聯(lián)合注意力算法對人工智能圖像識別卷積的優(yōu)化作用研究
2023-03-27 06:47:31王巍
電腦迷 2023年24期
關(guān)鍵詞:人工智能
王巍

【摘? 要】 人工智能圖像識別系統(tǒng)多采用卷積神經(jīng)網(wǎng)絡(luò)作為算法基礎(chǔ),利用注意力算法對卷積神經(jīng)網(wǎng)絡(luò)進行優(yōu)化,能夠?qū)崿F(xiàn)更為精準的特征提取,從而達到降低訓(xùn)練成本、提高識別準確率的根本目的。文章以此為研究目標,對聯(lián)合注意力算法下的卷積神經(jīng)網(wǎng)絡(luò)優(yōu)化與具體的參數(shù)計算方式進行詳細闡述,并通過訓(xùn)練實驗的方式對聯(lián)合注意力算法的識別有效性進行評價,發(fā)現(xiàn)該算法在圖像智能識別中具有較大的應(yīng)用價值。
【關(guān)鍵詞】 注意力算法;人工智能;圖像識別
一、聯(lián)合注意力算法卷積模型優(yōu)化
卷積神經(jīng)網(wǎng)絡(luò)是進行圖像識別的核心算法之一。該算法通過構(gòu)建卷積層與激活層的方式對圖像特征進行提取,并在池化后對未知圖像進行識別,同時利用識別數(shù)據(jù)對算法進行迭代。卷積神經(jīng)網(wǎng)絡(luò)的計算量相對較大,且特征提取屬于“算法黑箱”。在此背景下,引入注意力算法能夠降低特征點的識別維度,從而達到降低計算量、提高精準度的有效目的。
(一)卷積神經(jīng)網(wǎng)絡(luò)的圖像識別
注意力算法主要是指在卷積神經(jīng)網(wǎng)絡(luò)中引入特定的參數(shù)函數(shù),對卷積層中的特定像素集群進行再次“微池”化,將分散的像素整合為像素集合,進行集體分析,從而實現(xiàn)降低計算量的根本目的。如圖1所示,利用“運動”作為構(gòu)建DL(數(shù)據(jù)微池)的方式可以將視頻圖像中的物體運動特征進行整合提取,從而形成可視化熱力圖。
如圖1所示,在視頻圖像識別中,其目的在于對機場中物體的運動情況及軌跡進行識別。在此要求下,傳統(tǒng)卷積神經(jīng)網(wǎng)絡(luò)需要對圖像中的全部像素進行分析。而引入“運動”的注意力參數(shù),能夠?qū)⑦\動的擬合度作為特定特征點進行固定提取,從而形成可視化熱力圖如圖1(b),僅需要對熱力集中在“0.75~1”范圍內(nèi)的微池像素進行卷積分析便可以實現(xiàn)相同功能。根據(jù)理論推演,在引入注意力算法的情況下,原有圖像分析系統(tǒng)的計算量能夠下降90%,對提高識別效率、降低系統(tǒng)能耗與軟硬件需求具有重大的現(xiàn)實意義。類似的應(yīng)用可以在多種場景下得到應(yīng)用,如人臉識別、身份證識別、文字提取等。通過人工限定特定,形成池化數(shù)據(jù)的圖像識別需求均可以通過聯(lián)合注意力算法的方式對其卷積神經(jīng)網(wǎng)絡(luò)進行優(yōu)化。
(二)聯(lián)合注意力模塊應(yīng)用
在注意力算法對卷積神經(jīng)網(wǎng)絡(luò)的優(yōu)化過程分析中不難發(fā)現(xiàn),注意力算法的功能機制在圖像的特征提取過程中發(fā)揮實效。即通過在卷積神經(jīng)網(wǎng)絡(luò)中的激活層中以注意力算法替代原有的像素求解,從而實現(xiàn)對計算量降低的根本目的。為此,在利用注意力算法對卷積神經(jīng)網(wǎng)絡(luò)進行優(yōu)化時,應(yīng)該假設(shè)其在輸入特征圖到輸出特征圖之間。通過注意力算法獲得的輸出特征圖作為后續(xù)卷積神經(jīng)網(wǎng)絡(luò)的分析依據(jù),經(jīng)過激活層、池化等操作,完成后續(xù)的圖像識別與分析,具體的聯(lián)合模式與流程如圖2所示。
如圖2所示,注意力模塊在輸入特征圖與輸出特征圖區(qū)間,作為傳統(tǒng)卷積神經(jīng)網(wǎng)絡(luò)像素計算特征提取的替代性工具。按照能夠人工設(shè)定的注意力算法特征特性,其大致可以分為通道注意力模塊和空間注意力模塊。兩種模塊的主要區(qū)別在于人工設(shè)定特征點的屬性差異。前者以運動為基礎(chǔ),如對運動軌跡識別、動作識別、表情識別等;后者則多以物體為單位如對特定幾何形狀識別、文字識別等。
二、聯(lián)合注意力算法在圖像識別中的應(yīng)用
(一)聯(lián)合模型與總體架構(gòu)設(shè)計
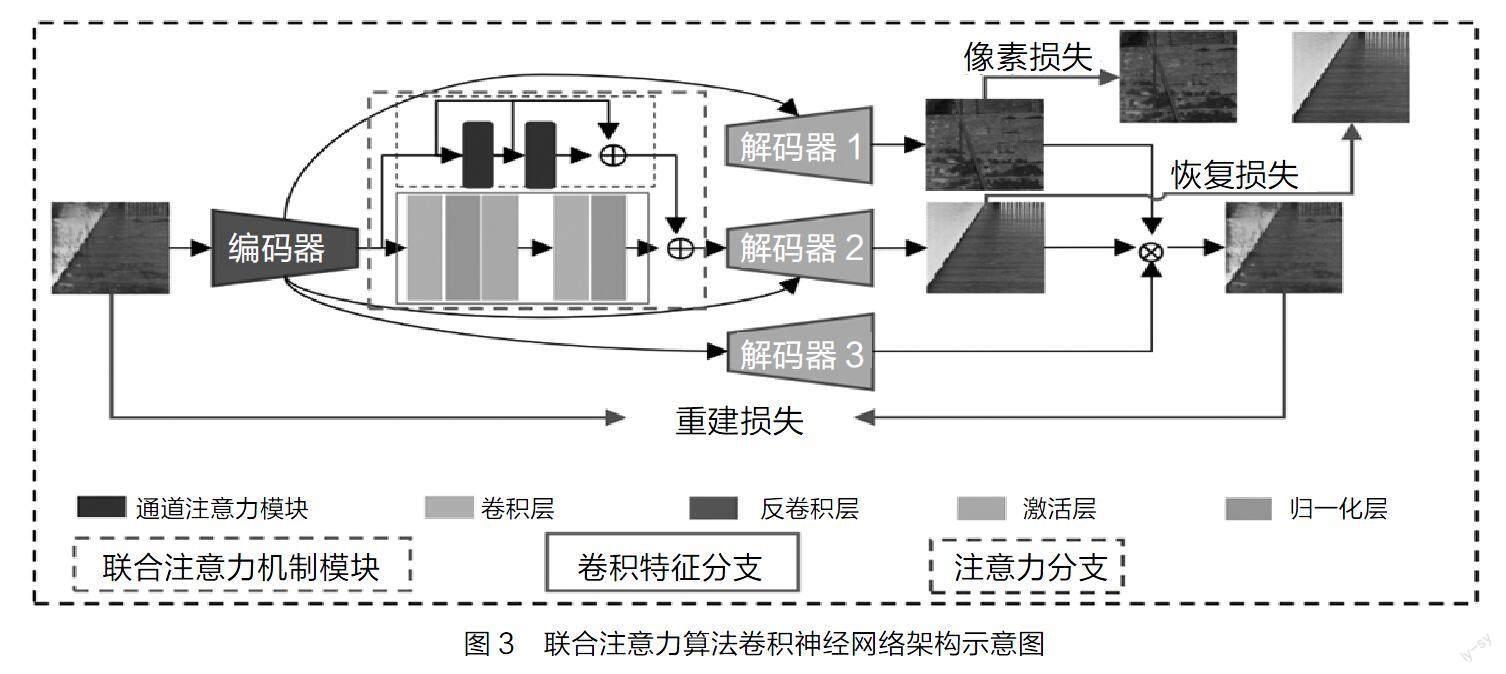
注意力模塊需要在圖像識別的池化過程之間發(fā)揮效能,需要整合入卷積神經(jīng)網(wǎng)絡(luò)系統(tǒng)內(nèi)提供額外的特征信息,幫助模型進行更為精準與高效的圖像識別。基于這一目標以及具體的應(yīng)用流程,優(yōu)化后模型的總體架構(gòu)如圖3所示,主要分為三個部分:
1. 輸入部分。包括原始圖像和編碼器兩個部分,該過程的核心任務(wù)是將目標圖片進行像素分解,為后續(xù)的訓(xùn)練與識別提供數(shù)據(jù)素材;
2. 注意力聯(lián)合部分。包括通道注意力模塊、卷積層、激活層和歸一化層等。該部分為注意力模塊的優(yōu)化核心,通過編碼器分解的像素數(shù)據(jù),在注意力模塊的作用下形成池化數(shù)據(jù)的雙通道結(jié)構(gòu),既當數(shù)據(jù)類別符合注意力特征閾值后則進入卷積層成為特征確定的標準之一,如不符合則按照傳統(tǒng)卷積神經(jīng)網(wǎng)絡(luò)進行識別分析;
3. 解碼與輸出部分。主要包括解碼器和損失檢測等部分。該部分的主要作用在于將卷積神經(jīng)網(wǎng)絡(luò)構(gòu)建的輸出結(jié)果進行解碼,同時對其可能產(chǎn)生的像素損失和重建損失進行修正回復(fù),最終輸出識別結(jié)果。
(二)編碼器的設(shè)計
編碼器需要將圖像信息轉(zhuǎn)變?yōu)榭晒┳⒁饬λ惴ㄗR別的像素信息,在模型設(shè)計中至關(guān)重要。模型主要通過反射圖像混合模型的方式方法對編碼器進行構(gòu)建,并對圖像的像素信息進行求解,具體模型公式如下:
I=M×T+(1-M)×(K×R)(公式1)
其中,I表示具有反射混合特征的圖像信息;R表示圖像反射層;T表示傳輸層;K表示反射模糊核;M表示反射混合約束矩陣。利用公式1可以對現(xiàn)有圖像進行矩陣切割,并提取其中的關(guān)鍵核心像素信息點,將照片的圖像信息轉(zhuǎn)變?yōu)槟P湍軌蜃R別的數(shù)值數(shù)據(jù)。
(三)損失函數(shù)的計算
通過編碼器的像素分解,在獲得可供分析的數(shù)據(jù)基礎(chǔ)上也必然會帶來數(shù)據(jù)細節(jié)的丟失,這就需要引入損失函數(shù)對其結(jié)果進行修正。損失函數(shù)的核心是對像素分析中的偏差丟失進行修正,其中包括像素損失、恢復(fù)損失和重建損失等三個主要要素。按照不同要素進行分類,其函數(shù)如圖3所示:
Lpixel=R∈MN(R,M)Lres=R∈M{(R,M)+N[G(R),G(M)]}Lrecon=I∈MN(R-I) (公式2)
其中,Lpixel表示像素損失修正;Lres表示恢復(fù)損失;Lrecon表示重建損失;R為真實圖像;M表示反射圖層;N表示預(yù)期損失系數(shù);G表示圖像梯度;I表示重建圖像。公式2可以在算法求解過程中對分析前后的像素特征損失系數(shù)進行求解,并通過迭代優(yōu)化的過程將公式2中的求解數(shù)字整合到公式1中,形成修正后的像素特征,具體表示為I修正=I+Lpixel表+Lres+Lrecon,當?shù)蠭修正近視等于I時迭代結(jié)束,系統(tǒng)完成自我修正,并可以將損失函數(shù)結(jié)果帶入后續(xù)識別中進行直接應(yīng)用。
三、聯(lián)合注意力算法模型效果分析
(一)實驗條件
利用注意力算法進行優(yōu)化的圖像智能識別系統(tǒng)本質(zhì)上依然是基于卷積神經(jīng)網(wǎng)絡(luò)構(gòu)建的一套具有迭代功能的智能體系。在實際應(yīng)用過程中,應(yīng)該通過具有標記作用的圖片進行“喂養(yǎng)”后方可形成有效識別效能。為進一步分析注意力算法的實際應(yīng)用效能,文章采用對比實驗的方式對其進行驗證,具體過程與環(huán)境設(shè)定分為如下幾個方面:1. 收集各類型圖片按照識別類別分為通道類和空間類,各類別集合內(nèi)圖片為10000張;2. 通過編號后隨機挑選的方式分為訓(xùn)練集和測試集,比例為19∶1;3. 以雙通道GTX4080Ti為GPU處理核心,在Ubuntu12.0系統(tǒng)上部署智能識別系統(tǒng),并連通輸入設(shè)備與結(jié)果輸出設(shè)備;4. 在平臺內(nèi)分別部署兩套算法系統(tǒng),分別為實驗?zāi)P秃蛯Ρ饶P停渲袑嶒災(zāi)P蜑樽⒁饬λ惴▋?yōu)化后的卷積神經(jīng)網(wǎng)絡(luò)模型,對比模型則為原始卷積神經(jīng)網(wǎng)絡(luò)模型。
(二)實驗結(jié)果分析
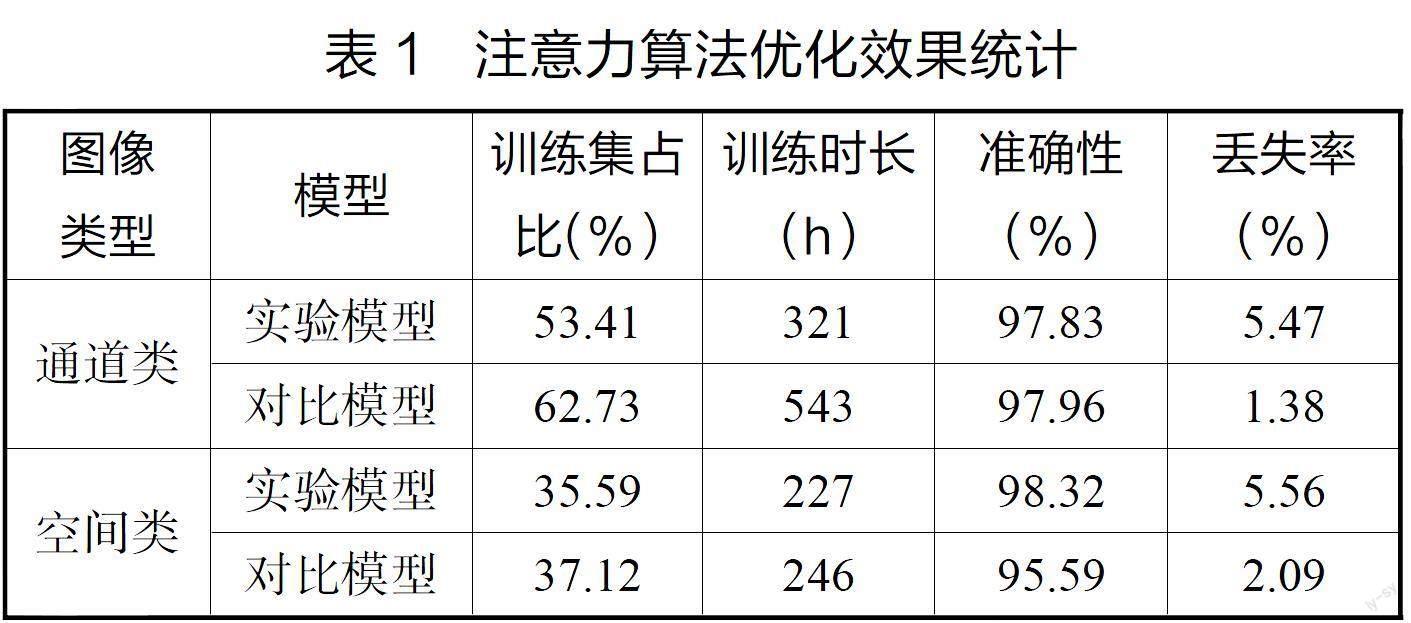
為驗證注意力算法對卷積神經(jīng)網(wǎng)絡(luò)模型優(yōu)化的有效性,通過開展對比實驗的方式對其進行分析。具體指標包括了2個維度的4項指標。其中,訓(xùn)練效率指標包括95%識別度訓(xùn)練集占比(%)、訓(xùn)練時長(h);準確性維度包括了識別準確性(%)、細節(jié)丟失率(%),實驗結(jié)果如表1所示。
由表1可知,通過注意力算法的優(yōu)化,模型在訓(xùn)練效率以及識別準確性方面均有不同程度提高。在同樣以95%訓(xùn)練穩(wěn)定度的條件下,通道類實驗?zāi)P陀?xùn)練穩(wěn)定時需使用訓(xùn)練集圖片總量的53.41%,遠低于對比模型使用量(62.73%)。同時,實驗?zāi)P驮谕ǖ李悎D片中的訓(xùn)練效率明顯低于空間類圖片,但兩種模型在空間類的訓(xùn)練效率中并無明顯差異,這說明兩種模型對空間類圖片的訓(xùn)練效率均相對較高,但注意力算法優(yōu)化對通道類圖像的識別應(yīng)用效果更佳。在訓(xùn)練時長上也表現(xiàn)出相同的數(shù)據(jù)規(guī)律,形成了交叉認證。
在準確性方面,通道類圖片條件下,二者準確率均超過了97%,符合應(yīng)用的基本要求,且沒有明顯差異,說明通過注意力算法優(yōu)化后的卷積神經(jīng)網(wǎng)絡(luò)對傳統(tǒng)模型具有較高的替代效果。但在空間類圖像的識別中,實驗?zāi)P偷臏蚀_率顯著高于對比模型,說明注意力算法在空間類圖像識別中更具有比較性優(yōu)勢。
除此之外,通過表1數(shù)據(jù)能夠發(fā)現(xiàn),在利用實驗?zāi)P瓦M行圖像識別時會丟失更多的細節(jié)數(shù)據(jù),這一問題主要是由于系統(tǒng)整合了除霧模塊,該模塊通過模糊處置圖層的前置信息,從而會造成一定的數(shù)據(jù)細節(jié)丟失,但對識別結(jié)果不造成顯著影響。
參考文獻:
[1] 陳杭,張兆江,劉闊,等. 聯(lián)合注意力機制與多級特征融合的街景全景分割算法研究[J]. 測繪與空間地理信息,2023,46(09):43-47.
[2] 蘇明,艾海明,馬琳,等. 基于AI的圖像識別乘駕安全監(jiān)測系統(tǒng)研制[J]. 傳感器與微系統(tǒng),2023,42(08):85-87+91.
[3] 王瑤涵,宋澤陽,張利冬. 基于卷積神經(jīng)網(wǎng)絡(luò)的安全標識分類算法研究[J]. 中國安全科學(xué)學(xué)報,2023,33(S1):263-269.
猜你喜歡
西安航空學(xué)院學(xué)報(2022年2期)2022-07-04 07:45:42
汽車零部件(2020年3期)2020-03-27 05:30:20
表面工程與再制造(2019年1期)2019-05-11 08:52:04
商界(2019年12期)2019-01-03 06:59:05
家庭影院技術(shù)(2018年9期)2018-11-02 05:31:34
IT經(jīng)理世界(2018年20期)2018-10-24 02:38:24
通信電源技術(shù)(2018年3期)2018-06-26 06:33:30
軍營文化天地(2018年1期)2018-02-10 05:19:25
小康(2017年16期)2017-06-07 09:00:59
學(xué)與玩(2017年12期)2017-02-16 06:51:12
