計算機系統類課程群概念圖自動構建研究
2023-07-16 08:16:32劉德喜陳雨婕劉宇星狄國強邱寶林廖國瓊
軟件導刊 2023年6期
劉德喜,陳雨婕,劉宇星,狄國強,邱寶林,廖國瓊
(江西財經大學 信息管理學院,江西 南昌 330013)
0 引言
計算機人才培養強調的程序性開發能力正在轉化為更重要的系統性設計能力,未來將會更關注學生掌握軟硬件協同工作的能力以及解決復雜工程問題的能力。根據新工科專業系統能力培養改革與實踐指導,突出系統化思想對于高校計算機專業教學和培養的重要影響。缺乏知識的整體性理解和系統的綜合實踐能力是現階段課程體系下暴露出來的問題,需要建立新的計算機專業教學課程體系,重新規劃計算機課程的重點內容和順序設置。高校受有限的教學課時等條件制約,需要對專業課程設置、課程內容選擇和課程之間的邏輯關系進行合理劃分和組織,形成一個有序、互聯的課程群落。系統類課程群的建設使專業知識框架更加合理和完善,帶動整體教學水平進一步提高,使學生的素質和實踐能力躍上新臺階。
計算機專業知識體系覆蓋范圍廣,課程群中術語和知識內容繁雜,不同課程知識之間具有連續性,授課過程中,一些術語總是孤立講授,未能與相關術語合理關聯,無法構成專業學科級知識體系。構建專業課程群應從課程定位以及課程之間的邏輯關系出發,基于最根本的課程內容結合“系統觀”思想,將專業知識點有機組織,有效指導教師的授課重點。通過融合和規劃相關課程群的信息,合理安排術語的講授順序和邏輯,可以在有限的時間內幫助學生構建知識框架,形成系統能力。
本文以計算機系統類課程群為例,基于術語、定義抽取及圖分析技術,自動完成課程群概念圖構建,以更好地輔助教師教學,培養學生系統能力并構建完整的知識框架,從而推動教育信息化、智能化發展。
1 相關研究
1.1 計算機系統類課程群及其建設方法
計算機系統類課程群建設主要研究在系統能力培養要求下的相關課程設置、課程定位和課程之間的邏輯關系。國內各高校參照示范單位并基于本校師資等條件,建設適合自己的計算機類專業系統能力培養方式,提高學生適應新經濟發展的整體素質和能力。
其中,清華大學提出分層、雙向的系統能力培養課程體系建設新思路,借鑒國外著名高校,開設系統能力培養課程橫縱向梳理知識體系,明確各層次教學內容,建立計算機系統層次間的聯系,并輔以課程實驗體系,逐級遞進,以迭代的方式培養學生能力[1]。廣東工業大學針對軟硬件教學活動分離的現狀,提出兩者結合的計算機專業基礎課程群實驗教學模式,通過對“軟”“硬”線課程內容協同優化,再總結和挖掘課程間的內在聯系,結合教學方案構建課程群知識地圖,通過關鍵路徑發現先修、后修制約關系支撐教學[2]。桂林電子科技大學根據系統能力培養總目標及計算機系統各層次之間的關系,明確各課程教學目標,并構建“三橫兩縱”實踐課程教學體系,從基礎、專業和綜合3個層次能力培養逐步過渡,和開設軟、硬件課程實踐環節兩個角度,培養學生計算機系統綜合開發能力[3]。北京航空航天大學以“三位一體”教學目標和“三工”教學準則,由傳統建設模式轉變為“以課程群為中心”的建設模式,精簡非必要知識,重構整個課程群體系[4]。其他高校計算機院系也以“系統能力培養”為主線組建“系統能力培養課程群”,對教學內容依學生掌握程度進行分解和整合,挖掘不同課程的相似內容,實現整體化協作式教學[5-6]。
本文依據教材分析整個課程或課程群中的相關術語及其之間的內在關系,構建計算機系統類課程群中的概念圖譜,輔助建設課程群。本文創新性地提出利用自動分析方法識別整個課程或課程群中的術語、定義,并確定核心術語以及它們之間的關聯形成專業課程群概念圖。該方法一方面可以改進現有研究在分析課程群概念關系上的主觀性,同時還能從課程群全局或系統出發,勾勒出概念關系圖,有利于幫助學生建立系統觀。
1.2 課程概念圖譜構建
課程概念圖譜直觀展示專業中的各個概念以及整合它們的關系網絡,是課程群建設的重要內容。相關工作中,有的從授課內容出發,構建簡略的教學知識圖譜[7];有對龐大的知識點進行梳理和分割,構建分層拓撲的概念圖譜[8]。這些方法中,主要根據對培養方案和教學大綱的研討和論證完成對知識點的提煉。已有工作大都采用人工方式,受人力、時間等因素局限,往往只涉及單個課程,提煉的知識點數量也很有限,難以展示課程知識結構以及知識點之間的關系。
在教育領域,對知識圖譜自動構建時,張勇等[9]以教學大綱和百度詞條為基礎,利用基于“自舉”的知識點識別算法,以典型知識點詞條為基礎,逐步擴展收集學科相關的其他知識點詞條,采取融合基于知識點上下文相似性和基于百度百科的點互信息策略構建知識點之間的關聯性,從而構建面向教育信息化和智能化的學科知識圖譜。黃超等[10]根據MOOC平臺上的課程相關信息,進行課程術語挖掘和課程先后序學習,其中借助圖的置信度傳播算法進行課程術語抽取,使用基于課程大綱骨架的抽取算法確定術語的上下文關系。朱鵬等[11]以課程知識內容的Web文檔資源為數據,構建基于課程知識圖譜的課程知識導航服務平臺,計算TF-IDF(Term Frequency-Inverse Document Frequency)和MI(Mutual Information)的權值,并結合相似度和細化度方法,科學地量化課程術語間的層次關系并完成課程知識圖譜模式層的本體構建,利用DOM(Document Object Model)樹完成課程知識圖譜的知識實例抽取。
本文創新性地利用自然語言處理等技術,從專業課程的文本教材中自動抽取術語及其依賴關系,以指導課程群建設。創新點體現在:構建了面向計算機課程教材的語料庫;結合規則、統計和深度學習方法,抽取教材中的專業術語及其定義,構建課程群概念圖譜;利用圖分析法對概念節點進行權重分析,識別核心概念。
2 課程群概念圖譜構建
課程群概念圖譜是基于術語節點之間的內在關系而形成的知識邏輯網絡,其中每個節點由教材文本中自動抽取的術語知識點構成,并基于它們在文本中的邏輯關系自動搭建術語之間的聯系。課程群概念圖譜的結構化形式貼合專業課程群的知識體系和知識結構,可以幫助教師設計更高效的培養方案和教學計劃,也可以幫助學生梳理知識點,形成系統觀。
課程群概念圖譜CNet(Concept Network)構建方案如圖1所示。
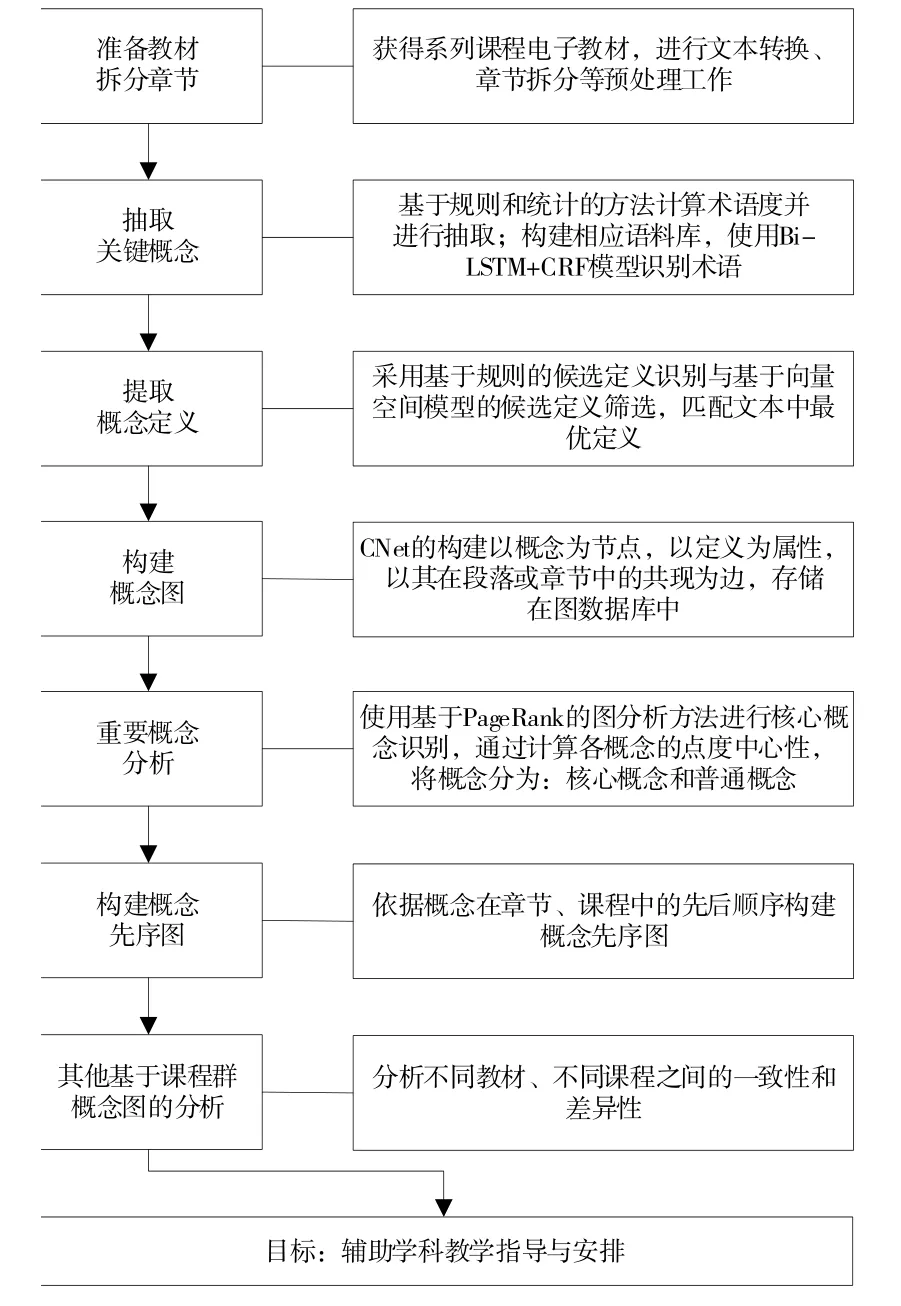
Fig.1 Construction plan of curriculum group CNet圖1 課程群概念圖譜CNet構建方案
2.1 術語抽取
術語抽取是構建課程群概念圖CNet的基礎,圖譜中的節點由文本中抽取的重要術語構成。本文基于計算機專業系列教材,包括《操作系統》《計算機組成原理》《計算機網絡》《數字邏輯》等不同課程的多部教材,采用基于規則方法和基于深度學習的方法。
2.1.1 基于規則和統計的術語抽取
將術語構詞規則、術語長度、術語出現頻率等因素作為詞語術語性的衡量標準。為解決基礎算法破壞術語構詞完整性、領域性的問題,采用單詞片拼接、語法規則庫過濾、融合TF-IDF和C-value的算法等步驟進行基于規則和統計的術語抽取[12]。
首先對原始語料進行分詞后得到單詞片,由于通用詞典分詞會破壞術語完整性,對每個單詞碎片與左右相鄰片段進行拼接得到詞串以還原術語的長度及單元性,其中根據計算機術語長度的最大值限制最大單詞片拼接數為5。對詞串串頻進行統計,為能涵蓋更多術語,將頻數閾值定為能涵蓋90%詞串處的值,串頻大于閾值的詞串將作為候選術語。由此得到的候選術語更具單元性和領域性,同時該方法也可處理嵌套術語的問題,例如“操作系統”和“單道批操作系統”的頻數同時大于閾值,則兩者都將被提取。
單純依靠單詞片的拼接,會導致結果中存在不符合邏輯或不符合術語構詞規則的短語。本文根據文本語料、實驗結果和語言學特征,總結明顯不能作為術語構詞的詞性規則,非術語構詞規則如表1所示。

Table 1 Rules of non-term words表1 非術語構詞規則
對候選術語進行詞性標注,并根據規則庫對不符合規則的候選術語進行過濾。但由于篩選后的結果中還包括普通常見詞語、無意義的字串等。針對出現的問題,參考張靜等[12]提出的IC-value計算公式,融合TF-IDF與C-value算法計算候選詞的術語度。
C-value算法主要依據統計信息,考慮了術語長度和嵌套術語的影響,認為術語長度對C-value值起促進作用。對于嵌套術語,若嵌套詞串出現的頻數較高,則被嵌套串是術語的可能性就越小,即嵌套串詞頻對被嵌套串的值起消極作用。但C-value方法不能有效過濾一些出現頻次很高的普通詞匯,因此融合算法中加入TF-IDF算法中的逆文檔頻率,以降低高頻次普通詞匯的術語度值。
本文根據處理方式的不同,采用改進的融合算法,既考慮了術語長度和術語嵌套,又剔除掉常用的普通詞匯,對候選術語a的術語度計算如式(1)所示。
其中,|a|表示候選術語a的長度即候選術語包含的字數,tf(x)表示x在文檔集中出現的頻次,df(a)表示候選術語a的文檔頻率,b是候選術語a的嵌套候選術語,Ta表示候選術語a的嵌套候選術語集合。
2.1.2 基于BiLSTM+CRF的術語識別模型
將術語識別轉化為序列標注任務,構建訓練集BiLSTM+CRF模型,并通過測試集考察模型對術語識別的效果。
計算機專業領域的術語范圍較大,種類較多,選取教材文本作為語料,其包括常見的重要術語,本次研究的重點在于識別所有教學術語,為后續構建概念圖做鋪墊。由基于統計和規則的方法得到結果,經過人工篩選后作為初始詞典,對教材中的字串打上“B”“I”“O”3種標簽,分別代表術語的開頭、術語的后續和非術語。
對教材每個章節均采用兩輪標注,下文對具體任務內容進行介紹。第一輪標注:使用當前詞典中所包含的術語,以章節為單位,進行第一輪標注,對得到的標注結果,進行人工審核和識別,并向計算機術語詞典中添加未標注的新術語,進行更新。第二輪標注:依據更新后的教材術語詞典對已進行第一輪標注的章節再次標注,并以句子為單位進行分割。
語料庫涵蓋計算機專業4門課程的教材文本,分別為:《操作系統》《計算機網絡》《計算機組成原理》《數字邏輯》,共有效標注17 122個句子,其中《操作系統》6 036句、《計算機網絡》6 962句、《計算機組成原理》3 814句、《數字邏輯》310句,平均每個句子包含4個術語,最多的包含26個術語,最少的情況為句子中沒有術語,句子中術語字符占比平均值為0.07,最大值為0.23;語料中共包含4 426個術語,他們出現的頻次為77 342次,其中《操作系統》30 392次、《計算機網絡》30 815次、《計算機組成原理》14 758次、《數字邏輯》1 377次;術語的平均長度為6個字符,最大長度為49個字符,在詞典中僅有一個,是“Internet-SecureAssociationandKeyManagementProtocol”,最小長度為1個字符。
BiLSTM+CRF模型通過神經網絡自動學習字符的特征和字符間關系,再由條件隨機場優化輸出序列,達到自動學習識別術語的目標。雙向長短期記憶網絡適合處理長序列數據,其隱藏層節點不僅取決于當前輸入的信息,還受前一時刻歷史數據的影響,因此能夠在處理整個序列數據時,不僅考慮單個詞語,還能更好地利用每個詞前后的雙向語義特征信息。同時在長序列訓練中,能夠處理反向傳播中出現的梯度消失和爆炸問題,有選擇地記憶重要信息和忘記不重要信息。條件隨機場可以學習標簽之間的約束關系,根據輸入的特征向量優化輸出序列,防止不合法的標簽情況。
2.2 術語定義提取
CNet抽取術語的定義作為概念圖譜中節點的屬性。術語定義提取包括兩個階段:基于規則的候選定義識別和基于向量空間模型的候選定義篩選。
受文獻[13-15]的啟發,結合對語料庫中定義語句的特征分析,首先通過術語定位候選句式,即句子中的關鍵詞被冒號引起來,或者后面接上了術語的英文形式。相應的規則表達式為:Term→[“|”|"]?+關鍵詞+'[“|”|"]?((.*?))?
定義8條候選定義識別規則,即術語所在的句子如果符合以下規則,則該句子為術語的候選定義。其中,“句首號”表示出現在句子開頭的符號,如句子開頭、逗號、右括號、序號等;“句尾號”表示出現在句子結束或停頓的符號,如句子結尾、逗號、分號等。具體規則如表2所示。

Table 2 Extraction rules of term definition表2 術語定義抽取規則
對于某個術語,基于規則可能識別出多條候選定義,本文借助向量空間模型進行術語定義準確度排序,計算選定的術語和候選定義之間的相似度,據此篩選出最合適的術語定義[14]。向量空間模型(Vector-space models,VSM)用特征項及其相應權值代表文檔信息,將文檔表示為向量,通過向量計算文檔之間的相似性。
給定候選術語定義句子S1,S2,S3,…,Sn,先對句子進行停用詞過濾,將過濾后得到的詞作為句子的特征項,再將候選術語定義句子視為一個集合,進行詞頻統計,挑選出前m個高頻詞語,構建高頻詞向量H=(<t1,w1>,<t2,w2>,…,<tm,wm>),t1,t2,…,tm為該術語定義的詞語坐標系,w1,w2,…,wm為相應的詞頻,作為其坐標值。之后,針對每個候選句子,根據高頻詞向量的詞語坐標,對其特征項進行詞頻統計,構建每個候選句子的向量S=(<t1,w1>,<t2,w2>,…,<t15,wm>)。計算每個句子向量與高頻詞向量的相似度,相似度最高的句子作為術語定義的最優選擇。本文在每個章節中的術語定義篩選時,m設置為15。
本文的定義提取是在特定領域,對于一個特定術語而言,所需篩選的候選定義與選定的術語屬于一個領域內的詞語,可能會多次出現在不同的句子中,導致其IDF值較低,因此與傳統TF-IDF權重不同,此處只以詞頻TF為權重。給定一個文檔S=(<t1,w1>,<t2,w2>,…<ti,wi>,…,<t|D|,w|D|>),t1,t2,…,t|D|是一個由詞表D張成的|D|維的坐標系,wi為詞ti在S中的權重,即詞頻,則S可表示為向量<w1,w2,…,wi,…,w|D|)。同樣地,視高頻詞集合為一個文本后,也可以表示為一個向量,記為H=<h1,h2,…,hi,…,h|D|)。H和S之間的相似度定義為兩個向量的夾角余弦,如式(2)所示[14]。
3 實驗與結果分析
3.1 數據集及實驗設置
實驗的數據集包括:湯小丹等編著的《計算機操作系統》(第三版)、左萬利等編著的《計算機操作系統教程》(第四版)、任國林編著的《計算機組成原理》、唐朔飛編著的《計算機組成原理》、謝希仁編著的《計算機網絡》(第7版)和陳光夢編著的《數字邏輯基礎》。
數據集共包含16 352條標注語句,對全部語料按照15∶1:1的比例劃分為訓練集、驗證集和測試集進行實驗。為測試訓練的模型是否能屏蔽上下文環境影響和是否具有發現新術語的能力。其中,新術語表示在訓練數據中未出現過而在測試集中出現的術語,實驗中使用《操作系統》《計算機網絡》《計算機組成原理》3本教材某一版本構成訓練集,并設置3個測試集,分別使用與上述3門課程教材相同(測試集1)、課程相同教材不同(測試集2)和課程不同(測試集3,《數字邏輯》教材)的測試數據。各數據集統計信息如表3所示。
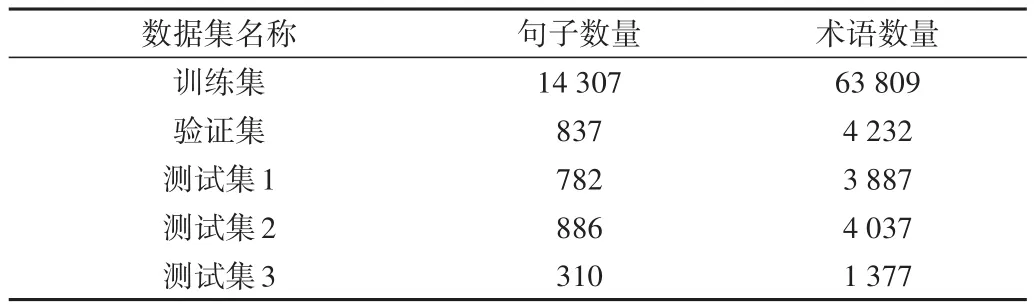
Table 3 Data set statistics表3 數據集統計
BiLSTM-CRF模型參數設置如表4所示。采用的字符向量維度為100維,字符LSTM的隱層大小為105維。使用隨機梯度下降(SGD)算法訓練模型,設置一個批次的樣本數為10,迭代次數為50,學習率為0.001。

Table 4 Parameter settings表4 模型參數設置
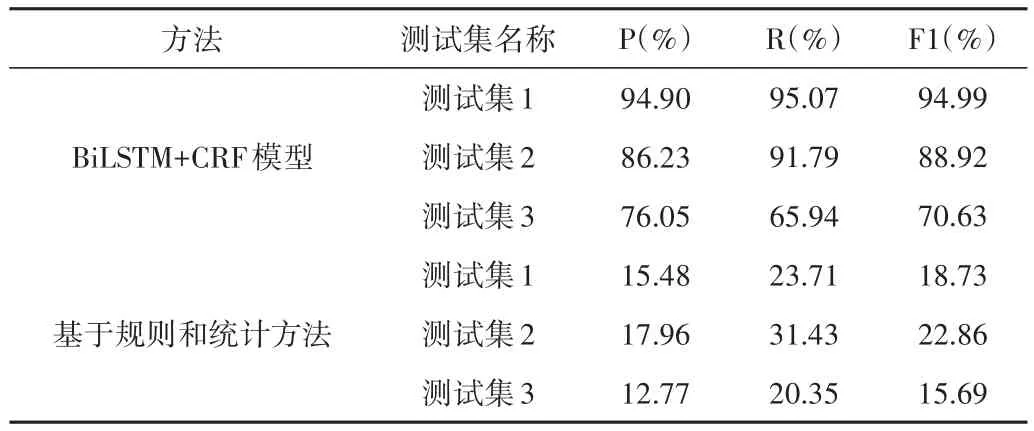
Table 5 Results of term recognition表5 術語識別結果
3.2 術語抽取實驗結果
對抽取結果選取精確率(Precision)、召回率(Recall)和F1值(F-Measure)作為評估指標。根據計算公式得出兩種方法在3個測試集上術語識別的對比結果。
對比BiLSTM+CRF模型在3個測試集上的表現:
測試集1與訓練集來源于相同教材,具有相同的上下文環境和同領域的術語。因此,根據上表的結果顯示,識別的效果在3個測試中最好,精確率和召回率都在95%左右,能夠有效抽取大部分術語。
測試集2與訓練集所屬相同課程,但來自于不同作者的教材。相對于測試集1,其改變了上下文環境,但是術語種類大致相似。根據實驗結果,精確率降低約10%,但召回率相差不多。模型在改變環境后,多識別出了一些非術語的詞語,例如:“LAN與WAN”“字證書”“FTP服務器”……出現很多將多種術語連在一起識別成一個術語、多識別或少識別出一個完整術語的部分字符的情況,但是在正確術語的覆蓋率上表現較好。
測試集3與訓練集屬于不同課程,因此大多數術語屬于沒有在訓練時出現過,僅僅出現過少量多門課程共同的術語。測試集3的目的在于測試模型的新詞發現能力。根據結果,模型識別出《數字邏輯》中199種新術語,包括“多輸出邏輯函數”“組合邏輯電路”“同步時序邏輯電路”“SynchronousSequentialLogicCircuit”……但是整體召回率較低,存在識別錯誤的非術語詞,例如:將“卡諾圖簡化邏輯函數”中的兩個術語抽取成“圖簡化邏輯函數”“數字邏輯系統”只抽取了“字邏輯系統”……模型在識別新詞方面還有待提高。
基于規則和統計的方法與BiLSTM+CRF模型相比,其準確率和召回率都相差較大,在候選術語頻率統計階段出現了較多低頻術語被篩掉的情況。其中,測試集1中被篩掉的低頻術語有216個,測試集2中被篩掉171個,測試集3中被篩掉67個,導致抽取效果不佳。
根據術語抽取結果,采用基于規則的候選定義識別與基于向量空間模型的候選定義篩選算法,對每個術語進行相應定義提取。實驗結果顯示,該方法在本文所給定的教材上有較好的抽取結果。基于規則匹配的方法具有良好的描述能力,而向量空間模型則考察了候選定義的相關性和重要性。
4 課程群概念圖譜及應用
4.1 課程群概念圖構建
CNet中共有4 426個節點,按所屬科目添加了不同顏色的標簽,節點屬性展示了相應的定義。通過PageRank算法可將它們按照重要性劃分為:普通術語和核心術語。按照專業術語在語料中的共現關系構建邊,其中一般關系(CoInChapter)表示連接的兩個節點在同一章節共現;緊密關系(CoInPara)表示連接的兩個節點在同一段落中共現。最終,完成的課程群概念局部圖展示如圖2所示。
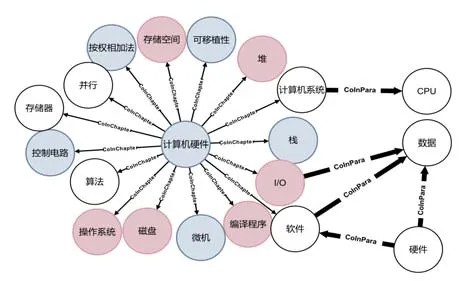
Fig.2 Partial display of curriculum group CNet圖2 課程群局部概念圖展示
4.2 核心術語分析
將課程群中的術語節點按重要性進行分類,可以幫助教師在課堂中有側重性地加以講解,加深學生術語學習印象。本文通過PageRank算法計算各術語的點度中心性,根據點度中心性的排序鑒定術語是否屬于核心術語[16-17]。
PageRank算法中一個節點的重要性依據鏈接節點的數量和鏈接結點的權重,對每個鏈入節點經過遞歸算法計算,達到收斂后,即為該節點的PR值,如式(3)所示。
其中,PR(A)是節點A的PR值;節點Ti是指向A的所有結點中的某個結點;C(Tn)是結點Tn的出度,也即Tn指向其他節點的邊的個數;d為阻尼系數,是指在任意時刻,用戶到達某結點后并繼續向后跳轉的概率,通常d=0.85。
本文實驗中設置迭代次數為20次,阻尼系數設置為0.85。對于概念圖中的每個節點計算其PR值,并設定閾值0.5,將大于閾值的術語定為重要術語,小于閾值的定位為普通術語,在圖譜中以不同節點加以區分。
4.3 課程群概念圖譜應用
課程群概念圖CNet旨在輔助課程群建設和教學。CNet融合和規劃了相關課程的群體性信息,又保留了每門課程單個術語自身的信息,可以在以下方面輔助教與學。
(1)使用CNet輔助高校專業課程體系構建。CNet中術語節點之間的聯系可以形成單門課程甚至整個專業的知識圖譜,幫助分析章節內、課程內、課程間不同術語之間的關系,進而形成概念子圖、概念社群,輔助課程群建設,合理安排課程設置,研究課程之間的邏輯關系。同時,也可以在培養方案設計時,恰當地劃分各課程的邊界,形成內容緊湊、銜接合理、分工明確的課程群。例如:存儲管理中“段頁式存儲管理”“虛擬存儲器”與存儲系統中“高速緩沖存儲器”“快表”以及“主存—輔存層次”之間的聯系,如圖3所示。
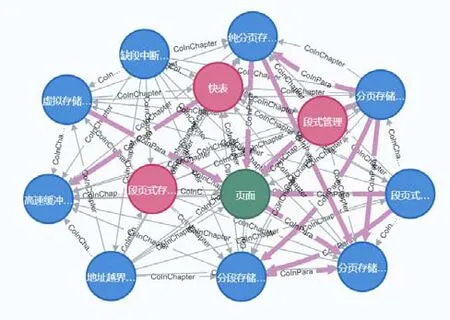
Fig.3 Sub-network of concept "storage management"圖3 “存儲管理”概念子圖
(2)CNet可以同時為教師與學生雙方服務。如果將課程學習的過程分為:預習階段、課堂拓展階段、課后復習階段。在預習階段,可以通過整個框架和核心術語對總體內容進行了解;課堂學習時,教師合理拓展關聯性術語,進行鞏固或延申講解;對課程內容總結復習時,重點關注核心術語,并將相關知識串聯,構建知識體系。利用概念圖進行自適應學習,依據使用者對知識的掌握程度,構建學習畫像,選擇圖譜中不同的概念子圖、不同的學習路徑,以提供個性化幫助,提高學習針對性。圖4是在概念知識圖譜基礎上,針對“數據表示”這一知識點提取和調整后的概念子圖,可以幫助學生了解各種數據表示方法之間的聯系。
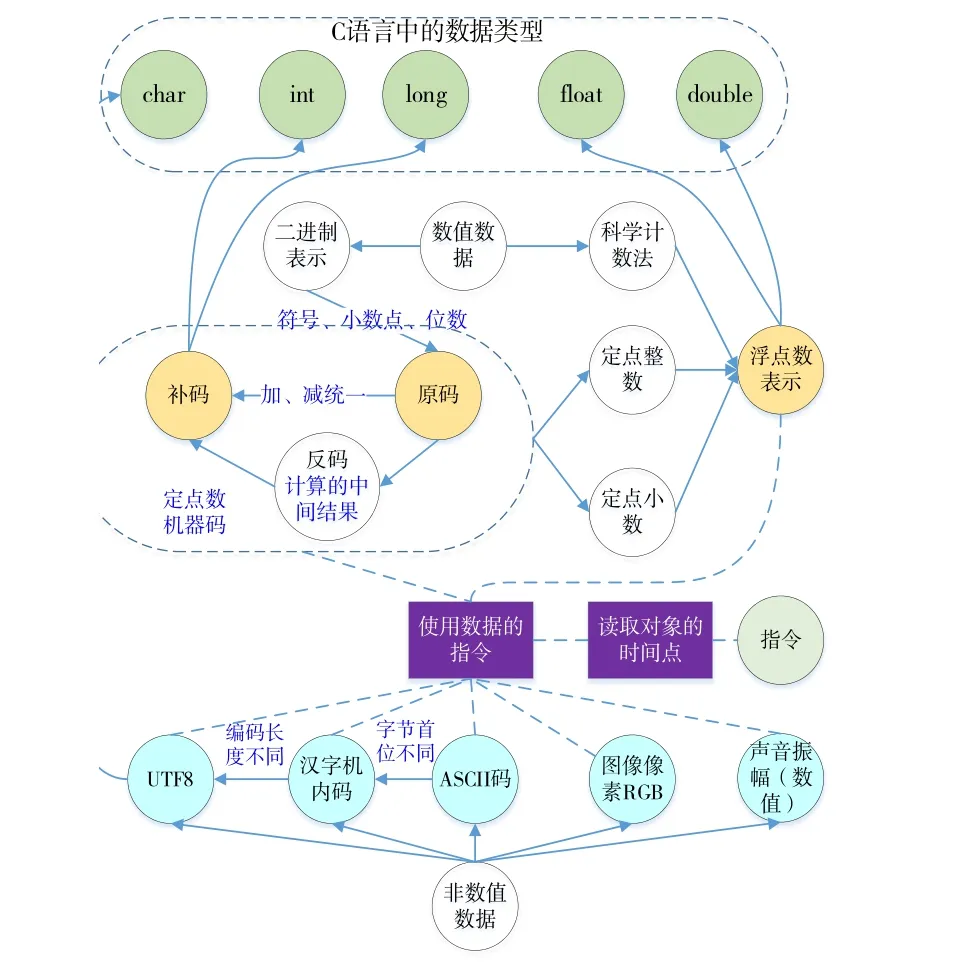
Fig.4 Sub-network of "data representation" knowledge point圖4 “數據表示”知識點的概念子圖
5 結語
在計算機專業系統能力培養時,課程內容的選擇和課程術語的梳理是課程群建設和教學改革的重要基礎,目前方法主要是基于任課教師的經驗,缺乏定量分析,主觀性較強。如何自動且有效地將各課程中的術語知識點有機組織起來,幫助教師在教與學時把握重點、理清關系,站在課程、課程群甚至整個專業的高度理解各個術語,提升系統觀和系統能力,這是本文構建概念圖譜的主要目的。本文通過文本分析、自然語言處理等技術實現課程群概念圖譜構建,輔助教師和學生由點及面地理解知識點,架建知識框架,形成系統能力。
本文以計算機系統類課程群為例,詳細闡述了課程群概念圖譜構建的完整過程。首先,使用基于規則和統計的方法以及基于BiLSTM+CRF的模型,從教材文本中抽取用于構建圖譜節點的關鍵術語;其次,通過基于規則匹配的術語定義識別算法和基于向量空間模型的定義篩選算法,從文本集中篩選最適合術語的定義作為相應節點的屬性,以術語在段落中的共現和在小節中的共現作為關系緊密程度的區分,分別構建了緊密關系和普通關系兩種邊,在圖譜中加以區分展示;第三,基于PageRank算法,分析概念圖譜中術語的重要性,將術語分為重要術語和普通術語,并在圖譜中區分顯示;第四,選擇高效的存儲方法,將課程群概念圖譜進行存儲,用以輔助教學。
本研究是課程群概念圖譜的初步探索,還有很多待改進之處,如計算機專業領域包含學科課程眾多,目前只對4門主要課程進行語料庫構建。后續工作中,可以繼續添加新課程教材文本,以及進一步擴充語料庫等。由于不同課程之間術語大多不同,本文的標注方法需要耗費大量人力,接下來可以進行方法的替換和更新,自動生成專業語料或者使用遷移學習更方便地構建語料庫。此外,本文所使用的基礎混合算法模型,在已學習的數據集上表現較好,而在更換上下文環境后以及進行新術語識別方面,還有待提高。可在基礎算法上作進一步優化,例如:在詞向量中加入子詞單元、語言學特征、注意力機制、多維特征等,以提高模型適應性和識別能力。同時,由于教材文本的行文特點,其中存在大量口語化表達,從而導致抽取出的結果中出現同義術語的多種表述形式,而這樣的同義術語應當在概念圖中使用一個節點進行表示。后續應對抽取的術語進行同義詞合并,進一步優化課程概念圖的存儲空間和查詢效率。
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
新世紀智能(英語備考)(2021年10期)2022-01-18 05:12:14
新世紀智能(英語備考)(2021年9期)2021-12-06 05:22:38
新世紀智能(英語備考)(2021年11期)2021-03-08 01:10:02
新世紀智能(英語備考)(2020年11期)2021-01-04 00:41:50
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
山東青年(2016年1期)2016-02-28 14:25:25
當代修辭學(2014年3期)2014-01-21 02:30:44
