基于CBAM-DDcGAN的鋅渣紅外與可見光圖像融合
2023-06-07 00:17:48秦浩,熊凌,陳琳
武漢科技大學學報 2023年3期
秦 浩,熊 凌,陳 琳
(1.武漢科技大學冶金自動化與檢測技術教育部工程研究中心,湖北 武漢,430081;2.武漢科技大學機器人與智能系統研究院,湖北 武漢,430081)
隨著智能制造技術的發展,熱鍍鋅生產線中撈渣機器人的智能化水平也在不斷提高。鋅渣精確識別是實現智能化撈渣的關鍵,單獨依靠紅外或可見光成像設備無法適應撈渣現場惡劣的工業環境,而紅外與可見光圖像融合是特殊場景下獲得高質量圖像的一種有效手段,融合圖像能夠同時呈現出鋅池液面的熱輻射信息與高分辨率的鋅渣分布細節信息。
紅外與可見光圖像融合的傳統方法主要包括基于多尺度分解的方法、基于稀疏表示的方法和基于混合模型的方法等。隨著視覺顯著性檢測概念的提出,出現了越來越多的相關融合算法。Ma等[1]提出基于視覺顯著圖(visual saliency map, VSM)與加權最小二乘優化(weighted least square,WLS)的紅外與可見光圖像融合方法,利用多尺度分解將輸入的紅外圖像和可見光圖像分為基礎層和細節層,利用視覺顯著圖融合基礎層,利用加權最小二乘優化法融合細節層,再通過多尺度逆變換得到融合圖像。Li等[2]提出一種基于潛在低秩表示(latent low-rank representation, LatLRR)的多級圖像分解方法MDLatLRR,將源圖像分解為低秩部分和顯著部分,采用不同的策略對兩部分分別進行融合,最后通過特征圖重建得到融合圖像。Zhang等[3]提出一種基于紅外特征提取和視覺信息保存的紅外與可見光圖像融合算法。盡管傳統圖像融合方法日趨成熟,但融合規則通常需要人工設計,具有實現難度和較高的計算成本。
近年來,基于深度學習的紅外與可見光圖像融合方法不斷出現。Liu等[4]提出一種基于卷積神經網絡(convolutional neural network, CNN)的紅外與可見光圖像融合方法,利用CNN計算權重高斯金字塔,對源圖像進行拉普拉斯分解,計算各層拉普拉斯系數并進行融合,最后重建得到融合圖像。Zhang等[5]提出一種基于CNN的通用圖像融合框架IFCNN,首先利用兩個卷積層從多張圖片中提取特征,再根據輸入圖像類型選擇適當的規則對特征圖進行融合,最后使用兩個卷積層重構特征圖得到輸出圖像。Xu等[6]提出一種可適用于多種圖像融合任務的端到端的無監督圖像融合網絡模型U2Fusion,用于保護融合圖像與源圖像之間的相似性,解決了基于深度學習的圖像融合任務中真值圖像獲取以及指標設計等問題。Ma等[7]利用生成對抗網絡(generative adversarial network, GAN)的特性,提出FusionGAN圖像融合方法,利用網絡中的生成器提取源圖像信息得到融合圖像,判別器使融合圖像具有更多的可見光信息,通過生成器和判別器的對抗訓練來提升融合圖像質量,避免了手動設計融合規則的缺陷;之后,Ma等[8]又提出基于雙判別器生成對抗網絡的融合方法DDcGAN,同時保留兩種源圖像的信息,進一步提升了圖像融合效果。
在熱鍍鋅實際生產中,鋅液溫度達到600 ℃以上,由于安裝距離的限制,紅外相機捕捉鋅液表面熱輻射信息的能力不足,而可見光圖像又存在光照不均勻、部分區域被遮擋等問題。傳統紅外與可見光圖像融合算法通常采用固定的模型提取圖像特征,大都針對公共數據集設計融合規則。鋅渣圖像集目標與背景區域相似度較高,源圖像中缺少明顯的識別目標,與公共數據集的差異較大,故采用傳統算法時圖像融合效果一般。利用卷積神經網絡實現紅外與可見光圖像端到端的融合,在充分提取圖像特征的同時,既能減少圖像融合過程中的計算量,又能避免融合規則的設計。
考慮到熱鍍鋅生產線中的鋅渣紅外與可見光圖像的特殊性,本文提出一種結合卷積注意力機制模塊(convolutional block attention module, CBAM)[9]與雙判別器生成對抗網絡的鋅渣圖像融合方法(記為CBAM-DDcGAN)。CBAM-DDcGAN網絡包含一個生成器和兩個判別器,將紅外與可見光圖像輸入生成器得到融合圖像,通過判別器和生成器的對抗訓練來更新生成器的參數,從而獲得更多的源圖像信息,而且生成器的內部卷積層采用密集連接方式,以最大程度地保留提取到的源圖像特征;同時,將CBAM引入GAN中,增強不同模態的圖像像素與全局依賴關系的表達,對全局特征和局部特征賦予不同權重,達到增強關鍵特征的效果,提升圖像融合質量。本文最后通過鋅渣圖像數據集進行算法驗證,并與其他主流圖像融合方法進行對比分析。
1 CBAM-DDcGAN網絡模型
1.1 DDcGAN融合網絡框架
該融合網絡主要由生成器G和兩個判別器Di、Dv構成,網絡總框架如圖1所示,基本原理如下:將紅外圖像i與可見光圖像v輸入到生成器G生成融合圖像f;將紅外圖像i與融合圖像f輸入判別器Di,將可見光圖像v與融合圖像f輸入判別器Dv;以i和v作為真值圖像對融合圖像f進行判別,通過判別器和生成器的對抗訓練來更新生成器的參數,使融合圖像f獲得更多源圖像的信息,以達到判別器無法區分二者的效果。

圖1 DDcGAN總體框架
1.2 生成器模型
生成器G采用在無監督學習情況下特征重構能力較強的編解碼結構,如圖2所示。紅外與可見光圖像經通道連接后,形成雙通道圖像并輸入到編碼器Encoder中進行特征提取,提取到的特征輸入到卷積注意力機制模塊來尋找關鍵特征,之后進行特征融合與特征重構。特征提取模塊的卷積層用Densenet結構代替常規的卷積層連接方式,其中n為卷積層輸出通道數,卷積層步長都為1,均使用3×3卷積核得到48個特征圖。CBAM利用卷積注意力機制給予輸入特征圖中的顯著像素以更多的權重,從而輸出更能表達原始圖像的特征增強圖。編碼器輸出的特征圖進入特征融合模塊進行圖像融合,再輸入解碼器Decoder,解碼器中卷積層的大小均為3×3,最后一個卷積層的激活函數為tanh函數,融合后的特征圖在解碼器中進行特征重構,最后通道數降至1,輸出融合圖像。在整個編解碼網絡中,最后一個卷積層之外的每個卷積層后面都使用批量歸一化層(batch nomalizatio, BN)和帶泄露線性整流函數(LeakyReLU)層來提高模型訓練時的穩定性。
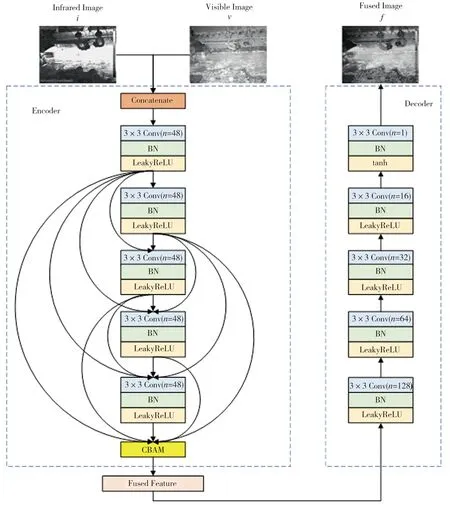
圖2 生成器的網絡結構
1.3 卷積注意力機制模塊
本文使用的卷積注意力機制模塊CBAM結合了通道注意力和空間注意力兩個子模塊,強調空間和通道兩個維度上的關鍵特征,其網絡結構如圖3所示。CBAM的給定輸入為編碼器提取的特征F,先經過通道注意力模塊,將所輸出的通道注意力一維卷積和輸入特征圖F做逐元素乘法操作,得到經過通道注意力增強的輸入特征圖F′;再經過空間注意力模塊,將所輸出的空間注意力二維卷積與該模塊的輸入特征圖F′做逐元素乘法,得到CBAM輸出的最終特征圖F″。

圖3 卷積注意力機制模塊
通道注意力模塊的網絡結構如圖4所示。首先將輸入特征圖F分別經過平均池化層和最大池化層以聚合輸入特征圖的空間信息,得到平均池化和最大池化特征,再分別通過一個共享網絡,共享網絡由多層感知機(multilayer perceptron, MLP)和一個隱藏層組成。將共享網絡輸出的特征做逐元素求和,經過sigmoid激活操作,產生F的通道注意力一維卷積Mc(F)。

圖4 通道注意力模塊
空間注意力模塊如圖5所示,其輸入為經過通道注意力增強的特征圖F′。首先,將F′通過最大池化和平均池化來聚合特征圖的通道信息,生成兩個二維特征圖,分別表示特征圖在通道中的平均池化特征和最大池化特征;然后通過標準的卷積層進行連接和卷積操作,經過sigmoid激活函數生成F′的空間注意力二維卷積Ms(F′)。
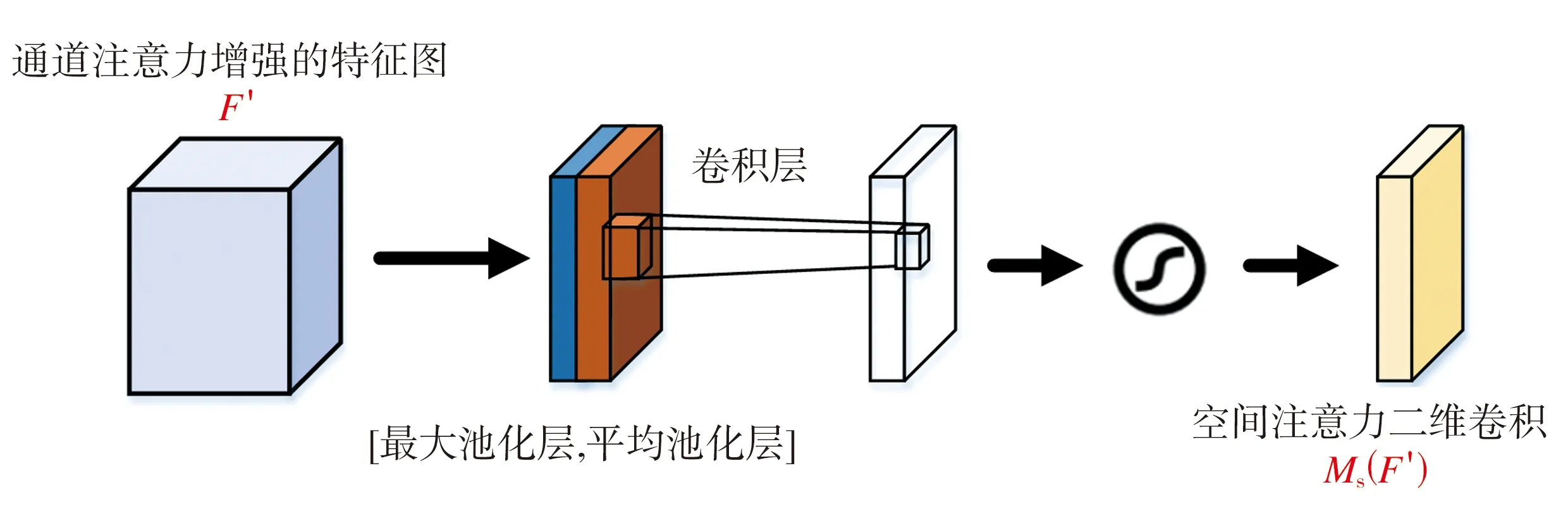
圖5 空間注意力模塊
卷積注意力機制的整體過程可以表示為:
Mc(F)=σ[MLP(AvgPool(F))+MLP(MaxPool(F))]
(1)
F′=Mc(F)?F
(2)
(3)
F″=Ms(F′)?F′
(4)
式中:AvgPool和MaxPool分別代表平均池化和最大池化操作,MLP代表多層感知機,?代表逐元素乘法操作,σ代表sigmoid激活函數,f7×7代表卷積核大小為7×7的卷積運算。
1.4 雙判別器模型
生成器G根據設計的損失函數使生成的融合圖像f盡可能多地保留紅外圖像i的高亮信息和可見光圖像v的紋理細節信息。GAN網絡中的判別器是用來與生成器進行對抗,在對抗訓練過程中指導生成器的參數更新,使融合圖像中的信息更加豐富。紅外圖像與可見光圖像的成像機理不同,本文針對兩種圖像的模態差異設計了兩個判別器Di和Dv,將融合圖像與紅外圖像和可見光圖像分別進行判別。判別器網絡架構如圖6所示,雙判別器內部共享相同的網絡結構,輸入分別為紅外圖像與融合圖像或者可見光圖像與融合圖像。判別器包括4個卷積層,第1層到第3層中的卷積核大小均為3×3,步長設置為1,最后一層為tanh激活函數與全連接層(fully connected layer, FC),判別器會從輸入的圖像中提取特征并進行特征分類,全連接層將特征進行整合,tanh激活函數生成一個標量(Scalar),代表判別結果,即輸入圖像來自源圖像而非融合圖像的概率。

圖6 判別器網絡結構
2 損失函數
生成器的目標是要在融合圖像中盡可能多地保留源圖像的豐富信息,使得判別器無法對二者進行區分。生成器的損失函數由生成器與判別器之間的對抗損失Ladv(G,D)和生成器自身的內容損失Lcon構成。對抗損失的計算如式(5)~式(7)所示:
Ladv-i,f(G,Di)=E[log(1-Di(G(v,i)))]
(5)
Ladv-v,f(G,Dv)=E[log(1-Dv(G(v,i)))]
(6)
Ladv(G,D)=Ladv-i,f(G,Di)+Ladv-v,f(G,Dv)
(7)
這里E代表期望。
在圖像復原過程中,圖像中的一點點噪聲可能就會對復原結果產生非常大的影響,因此需要通過內容損失函數來保證圖像的光滑性。內容損失Lcon的設計結合Frobenius范數和全變分模型,前者從像素強度方面來約束融合圖像與紅外圖像的相似度,后者能有效消除圖像復原過程中可能產生的偽影,使融合圖像盡可能多地繼承可見光圖像的信息,Lcon的計算如式(8)所示:
η||G(v,i)-v||TV]
(8)
式中:η代表平衡像素強度與可見光信息的權重系數,下標F代表Frobenius范數,下標TV代表全變分(Total Variation)范數,G(v,i)代表生成器生成的融合圖像,φ(x)代表提取x的特征圖。
3 實驗與結果評價
3.1 數據集與實驗設置
在訓練階段,從經過矯正配準的鋅渣圖像數據集中選取10對不同場景下的紅外與可見光圖像作為基礎訓練數據,通過滑窗方式裁剪原始圖像進行數據增強,最終得到3060對分辨率為84×84的紅外與可見光圖像作為本文實驗的訓練集。在訓練過程中,批次大小設為12,優化器選擇Adam Optimizer,訓練階段總共包含255個epoch,初始學習率設為0.0001。實驗環境配置如下:操作系統為Win10專業版,顯卡為GeForce RTX 3080Ti,內存為16 GB,采用TensorFlow和OpenCV深度學習開源框架搭建網絡環境。
在測試階段,選取鋅渣紅外與可見光圖像作為測試集,輸入訓練好的生成器進行圖像融合。
3.2 對比實驗
本文選取多種傳統圖像融合算法和基于深度學習的圖像融合算法進行對比實驗,對比算法包括VSM-WLS[1]、紅外特征提取(IR-Feature)[3]、CNN[4]、MDLatLRR[2]、U2Fusion[6]、FusionGAN[7]、IFCNN[5]。部分實驗結果如圖7所示,圖中(a)~(d)代表所選取的4幅狀態或區域不同的鋅渣圖像,紅外圖像中較暗的部分為待撈渣區域,高亮部分為鋅渣分布較少的區域,圖中第三到第十行均為不同算法得到的融合圖像。

圖7 不同算法的圖像融合效果對比
從圖7可以發現,幾種算法得到的融合圖像有明顯差異。由于鋅渣圖像的特殊性,紅外特征提取算法的融合策略在部分區域產生紅外與可見光特征相互干擾、融合特征選擇錯誤的問題,導致融合圖像對比度失真現象嚴重;VSM-WLS、CNN、MDLatLRR、U2Fusion和IFCNN算法有效避免了上述問題,融合圖像具有較好的對比度,能夠突出鋅液中的待打撈區域,背景的紋理信息也較為充分,但對于液面區域的細節紋理信息恢復不夠全面,無法有效體現液面待打撈狀態。圖7(b2)和圖7(c2)中存在光照不均勻的區域,上述幾種方法在融合過程中不能較好地克服這個問題,無法正確判斷高強度光照區域,導致在圖7(b3)~圖7(b8)和圖7(c3)~圖7(c8)中,本該打撈的厚渣區域呈現出錯誤的高亮信息,這會對后續的撈渣作業產生不利影響。FusionGAN與本文方法是利用生成對抗網絡的原理完成圖像融合任務,通過判別器反復對融合圖像與可見光圖像進行比較,能夠較好地解決光照不均勻的問題,得到較高質量的融合圖像。FusionGAN使用單判別器,導致融合圖像更趨近于紅外圖像的像素分布,缺乏紋理細節信息,且融合圖像過于平滑,視覺效果模糊。本文算法在生成對抗網絡的基礎上采用了雙判別器分別與紅外圖像和可見光圖像進行判別,融合圖像具有較好的對比度,在突出待打撈區域的同時又包含了豐富的紋理細節信息,整體圖像更傾向于真實的鋅渣液面,便于人眼觀察識別。
以上定性評價方法具有主觀意識強、易受外界環境干擾等缺陷,需要與客觀的定量評價標準相結合來對融合圖像進行綜合評價,本文選取的定量評價指標如下[10-15]:
(1)信息熵(entropy, EN)
EN是一種衡量圖像中信息量多少的指標,熵值越大表示融合圖像的信息越豐富,融合效果越好。
(2)互信息(mutual information, MI)
MI用來衡量融合圖像獲取自源圖像的信息量,互信息的數值越大表示融合圖像保留了更多的源圖像特征,融合效果也更好。
(3)差異相關性總和(sum of the correlations of differences, SCD)
SCD是一種衡量融合圖像包含源圖像互補信息量的指標,值越大表明融合圖像包含源圖像的互補信息量越多,融合效果也就越好。
(4)圖像融合質量指數(quality assessment of fused images, Q(a,b,f))
Q(a,b,f)是一種較為新穎的融合圖像客觀非參考質量評估指標,它利用局部度量去估計來自輸入的關鍵信息在融合圖像中的表現程度,其值越高表示融合圖像的質量越好。
(5)峰值信噪比(peak signal to noise ration, PSNR)
PSNR用于衡量圖像有效信息與噪聲的比率,能夠反映圖像是否失真,PSNR值越大表示融合圖像的質量越好。
(6)結構相似度(structural similarity index measure, SSIM)
SSIM是衡量兩幅圖像相似度的指標,SSIM將失真建模為亮度、對比度和結構3個不同因素的組合,用均值作為亮度的估計,用標準差作為對比度的估計,用協方差作為結構相似程度的度量。SSIM的數值范圍為-1~1,越接近1表示兩張圖像越相似。
表1為不同融合算法在鋅渣數據集上的定量評價指標統計結果,表中數值為多幅融合圖像指標的平均結果,最優值用粗體顯示,次優值用斜體顯示。從表1可以看出,相比于其他算法,本文算法有4個指標達到最優,1個指標達到次優。這表明本文算法針對鋅渣數據集達到了較好的融合效果,融合圖像信息量最多,包含源圖像的互補信息最多,并且融合圖像的細節特征較為豐富,更符合人眼視覺的感知特性。

表1 不同算法所得融合圖像的定量評價指標
表2為不同算法融合多張圖像所需的平均時間,可以看出幾種算法在運行效率上存在一定差異。由于CNN算法是直接利用卷積神經網絡提取源圖像的深度特征來生成融合圖像,故而所需時間遠多于其他算法;IR-Feature算法所需時間雖然最短,但由圖7可知,其融合圖像存在明顯失真,無法保證融合質量;其余算法所需時間基本處于同一量級。以上結果表明,本文算法在提升圖像融合質量的同時還能夠兼顧運行效率,具有較為全面的性能表現。

表2 不同算法融合圖像的平均時間
3.3 消融實驗
為了進一步驗證本方法中卷積注意力機制模塊和雙判別器的有效性,下面使用鋅渣圖像數據集進行消融實驗,采用4種不同的融合模型:①無卷積注意力機制模塊且單判別器(no_CBAM &single_dis)、②無卷積注意力機制模塊且雙判別器(no_CBAM &double_dis)、③有卷積注意力機制模塊且單判別器(CBAM &single_dis)、④有卷積注意力機制模塊且雙判別器(CBAM &double_dis)。同時,還對不同網絡模型訓練階段所需時長Ttrain進行統計分析,以驗證本文方法的實用性。
表3所示為4種模型在鋅渣圖像數據集上的客觀評價指標及Ttrain。雙判別器能夠豐富融合圖像的特征信息,CBAM機制有助于選擇關鍵特征,二者原則上都能一定程度地提升圖像融合質量。然而,由表3中數據可以發現,雙判別器網絡no_CBAM &double_dis在融合圖像的部分性能指標上反而劣于單判別器模型no_CBAM &single_dis,其原因在于,工業場景存在光照不均勻的情況,低溫的厚渣區域由于強光照射,在圖片中變成了高溫區域,從而導致紅外圖像中出現冗余和錯誤信息,最終影響了網絡模型的融合性能。雙判別器模型的優勢在于特征提取能力強,與CBAM機制相結合,才能更好地突出紅外與可見光源圖像中的關鍵信息,抑制冗余和錯誤信息,使融合圖像保留更多有效的紅外熱輻射信息與可見光紋理信息,從而提升圖像的融合質量。另外,本文算法結合了雙判別器模型和CBAM模塊,增加了網絡模型復雜度,導致模型訓練階段時間有所延長,但增加幅度較小,且不會對測試階段造成影響,得到的融合圖像在各項指標上均有一定的提升,驗證了算法的有效性和實用性。

表3 消融實驗結果
4 結語
本文提出了一種結合雙判別器生成對抗網絡與卷積注意力機制的紅外與可見光圖像融合算法,用于熱鍍鋅生產線上鋅池撈渣工藝中的鋅渣識別階段,以改善惡劣的工業環境下紅外或可見光成像設備無法提供清晰圖像的情況。該算法在生成對抗網絡中使用雙判別器結構,使融合圖像盡可能多地保留紅外與可見光源圖像的特征信息;同時引入卷積注意力機制,在特征提取過程中增強對關鍵特征的表達,從而提高紅外與可見光圖像的融合質量。與其他主流圖像融合算法相比,本文算法獲得的融合圖像既能通過豐富的熱輻射信息確定厚渣的位置,又包含了鋅渣的紋理細節信息,其主觀可視性和定量評價指標都得到一定程度的改善,能夠為智能化撈渣作業后續的目標識別和檢測等任務提供有效的技術支撐。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
