融合專利與論文信息的內容挖掘和引用基礎的企校創新合作推薦研究
2023-03-01 01:57:02閆曉慧馬博聞鄧三鴻王蔚萍
現代情報 2023年3期
閆曉慧 馬博聞 鄧三鴻 王蔚萍
(1.南京大學信息管理學院,江蘇 南京 210023;2.江蘇省數據工程與知識服務重點實驗室,江蘇 南京 210023;3.江蘇螞蟻云數據技術有限公司,江蘇 南京 210008)
在全球新一輪的科技革命中,科技創新是引領發展的第一動力,科技產業逐漸成為各個國家(地區)的發展引擎[1]。2022年兩會通過的政府工作報告[2]強調,要促進科技創新,強化企業創新的主體地位,深入實施創新驅動發展戰略,依靠創新提高發展質量。雖然我國目前已經成為世界第二大經濟體,但是其創新體系仍存在一定的缺陷[3]。同時,高校是技術創新和科技創新的源泉,深入企業和高校合作,對于應對當前復雜的網絡化創新問題具有重要意義,對于科學發展也具有極其深遠的實踐意義[4]。
持續推進科技創新,深化企校合作,首要的任務就是為企業尋找最佳的高校合作伙伴,來促進科技成果轉移轉化。企業尋求高校合作有助于突破供給約束堵點,實現企校共贏[5]。專利和論文是科技創新的主要表現形式,也是發明創新的主要成果,對專利和論文進行分析可以較好地反映具體產業的技術程度。如何通過專利和論文尋找恰當的合作機構,成為當前科學研究中的又一重要課題。
1 文獻回顧
企業和高校等機構合作可以促進科技成果快速轉化為技術,市場需求通過企業傳遞到高校等研究機構給科研創新方向做指導。到目前為止,國內外對于企業和高校之間的合作研究已經取得了較為豐碩的成果。綜合而言,當前國內外學者針對企業和高校等機構間的合作研究主要集中在3個方面:其一是對企業和高校等機構之間合作動機的研究。產學研機構合作有助于實現突破式創新[6],企業和高校等機構之間的合作動機分為資助動機、學習動機和使命動機3種[7]。企業通過和高校等機構合作能夠降低運行成本、風險以及與生產技術相關的多種不確定性[8],并且其自身分擔成本和風險的能力對參與合作的意愿具有顯著影響[9]。企業和高校之間的專利合作有利于促進經濟發展,并且有必要進一步提升高校在該合作中的參與度[10]。其二是關于企業和高校合作中的具體問題研究。機構合作對于企業、高校和科研機構三方都會帶來積極影響[11],協同創新過程中涉及的指標有助于產學研合作管理[12],機構之間的地理距離對合作績效有很重要的影響[13],產學研合作網絡中的平均路徑長度會影響企業的創新[14]。政府資助對于企業和高校之間的合作效率存在著顯著的抑制作用[15],SE-SBM模型常用來進行產學研合作效率的演化研究[16]。專利和新產品是機構合作相關研究中常采用的創新產出指標[17],從論文—專利角度切入產學研合作網絡可探索機構潛在合作機會[18]。其三是對企業和高校等機構合作整體研究。大學、產業、政府、公眾與公民社會、自然環境五者之間的相互作用關系被稱為五螺旋模型[19]。具體研究中,可以從大學角度出發,對比產學研創新合作的模式[20],Agrawal A K[21]總結了企業特征、大學特征、知識溢出地理特征和知識轉移渠道等方面的相關研究。此外,中國[22]、中美兩國[3]、斯洛文尼亞共和國[23]、日本[24]、意大利區域[25]、金磚五國[26]等國家(地區)級別的產學研合作也備受科研人員的關注。
綜上所述,國內外的研究大多基于合作后的機構共現情況進行分析,針對合作前的機構推薦工作的研究較少,并且推薦方法比較單一,涉及的維度也較少。因此,本文從企業角度入手,分內容挖掘和引用基礎兩個方面來進行企校合作機構推薦綜合研究,前者主要用來分析機構的科研重點,后者著重表示機構對前人研究的主動選擇性。本研究能夠幫助企業實現特定研究領域下的高校合作伙伴尋找,以期為我國企校合作提供參考支持。
2 融合專利與論文信息的內容挖掘和引用基礎的企校創新合作推薦模型構建
2.1 模型總架構
本文構建的融合專利與論文信息的內容挖掘和引用基礎的企校創新合作推薦模型,首先從德溫特創新索引庫和Web of Science核心合集數據庫進行專利和論文數據收集與預處理,與此同時,通過專利與論文信息的內容挖掘相似度計算和引用基礎相似度計算兩個方面進行模型構建,其中,基于專利與論文信息的內容挖掘相似度計算部分又分為基于細分領域的相似度計算和基于關鍵詞的相似度計算兩個部分,最后進行組合推薦。具體的模型構建框架如圖1所示。
本模型構建的核心部分是企校機構間相似度計算,這一部分包含著基于細分領域相似度計算、基于機構關鍵詞相似度計算和基于機構引用基礎相似度計算3個部分。本文選用Jaccard相似系數進行3個部分的相似度計算,其中關鍵詞相似度計算部分,引入TF-IDF算法進行權重分析。3個部分的相似度計算完成后,通過專家咨詢法賦予權重進行企校合作機構的綜合推薦研究。
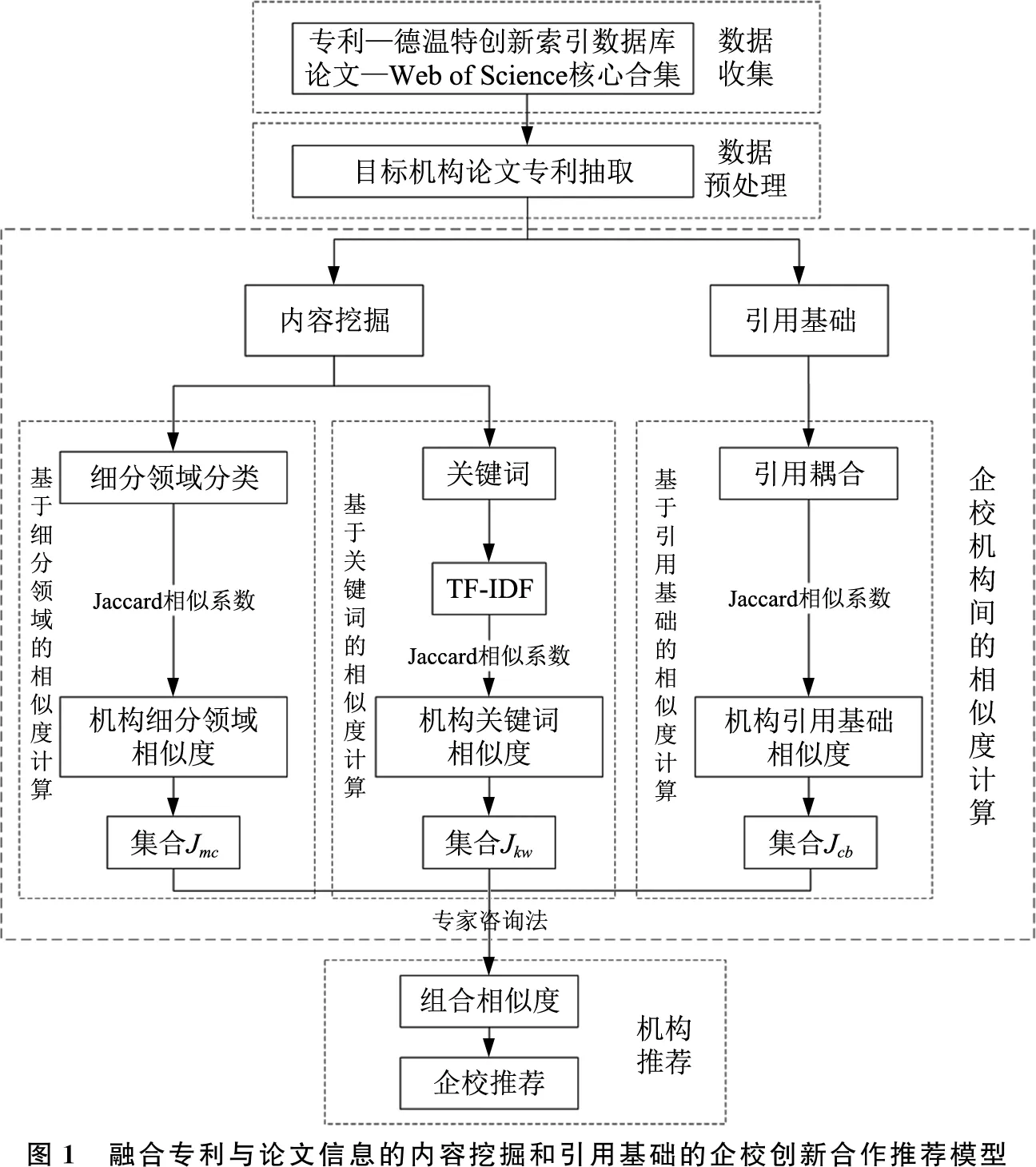
2.2 基于專利與論文信息的細分領域的相似度計算
德溫特專利數據庫收集的專利文獻信息全面可靠。該數據庫在收集到專利數據后,經過專門的標引人員根據具體的技術創新按照層級關系賦予該數據庫專有的分類代碼,又稱德溫特手工代碼,給每一個專利都賦予不止一個的分類代碼來體現該專利的核心內容和主題。所以,德溫特分類代碼就相當于整個數據庫中的“關鍵詞”,并且,值得注意的是,德溫特分類代碼一經標注,除非有新的技術領域或研究方向產生,否則是不會更改的,這也是該數據庫的主要特色之一[27]。WOS數據庫依照基本科學指標數據庫(Essential Science Indicators,簡稱ESI)學科目錄對收錄文獻進行分類,是圍繞基礎研究建立的同行評議、評估體系,沒有進行分級設類,直接按照英文字母A~Z順序進行排序,總類目共有251種。很多研究以德溫特分類代碼和科研成果的學科分類為計算基礎,判斷企業之間的合作可能性[28-29]。換言之,專利的德溫特分類代碼和論文的Web of Science學科分類在一定程度上可以說是專利和論文內容的總結,在此,本文將德溫特分類代碼和學科分類代碼合并稱為細分領域。因此,機構的創新研究重點可以通過其細分領域進行表征。
機構之間相似度的計算方法比較多,其中,Jaccard相似系數經常用來計算研究機構之間的相似度,并且Jaccard相似系數表示的是兩個機構之間的交集和并集比值,能夠消除兩個機構之間因體量大小導致的差異[30-31]。因此,本文采用Jaccard相似系數來計算機構之間的相似度,具體到計算企業和高校之間的專利和論文研究的相似度。
企業(Enterprises,簡稱E)和高校(Universities,簡稱U)之間的Jaccard相似系數等于兩機構之間的交集大小與并集大小的比值,具體表示見式(1),取值范圍為[0,1]:
(1)
在本研究中,企業和高校兩機構間基于細分領域的Jaccard相似系數Jmc的計算方法見式(2):
(2)
其中,Jmc表示機構之間的細分領域的Jaccard相似系數,Emc和Umc分別表示企業和高校的細分領域的具體數量,I(E,U)表示兩個機構之間的細分領域的交集,Emc+Umc-I(E,U)表示兩個機構之間的細分領域數量的并集。
2.3 基于專利與論文信息的內容關鍵詞的相似度計算
通過挖掘專利與論文信息的內容研究可用來尋找合作伙伴[32-33]。而專利與論文的內容由不同的關鍵詞構成,在具體的計算中,還需考慮關鍵詞的權重。首先,通過Python中Jieba分詞包進行分詞;其次,剔除沒有實際意義的詞,并輔助以人工檢測進行關鍵詞處理,同時將同一關鍵詞的不同形式、相同內容的關鍵詞等進行標準化處理;最終,得到每個機構的關鍵詞表。
TF-IDF算法是當前較為常見的一種計算集合內關鍵詞權重的方法,可以用來計算一個機構內某個關鍵詞的權重。計算公式見式(3):
(3)
其中,i是機構專利與論文內容關鍵詞的序號,Wti表示關鍵詞ti的內容權重,tf(ti,d)指關鍵詞ti在機構專利與論文內容關鍵詞集合中出現的頻次,|D|是一個機構的專利和論文數,df(ti)為機構專利和論文中包含關鍵詞ti的專利和論文數。
根據TF-IDF算法得出機構專利與論文內容關鍵詞權重,選定合適數量的關鍵詞作為機構專利與論文內容的特征詞,最終通過Jaccard相似系數計算兩機構之間的關鍵詞相似度集合Jkw。
2.4 基于專利與論文信息的引用基礎的相似度計算
專利申請和論文創作前期,研究人員需要對前人的相關研究進行學習和繼承,才能有所突破,得到新的專利或論文成果,引用基礎就是對前人研究最直接和全面的反映。
同被引和耦合是引用分析中常用的兩種方法,當兩個機構的專利或論文同時被其他專利或者論文等引用時,機構間存在同被引關系。兩個機構的專利或論文同時引用同一份專利或者論文等的內容,這兩個機構之間的關系為耦合。兩者的主要區別在于耦合經常被用來探索未來的發展傾向,同被引則主要用來回顧其具體的基礎情況[34]。引用耦合屬機構的“主動”選擇,同被引則屬于機構“被動”地選擇。因此,相對于同被引關系,本文認為,引用基礎耦合更適合于企校機構間相似性的研究。
將機構專利與論文中引用的專利和論文全部抽取出來,構建各個企業和高校的引用基礎數據集,最終通過Jaccard相似系數計算企業和高校之間的引用基礎相似度集合Jcb。
2.5 相似度整合
前文計算可以得到企校機構間的相似度集合Jmc、Jkw、Jcb。為了更加合理地進行模型構建,本文采用專家咨詢法將3種相似度以一定的比例組合,得到企業和高校之間的專利和論文的相似度,整合后見式(4):
Simi=α×Jmc+β×Jkw+γ×Jcb
(4)
其中,Simi表示兩個機構在某一方面(用i表示)整合后的相似度,i取值為專利(p)、論文(a);Jmc表示基于細分領域的相似度;Jkw表示基于機構關鍵詞的相似度;Jcb表示基于機構引用基礎的相似度,α+β+γ=1。
本文邀請5位了解“人工智能”領域的計量學專家對權重進行兩輪的賦值,在少數服從多數的指導原則下,取5位專家賦值的平均數,并保留1位小數,最后得到3個方面的權重如下:Jmc∶Jkw∶Jcb=0.5∶0.3∶0.2。由此,得到式(5):
Simi=0.5×Jmc+0.3×Jkw+0.2×Jcb
(5)
再次邀請這5位專家,對專利和論文對機構相似度的權重進行賦值,秉承求同存異的原則,得到Simp∶Sima=0.6∶0.4。這樣,得到融合專利和論文信息的內容挖掘與引用基礎的企校創新合作推薦模型見式(6),最終選擇以相似度排名前五的高校進行推薦:
Sim=0.6×Simp+0.4×Sima
(6)
3 實證研究
3.1 數據收集
近年來,人工智能對社會和經濟影響日益凸顯。我國自2015年以來,多次將人工智能的發展和規劃列入國家政策,各省市積極響應中央號召,推出相應的地方發展規劃和政策,逐步確立人工智能技術在我國戰略發展中的重要性。2022年政府工作報告中強調,促進數字經濟發展,要壯大人工智能等數字產業,提升關鍵軟硬件技術創新和供給能力。因此,本文選取“人工智能”主題下的專利和論文數據進行分析。
本文的專利數據來源于德溫特創新索引數據庫(Derwent Innovations Index)中的專利數據,論文數據來源于Web of Science核心合集數據庫。其中,檢索式為“TS=(‘artificial intelligence*’ or ‘Depth learning*’ or ‘Natural language processing*’ or ‘Speech Recognition*’ or ‘Computer vision*’ or ‘Gesture control*’ or ‘smart robot*’ or ‘Video recognition*’ or ‘Voice translation*’ or ‘Image Recognition*’ or ‘Machine learning*’)”。為控制成果質量,專利只選擇發明專利,文獻的類型為Article并且只選取SCI和SSCI兩個數據庫。時間限定為2012年1月1日—2021年12月31日,共收集到117 482條人工智能專利數據和153 165篇人工智能論文。
3.2 數據預處理
本文進行的是我國企業和高校機構之間的合作推薦研究,企業選擇的是由中國科學院旗下《互聯網周刊》聯合eNet研究院研究發布的“2020人工智能企業百強”榜單的前50強[35],該單位已經連續發布了2017—2020年的人工智能企業百強榜單,具有一定的連續性和權威性。高校樣本則選擇我國的985高校,這些高校是我國早期立項的教育領域的重點工程,同科研實力較強的很多企業有著比較穩定持久的合作關系[36]。
數據預處理過程共分為三步:第一步,數據抽取。將“3.1數據收集”部分收集到的專利和論文數據逐條編碼,著重抽取出每條數據的機構情況。如專利數據以“AE”字段為主,論文數據選擇“C1”字段中的作者機構。根據從我國人工智能前50強企業和985高校的官網上收集其所有名稱,并將所有國內機構的數據全部抽取出來;第二步,機構數據合并。將同一機構的數據進行合并,并且對各個機構進行唯一編碼,可得到我國前50強人工智能企業和高校的專利和論文的數量情況,具體如表1所示;第三步,數據庫建立。將第二部抽取出的不同機構專利和論文數據分別建立數據庫,再將不同機構的專利或論文數據分別根據“細分領域”“關鍵詞”和“引用基礎”3個方面進行數據庫建立。
從表1分析,國內前50強人工智能企業申請的專利共有8 899條,占所有專利的7.57%,論文共有19 980篇,占所有論文的13.04%。整體而言,我國人工智能前50強企業和高校申請的專利和論文的數量相對較少。從數據來看,企業申請的專利比高校申請的數量要多一些,其中,百度公司申請的專利最多,騰訊和平安科技公司緊隨其后,申請專利數量前四的機構全部為企業。高校中浙江大學和清華大學申請的專利較其他高校多一些。論文成果量最多的機構為清華大學,浙江大學和上海交通大學依次位列第二和第三;企業中阿里巴巴公司的論文發表量最高。

表1 我國前50強人工智能企業和高校的專利申請和論文發表情況
分別對企校機構之間的合作情況進行統計,可得論文中的機構合作較專利多,故不做具體分析,我國前50強人工智能企業和高校機構間的合作類型及合作次數如表2所示。
表2中,專利合作分為“企—校”“企—企”“校—校”3種,“企—校”合作(42次)次數最多,并且遠遠超過“企—企”和“校—校”之間的合作總和。其中,思必馳公司和上海交通大學之間的專利合作最多,思必馳公司的總部在江蘇蘇州,同上海交通大學聯合共建運營蘇州交馳人工智能研究院有限公司,全面負責智研院的商業運營工作。在前50強人工智能企業中,一共有7家企業參與專利合作,騰訊公司是參與專利合作最多的企業。
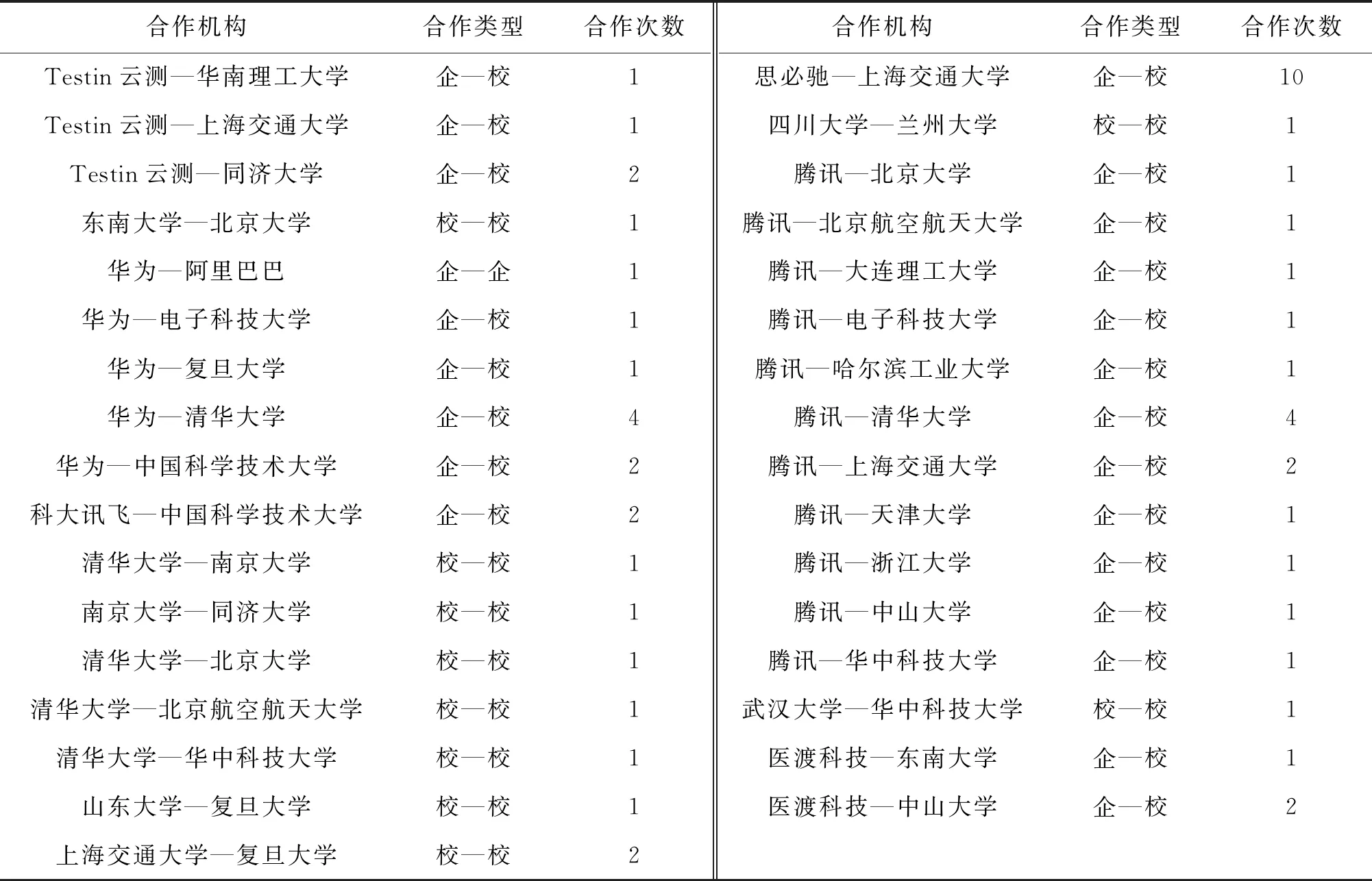
表2 前50強人工智能企業和高校的專利合作情況
3.3 機構間相似度計算
企校機構之間的相似度包含“細分領域”“關鍵詞”和“引用基礎”3個方面,本文利用“3.2數據預處理”部分建立的數據庫,通過式(5)分別計算企業和高校機構之間專利和論文Jaccard相似度,具體計算結果如表3、表4所示。類型列中的“Jmc”“Jkw”“Jcb”“Simp”和“Sima”分別表示“細分領域相似度”“關鍵詞相似度”“引用基礎相似度”“專利信息下的機構相似度”和“論文信息下的機構相似度”。表3、表4中,百度公司和北京大學兩個機構之間綜合內容挖掘和引用基礎兩個方面的專利和論文整體相似度分別為4.45%和4.78%。整體分析可以得出,細分領域相似度對于企校機構間相似度的區分性最高,其次為關鍵詞相似度,引用基礎相似度的區分性最低,在一定程度上印證了“2.5相似度整合”部分專家咨詢確定權重的科學性。
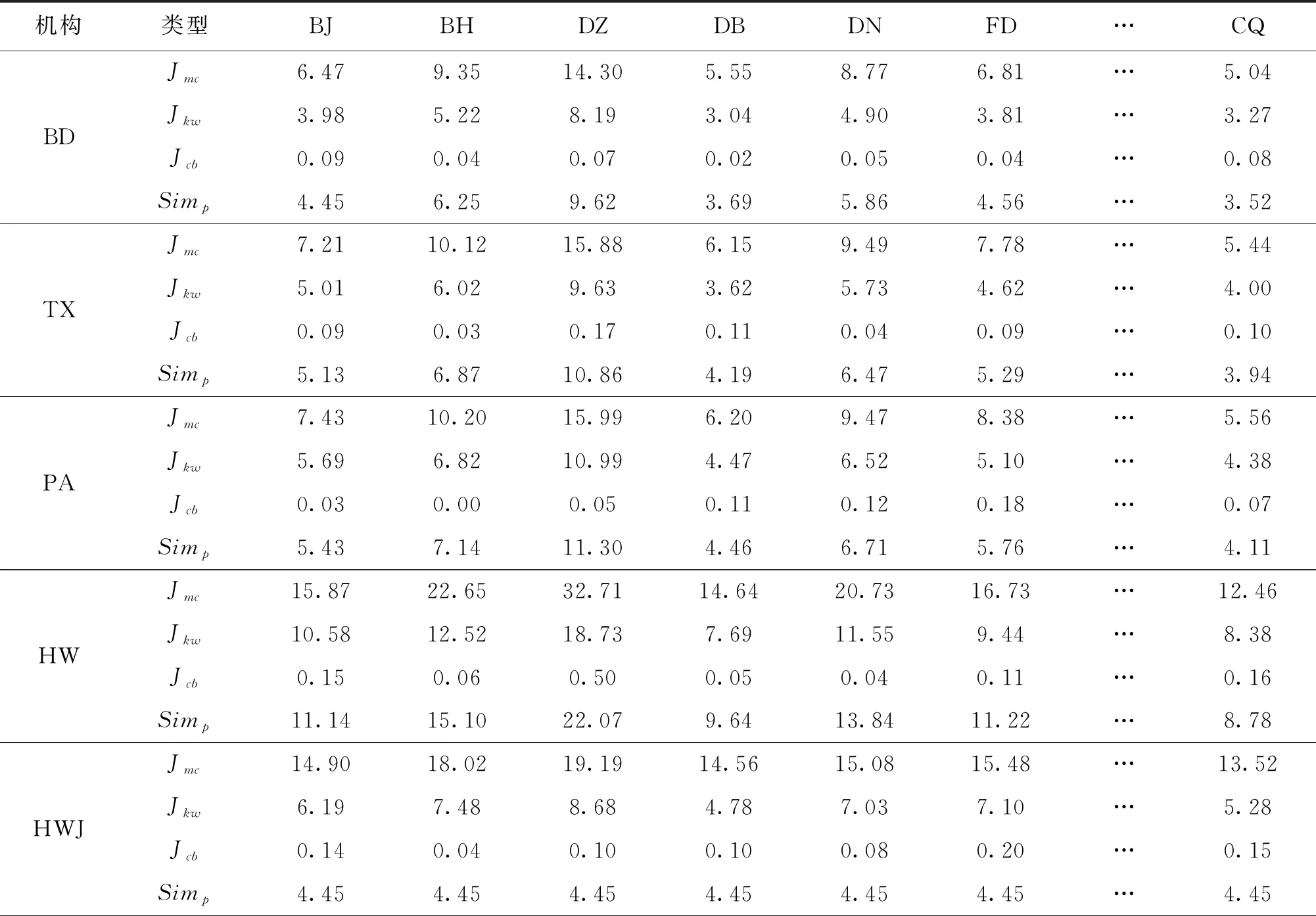
表3 專利信息下企業和高校機構間的不同相似度(局部) %
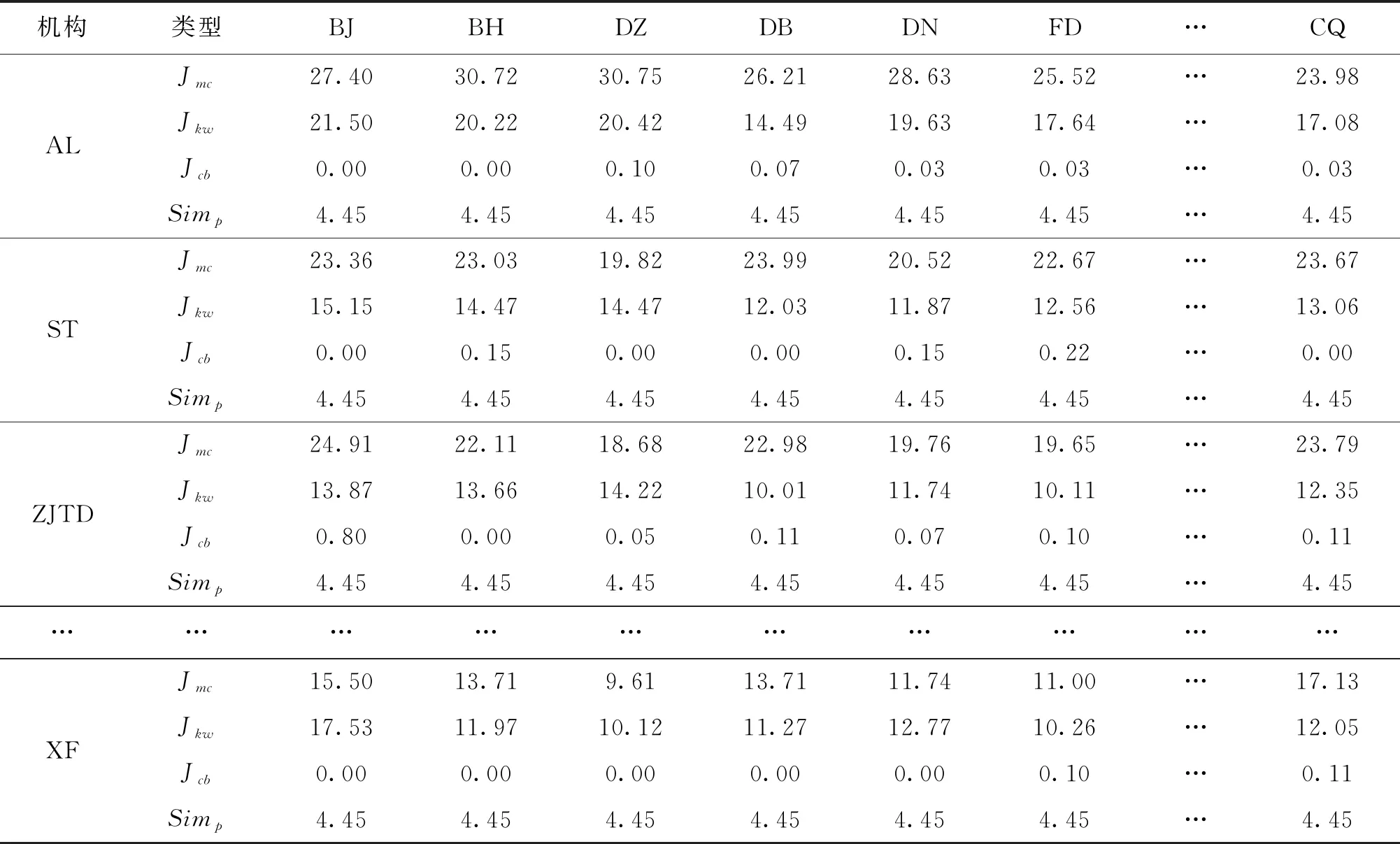
表3(續)
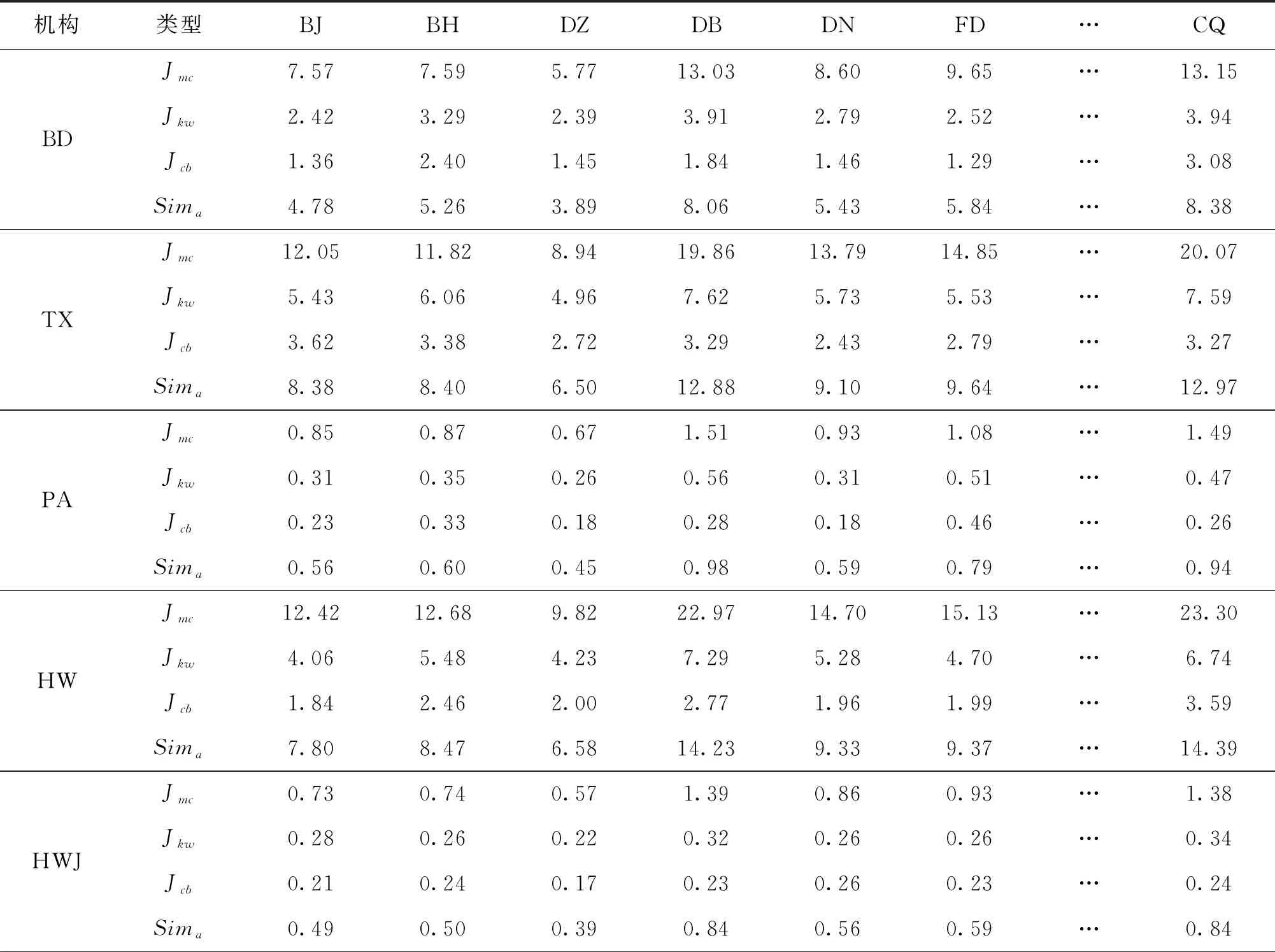
表4 論文信息下企業和高校機構間的不同相似度(局部) %
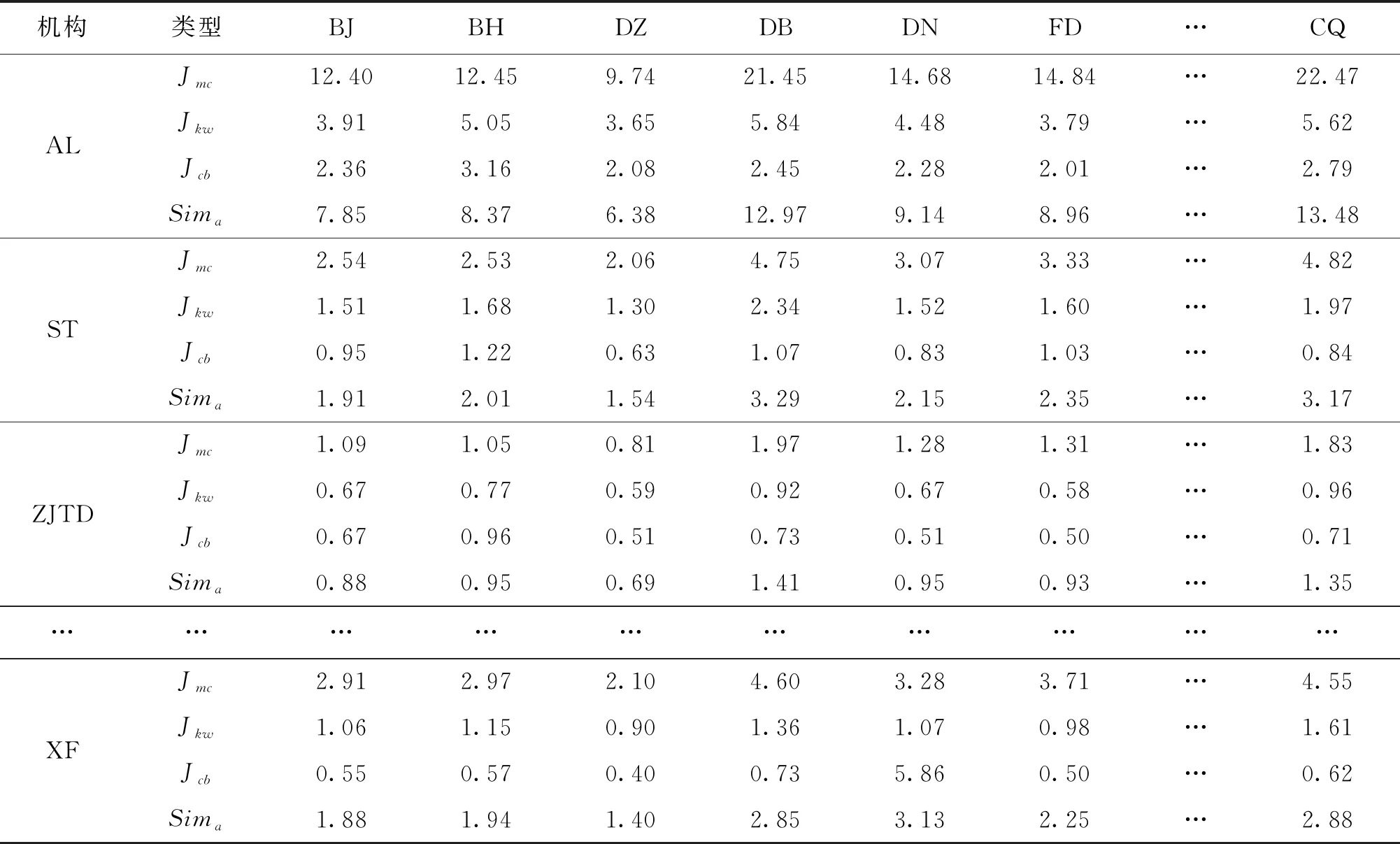
表4(續)
利用表3和表4的數據,再根據“2.5相似度整合”部分的式(6),計算得出融合專利與論文信息的內容挖掘和引用基礎的企校創新合作機構間的相似度結果,具體結果如表5所示。百度公司和北京大學兩個機構之間融合專利與論文信息的內容挖掘和引用基礎的企校機構間的相似度為4.58%,同北京航空航天大學的相似度為5.85%。
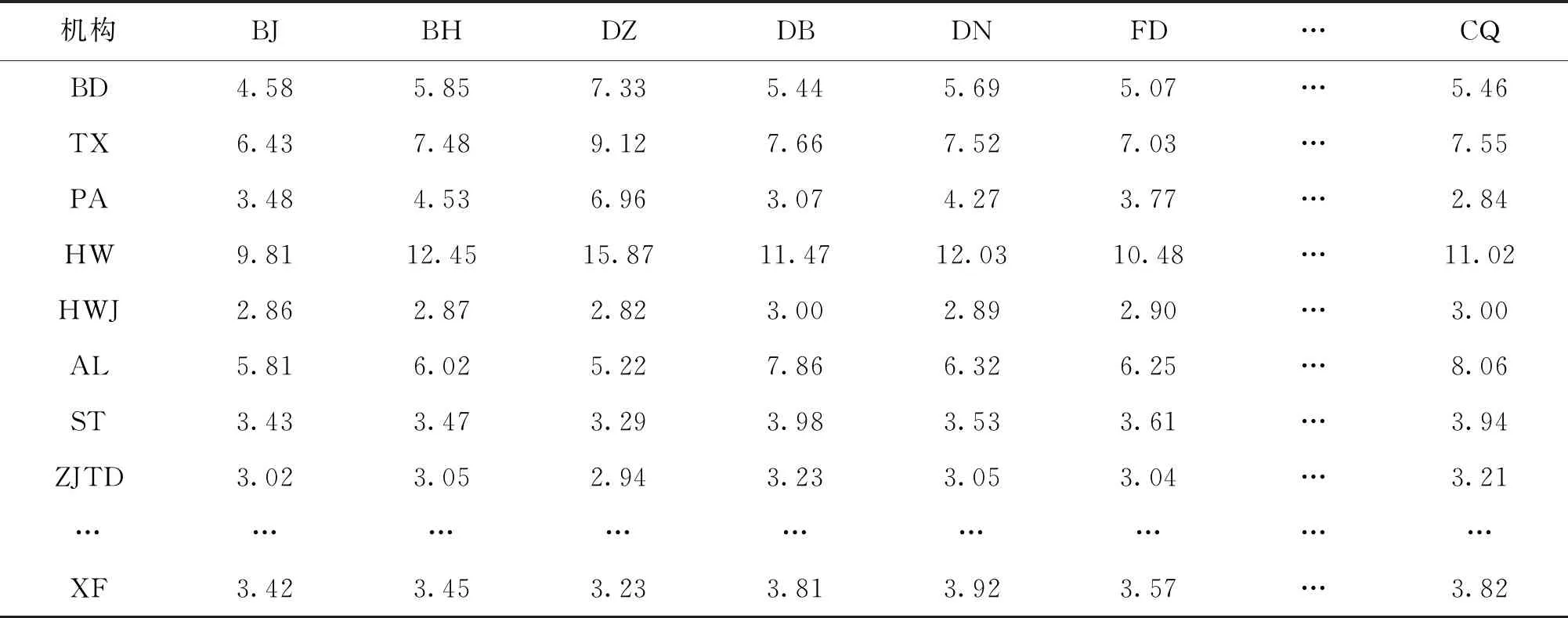
表5 融合專利與論文信息的內容挖掘和引用基礎的企校機構間的不同相似度(局部) %
3.4 推薦結果展示
根據表5的計算結果,得出企業與不同高校之間的“人工智能”領域的相似度排名,根據企校機構間的相似度順序,為每一個企業推薦前5所合作高校,具體的推薦結果如表6所示。其中,中國人民大學的專利和論文的數量都不是最多的,但是被推薦的次數最多,究其原因,中國人民大學涉及“人工智能”方面的領域研究分布比較均勻,并沒有很明顯地側重于某些具體方向。從表1可得,清華大學、浙江大學和上海交通大學3所高校的“人工智能領域”成果較多,每個學校有其明顯的研究側重點,如本文為平安科技公司推薦上海交通大學為第一高校,兩個機構在“數據庫應用”和“神經網絡”等方面的科研投入最為相似。
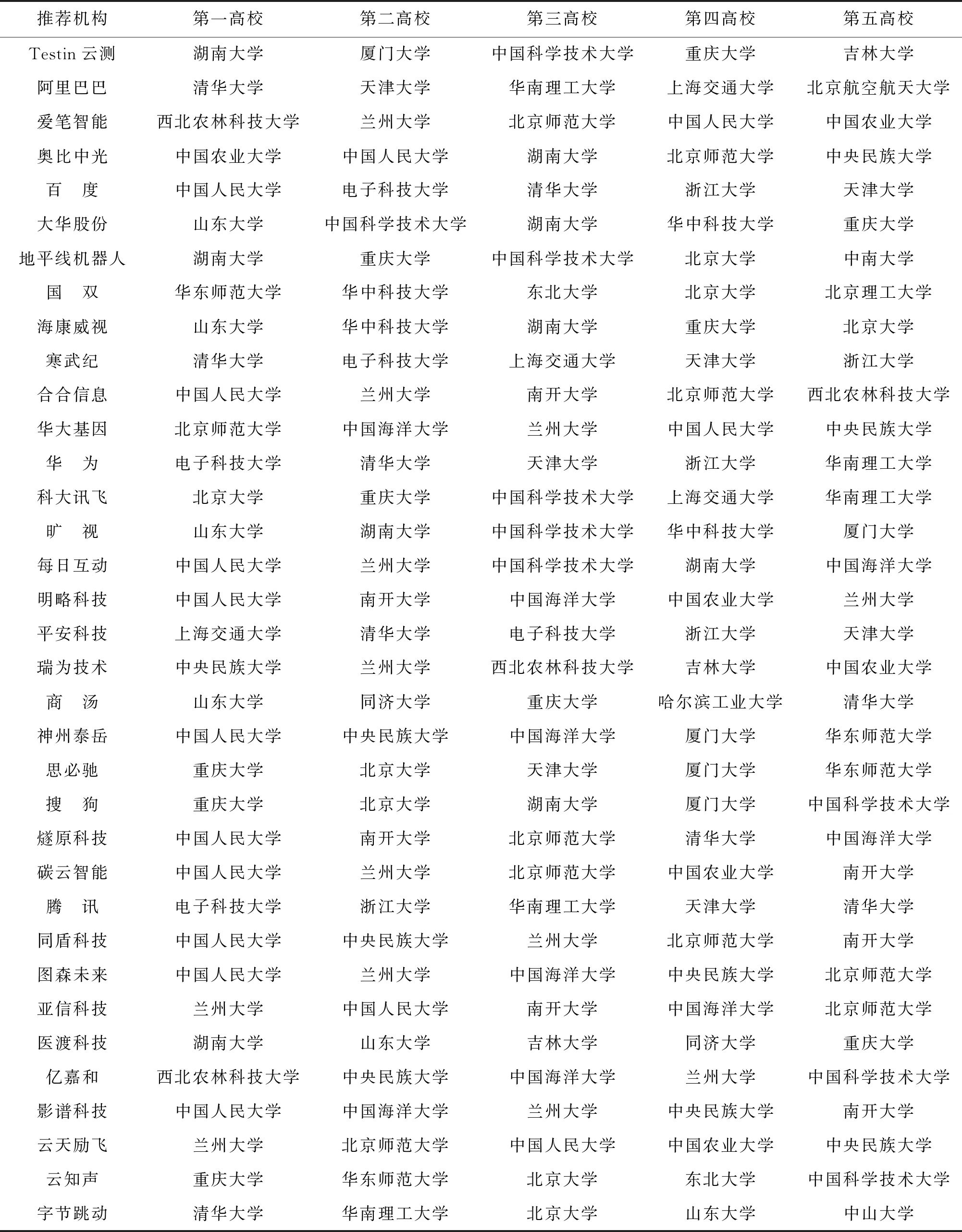
表6 人工智能前50強企業的合作高校推薦結果
4 比較研究與結果分析
4.1 比較研究
由表2可知,騰訊公司同高校的專利合作最多,因此,采用騰訊公司為研究對象作對比分析研究。LDA模型能夠對文本信息中的隱含主題信息進行建模,是當前一種文本表示的常用方法[37],因此,選擇LDA模型同本文構建的模型進行對比分析。LDA模型具體處理過程分三步:首先,將各機構專利和論文的文檔進行分詞、去除停用詞、詞形還原等處理;其次,基于預處理的數據訓練LDA模型,主題數K從10開始取值,步長為5,最大取值到200,經過嘗試,發現主題—困惑度曲線在K為10~115之間時較為陡峭,115之后趨于平緩。所以本文最終確定主題數為115。其他參數方面,Alpha設置為0.43(即50/K=50/115≈0.43),Beta參數設為0.01。通過具體實驗,發現迭代500次左右,模型困惑度不再明顯下降,獲得最終的LDA主題模型;最后,通過LDA模型,每條文本被表示為115維的主題向量,各維數之和為1。由于一個機構可能有多個文檔,本文采用向量平均化的方式來對不同機構的專利文本主題向量進行表示,之后,通過余弦相似度來計算各機構的主題相似性。比較研究的具體結果如表7所示。
首先,本文構建模型得出騰訊公司和高校之間的相似度在3.60%~9.55%之間,LDA模型得出的相似度范圍為41.02%~64.68%,本文構建模型得出的企校機構間的相似度遠遠小于LDA模型的結果,相對比較符合實際情況;其次,由于騰訊公司合作的高校有11所,按照兩種模型進行合作高校前20推薦,由表7可知,本文模型得出的機構未合作比例為65%,LDA模型得出的未合作比例為55%,本文構建模型得到的機構合作促進空間稍大于LDA模型。因此,本文構建的模型取得的結果較好。
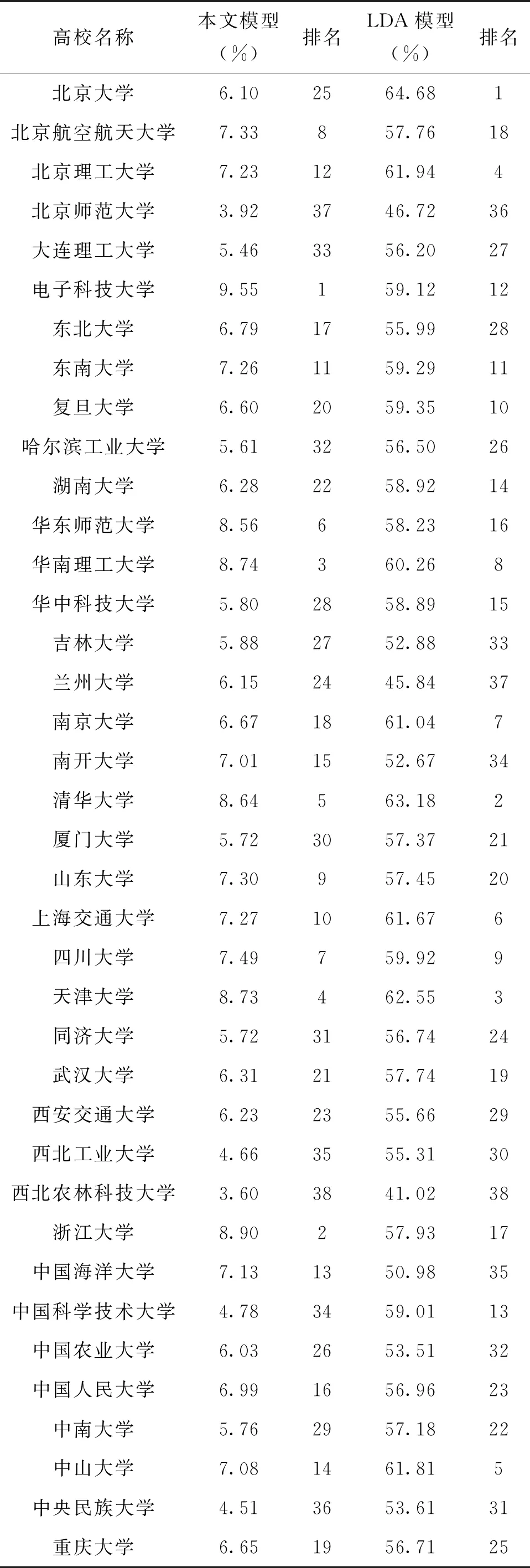
表7 騰訊公司同國內高校機構間的相似度
4.2 結果分析
表2中共有6個企業同高校存在著人工智能領域的專利合作關系。本模型為除騰訊公司外的5個企業推薦的高校名單中,已經存在合作和未合作的情況如表8所示。

表8 5個企業和高校機構間已合作和未合作的情況
整體分析,5個企業同高校的已合作比例為16%,未合作比例為84%,未合作的比例遠遠大于已合作比例,因此,對促進企校機構之間進行人工智能領域的合作空間比較大。5個企業中,華為和科大訊飛公司的推薦結果都包含了部分的或者全部的合作高校。其他的3所機構中,Testin云測、湖南大學兩個機構都比較關注圖像處理方面的研究;思必馳公司和重慶大學更加關注人工智能在新事物的識別中的作用;醫渡科技公司主要為醫療行業參與者提供數據分析和決策支持等服務,中國海洋大學申請的專利和發表的論文中包含基于深度學習的冠狀病毒患者行為跟蹤裝置,并且還有對醫療電子裝置等的研究。推動這兩個機構合作,有助于醫學研究,也有利于實現智能化疾病管理。再以華為公司為例,本模型為華為公司推薦的5所高校中,華為同第一高校(電子科技大學)和第二高校(清華大學)在人工智能領域內已經存在合作關系,同其他3所高校在人工智能領域暫時沒有合作,但是華為公司已經分別在2020年12月、2021年1月、2020年11月和天津大學、浙江大學、華南理工大學簽訂了產教融合等協同育人協議,相信它們之間在人工智能領域的合作指日可待。
5 結 語
本文構建了一種融合專利與論文信息的內容挖掘和引用基礎兩個方面的企校創新合作機構推薦模型,并進行了比較研究和結果分析。結果表明,本文構建的企校合作推薦模型效果較好,能夠實現為企業進行針對性尋找高校合作伙伴的目標。本模型的構建對于當前企校合作的相關研究具有一定的促進作用,企業可根據自身的發展情況以及戰略目標,明確合作技術主題,尋找特定領域的最佳合作高校,借助高校科研優勢,達到在市場中取得一定競爭優勢的目的。
雖然本研究為我國人工智能領域的企校機構合作提供借鑒,但只選擇了國際專利和論文,在后續的研究和應用中,可擴大檢索范圍,從而為我國人工智能領域的發展提供更多參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
云南畫報(2020年9期)2020-10-27 02:03:26
數學物理學報(2020年2期)2020-06-02 11:29:24
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
