稀疏獎勵下基于強化學習的無人集群自主決策與智能協同
2023-07-10 03:08:30李超王瑞星黃建忠江飛龍魏雪梅孫延鑫
兵工學報 2023年6期
李超,王瑞星,黃建忠,江飛龍,魏雪梅,孫延鑫
(1.中國兵器工業試驗測試研究院 技術中心,陜西 西安 710116;2.南京理工大學 機械工程學院,江蘇 南京 210094;3.哈爾濱工業大學 航天學院,黑龍江 哈爾濱 150001)
0 引言
二戰結束以來,盡管大規模世界戰爭未有發生,但局部性戰爭卻從未停止,從朝鮮戰爭到阿富汗戰爭再到納卡戰爭以及硝煙彌漫的俄烏戰場,科技力量帶來的加成逐漸顯現,尤其是新世紀發生的幾次戰爭中,無人智能裝備發揮了重要的作用[1]。
未來,無人智能集群作戰將會是典型的作戰模式。而無人集群的最終應用離不開無人集群對抗建模及群體智能演化機理、無人集群探測識別與態勢感知、無人集群通信、無人集群導航、無人集群自主決策、無人集群運動控制以及無人集群對抗策略遷移與泛化[2]、無人集群試驗與評估[3]等技術研究。其中在無人集群自主決策研究領域[4],強化學習技術被廣泛使用。
多智能體系統,由一系列相互作用的智能體構成,多個智能體之間通過相互通信、合作、競爭等方式,完成單個智能體不能完成的、大量而又復雜的工作。目前,結合多智能體系統和強化學習方法形成的多智能體強化學習正逐漸成為研究熱點[5]。
如圖1所示,多智能體強化學習技術框架包含環境、智能體兩部分,智能體n感知環境狀態,輸出狀態矩陣sn,輸出的狀態組成聯合狀態集 (s1,s2,s3,…,sn),并依據策略網絡選擇動作an,輸出的動作組成聯合動作集(a1,a2,a3,…,an),作用于環境,環境依據聯合動作給予對應獎勵rn組成總獎勵集(r1,r2,r3,…,rn)并更新狀態[6]。在多智能體與環境交互過程中,獎勵為多智能體策略迭代的重要依據。豐富的獎勵反饋,可以有效引導多智能體學習到最優動作策略,但在強化學習技術的應用領域中,獎勵稀疏性問題廣泛存在。尤其隨著深度學習技術與強化學習技術的深度融合,深度神經網絡被應用到強化學習應用領域之后,因網絡訓練過程需要大量樣本支撐,稀疏獎勵問題也就愈加凸顯[7]。
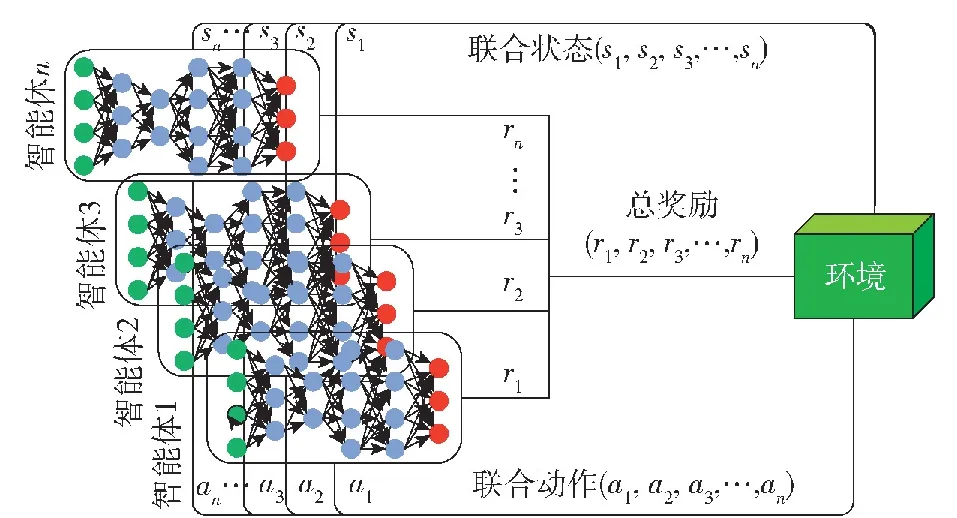
圖1 多智能體強化學習原理圖Fig.1 Schematic diagram of multi-agent reinforcement learning
針對廣泛存在的獎勵稀疏性,獎勵塑造利用經驗知識人工設計獎勵函數以擴充獎勵體系引導智能體進行最優策略學習[8-9]。課程學習通過不斷增加任務難度以改善獎勵稀疏造成的網絡收斂緩慢問題[10]。事后經驗回放是一種從失敗經歷中提取有效信息的強化學習方法,通過對失敗經歷進行處理產生獎勵信息,解決獎勵的稀疏性問題[11]。分層強化學習通過縮小各層策略的動作序列空間,提高解決稀疏獎勵問題的能力[12]。現有獎勵體制機制研究多針對于單智能體策略學習問題,且仿真或試驗的場景設定較為簡單,狀態-動作空間維度較低[13-15]。
針對基于強化學習的無人集群自主決策與智能協同策略學習這一多智能體問題存在的獎勵稀疏性,建立了無人集群攻防對抗任務場景模型,并提出了基于局部回報重塑的獎勵機制設定方法,在此基礎上疊加優先經驗回放(PER),通過程序仿真及演示系統驗證,本研究有效地改善了獎勵稀疏性,極大提升了策略學習的效率。
1 無人集群對抗模型設計
針對無人集群對抗問題特點,設計的模型框架應包含以下3層內容:
1)場景層:該層主要對無人集群對抗的場景類別和場景特點進行設計。明確場景目標、場景構成,為后續無人集群對抗模型設計奠定基礎。
2)單元層:該層主要對對抗場景下單元數量及單元屬性進行設計。其中異構無人集群對抗還需對單元種類進行設計,通常異構無人集群對抗可包含探測單元、防御單元和攻擊單元等。另外在單元屬性方面,可設計生命屬性、移動屬性、探測屬性、攻擊屬性、防御屬性等。
3)規則層:該層應明確集群對抗雙方在具體對抗場景下的博弈策略及勝負判別規則。
在模型設計時,場景層、單元層、規則層設計可以劃分為場景模型設計和對抗規則設計兩大過程,如圖2所示。場景模型設計包含場景類別設計、場景特點設計、單元構成設計及單元屬性設計,對抗規則設計包含無人集群對抗雙方的博弈策略設計以及對抗過程的判別規則設計。
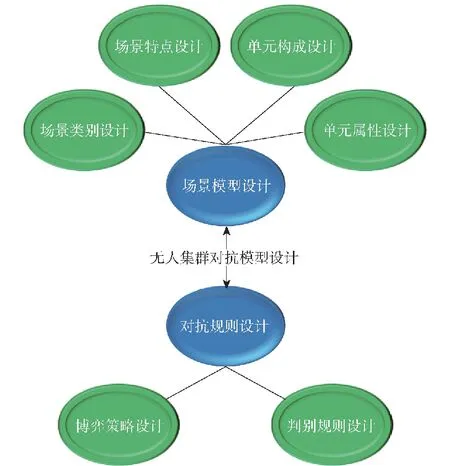
圖2 無人集群對抗模型構成Fig.2 Composition of the UAV swarm confrontation model
1.1 無人集群攻防對抗場景模型設計
基于圖2所示模型框架,本研究設計了無人集群攻防對抗場景模型,攻防對抗為無人集群對抗典型任務場景。在單元種類方面,設計攻擊、探測、防御3種單元。在單元數量方面,攻擊單元、防御單元、探測單元分別為6個、4個、2個。在任務目標方面,基于藍方采用設定策略的前提,通過基于強化學習的自主決策與智能協同技術,使得紅方單元學習到比藍方更優的博弈策略。
圖3為無人集群攻防對抗仿真模型紅藍初始站位圖,其中正方形框線表示紅藍對抗區域,雙方無人集群智能單元在對抗區域兩側一字排開。在仿真示意方面,雙方攻擊單元、防御單元、探測單元及生命值、防御范圍、探測范圍等單元屬性示意如圖3所示[16-18]。圖3中,AT、DE、DT分別表示紅藍雙方攻擊單元、防御單元、探測單元存活數。
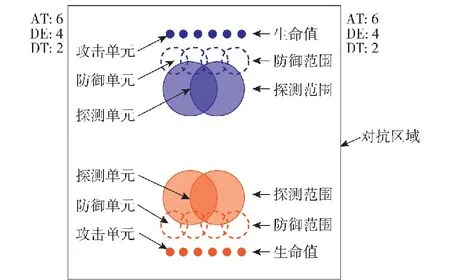
圖3 紅藍無人集群攻防對抗仿真模型初始站位圖Fig.3 Initial site map of attack-defense confrontation simulation model of the red and blue UAV swarms
1.2 無人集群攻防對抗規則設計
無人集群對抗規則設計包含博弈策略設計及判別規則設計,其中博弈策略設計包含集群對抗雙方在任務場景下的博弈對抗策略。針對本研究所設計的無人集群攻防對抗任務場景,紅藍對抗雙方的博弈策略如圖4所示。
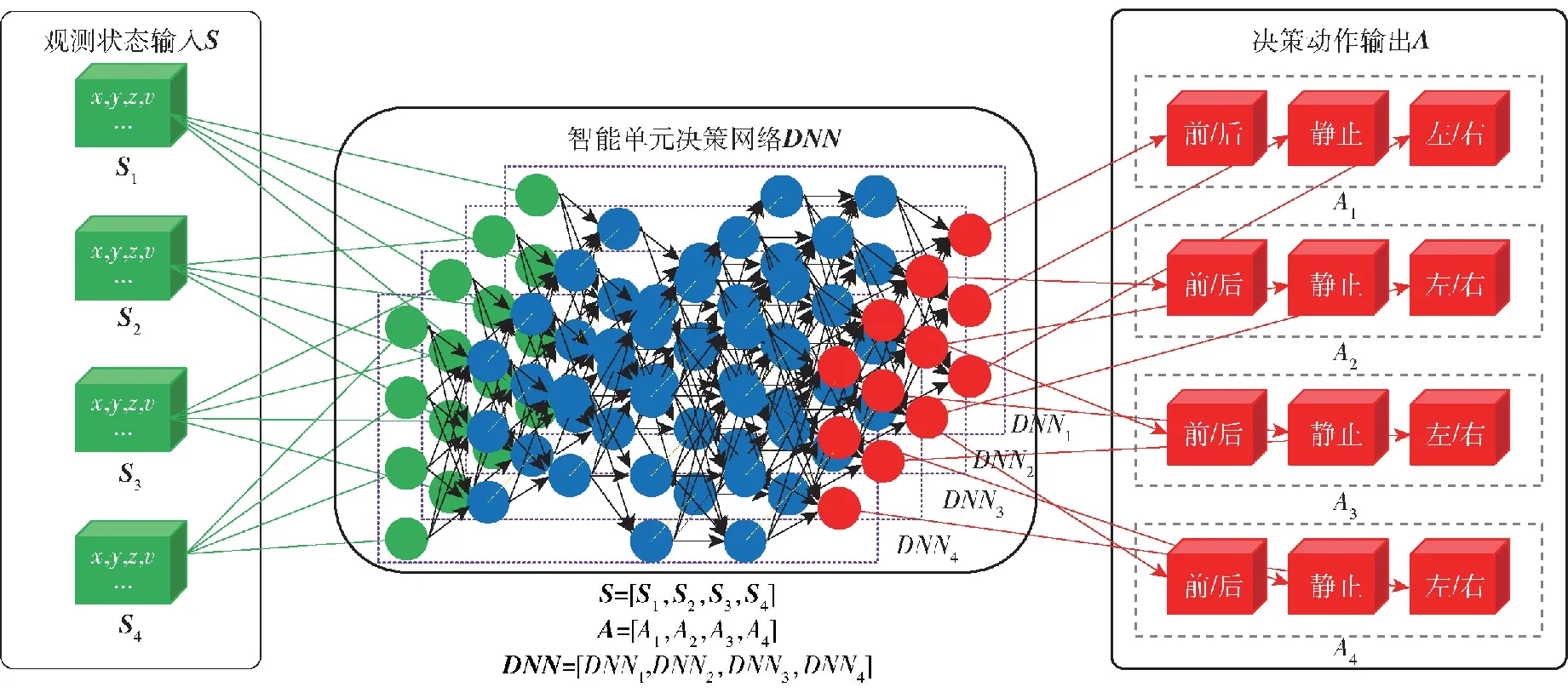
圖4 紅方智能單元自主決策原理示意圖Fig.4 Schematic diagram of the autonomous decision-making principle for the redintelligent units
紅方為基于深度神經網絡的自主決策單元,如圖4所示,若紅方無人集群包含4個智能單元,智能單元決策網絡DNN則相應設計4個智能體的自主決策DNN1、DNN2、DNN3、DNN4,在網絡設計過程中,每個智能體的自主決策在結構上獨立,但在參數上存在耦合,從而使得多類多個智能單元具備自主決策能力的同時具備協同能力涌現的潛能。在決策網絡輸入輸出方面,以智能體觀測狀態如自身/對方位置、速度、數量等參數為狀態輸入,Sn為第n個智能體觀測狀態,包含位置(x,y,z)、速度v狀態量,多個智能體觀測狀態組成智能體聯合狀態集S。以智能體移動/靜止狀態選擇、移動方向為動作輸出[19-21],多個智能體動作輸出組成智能體聯合動作集A。
藍方單元采用既定博弈策略,通過對無人智能單元集群作戰戰術戰法的深入了解,設計藍方單元博弈策略。針對防御屬性、探測屬性、攻擊屬性,依據各屬性范圍內有無被防御、被探測、被攻擊單元將3種智能單元的移動策略分別歸為兩類。其中針對防御單元,如圖5(a)所示:當單個單元防御范圍有被防御單元時,防御單元靜止;當多個防御單元防御范圍重疊處有被防御單元,其中一個防御單元靜止,其余單元被認定為防御范圍內無被防御單元;當防御范圍內無被防御單元時,趨向最近的需被防御單元。針對探測單元,如圖5(b)所示:當探測范圍內有被探測單元,探測單元靜止;當探測范圍內無被探測單元時,如存在未被探測到攻擊己方單元的敵方攻擊單元,則趨向最近的該類型單元;否則趨向最近的被探測單元。針對進攻單元,如圖5(c)所示:當攻擊范圍內無處于探測單元探測視角下的被攻擊單元,則趨向最近的該類型單元;否則,攻擊單元靜止并轉為攻擊狀態。

圖5 藍方智能單元博弈對抗策略示意圖Fig.5 Schematic diagram of the game confrontation strategy of the blueintelligent units
判別規則設計包含對抗過程有效性判別及對抗終局勝負性判別。有效性判別方面,雙方應在對抗區域內、設定屬性限制下進行對抗。勝負性判別方面,為考察智能單元自主決策算法的學習效率,在雙方單次對局中,設置最大仿真步。未達到最大仿真步時,若一方智能單元中探測或攻擊單元被全部消滅,判定該方對局失敗。達到最大仿真步時,對局結束,對所有智能單元的剩余總血量進行比較,總血量大的一方對局勝利,相同則判定平局。
2 稀疏獎勵解決方法
2.1 基于局部回報重塑的無人攻防集群對抗獎勵工程設定
無人集群對抗領域問題在應用強化學習技術時,現有的獎勵體系依據對局是否勝利進行獎勵反饋,對局勝利給予獎勵,對局失敗無獎勵。上述為稀疏獎勵的一種極端形式,名為二元獎勵。在該獎勵機制下,策略網絡訓練過程會被嚴重滯緩甚至策略網絡根本無法收斂。
本研究提出基于局部回報重塑的獎勵工程設計方法。即首先將任務分解為多個子任務,對應明確任務目標及子目標,在細分的過程中確定任務執行主體與子目標之間的邏輯關系。以異構無人集群對抗場景為例,因不同種類的智能體特點屬性不同,在任務中扮演的角色也有所不同。因此可以有針對性地對任務目標進行分解,適配不同種類智能體的功能屬性[22]。
針對本文研究的無人集群攻防對抗任務場景,在設定獎勵機制的過程中,依據不同種類智能單元的屬性特點分別設計獎勵函數。針對攻擊單元,鼓勵攻擊、低血量退避、躲避敵方探測單元等行為。針對防御單元,鼓勵有效防御行為。針對探測單元,鼓勵有效探測、躲避敵方攻擊、躲避敵方探測單元等行為。針對所有單元,鼓勵盡快結束回合行為,以上各種獎勵引導項的最終目標為短時間內消滅對方智能單元從而在單次對局中獲勝。上述定性設計結果如圖6所示。
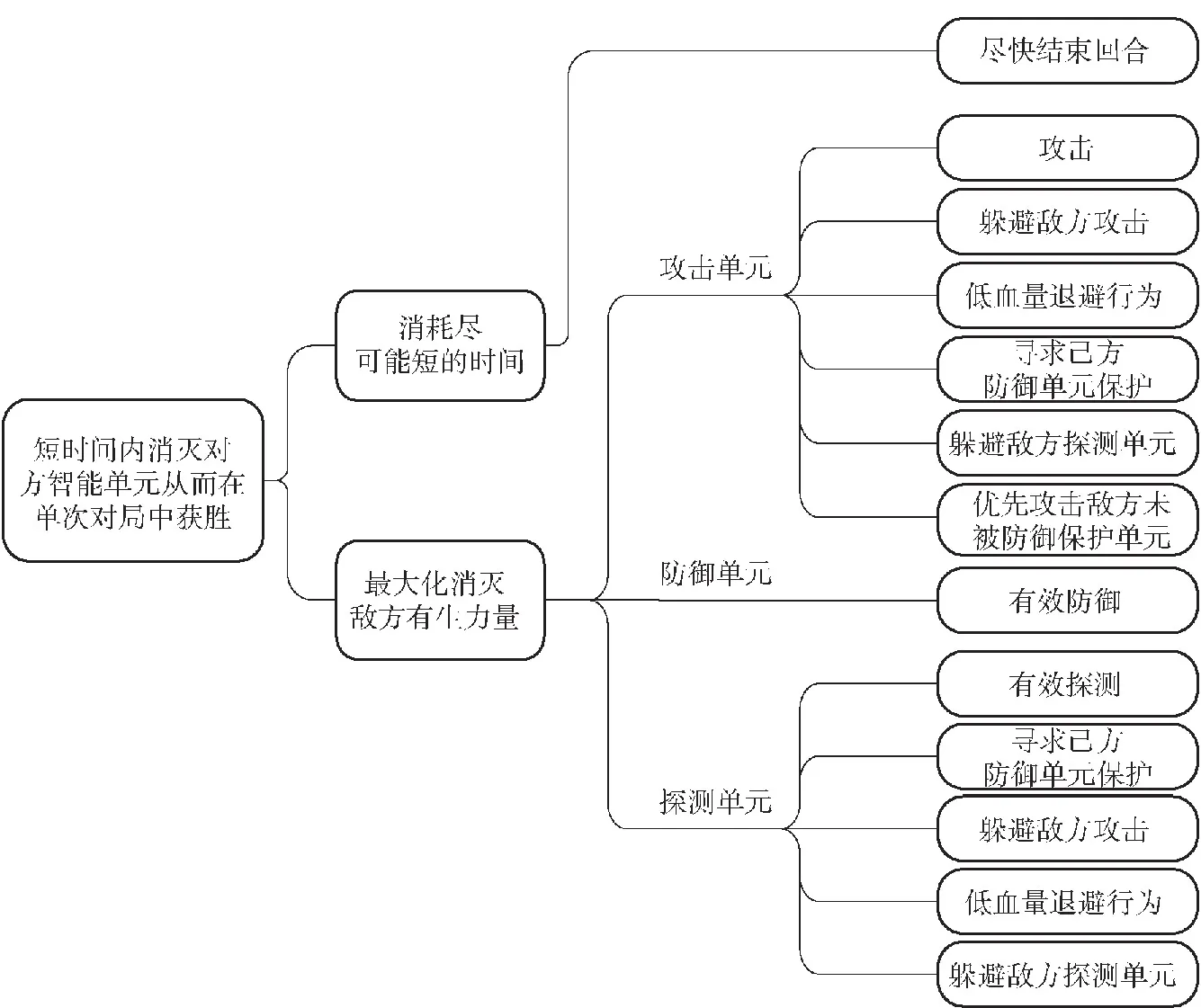
圖6 無人集群攻防對抗場景下基于局部回報重塑的獎勵工程設定Fig.6 Reward engineering setting based on local reward reshaping in UAV swarm attack-defense confrontation scenarios
定量獎勵函數設計方面,目前獎勵函數中獎懲數值設計主要依靠經驗。本研究場景下的獎勵函數為
(1)
(2)
式中:r為單次對局總獎勵;ri為第i回合總獎勵;rATj為單回合內第j個攻擊單元獎懲差;rDEk為單回合內第k個防御單元獎懲差;rDTl為單回合內第l個探測單元獎懲差。rATj計算公式為
(3)
式中:x1~x3為獎勵項,值為正;y1~y4、a、b為懲罰項,值為負。rDEk及rDEl獎勵函數計算方式同上。
2.2 基于局部回報重塑及PER的無人集群攻防對抗方法框架
通過局部回報重塑的獎勵工程設計方法對無人集群攻防對抗場景已有的二元獎勵進行擴充,獎勵體系得到了豐富。將單次對局下基于局部回報重塑的無人集群對抗所有回合獎勵信號進行輸出,結果如圖7所示。在總數約800個狀態動作序列對樣本中,只有約12%的狀態動作序列對存在獎勵信號,其余均無獎勵信號,這意味著約88%狀態下采取動作的有效性無法進行評判。因此,通過局部回報重塑方法設計的獎勵機制獎勵稀疏性依舊嚴峻。
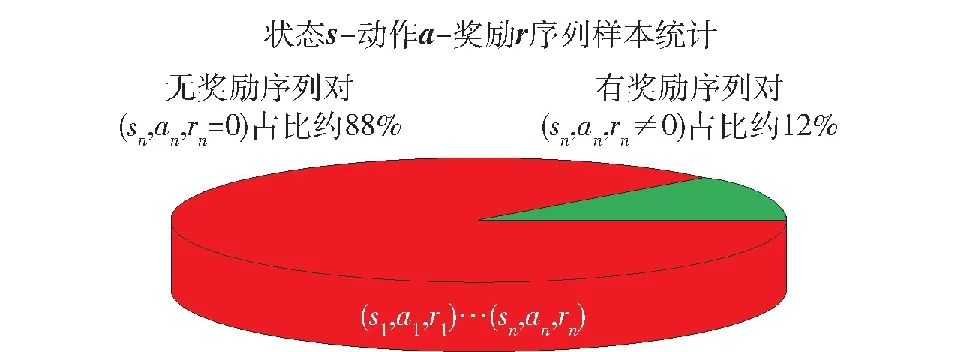
圖7 局部回報重塑方法下獎勵稀疏性示意Fig.7 Reward sparsity under the local reward reshaping
依據是否存在獎勵信號,智能單元與環境交互產生的狀態動作序列樣本具備不同的重要性。存在獎勵信號的狀態動作序列對有學習價值,優先級高。而無獎勵信號的狀態動作序列對無學習價值,優先級低。因此,可采用PER[23]實現對經驗樣本的差別利用。在回放訓練的過程中,通過對有效經驗樣本進行優先級排序,實現對高價值樣本的優先利用,以實現對抗策略的快速有效學習。在算法方面,因本文仿真模型為離散輸出,故選擇深度強化學習(DQN)算法[24]。采用回放記憶單元存儲(s,a,r,s′)序列,其中s為當前回合狀態,a為當前回合動作,r為當前回合獎勵,s′為下一回合狀態,基于PER算法對回放記憶單元進行優先級采樣,作為動作值函數逼近網絡與目標值網絡的訓練樣本,通過DQN誤差函數計算迭代,進行網絡參數更新。
綜上,若將局部回報重塑方法稱為稀疏獎勵問題下獎勵信號的“開源”,PER的使用則是從“節流”的角度對樣本進行了高效利用。通過獎勵信號“開源”、“節流”兩種手段實現了對稀疏獎勵問題的有效解決,最終形成基于局部回報重塑及PER的無人集群對抗自主決策與智能協同策略學習方法框架,如圖8所示。首先通過局部回報重塑方法對基于強化學習技術的無人集群對抗問題所固有的二元獎勵進行擴充,局部回報重塑很大程度上改善了獎勵的稀疏性,但獎勵稀疏性依舊嚴峻,然后依據樣本是否存在獎勵信號及獎勵信號數值進行優先級排序,在樣本回放學習過程中進行優先級采樣,對高價值樣本進行優先學習。最終通過兩種方法組合實現稀疏獎勵下無人集群自主決策與智能協同對抗策略的高效學習。
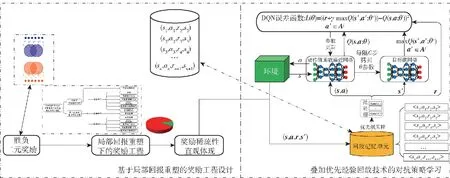
圖8 基于局部回報重塑及PER的無人集群對抗自主決策與智能協同策略學習方法框架Fig.8 Framework for autonomous decision-making and intelligent collaboration strategy learning method for UAV swarm confrontation based on local reward reshaping and prioritized experience replay
3 無人集群攻防對抗仿真及演示系統設計
3.1 無人集群攻防對抗程序仿真
在無人集群攻防對抗場景下,將強化學習算法與稀疏獎勵方法組合設計進行了程序仿真。
在DQN及局部回報重塑組合算法(簡稱DQN+局部回報重塑算法)下,通過2 000代訓練,紅方智能單元策略收斂,勝率約80%,如圖9(a)所示。采用DQN改進算法即Double DQN及局部回報重塑組合算法(簡稱Double DQN+局部回報重塑算法),通過緩解策略學習過程中價值高估問題,訓練1 500代后,策略實現了收斂,如圖9(b)所示。在上述方法基礎上,疊加PER(簡稱Double DQN+局部回報重塑+PER算法),通過對有效樣本的高效利用,訓練700代后策略實現收斂,如圖9(c)所示。
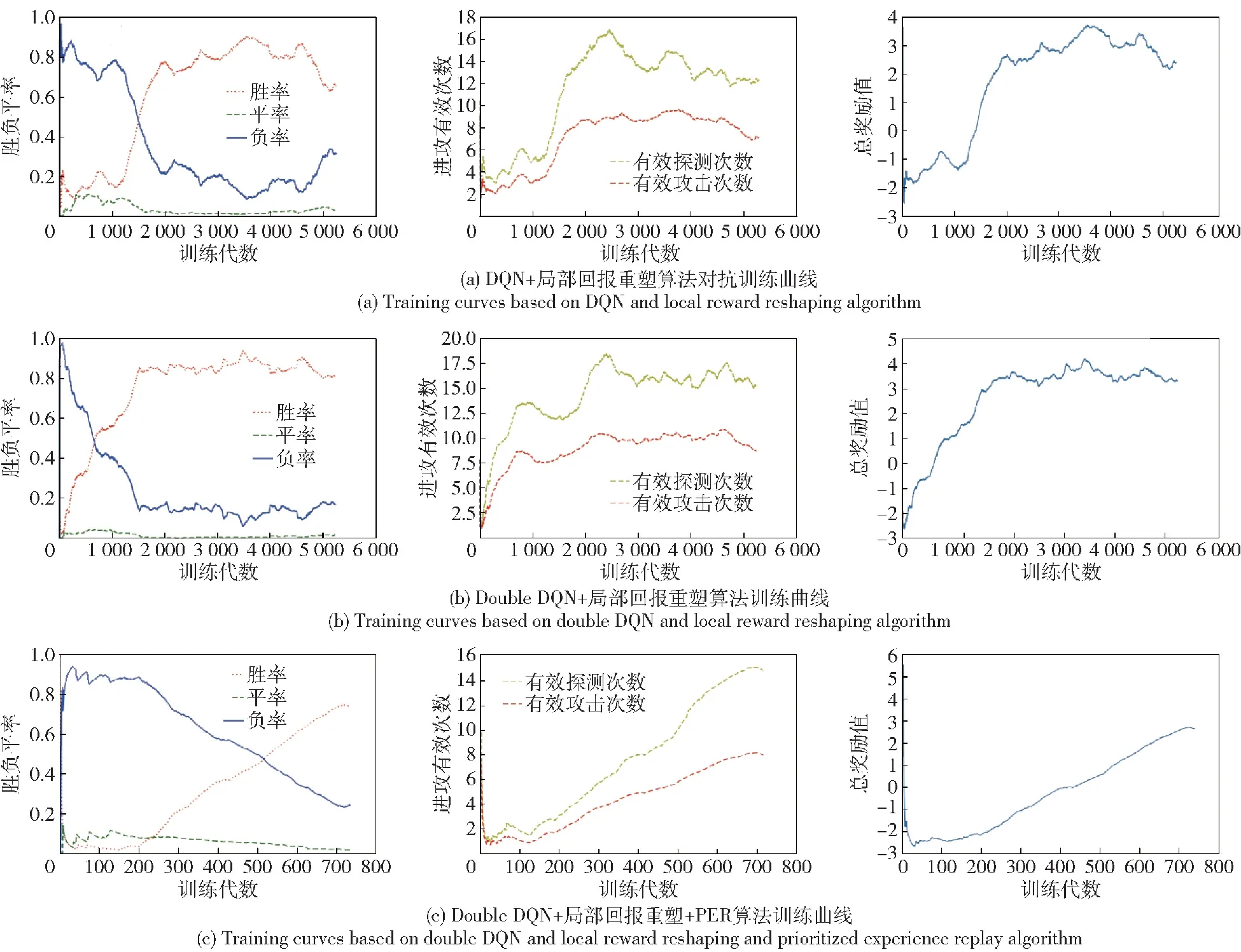
圖9 無人集群攻防對抗算法效率對比Fig.9 Efficiency comparison for attack-defense confrontation algorithms of UAV swarms
此外,在進攻有效數據及防御有效數據方面,仿真曲線圖均呈現逐漸提升的趨勢,證明了算法的有效性,3種算法效率對比如表1所示。
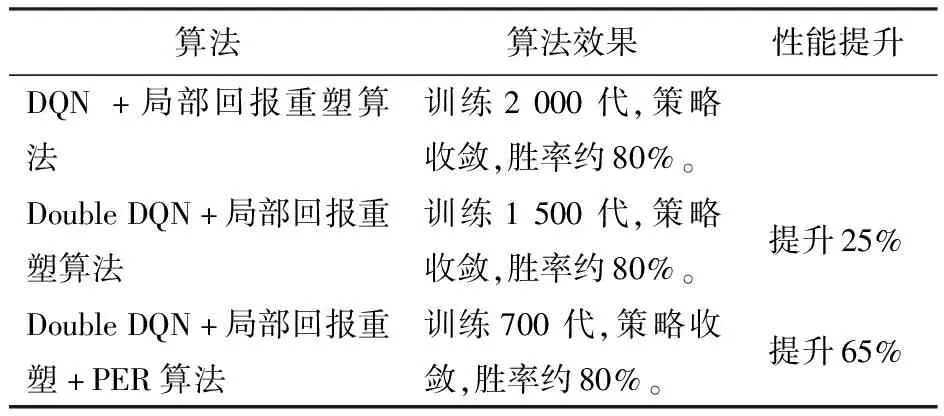
表1 無人集群攻防對抗算法效率對比Table 1 Efficiency comparison forattack-defense confrontation algorithms of UAV swarms
在同樣達約80%勝率的對抗能力前提下,DQN+局部回報重塑算法訓練了2 000代,Double DQN+局部回報重塑算法訓練了1 500代,算法提升25%,Double DQN+局部回報重塑+PER算法訓練700代,算法提升65%。
上述為算法在對抗策略宏觀層面的表現。在微觀層面,即策略收斂后的單次對局中,紅方無人智能集群呈現協同對抗態勢,如圖10所示。攻擊單元整體居中,在己方防御單元的防御保護下對處于己方探測單元探測視角內的敵方單元進行飽和攻擊;防御單元居陣型前方,集中防御,保護己方攻擊單元和探測單元;探測單元居陣型后方,向后退避、向前沖鋒行為動態切換,為己方攻擊單元提供探測視角的同時,最大化保證自身的生存。不同類型單元根據自身屬性特點實現了行為協同、功能互補,同類型單元也呈現出明顯的群集優勢。
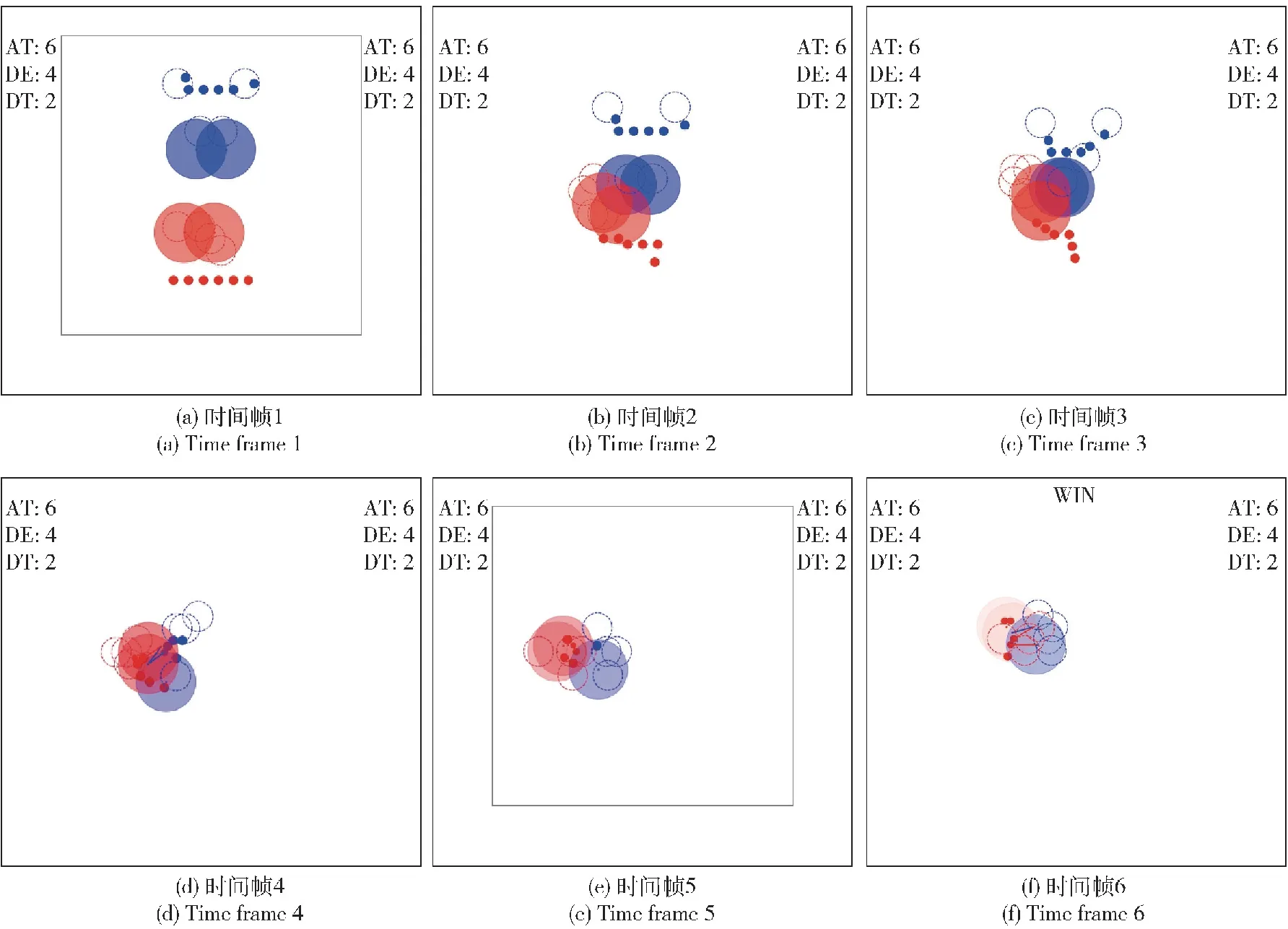
圖10 紅藍無人集群攻防對抗仿真對局態勢圖Fig.10 Situation forattack-defense confrontation simulation of red and blue UVA swarms
3.2 無人集群對抗演示系統
為了直觀展示紅藍雙方集群對抗過程,設計了無人集群對抗實時演示系統,如圖11所示。演示系統中針對無人集群攻防對抗任務場景設計了5個模塊,其中實時攻防對抗態勢演示模塊位于演示面板中央,雙方實時對抗過程以回合步為單位進行更新。攻防對抗雙方實時勝率演示模塊、攻防對抗雙方實時有效進攻/防御數據位于演示面板左側;雙方各類型單元實時存活數、雙方各類型單元實時總血量位于演示面板右側;左右側四大演示模塊除攻防對抗雙方實時勝率以對局為單位更新外均以回合步為單位更新。

圖11 無人集群攻防對抗任務場景演示面板Fig.11 Demonstration panel for attack-defense confrontation scenario of UVA swarms
4 結論
無人集群為無人系統與群體智能的結合,意圖通過群體智能算法使多數量無人系統具備自組織能力并實現協同能力涌現。在這一過程中,強化學習技術被廣泛采用,稀疏獎勵問題廣泛存在。本文構建了無人集群對抗模型框架,并以無人集群攻防對抗為具體場景進行了模型設計,通過分析獎勵函數機理機制,設計了局部回報重塑方法,并疊加PER方法,最后進行了程序仿真與演示系統設計。經對比證明該方法有效提升了算法效率,后續將在以下方面展開進一步研究:
1)針對稀疏獎勵問題,當前方法在智能性、泛化性、設計耗時方面具備提升空間,可進一步研究智能性更強、泛化性更好、設計耗時更短的稀疏獎勵算法,促進強化學習技術從理論研究邁向工程應用。
2)當前研究關注自主決策算法,后續可對基于實際動力學模型及態勢感知下的自主決策算法展開研究,進一步提升自主決策算法驗證過程置信度。
猜你喜歡
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
藝術啟蒙(2018年7期)2018-08-23 09:14:18
數學大世界(2018年1期)2018-04-12 05:39:14
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
