流式計算引擎中密集滑動窗口的性能優化研究
2023-04-07 05:43:41程盛陽
軟件工程 2023年4期
關鍵詞:大數據
關鍵詞:大數據;流式計算;窗口計算;Flink
中圖分類號:TP316.4 文獻標識碼:A
1引言(Introduction)
在大數據技術發展早期,批處理技術應用廣泛,如阿帕奇軟件基金會開發的Hadoop MapReduce框架、加州大學伯克利分校開發的Spark框架等,取得了令人矚目的成果[1];但隨著業務要求的不斷提高,離線計算高延遲的弊端逐漸暴露,流式計算引擎應運而生,包括最早由推特公司開發的Storm框架、Spark框架的流計算擴展Spark Streaming、谷歌公司開發的Google Dataflow框架、最早由柏林工業大學開發的Flink框架等[2],它們能在數據連續到達的同時進行實時計算,被廣泛應用在對時間性要求很高的場景中。流式計算的數據源沒有邊界,由計算引擎負責確定窗口范圍,但在如“雙11”網購促銷日、春運搶票等高負載應用中,原生窗口的性能常無法滿足實際應用需要[3]。分析原因,一是這些框架采用的全量創建窗口的方式難以支持毫秒級的刷新頻率,生成的窗口數量巨大;二是交易數據流存在非均勻性,為及時計算活躍用戶的數據,窗口必須密集,但也會導致系統為低活躍的用戶構造大量的重復窗口,造成資源浪費。
本文以由阿帕奇軟件基金會孵化的Apache Flink計算引擎為例,分析其窗口機制性能缺陷的根源。之后提出一種優化密集滑動窗口的方案,能減少系統需要構造的窗口數量,并通過計算比較兩種方案,闡明優化方案的有效性。
2原生窗口機制及其問題(The native windowmechanism and its problems)
2.1原生窗口機制
流式計算中的數據源不斷產生數據形成流,需要由窗口劃定一段時間范圍的計算結果。例如,一個商務平臺中對每個商戶的交易進行1 min的統計,每500 ms更新一次計算結果,生成一個滑動窗口,則1 min為滑動窗口的長度(size),500 ms為此窗口的步長(slide),商戶號為此窗口的聚合鍵(key)。
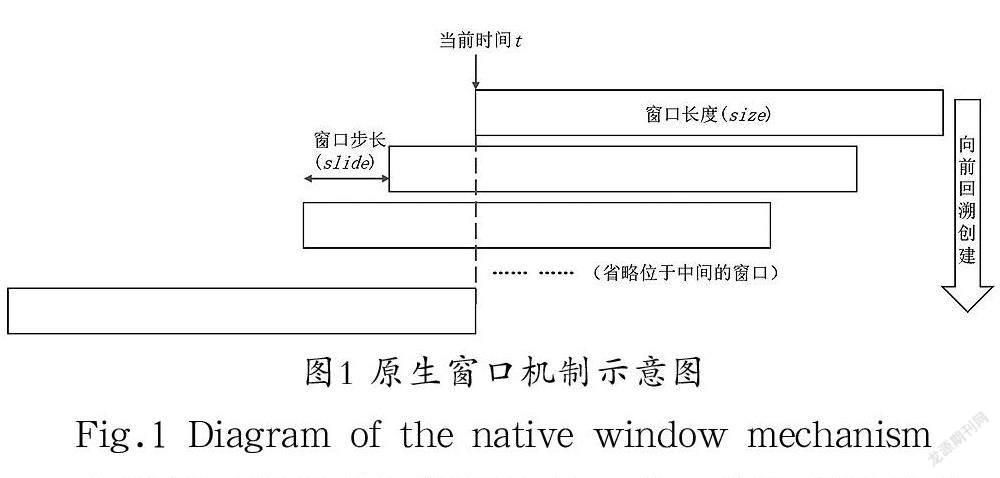
在理想情況下,流處理引擎應該為每個key預先分配好滑動窗口,這樣在有數據到達時,數據就可以直接落到對應的窗口中,但實際上流式計算框架普遍采用懶構造方式[4],這種方式為了節省資源是不會為還未出現的key預先分配窗口的,只有當一個key有對應數據到達后才會創建,然后向前追溯,補充生成之前由于懶策略而跳過的所有窗口。圖1展示了Flink計算滑動窗口的創建過程:數據在t時刻到達后,除了創建從t到t+size范圍的窗口,還通過循環不斷向前補充創建需要追溯的滑動窗口。
在后續不斷有新數據抵達時,窗口構建策略依然不變,繼續循環和向前追溯。此外,Flink會將準備創建的新窗口和已有的窗口進行比較,合并相同的窗口,這在Flink源代碼中streaming.runtime模塊的WindowOperator類的processElement方法中實現。
2.2滑窗機制存在的問題
首先是數據傾斜帶來的問題,在流式系統中的數據源是非均勻性的,在相同時間內,不同key產生的數據量級存在顯著的差異,或者對于同一個key,其數據產生頻率在不同時間段存在顯著的差異。對于頻繁更新的key,為了保證數據的及時性,必須使用較小的步長,滿足熱點key的刷新頻率要求,導致系統不得不為稀疏key也配置同樣的窗口創建策略,而這些窗口內部大部分都保存了相同的狀態、具有相同的輸出,實際上是多余的,造成內存資源的浪費。
其次是實時性問題,在很多系統中,響應時間是評估系統能力的硬指標,例如對于風險監控系統,風險行為越早被檢測到,被攔截或挽回損失的可能性就越大。流式計算引擎的窗口刷新頻率決定了一個風險行為從發生到體現在計算結果的延遲時間。假設窗口計算的步長是10 min,那么無論將系統處理和數據傳輸的延遲壓縮到多低,在最壞情況下,一個風險事件也要在10 min后才從窗口統計中被輸出。在這個時間差之內,系統無法感知到風險的發生,也無法及時響應。因此,理想情況下,毫秒級的窗口步長是最佳的,但根據窗口的定義方式,對每個新key所需要創建窗口的個數=窗口長度/窗口步長,當窗口長度達到小時甚至天數時,維持毫秒級的步長會導致窗口數量巨大,如果實際系統中有百萬級以上數量的key,就會帶來大型分布式計算架構也難以承擔的負載。
同時,密集的多余窗口在創建和銷毀時的高并發會導致CPU占用過高和I/O負載高,這使得高頻(毫秒級延遲)的窗口很難用原生窗口實現,因為在下一輪窗口創建時,上一輪窗口產生的CPU占用和I/O負載可能還未被完全消化,導致系統性能雪崩問題[5]。
3現有優化及其不足(Existing optimization and itsdeficiencies)
3.1 ProcessFunction優化方法
應用層目前使用處理函數(ProcessFunction)替代傳統窗口是一種常用的優化方法,它本質上是應用一個流處理函數,在其中定義對每條上游數據的獨立處理邏輯[ 6 ]。
ProcessFunction對一個key只構造一個實例,接受與保存新到達的數據,不斷地對過期的舊數據進行清理。以Flink為例,其提供了MapState類用于保存ProcessFunction的狀態,之后可以調用windowState.put()方法向其中添加和更新狀態。這樣就可以將ProcessFunction當作一個窗口,雖然此優化避免了窗口冗余,但是要求在函數內部保存原始數據,因此削弱了優化效果。此外,如果Flink上游數據更新非常快,而ProcessFunction沒有滑窗策略的頻率控制的步長,下游的I/O負載壓力會顯著增大。
3.2采用分桶策略的ProcessFunction優化
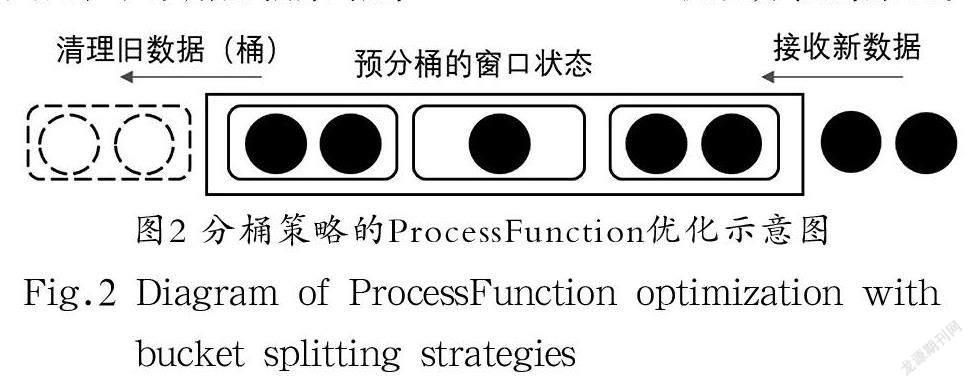
為了減少ProcessFunction優化方法中保存原始數據過多消耗的內存空間,可以在犧牲一定精度的情況下采用分桶策略,在新數據到達時進行部分聚合。例如,對一個長度為10 min的窗口,每分鐘分為一桶,這樣窗口中只需要存10 份子狀態,每分鐘清理一個桶即可,不再需要保存原始數據。圖2展示了采用分桶策略的ProcessFunction優化方法的原理。
此優化方法雖然在一定程度上解決了內存問題,但同時限制了計算的粒度,如果分桶的間隔過小(例如毫秒級分桶),就難以達到優化效果,甚至因加入了額外的邏輯而進一步加重了系統的負擔。擴大分桶的間隔相當于放大了滑動窗口的步長,雖然能夠起到優化內存占用的效果,但是無法滿足上文所述的對于高刷新頻率的需求。
綜上所述,應用層的常用優化方法雖然能夠在一定程度上減少窗口冗余、降低一定的內存負載,但其優化策略均存在一定的副作用,難以滿足非均勻數據源、高窗口刷新率場景的應用要求。除此以外,使用這些優化方法不僅要求重新編碼實現計算邏輯,還必須手動維護和清理狀態,這與直接使用引擎提供的窗口功能相比,額外增加了開發工作量。
4基于關鍵窗口機制的優化(Optimization basedon key-window mechanism)
為解決非均勻數據源中稀疏key導致的狀態內存資源浪費及CPU占用高和I/O負載高的問題,本文提出一種基于關鍵窗口機制的窗口實現優化方案,即在不影響計算結果正確性的情況下,流處理引擎只進行真正組成計算結果的關鍵窗口的創建,省略多余的原生窗口,從而較少了內部窗口數量,優化了系統性能。
4.1關鍵窗口的定義
如上文所述,流式處理引擎的原生窗口機制的問題根源在于,為稀疏key構造了大量的內部狀態和輸出都相同的冗余窗口。為了從根本上優化系統性能,就需要設計一種方法使得系統跳過對多余窗口的創建。在排除冗余窗口之后,剩下的窗口就是關鍵窗口。
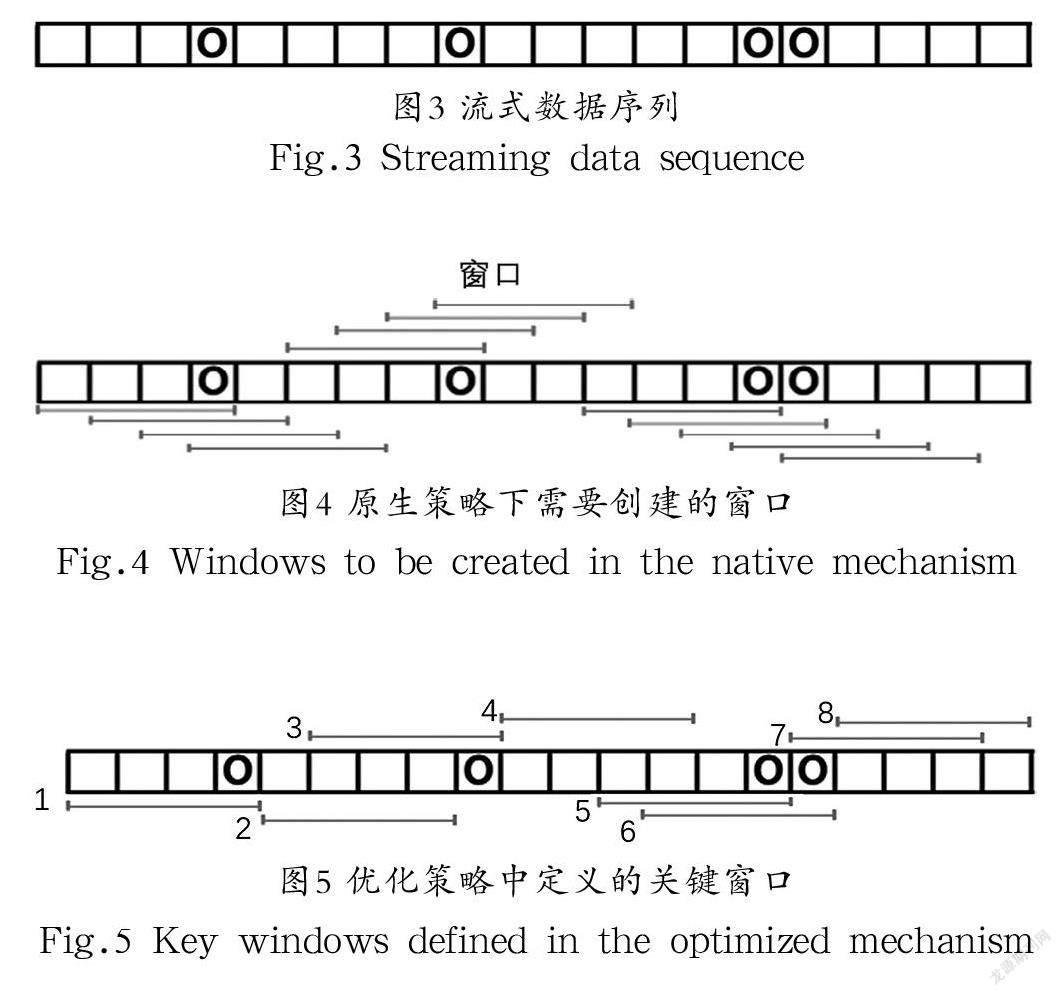
具體可以將“關鍵窗口”定義為所有窗口中那些輸出能使得計算結果實際產生變化的窗口。例如,對于圖3中的數據序列,每個方格表示一個時間單位,方格中的圓形符號表示該時間單位內上游系統向流計算引擎發送了數據。
在本研究中,采用長度為4 個單位時間、步長為1 個單位時間的滑動窗口進行統計,如果采用原生的窗口邏輯,則需要創建的窗口如圖4所示,圖中數據流上下方的每個線段表示一個窗口,共有13個。
對同樣的數據源若采用優化的策略,根據上文對“關鍵窗口”的定義,需要創建的關鍵窗口如圖5所示,共有8個。這些關鍵窗口分別對應了各個計算結果發生變化的時間節點:“1”表示首個數據點進入統計,“2”表示首個數據點離開統計,“3”表示第二個數據點進入統計,“4”表示第二個數據點離開統計,“5”表示第三個數據點進入統計,“6”表示第四個數據點進入統計,“7”表示第三個數據點離開統計,“8”表示第四個數據點離開統計。
在本研究中,關鍵窗口的數量比默認窗口少5 個,而隨著窗口長度越長、窗口步長越短,以及數據源的不均勻程度越高,關鍵窗口和原生窗口相比,在數量上的優勢就會越發明顯。
4.2關鍵窗口優化方案的實現
本文提出的關鍵窗口優化方案,不需要推倒現有的流計算框架從零設計新系統,而是可以通過對現有的流計算引擎進行適當的改造,使其支持關鍵窗口的創建和計算。這樣能充分利用成熟引擎在功能和穩定性上的諸多優勢,使優化方案低成本地投入工程應用。
改造現有流計算引擎實現關鍵窗口,關鍵在于使關鍵窗口的創建和計算都基于原生的方法實現,不增加額外的方法和狀態存儲。以Flink為例,其原生的窗口機制是基于Accumulator(也稱Aggregate Function,聚合函數)的方式實現的[7],這要求在僅利用窗口的add()、merge()和getResult()方法的前提下,完成對所有關鍵窗口的生成和計算,而不需要借助額外的Evictor(即刪除元素的方法)或其他的狀態管理手段:不使用Evictor,是因為指定Evictor之后,會使得窗口不再進行預聚合,實際上導致系統喪失了有狀態計算的優勢;而借助其他底層狀態管理函數,如ProcessFunction,則會丟失窗口的語義性,使其和更高抽象的API(如SQL API)的兼容出現問題[8]。
基于上述前提,本文提出的關鍵窗口實現方案如下。
將關鍵窗口分為左關鍵窗口和右關鍵窗口,關鍵窗口定義示意圖如圖6所示。左關鍵窗口是有數據進入而使得計算結果發生改變的窗口,右關鍵窗口是有數據離開而使得計算結果發生改變的窗口。
對窗口創建邏輯的改變不影響數據進入窗口后的計算方式,需要相應改變的是窗口狀態的初始化方法:在傳統的窗口機制中,窗口的創建是時間驅動的,窗口按照步長逐個創建,新數據到達時,它所屬于的所有窗口在邏輯上已經處于預備的狀態,在等待這個新數據;而在關鍵窗口機制中,窗口的創建是數據驅動的,所有窗口均是隨著相對應的某個數據點的到達而創建的。因此,在新數據到達時,它一方面會落入此前已經創建好的窗口,另一方面同時需要創建其自身所對應的關鍵窗口。
右關鍵窗口反映的是這個數據點失效而使計算結果發生的變化。因為在創建時,當前數據點是最新的,其后的數據還未到來,所以為了表示當前數據點失效而產生的變化,直接創建一個空窗口即可。
左關鍵窗口反映的是這個數據點加入統計后使得計算結果發生的變化。左關鍵窗口在創建時需要繼承此前的歷史狀態。根據對“關鍵窗口”的定義,系統會在有數據點進入和失效的關鍵時間位置創建窗口,而系統的統計結果是完全由窗口輸出的。因此,當一個新數據點抵達時,必然能夠找到一個已經存在的窗口,其中保存的狀態正是新窗口需要繼承的歷史狀態。最簡單的一種情況是,在前一個窗口時間內,沒有其他數據抵達,即無歷史狀態可以繼承,這種情況下直接創建空窗口即可。如果在前一個窗口時間內存在數據點,就要將當前的數據合并到最新的歷史狀態中,即取到系統輸出的前一個統計結果,再將新數據加入計算。在流計算引擎中,窗口管理器只記錄各個窗口起始和結束的位置信息[9],它無法直接感知到系統的前一個統計結果是什么,或者是由哪個窗口觸發的,因此需要通過判斷窗口位置的確定從哪個窗口繼承歷史狀態信息。
具體策略如下:當新數據到達時,如上文所述,首先創建一個空的右關鍵窗口;然后確定此數據對應的左關鍵窗口的位置;檢查即將創建的左關鍵窗口和此前存在的左關鍵窗口是否存在重合;若無重合,直接創建此窗口;若有重合,檢查即將創建的左關鍵窗口與最近一個左關鍵窗口的非重疊部分是否包含數據(即其中是否存在右關鍵窗口的起點);若沒有這樣的右關鍵窗口,調用merge()方法,合并最接近的一個左關鍵窗口;若存在這樣的右關鍵窗口,調用merge()方法,合并最新的一個右關鍵窗口。
對下游使用計算結果的系統而言,采用關鍵窗口后,下游系統依然能夠感知到所有計算結果的更新,而唯一的區別在于,原生窗口會每隔一個窗口步長的時間就向下游發送一次數據,而關鍵窗口僅在計算結果更新時發送。為了配合優化,下游系統需要對失效時間的利用做簡單的調整。
具體來說,在使用原生窗口時,引擎不會發送某個key統計結果歸零的數據,需要下游系統自行觀察該key的數據不再更新,從而得知該key的最后一個統計結果過期。在使用關鍵窗口優化后,數據過期時會將空窗口的輸出發送給下游,因此下游系統僅需將數據過期時間調整為窗口長度即可,如果下游系統在此數據過期之前收到了新的輸出,則說明有新數據抵達,要對數據過期時間進行重置。因此,改用關鍵窗口后,僅需調整下游系統的數據過期時間即可兼容此優化,不會影響系統本身的功能。
4.3優化效果
設某系統正在使用長度為p s,步長為k s的窗口。對目前的流式計算引擎而言,接收到n 個數據后,需要創建的窗口最大個數為p×n/k個。這是因為每接收到一個數據,系統都需要創建最多p/k個窗口。在引入關鍵窗口優化后,接收到n 個數據后,系統需要創建的窗口數量為2n 個。這是因為關鍵窗口僅體現數據加入統計、失效離開統計的變化,系統每接收到一個數據,只需要創建2 個關鍵窗口。
在實際應用中,p/k幾乎總是大于2的。例如,統計每個用戶在過去120 s內的操作次數,每2 s更新一次統計結果,那么p/k=60。顯然,統計窗口的長度越大、刷新頻率越快時,p/k值也就越大,將遠遠超過2。可見,關鍵窗口優化能夠有效地減少需要的窗口數量。
5結論(Conclusion)
首先,本文分析了目前流式計算引擎在密集窗口情況下在性能方面存在的潛在問題,指出采用原生的窗口策略是導致高負載的原因。其次,說明了現有的優化方法雖然能降低內存消耗,但是存在不足之處。最后,本文提出了基于關鍵窗口的優化方案,通過減少計算中創建的窗口數量,能有效地降低系統在內存和I/O兩方面的性能壓力。目前,本優化方案是基于系統時間的,若要推廣到使用事件時間的應用,未來可以進一步優化對數據流水位線等機制的兼容。
作者簡介:
程盛陽(1996-),男,碩士,助理工程師.研究領域:計算機應用.
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
