基于深度學習的醫學影像問答模型*
2023-06-30 02:27:26趙晉稷
醫學信息學雜志 2023年5期
趙晉稷 劉 旻
(1天津中醫藥大學第一附屬醫院 天津 300193 2 國家中醫針灸臨床醫學研究中心 天津 300193)
1 引言
我國衛生資源總體缺乏,優質衛生資源嚴重不足。醫生在臨床工作中需要閱讀大量醫療檢查報告,存在人為錯誤的可能性,醫療資源不足可能會加劇這一現象。近年來,隨著“互聯網+醫療”模式的推廣,在線問診平臺發展迅速,患者可以通過平臺直接與醫生溝通[1-2]。中醫問診平臺中,大量舌象圖像咨詢成為急需解決的問題。伴隨人工智能賦能醫療行業,醫學領域出現了一系列智能分析系統,如醫學影像問答系統,能夠依托平臺輔助解答并分流大量信息,提高工作效率,減輕醫務工作者壓力[3]。
2 相關工作
醫學影像問答(medical visual question answering,Med-VQA)是醫學領域的問答任務。在該過程中,輸入醫學影像和與之相關的臨床問題,將自動輸出答案[4]。患者可以在提問后及時得到反饋,醫生也可以在診斷疾病時將系統反饋的答案作為參考意見。醫學影像問答系統可以節省寶貴的醫療資源,輔助醫生診斷。已有醫學影像問答系統及相關模型[4]直接將自然場景下的圖像問答模型遷移到醫學場景使用。考慮到自然圖像和醫學圖像中包含的語義有較大差異,有研究者提出注意力堆疊網絡(stacked attention networks,SAN)[5]、雙線性池化(multimodal compact bilinear,MCB)[6]、增強醫學圖像中的視覺信息(mixture of enhanced visual features,MEVF)[7]、問題為前提的推理(question-conditioned reasoning,QCR)[8]、雙線性注意力網絡(bilinear attention networks,BAN)[9]等操作,以緩解數據缺乏問題。已有模型性能較差,主要存在3方面問題:一是面對數據分布不相同的自然圖片和醫學影像,適用于自然圖片問答系統的模型在醫學影像問答系統并不一定有效;二是醫學影像問答任務相關數據集需要人工標注,因此很多數據集包含訓練樣本較少,限制模型訓練效果;三是醫學影像問答任務相對于自然圖像問答難度更大,因此在完成該任務時需要模型有更強的語義分析和多模態融合處理能力,見表1。本文在上述工作基礎上采用語義圖卷積(semantic graph convolution,SGC)進一步獲取醫學影像和文本之間的關聯,從而更好地解決醫學影像問答任務。針對問題一,通過元學習和自編碼器增強醫學影像相關數據,提高模型對噪聲的魯棒性;針對問題二,增加數據可以緩解訓練樣本較少的問題;針對問題三,通過設計語義圖結構,進一步增強提取醫學影像和文本之間關聯的能力,并通過門控線性單元選擇出文本中的重要部分,從而更好地完成醫學影像問答任務。
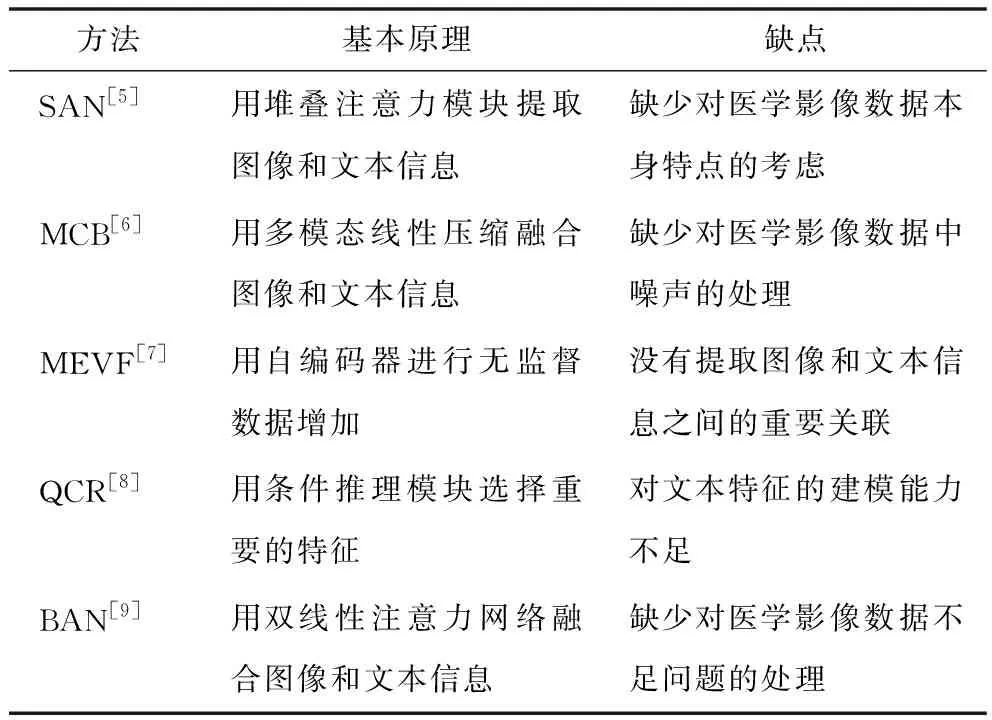
表1 多種醫學影像問答方法的基本原理和缺點
3 方法
3.1 醫學影像問答任務
首先輸入一張待診斷圖片,如電子計算機斷層掃描(computed tomography,CT)圖像、舌象圖像等;然后輸入一個與該圖像相關的問題;模型充當醫生角色,根據輸入圖片回答給定問題,從而進行智能問診。本文提出基于語義圖卷積的醫學影像問答模型,見圖1。
兩口子忙了半下午,瞅瞅,日光已經西斜了。看來覺是不能睡了,也睡不著了。相反,兩人的精神頭,倒比睡著了更好。
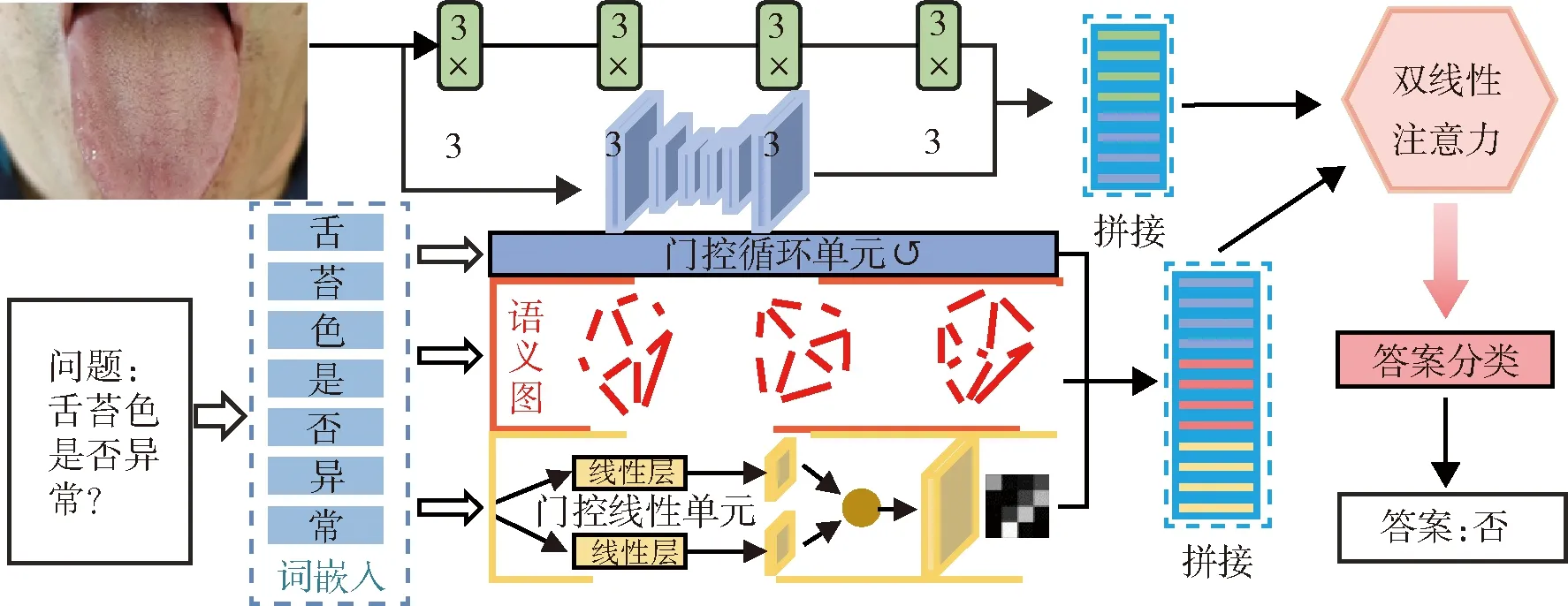
圖1 研究框架
3.2 圖像信息處理
輸入醫學圖像I之后,對該圖像采用如下預處理。一是將圖像首先輸入4層3×3的卷積網絡,然后進行全局平均池化,并采用元學習(model-agnostic meta-learning,MAML)方法初始化網絡權重[10],最終該操作得到的特征維度為64。二是采用自編碼器對圖像進行進一步處理[11]。三是將上述兩步操作得到的特征進行拼接,得到圖像特征V∈R1×128。
3.3 文本信息處理
本文在醫學問答數據集(visual questions and answers about radiology images,VQA-RAD)上進行訓練和測試[15],該數據集包含315張醫學領域相關待診斷圖片和3 515條醫生標注的問診對話。其中,問診對話包含兩種類型:固定式問答和開放式問答。固定式問答的答案為“是”或“否”兩種特定選項,例如問題為“該胸部CT圖像中是否有異常狀況”,答案為“是”;開放式問答的答案沒有固定形式,例如問題為“該頭顱核磁中的病灶在什么位置”,答案為對應的特定位置。在實驗中,采用3 064條問答對話作為訓練集,451條對話作為測試集。訓練過程中采用自適應動量優化器進行梯度下降優化,學習率為0.000 1,訓練輪數為150輪。
可以看到與QCR相比,本文方法在開放式問答數據集準確率方面提升2.8個百分點,達到55.6%;在固定式問答數據集準確率方面提升2.5個百分點,達到79.3%,見圖2。其中紅色代表正確回答,綠色代表錯誤回答。為了進一步分析圖2中的問答結果,將本文方法(SGC)與已有方法(QCR)模型提取的中間層特征進行可視化,見圖3。圖3針對圖2中的問題1和問題3進行分析,高亮部分分別為本文方法(紅色)和已有方法(綠色)重點關注區域,結合問題1(“動脈瘤”)和問題3(“右側顳葉”)文本部分可知,本文方法可以更好地捕捉與文本相關的醫學影像區域,從而更好地回答問題。通過圖3所示的可視化結果可以看到,本文方法通過設計語義圖結構可以更好地提取醫學影像和文本中的關聯信息,優于已有方法。
第2步:考慮到語句本身包含上下文序列信息,為了編碼整個語句序列特征Qs∈Rn×ds,采用門控循環單元(gate recurrent unit,GRU)[12],該步的輸入為上一步得到的詞嵌入特征Qe,輸出為包含上下文序列信息的語句特征Qs。
第3步:考慮到語句中單個文字之間的關聯以及整個語句中的語義結構,將整個語句嵌入到圖結構中構成語義圖[13],并采用圖卷積網絡提取特征,語義圖本質上是一種特殊的特征結構方式。首先提取語句之間的關聯強度作為語義圖的鄰接矩陣:
(1)
其中We1,We2∈Rde×da,da表示圖結構的隱式特征維度,A0∈Rn×n表示該語義圖的鄰接矩陣。接下來基于鄰接矩陣進行圖卷積操作:
ΔROA=γ0+γ1cashi+γ2mixi+γ3leveragei+γ4scalei+γ5sizei+γ6tobinQi+εi
Qg=A0QeWe1Wg0
(2)
第4步:為了進一步提取并突出語句中重要的文字特征,采用門控線性單元(gated linear unit,GLU)[14]:
出版類企業核心競爭力提升策略探析 ………………………………………………………………………………… 黃 曉(2/24)
其中Wg0∈Rda×de為可學習的參數,Qg∈Rn×de為經過語義圖嵌入后的語句特征,不僅包含語句文字之間的關聯信息,而且融合了語句整體信息。在語義圖中,每個文字是1個單獨的圖節點,每個圖節點之間邊的權重通過關聯強度決定,圖卷積過程相當于對整個圖結構的邊不斷進行更新,訓練完成后得到整個語義圖最優結構。
U1=φ1(QeW1)
(3)
U2=φ2(QeW2)
(4)
Ql=φ3(U1⊙U2)Wl
(5)
根據前文表2中的實驗結果和上述分析可知本文提出的基于語義圖問答模型的有效性,針對開放式問答和固定式問答,通過語義圖模塊可以加強文本特征之間關聯的表達,同時利用門控線性單元篩選文本特征中的重要信息,提升了整個模型的問答準確率。
第5步:在得到上下文序列信息的語句特征Qs、語句的語義圖特征Qg、重要性相關語句特征Ql后,將不同層次級別的語句特征進行特征融合,具體實現方式如下:
Qfea=[Qs;Qg;Ql]Wq
(6)
其中Ac表示正確回答的問題數量,Aall表示整個數據集中的問題數量。為了更準確地分析方法效果和性能,實驗結果部分對開放式問答和固定式問答分別進行統計。
巖體稀土元素含量∑REE為116.43×10-6,∑Ce/∑Y比值為2.66,δEu為0.61。(La/Sm)N值為3.47,(Gd/Yb)N為0.91;為富輕稀土型。δEu<0.7,表明巖漿為上地殼經不同程度的部分熔融形成的。
3.4 問答系統
采用雙線性注意力網絡對圖像特征V和文本特征Qfea進行融合:
y=BAN(V,Qfea)
(7)
然后通過分類器預測答案的置信分數s,將概率最大的作為最終結果。
4 實驗結果與分析
4.1 實驗設置
在實際應用中,當患者將待診斷圖像上傳后,會提出并輸入相應問題q∈Rn,其中n為問句長度。對該問句采取如下特征處理過程。
4.2 評價指標
(8)
其中,[;]表示特征拼接操作,Wq∈R(ds+dg+dl)×dq是可學習的參數,Qfea∈Rn×dq表示最終提取得到的文本特征。
4.3 實驗結果
本文提出的方法(SGC)與已有方法應用于開放式問答和固定式問答任務的準確率對比結果,見表2。
1)果園深翻。秋季采果后結合秋施基肥進行,只要方法合適,春、夏、秋季都可進行深翻,其中以秋季果實采收后至落葉期進行為好。針對貴州蘋果產區中的山區薄土層果園,土壤深翻,能夠加厚活土層,促進巖土的風化和熟化,提高土壤蓄水保肥能力。
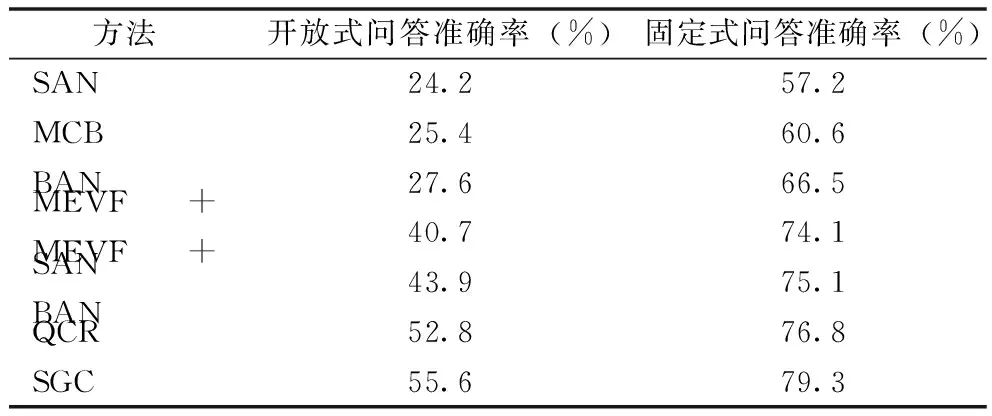
表2 不同方法準確率對比
第1步:對問句中每個文字進行詞嵌入(word embedding,WE),得到語句特征Qe=[w1,w2,…,wn]∈Rn×de。

圖2 本文方法與已有方法的問答結果
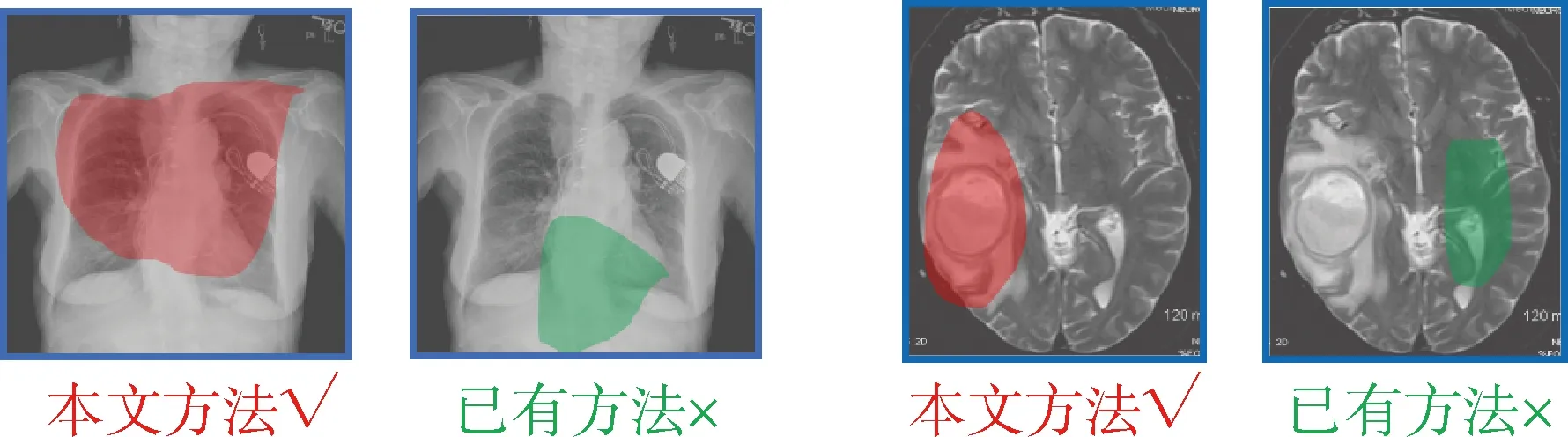
圖3 本文方法與已有方法對醫學影像的關注區域可視化
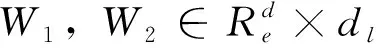
4.4 消融分析
為了進一步探討本文提出模型(SGC)中各模塊對于任務的作用和效果,從語義圖模塊、門控模塊以及兩模塊中包含的激活函數3方面進行消融分析。不同模塊消融后的基于問答準確率的實驗結果,見表3。

表3 不同模塊消融實驗
其中“√”表示使用該模塊,“-”表示不使用此模塊。從表3第1行可以看到門控線性模塊對提升問答準確率的重要作用,固定式問答任務性能提升約6%;從第2行可以看到語義圖模塊能夠在較難的開放任務上有效捕捉文本內部關聯;從第3行可以看到語義圖模塊和門控線性模塊中的激活函數對任務準確度也有一定影響。
為了分析不同維度對模型性能的影響,實施相關模塊對模型維度敏感度分析,見圖4、圖5。可以看到不同語義圖嵌入維度對模型性能影響較小,當維度達到足以表征語義圖時,模型性能達到飽和,更高維度的隱式空間是不必要的;門控線性模塊對不同維度選擇有一定要求,合適的隱藏層維度有利于該模塊尋找重要語句文本。
原來這屆的社長要改選時,一共有七位大三的學長符合選舉資格,但沒有一位想當社長,最后只好用猜拳決定,猜輸的當社長。
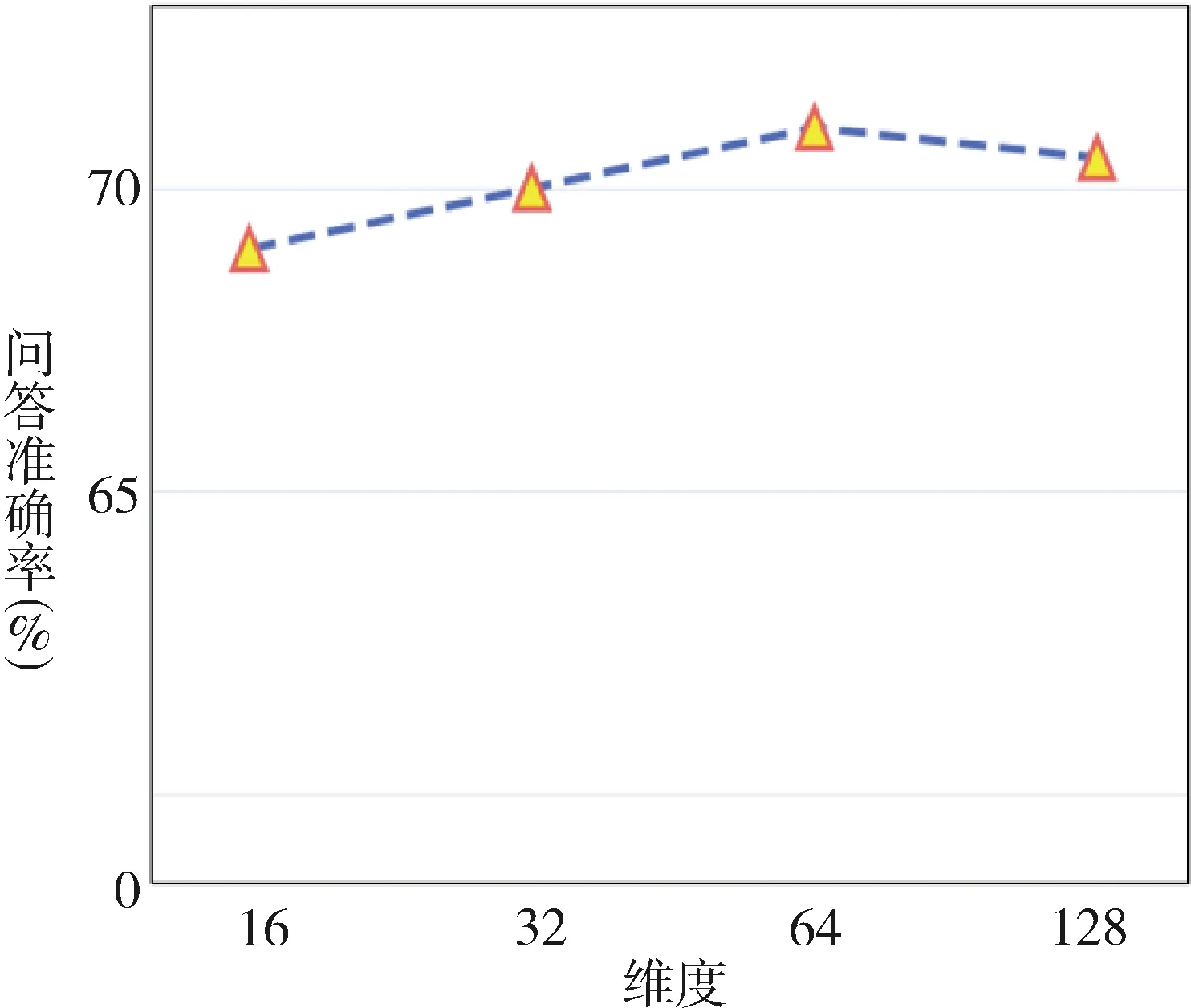
圖4 不同語義圖維度模型性能
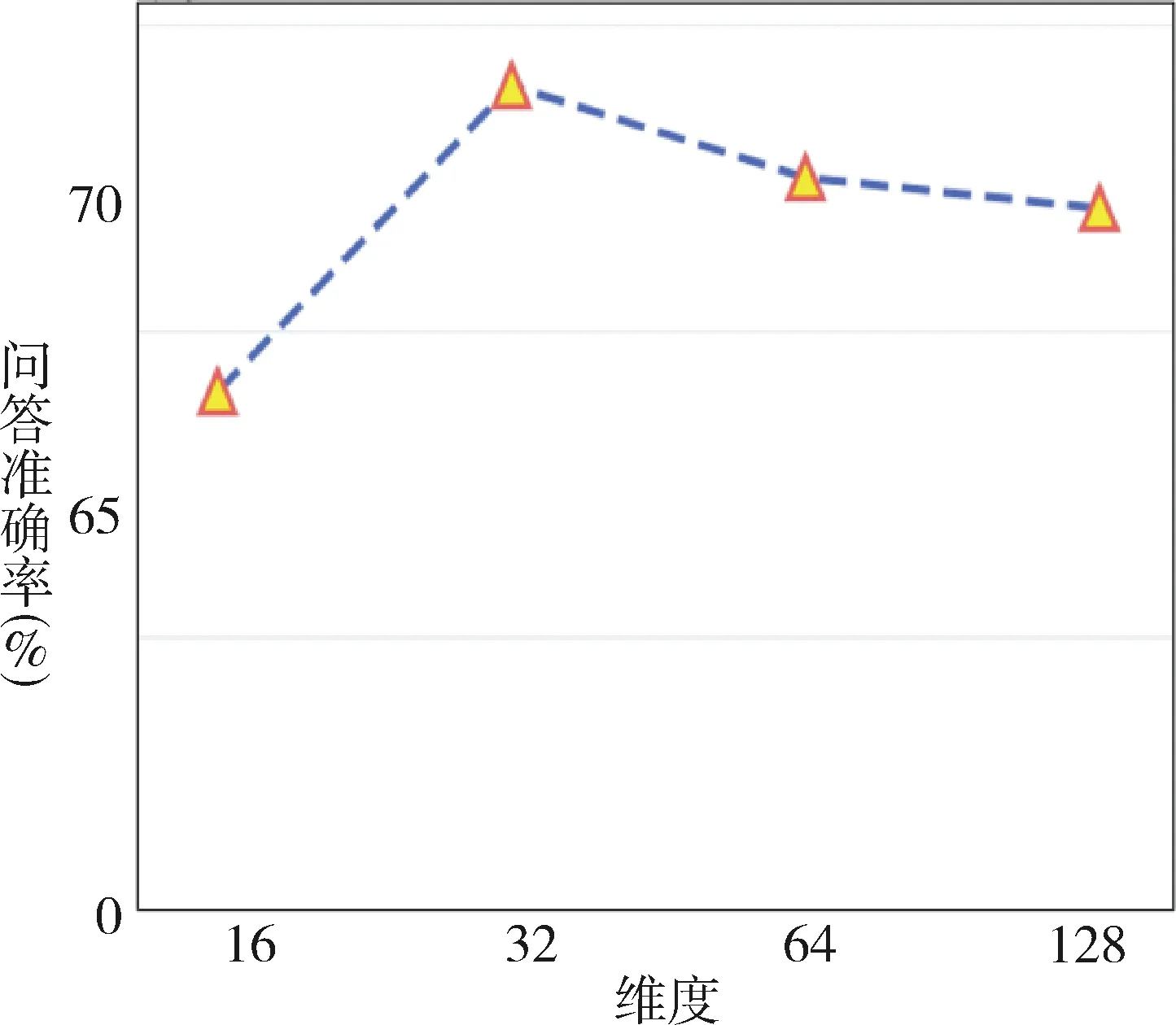
圖5 不同門控線性模塊維度模型性能
針對語義圖維度和門控模塊維度,從模型表達能力而言,兩者在一定范圍內的提高均可以提升相應表達能力,但是更高維度會帶來更大的計算復雜度,在神經網絡訓練過程中有較大開銷,延緩整個模型的收斂效率,有一定可能造成性能下降,因而隱藏層維度并不是越大越好,這也與圖4和圖5的實驗現象一致。從模型過擬合而言,雖然雙向編碼器表征模型[16]的隱藏層維度可達768甚至1 024,卻能同時擁有更強表達能力,對比可知,造成本文模型維度受限的另一個主要原因是訓練集數據量較少,較深維度容易導致過擬合性能下降,由于醫學領域標注的數據集有限,擁有專業醫學知識的標注人員稀缺,標注難度較大,這也是醫學問答領域乃至“人工智能+醫學信息”領域目前的重要挑戰。
隨著新媒體的快速發展,微信群成為家校溝通的重要渠道。管理班級微信群,與其要求家長在群里不能做什么,還不如與家長商討能做什么,以及怎么做。開學初,我借助家長會,與各科老師以及家長充分探討,最終確定了班級微信群每天“群聊”的話題。同時,這也被當作家長的一項“作業”來完成。
5 結語
本文使用深度學習方法解決醫學影像問答問題,通過元學習和自編碼器模塊提取醫學影像視覺特征,通過語義圖卷積提取問題中的文本特征,并獲取視覺特征和文本特征之間的重要關聯。實驗結果表明本文方法在相關醫學影像問答數據集上較已有工作有一定提升,開放式問答準確率提升到55.6%;固定式問答準確率提升到79.3%。本文方法在開放式問答性能提升方面尚有較大空間,開放式問答任務本身需要生成對應答案,因此需要提升模型生成能力。在未來工作中將從以下兩個方面進行改進,首先在語言特征提取時采用預訓練的大模型[16]提升特征表達能力,其次是收集并標注更多醫學領域語料庫用于訓練,使模型具備更好的文本生成能力。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
