過擬合能力;核嶺回歸通過增加正則化項,提升了訓練的穩定性,具有可解釋性、泛化能力強等優點,并且適用于小樣本數據回歸;支持向量回歸作為一種監督學習算法,具有很好的泛化能力,并且對異常值具有魯棒性.
為了得到穩定的結果,利用5 折交叉驗證對模型進行檢驗.5 折交叉驗證將數據集平均劃分成5 份,依次用其中的一份作為測試集,其他數據作為訓練集來得到誤差.最后,計算5 個誤差的平均值作為模型最終的誤差.在不同的機器學習方法和不同的輸入原子特征向量組成的模型中,使用參數搜索的方式得到最優的模型.相同的機器學習方法的參數在同一個參數空間中進行搜索,所有的機器學習算法模型都是使用開源庫Scikit-learn[25]實現的.隨機森林模型的參數如表1 所示,核嶺回歸的參數如表2 所示,支持向量回歸模型參數如表3所示.

表1 隨機森林模型參數Table 1.The random forest model parameter.

表2 核嶺回歸模型參數Table 2.Kernel ridge regression model parameter.

表3 支持向量機回歸模型參數Table 3.Support vector regression model parameter.
各模型的預測結果的平均絕對誤差如圖7 所示,對于3 種機器學習方法,基于深度學習得到的原子特征向量作為輸入特征時的平均絕對誤差要低于已有的兩種原子特征向量表示方法.此外,當Magpie 和Atom2Vec 方法得到的原子特征向量輸入機器學習模型中時,核嶺回歸模型預測的精度是最差的;而對于本文提出的原子特征向量方法,核嶺回歸模型預測的精度比其他兩種方法高.由于核嶺回歸更適用于處理特征相關性高的數據集,而Magpie 得到的原子特征向量分量量綱不統一,特征相關性自然很低,所以平均絕對誤差比較高;而本文提出的原子特征向量量綱統一,各特征之間有一定的相關性,所以平均絕對誤差較低,這也說明本文得到的原子特征向量是低維、密集的分布式特征向量.
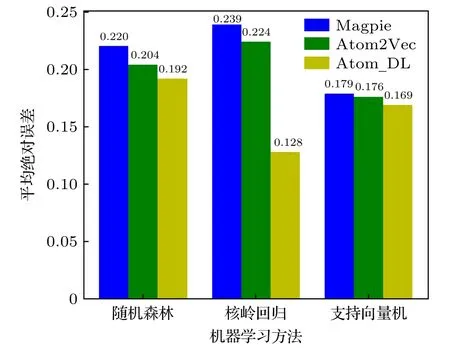
圖7 對MXY Janus 單分子層材料的帶隙預測平均絕對誤差Fig.7.MAE of band gap prediction for MXY Janus monolayer materials.
表4 列出了測試集中的24 個樣本的帶隙計算值和帶隙預測值,其中帶隙計算值是通過基于密度泛函理論的第一性原理計算得到的,在密度泛函理論中使用PBE 交換關聯泛函進行計算,自旋軌道耦合通過非自洽對角化包含在Kohn-Sham 特征態的全基中[22].從表4 可以看出,3 種機器學習模型均對基于深度學習的原子特征向量具有良好的預測效果.這也驗證本文得到的原子特征向量的在機器學習方法中的有效性,這樣得到的原子特征向量可以應用到其他材料性質預測的任務中.
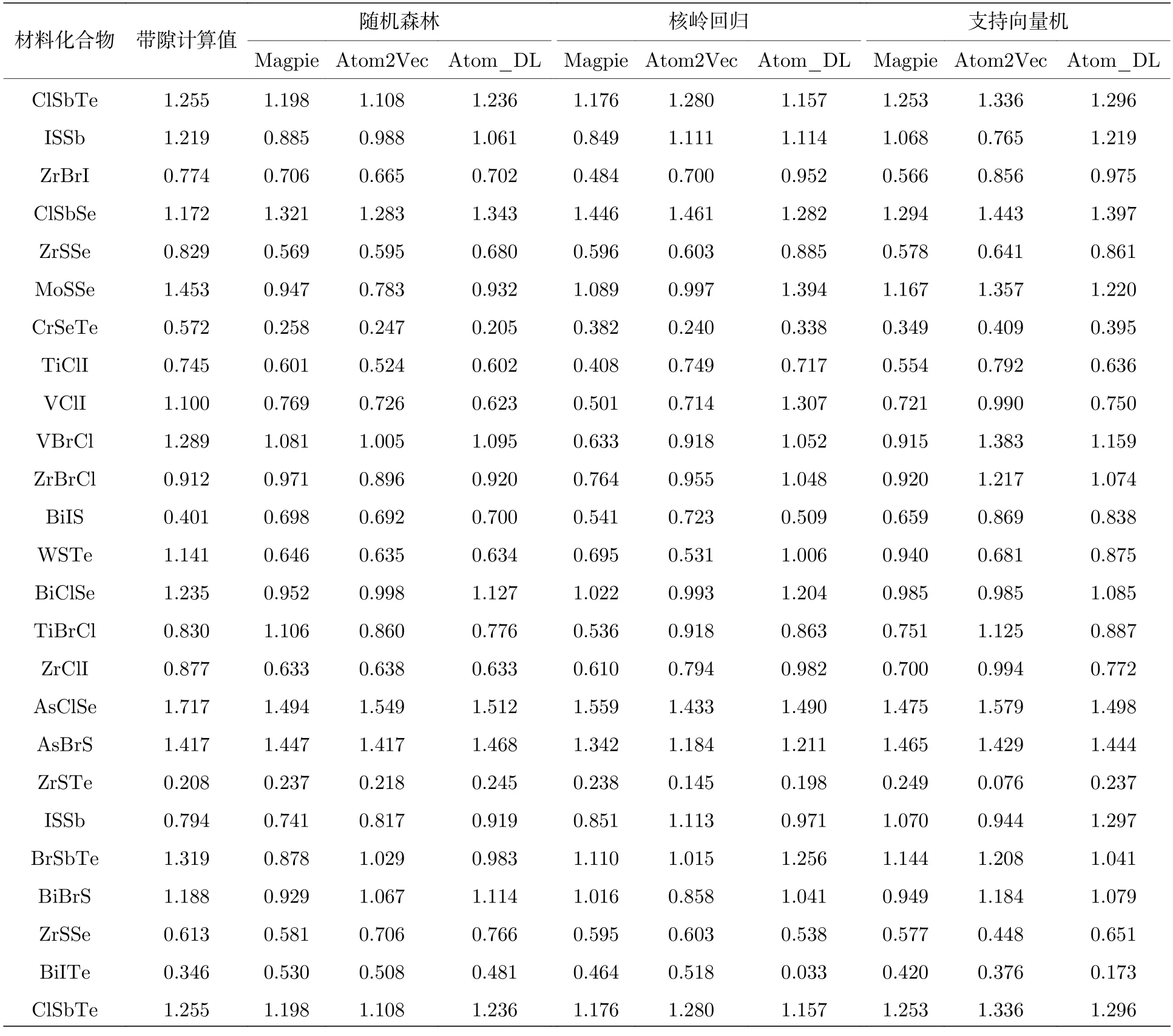
表4 測試集材料預測值和計算值對比Table 4.Comparison of material predictive and experimental values in the test.
5 結論
本研究基于性質相似的原子可以和同樣的原子形成結構和性質相似的化合物的觀點,利用深度學習的方法從大量材料化學式數據中提取主族元素和大多數副族元素的原子特征.使用隨機森林、核嶺回歸和支持向量回歸3 種機器學習方法對Janus 結構過渡金屬硫化物MXY Janus 單分子層材料的帶隙性質進行預測.在材料特征表示上,使用了材料結構特征和原子特征.材料結構特征使用組成化合物各原子的歸一化相對位置和晶胞面積,原子特征分別使用Magpie,Atom2Vec 和Atom_DL.為了得到回歸效果更好的模型,對每一種機器學習模型定義一個相同的參數搜索空間,使用Scikit-learn 庫中的參數網格搜索函數在參數搜索空間中進行搜索,得到機器學習模型的最佳參數,使用該參數對測試集上的材料數據進行預測,計算測試集的平均絕對誤差.從結果上來看,基于深度學習提取到的原子特征在機器學習模型中表現出更好的性能.
隨著機器學習的不斷發展,機器學習模型在材料信息學中的應用越來越廣泛.而利用機器學習模型的第一步就是特征工程,所以本研究結果可以應用到其他材料任務中去.在材料的特征表示上,材料的結構特征對性能的影響也不容忽視,也將關注提取不同類型材料的材料結構特征.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
